
DirectX11 Windows Windows SDK--28 計算著色器:波浪(水波)
前言
有關計算著色器的基礎其實並不是很多。接下來繼續講解如何使用計算著色器實現水波效果,即龍書中所實現的水波。但是光看程式碼可是完全看不出來是在做什麼的。個人根據書中所給的參考書籍找到了對應的實現原理,但是裡面涉及到比較多的物理公式。因此,要看懂這一章需要有高數功底(求導、偏導、微分方程),我會把推導過程給列出來。
本章演示專案還用到了其他的一些效果,在學習本章之前建議先了解如下內容:
| 章節內容 |
|---|
| 11 混合狀態 |
| 17 利用幾何著色器實現公告板效果(霧效部分) |
| 26 計算著色器:入門 |
| 27 計算著色器:雙調排序(非雙調排序部分) |
學習目標:
- 熟悉如何利用三角形柵格來表示地形和水
- 熟悉如何用CPU或者計算著色器生成水波
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什麼問題也可以在這裡彙報。
用三角形柵格表示地形
我們可以使用一個函式\(y=f(x, z)\)來表示一個曲面,在xz平面內構造一個柵格來近似地表示這個曲面。其中的每個四邊形都是由兩個三角形所構成的,接下來再利用該函式計算出每個柵格點處的高度即可。
如下圖所示,我們先在xz平面內“鋪設”一層柵格
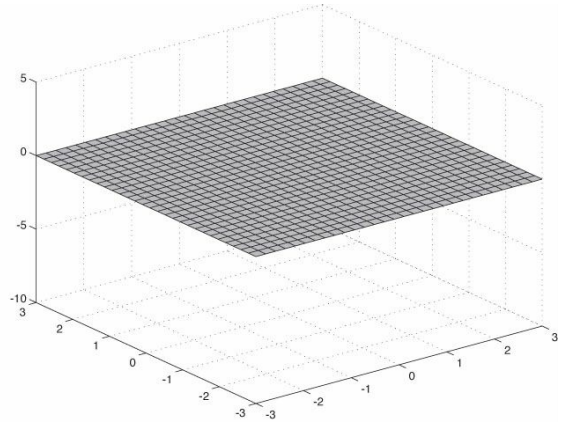
然後我們再運用函式\(y=f(x, z)\)來為每個柵格點獲取對應的y座標。再利用\((x, f(x, z), z)\)的所有頂點構造出地形柵格
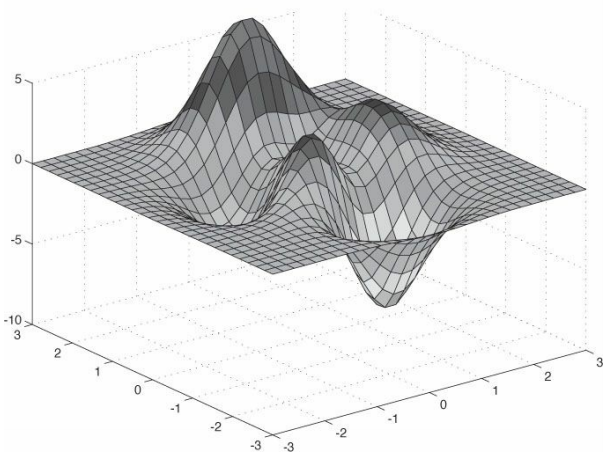
生成柵格頂點
由以上分析可知,我們首先需要完成的就是來構建xz平面內的柵格。若規定一個m行n列的柵格,那麼柵格包含m * n個四邊形,即對應2 * m * n個三角形,頂點數為(m + 1) * (n + 1)。
在Geometry中建立地形的方法比較複雜,後三行的形參是根據(x, z)座標來分別確定出高度y、法向量n和顏色c的函式:
template<class VertexType = VertexPosNormalTex, class IndexType = DWORD> MeshData<VertexType, IndexType> CreateTerrain( const DirectX::XMFLOAT2& terrainSize, // 地形寬度與深度 const DirectX::XMUINT2& slices, // 行柵格數與列柵格數 const DirectX::XMFLOAT2 & maxTexCoord, // 最大紋理座標(texU, texV) const std::function<float(float, float)>& heightFunc, // 高度函式y(x, z) const std::function<DirectX::XMFLOAT3(float, float)>& normalFunc, // 法向量函式n(x, z) const std::function<DirectX::XMFLOAT4(float, float)>& colorFunc); // 顏色函式c(x, z) template<class VertexType = VertexPosNormalTex, class IndexType = DWORD> MeshData<VertexType, IndexType> CreateTerrain( float width, float depth, // 地形寬度與深度 UINT slicesX, UINT slicesZ, // 行柵格數與列柵格數 float texU, float texV, // 最大紋理座標(texU, texV) const std::function<float(float, float)>& heightFunc, // 高度函式y(x, z) const std::function<DirectX::XMFLOAT3(float, float)>& normalFunc, // 法向量函式n(x, z) const std::function<DirectX::XMFLOAT4(float, float)>& colorFunc); // 顏色函式c(x, z)
我們的程式碼是從左下角開始,逐漸向右向上地計算出其餘頂點座標。需要注意的是,紋理座標是以左上角為座標原點,U軸朝右,V軸朝下。
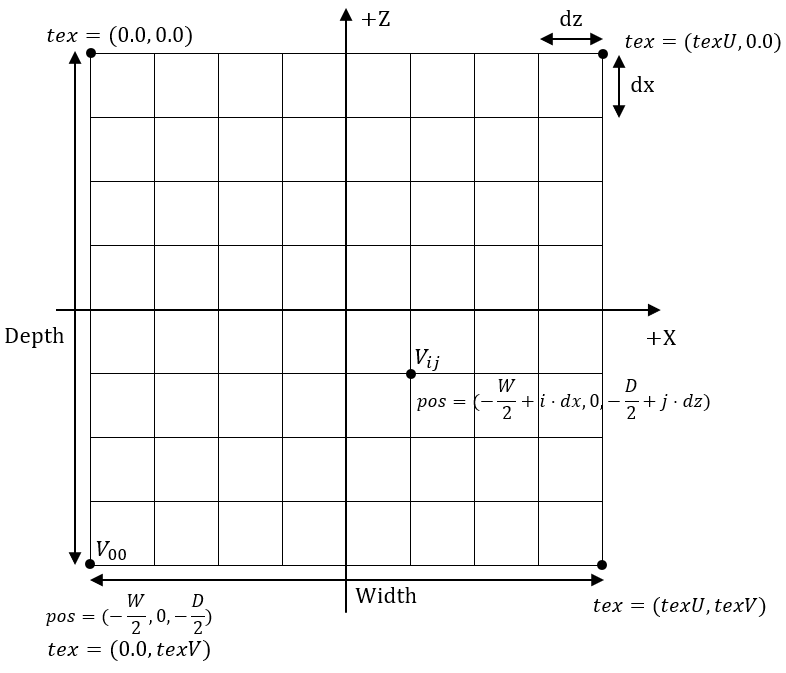
下面的程式碼展示瞭如何生成柵格頂點:
template<class VertexType, class IndexType>
MeshData<VertexType, IndexType> CreateTerrain(
float width, float depth,
UINT slicesX, UINT slicesZ,
float texU, float texV,
const std::function<float(float, float)>& heightFunc,
const std::function<DirectX::XMFLOAT3(float, float)>& normalFunc,
const std::function<DirectX::XMFLOAT4(float, float)>& colorFunc)
{
using namespace DirectX;
MeshData<VertexType, IndexType> meshData;
UINT vertexCount = (slicesX + 1) * (slicesZ + 1);
UINT indexCount = 6 * slicesX * slicesZ;
