
能快速理解Java_集合類_的文章
目錄
@ 這篇文章是我學習完Java集合類做的筆記和總結,如果你想認真細讀這篇文章,請做好受虐的準備(建議電腦看),因為這篇文章有點長,ヽ(ー_ー)ノ。 如果在看我這篇文章過程中,發現了錯誤,望指點。
一、什麼是集合?
舉個例子:當你有很多書時,你會考慮買一個書櫃,將你的書分門別類擺放進入。使用了書櫃不僅僅使房間變得整潔,也便於以後使用書時方便查詢。在計算機中管理物件亦是如此,當獲得多個物件後,也需要一個容器將它們管理起來,這個容器就是集合。
集合本質是基於某種資料結構資料容器。常見的資料結構:陣列(Array)、集(Set)、佇列(Queue)、連結串列(Linkedlist)、樹(Tree)、堆(Heap)、棧(Stack)和對映(Map)等結構。
下面便 一 . 一 介紹:
其中在兩大介面中會有框架圖,以方便大家學前、學後在大腦裡可以形成一個思維導圖,也方便大家檢查自己對各各知識點的熟悉程度。 注意: 由於在集合中是有一個引數化型別的,所以在下面的程式碼裡我會 指定成Object 。為什麼我要指定為Object呢?因為Java中的Object類是所有類的超類。 先涉及一下泛型的定義:集合類<引數化型別> 物件 = new 集合類<引數化型別> (); 也可以先前往 四、泛型,瞭解U•ェ•*U
二、Collection介面

1、集合類中Collection介面的介紹
首先了解一下Collection介面是List、Set、Queue等介面的父介面。 先簡單瞭解一下Collection介面的常用方法吧:
bollean add(Object obj) 向集合新增一個obj元素
void clear() 清空集合中所有元素
boolean isEmpty() 如果此集合為空,則返回turn
int size() 返回此集合中元素個數如果想了解其他方法可以查詢 Java基礎類庫(API) 這個是個好東西強烈推薦
下面先看看例題演示上面的方法吧:
import java.util.*; public class TestCollection{ public static void main(String[] args) { Collection<Object> coll = new ArrayList<Object>(); //建立集合 coll.add(1000); //新增集合 coll.add("phone"); System.out.println(coll); //列印集合coll System.out.println(coll.size()); //列印集合長度 Collection<Object> coll2 = new HashSet<Object>(); coll2.add(1000); coll2.add("phone"); System.out.println(coll2); //列印集合coll2 coll.clear(); //清空集合 System.out.println(coll.isEmpty()); //列印集合是否為空 } }
輸出的結果為:
[1000, phone]
2
[1000, phone]
true需要注意的是,在用Collection建立集合時是以實現類ArrayList的例項和實現類HashSet的例項來當做Collection來使用的。
Collection的簡單瞭解就到這裡。
2、List介面
特點:List介面能夠精確地控制每一個元素插入的位置,使用者可以通過索引來訪問集合中指定的元素,List還有一個特點就是元素的存入順序與取出順序相一致。
(1)、ArrayList實現類
其中ArrayList(效率高但執行緒不安全)是List的主要實現類,它是一個數組佇列,相當於動態陣列。通過下面例題了解:
import java.util.*;
public class TestArrayList{
public static void main(String[] args) {
ArrayList<Object> arr = new ArrayList<Object>(); //建立ArrayList集合
arr.add(1000); //向集合中新增元素
arr.add("phone");
System.out.println(arr.size()); //列印集合元素的個數
System.out.println(arr.get(0)); //取到並列印集合中指定索引的元素
}
}列印結果為:
2
1000雖然ArrayList的查詢效率很高,非常適合做大量的查詢操作,但不適合大量的增刪操作,所以為了解決這一問題就添加了LinkedList實現類
(2)、LinkedList實現類
建立了LinkedList集合後,便可使用以下方法(想了解更多請查詢JAVA基礎類庫):
void add(int index, Object o) 將o插入索引為index的位置
void addFirst(Object o) 將o插入集合的開頭
void addLast(Object o) 將o插入集合的結尾
Object removeFirst() 刪除並返回集合的第一個元素
Object removeLast() 刪除並返回集合的最後一個元素例題演示上面介紹的方法:
import java.util.*;
public class TestLinkedList{
public static void main(String[] args) {
LinkedList<Object> link = new LinkedList<Object>(); //建立LinkedList集合
link.add(1000);
link.add("phone");
System.out.println(link);
link.add(1,"charu"); //在索引1的位置,插入
System.out.println(link);
link.addFirst("stu"); //在集合首部新增元素
System.out.println(link);
