
原始碼分析Kafka 訊息拉取流程
目錄
- 1、KafkaConsumer poll 詳解
- 2、Fetcher 類詳解
本節重點討論 Kafka 的訊息拉起流程。
@(本節目錄)
1、KafkaConsumer poll 詳解
訊息拉起主要入口為:KafkaConsumer#poll方法,其宣告如下:
~java
public ConsumerRecords<K, V> poll(final Duration timeout) { // @1
return poll(time.timer(timeout), true); // @2
}
程式碼@1:引數為超時時間,使用 java 的 Duration 來定義。
程式碼@2:呼叫內部的 poll 方法。
KafkaConsumer#poll
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) { // @1 acquireAndEnsureOpen(); // @2 try { if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) { // @3 throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions"); } // poll for new data until the timeout expires do { // @4 client.maybeTriggerWakeup(); //@5 if (includeMetadataInTimeout) { // @6 if (!updateAssignmentMetadataIfNeeded(timer)) { return ConsumerRecords.empty(); } } else { while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE))) { log.warn("Still waiting for metadata"); } } final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer); // @7 if (!records.isEmpty()) { if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) { // @8 client.pollNoWakeup(); } return this.interceptors.onConsume(new ConsumerRecords<>(records)); // @9 } } while (timer.notExpired()); return ConsumerRecords.empty(); } finally { release(); } }
程式碼@1:首先先對其引數含義進行講解。
- boolean includeMetadataInTimeout
拉取訊息的超時時間是否包含更新元資料的時間,預設為true,即包含。
程式碼@2:檢查是否可以拉取訊息,其主要判斷依據如下:
- KafkaConsumer 是否有其他執行緒再執行,如果有,則丟擲異常,因為 - KafkaConsumer 是執行緒不安全的,同一時間只能一個執行緒執行。
- KafkaConsumer 沒有被關閉。
程式碼@3:如果當前消費者未訂閱任何主題或者沒有指定佇列,則丟擲錯誤,結束本次訊息拉取。
程式碼@4:使用 do while 結構迴圈拉取訊息,直到超時或拉取到訊息。
程式碼@5:避免在禁止禁用wakeup時,有請求想喚醒時則丟擲異常,例如在下面的@8時,會禁用wakeup。
程式碼@6:更新相關元資料,為真正向 broker 傳送訊息拉取請求做好準備,該方法將在下面詳細介紹,現在先簡單介紹其核心實現點:
- 如有必要,先向 broker 端拉取最新的訂閱資訊(包含消費組內的線上的消費客戶端)。
- 執行已完成(非同步提交)的 offset 提交請求的回撥函式。
- 維護與 broker 端的心跳請求,確保不會被“踢出”消費組。
- 更新元資訊。
- 如果是自動提交消費偏移量,則自動提交偏移量。
- 更新各個分割槽下次待拉取的偏移量。
這裡會有一個更新元資料是否佔用訊息拉取的超時時間,預設為 true。
程式碼@7:呼叫 pollForFetches 向broker拉取訊息,該方法將在下文詳細介紹。
程式碼@8:如果拉取到的訊息集合不為空,再返回該批訊息之前,如果還有擠壓的拉取請求,可以繼續傳送拉取請求,但此時會禁用warkup,主要的目的是使用者在處理訊息時,KafkaConsumer 還可以繼續向broker 拉取訊息。
程式碼@9:執行消費攔截器。
接下來對上文提到的程式碼@6、@7進行詳細介紹。
1.1 KafkaConsumer updateAssignmentMetadataIfNeeded 詳解
KafkaConsumer#updateAssignmentMetadataIfNeeded
boolean updateAssignmentMetadataIfNeeded(final Timer timer) {
if (coordinator != null && !coordinator.poll(timer)) { // @1
return false;
}
return updateFetchPositions(timer); // @2
}要理解這個方法實現的用途,我們就必須依次對 coordinator.poll 方法與 updateFetchPositions 方法。
1.1.1 ConsumerCoordinator#poll
public boolean poll(Timer timer) {
invokeCompletedOffsetCommitCallbacks(); // @1
if (subscriptions.partitionsAutoAssigned()) { // @2
pollHeartbeat(timer.currentTimeMs()); // @21
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) { //@22
return false;
}
if (rejoinNeededOrPending()) { // @23
if (subscriptions.hasPatternSubscription()) { // @231
if (this.metadata.timeToAllowUpdate(time.milliseconds()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
