
支撐百萬級併發,Netty如何實現高效能記憶體管理

Netty作為一款高效能網路應用程式框架,實現了一套高效能記憶體管理機制
通過學習其中的實現原理、演算法、併發設計,有利於我們寫出更優雅、更高效能的程式碼;當使用Netty時碰到記憶體方面的問題時,也可以更高效定位排查出來
本文基於Netty4.1.43.Final介紹其中的記憶體管理機制
ByteBuf分類
Netty使用ByteBuf物件作為資料容器,進行I/O讀寫操作,Netty的記憶體管理也是圍繞著ByteBuf物件高效地分配和釋放
當討論ByteBuf物件管理,主要從以下方面進行分類:
- Pooled 和 Unpooled
Unpooled,非池化記憶體每次分配時直接呼叫系統 API 向作業系統申請ByteBuf需要的同樣大小記憶體,用完後通過系統呼叫進行釋放
Pooled,池化記憶體分配時基於預分配的一整塊大記憶體,取其中的部分封裝成ByteBuf提供使用,用完後回收到記憶體池中
tips: Netty4預設使用Pooled的方式,可通過引數-Dio.netty.allocator.type=unpooled或pooled進行設定
- Heap 和 Direct
Heap,指ByteBuf關聯的記憶體JVM堆內分配,分配的記憶體受GC 管理
Direct,指ByteBuf關聯的記憶體在JVM堆外分配,分配的記憶體不受GC管理,需要通過系統呼叫實現申請和釋放,底層基於Java NIO的DirectByteBuffer物件
note: 使用堆外記憶體的優勢在於,Java進行I/O操作時,需要傳入資料所在緩衝區起始地址和長度,由於GC的存在,物件在堆中的位置往往會發生移動,導致物件地址變化,系統調用出錯。為避免這種情況,當基於堆記憶體進行I/O系統呼叫時,需要將記憶體拷貝到堆外,而直接基於堆外記憶體進行I/O操作的話,可以節省該拷貝成本
池化(Pooled)物件管理
非池化物件(Unpooled),使用和釋放物件僅需要呼叫底層介面實現,池化物件實現則複雜得多,可以帶著以下問題進行研究:
- 記憶體池管理演算法是如何實現高效記憶體分配釋放,減少記憶體碎片
- 高負載下記憶體池不斷申請/釋放,如何實現彈性伸縮
- 記憶體池作為全域性資料,在多執行緒環境下如何減少鎖競爭
1 演算法設計
1.1 整體原理
Netty先向系統申請一整塊連續記憶體,稱為chunk,預設大小chunkSize = 16Mb,通過PoolChunk物件包裝。為了更細粒度的管理,Netty將chunk進一步拆分為page,預設每個chunk包含2048個page(pageSize = 8Kb)
不同大小池化記憶體物件的分配策略不同,下面首先介紹申請記憶體大小在(pageSize/2, chunkSize]區間範圍內的池化物件的分配原理,其他大物件和小物件的分配原理後面再介紹。在同一個chunk中,Netty將page按照不同粒度進行多層分組管理:

- 第1層,分組大小size = 1*pageSize,一共有2048個組
- 第2層,分組大小size = 2*pageSize,一共有1024個組
- 第3層,分組大小size = 4*pageSize,一共有512個組
...