System.out.println(link.removeLast()); //刪除並返回集合的最後一個元素
System.out.println(link);
}
}結果為:
[1000, phone]
[1000, charu, phone]
[stu, 1000, charu, phone]
phone
[stu, 1000, charu]由此可見,LinkedList對增加和刪除的操作高效且便捷
(3)、迭代器(Iterator)
既然我們已經儲存了很多元素,並且也做到了增與刪,但我們可不可以遍歷列印所以元素呢? 迭代器(Iterator) 它可以
建立了bianli的物件後,可以這樣使用迭代器(Iterator)
Iterator i = bianli.iterator(); //獲取Iterator物件
while(i.hasNext()){ //hasNext()方法檢測是否存在下一個元素
System.out.println(i.next()); //next()方法獲取元素,獲取條件必須是hasNext()方法判斷下一個元素存在,否則停止遍歷
}程式碼演示:
import java.util.*;
public class TestIterator{
public static void main(String[] args) {
Collection<Object> bianli = new ArrayList<Object>(); //建立LinkedList集合
bianli.add(2020);
bianli.add("新年快樂");
bianli.add("B站的跨年晚會");
bianli.add("很精彩");
Iterator<Object> i = bianli.iterator(); //獲取Iterator物件
while(i.hasNext()){ //hasNext()方法檢測是否存在下一個元素
System.out.println(i.next()); //next()方法獲取元素,獲取條件必須是hasNext()方法判斷下一個元素存在,否則停止遍歷
}
}
}但迭代器(Iterator)執行過於複雜且效能差,所以儘量別用。
(4)、for each迴圈
由於迭代器(Iterator)有些複雜,萬能的Java便又添加了for each迴圈,該迴圈能遍歷集合與陣列
語法格式:
for(容器中元素型別 臨時變數 : 容量變數){ //容量變數指的是1、陣列,則填儲存陣列名。2、集合,則填集合物件
程式語句
}for each有侷限性,因為臨時變數,所以只能進行訪問,而無法進行修改。
(5)、ListIterator介面
在 迭代器(Iterator) 中存在著無法解決併發執行操作的問題(併發操作:指在巨集觀上的同一時間內同時執行多個任務),其實就是在迭代器(Iterator)遍歷過程(while程式語句裡)中給集合新增元素,但由於Iterator介面不能很好地支援併發操作,從而出現執行出錯。
在java中為了解決這一問題便提供了,ListIterator介面來解決這一問題
語法格式與迭代器(Iterator)差不多
ListIterator 臨時變數 = 物件.listIterator();
(6)、Enumeration介面的古老實現類Vector
其實在沒有遍歷集合Iterator介面前,很古老的實用類Vector(執行緒安全但效率低),與Iterator介面類似,下面給大家瞭解一下Vector類,它提供了elements()方法用於返回Enumeration物件,然後通過Enumeration物件遍歷集合中的元素。
格式與介紹其hasMoreElements()、nextElement()兩個方法的使用
Enumeration ele = v.elements(); //獲得Enumeration物件
while(ele.hasMoreElements()){ //判斷ele物件是否仍有元素
Object o = ele.nextElement(); //取出ele的下一個元素
System.out.println(o);
}Vector是比較古老的集合類,瞭解一下就好。
當你看到這裡,你大概基本瞭解Collection介面的用法,當你把他們所有的關係寫成流程圖,你會發它們的關係非常有意思,比如:因為ArrayList集合由於不適合大量增刪操作,所以提供了LinkedList實現類來解決這一問題等等,會發現很多的方法都是建立在原來方法的問題上,用另外的方法去解決它。
3、Set介面
(1)、Set的簡單介紹和hashSet集合的使用
好,我們繼續瞭解一下Collection的另外一個子介面Set吧!!! Set集合中的元素是無序的、不可重複的。但這裡的無序性不等於隨機性,無序性指的是元素在底層儲存位置是無序的。
Set介面的主要實現類是HashSet和TreeSet。
下面來好好介紹一下吧。HashSet集合(它是按雜湊演算法來儲存集合中的元素的):
下面先了解一下例題程式碼吧:
import java.util.*;
public class TestHashSet{
public static void main(String[] args) {
Set<Object> set = new HashSet<Object> (); //建立HashSet集合
set.add(null); //向集合儲存元素
set.add(new String("JAVA"));
set.add("程式");
set.add("設計");
set.add("JAVA");
for(Object o : set) { //遍歷集合
System.out.println(o);
}
}
}列印結果:
null
JAVA
設計
程式可以看出按照存入順序應該是先列印 "程式" 再列印 "設計" 的,但結果不是,這證明了HashSet儲存的無序性;其中我們儲存了兩次"JAVA"但列印的只有一次,同樣也說明了HashSet元素的不可重複性。
(2)、雜湊的簡單介紹
可能有人會問為什麼不可重複呢?