meshData.vertexVec.resize(vertexCount);
meshData.indexVec.resize(indexCount);
Internal::VertexData vertexData;
UINT vIndex = 0;
UINT iIndex = 0;
float sliceWidth = width / slicesX;
float sliceDepth = width / slicesZ;
float leftBottomX = -width / 2;
float leftBottomZ = -depth / 2;
float posX, posZ;
float sliceTexWidth = texU / slicesX;
float sliceTexDepth = texV / slicesZ;
XMFLOAT3 normal;
XMFLOAT4 tangent;
// 建立網格頂點
// __ __
// | /| /|
// |/_|/_|
// | /| /|
// |/_|/_|
for (UINT z = 0; z <= slicesZ; ++z)
{
posZ = leftBottomZ + z * sliceDepth;
for (UINT x = 0; x <= slicesX; ++x)
{
posX = leftBottomX + x * sliceWidth;
// 計算法向量並歸一化
normal = normalFunc(posX, posZ);
XMStoreFloat3(&normal, XMVector3Normalize(XMLoadFloat3(&normal)));
// 計演算法平面與z=posZ平面構成的直線單位切向量,維持w分量為1.0f
XMStoreFloat4(&tangent, XMVector3Normalize(XMVectorSet(normal.y, -normal.x, 0.0f, 0.0f)) + g_XMIdentityR3);
vertexData = { XMFLOAT3(posX, heightFunc(posX, posZ), posZ),
normal, tangent, colorFunc(posX, posZ), XMFLOAT2(x * sliceTexWidth, texV - z * sliceTexDepth) };
Internal::InsertVertexElement(meshData.vertexVec[vIndex++], vertexData);
}
}
// 放入索引
for (UINT i = 0; i < slicesZ; ++i)
{
for (UINT j = 0; j < slicesX; ++j)
{
meshData.indexVec[iIndex++] = i * (slicesX + 1) + j;
meshData.indexVec[iIndex++] = (i + 1) * (slicesX + 1) + j;
meshData.indexVec[iIndex++] = (i + 1) * (slicesX + 1) + j + 1;
meshData.indexVec[iIndex++] = (i + 1) * (slicesX + 1) + j + 1;
meshData.indexVec[iIndex++] = i * (slicesX + 1) + j + 1;
meshData.indexVec[iIndex++] = i * (slicesX + 1) + j;
}
}
return meshData;
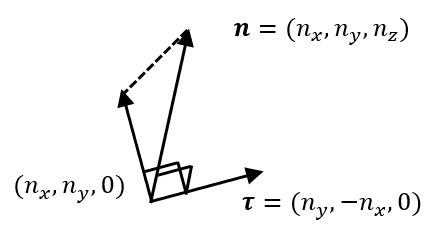
}其中需要額外瞭解的是切線向量的產生。由於要讓切線向量能夠與xOy平面平行,需要先讓法向量投影到xOy平面,然後再得到對應的未經標準化的切線向量,如下圖所示:
一種表示山峰的函式
正弦函式適合用於表示起伏不定的山坡,一種二維山川地形的函式為:
\[ y(x,z)=\frac{3}{10}(zsin(\frac{1}{10}x)+xcos(\frac{1}{10}z)) \]
其在(x, y, z)處未經標準化的法向量為:
\[ \mathbf{n}=(-\frac{\partial{y}}{\partial{x}}, 1, -\frac{\partial{y}}{\partial{z}}) \]
其中y對x和對z的偏導分別為:
\[
\frac{\partial{y}}{\partial{x}}=\frac{3}{10}(\frac{1}{10}zcos(\frac{1}{10}x)+cos(\frac{1}{10}z))\\
\frac{\partial{y}}{\partial{z}}=\frac{3}{10}(sin(\frac{1}{10}x)-\frac{1}{10}xsin(\frac{1}{10}z))
\]

因此建立上述地形的函式可以寫成:
MeshData<VertexPosNormalTex, DWORD> landMesh = Geometry::CreateTerrain(XMFLOAT2(160.0f, 160.0f),
XMUINT2(50, 50), XMFLOAT2(10.0f, 10.0f),
[](float x, float z) { return 0.3f*(z * sinf(0.1f * x) + x * cosf(0.1f * z)); }, // 高度函式
[](float x, float z) { return XMFLOAT3{ -0.03f * z * cosf(0.1f * x) - 0.3f * cosf(0.1f * z), 1.0f, -0.3f * sinf(0.1f * x) + 0.03f * x * sinf(0.1f * z) }; }) // 法向量函式當然,Lambda函式不理解,你也可以寫成這樣:
float GetHillsHeight(float x, float z)
{
return 0.3f * (z * sinf(0.1f * x) + x * cosf(0.1f * z));
}
XMFLOAT3 GetHillsNormal(float x, float z)
{
return XMFLOAT3(-0.03f * z * cosf(0.1f * x) - 0.3f * cosf(0.1f * z), 1.0f,
-0.3f * sinf(0.1f * x) + 0.03f * x * sinf(0.1f * z));
}
MeshData<VertexPosNormalTex, DWORD> landMesh = Geometry::CreateTerrain(XMFLOAT2(160.0f, 160.0f),
XMUINT2(50, 50), XMFLOAT2(10.0f, 10.0f), GetHillsHeight, GetHillsNormal);流體模擬
在許多遊戲中,你可能會看到有水面流動的場景,實際上他們不一定是真正的流體,而有可能只是一個正在運動的水體表面。出於執行效率的考慮,這些效果的實現或多或少涉及到數學公式或者物理公式。
本節我們只討論龍書所實現的方法,即使用波動方程來表現區域性位置激起的水波。它的公式推導比較複雜,但是用心看下去的會應該還是能看得懂的。
話不多說,接下來我們需要啃硬骨頭了。
波動方程的推導
波動方程是一個描述在持續張力作用下的一維繩索或二維表面的某一點處的運動。在一維情況下,我們可以考慮將一個富有彈性的繩索緊緊綁在兩端(有輕微拉伸),讓繩索落在x軸上來派生出一維的波動方程。我們假定當前的繩索在每一點處的線密度(單位長度下的質量)都是恆等的ρ,並且沿著繩索在該點處受到沿著切線的方向持續的張力T。

令函式\(z(x,t)\)代表繩索在x點處,t時刻的垂直位移量。當繩索在z方向產生位移時,表明繩子正在被拉伸。由牛頓第二定律,我們可以知道在t時刻內,位於\(x=s\)和\(x=s+\Delta x\)之間的繩索段在合力\(\mathbf{F}(x, t)\)的作用下,加速度為:
\[
\mathbf{a}(x,t)=\frac{\mathbf{F}(x,t)}{\rho\Delta x} \tag{28.1}
\]
在下面的公式中,我們可以將位於\(x=s\)和\(x=s+\Delta x\)之間的繩索段的兩個端點所受的力分解成水平方向和豎直方向的力,得到\(H(x,t)\)和\(V(x,t)\)。讓θ表示繩索在\(x=s\)處切向量與x軸方向的夾角。由於張力T沿著切線方向作用,水平分量\(H(s,t)\)和垂直分量\(V(s,t)\)可以表示為:
\[
H(s,t)=Tcos\theta \\
V(s,t)=Tsin\theta \tag{28.2}
\]
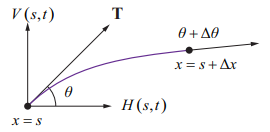
讓\(\theta+\Delta\theta\)表示另一個端點\(x=s+\Delta x\)處切線向量與x軸的夾角。這樣作用在該端點上的張力的水平分量\(H(s+\Delta x,t)\)和垂直分量\(V(s+\Delta x,t)\)則表示為:
\[
H(s+\Delta x,t)=Tcos(\theta + \Delta\theta) \\
V(s+\Delta x,t)=Tsin(\theta + \Delta\theta) \tag{28.3}
\]
對於小幅度的運動,我們假定繩索段的水平合力為0,這樣繩索段的加速度僅僅包含垂直方向。因此,對於\(x=s\)與\(x=s+\Delta x\)之間的繩索段,我們有下面的公式:
\[
H(s+\Delta x, t) - H(s, t) = 0 \tag{28.4}
\]
這樣H函式就不需要依賴x了,我們可以用\(H(t)\)取代\(H(x,t)\)。
作用在\(x=s\)和\(x=s+\Delta x\)之間的繩索段的垂直合力會在z方向產生一個加速度。由於垂直加速度等於位置函式\(z(x,t)的二階導\),因此有:
\[
a_z(s,t)=\frac{{\partial}^2}{{\partial}t^2}z(s,t)=\frac{V(s+\Delta x,t)-V(s,t)}{\rho\Delta x} \tag{28.5}
\]
等式兩邊乘上ρ,然後讓\(\Delta x\)趨向於0,此時等式右邊正好為偏導數的定義:
\[
\rho\frac{{\partial}^2}{{\partial}t^2}z(s,t)=\lim_{\Delta x \to 0}\frac{V(s+\Delta x,t)-V(s,t)}{\Delta x} \tag{28.6}
\]
因此又有:
\[
\rho\frac{{\partial}^2}{{\partial}t^2}z(s,t)=\frac{\partial}{{\partial}x}V(s,t) \tag{28.7}
\]
將方程組(28.2)聯立,我們可以寫成:
\[
V(s, t)=H(t)tan\theta \tag{28.8}
\]
因為θ是繩索在X軸方向與切線之間的夾角,\(\tan\theta\)正好也是函式z(x, t)在s處的斜率,因此:
\[
V(s, t)=H(t)\frac{\partial}{\partial x}z(s,t) \tag{28.9}
\]
即:
\[
\rho\frac{{\partial}^2}{{\partial}t^2}z(s,t)=\frac{\partial}{\partial x}[H(t)\frac{\partial}{\partial x}z(s,t)] \tag{28.10}
\]
由於H(t)並不依賴於x,我們又可以寫成:
\[