}
if (!ensureActiveGroup(timer)) { // @232
return false;
}
}
} else { // @3
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
maybeAutoCommitOffsetsAsync(timer.currentTimeMs()); // @4
return true;
}程式碼@1:執行已完成的 offset (消費進度)提交請求的回撥函式。
程式碼@2:佇列負載演算法為自動分配(即 Kafka 根據消費者個數與分割槽書動態負載分割槽)的相關的處理邏輯。其實現關鍵點如下:
- 程式碼@21:更新發送心跳相關的時間,例如heartbeatTimer、sessionTimer、pollTimer 分別代表傳送最新發送心跳的時間、會話最新活躍時間、最新拉取訊息。
- 程式碼@22:如果不存在協調器或協調器已斷開連線,則返回 false,結束本次拉取。如果協調器就緒,則繼續往下走。
- 程式碼@23:判斷是否需要觸發重平衡,即消費組內的所有消費者重新分配topic中的分割槽資訊,例如元資料傳送變化,判斷是否需要重新重平衡的關鍵點如下:
- 如果佇列負載是通過使用者指定的,則返回 false,表示無需重平衡。
- 如果佇列是自動負載,topic 佇列元資料發生了變化,則需要重平衡。
- 如果佇列是自動負載,訂閱關係發生了變化,則需要重平衡。
如果需要重重平衡,則同步更新元資料,此過程會阻塞。詳細的重平衡將單獨重點介紹,這裡暫時不深入展開。
程式碼@3:使用者手動為消費組指定負載的佇列的相關處理邏輯,其實現關鍵如下:
- 如果需要更新元資料,並且還沒有分割槽準備好,則同步阻塞等待元資料更新完畢。
程式碼@4:如果開啟了自動提交消費進度,並且已到下一次提交時間,則提交。Kafka 消費者可以通過設定屬性 enable.auto.commit 來開啟自動提交,該引數預設為 true,則預設會每隔 5s 提交一次消費進度,提交間隔可以通過引數 auto.commit.interval.ms 設定。
接下來繼續探討 updateAssignmentMetadataIfNeeded (更新元資料)的第二個步驟,更新拉取位移。
1.1.2 updateFetchPositions 詳解
KafkaConsumer#updateFetchPositions
private boolean updateFetchPositions(final Timer timer) {
cachedSubscriptionHashAllFetchPositions = subscriptions.hasAllFetchPositions();
if (cachedSubscriptionHashAllFetchPositions) { // @1
return true;
}
if (coordinator != null && !coordinator.refreshCommittedOffsetsIfNeeded(timer)) // @2
return false;
subscriptions.resetMissingPositions(); // @3
fetcher.resetOffsetsIfNeeded(); // @4
return true;
}程式碼@1:如果訂閱關係中的所有分割槽都有有效的位移,則返回 true。
程式碼@2:如果存在任意一個分割槽沒有有效的位移資訊,則需要向 broker 傳送請求,從broker 獲取該消費組,該分割槽的消費進度。相關的實現細節將在後續文章【Kafka 消費進度】專題文章中詳細介紹。
程式碼@3:如果經過第二步,訂閱關係中還某些分割槽還是沒有獲取到有效的偏移量,則使用偏移量重置策略進行重置,如果未配置,則丟擲異常。
程式碼@4:傳送一個非同步請求去重置那些正等待重置位置的分割槽。有關 Kafka 消費消費進度、重平衡等知識將會在後續文章中深入探討,本文只需瞭解 poll 訊息的核心處理流程。
從 KafkaConsumer#poll 中流程可以看到,通過 updateAssignmentMetadataIfNeeded 對元資料、重平衡,更新拉取偏移量等工作處理完成後,下一步就是需要向 broker 拉取訊息了,其實現入口為:KafkaConsumer 的 pollForFetches 方法。
1.2 訊息拉取
KafkaConsumer#pollForFetches
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs()); // @1
// if data is available already, return it immediately
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); // @2
if (!records.isEmpty()) {
return records;
}
fetcher.sendFetches(); // @3
// We do not want to be stuck blocking in poll if we are missing some positions
// since the offset lookup may be backing off after a failure
// NOTE: the use of cachedSubscriptionHashAllFetchPositions means we MUST call
// updateAssignmentMetadataIfNeeded before this method.
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) { // @4
pollTimeout = retryBackoffMs;
}
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
return !fetcher.hasCompletedFetches();
}); // @5
timer.update(pollTimer.currentTimeMs()); // @6
if (coordinator != null && coordinator.rejoinNeededOrPending()) { // @7
return Collections.emptyMap();
}
return fetcher.fetchedRecords(); // @8
}程式碼@1:計算本次拉取的超時時間,其計算邏輯如下:
- 如果協調器為空,則返回當前定時器剩餘時間即可。
- 如果協調器不為空,其邏輯較為複雜,為下面返回的超時間與當前定時器剩餘時間相比取最小值。
- 如果不開啟自動提交位移並且未加入消費組,則超時時間為Long.MAX_VALUE。
- 如果不開啟自動提交位移並且已加入消費組,則返回距離下一次傳送心跳包還剩多少時間。
- 如果開啟自動提交位移,則返回 距離下一次自動提交位移所需時間 與 距離下一次傳送心跳包所需時間 之間的最小值。
程式碼@2:如果資料已經拉回到本地,直接返回資料。將在下文詳細介紹 Fetcher 的 fetchedRecords 方法。
程式碼@3:組裝傳送請求,並將儲存在待發送請求列表中。
程式碼@4:如果已快取的分割槽資訊中存在某些分割槽缺少偏移量,如果拉取的超時時間大於失敗重試需要阻塞的時間,則更新此次拉取的超時時間為失敗重試需要的間隔時間,主要的目的是不希望在 poll 過程中被阻塞【後續會詳細介紹 Kafka 拉取訊息的執行緒模型,再來回顧一下這裡】。
程式碼@5:通過呼叫NetworkClient 的 poll 方法發起訊息拉取操作(觸發網路讀寫)。
程式碼@6:更新本次拉取的時間。
程式碼@7:檢查是需要重平衡。
程式碼@8:將從 broker 讀取到的資料返回(即封裝成訊息)。
從上面訊息拉取流程來看,有幾個比較重要的方法,例如 Fetcher 類相關的方法,NetworkClient 的 poll 方法,那我們接下來來重點探討。
我們先用一張流程圖總結一下訊息拉取的全過程:
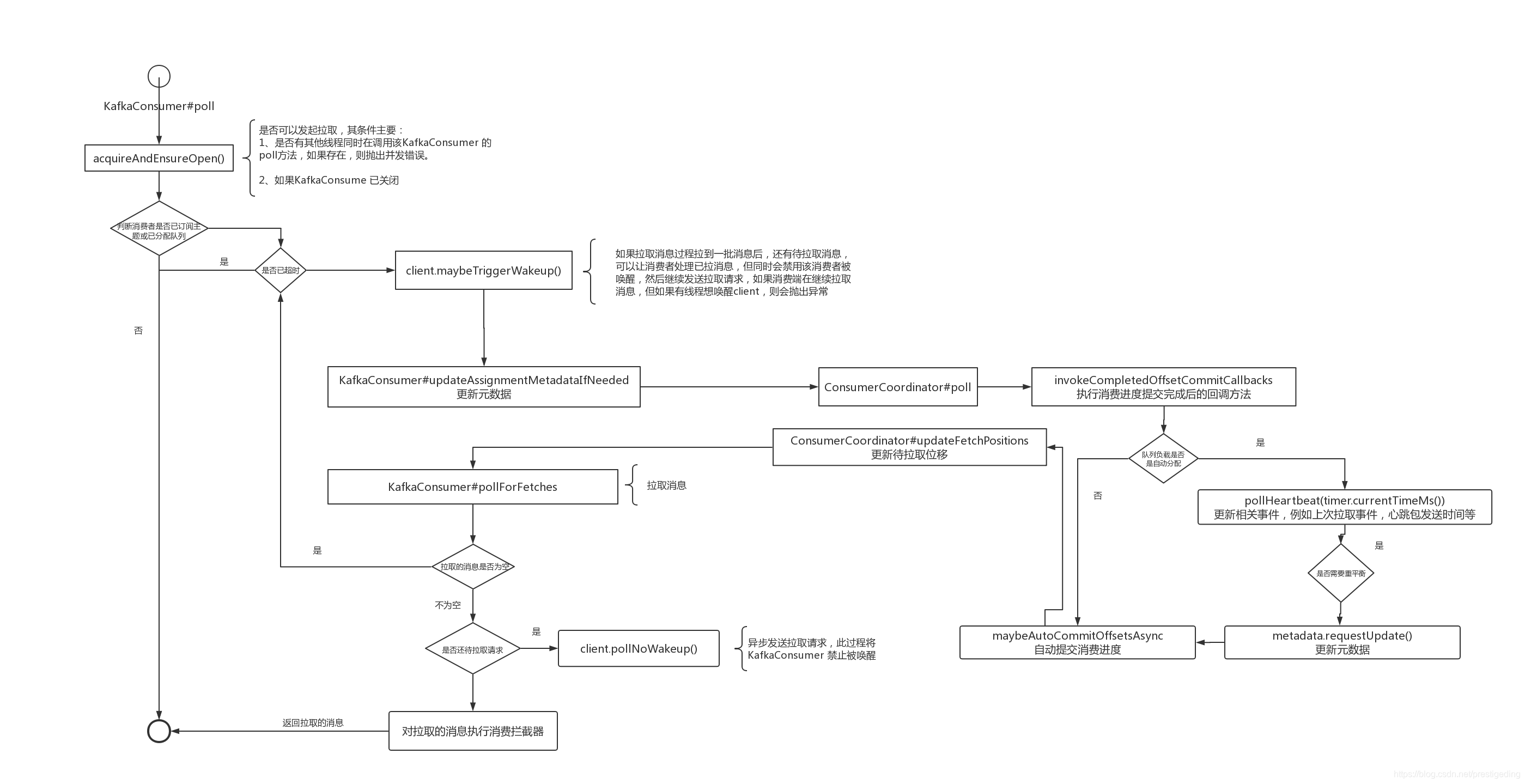
接下來我們將重點看一下 KafkaConsumer 的 pollForFetches 詳細過程,也就是需要詳細探究 Fetcher 類的實現細節。
2、Fetcher 類詳解
Fetcher 封裝訊息拉取的方法,可以看成是訊息拉取的門面類。
2.1 類圖

我們首先一一介紹一下 Fetcher 的核心屬性與核心方法。
- ConsumerNetworkClient client
消費端網路客戶端,Kafka 負責網路通訊實現類。 - int minBytes
一次訊息拉取需要拉取的最小位元組數,如果不組,會阻塞,預設值為1位元組,如果增大這個值會增大吞吐,但會增加延遲,可以通引數 fetch.min.bytes 改變其預設值。 - int maxBytes
一次訊息拉取允許拉取的最大位元組數,但這不是絕對的,如果一個分割槽的第一批記錄超過了該值,也會返回。預設為50M,可通過引數 fetch.max.bytes 改變其預設值。同時不能超過 broker的配置引數(message.max.bytes) 和 主題級別的配置(max.message.bytes)。 - int maxWaitMs
在 broker 如果符合拉取條件的資料小於 minBytes 時阻塞的時間,預設為 500ms ,可通屬性 fetch.max.wait.ms 進行定製。 - int fetchSize
每一個分割槽返回的最大訊息位元組數,如果分割槽中的第一批訊息大於 fetchSize 也會返回。 - long retryBackoffMs
失敗重試後需要阻塞的時間,預設為 100 ms,可通過引數 retry.backoff.ms 定製。 - long requestTimeoutMs
客戶端向 broker 傳送請求最大的超時時間,預設為 30s,可以通過 request.timeout.ms 引數定製。 - int maxPollRecords
單次拉取返回的最大記錄數,預設值 500,可通過引數 max.poll.records 進行定製。 - boolean checkCrcs
是否檢查訊息的 crcs 校驗和,預設為 true,可通過引數 check.crcs 進行定製。 - Metadata metadata
元資料。 - FetchManagerMetrics sensors
訊息拉取的統計服務類。 - SubscriptionState subscriptions
訂閱資訊狀態。 - ConcurrentLinkedQueue< CompletedFetch> completedFetches
已完成的 Fetch 的請求結果,待消費端從中取出資料。 - Deserializer< K> keyDeserializer
key 的反序列化器。 - Deserializer< V> valueDeserializer
value 的飯序列化器。 - IsolationLevel isolationLevel
Kafka的隔離級別(與事務訊息相關),後續在研究其事務相關時再進行探討。 - Map<Integer, FetchSessionHandler> sessionHandlers
拉取會話監聽器。
接下來我們將按照訊息流程,一起來看一下 Fetcher 的核心方法。
2.2 Fetcher 核心方法
2.2.1 Fetcher#fetchedRecords
Fetcher#fetchedRecords
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>(); // @1
int recordsRemaining = maxPollRecords;
try {
while (recordsRemaining > 0) { // @2
if (nextInLineRecords == null || nextInLineRecords.isFetched) { // @3
CompletedFetch completedFetch = completedFetches.peek();
if (completedFetch == null) break;
try {
nextInLineRecords = parseCompletedFetch(completedFetch);
} catch (Exception e) {
FetchResponse.PartitionData partition = completedFetch.partitionData;
if (fetched.isEmpty() && (partition.records == null || partition.records.sizeInBytes() == 0)) {
completedFetches.poll();
}
throw e;
}
completedFetches.poll();
} else { // @4
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining);
TopicPartition partition = nextInLineRecords.partition;
