
Netty之緩衝區ByteBuf解讀(一)

Netty 在資料傳輸過程中,會使用緩衝區設計來提高傳輸效率。雖然,Java 在 NIO 程式設計中已提供 ByteBuffer 類進行使用,但是在使用過程中,其編碼方式相對來說不太友好,也存在一定的不足。所以高效能的 Netty 框架實現了一套更加強大,完善的 ByteBuf,其設計理念也是堪稱一絕。
ByteBuffer 分析
在分析 ByteBuf 之前,先簡單講下 ByteBuffer 類的操作。便於更好理解 ByteBuf 。
ByteBuffer 的讀寫操作共用一個位置指標,讀寫過程通過以下程式碼案例分析:
// 分配一個緩衝區,並指定大小 ByteBuffer buffer = ByteBuffer.allocate(100); // 設定當前最大快取區大小限制 buffer.limit(15); System.out.println(String.format("allocate: pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity())); String content = "ytao公眾號"; // 向緩衝區寫入資料 buffer.put(content.getBytes()); System.out.println(String.format("put: pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));
其中列印了緩衝區三個引數,分別是:
- position 讀寫指標位置
- limit 當前快取區大小限制
- capacity 緩衝區大小
列印結果:
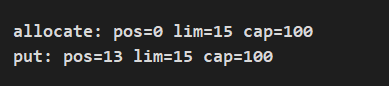
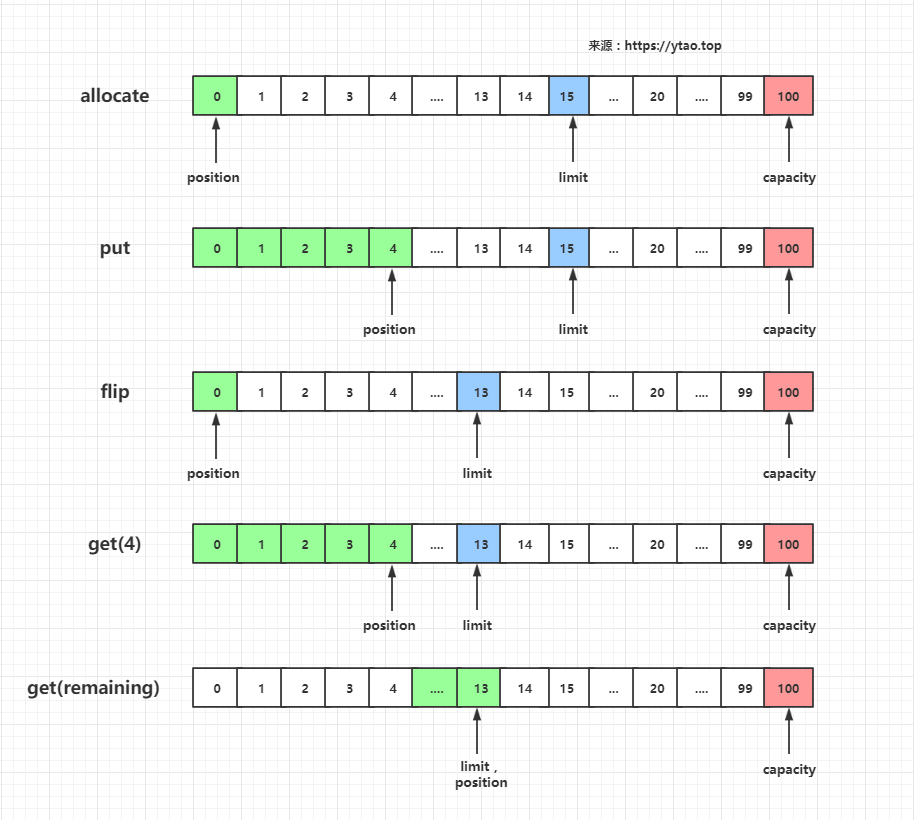
當我們寫入內容後,讀寫指標值為 13,ytao公眾號英文字元佔 1 個 byte,每個中文佔 4 個 byte,剛好 13,小於設定的當前緩衝區大小 15。
接下來,讀取內容裡的 ytao 資料:
buffer.flip(); System.out.println(String.format("flip: pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity())); byte[] readBytes = new byte[4]; buffer.get(readBytes); System.out.println(String.format("get(4): pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity())); String readContent = new String(readBytes); System.out.println("readContent:"+readContent);
