
Mysql的SQL優化指北
概述
在一次和技術大佬的聊天中被問到,平時我是怎麼做Mysql的優化的?在這個問題上我只回答出了幾點,感覺回答的不夠完美,所以我打算整理一次SQL的優化問題。
要知道怎麼優化首先要知道一條SQL是怎麼被執行的

- 首先我們會連線到這個資料庫上,這時候接待你的就是聯結器。聯結器負責跟客戶端建立連線、獲取許可權、維持和管理連線。
- MySQL拿到一個查詢請求後,會先到查詢快取看看,之前是不是執行過這條語句。
- 然後分析器先會做“詞法分析”,MySQL需要識別出裡面的字串分別是什麼,代表什麼。接著要做“語法分析”,根據詞法分析的結果,語法分析器會根據語法規則,判斷你輸入的這個SQL語句是否滿足MySQL語法。
- 然後執行優化器,優化器是在表裡面有多個索引的時候,決定使用哪個索引;或者在一個語句有多表關聯(join)的時候,決定各個表的連線順序。
- MySQL通過分析器知道了你要做什麼,通過優化器知道了該怎麼做,於是就進入了執行器階段,開始執行語句。開始執行的時候,要先判斷一下你對這個表T有沒有執行查詢的許可權,如果沒有,就會返回沒有許可權的錯誤。
所以SQL優化工作都是優化器的功勞,而我們要做的就是寫出符合能被優化器優化的SQL。
我們在這裡假設有一張表person_info,裡面有個聯合索引idx_name_birthday_phone_number(name, birthday, phone_number)作為一個例子。
由於聯合索引在B+樹中是按照索引的先後順序進行排序的,所以在索引idx_name_birthday_phone_number中,先按照name列的值進行排序,如果name列的值相同,則按照birthday列的值進行排序,如果birthday列的值也相同,則按照phone_number 的值進行排序。
優化點
不要建立太多索引
我們雖然可以根據我們的喜好在不同的列上建立索引,但是建立索引是有代價的:
空間上的代價
每建立一個索引都要為它建立一棵B+樹,每一棵B+樹的每一個節點都是一個數據頁,一個頁預設會佔用16KB的儲存空間,一棵很大的B+樹由許多資料頁組成,可想而知會佔多少儲存空間了時間上的代價
每次對錶中的資料進行增、刪、改操作時,都需要去修改各個B+樹索引。在B+ 樹上每層節點都是按照索引列的值從小到大的順序排序而組成了雙向連結串列。不論是葉子節點中的記錄,還是內節點中的記錄(也就是不論是使用者記錄還是目錄項記錄)都是按照索引列的值從小到大的順序而形成了一個單向連結串列。而增、刪、改操作可能會對節點和記錄的排序造成破壞,所以儲存引擎需要額外的時間進行一些記錄移位,頁面分裂、頁面回收啥的操作來維護好節點和記錄的排序。
聯合索引使用問題
B+樹中每層節點都是按照索引列的值從小到大的順序而形成了一個單鏈表。如果是聯合索引的話,則頁面和記錄先按照聯合索引前邊的列排序,如果該列值相同,再按照聯合索引後邊的列排序。
匹配左邊的列
因為B+樹的資料頁和記錄先是按照name列的值排序的,在name列的值相同的情況下才使用birthday列進行排序,也就是說name列的值不同的記錄中birthday的值可能是無序的。
如果用的不是最左列的話就無法使用到索引,例如:
SELECT * FROM person_info WHERE birthday = '1990-09-27';如果我們使用的是:
SELECT * FROM person_info WHERE name = 'Ashburn' AND phone_number = '15123983239';這樣只能用到name列的索引,birthday和phone_number的索引就用不上了,因為name值相同的記錄先按照birthday的值進行排序,birthday值相同的記錄才按照phone_number值進行排序。
匹配範圍值
在使用聯合索引進行範圍查詢時候,如果對多個列同時進行範圍查詢的話,只有對索引最左邊的那個列進行範圍查詢的時候才能用到B+樹索引。