這是因為HashSet底層是雜湊表結構,可能有人不懂“雜湊”是什麼?那我就簡單說一下吧。
雜湊和雜湊演算法,雜湊也稱雜湊,雜湊表是一種與陣列、連結串列等不同的資料結構,與他們需要不斷的遍歷比較來查詢的辦法,
雜湊表設計了一個對映關係f(key)= address,根據key來計算儲存地址address,這樣可以1次查詢,f既是儲存資料過程中
用來指引資料儲存到什麼位置的函式,也是將來查詢這個位置的演算法,叫做雜湊演算法。還是不懂!??那好吧,舉個栗子
你在家裡忘記了指甲刀放在哪裡,通常要在你家所有抽屜中順序尋找,直到找到,最差情況下,有N個抽屜,
你就要開啟N個抽屜。這種儲存方式叫陣列,查詢方法稱為「遍歷」。
而雜湊就不一樣了,所有物品分門別類放入整理箱,再將整理箱編號,比如1號放入針線,2號放入證件,3號放入細軟。這種儲存和查詢方式稱為「雜湊」,
如果這個時候要查詢護照,你不許要再翻所有抽屜,直接可在2號整理箱中獲取,通常只用一次查詢即可,如何編號整理箱,稱為雜湊演算法。因為hashCode()是算出一個值後,元素然後去找集合的位置,如果該位置沒有元素,則直接存入;但如果該位置有元素,則用equals()來 判斷是否相同,相同則不儲存,否則在該位置上儲存兩個元素(一般不可能重複),所以在一個自定義的物件想正確存入HashSet集合時,那麼應該重寫自定義物件的 hashCode() 和 equals()方法。
你是不是懵了,因為在剛才例題程式碼裡,不也沒有重寫嗎?為什麼還是能正常工作?那是因為String類會自動重寫hashCode()和equals()方法。
給你看看如果我不用String會是什麼情況呢?
import java.util.*;
public class TestHashSet{
public static void main(String[] args) {
Set<Object> set = new HashSet<Object>();
set.add(null);
set.add(new People("JAVA")); //沒有使用String
set.add("程式");
set.add("設計");
set.add("JAVA");
for(Object o : set) {
System.out.println(o);
}
}
}
class People{
String name;
int age;
public People(String name) {
this.name = name;
}
public String toString() {
return name ;
}
}列印結果為:
null
JAVA
JAVA
設計
程式結果很明顯一樣是都列印了,那要解決這一問題要怎麼做呢? 要想解決這一問題,只需要在People類中新增:
public int hashCode(){
通過計算(因為雜湊演算法可以隨意設計,想怎麼算都可以),返回物件的雜湊值
}
public boolean equals(Object obj){
與各各不同型別的物件判斷是否相同,返回為false時,則儲存
}就可以了;HashSet集合就說到這裡。
(3)、TreeSet集合
TreeSet底層是用自平衡的排序二叉樹實現的,所以它既能保證元素的唯一性,又可以對元素進行排序。還提供了一些特有的方法:
import java.util.*;
public class TestTreeSet{
public static void main(String[] args) {
TreeSet<Object> tree = new TreeSet<Object>();
tree.add(1);
tree.add(7);
tree.add(18);
System.out.println(tree); //列印集合
System.out.println(tree.first()); //列印集合中第一個元素 last列印最後一個元素
System.out.println(tree.subSet(5, 20)); //列印集合中大於5小於20的元素
System.out.println(tree.headSet(10)); //列印小於10的元素;tailSet大於
}
}列印結果:
[1, 7, 18]
1
[7, 18]
[1, 7]其中Tree有兩種排序方法:自然排序(預設條件下)與定製排序。 預設排序便不多說,知道有一個方法compareTo(Object obj) 是用來比較元素之間的大小關係,例如:obj1.compareTo(obj2),若方法返回0,則相等;若方法返回正整數,則說明obj1大於obj2;若方法返回負整數,則說明obj1小於obj2.