讀取內容需要建立個 byte 陣列來接收,並制定接收的資料大小。
在寫入資料後再讀取內容,必須主動呼叫ByteBuffer#flip或ByteBuffer#clear。
ByteBuffer#flip它會將寫入資料後的指標位置值作為當前緩衝區大小,再將指標位置歸零。會使寫入資料的緩衝區改為待取資料的緩衝區,也就是說,讀取資料會從剛寫入的資料第一個索引作為讀取資料的起始索引。
ByteBuffer#flip相關原始碼:
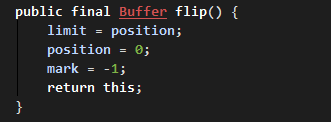
ByteBuffer#clear則會重置 limit 為預設值,與 capacity 大小相同。

接下讀取剩餘部分內容:
第二次讀取的時候,可使用buffer#remaining
limit - position,所以當前緩衝區域一定在這個值範圍內。
readBytes = new byte[buffer.remaining()];
buffer.get(readBytes);
System.out.println(String.format("get(remaining): pos=%s lim=%s cap=%s", buffer.position(), buffer.limit(), buffer.capacity()));列印結果:

以上操作過程中,索引變化如圖:
ByteBuf 讀寫操作
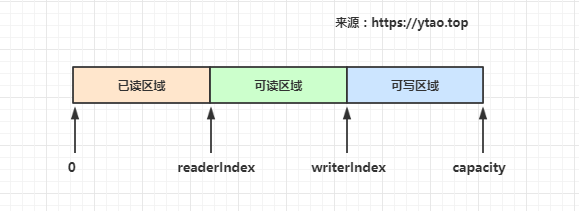
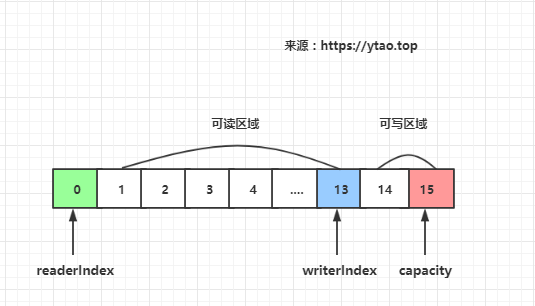
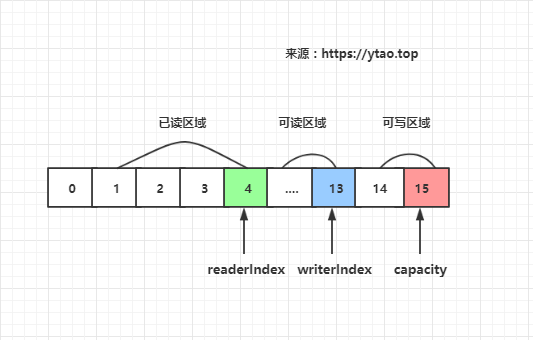
ByteBuf 有讀寫指標是分開的,分別是buf#readerIndex和buf#writerIndex,當前緩衝器大小buf#capacity。
這裡緩衝區被兩個指標索引和容量劃分為三個區域:
- 0 -> readerIndex 為已讀緩衝區域,已讀區域可重用節約記憶體,readerIndex 值大於或等於 0
- readerIndex -> writerIndex 為可讀緩衝區域,writerIndex 值大於或等於 readerIndex
- writerIndex -> capacity 為可寫緩衝區域,capacity 值大於或等於 writerIndex
如下圖所示:
分配緩衝區
ByteBuf 分配一個緩衝區,僅僅給定一個初始值就可以。預設是 256。初始值不像 ByteBuffer 一樣是最大值,ByteBuf 的最大值是Integer.MAX_VALUE
ByteBuf buf = Unpooled.buffer(13);
System.out.println(String.format("init: ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));列印結果:

寫操作
ByteBuf 寫操作和 ByteBuffer 類似,只是寫指標是單獨記錄的,ByteBuf 的寫操作支援多種型別,有以下多個API:
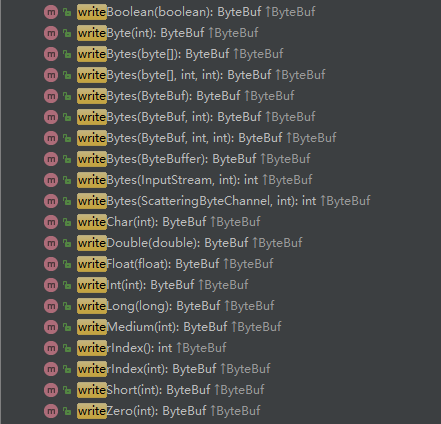
寫入位元組陣列型別:
String content = "ytao公眾號";
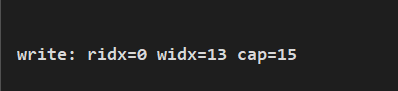
buf.writeBytes(content.getBytes());
System.out.println(String.format("write: ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));列印結果:
索引示意圖:
讀操作
一樣的,ByteBuf 寫操作和 ByteBuffer 類似,只是寫指標是單獨記錄的,ByteBuf 的讀操作支援多種型別,有以下多個API:
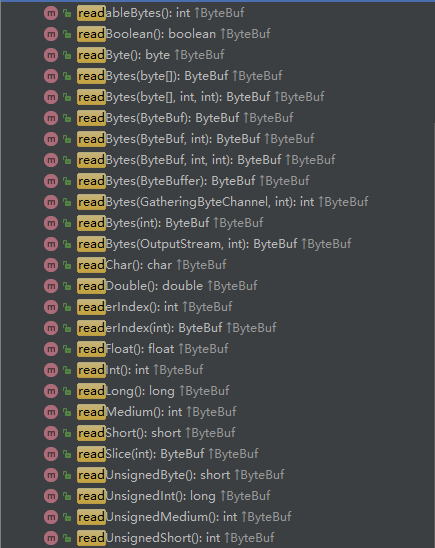
從當前 readerIndex 位置讀取四個位元組內容:
byte[] dst = new byte[4];
buf.readBytes(dst);
System.out.println(new String(dst));
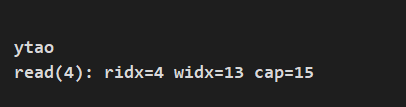
System.out.println(String.format("read(4): ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));列印結果:
索引示意圖:
ByteBuf 動態擴容
通過上面的 ByteBuffer 分配緩衝區例子,向裡面新增 [ytao公眾號ytao公眾號] 內容,使寫入的內容大於 limit 的值。
ByteBuffer buffer = ByteBuffer.allocate(100);
buffer.limit(15);
String content = "ytao公眾號ytao公眾號";
buffer.put(content.getBytes());執行結果異常:

內容位元組大小超過了 limit 的值時,緩衝區溢位異常,所以我們每次寫入資料前,得檢查緩區大小是否有足夠空間,這樣對編碼上來說,不是一個好的體驗。
使用 ByteBuf 新增同樣的內容,給定同樣的初始容器大小。
ByteBuf buf = Unpooled.buffer(15);
String content = "ytao公眾號ytao公眾號";
buf.writeBytes(content.getBytes());
System.out.println(String.format("write: ridx=%s widx=%s cap=%s", buf.readerIndex(), buf.writerIndex(), buf.capacity()));列印執行結果:
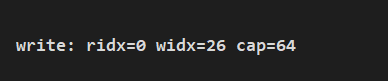