\rho\frac{{\partial}^2}{{\partial}t^2}z(s,t)=H(t)\frac{{\partial}^2}{\partial x^2}z(s,t) \tag{28.11}
\]
對於小幅度的運動,\(cos\theta\)接近於1(此時水平分量的力為0),因此我們用\(H(t)\)來近似表示張力T。讓\(c^2=T/\rho\),我們現在得到了一維的波動方程:
\[
\frac{{\partial}^2 z}{{\partial}t^2}=c^2\frac{{\partial}^2 z}{\partial x^2} \tag{28.12}
\]
同理,二維的波動方程可以通過新增一個y項得到:
\[
\frac{{\partial}^2 z}{{\partial}t^2}=c^2(\frac{{\partial}^2 z}{\partial x^2}+\frac{{\partial}^2 z}{\partial y^2}) \tag{28.13}
\]
常數c具有單位時間距離的尺度,因此可以表示速度。事實上我們也不會證明c實際上就是波沿著繩索或表面傳遞的速度。這是有意義的,因為波的速度隨介質所受張力T的變大而增加,隨介質密度μ的減小而減小。
滿足一維波動方程的解有無窮多個,例如一種常見的波函式形式為\(z(x,t)=Asin(\omega(t-\frac{x}{v}))\),函式隨著時間的推移影象如下:
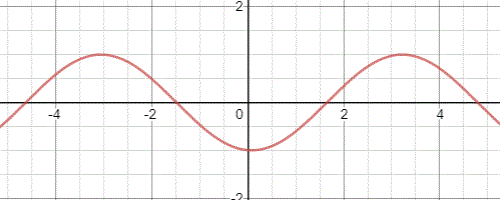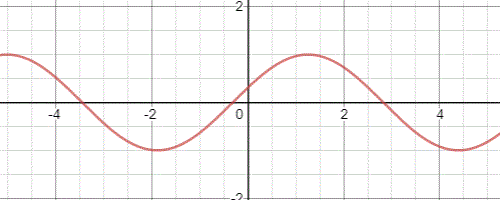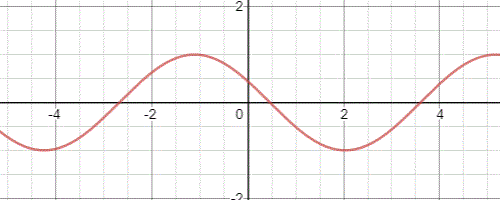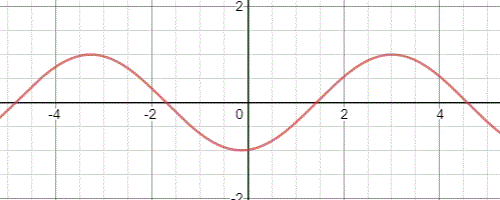
然而方程(28.13)僅包含了張力,沒有考慮到其他阻力因素,這導致波的平均振幅並不會有任何損耗。我們可以給方程組新增一個與張力方向相反,且與點的運動速度有關的粘性阻尼力:
\[
\frac{{\partial}^2 z}{{\partial}t^2}=c^2(\frac{{\partial}^2 z}{\partial x^2}+\frac{{\partial}^2 z}{\partial y^2})-\mu\frac{\partial z}{\partial t} \tag{28.14}
\]
其中非負實數μ代表了液體的粘性,用來控制水面的波什麼時候能夠平靜下來。μ越大,水波消亡的速度越快。對於水來說,通常它的μ值會比較小,使得水波能夠存留比較長的時間;但對於油來說,它的μ值會比較大一些,因此水波消亡的速度會比較快。
近似導數
帶粘性阻尼力的二維波動方程(28.14)可以通過可分離變數的形式解出來。然而它的解十分複雜,需要大規模的實時模擬演算。取而代之的是,我們將使用一種數值上的技術來模擬波在流體表面的傳播。
假定我們的流體表面可以表示成一個n×m的矩形柵格,如下圖所示。
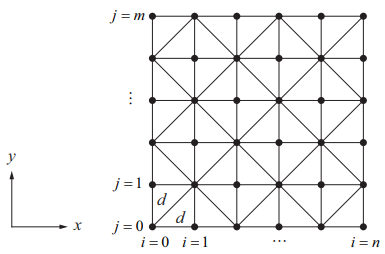
其中d為兩個鄰近頂點在x方向的距離及y方向的距離(規定相等),t為時間間隔。我們用\(z(i, j, k)\)來表示頂點的位移量,其中i和j分別要滿足\(0\leq i<n\)及\(0\leq j<m\),代表世界位置(id, jd)的頂點。k則用來表示時間。因此,\(z(i, j, k)\)等價於頂點(id, jd)在t時刻的z方向位移。
此外,我們需要施加邊界條件,讓處在邊緣的頂點位移量固定為0.內部頂點的偏移則可以使用(28.14)方程,採用近似導數的方法計算出來。如下圖所示,我們可以通過在x方向上計算頂點[i][j]分別和它的相鄰的兩個頂點[i-1][j]和[i+1][j]的微分的平均值\(\frac{\Delta z}{\Delta x}\)來逼近具有座標[i][j]的頂點上與x軸對齊的切線。這樣就有\(\Delta x = d\),我們將偏導數\(\frac{\partial z}{\partial x}\)定義為:
\[
\begin{equation} \begin{split}
\frac{\partial}{\partial x}z(i,j,k) &= \frac{\frac{z(i,j,k)-z(i-1,j,k)}{d}+\frac{z(i+1,j,k)-z(i,j,k)}{d}}{2} \\
&=\frac{z(i+1,j,k)-z(i-1,j,k)}{2d} \\
\end{split} \end{equation} \tag{28.15}
\]
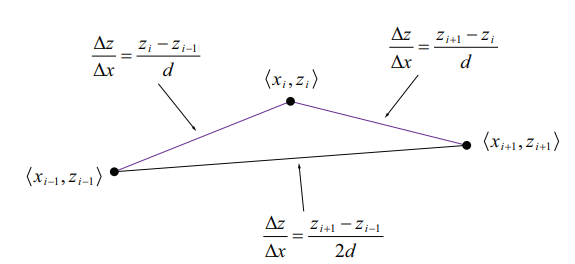
同理,我們取頂點[i][j]的兩個y方向上的相鄰頂點[i][j-1]和[i][j+1]來近似計算z對於y的偏導數:
\[
\frac{\partial}{\partial y}z(i,j,k) =\frac{z(i,j+1,k)-z(i,j-1,k)}{2d} \tag{28.16}
\]
至於時間,我們可以通過計算頂點在當前時刻分別與上一個時刻和下一個時刻的平均位移差來定義z對時間t偏導\(\frac{\Delta z}{\Delta t}\):
\[
\frac{\partial}{\partial t}z(i,j,k) =\frac{z(i,j,k+1)-z(i,j,k-1)}{2t} \tag{28.17}
\]
二階偏導也可以使用和一階偏導相同的方法來計算。假如我們已經計算出了頂點[i-1][j]和[i+1][j]的偏移z對x的一階偏導數,那麼我們就可以得到兩者平均差值:
\[
\begin{equation} \begin{split}
\Delta[\frac{\partial}{\partial x}z(i,j,k)] &= \frac{\frac{\partial}{\partial x}z(i+1,j,k)-\frac{\partial}{\partial x}z(i,j,k)}{2} + \frac{\frac{\partial}{\partial x}z(i,j,k)-\frac{\partial}{\partial x}z(i-1,j,k)}{2} \\