if (!records.isEmpty()) {
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
}
return fetched;
}程式碼@1:首先先解釋兩個區域性變數的含義:
- Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched 按分割槽存放已拉取的訊息,返回給客戶端進行處理。
- recordsRemaining:剩餘可拉取的訊息條數。
程式碼@2:迴圈去取已經完成了 Fetch 請求的訊息,該 while 迴圈有兩個跳出條件:
- 如果拉取的訊息已經達到一次拉取的最大訊息條數,則跳出迴圈。
- 快取中所有拉取結果已處理。
程式碼@3、@4 主要完成從快取中解析資料的兩個步驟,初次執行的時候,會進入分支@3,然後從 呼叫 parseCompletedFetch 解析成 PartitionRecords 物件,然後程式碼@4的職責就是從解析 PartitionRecords ,將訊息封裝成 ConsumerRecord,返回給消費端執行緒處理。
程式碼@3的實現要點如下:
- 首先從 completedFetches (Fetch請求的返回結果) 列表中獲取一個 Fetcher 請求,主要使用的 Queue 的 peek()方法,並不會從該佇列中移除該元素。
- 然後呼叫 parseCompletedFetch 對處理結果進行解析返回 PartitionRecords。
- 處理成功後,呼叫 Queue 的方法將已處理過的 Fetcher結果移除。
從上面可知,上述方法的核心方法是:parseCompletedFetch。
程式碼@4的實現要點無非就是呼叫 fetchRecords 方法,按分割槽組裝成 Map<TopicPartition, List<ConsumerRecord<K, V>>>,供消費者處理,例如供業務處理。
接下來將重點探討上述兩個方法的實現細節。
2.2.1.1 Fetcher#parseCompletedFetch
在嘗試探討該方法之前,我們首先對其入參進行一個梳理,特別是先認識其主要資料結構。
1、CompletedFetch 相關類圖
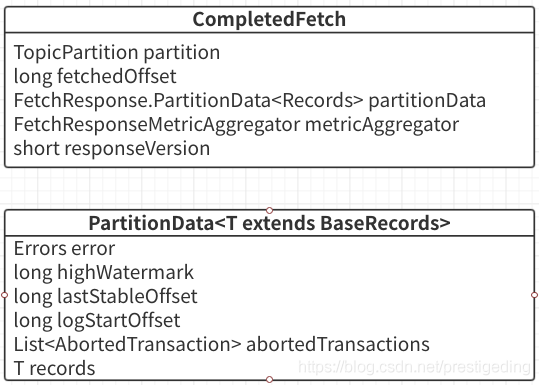
從上圖可以看出,CompleteFetch 核心屬性主要如下:
- TopicPartition partition
分割槽資訊,返回結果都是以分割槽為緯度。 - long fetchedOffset
本次拉取的開始偏移量。 - FetchResponse.PartitionData partitionData
返回的分割槽資料。 - FetchResponseMetricAgregator metricAggregator
統計指標相關。 - short responseVersion
broker 端的版本號。
分割槽的資料是使用 PartitionData 來進行封裝的。我們也來簡單的瞭解一下其內部資料結果。
- Errors error
分割槽拉取的相應結果,Errors.NONE 表示請求成功。 - long highWatermark
broker 端關於該分割槽的高水位線,即小於該偏移量的訊息對於消費端是可見的。 - long lastStableOffset
分割槽中小於該偏移量的訊息的事務狀態已得到確認,要麼是已提交,要麼是已回滾,與事務相關,後面會專門探討。 - List< AbortedTransaction> abortedTransactions
已拒絕的事物。 - T records
分割槽資料,是 BaseRecords 的子類。
2、parseCompletedFetch 詳解
private PartitionRecords parseCompletedFetch(CompletedFetch completedFetch) {
TopicPartition tp = completedFetch.partition;
FetchResponse.PartitionData<Records> partition = completedFetch.partitionData;
long fetchOffset = completedFetch.fetchedOffset;
PartitionRecords partitionRecords = null;
Errors error = partition.error;
try {
if (!subscriptions.isFetchable(tp)) { // @1
log.debug("Ignoring fetched records for partition {} since it is no longer fetchable", tp);
} else if (error == Errors.NONE) { // @2
Long position = subscriptions.position(tp);
if (position == null || position != fetchOffset) { // @21
log.debug("Discarding stale fetch response for partition {} since its offset {} does not match " +
"the expected offset {}", tp, fetchOffset, position);
return null;
}
log.trace("Preparing to read {} bytes of data for partition {} with offset {}",
partition.records.sizeInBytes(), tp, position);
Iterator<? extends RecordBatch> batches = partition.records.batches().iterator(); // @22
partitionRecords = new PartitionRecords(tp, completedFetch, batches);
if (!batches.hasNext() && partition.records.sizeInBytes() > 0) { // @23
if (completedFetch.responseVersion < 3) {
Map<TopicPartition, Long> recordTooLargePartitions = Collections.singletonMap(tp, fetchOffset);