當請求分配記憶體時,將請求分配的記憶體數向上取值到最接近的分組大小,在該分組大小的相應層級中從左至右尋找空閒分組
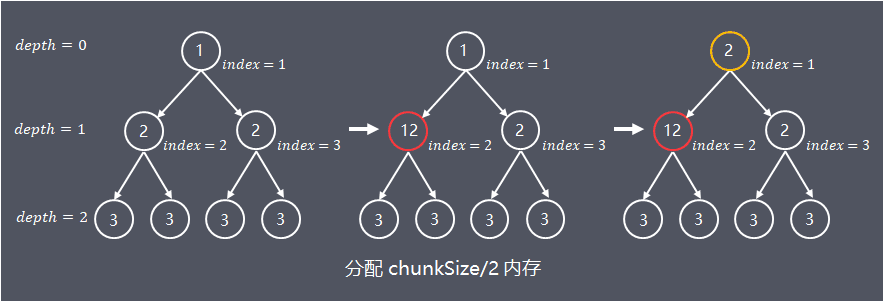
例如請求分配記憶體物件為1.5 pageSize,向上取值到分組大小2 pageSize,在該層分組中找到完全空閒的一組記憶體進行分配,如下圖:

當分組大小2 * pageSize的記憶體分配出去後,為了方便下次記憶體分配,分組被標記為全部已使用(圖中紅色標記),向上更粗粒度的記憶體分組被標記為部分已使用(圖中黃色標記)
1.2 演算法結構
Netty基於平衡樹實現上面提到的不同粒度的多層分組管理
當需要建立一個給定大小的ByteBuf,演算法需要在PoolChunk中大小為chunkSize的記憶體中,找到第一個能夠容納申請分配記憶體的位置
為了方便快速查詢chunk中能容納請求記憶體的位置,演算法構建一個基於byte陣列(memoryMap)儲存的完全平衡樹,該平衡樹的多個層級深度,就是前面介紹的按照不同粒度對chunk進行多層分組:
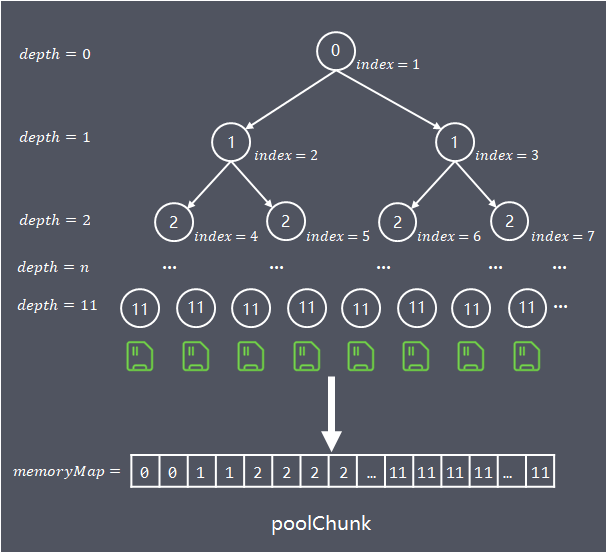
樹的深度depth從0開始計算,各層節點數,每個節點對應的記憶體大小如下:
depth = 0, 1 node,nodeSize = chunkSize
depth = 1, 2 nodes,nodeSize = chunkSize/2
...
depth = d, 2^d nodes, nodeSize = chunkSize/(2^d)
...
depth = maxOrder, 2^maxOrder nodes, nodeSize = chunkSize/2^{maxOrder} = pageSize樹的最大深度為maxOrder(最大階,預設值11),通過這棵樹,演算法在chunk中的查詢就可以轉換為:
當申請分配大小為chunkSize/2^k的記憶體,在平衡樹高度為k的層級中,從左到右搜尋第一個空閒節點
陣列的使用域從index = 1開始,將平衡樹按照層次順序依次儲存在陣列中,depth = n的第1個節點儲存在memoryMap[2^n] 中,第2個節點儲存在memoryMap[2^n+1]中,以此類推。
可以根據memoryMap[id]的值得出節點的使用情況,memoryMap[id]值越大,剩餘的可用記憶體越少
- memoryMap[id] = depth_of_id:id節點空閒, 初始狀態,depth_of_id的值代表id節點在樹中的深度
- memoryMap[id] = maxOrder + 1:id節點全部已使用,節點記憶體已完全分配,沒有一個子節點空閒
- depth_of_id < memoryMap[id] < maxOrder + 1:id節點部分已使用,memoryMap[id] 的值 x,代表id的子節點中,第一個空閒節點位於深度x,在深度[depth_of_id, x)的範圍內沒有任何空閒節點
1.3 申請/釋放記憶體
當申請分配記憶體,會首先將請求分配的記憶體大小歸一化(向上取值),通過PoolArena#normalizeCapacity()方法,取最近的2的冪的值,例如8000byte歸一化為8192byte( chunkSize/2^11 ),8193byte歸一化為16384byte(chunkSize/2^10)
處理記憶體申請的演算法在PoolChunk#allocateRun方法中,當分配已歸一化處理後大小為chunkSize/2^d的記憶體,即需要在depth = d的層級中找到第一塊空閒記憶體,演算法從根節點開始遍歷 (根節點depth = 0, id = 1),具體步驟如下:
