
小白學 Python 爬蟲(29):Selenium 獲取某大型電商網站商品資訊

人生苦短,我用 Python
前文傳送門:
小白學 Python 爬蟲(1):開篇
小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝
小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門
小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門
小白學 Python 爬蟲(5):前置準備(四)資料庫基礎
小白學 Python 爬蟲(6):前置準備(五)爬蟲框架的安裝
小白學 Python 爬蟲(7):HTTP 基礎
小白學 Python 爬蟲(8):網頁基礎
小白學 Python 爬蟲(9):爬蟲基礎
小白學 Python 爬蟲(10):Session 和 Cookies
小白學 Python 爬蟲(11):urllib 基礎使用(一)
小白學 Python 爬蟲(12):urllib 基礎使用(二)
小白學 Python 爬蟲(13):urllib 基礎使用(三)
小白學 Python 爬蟲(14):urllib 基礎使用(四)
小白學 Python 爬蟲(15):urllib 基礎使用(五)
小白學 Python 爬蟲(16):urllib 實戰之爬取妹子圖
小白學 Python 爬蟲(17):Requests 基礎使用
小白學 Python 爬蟲(18):Requests 進階操作
小白學 Python 爬蟲(19):Xpath 基操
小白學 Python 爬蟲(20):Xpath 進階
小白學 Python 爬蟲(21):解析庫 Beautiful Soup(上)
小白學 Python 爬蟲(22):解析庫 Beautiful Soup(下)
小白學 Python 爬蟲(23):解析庫 pyquery 入門
小白學 Python 爬蟲(24):2019 豆瓣電影排行
小白學 Python 爬蟲(25):爬取股票資訊
小白學 Python 爬蟲(26):為啥買不起上海二手房你都買不起
小白學 Python 爬蟲(27):自動化測試框架 Selenium 從入門到放棄(上)
小白學 Python 爬蟲(28):自動化測試框架 Selenium 從入門到放棄(下)
目標
先介紹下我們本篇文章的目標,如圖:
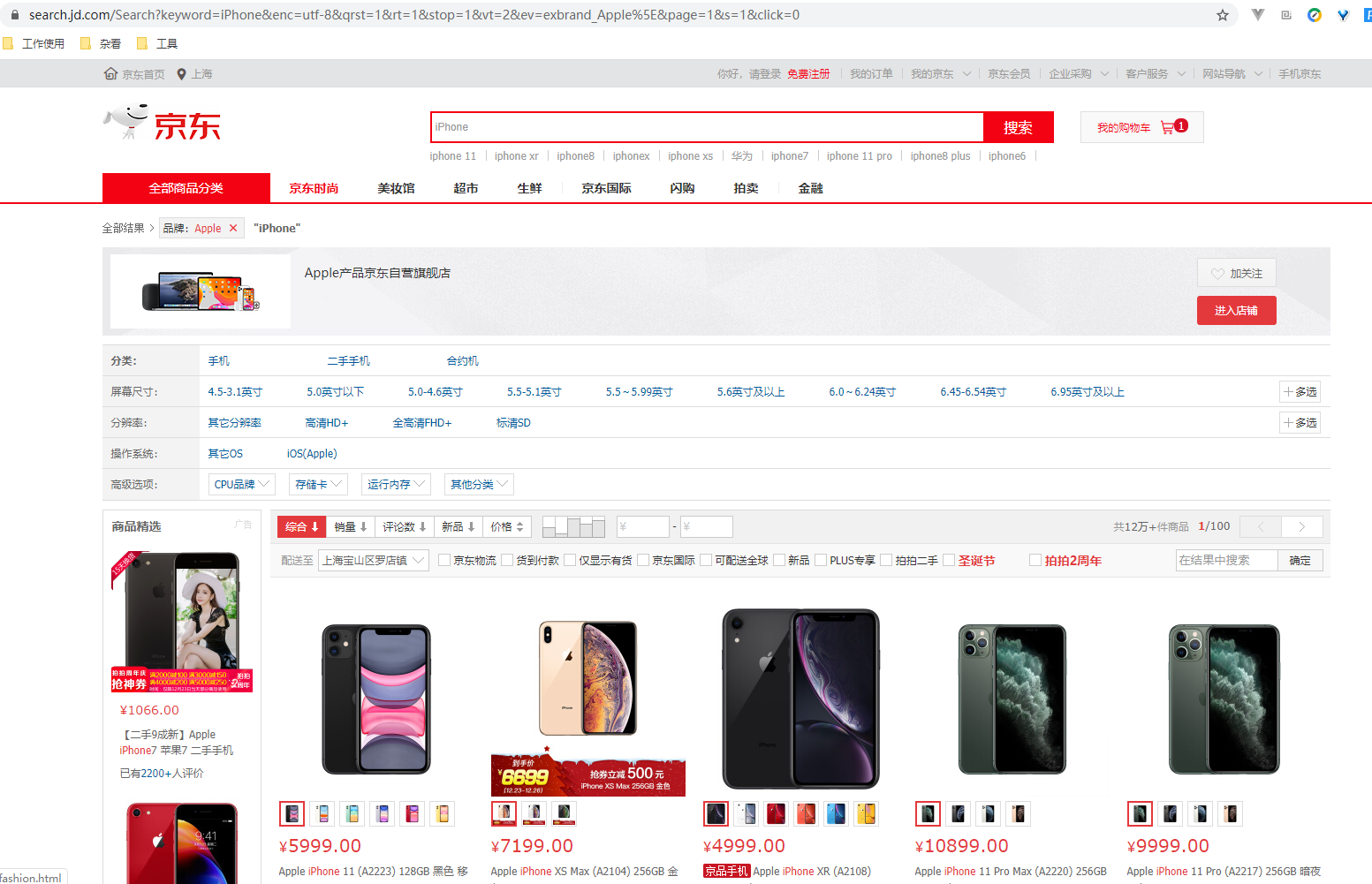
本篇文章計劃獲取商品的一些基本資訊,如名稱、商店、價格、是否自營、圖片路徑等等。
準備
首先要確認自己本地已經安裝好了 Selenium 包括 Chrome ,並已經配置好了 ChromeDriver 。如果還沒安裝好,可以參考前面的前置準備。
分析
接下來我們就要分析一下了。