throw new RecordTooLargeException("There are some messages at [Partition=Offset]: " +
recordTooLargePartitions + " whose size is larger than the fetch size " + this.fetchSize +
" and hence cannot be returned. Please considering upgrading your broker to 0.10.1.0 or " +
"newer to avoid this issue. Alternately, increase the fetch size on the client (using " +
ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG + ")",
recordTooLargePartitions);
} else {
// This should not happen with brokers that support FetchRequest/Response V3 or higher (i.e. KIP-74)
throw new KafkaException("Failed to make progress reading messages at " + tp + "=" +
fetchOffset + ". Received a non-empty fetch response from the server, but no " +
"complete records were found.");
}
}
if (partition.highWatermark >= 0) { // @24
log.trace("Updating high watermark for partition {} to {}", tp, partition.highWatermark);
subscriptions.updateHighWatermark(tp, partition.highWatermark);
}
if (partition.logStartOffset >= 0) { // @25
log.trace("Updating log start offset for partition {} to {}", tp, partition.logStartOffset);
subscriptions.updateLogStartOffset(tp, partition.logStartOffset);
}
if (partition.lastStableOffset >= 0) { // @26
log.trace("Updating last stable offset for partition {} to {}", tp, partition.lastStableOffset);
subscriptions.updateLastStableOffset(tp, partition.lastStableOffset);
}
} else if (error == Errors.NOT_LEADER_FOR_PARTITION ||
error == Errors.REPLICA_NOT_AVAILABLE ||
error == Errors.KAFKA_STORAGE_ERROR) { // @3
log.debug("Error in fetch for partition {}: {}", tp, error.exceptionName());
this.metadata.requestUpdate();
} else if (error == Errors.UNKNOWN_TOPIC_OR_PARTITION) { // @4
log.warn("Received unknown topic or partition error in fetch for partition {}", tp);
this.metadata.requestUpdate();
} else if (error == Errors.OFFSET_OUT_OF_RANGE) { // @5
if (fetchOffset != subscriptions.position(tp)) {
log.debug("Discarding stale fetch response for partition {} since the fetched offset {} " +
"does not match the current offset {}", tp, fetchOffset, subscriptions.position(tp));
} else if (subscriptions.hasDefaultOffsetResetPolicy()) {
log.info("Fetch offset {} is out of range for partition {}, resetting offset", fetchOffset, tp);
subscriptions.requestOffsetReset(tp);
} else {
throw new OffsetOutOfRangeException(Collections.singletonMap(tp, fetchOffset));
}
} else if (error == Errors.TOPIC_AUTHORIZATION_FAILED) { // @6
log.warn("Not authorized to read from topic {}.", tp.topic());
throw new TopicAuthorizationException(Collections.singleton(tp.topic()));
} else if (error == Errors.UNKNOWN_SERVER_ERROR) {
log.warn("Unknown error fetching data for topic-partition {}", tp);
} else {
throw new IllegalStateException("Unexpected error code " + error.code() + " while fetching data");
}
} finally { // @7
if (partitionRecords == null)
completedFetch.metricAggregator.record(tp, 0, 0);