步驟1 判斷是否當前節點值memoryMap[id] > d
如果是,則無法從該chunk分配記憶體,查詢結束步驟2 判斷是否節點值memoryMap[id] == d,且depth_of_id == h
如果是,當前節點是depth = d的空閒記憶體,查詢結束,更新當前節點值為memoryMap[id] = max_order + 1,代表節點已使用,並遍歷當前節點的所有祖先節點,更新節點值為各自的左右子節點值的最小值;如果否,執行步驟3步驟3 判斷是否當前節點值memoryMap[id] <= d,且depth_of_id < h
如果是,則空閒節點在當前節點的子節點中,則先判斷左子節點memoryMap[2 * id] <=d(判斷左子節點是否可分配),如果成立,則當前節點更新為左子節點,否則更新為右子節點,然後重複步驟2
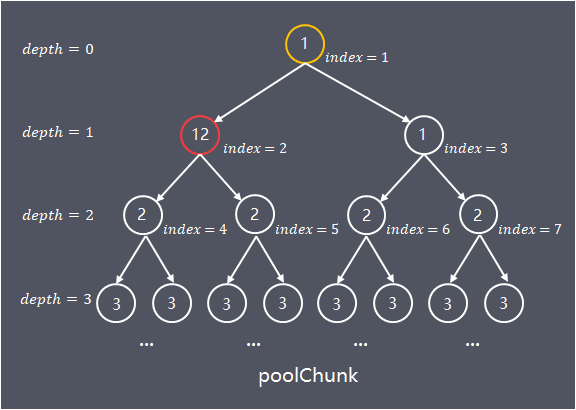
參考示例如下圖,申請分配了chunkSize/2的記憶體
note:圖中雖然index = 2的子節點memoryMap[id] = depth_of_id,但實際上節點記憶體已分配,因為演算法是從上往下開始遍歷,所以在實際處理中,節點分配記憶體後僅更新祖先節點的值,並沒有更新子節點的值
釋放記憶體時,根據申請記憶體返回的id,將 memoryMap[id]更新為depth_of_id,同時設定id節點的祖先節點值為各自左右節點的最小值
1.4 巨型物件記憶體管理
對於申請分配大小超過chunkSize的巨型物件(huge),Netty採用的是非池化管理策略,在每次請求分配記憶體時單獨建立特殊的非池化PoolChunk物件進行管理,內部memoryMap為null,當物件記憶體釋放時整個Chunk記憶體釋放,相應記憶體申請邏輯在PoolArena#allocateHuge()方法中,釋放邏輯在PoolArena#destroyChunk()方法中
1.5 小物件記憶體管理
當請求物件的大小reqCapacity <= 496,歸一化計算後方式是向上取最近的16的倍數,例如15規整為15、40規整為48、490規整為496,規整後的大小(normalizedCapacity)小於pageSize的小物件可分為2類:
微型物件(tiny):規整後為16的整倍數,如16、32、48、...、496,一共31種規格
小型物件(small):規整後為2的冪的,有512、1024、2048、4096,一共4種規格
這些小物件直接分配一個page會造成浪費,在page中進行平衡樹的標記又額外消耗更多空間,因此Netty的實現是:先PoolChunk中申請空閒page,同一個page分為相同大小規格的小記憶體進行儲存

這些page用PoolSubpage物件進行封裝,PoolSubpage內部有記錄記憶體規格大小(elemSize)、可用記憶體數量(numAvail)和各個小記憶體的使用情況,通過long[]型別的bitmap相應bit值0或1,來記錄記憶體是否已使用
note:應該有讀者注意到,Netty申請池化記憶體進行歸一化處理後的值更大了,例如1025byte會歸一化為2048byte,8193byte歸一化為16384byte,這樣是不是造成了一些浪費?可以理解為是一種取捨,通過歸一化處理,使池化記憶體分配大小規格化,大大方便記憶體申請和記憶體、記憶體複用,提高效率
2 彈性伸縮
前面的演算法原理部分介紹了Netty如何實現記憶體塊的申請和釋放,單個chunk比較容量有限,如何管理多個chunk,構建成能夠彈性伸縮記憶體池?