&=\frac{\frac{\partial}{\partial x}z(i+1,j,k)-\frac{\partial}{\partial x}z(i-1,j,k)}{2} \\
\end{split} \end{equation} \tag{28.18}
\]
將方程(28.15)帶入上式,可以得到:
\[
\begin{equation} \begin{split}
\Delta[\frac{\partial}{\partial x}z(i,j,k)] &= \frac{\frac{z(i+2,j,k)-z(i,j,k)}{2d} - \frac{z(i,j,k)-z(i-2,j,k)}{2d}}{2} \\
&=\frac{z(i+2,j,k)-2z(i,j,k)+z(i-2,j,k)}{4d} \\
\end{split} \end{equation} \tag{28.19}
\]
除以d使得我們可以得到\(\Delta(\frac{\partial z}{\partial x})/\Delta x\),對應二階偏導:
\[
\frac{{\partial}^2}{{\partial}x^2}z(i,j,k)=\frac{z(i+2,j,k)-2z(i,j,k)+z(i-2,j,k)}{4d^2} \tag{28.20}
\]
該公式要求我們使用x軸距離為2的頂點[i+2][j]和[i-2][j]來計算二階偏導。不過相鄰的兩個頂點就沒有用到了,我們可以基於頂點[i][j]將x軸縮小一半,使用距離最近的兩個相鄰點[i+1][j]和[i-1][j]來計算二階偏導:
\[
\frac{{\partial}^2}{{\partial}x^2}z(i,j,k)=\frac{z(i+1,j,k)-2z(i,j,k)+z(i-1,j,k)}{d^2} \tag{28.21}
\]
同理可得:
\[
\frac{{\partial}^2}{{\partial}y^2}z(i,j,k)=\frac{z(i,j+1,k)-2z(i,j,k)+z(i,j-1,k)}{d^2} \tag{28.22}
\]
\[ \frac{{\partial}^2}{{\partial}t^2}z(i,j,k)=\frac{z(i,j,k+1)-2z(i,j,k)+z(i,j,k-1)}{t^2} \tag{28.23} \]
求出水面位移
聯立z對t的一階偏導(公式28.17)以及二階偏導(公式28.21、28.22、28.23),帶粘性阻尼力的二維波動方程可以表示為:
\[
\frac{z(i,j,k+1)-2z(i,j,k)+z(i,j,k-1)}{t^2}=c^{2}\frac{z(i+1,j,k)-2z(i,j,k)+z(i-1,j,k)}{d^2}\\
+c^{2}\frac{z(i,j+1,k)-2z(i,j,k)+z(i,j-1,k)}{d^2}-\mu\frac{z(i,j,k+1)-z(i,j,k-1)}{2t} \tag{28.24}
\]
我們想要能夠在傳遞模擬間隔t來確定下一次模擬位移量\(z(i,j,k+1)\),現在我們已經知道當前位移量\(z(i,j,k)\)和上一次模擬的位移量\(z(i,j,k-1)\)。因此\(z(i,j,k+1)\)的解為:
\[
z(i,j,k+1)=\frac{4-8c^2t^2/d^2}{\mu t+2}z(i,j,k)+\frac{\mu t-2}{\mu t+2}z(i,j,k-1)\\
+\frac{2c^2t^2/d^2}{\mu t+2}[z(i+1,j,k)+z(i-1,j,k)+z(i,j+1,k)+z(i,j-1,k)] \tag{28.25}
\]
這條公式正是我們想要的。其中常量部分可以預先計算出來,只剩下3個帶t的因式和4個加法需要給網格中每個頂點進行運算。
如果波速c過快,或者時間段t太長,上述式子的偏移量有可能趨向於無窮。為了保持結果是有窮的,我們需要給上式確定額外的條件,並且要保證在我們抬高一個頂點並釋放後能夠確保水波逐漸遠離頂點位置。
假定我們擁有一個n×m頂點陣列(其任意\(z(i,j,0)=0\)和\(z(i,j,1)=0\)),現在讓某處頂點被抬高使得\(z(i_0, j_0, 0)=h\)和\(z(i_0, j_0, 1)=h\),h是一個非0位移值。若該處頂點被釋放了2t時間,此時式子(28.25)中第三個加法部分的值為0,故有:
\[
\begin{equation} \begin{split}
z(i,j,2)&=\frac{4-8c^2t^2/d^2}{\mu t+2}z(i,j,1)+\frac{\mu t-2}{\mu t+2}z(i,j,0)\\
&=\frac{2-8c^2t^2/d^2+\mu t}{\mu t+2}h
\end{split} \end{equation} \tag{28.26}
\]
為了讓頂點向周圍平坦的水面移動,它在2t時刻的位移必須要比在t時刻的更小一些。因此就有:
\[
\left| z(i_0, j_0, 2)\right| < \left| z(i_0, j_0, 1) \right| = \left| h \right| \tag{28.27}
\]
代入方程(28.26),有:
\[
\left| \frac{2-8c^2t^2/d^2 + \mu t}{\mu t + 2} \right|\cdot\left| h\right| < \left| h \right| \tag{28.28}
\]
因此,
\[
-1 < \frac{2-8c^2t^2/d^2 + \mu t}{\mu t + 2} < 1 \tag{28.29}
\]