通過上面列印資訊,可以看到 cap 從設定的 15 變為了 64,當我們容器大小不夠時,就是進行擴容,接下來我們分析擴容過程中是如何做的。
進入 writeBytes 裡面:

校驗寫入內容長度:
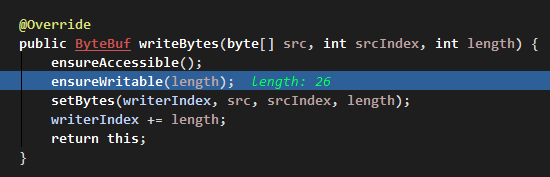
在可寫區域檢查裡:
- 如果寫入內容為空,丟擲非法引數異常。
- 如果寫入內容大小小於或等於可寫區域大小,則返回當前緩衝區,當中的
writableBytes()函式為可寫區域大小capacity - writerIndex - 如果寫入內容大小大於最大可寫區域大小,則丟擲索引越界異常。
- 最後剩下條件的就是寫入內容大小大於可寫區域,小於最大區域大小,則分配一個新的緩衝區域。
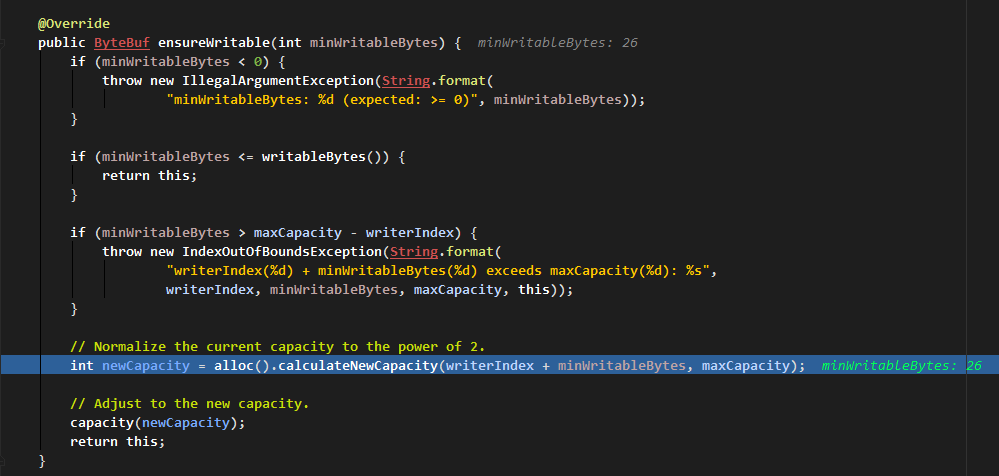
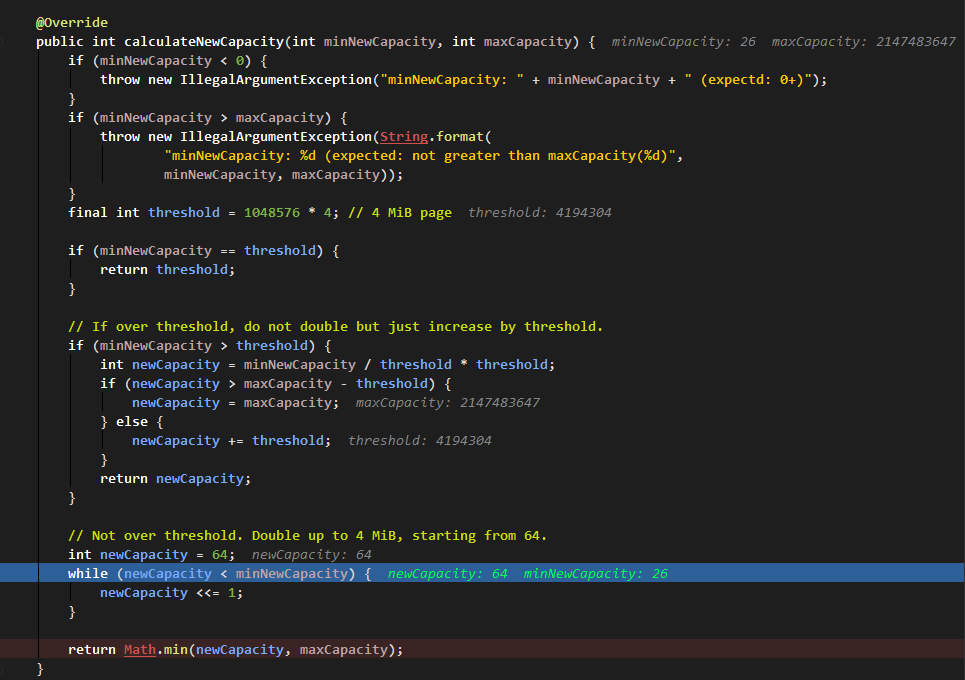
在容量不足,重新分配緩衝區的裡面,以 4M 為閥門:
- 如果待寫內容剛好為 4M, 那麼就分配 4M 的緩衝區。
- 如果待寫內容超過這個閥門且與閥門值之和不大於最大容量值,就分配(閥門值+內容大小值)的緩衝區;如果超過這個閥門且與閥門值之和大於最大容量值,則分配最大容量的緩衝區。
- 如果待寫內容不超過閥門值且大於 64,那麼待分配緩衝區大小就以 64 的大小進行倍增,直到相等或大於待寫內容。
- 如果待寫內容不超過閥門值且不大於 64,則返回待分配緩衝區大小為 64。
最後
Netty 實現的緩衝區,八個基本型別中,除了布林型別,其他7種都有自己對應的 Buffer,但是實際使用過程中, ByteBuf 才是我們嘗試用的,它可相容任何型別。ByteBuf 在 Netty 體系中是最基礎也是最重要的一員,要想更好掌握和使用 Netty,先理解並掌握 ByteBuf 是必需條件之一。
個人部落格: https://ytao.top
關注公眾號 【ytao】,更多原創好文

相關推薦
Netty之緩衝區ByteBuf解讀(一)
Netty 在資料傳輸過程中,會使用緩衝區設計來提高傳輸效率。雖然,Java 在 NIO 程式設計中已提供 ByteBuffer 類進行使用,但是在使用過程中,其編碼方式相對來說不太友好,也存在一定的不足。所以高效能的 Netty 框架實現了一套更加強大,完善的 ByteBuf,其設計理念也是堪稱一絕。
Netty之緩衝區ByteBuf解讀(二)
 > 上篇介紹了 ByteBuf 的簡單讀寫操作以及讀寫指標的基本介紹,本文繼續對 ByteBuf 的基本操作進行解
Spark學習之路 (十五)SparkCore的源碼解讀(一)啟動腳本
-o 啟動服務 binary dirname ppi std 參數 exp 情況 一、啟動腳本分析 獨立部署模式下,主要由master和slaves組成,master可以利用zk實現高可用性,其driver,work,app等信息可以持久化到zk上;slaves由一臺至多
資料之路-民宿市場資料解讀(一)