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01';對於聯合索引idx_name_birthday_phone_number來說,可以用name快速定位到通過條件name > 'Asa' AND name < 'Barlow’,但是卻無法通過birthday > '1980-01-01'條件繼續過濾,因為通過name進行範圍查詢的記錄中可能並不是按照birthday列進行排序的。
精確匹配某一列並範圍匹配另外一列
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000';在這條SQL中,由於對name是精確查詢,所以在name相同的情況下birthday是排好序的,birthday列進行範圍查詢是可以用到B+樹索引的。但是對於phone_number來說,通過birthday的範圍查詢的記錄的birthday的值可能不同,所以這個條件無法再利用B+樹索引了。
排序
對於聯合索引來說,ORDER BY的子句後邊的列的順序也必須按照索引列的順序給出,如果給出ORDER BY phone_number, birthday, name的順序,那也是用不了B+樹索引。
- ASC、DESC混用是不能使用到索引的
對於使用聯合索引進行排序的場景,我們要求各個排序列的排序順序是一致的,也就是要麼各個列都是ASC規則排序,要麼都是DESC規則排序。 - WHERE子句中出現非排序使用到的索引列無法使用到索引
如:
SELECT * FROM person_info WHERE country = 'China' ORDER BY name LIMIT 10;這個語句需要回表後查出整行記錄進行過濾後才能進行排序,無法使用索引進行排序
- 排序列包含非同一個索引的列無法使用索引
比方說:
SELECT * FROM person_info ORDER BY name, country LIMIT 10;- Order by 中使用了函式也無法使用索引
匹配列字首
和聯合索引其實有點類似,如果一個欄位比如是varchar型別的name欄位,那麼在索引中name欄位的排列就會:
- 先比較字串的第一個字元,第一個字元小的那個字串就比較小
- 如果兩個字串的第一個字元相同,那就再比較第二個字元,第二個字元比較小的那個字串就比較小
- 如果兩個字串的第二個字元也相同,那就接著比較第三個字元,依此類推
所以這樣是可以用到索引:
SELECT * FROM person_info WHERE name LIKE 'As%';但是這樣就用不到:
SELECT * FROM person_info WHERE name LIKE '%As%';覆蓋索引
如果我們查詢的所有列都可以在索引中找到,那麼就可以就不需要回表去查詢對應的列了。
例如:
SELECT name, birthday, phone_number FROM person_info WHERE name > 'Asa' AND name < 'Barlow'因為我們只查詢name, birthday, phone_number這三個索引列的值,所以在通過idx_name_birthday_phone_number索引得到結果後就不必到聚簇索引中再查詢記錄的剩餘列,也就是country列的值了,這樣就省去了回表操作帶來的效能損耗
讓索引列在比較表示式中單獨出現
假設表中有一個整數列my_col,我們為這個列建立了索引。下邊的兩個WHERE子句雖然語義是一致的,但是在效率上卻有差別:
- WHERE my_col * 2 < 4
- WHERE my_col < 4/2
第1個WHERE子句中my_col列並不是以單獨列的形式出現的,而是以my_col * 2這樣的表示式的形式出現的,儲存引擎會依次遍歷所有的記錄,計算這個表示式的值是不是小於4,所以這種情況下是使用不到為my_col列建立的B+樹索引的。而第2個WHERE子句中my_col列並是以單獨列的形式出現的,這樣的情況可以直接使用B+樹索引。
頁分裂帶來的效能損耗
我們假設一個頁中只能儲存5條資料:

如果這時候我插入一條id為4的資料,那麼我們就要在分配一個新頁。由於5>4,索引是有序的,所以需要將id=5這條資料移動到下一頁中,並插入一條id=4新的資料到頁10中:

這個過程我們也可以稱為頁分裂。頁面分裂和記錄移位意味著效能損耗所以如果我們想盡量避免這樣無謂的效能損耗,最好讓插入的記錄的主鍵值依次遞增,這樣就不會發生這樣的效能損耗了。所以我們建議:讓主鍵具有AUTO_INCREMENT,讓儲存引擎自己為表生成主鍵。
減少對行鎖的時間
兩階段鎖協議:
在InnoDB事務中,行鎖是在需要的時候才加上的,但並不是不需要了就立刻釋放,而是要等到事務結束時才釋放。
所以,如果你的事務中需要鎖多個行,要把最可能造成鎖衝突、最可能影響併發度的鎖儘量往後放。
假設你負責實現一個電影票線上交易業務,顧客A要在影院B購買電影票。我們簡化一點,這個業務需要涉及到以下操作:
- 從顧客A賬戶餘額中扣除電影票價;
- 給影院B的賬戶餘額增加這張電影票價;
- 記錄一條交易日誌。
也就是說,要完成這個交易,我們需要update兩條記錄,並insert一條記錄。當然,為了保證交易的原子性,我們要把這三個操作放在一個事務中。
試想如果同時有另外一個顧客C要在影院B買票,那麼這兩個事務衝突的部分就是語句2了。因為它們要更新同一個影院賬戶的餘額,需要修改同一行資料。
根據兩階段鎖協議,不論你怎樣安排語句順序,所有的操作需要的行鎖都是在事務提交的時候才釋放的。所以,如果你把語句2安排在最後,比如按照3、1、2這樣的順序,那麼影院賬戶餘額這一行的鎖時間就最少。這就最大程度地減少了事務之間的鎖等待,提升了併發度。
count 函式優化
我們主要來看看count(*)、count(主鍵id)、count(欄位)和count(1)這三者的效能差別。
對於count(主鍵id)來說,InnoDB引擎會遍歷整張表,把每一行的id值都取出來,返回給server層。server層拿到id後,判斷是不可能為空的,就按行累加。
對於count(1)來說,InnoDB引擎遍歷整張表,但不取值。server層對於返回的每一行,放一個數字“1”進去,判斷是不可能為空的,按行累加。
單看這兩個用法的差別的話,你能對比出來,count(1)執行得要比count(主鍵id)快。因為從引擎返回id會涉及到解析資料行,以及拷貝欄位值的操作。
對於count(欄位)來說:
- 如果這個“欄位”是定義為not null的話,一行行地從記錄裡面讀出這個欄位,判斷不能為null,按行累加;
- 如果這個“欄位”定義允許為null,那麼執行的時候,判斷到有可能是null,還要把值取出來再判斷一下,不是null才累加。
也就是前面的第一條原則,server層要什麼欄位,InnoDB就返回什麼欄位。
但是count()是例外,並不會把全部欄位取出來,而是專門做了優化,不取值。count()肯定不是null,按行累加。
所以結論是:按照效率排序的話,count(欄位)<count(主鍵id)<count(1)≈count(),所以我建議你,儘量使用count()。
order by效能優化
在MySQL排序中會用到記憶體來進行排序,sort_buffer_size,就是MySQL為排序開闢的記憶體(sort_buffer)的大小。如果要排序的資料量小於sort_buffer_size,排序就在記憶體中完成。但如果排序資料量太大,記憶體放不下,則不得不利用磁碟臨時檔案輔助排序。
如果查詢要返回的欄位很多的話,那麼sort_buffer裡面要放的欄位數太多,這樣記憶體裡能夠同時放下的行數很少,要分成很多個臨時檔案,排序的效能會很差。MySQL就會根據max_length_for_sort_data引數來限定排序的行資料的長度,如果單行的長度超過這個值,MySQL就認為單行太大,要根據rowid排序。
rowid排序只會在sort_buffer放入要排序的欄位,減少要排序的資料的大小,但是rowid排序會多訪問一次主鍵索引,多一次回表以便拿到需要返回的資料。
所以我們在寫排序SQL的時候,需要儘量做到以下三點:
- 返回的資料列數儘量的少,不要返回不必要的資料列
- 因為索引天然是有序的,所以如果要排序的列如果有必要的話,可以設定成索引,那麼就不需要在sort_buffer中排序就可以直接返回了
- 如果有必要的話可以使用覆蓋索引,這樣在返回資料的時候連通過主鍵回表都不需要做就可以直接查詢得到資料
隱式型別轉換
例如:
mysql> select * from tradelog where tradeid=110717;在這條sql中,交易編號tradeid這個欄位上,本來就有索引,但是explain的結果卻顯示,這條語句需要走全表掃描。你可能也發現了,tradeid的欄位型別是varchar(32),而輸入的引數卻是整型,所以需要做型別轉換。
因為在MySQL中,字串和數字做比較的話,是將字串轉換成數字。所以上面的SQL相當於:
mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;所以這條包含了隱式型別轉換的SQL是無法走樹搜尋功能的。
隱式字元編碼轉換
例如:
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2; /*語句Q1*/在這條SQL中,如果tradelog表的字符集編碼是utf8mb4,trade_detail表的字符集編碼是utf8,那麼也是無法走索引的。
因為在這個SQL中,我們跑執行計劃可以發現tradelog是驅動表,trade_detail是被驅動表,也就是從tradelog表中取tradeid欄位,再去trade_detail表裡查詢匹配欄位。
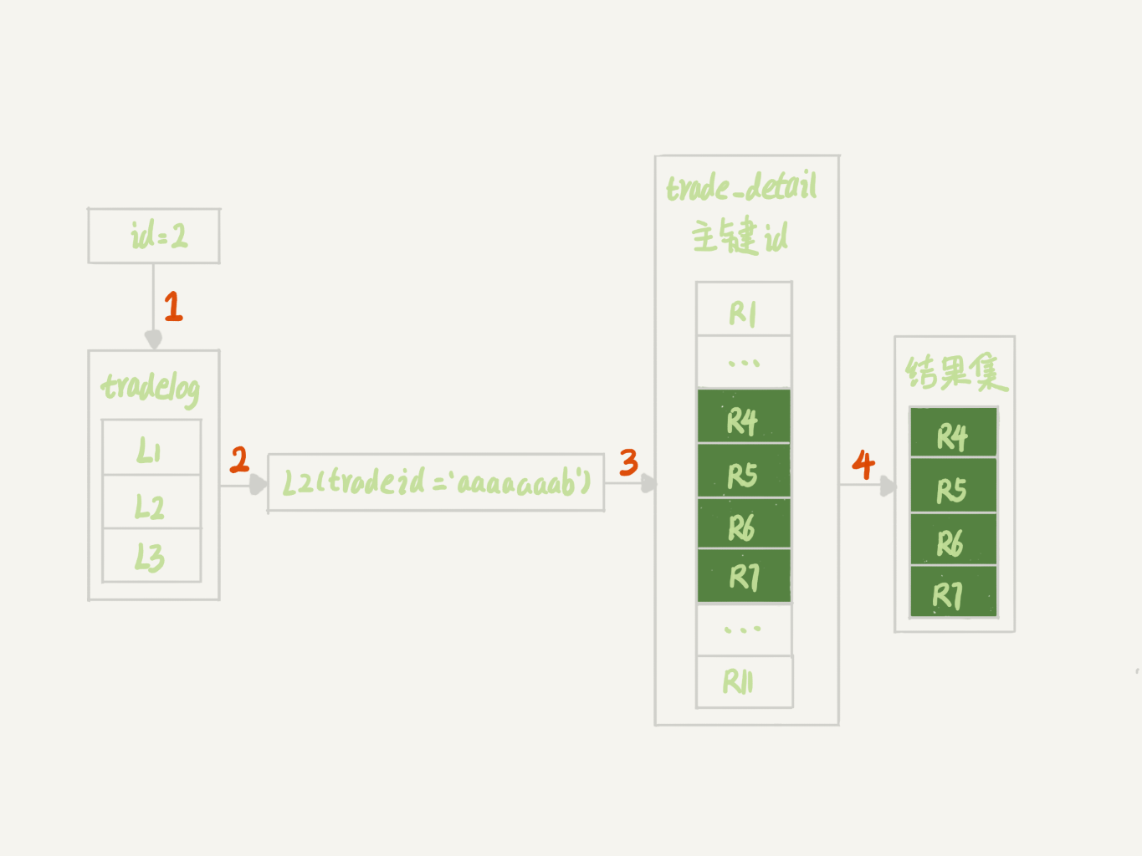
字符集utf8mb4是utf8的超集,所以當這兩個型別的字串在做比較的時候,MySQL內部的操作是,先把utf8字串轉成utf8mb4字符集,再做比較。
因此, 在執行上面這個語句的時候,需要將被驅動資料表裡的欄位一個個地轉換成utf8mb4。所以是無法走索引的。
所以我們可以如下優化:
- 把trade_detail表上的tradeid欄位的字符集也改成utf8mb4
alter table trade_detail modify tradeid varchar(32) CHARACTER SET utf8mb4 default null;- 修改SQL語句
mysql> select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2; Join優化
- 在關聯欄位上使用索引
如:
我這裡有兩個表,t1和t2,表結果一模一樣,欄位a是索引欄位
select * from t1 straight_join t2 on (t1.a=t2.a);這樣關聯的資料執行邏輯就是:
1. 從表t1中讀入一行資料 R;
2. 從資料行R中,取出a欄位到表t2裡去查詢;
3. 取出表t2中滿足條件的行,跟R組成一行,作為結果集的一部分;
4. 重複執行步驟1到3,直到表t1的末尾迴圈結束。
這個SQL由於使用了索引,所以在將t1表資料取出來後根據t1表的a欄位實際上是對t2表的一個索引的等值查詢,所以t1和t2比較的行數是相同的,這樣使用被驅動表的索引關聯稱之為“Index Nested-Loop Join”,簡稱NLJ。
由於是驅動表t1去匹配被驅動表t2,那麼匹配次數取決於t1有多少資料,所以在用索引關聯的時候還需要注意,最好使用資料量少的表作為驅動表。
- 使用join_buffer來進行關聯
如果我們將sql改成如下(在t2表中b欄位是無索引的):
select * from t1 straight_join t2 on (t1.a=t2.b);這時候,被驅動表上沒有可用的索引,演算法的流程是這樣的:
1. 把表t1的資料讀入執行緒記憶體join_buffer中,由於我們這個語句中寫的是select *,因此是把整個表t1放入了記憶體;
2. 掃描表t2,把表t2中的每一行取出來,跟join_buffer中的資料做對比,滿足join條件的,作為結果集的一部分返回。
join_buffer的大小是由引數join_buffer_size設定的,預設值是256k。如果放不下表t1的所有資料話,策略很簡單,就是分段放。如果分段放的話,那麼被驅動表就要掃描多次,那麼就會有效能問題。
所以如果join_buffer_size放不下的話就要使用小表作為驅動表,減少分段放的次數,在決定哪個表做驅動表的時候,應該是兩個表按照各自的條件過濾,過濾完成之後,計算參與join的各個欄位的總資料量,資料量小的那個表,就是“小表”,應該作為驅動表。