把速度c解出來,我們可以得到:
\[
0<c<\frac{d}{2t}\sqrt{\mu t + 2} \tag{28.30}
\]
這告訴我們對於公式(28.25),給定兩個頂點的距離d以及時間間隔t,波速c必須小於上式的最大值
又或者,給定距離d和波速c,我們能夠計算出最大的時間間隔t。對不等式(28.29)乘上\((-\mu t + 2)\)來簡化得到:
\[
0<\frac{4c^2}{d^2}t^2<\mu t+2 \tag{28.31}
\]
由於t>0,中間部分恆大於0,去掉左半部分解一元二次不等式,並捨去t<=0的部分,得:
\[
0<t<\frac{\mu+\sqrt{\mu ^2+32c^2/d^2}}{8c^2/d^2} \tag{28.32}
\]
使用c區間和t區間外的值會導致位移z的結果呈指數級爆炸。
程式碼實現
現在我們需要準備兩個二維頂點位置陣列,其中一個數組表示的是當前模擬所有頂點的位置,而另一個數組則表示的是上一次模擬所有頂點的位置。當我們計算新的位移時,將下一次模擬的結果直接寫在存放上一次模擬頂點的陣列即可(可以觀察公式28.25,我們需要的是當前頂點上一次模擬、當前模擬的資料,以及當前模擬相鄰四個頂點的資料,因此其他頂點在計算位移量的時候不會有影響)。
為了執行光照計算,我們還需要為每個頂點獲取正確的法向量以及可能正確的切線向量。對於頂點座標(i, j),未標準化的,與x軸對齊的切向量T和與y軸對齊的切線向量B如下:
\[
\mathbf{T}=(1,0,\frac{\partial}{\partial x}z(i,j,k))\\
\mathbf{B}=(0,1,\frac{\partial}{\partial y}z(i,j,k)) \tag{28.33}
\]
用公式28.15和28.16代入28.33,可得:
\[
\mathbf{T}=(1,0,\frac{z(i+1,j,k)-z(i-1,j,k)}{2d})\\
\mathbf{B}=(0,1,\frac{z(i,j+1,k)-z(i,j-1,k)}{2d}) \tag{28.34}
\]
經過叉乘後可以得到未經標準化的法向量:
\[
\begin{equation} \begin{split}
\mathbf{N} &= \mathbf{T}\times\mathbf{B} \\
&=\begin{vmatrix}
\mathbf{i} & \mathbf{j} & \mathbf{k} \\
1 & 0 & \frac{z(i+1,j,k)-z(i-1,j,k)}{2d} \\
0 & 1 & \frac{z(i,j+1,k)-z(i,j-1,k)}{2d} \\
\end{vmatrix} \\
&= (-\frac{z(i+1,j,k)-z(i-1,j,k)}{2d},-\frac{z(i,j+1,k)-z(i,j-1,k)}{2d}, 1)
\end{split} \end{equation} \tag{28.35}
\]
對上述向量乘上2d的倍數並不會改變它的方向,但可以消除除法:
\[
\mathbf{T}=(2d,0,z(i+1,j,k)-z(i-1,j,k))\\
\mathbf{B}=(0,2d,z(i,j+1,k)-z(i,j-1,k))\\
\mathbf{N}=(z(i-1,j,k)-z(i+1,j,k),z(i,j-1,k)-z(i,j+1,k), 2d) \tag{28.36}
\]
注意這裡T和B並沒有相互正交。
要意識到兩次模擬期間的時間間隔必須是恆定的,而不是依據幀間隔。不同遊戲執行幀數不同,因此在幀速率較高的情況下,必須採用一定的機制保證在經過足夠多的時間後才更新位置。
CPU計演算法
利用上述方式實現的波浪有兩種程式碼實現形式:
- 使用動態頂點緩衝區,模擬過程在CPU完成,然後結果寫入頂點緩衝區
- 通過計算著色器,將結果寫入位移貼圖(即紋理資料存放的是位移值,而不是顏色),然後在渲染的時候再利用它
其中前者的效率一般不如後者(在Debug模式下差別過於明顯,而在Release模式下好很多),但實現起來比較簡單。
這裡兩種方法都已經實現了,按順序講解。
基類WavesRender
基類WavesRender定義及Init過程如下:
class WavesRender
{
public:
template<class T>
using ComPtr = Microsoft::WRL::ComPtr<T>;
void SetMaterial(const Material& material);
void XM_CALLCONV SetWorldMatrix(DirectX::FXMMATRIX world);
UINT RowCount() const;
UINT ColumnCount() const;
protected:
// 不允許直接構造WavesRender,請從CpuWavesRender或GpuWavesRender構造
WavesRender() = default;
~WavesRender() = default;
// 不允許拷貝,允許移動
WavesRender(const WavesRender&) = delete;
WavesRender& operator=(const WavesRender&) = delete;
WavesRender(WavesRender&&) = default;
WavesRender& operator=(WavesRender&&) = default;
void Init(
UINT rows, // 頂點行數
UINT cols, // 頂點列數
float texU, // 紋理座標U方向最大值
float texV, // 紋理座標V方向最大值
float timeStep, // 時間步長
float spatialStep, // 空間步長
float waveSpeed, // 波速