首先,我們的搜尋關鍵字是 iPhone ,直接先翻到最後一頁看下結果,發現有好多商品並不是 iPhone ,而是 iPhone 的手機殼,這個明顯不是我們想要的結果,小編這裡選擇了一下品牌 Apple ,再翻到最後一頁,這次就全都是手機了。
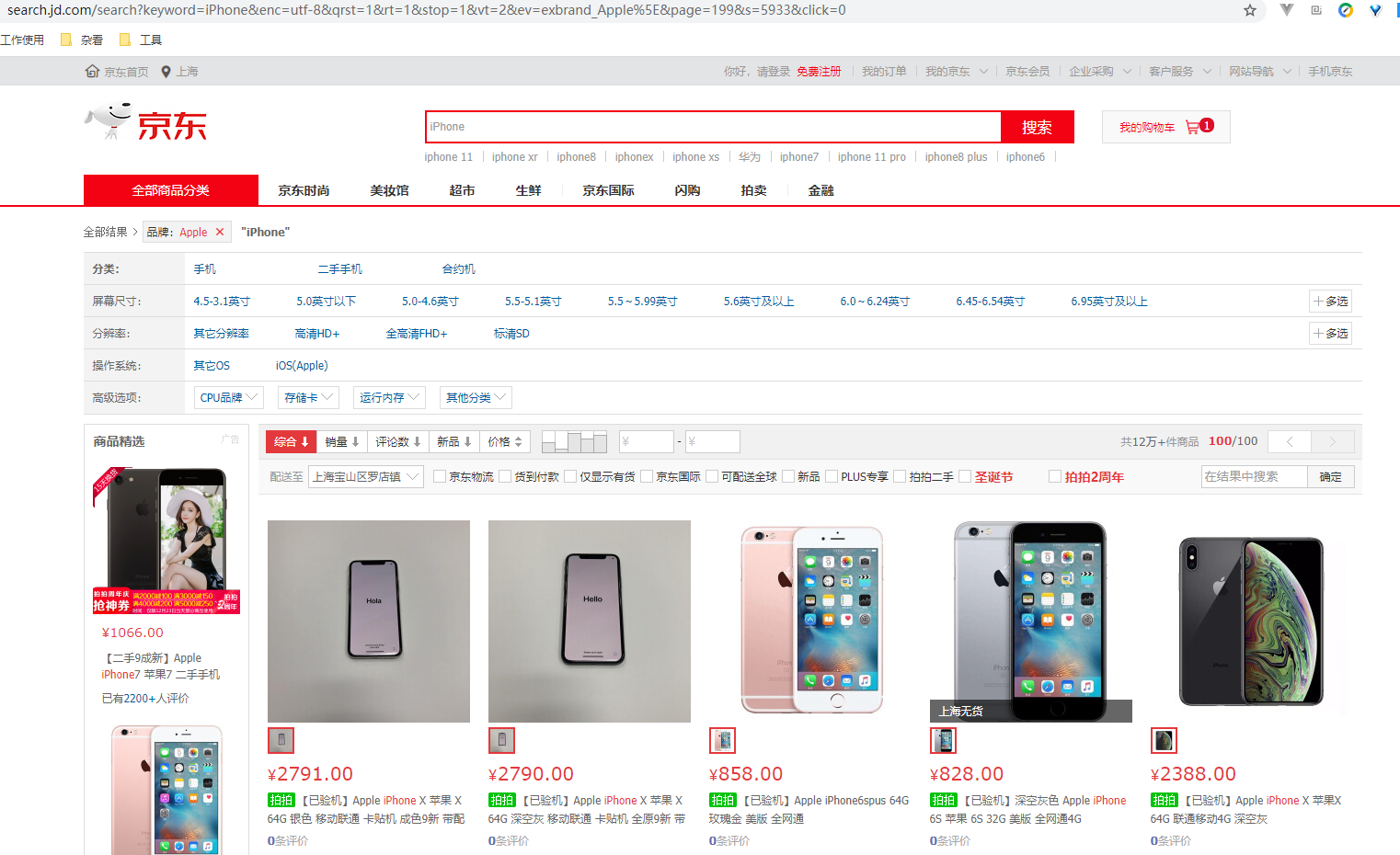
先把位址列的地址 Copy 出來看一下,裡面有很多無效引數:
https://search.jd.com/search?keyword=iPhone&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&ev=exbrand_Apple%5E&page=199&s=5933&click=0如果問小編怎麼知道是無效引數還是有效引數,emmmmmmmmm
這個要麼靠經驗,一般大網站的引數的命名都是比較規範的,當然也不排除命名不規範的。還有一種辦法就是試,小編這邊試出來的結果是這樣滴:
https://search.jd.com/Search?keyword=iPhone&ev=exbrand_Apple第一個引數 keyword 就是我們需要的商品名稱,第二個引數 ev 是品牌的引數。
接下來我們看如何獲取商品的詳細資訊,我們使用 F12 開啟開發者模式,使用看下具體的資訊都放在哪裡:
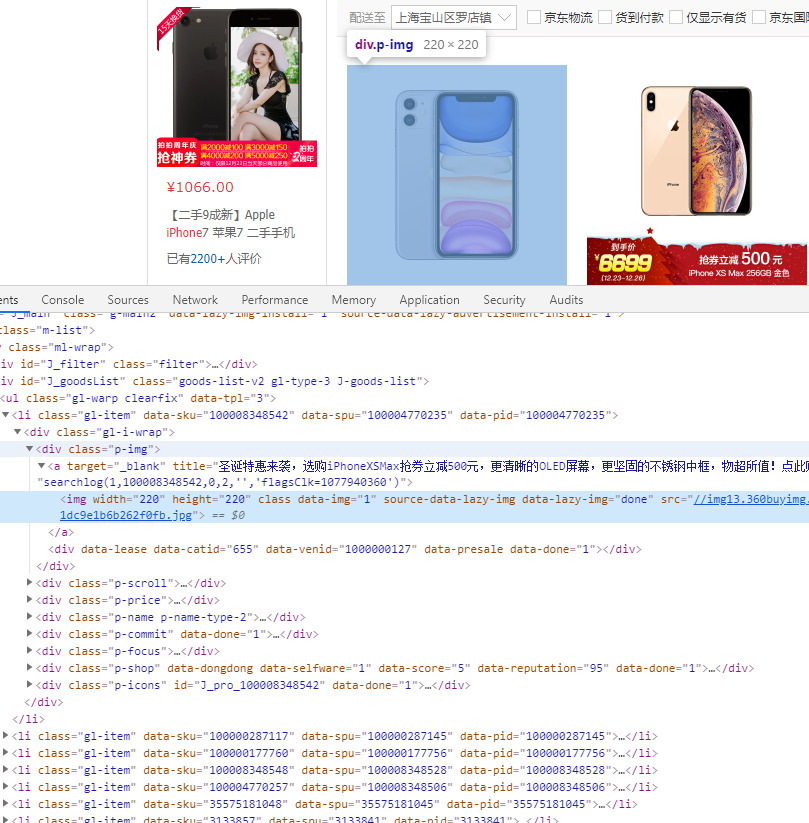
可以看到,我們想要獲取的資訊在這個頁面的 DOM 節點中都能獲取到。
接下來因為我們是使用 Selenium 來模擬瀏覽器訪問電商網站,所以後續的介面分析也就不需要做了,直接獲取瀏覽器顯示的內容的原始碼就可以輕鬆獲取到各種資訊。
獲取商品列表頁面
首先,我們需要構造一個獲取商品列表頁面的 URL ,這個上面已經得到了,接下來就是使用 Selenium 來獲取這個頁面了:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.set_window_size(1280,800)
def index_page(page):
"""
抓取索引頁
:param page: 頁碼
"""
print('正在爬取第', str(page), '頁資料')
try:
url = 'https://search.jd.com/Search?keyword=iPhone&ev=exbrand_Apple'
driver.get(url)
if page > 1:
input = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[2]/input')
button = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[2]/a')
input.clear()
input.send_keys(page)
button.click()
get_products()
except TimeoutException:
index_page(page)這裡我們依然使用隱式等待來進行 URL 訪問,這裡小編通過 xpath 的方式獲取到了整個頁面最下面的翻頁元件:

小編這裡的翻頁實際上是使用這裡的輸入框和後面的確認按鈕進行的。
獲取商品詳細資料
這裡其實有一個坑,JD 的首頁上的圖片是懶載入的,就是當頁面的滾動條沒有滾到這個圖片可以顯示在螢幕上的位置的時候,這個圖片是不會加載出來的。這就造成了小編一開始的只能獲取到前 4 個商品的圖片地址。
小編後來想了個辦法,使用 JavaScript 來模擬滾動條滾動,先將所有的圖片加載出來,然後再進行資料的獲取,程式碼如下:
def get_products():
"""
提取商品資料
"""
js = '''
timer = setInterval(function(){
var scrollTop=document.documentElement.scrollTop||document.body.scrollTop;
var ispeed=Math.floor(document.body.scrollHeight / 100);
if(scrollTop > document.body.scrollHeight * 90 / 100){
clearInterval(timer);
}
console.log('scrollTop:'+scrollTop)
console.log('scrollHeight:'+document.body.scrollHeight)
window.scrollTo(0, scrollTop+ispeed)
}, 20)
'''
driver.execute_script(js)
time.sleep(2.5)
html = driver.page_source
doc = PyQuery(html)
items = doc('#J_goodsList .gl-item .gl-i-wrap').items()
i = 0
for item in items:
insert_data = {
'image': item.find('.p-img a img').attr('src'),
'price': item.find('.p-price i').text(),
'name': item.find('.p-name em').text(),
'commit': item.find('.p-commit a').text(),
'shop': item.find('.p-shop a').text(),
'icons': item.find('.p-icons .goods-icons').text()
}
i += 1
