
原始碼分析 Kafka 訊息傳送流程(文末附流程圖)
溫馨提示:本文基於 Kafka 2.2.1 版本。本文主要是以原始碼的手段一步一步探究訊息傳送流程,如果對原始碼不感興趣,可以直接跳到文末檢視訊息傳送流程圖與訊息傳送本地快取儲存結構。
從上文 初識 Kafka Producer 生產者,可以通過 KafkaProducer 的 send 方法傳送訊息,send 方法的宣告如下:
Future<RecordMetadata> send(ProducerRecord<K, V> record) Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
從上面的 API 可以得知,使用者在使用 KafkaProducer 傳送訊息時,首先需要將待發送的訊息封裝成 ProducerRecord,返回的是一個 Future 物件,典型的 Future 設計模式。在傳送時也可以指定一個 Callable 介面用來執行訊息傳送的回撥。
我們在學習訊息傳送流程之前先來看一下用於封裝一條訊息的 ProducerRecord 的類圖,先來認識一下 kafka 是如何對一條訊息進行抽象的。
1、ProducerRecord 類圖

我們首先來看一下 ProducerRecord 的核心屬性,即構成 訊息的6大核心要素:
- String topic
訊息所屬的主題。 - Integer partition
訊息所在主題的佇列數,可以人為指定,如果指定了 key 的話,會使用 key 的 hashCode 與佇列總數進行取模來選擇分割槽,如果前面兩者都未指定,則會輪詢主題下的所有分割槽。 - Headers headers
該訊息的額外屬性對,與訊息體分開儲存. - K key
訊息鍵,如果指定該值,則會使用該值的 hashcode 與 佇列數進行取模來選擇分割槽。 - V value
訊息體。 - Long timestamp
訊息時間戳,根據 topic 的配置資訊 message.timestamp.type 的值來賦予不同的值。- CreateTime
傳送客戶端傳送訊息時的時間戳。 - LogAppendTime
訊息在 broker 追加時的時間戳。
- CreateTime
其中Headers是一系列的 key-value 鍵值對。
在瞭解 ProducerRecord 後我們開始來探討 Kafka 的訊息傳送流程。
2、Kafka 訊息追加流程
KafkaProducer 的 send 方法,並不會直接向 broker 傳送訊息,kafka 將訊息傳送非同步化,即分解成兩個步驟,send 方法的職責是將訊息追加到記憶體中(分割槽的快取佇列中),然後會由專門的 Send 執行緒非同步將快取中的訊息批量傳送到 Kafka Broker 中。
訊息追加入口為 KafkaProducer#send
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); // @1
return doSend(interceptedRecord, callback); // @2
}程式碼@1:首先執行訊息傳送攔截器,攔截器通過 interceptor.classes 指定,型別為 List< String >,每一個元素為攔截器的全類路徑限定名。
程式碼@2:執行 doSend 方法,後續我們需要留意一下 Callback 的呼叫時機。
接下來我們來看 doSend 方法。
2.1 doSend
KafkaProducer#doSend
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);Step1:獲取 topic 的分割槽列表,如果本地沒有該topic的分割槽資訊,則需要向遠端 broker 獲取,該方法會返回拉取元資料所耗費的時間。在訊息傳送時的最大等待時間時會扣除該部分損耗的時間。
溫馨提示:本文不打算對該方法進行深入學習,後續會有專門的文章來分析 Kafka 元資料的同步機制,類似於專門介紹 RocketMQ 的 Nameserver 類似。
KafkaProducer#doSend
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}Step2:序列化 key。注意:序列化方法雖然有傳入 topic、Headers 這兩個屬性,但參與序列化的只是 key 。
KafkaProducer#doSend
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}Step3:對訊息體內容進行序列化。
KafkaProducer#doSend
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);Step4:根據分割槽負載演算法計算本次訊息傳送該發往的分割槽。其預設實現類為 DefaultPartitioner,路由演算法如下:
- 如果指定了 key ,則使用 key 的 hashcode 與分割槽數取模。
- 如果未指定 key,則輪詢所有的分割槽。
KafkaProducer#doSend
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();Step5:如果是訊息頭資訊(RecordHeaders),則設定為只讀。
KafkaProducer#doSend
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);Step5:根據使用的版本號,按照訊息協議來計算訊息的長度,並是否超過指定長度,如果超過則丟擲異常。
KafkaProducer#doSend
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);Step6:先初始化訊息時間戳,並對傳入的 Callable(回撥函式) 加入到攔截器鏈中。
KafkaProducer#doSend
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);Step7:如果事務處理器不為空,執行事務管理相關的,本節不考慮事務訊息相關的實現細節,後續估計會有對應的文章進行解析。
KafkaProducer#doSend