float damping, // 粘性阻尼力
float flowSpeedX, // 水流X方向速度
float flowSpeedY); // 水流Y方向速度
protected:
UINT m_NumRows; // 頂點行數
UINT m_NumCols; // 頂點列數
UINT m_VertexCount; // 頂點數目
UINT m_IndexCount; // 索引數目
DirectX::XMFLOAT4X4 m_WorldMatrix; // 世界矩陣
DirectX::XMFLOAT2 m_TexOffset; // 紋理座標偏移
float m_TexU; // 紋理座標U方向最大值
float m_TexV; // 紋理座標V方向最大值
Material m_Material; // 水面材質
float m_FlowSpeedX; // 水流X方向速度
float m_FlowSpeedY; // 水流Y方向速度
float m_TimeStep; // 時間步長
float m_SpatialStep; // 空間步長
float m_AccumulateTime; // 累積時間
//
// 我們可以預先計算出來的常量
//
float m_K1;
float m_K2;
float m_K3;
};
void WavesRender::Init(UINT rows, UINT cols, float texU, float texV,
float timeStep, float spatialStep, float waveSpeed, float damping, float flowSpeedX, float flowSpeedY)
{
XMStoreFloat4x4(&m_WorldMatrix, XMMatrixIdentity());
m_NumRows = rows;
m_NumCols = cols;
m_TexU = texU;
m_TexV = texV;
m_TexOffset = XMFLOAT2();
m_VertexCount = rows * cols;
m_IndexCount = 6 * (rows - 1) * (cols - 1);
m_TimeStep = timeStep;
m_SpatialStep = spatialStep;
m_FlowSpeedX = flowSpeedX;
m_FlowSpeedY = flowSpeedY;
m_AccumulateTime = 0.0f;
float d = damping * timeStep + 2.0f;
float e = (waveSpeed * waveSpeed) * (timeStep * timeStep) / (spatialStep * spatialStep);
m_K1 = (damping * timeStep - 2.0f) / d;
m_K2 = (4.0f - 8.0f * e) / d;
m_K3 = (2.0f * e) / d;
}Init方法將公式(28.25)的三個重要引數先初始化,以供後續計算使用。
CPUWavesRender類
CPUWavesRender的定義如下:
class CpuWavesRender : public WavesRender
{
public:
CpuWavesRender() = default;
~CpuWavesRender() = default;
// 不允許拷貝,允許移動
CpuWavesRender(const CpuWavesRender&) = delete;
CpuWavesRender& operator=(const CpuWavesRender&) = delete;
CpuWavesRender(CpuWavesRender&&) = default;
CpuWavesRender& operator=(CpuWavesRender&&) = default;
HRESULT InitResource(ID3D11Device* device,
const std::wstring& texFileName, // 紋理檔名
UINT rows, // 頂點行數
UINT cols, // 頂點列數
float texU, // 紋理座標U方向最大值
float texV, // 紋理座標V方向最大值
float timeStep, // 時間步長
float spatialStep, // 空間步長
float waveSpeed, // 波速
float damping, // 粘性阻尼力
float flowSpeedX, // 水流X方向速度
float flowSpeedY); // 水流Y方向速度
void Update(float dt);
// 在頂點[i][j]處激起高度為magnitude的波浪
// 僅允許在1 < i < rows和1 < j < cols的範圍內激起
void Disturb(UINT i, UINT j, float magnitude);
// 繪製水面
void Draw(ID3D11DeviceContext* deviceContext, BasicEffect& effect);
void SetDebugObjectName(const std::string& name);
private:
std::vector<VertexPosNormalTex> m_Vertices; // 儲存當前模擬結果的頂點二維陣列的一維展開
std::vector<VertexPos> m_PrevSolution; // 儲存上一次模擬結果的頂點位置二維陣列的一維展開
ComPtr<ID3D11Buffer> m_pVertexBuffer; // 當前模擬的頂點緩衝區