print('當前第', str(i), '條資料,內容為:' , insert_data)中間那段 js 就是模擬滾動條向下滾動的程式碼,這裡小編做了一個定時任務,這個定時任務將整個頁面的長度分成了 100 份,每 20 ms 就向下滾動 1% ,共計應該總共 2s 可以滾到最下面,這裡下面做了 2.5s 的睡眠,保證這個頁面的圖片都能加載出來,最後再獲取頁面上的資料。
主體程式碼到這裡就結束了,剩下的程式碼無非就是將資料儲存起來,不管是儲存在資料中還是儲存在 Excel 中,或者是 CSV 中,又或者是純粹的文字檔案 txt 或者是 json ,都不難,小編這次就不寫了,希望大家能自己完善下這個程式碼。
執行的時候,可以看到一個瀏覽器彈出來,然後滾動條自動以比較順滑的速度滾到最下方(小編為了這個順滑的速度調了很久),確保所有圖片都加載出來,再使用 pyquery 獲取相關的資料,最後組成了一個 json 物件,給大家看下抓取下來的結果吧:

Chrome 無介面模式
我們在爬取資料的時候,彈出來一個瀏覽器總感覺有點老不爽了,可以使用如下命令將這個瀏覽器隱藏起來,不過需要的是 Chrome 比較新的版本。
# 開啟無視窗模式
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options)首先,建立 ChromeOptions 物件,接著新增 headless 引數,然後在初始化 Chrome 物件的時候通過 chrome_options 傳遞這個 ChromeOptions 物件,這樣我們就可以成功啟用 Chrome 的Headless模式了。
FireFox
如果我們不想使用 Chrome 瀏覽器,還可以使用 FireFox 瀏覽器,前提是需要安裝好 FireFox 和對應的驅動 GeckoDriver ,並且完成相關配置,不清楚如何安裝的同學可以翻一翻前面的前置準備。
我們需要切換 FireFox 瀏覽器的時候,異常的簡單,只需要修改一句話就可以了:
driver = webdriver.Firefox()這裡我們修改了 webdriver 初始化的方式,這樣在接下來的操作中就會自動使用 FireFox 瀏覽器了。
如果 Firefox 也想開啟無介面模式的話,同樣也是可以的,和上面 Chrome 開啟無介面模式大同小異:
# FireFox 開啟無視窗模式
firefox_options = webdriver.FirefoxOptions()
firefox_options.add_argument('--headless')
driver = webdriver.Firefox(firefox_options=firefox_options)一樣是在 Webdriver 初始化的時候增加 headless 引數就可以了。
好了,本篇的內容就到這裡了,希望各位同學可以自己動手練習下哦~~~
注意: 本文相關內容僅做學習使用,使用時請遵守國家相關法律規定。
示例程式碼
本系列的所有程式碼小編都會放在程式碼管理倉庫 Github 和 Gitee 上,方便大家取用。
示例程式碼-Github
示例程式碼-Gi