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;Step8:將訊息追加到快取區,這將是本文重點需要探討的。如果當前快取區已寫滿或建立了一個新的快取區,則喚醒 Sender(訊息傳送執行緒),將快取區中的訊息傳送到 broker 伺服器,最終返回 future。這裡是經典的 Future 設計模式,從這裡也能得知,doSend 方法執行完成後,此時訊息還不一定成功傳送到 broker。
KafkaProducer#doSend
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (BufferExhaustedException e) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, tp, e);
throw e;
}Step9:針對各種異常,進行相關資訊的收集。
接下來將重點介紹如何將訊息追加到生產者的傳送快取區,其實現類為:RecordAccumulator。
2.2 RecordAccumulator append 方法詳解
RecordAccumulator#append
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock) throws InterruptedException {在介紹該方法之前,我們首先來看一下該方法的引數。
- TopicPartition tp
topic 與分割槽資訊,即傳送到哪個 topic 的那個分割槽。 - long timestamp
客戶端傳送時的時間戳。 - byte[] key
訊息的 key。 - byte[] value
訊息體。 - Header[] headers
訊息頭,可以理解為額外訊息屬性。 - Callback callback
回撥方法。 - long maxTimeToBlock
訊息追加超時時間。
RecordAccumulator#append
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}Step1:嘗試根據 topic與分割槽在 kafka 中獲取一個雙端佇列,如果不存在,則建立一個,然後呼叫 tryAppend 方法將訊息追加到快取中。Kafka 會為每一個 topic 的每一個分割槽建立一個訊息快取區,訊息先追加到快取中,然後訊息傳送 API 立即返回,然後由單獨的執行緒 Sender 將快取區中的訊息定時傳送到 broker 。這裡的快取區的實現使用的是 ArrayQeque。然後呼叫 tryAppend 方法嘗試將訊息追加到其快取區,如果追加成功,則返回結果。
在講解下一個流程之前,我們先來看一下 Kafka 雙端佇列的儲存結構:
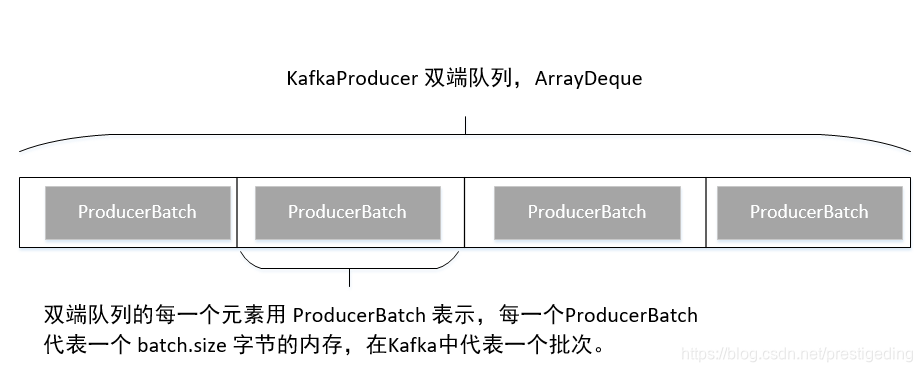
RecordAccumulator#append
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
buffer = free.allocate(size, maxTimeToBlock);Step2:如果第一步未追加成功,說明當前沒有可用的 ProducerBatch,則需要建立一個 ProducerBatch,故先從 BufferPool 中申請 batch.size 的記憶體空間,為建立 ProducerBatch 做準備,如果由於 BufferPool 中未有剩餘記憶體,則最多等待 maxTimeToBlock ,如果在指定時間內未申請到記憶體,則丟擲異常。
RecordAccumulator#append
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 省略部分程式碼
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}Step3:建立一個新的批次 ProducerBatch,並將訊息寫入到該批次中,並返回追加結果,這裡有如下幾個關鍵點:
- 建立 ProducerBatch ,其內部持有一個 MemoryRecordsBuilder物件,該物件負責將訊息寫入到記憶體中,即寫入到 ProducerBatch 內部持有的記憶體,大小等於 batch.size。
- 將訊息追加到 ProducerBatch 中。
- 將新建立的 ProducerBatch 新增到雙端佇列的末尾。
- 將該批次加入到 incomplete 容器中,該容器存放未完成傳送到 broker 伺服器中的訊息批次,當 Sender 執行緒將訊息傳送到 broker 服務端後,會將其移除並釋放所佔記憶體。
- 返回追加結果。
縱觀 RecordAccumulator append 的流程,基本上就是從雙端佇列獲取一個未填充完畢的 ProducerBatch(訊息批次),然後嘗試將其寫入到該批次中(快取、記憶體中),如果追加失敗,則嘗試建立一個新的 ProducerBatch 然後繼續追加。
接下來我們繼續探究如何向 ProducerBatch 中寫入訊息。
2.3 ProducerBatch tryAppend方法詳解
ProducerBatch #tryAppend
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) { // @1
return null;
} else {
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers); // @2
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compressionType(), key, value, headers)); // @3
this.lastAppendTime = now; //
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length,
Time.SYSTEM); // @4
// we have to keep every future returned to the users in case the batch needs to be
// split to several new batches and resent.