而定製排序。。。。。emmmm其實就是繼承了Comparator介面後,在自定義的子介面中實現一個campare方法,通過返回正負整數還有零,來進行排序, 從而可以達到降序排列等定製排序的目的。
Set介面就說到這裡。
4、Queue介面
下面我們來了解Collection介面的最後一個子介面Queue。 Queue用於模擬佇列這種資料結構,佇列通常是指"先進先出"(FIFO)的容器。
Queue介面有一個PriorityQueue實現類,除此之外,還有一個介面Deque(代表一個"雙端佇列",雙端佇列可以同時從兩端來新增、刪除元素)。Deque可以在佇列、棧(該類裡的棧包含pop(出棧)、push(入棧)兩個方法)中使用,並且提供了實現類ArrayDeque。
(1)、Priority Queue實現類
Priority Queue實現類是一個比較標準的佇列,為什麼說比較標準?因為儲存的元素不是按加入順序,而是按大小排序。
下面我們來看例題程式碼:
import java.util.PriorityQueue;
public class TestPriorityQueue{
public static void main(String[] args) {
PriorityQueue<Object> pq = new PriorityQueue<Object>();
pq.offer(10);
pq.offer(1);
pq.offer(100);
System.out.println(pq);
System.out.println(pq.remove()); //Queue的方法,remove()獲取佇列頭部的元素,並刪除該元素
System.out.println(pq);
}
}列印結果:
[1, 10, 100]
1
[10, 100]可以看出PriorityQueue比較標準的排序和一些Queue簡單的方法(如要了解更多請查閱Java基礎類包),注意:PriorityQueue不允許插入null元素
PriorityQueue也有兩種排序方式:
1、是自然排序
2、是定製排序
排序要求與TreeSet集合一致
繼續瞭解Queue的另外的介面Deque與ArrayDeque實現類
Deque的方法眾多,我便不進行講解,因為方法的作用與前面所說的差不多,只是方法名不同罷了,其中講一下ArrayDeque實現類比較特殊的方法,看程式碼:
import java.util.ArrayDeque;
public class TestArrayDequeStack{
public static void main(String[] args) {
ArrayDeque<Object> stack = new ArrayDeque<Object>();
stack.push("廣東"); //依次將三個元素push入"棧"
stack.push("培正");
stack.push("學院");
System.out.println(stack); //因為是棧的緣故(先進後出),所以存入的元素順序越靠前,在元素安排上越往後
System.out.println(stack.peek()); //訪問第一個元素,但並不將其pop出棧;Queue方法peek()獲取佇列頭部元素,但是不刪除該元素。如果佇列為空,則返回null
System.out.println(stack);
System.out.println(stack.pop()); //pop出第一個元素
System.out.println(stack);
}
}列印結果為:
[學院, 培正, 廣東]
學院
[學院, 培正, 廣東]
學院
[培正, 廣東]從結果可以看出,ArrayDeque有棧的行為("棧"嘛,先進後出,先存入的越往後放),所以當程式中需要所以“棧”這種資料結構時,便可使用。
其中給大家瞭解一下,雖然Stack也可以作出棧的行為(是以普通方法的形式進行使用的),但儘量避免使用Stack,因為Stack是古老的集合,效能較差。
當然不能忘了ArrayDeque也可以作為佇列中使用,只需要在上面的例題程式碼中,把push修改為offer(boolean offer(Object e)方法將指定元素加入佇列尾部。當使用有容量限制的佇列時,此方法通常比add(Object e)方法更好)即可。
學習到這裡,也把Collection介面的相關知識也瞭解了,那我問幾個問題供你思考。 1、Set介面和List介面有哪些區別? List是有序的可重複的Collection,使用此介面能夠精確的控制每個元素插入的位置。能夠使用索引高效地訪問List中的元素,這類似於Java的陣列。Set是一種無序的不包含重複元素的Collection,相比List,它可以更高效地處理增添和刪除元素。
2、Iterator(迭代器)和ListIterator介面的區別是什麼? Iterator可用來遍歷Set和List集合,但是ListIterator只能用來遍歷List。Iterator對集合只能是前向遍歷,ListIterator既可以前向也可以後向。ListIterator實現了Iterator介面,幷包含其他的功能,比如:增加元素,替換元素,獲取前一個和後一個元素的索引等。
3、Enumeration介面和Iterator介面的區別有哪些? Enumeration速度是Iterator的2倍,同時佔用更少的記憶體。但是,Iterator遠遠比Enumeration安全,因為其他執行緒不能夠修改正在被iterator遍歷的集合裡面的物件。同時,Iterator允許呼叫者刪除底層集合裡面的元素,這對Enumeration來說是不可能的。
終於把Collection的介面以及子介面List、Set、Queue記錄完了。
你以為完了,天真!!!接下來繼續記錄Map介面吧!??