2.1 PoolChunk管理
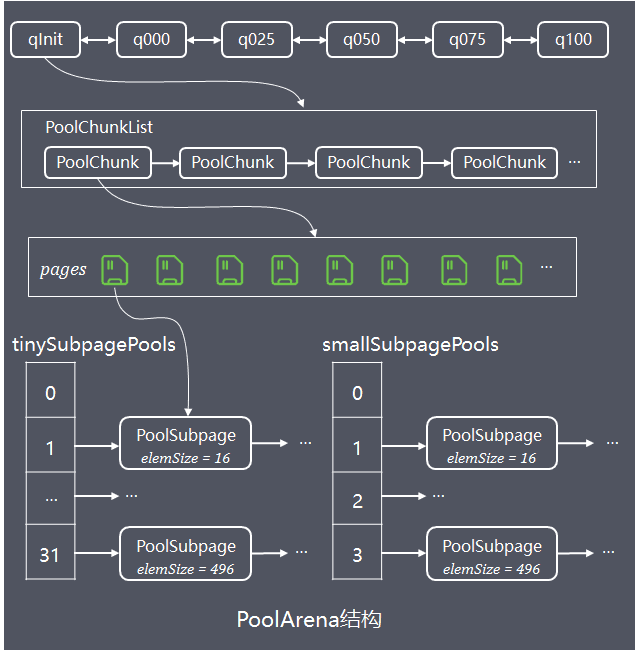
為了解決單個PoolChunk容量有限的問題,Netty將多個PoolChunk組成連結串列一起管理,然後用PoolChunkList物件持有連結串列的head
將所有PoolChunk組成一個連結串列的話,進行遍歷查詢管理效率較低,因此Netty設計了PoolArena物件(arena中文是舞臺、場所),實現對多個PoolChunkList、PoolSubpage的管理,執行緒安全控制、對外提供記憶體分配、釋放的服務
PoolArena內部持有6個PoolChunkList,各個PoolChunkList持有的PoolChunk的使用率區間不同:
// 容納使用率 (0,25%) 的PoolChunk
private final PoolChunkList<T> qInit;
// [1%,50%)
private final PoolChunkList<T> q000;
// [25%, 75%)
private final PoolChunkList<T> q025;
// [50%, 100%)
private final PoolChunkList<T> q050;
// [75%, 100%)
private final PoolChunkList<T> q075;
// 100%
private final PoolChunkList<T> q100;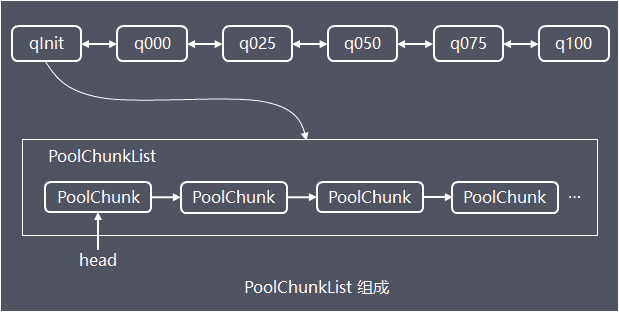
6個PoolChunkList物件組成雙向連結串列,當PoolChunk記憶體分配、釋放,導致使用率變化,需要判斷PoolChunk是否超過所在PoolChunkList的限定使用率範圍,如果超出了,需要沿著6個PoolChunkList的雙向連結串列找到新的合適PoolChunkList,成為新的head;同樣的,當新建PoolChunk並分配完記憶體,該PoolChunk也需要按照上面邏輯放入合適的PoolChunkList中
分配歸一化記憶體normCapacity(大小範圍在[pageSize, chunkSize]) 具體處理如下:
- 按順序依次訪問q050、q025、q000、qInit、q075,遍歷PoolChunkList內PoolChunk連結串列判斷是否有PoolChunk能分配記憶體
- 如果上面5個PoolChunkList有任意一個PoolChunk記憶體分配成功,PoolChunk使用率發生變更,重新檢查並放入合適的PoolChunkList中,結束
- 否則新建一個PoolChunk,分配記憶體,放入合適的PoolChunkList中(PoolChunkList擴容)
note:可以看到分配記憶體依次優先在q050 -> q025 -> q000 -> qInit -> q075的PoolChunkList的內分配,這樣做的好處是,使分配後各個區間記憶體使用率更多處於[75,100)的區間範圍內,提高PoolChunk記憶體使用率的同時也兼顧效率,減少在PoolChunkList中PoolChunk的遍歷
當PoolChunk記憶體釋放,同樣PoolChunk使用率發生變更,重新檢查並放入合適的PoolChunkList中,如果釋放後PoolChunk記憶體使用率為0,則從PoolChunkList中移除,釋放掉這部分空間,避免在高峰的時候申請過記憶體一直快取在池中(PoolChunkList縮容)

PoolChunkList的額定使用率區間存在交叉,這樣設計是因為如果基於一個臨界值的話,當PoolChunk記憶體申請釋放後的記憶體使用率在臨界值上下徘徊的話,會導致在PoolChunkList連結串列前後來回移動
2.2 PoolSubpage管理
PoolArena內部持有2個PoolSubpage陣列,分別儲存tiny和small規格型別的PoolSubpage:
// 陣列長度32,實際使用域從index = 1開始,對應31種tiny規格PoolSubpage
private final PoolSubpage<T>[] tinySubpagePools;
// 陣列長度4,對應4種small規格PoolSubpage