if (error != Errors.NONE)
// we move the partition to the end if there was an error. This way, it's more likely that partitions for
// the same topic can remain together (allowing for more efficient serialization).
subscriptions.movePartitionToEnd(tp);
}
return partitionRecords;
}上面的程式碼雖然比較長,其實整體還是比較簡單,只是需要針對各種異常處理,列印對應的日誌,接下來詳細介紹該方法的實現關鍵點。
程式碼@1:判斷該分割槽是否可拉取,如果不可拉取,則忽略這批拉取的訊息,判斷是可拉取的要點如下:
- 當前消費者負載的佇列包含該分割槽。
- 當前消費者針對該佇列並沒有被使用者設定為暫停(消費端限流)。
- 當前消費者針對該佇列有有效的拉取偏移量。
程式碼@2:該分支是處理正常返回的相關邏輯。其關鍵點如下:
- 如果當前針對該佇列的消費位移 與 發起 fetch 請求時的 偏移量不一致,則認為本次拉取非法,直接返回 null ,如程式碼@21。
- 從返回結構中獲取本次拉取的資料,使用資料迭代器,其基本資料單位為 RecordBatch,即一個傳送批次,如程式碼@22。
- 如果返回結果中沒有包含至少一個批次的訊息,但是 sizeInBytes 又大於0,則直接丟擲錯誤,根據服務端的版本,其錯誤資訊有所不同,但主要是建議我們如何處理,如果 broker 的版本低於 0.10.1.0,則建議升級 broker 版本,或增大客戶端的 fetch size,這種錯誤是因為一個批次的訊息已經超過了本次拉取允許的最大拉取訊息大小,如程式碼@23。
- 依次更新消費者本地關於該佇列的訂閱快取資訊的 highWatermark、logStartOffset、lastStableOffset。
從程式碼@3到@8 是多種異常資訊的處理。
程式碼@3:如果出現如下3種錯誤碼,則使用 debug 列印錯誤日誌,並且向服務端請求元資料並更新本地快取。
- NOT_LEADER_FOR_PARTITION
請求的節點上不是該分割槽的 Leader 分割槽。 - REPLICA_NOT_AVAILABLE
該分割槽副本之間無法複製 - KAFKA_STORAGE_ERROR
儲存異常。
Kafka 認為上述錯誤是可恢復的,而且對消費不會造成太大影響,故只是用 debug 列印日誌,然後更新本地快取即可。
程式碼@4:如果出現 UNKNOWN_TOPIC_OR_PARTITION 未知主題與分割槽時,則使用 warn 級別輸出錯誤日誌,並更新元資料。
程式碼@5:針對 OFFSET_OUT_OF_RANGE 偏移量超過範圍異常的處理邏輯,其實現關鍵點如下:
- 如果此次拉取的開始偏移量與消費者本地快取的偏移量不一致,則丟棄,說明該訊息已過期,列印錯誤日誌。
- 如果此次拉取的開始偏移量與消費者本地快取的偏移量一致,說明此時的偏移量非法,如果有配置重置偏移量策略,則使用重置偏移量,否則丟擲 OffsetOutOfRangeException 錯誤。
程式碼@6:如果是 TOPIC_AUTHORIZATION_FAILED 沒有許可權(ACL)則丟擲異常。
程式碼@7:如果本次拉取的結果不是NONE(成功),並且是可恢復的,將該佇列的訂閱關係移動到消費者快取列表的末尾。如果成功,則返回拉取到的分割槽資料,其封裝物件為 PartitionRecords。
接下來我們再來看看 2.1.1 fetchedRecords 中的另外一個核心方法。
2.2.1.2 fetchRecords()
在介紹該方法之前同樣先來看一下引數 PartitionRecords 的內部結構。
1、PartitionRecords 類圖

主要的核心屬性如下:
- TopicPartition partition
分割槽資訊。 - CompletedFetch completedFetch
Fetch請求完成結果 - Iterator<? extends RecordBatch> batches
本次 Fetch 操作獲取的結果集。 - Set< Long> abortedProducerIds
與事物相關,後續會專門的章節詳細介紹。 - PriorityQueue<FetchResponse.AbortedTransaction> abortedTransactions
與事物相關,後續會專門的章節詳細介紹。 - int recordsRead
已讀取的記錄條數。 - int bytesRead
已讀取的記錄位元組數。 - RecordBatch currentBatch
當前遍歷的批次。 - Record lastRecord
該迭代器最後一條訊息。 - long nextFetchOffset
下次待拉取的偏移量。
2、fetchRecords 詳解
private List<ConsumerRecord<K, V>> fetchRecords(PartitionRecords partitionRecords, int maxRecords) {
if (!subscriptions.isAssigned(partitionRecords.partition)) { // @1
// this can happen when a rebalance happened before fetched records are returned to the consumer's poll call
log.debug("Not returning fetched records for partition {} since it is no longer assigned",
partitionRecords.partition);
} else if (!subscriptions.isFetchable(partitionRecords.partition)) { // @2
// this can happen when a partition is paused before fetched records are returned to the consumer's
// poll call or if the offset is being reset
log.debug("Not returning fetched records for assigned partition {} since it is no longer fetchable",
partitionRecords.partition);