三、Map介面
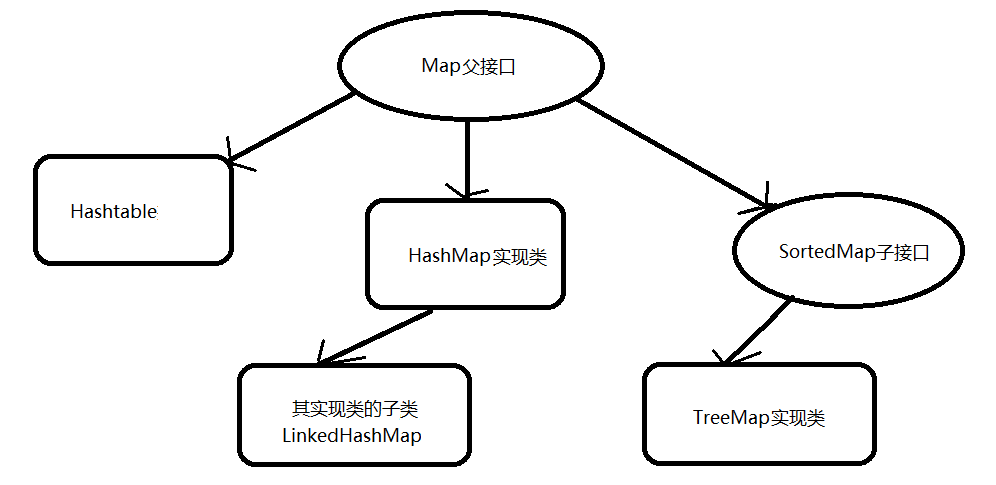
先給大家講一下什麼是對映:對映,或者射影,在數學及相關的領域還用於定義函式。函式是從非空數集到非空數集的對映,而且只能是一對一對映或多對一對映。而在這裡主要是說每一個指定的鍵(key)總能找到唯一的、確定的值(value),存在單向一對一關係。
Map與Collection介面是並列存在的,它是用於儲存鍵--值對(key-value)形式的元素,描述了由不重複的鍵到值的對映。(其中鍵-值可以是任何引用型別的資料)。因為不可重複性,所以在同一個Map物件所對應的類,必須重寫hashCosh()方法和equals()方法。
Map介面的方法有很多,我們瞭解最常用的兩個方法便可:
Object put(Object key, Object value) 功能:將指定的值與此對映中的指定鍵關聯(可選操作)
Object get(Object key) 功能:返回指定鍵所對映的值;如果此對映不包含該鍵的對映關係,則返回null。1、HashMap實現類
當然Map的實現類也很多,但最常用的是HashMap類和TreeMap類,接下來詳細講解一下:
HashMap類可以說是Map介面中使用頻率最高的實現類,允許使用null鍵和null值,與前面的HashSet集合一樣,不保證對映的順序,判斷兩個鍵(key)是否相同,同樣是使用equals()方法,若返回true,則hashCode(雜湊)值也相等。
import java.util.*;
public class TestHashMap{
public static void main(String[] args) {
Map<Object, Object> map = new HashMap<Object, Object>(); //建立HashMap集合
map.put("one", "廣東"); //存入元素
map.put("two", "培正");
map.put("three", "學院");
map.put("four", "數科院");
map.put(null, null);
map.put("four", "資料科學與計算機學院"); //體現HashMap集合的不可重複性
System.out.println(map.size()); //列印集合長度
System.out.println(map); //列印集合所有元素
System.out.println(map.get("two")); //取出並列印鍵為two的值
}
}列印結果:
5
{null=null, four=資料科學與計算機學院, one=廣東, two=培正, three=學院}
培正相信大家看了上面的例題程式碼,會發現和HashSet集合一樣,結果具有無序性;同時也發現若出現相同的鍵(key) 時,後新增的值(value)會覆蓋先新增的值(value).