private final PoolSubpage<T>[] smallSubpagePools;相同規格大小(elemSize)的PoolSubpage組成連結串列,不同規格的PoolSubpage連結串列的head則分別儲存在tinySubpagePools 或者 smallSubpagePools陣列中,如下圖:

當需要分配小記憶體物件到PoolSubpage中時,根據歸一化後的大小,計算出需要訪問的PoolSubpage連結串列在tinySubpagePools和smallSubpagePools陣列的下標,訪問連結串列中的PoolSubpage的申請記憶體分配,如果訪問到的PoolSubpage連結串列節點數為0,則建立新的PoolSubpage分配記憶體然後加入連結串列
PoolSubpage連結串列儲存的PoolSubpage都是已分配部分記憶體,當記憶體全部分配完或者記憶體全部釋放完的PoolSubpage會移出連結串列,減少不必要的連結串列節點;當PoolSubpage記憶體全部分配完後再釋放部分記憶體,會重新將加入連結串列
PoolArean記憶體池彈性伸縮可用下圖總結:
3 併發設計
記憶體分配釋放不可避免地會遇到多執行緒併發場景,無論是PoolChunk的平衡樹標記或者PoolSubpage的bitmap標記都是多執行緒不安全,如何線上程安全的前提下儘量提升併發效能?
首先,為了減少執行緒間的競爭,Netty會提前建立多個PoolArena(預設生成數量 = 2 * CPU核心數),當執行緒首次請求池化記憶體分配,會找被最少執行緒持有的PoolArena,並儲存執行緒區域性變數PoolThreadCache中,實現執行緒與PoolArena的關聯繫結(PoolThreadLocalCache#initialValue()方法)
note:Java自帶的ThreadLocal實現執行緒區域性變數的原理是:基於Thread的ThreadLocalMap型別成員變數,該變數中map的key為ThreadLocal,value-為需要自定義的執行緒區域性變數值。呼叫ThreadLocal#get()方法時,會通過Thread.currentThread()獲取當前執行緒訪問Thread的ThreadLocalMap中的值
Netty設計了ThreadLocal的更高效能替代類:FastThreadLocal,需要配套繼承Thread的類FastThreadLocalThread一起使用,基本原理是將原來Thead的基於ThreadLocalMap儲存區域性變數,擴充套件為能更快速訪問的陣列進行儲存(Object[] indexedVariables),每個FastThreadLocal內部維護了一個全域性原子自增的int型別的陣列index
此外,Netty還設計了快取機制提升併發效能:當請求物件記憶體釋放,PoolArena並沒有馬上釋放,而是先嚐試將該記憶體關聯的PoolChunk和chunk中的偏移位置(handler變數)等資訊存入PoolThreadLocalCache中的固定大小快取佇列中(如果快取佇列滿了則馬上釋放記憶體);
當請求記憶體分配,PoolArena會優先訪問PoolThreadLocalCache的快取佇列中是否有快取記憶體可用,如果有,則直接分配,提高分配效率
總結
Netty池化記憶體管理的設計借鑑了Facebook的jemalloc,同時也與Linux記憶體分配演算法Buddy演算法和Slab演算法也有相似之處,很多分散式系統、框架的設計都可以在作業系統的設計中找到原型,學習底層原理是很有價值的
下一篇,介紹Netty堆外記憶體洩漏問題的排查
參考
《scalable memory allocation using jemalloc —— Facebook》
https://engineering.fb.com/core-data/scalable-memory-allocation-using-jemalloc/
《Netty入門與實戰:仿寫微信 IM 即時通訊系統》
https://juejin.im/book/5b4bc28bf265da0f60130116?referrer=598ff735f265da3e1c0f9643
更多精彩,歡迎關注公眾號 分散式系統架構