} else {
long position = subscriptions.position(partitionRecords.partition); // @3
if (partitionRecords.nextFetchOffset == position) { // @4
List<ConsumerRecord<K, V>> partRecords = partitionRecords.fetchRecords(maxRecords);
long nextOffset = partitionRecords.nextFetchOffset;
log.trace("Returning fetched records at offset {} for assigned partition {} and update " +
"position to {}", position, partitionRecords.partition, nextOffset);
subscriptions.position(partitionRecords.partition, nextOffset);
Long partitionLag = subscriptions.partitionLag(partitionRecords.partition, isolationLevel);
if (partitionLag != null)
this.sensors.recordPartitionLag(partitionRecords.partition, partitionLag);
Long lead = subscriptions.partitionLead(partitionRecords.partition);
if (lead != null) {
this.sensors.recordPartitionLead(partitionRecords.partition, lead);
}
return partRecords;
} else { // @5
// these records aren't next in line based on the last consumed position, ignore them
// they must be from an obsolete request
log.debug("Ignoring fetched records for {} at offset {} since the current position is {}",
partitionRecords.partition, partitionRecords.nextFetchOffset, position);
}
}
partitionRecords.drain();
return emptyList();
}程式碼@1:從 PartitionRecords 中提取訊息之前,再次判斷訂閱訊息中是否包含當前分割槽,如果不包含,則使用 debug 列印日誌,很有可能是發生了重平衡。
程式碼@2:是否允許拉取,如果使用者主動暫停消費,則忽略本次拉取的訊息。備註:Kafka 消費端如果消費太快,可以進行限流。
程式碼@3:從本地消費者快取中獲取該佇列已消費的偏移量,在傳送拉取訊息時,就是從該偏移量開始拉取的。
程式碼@4:如果本地快取已消費偏移量與從服務端拉回的起始偏移量相等的話,則認為是一個有效拉取,否則則認為是一個過期的拉取,該批訊息已被消費,見程式碼@5。如果是一個有效請求,則使用 sensors 收集統計資訊,並返回拉取到的訊息, 返回結果被封裝在 List<ConsumerRecord<K, V>> 。
2.2.2 sendFetches
“傳送” fetch 請求,注意這裡並不會觸發網路操作,而是組裝拉取請求,將其放入網路快取區。
Fetcher#sendFetches
```java
public synchronized int sendFetches() {
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests(); // @1
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) { // @2
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget()); // @3
client.send(fetchTarget, request) // @4
.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) { // @5
synchronized (Fetcher.this) {
@SuppressWarnings("unchecked")
FetchResponse<Records> response = (FetchResponse<Records>) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponse.PartitionData<Records>> entry :
response.responseData().entrySet()) {
TopicPartition partition = entry.getKey();
long fetchOffset = data.sessionPartitions().get(partition).fetchOffset;
FetchResponse.PartitionData<Records> fetchData = entry.getValue();
completedFetches.add(new CompletedFetch(partition, fetchOffset, fetchData, metricAggregator,
resp.requestHeader().apiVersion()));
} // @6
sensors.fetchLatency.record(resp.requestLatencyMs());
}
}
public void onFailure(RuntimeException e) { // @7
synchronized (Fetcher.this) {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
}
}
});
}
return fetchRequestMap.size();}
```java
上面的方法比較長,其實現的關鍵點如下:
程式碼@1:通過呼叫 Fetcher 的 prepareFetchRequests 方法按節點組裝拉取請求,將在後面詳細介紹。