(1)、Map的遍歷
既然我們集合添加了元素,當然就要一 一遍歷出來啦,在之前說了遍歷List和for each,但Map遍歷方式有所不同,其中遍歷方式有兩種,先說說第一種吧。 因為Map是關於鍵與值的關係,所以遍歷當然離不開它們,看下面例題程式碼:
import java.util.*;
public class TestKeySet{
public static void main(String[] args) {
Map<Object, Object> map = new HashMap<Object, Object>(); //建立HashMap集合
map.put("one", "廣東"); //存入元素
map.put("two", "培正");
map.put("three", "學院");
map.put("four", "數科院");
System.out.println(map); //列印集合所有元素
Set<Object> keySet = map.keySet(); //獲取鍵的集合,keySet()方法可以獲取鍵的集合
Iterator<Object> iterator = keySet.iterator(); //獲取迭代器物件
while(iterator.hasNext()) {
Object key = iterator.next();
Object value = map.get(key);
System.out.println(key + ":" + value);
}
}
}列印結果為:
{four=數科院, one=廣東, two=培正, three=學院}
four:數科院
one:廣東
two:培正
three:學院相信大家已初步瞭解第一種遍歷,廢話不多說,繼續第二種遍歷,第二種遍歷的方式是:先獲得集合中所有的對映關係,然後從對映關係獲取鍵和值。看例題程式碼:
import java.util.*;
import java.util.Map.Entry;
public class TestEntrySet{
public static void main(String[] args) {
Map<Object, Object> map = new HashMap<Object, Object>(); //建立HashMap集合
map.put("one", "廣東"); //存入元素
map.put("two", "培正");
map.put("three", "學院");
map.put("four", "數科院");
System.out.println(map); //列印集合所有元素
Set<Entry<Object, Object>> entrySet = map.entrySet(); //entrySet()方法:返回此對映所包含的對映關係
Iterator<Entry<Object, Object>> iterator = entrySet.iterator(); //獲取迭代器物件
while(iterator.hasNext()) {
Map.Entry<Object, Object> entry = (Entry<Object, Object>) iterator.next();
Object key = entry.getKey(); //獲取關係中的鍵
Object value = entry.getValue(); //獲取關係中的值
System.out.println(key + ":" + value);
}
}
}列印結果為:
{four=數科院, one=廣東, two=培正, three=學院}
four:數科院
one:廣東
two:培正
three:學院看完兩種遍歷方式會發現,Map的遍歷都是圍繞著鍵(key)和值(value)它們單向一 一對應的關係。但我們前面有說能不用迭代器(Iterator)就不要用,因為這種方式複雜且效能差,所以給大家介紹一下用for each迴圈的使用:
import java.util.*;
public class Testforeach{
public static void main(String[] args) {
Map<Object, Object> map = new HashMap<Object, Object> ();
map.put(1,"2020");
map.put(2,"新起點");
map.put(3,"新開始");
Set<Map.Entry<Object, Object>> entries = map.entrySet(); //entrySet()方法:返回此對映所包含的對映關係,給方式一和方式二用
System.out.println("方式一:"); //第一種:在for each迴圈中直接列印鍵與值的關係
for(Map.Entry<Object, Object> entry : entries) {
System.out.println(entry);
}
System.out.println("方式二:"); //第二種:與第一種的列印方式不同,是分別獲取有關係的鍵和有關係的值,再列印
for(Map.Entry<Object, Object> entry : entries) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
System.out.println("方式三:"); //第三種:是獲取了鍵的集合,在列印相對應的值
Set<Object> objects = map.keySet();