thunks.add(new Thunk(callback, future)); // @5
this.recordCount++;
return future;
}
}程式碼@1:首先判斷 ProducerBatch 是否還能容納當前訊息,如果剩餘記憶體不足,將直接返回 null。如果返回 null ,會嘗試再建立一個新的ProducerBatch。
程式碼@2:通過 MemoryRecordsBuilder 將訊息寫入按照 Kafka 訊息格式寫入到記憶體中,即寫入到 在建立 ProducerBatch 時申請的 ByteBuffer 中。本文先不詳細介紹 Kafka 各個版本的訊息格式,後續會專門寫一篇文章介紹 Kafka 各個版本的訊息格式。
程式碼@3:更新 ProducerBatch 的 maxRecordSize、lastAppendTime 屬性,分別表示該批次中最大的訊息長度與最後一次追加訊息的時間。
程式碼@4:構建 FutureRecordMetadata 物件,這裡是典型的 Future模式,裡面主要包含了該條訊息對應的批次的 produceFuture、訊息在該批訊息的下標,key 的長度、訊息體的長度以及當前的系統時間。
程式碼@5:將 callback 、本條訊息的憑證(Future) 加入到該批次的 thunks 中,該集合儲存了 一個批次中所有訊息的傳送回執。
流程執行到這裡,KafkaProducer 的 send 方法就執行完畢了,返回給呼叫方的就是一個 FutureRecordMetadata 物件。
原始碼的閱讀比較枯燥,接下來用一個流程圖簡單的闡述一下訊息追加的關鍵要素,重點關注一下各個 Future。
2.4 Kafka 訊息追加流程圖與總結
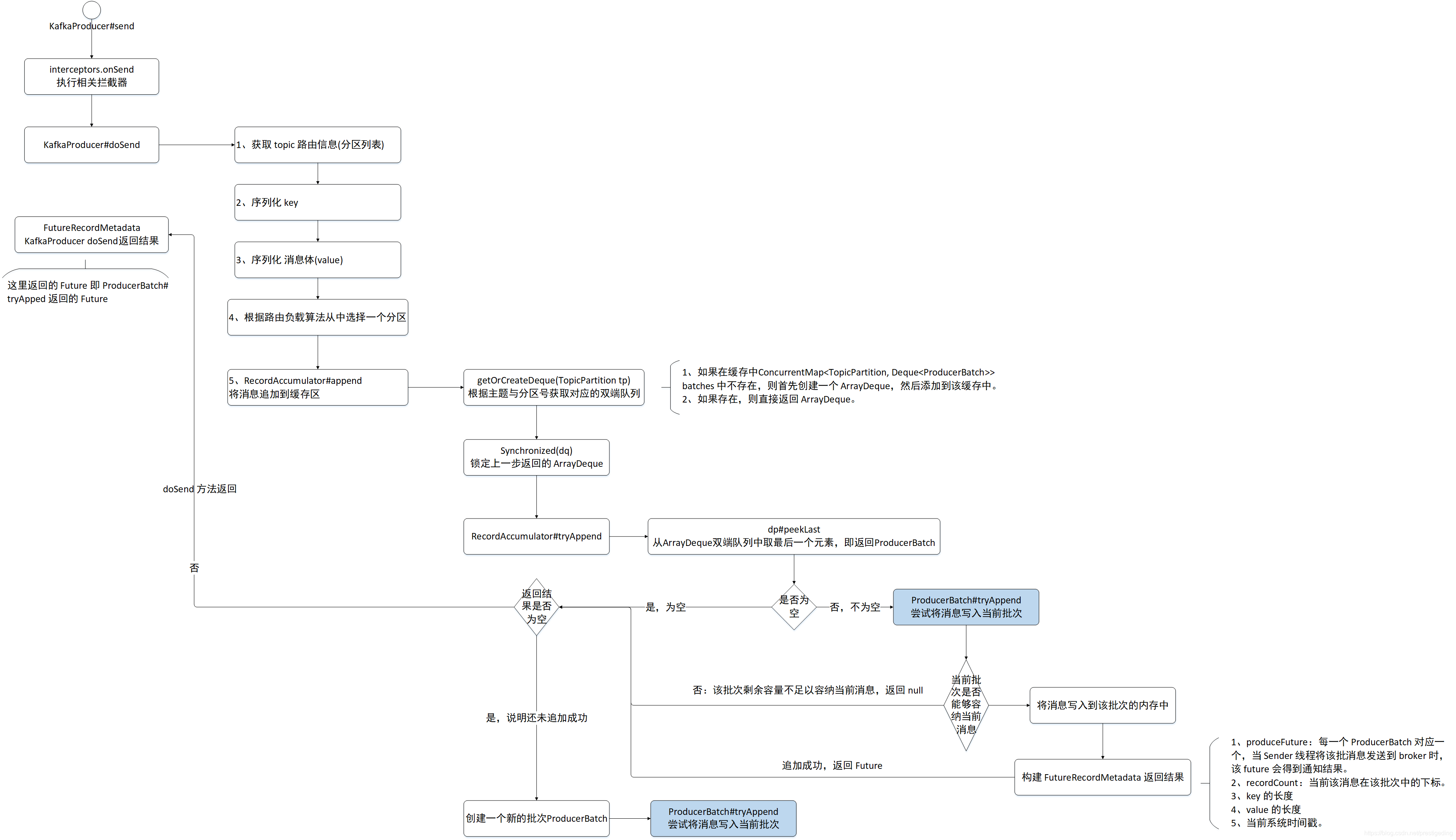