程式碼@2:遍歷上面的待發請求,進一步組裝請求。下面就是分節點發送拉取請求。
程式碼@3:構建 FetchRequest 拉取請求物件。
程式碼@4:呼叫 NetworkClient 的 send 方法將其傳送到傳送快取區,本文不會詳細介紹網路方面的實現,但下文會截圖說明拉取請求傳送快取區的一個關鍵點。
程式碼@5:這裡會註冊事件監聽器,當訊息從 broker 拉取到本地後觸發回撥,即訊息拉取請求收到返回結果後會將返回結果放入到completedFetches 中(程式碼@6),這就和上文訊息拉取時 Fetcher 的 fetchedRecords 方法形成閉環。
程式碼@7:訊息拉取一次處理。
接下來詳細介紹 prepareFetchRequests 方法。
2.2.2.1 Fetcher prepareFetchRequests 方法詳解
private Map<Node, FetchSessionHandler.FetchRequestData> prepareFetchRequests() {
Map<Node, FetchSessionHandler.Builder> fetchable = new LinkedHashMap<>();
for (TopicPartition partition : fetchablePartitions()) { // @1
Node node = metadata.partitionInfoIfCurrent(partition).map(PartitionInfo::leader).orElse(null); // @2
if (node == null) { // @3
metadata.requestUpdate();
} else if (client.isUnavailable(node)) { // @4
client.maybeThrowAuthFailure(node);
log.trace("Skipping fetch for partition {} because node {} is awaiting reconnect backoff", partition, node);
} else if (client.hasPendingRequests(node)) { // @5
log.trace("Skipping fetch for partition {} because there is an in-flight request to {}", partition, node);
} else {
// if there is a leader and no in-flight requests, issue a new fetch
FetchSessionHandler.Builder builder = fetchable.get(node); // @7
if (builder == null) {
FetchSessionHandler handler = sessionHandler(node.id());
if (handler == null) {
handler = new FetchSessionHandler(logContext, node.id());
sessionHandlers.put(node.id(), handler);
}
builder = handler.newBuilder();
fetchable.put(node, builder);
}
long position = this.subscriptions.position(partition);
builder.add(partition, new FetchRequest.PartitionData(position, FetchRequest.INVALID_LOG_START_OFFSET,
this.fetchSize, Optional.empty()));
log.debug("Added {} fetch request for partition {} at offset {} to node {}", isolationLevel,
partition, position, node);
}
}
Map<Node, FetchSessionHandler.FetchRequestData> reqs = new LinkedHashMap<>();
for (Map.Entry<Node, FetchSessionHandler.Builder> entry : fetchable.entrySet()) {
reqs.put(entry.getKey(), entry.getValue().build());
}
return reqs;
}程式碼@1:首先通過呼叫 fetchablePartitions() 獲取可發起拉取任務的分割槽資訊,下文簡單介紹一下。
程式碼@2:如果該分割槽在客戶端本地快取中獲取該分割槽的 Leader 節點資訊。
程式碼@3:如果其 Leader 節點資訊為空,則發起更新元資料請求,本次拉取任務將不會包含該分割槽。
程式碼@4:如果客戶端與該分割槽的 Leader 連線為完成,如果是因為許可權的原因則丟擲ACL相關異常,否則列印日誌,本次拉取請求不會包含該分割槽。
程式碼@5:判斷該節點是否有掛起的拉取請求,即傳送快取區中是待發送的請求,如果有,本次將不會被拉取。
程式碼@6:構建拉取請求,分節點組織請求。
2.2.2.2 NetworkClient send 方法關鍵點
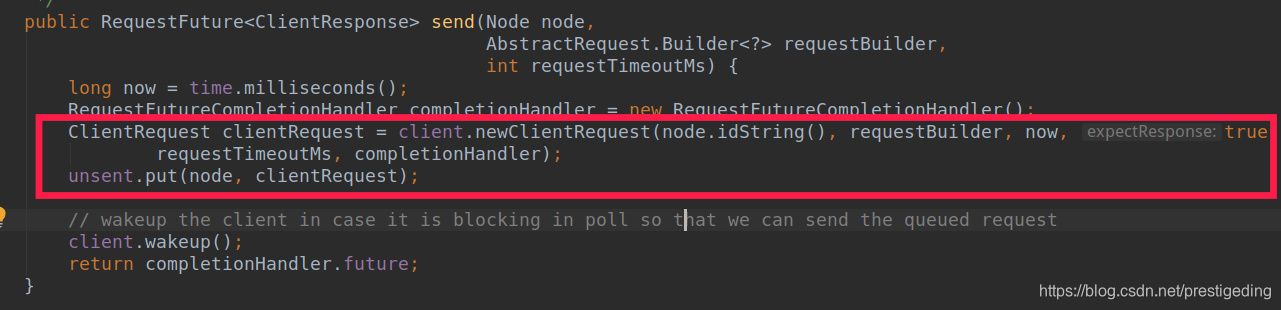
NetworkClient 的 send 方法只是將其放入 unsent 中。
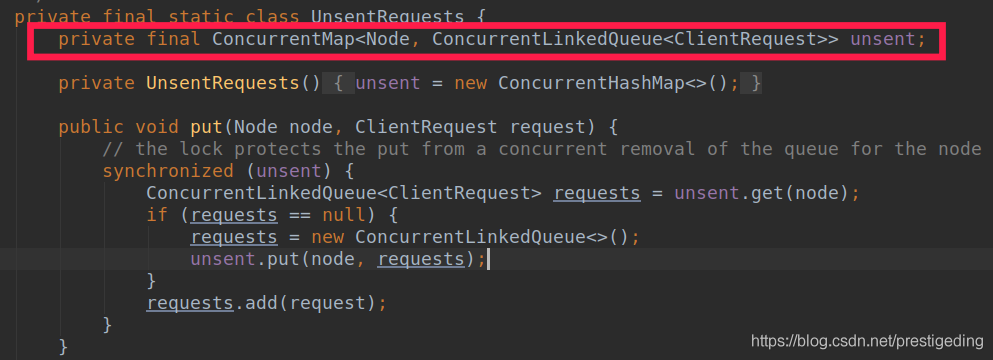
與上文的 client.hasPendingRequests(node) 方法遙相呼應。
3、總結
上面的原始碼分析有點長,也有點枯燥,我們還是畫一張流程圖來進行總結。
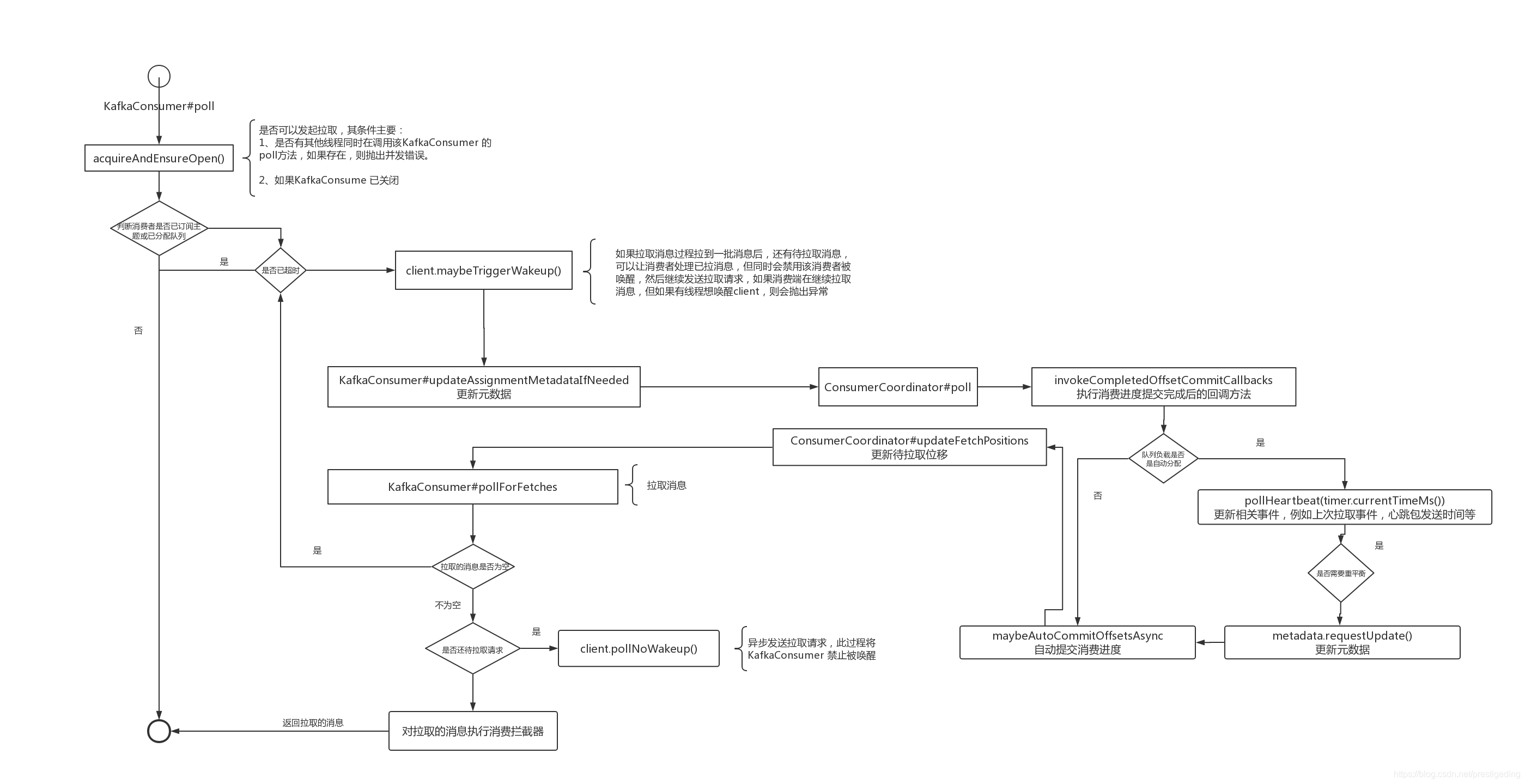
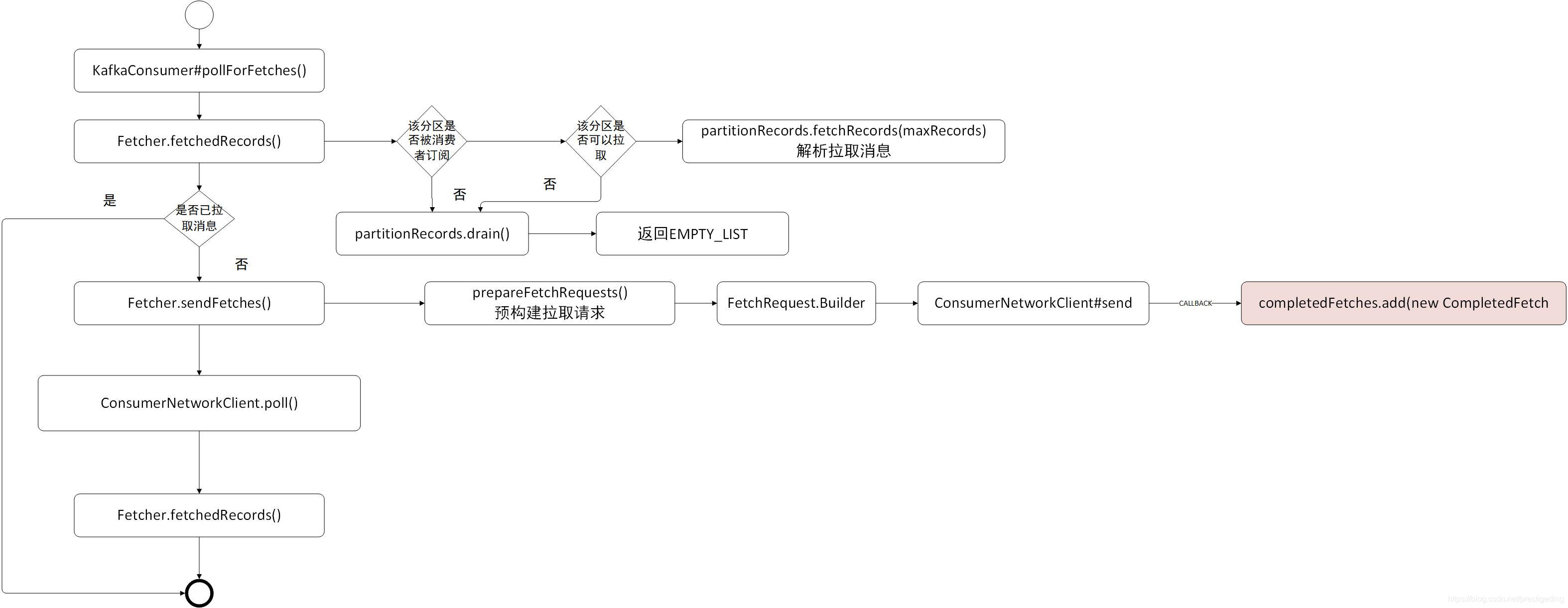
Kafka 的訊息拉取流程還是比較複雜的,後面會基於上述流程,重點進行拆解,例如消費進度提交,負載佇列重平衡等等。
作者介紹:
丁威,《RocketMQ技術內幕》作者,RocketMQ 社群佈道師,公眾號:中介軟體興趣圈 維護者,目前已陸續發表原始碼分析Java集合、Java 併發包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等原始碼專欄。歡迎加入我的知識星球,構建一個高質量的技術交流社群。