for(Object object : objects) {
System.out.println(object + ":" + map.get(object));
}
}
}是否發現for each迴圈更簡單更高效呢。
(2)、子類LinkedHashMap
emmmm遍歷就說到這裡,下面我們繼續來了解HashMap的一個子類LinkedHashMap,其中該類的主要作用是:可以維護Map的迭代器順序,迭代順序與鍵-值對的插入順序一致。簡單地說:就是列印的結果可以不是無序的了,可以按照怎麼輸入就怎麼輸出了。來看程式碼:
import java.util.*;
public class TestLinkedHashMap{
public static void main(String[] args) {
Map<Object, Object> map = new LinkedHashMap<Object, Object>(); //建立LinkedHashMap集合
map.put("one", "廣東"); //新增元素
map.put("two", "培正");
map.put("three", "學院");
map.put("four", "數科院");
System.out.println(map); //列印集合所有元素
}
}列印結果為:
{one=廣東, two=培正, three=學院, four=數科院}所以只要建立了LinkedHashMap集合就可以列印輸入順序了。
2、TreeMap實現類
下面我們來了解一下,Map第二個常用的類TreeMap吧。
既然前面的TreeSet可以排序,當然這個也可以啦,只需要建立TreeMap集合,便可以預設的進行自然排序,當然在新增元素時要有資料型,不然如何比較排序呢。
有預設當然就要有可以根據自己的需求來排序邏輯,以前面的相同,都是用到int compareTO(T t1, T t2) 方法返回正負零值,然後根據大小進行邏輯排序。
(1)、古老的實現類Hashtable與其子類Properties
前面都說有古老的、執行緒安全的實現類,Map當然也不會少,它有一個與HashMap集合幾乎相同,有不同的是它不允許使用null作為鍵和值,而它就是Hashtable類,由於它存取速度慢,目前基本被HashMap取代,所以我們瞭解一下有這個東西便好,但其中Hashtable類有一個子類Properties在實際開發中很常用,所以現在我們來理解一下這個Properties集合。
現在我們先了解其作用:Properties集合是用於處理屬性檔案,因為屬性檔案裡的鍵和值都是字串,所以Properties類裡的鍵和值也字串型別。
Properties類的方法有很多,我們瞭解它最常用的便好。
String getProperty(String key) 功能:可以根據屬性檔案(配置檔案)中屬性的鍵,獲取對應屬性的值。看看例題程式碼吧:
import java.io.FileOutputStream;
import java.util.Properties;
public class TestProperties{
public static void main(String[] args) throws Exception {
Properties pro = new Properties(); //建立Properties物件
pro.setProperty("username", "mouse"); //向Properties中新增屬性
pro.setProperty("password", "2020");
pro.store(new FileOutputStream("test.ini"),"title"); //將Properties中的屬性儲存到test.ini中
}
}程式執行後,會在當前資料夾目錄中生成一個test.ini檔案,內容如下:
#title
#Mon Dec 30 11:19:14 CST 2019
password=2020
username=mouse在實際開發中通常用這種方式處理屬性檔案。
雖然說是這麼說,不知道你們有沒有和我一樣的疑問?Properties類可以處理屬性檔案,那然後呢?我拿這個屬性檔案能幹什麼?
據目前瞭解,它可以與資料庫相關聯、框架也有時需要,並且在日後一個專案放到生產環境,在開發維護過程中,如果有些地方需要修改,維護人員更改配置檔案重啟就OK了;不然在程式碼中進行修改,會累成狗的。
好,終於集合類的兩個重要介面Collection和Map的介紹告一段落了。 到這裡當然要有個小問題供大家思考了┗( ▔, ▔ )┛
Collection介面和Map介面的主要區別是什麼? Collection和Map介面之間的主要區別在於:Collection中儲存了一組物件,而Map儲存關鍵字/值對。
可以看看這個博主的記錄,裡面包含了Collection介面、Map介面的總結和區別。轉載: 我用CSDN這個app發現了有技術含量的部落格,小夥伴們求同去《Collection和map的區別》,, 一起來圍觀吧 ! ! !
四、泛型
使用泛型的好處:它提供了編譯期的型別安全,確保你只能把正確型別的物件放入集合中,避免了在執行時出現ClassCastException。程式的可讀性和健壯性更高。
泛型: 這位博主的泛型講解的非常好,轉載: 我用CSDN這個app發現了有技術含量的部落格,小夥伴們求同去《小白都能看得懂的java泛型》,一起來圍觀吧!!!
五、兩個工具類
接下來的內容,在我看來會模仿會用就行,所以就看看吧!