上面的訊息傳送,其實用訊息追加來表達更加貼切,因為 Kafka 的 send 方法,並不會直接向 broker 傳送訊息,而是首先先追加到生產者的記憶體快取中,其記憶體儲存結構如下:ConcurrentMap< TopicPartition, Deque< ProducerBatch>> batches,那我們自然而然的可以得知,Kafka 的生產者為會每一個 topic 的每一個 分割槽單獨維護一個佇列,即 ArrayDeque,內部存放的元素為 ProducerBatch,即代表一個批次,即 Kafka 訊息傳送是按批發送的。其快取結果圖如下:
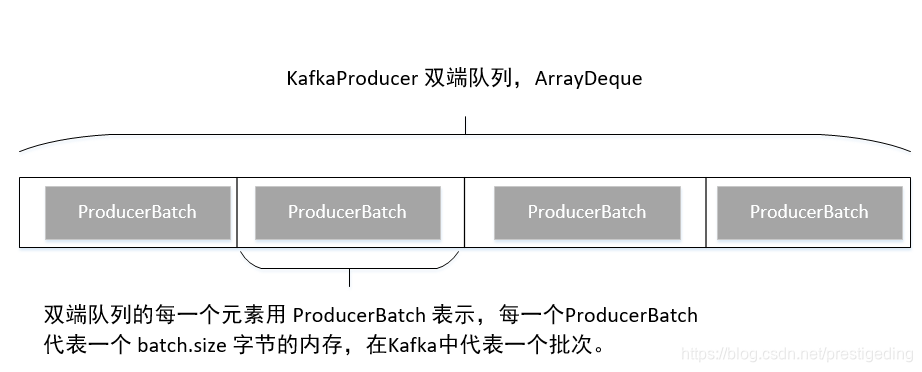
KafkaProducer 的 send 方法最終返回的 FutureRecordMetadata ,是 Future 的子類,即 Future 模式。那 kafka 的訊息傳送怎麼實現非同步傳送、同步傳送的呢?
其實答案也就蘊含在 send 方法的返回值,如果專案方需要使用同步傳送的方式,只需要拿到 send 方法的返回結果後,呼叫其 get() 方法,此時如果訊息還未傳送到 Broker 上,該方法會被阻塞,等到 broker 返回訊息傳送結果後該方法會被喚醒並得到訊息傳送結果。如果需要非同步傳送,則建議使用 send(ProducerRecord< K, V > record, Callback callback),但不能呼叫 get 方法即可。Callback 會在收到 broker 的響應結果後被呼叫,並且支援攔截器。
訊息追加流程就介紹到這裡了,訊息被追加到快取區後,什麼是會被髮送到 broker 端呢?將在下一篇文章中詳細介紹。
如果文章對您有所幫助的話,麻煩幫忙點個贊,謝謝您的認可與支援。
作者介紹:
丁威,《RocketMQ技術內幕》作者,RocketMQ 社群佈道師,公眾號:中介軟體興趣圈 維護者,目前已陸續發表原始碼分析Java集合、Java 併發包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等原始碼專欄。歡迎加入我的知識星球,構建一個高質量的技術交流社群。