筆者有個朋友,北上廣打拼多年,每天加班加點,披星戴月…終於不堪折磨,萌生退意,想要歸隱山林,開個農家院收租為生… 在無情的嘲笑了他後,筆者也很好奇,到底民宿市場如何?做民宿到底賺不賺錢?什麼樣的民宿比較賺錢?使用者都是哪些人? 帶著這些問題筆者開始了民宿市場的探
Netty原始碼解讀(一)概述
感謝網友【黃億華】投遞本稿。 Netty和Mina是Java世界非常知名的通訊框架。它們都出自同一個作者,Mina誕生略早,屬於Apache基金會,而Netty開始在Jboss名下,後來出來自立門戶netty.io。關於Mina已有@FrankHui的Mina系列文章,我正好最近也要做一些網路
java原始碼之 io 流原始碼解讀(一)
剛剛喝了一波毒雞湯,其中印象最深的就是這兩個: 沒有人能夠讓你放棄夢想,自己想想就放棄了。 找物件的時候不能光看對方的外表。。。。 還要看看自己的外表 哈哈哈~~ 吸收了這一大波精氣之後,我感覺我的
uboot學習筆記之原始碼解讀(一)
1、BootLoader介紹 對於計算機系統來說,從開機上電到作業系統啟動需要一個引導過程。嵌入式Linux系統同樣離不開載入程式,這個載入程式就叫作啟動載入程式(Bootloader)。 Bootloader是在作業系統執行之前執行的一段小程式。通過這段小程式,可以初始
python框架之 Tornado 學習筆記(一)
tornado pythontornado 一個簡單的服務器的例子:首先,我們需要安裝 tornado ,安裝比較簡單: pip install tornado 測試安裝是否成功,可以打開python 終端,輸入: import tornado.https
python大法之二-一些基礎(一)
計算機編程 python 獨立博客 hello 解釋器 個人獨立博客出處:http://www.xbman.cn/出處:http://www.xbman.cn/article/3Python是一種解釋性計算機編程語言。采用縮進式語法,寫起來的感覺有點像排了版的shell,這裏要註意寫pyt
Linux之Ubuntu環境配置(一)
sogou home ade -- linux下 安裝 linux64 x64 inux Linux下的搜狗輸入法安裝: 1.搜狗官網下載Linux64bit版本文件,默認在/home/username/Downloads目錄下。 2.cd /home/username/D
數據結構之二叉樹(一)
reorder system style 序列 urn creat 編寫程序 space ont 設計和編寫程序,按照輸入的遍歷要求(即先序、中序和後序)完成對二叉樹的遍歷,並輸出相應遍歷條件下的樹結點序列。 1 //遞歸實現 2 #include
vuex實踐之路——筆記本應用(一)
time 中大 -- this 隔離 思想 一個表 環境搭建 一定的 首先使用vue-cli把環境搭建好。 介紹一下應用的界面。 App.vue根組件,就是整個應用的最外層 Toolbar.vue:最左邊紅色的區域,包括三個按鈕,添加、收藏、刪除。 NoteList.vu