給大家介紹一下集合的兩個工具類:Collection和Arrays. 瞭解會用就可以了。
1、Collections工具類
Collections工具類:適用於List集合的排序靜態方法
static void reverse(List list) 將list集合元素順序反轉
static void shuffle(List list) 將list集合隨機排序
static void sort(List list) 將list集合根據元素自然順序排序
static void swap(List list, int i, int j) 將list集合中的i處元素與j處元素交換下面程式碼演示這些方法:
import java.util.*;
public class TestCollections{
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
System.out.println(list); //列印集合
Collections.reverse(list); //反轉集合
System.out.println(list);
Collections.shuffle(list); //隨機排序
System.out.println(list);
Collections.sort(list); //按自然順序排序
System.out.println(list);
Collections.swap(list, 1, 3); //將索引為1的元素和索引為3的元素交換位置,索引也是從0開始的
System.out.println(list);
}
}結果為:
[1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
[4, 1, 5, 2, 3]
[1, 2, 3, 4, 5]
[1, 4, 3, 2, 5]工具嘛,知道怎麼拿來用就行。Collections工具類除了對List集合的排序外,還可以對集合進行查詢和替換,其方法為:
static int binarySearch(List list, Object o) 使用二分法搜尋o元素在list集合中的索引,查詢的list集合中元素必須是有序的
static Object max(Collection coll) 根據元素自然順序,返回coll集合中最大的元素
static Object min(Collection coll) 根據元素自然順序,返回coll集合中最小的元素
static boolean replaceAll(List list, Object o1, Object o2) 用o2元素替換list集合中所有的o1元素
int frequency(Collection coll, Object o) 返回coll集合中,o元素出現的次數方法的使用:
import java.util.*;
public class TestCollections{
public static void main(String[] args) {
List list = new ArrayList(5);
list.add(11);
list.add(22);
list.add(33);
list.add(44);
list.add(55);
System.out.println(Collections.binarySearch(list, 33)); //列印元素33在list集合中的索引
System.out.println("集合中的最大元素:" + Collections.max(list));
System.out.println("集合中的最小元素:" + Collections.min(list));
Collections.replaceAll(list, 33, 11); //在集合中list中,用元素11替代元素33
System.out.println(Collections.frequency(list, 11)); //列印集合中元素11出現的次數,在查詢最大最小時,11查了兩次
}
}結果為:
2
集合中的最大元素:55
集合中的最小元素:11
2Collections還提供了對集合設定不可變、對集合物件實現同步控制等方法,有興趣可以通過Java基礎類庫查詢。
這些工具類會使用就好,繼續來講Array工具類。
2、Array工具類
Array是陣列工具類,具體方法為:
static void sort(Object[] arr) 將arr陣列元素按自然順序排序
static int binarySearch(Object[] arr,Object o) 用二分搜尋法搜尋元素o在arr陣列中索引
static fill(Object[] arr,Object o) 將arr陣列中所有元素替換為o元素
static String toString(Object[] arr) 將arr陣列轉換為字串
static object[] copyOfRange(Object[] arr,int i,int j) 將arr陣列索引從i到j-1的j-i個元素複雜到一個新陣列,不足的元素預設為0方法演示:
import java.util.*;
public class TestArrays{
public static void main(String[] args) {
int arr[] = new int[] {3, 5, 2, 4, 1}; //建立陣列初始化內容
System.out.println(Arrays.binarySearch(arr, 2)); //列印元素2在陣列arr中的索引
Arrays.sort(arr); //對arr陣列按自然順序排列
for(int a : arr) {
System.out.print(a);
}
System.out.println();
System.out.println(Arrays.toString(arr)); //將陣列轉換為字串並列印
int arr2[] = Arrays.copyOfRange(arr, 2, 9); //將arr[2]之後的元素複製到陣列arr2中並列印,不足的元素預設為0
for(int a : arr2) {
System.out.print(a);
}
}
}結果為:
2
12345
[1, 2, 3, 4, 5]
3450000Arrays工具類一樣還有很多方法,有興趣的可以查閱Java基礎類庫。
3、集合轉換
最後我們瞭解一下集合轉換: 首先是集合轉換為陣列,程式碼演示:
import java.util.*;
public class TestCollectionToArray{
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(3);
list.add(2);
Object[] array = list.toArray(); //將集合轉換為陣列
for(Object object : array) {
System.out.print(object + "\t");
}
}
}結果為:
1 3 2其次是陣列轉換為集合,程式碼演示:
import java.util.*;
public class TestArrayToList{
public static void main(String[] args) {
String arr[] = new String[] {"1","3","2"};
List list = Arrays.asList(arr); //將陣列轉換為集合
System.out.println(list);
}
}結果為:
[1, 3, 2]需要注意的是,如果陣列是int[]型別,應該先把int[]轉換為Integer[],因為asList(Object[] arr)方法的引數必須是物件。
問:Collection介面與Collections工具類有什麼區別? Collection是集合類的上級介面,繼承於他的介面主要有Set和List,Collections是針對集合類的一個幫助類,他提供一系列靜態方法實現對各種集合的搜尋、排序、執行緒安全化等操作。
通過上面的學習,相信已經能夠掌握Java集合框架的相關知識,我也相信這篇文章有一定的瑕疵,畢竟是一個Java小白學習完集合類後所記錄的筆記,希望大家發現問題後能提出來,Thanks♪(・ω・)ノ。 我的java集合類的筆記就到這裡,O(∩_∩)O哈