構建之法--探索篇(一)
構建 編寫 裏的 set namespace 對象 之前 定義 時也 問題一: 在Cust中無法找到telephone的get方法,這裏是因為我之前沒有telephone的成員變量,加上之後有沒有寫telephone的get方法; 解決方案:只要在Cust這個類裏面,加上
solr搜索之入門及原理(一)
solr solr入門 1 solr簡介solr官方文檔:http://wiki.apache.org/solr/DataImportHandler 下載地址:http://www.apache.org/dyn/closer.cgi/lucene/solr/2 solr入門我們使
C#.Net 設計模式學習筆記之創建型 (一)
應用 種類 單件 src nag abstract 子類 指定 相關 1、抽象工廠(Abstract Factory)模式 常規的對象創建方法: //創建一個Road對象 Road road =new Road(); new 的問題: 實現依賴,不能應對“具
.NET中使用Redis之ServiceStack.Redis學習(一)安裝與簡單的運行
arraylist write client cli ring blog 控制臺 創建 spa 1.下載ServiceStack.Redis PM> Install-Package ServiceStack.Redis 2.vs中創建一個控制臺程序 class Pro
構建之法學習回顧(一)
第三章 多人合作 認識 案例 回歸 實用 效能 可執行 代碼規範 在學習完構建之法一到四章之後,作為軟件工程專業的一名在校生,有了一些全新的認識,作者把軟件工程開發的方法和案例講的清晰有趣而又實用,我們的思維水平也升級了不少。 在
構建之法-----閱讀問題(一)
閱讀 原因 開發流程 閱讀內容 簡單的 天都 不能 作者 敏捷開發 閱讀內容:第六章 敏捷開發流程 在敏捷開發流程中,作者提出了一個觀點-----每日立會,在聽老師講的過程中,覺得這種模式很好,在每日立會中,定義好任務究竟是什麽?完成這個任務的時間是什麽?能夠及時發現自己
Linux基礎之常見命令用法(一)
linux基礎命令入門(一)一、Linux文件目錄結構 在講述之前,先簡短的說說Windows文件結構,打開‘計算機’,看到的一個個的驅動器(盤符,例C盤、D盤等),點開其中任意盤符,看到的是一個個文件或文件夾,繼續打開...,每個盤都有自己的根目錄。若是把其打開過程畫下來,便可得到如下多棵倒樹並列的圖
初識Hibernate之關聯映射(一)
ber 初識 album nat amp uid 關聯映射 映射 pic http://pic.cnhubei.com/space.php?uid=1774&do=album&id=1361989http://pic.cnhubei.com/space.ph