ComPtr<ID3D11Buffer> m_pIndexBuffer; // 當前模擬的索引緩衝區
ComPtr<ID3D11ShaderResourceView> m_pTextureDiffuse; // 水面紋理
bool m_isUpdated; // 當前是否有頂點資料更新
};其中頂點的位置我們只保留了兩個副本,即當前模擬和上一次模擬的。而由於在計算出下一次模擬的結果後,我們就可以拋棄掉上一次模擬的結果。因此我們可以直接把結果寫在存放上一次模擬的位置,然後再進行交換即可。此時原本是當前模擬的資料則變成了上一次模擬的資料,而下一次模擬的結果則變成了當前模擬的資料。頂點的法向量只需要在完成了下一次模擬後再更新,因此也不需要多餘的副本了。
在使用CpuWavesRender之前固然是要呼叫InitResource先進行初始化的,但現在我們跳過這部分程式碼,直接看和演算法相關的幾個方法。
CpuWavesRender::Disturb方法--激起波浪
由於我們施加了邊界0的條件,因此不能對邊界區域激起波浪。在修改高度時,我們還對目標點的相鄰四個頂點也修改了高度使得一開始的波浪不會看起來太突兀:
void CpuWavesRender::Disturb(UINT i, UINT j, float magnitude)
{
// 不要對邊界處激起波浪
assert(i > 1 && i < m_NumRows - 2);
assert(j > 1 && j < m_NumCols - 2);
float halfMag = 0.5f * magnitude;
// 對頂點[i][j]及其相鄰頂點修改高度值
size_t curr = i * (size_t)m_NumCols + j;
m_Vertices[curr].pos.y += magnitude;
m_Vertices[curr - 1].pos.y += halfMag;
m_Vertices[curr + 1].pos.y += halfMag;
m_Vertices[curr - m_NumCols].pos.y += halfMag;
m_Vertices[curr + m_NumCols].pos.y += halfMag;
m_isUpdated = true;
}CpuWavesRender::Update方法--更新波浪
之前提到,兩次模擬期間的時間間隔必須是恆定的,而不是依據幀間隔。因此在設定好初始的時間步長後,每當經歷了大於時間步長的累積時間就可以進行更新了。同樣在更新過程中我們要始終限制邊界值為0。雖然公式複雜,但好在實現過程並不複雜。詳細見程式碼:
void CpuWavesRender::Update(float dt)
{
m_AccumulateTime += dt;
m_TexOffset.x += m_FlowSpeedX * dt;
m_TexOffset.y += m_FlowSpeedY * dt;
// 僅僅在累積時間大於時間步長時才更新
if (m_AccumulateTime > m_TimeStep)
{
m_isUpdated = true;
// 僅僅對內部頂點進行更新
for (size_t i = 1; i < m_NumRows - 1; ++i)
{
for (size_t j = 1; j < m_NumCols - 1; ++j)
{
// 在這次更新之後,我們將丟棄掉上一次模擬的資料。
// 因此我們將運算的結果儲存到Prev[i][j]的位置上。
// 注意我們能夠使用這種原址更新是因為Prev[i][j]
// 的資料僅在當前計算Next[i][j]的時候才用到
m_PrevSolution[i * m_NumCols + j].pos.y =
m_K1 * m_PrevSolution[i * m_NumCols + j].pos.y +
m_K2 * m_Vertices[i * m_NumCols + j].pos.y +
m_K3 * (m_Vertices[(i + 1) * m_NumCols + j].pos.y +
m_Vertices[(i - 1) * m_NumCols + j].pos.y +
m_Vertices[i * m_NumCols + j + 1].pos.y +
m_Vertices[i * m_NumCols + j - 1].pos.y);
}
}
// 由於把下一次模擬的結果寫到了上一次模擬的緩衝區內,
// 我們需要將下一次模擬的結果與當前模擬的結果交換
for (size_t i = 1; i < m_NumRows - 1; ++i)
{
for (size_t j = 1; j < m_NumCols - 1; ++j)
{
std::swap(m_PrevSolution[i * m_NumCols + j].pos, m_Vertices[i * m_NumCols + j].pos);
}
}
m_AccumulateTime = 0.0f; // 重置時間
// 使用有限差分法計算法向量
for (size_t i = 1; i < m_NumRows - 1; ++i)
{
for (size_t j = 1; j < m_NumCols - 1; ++j)
{
float left = m_Vertices[i * m_NumCols + j - 1].pos.y;
float right = m_Vertices[i * m_NumCols + j + 1].pos.y;
float top = m_Vertices[(i - 1) * m_NumCols + j].pos.y;
float bottom = m_Vertices[(i + 1) * m_NumCols + j].pos.y;
m_Vertices[i * m_NumCols + j].normal = XMFLOAT3(-right + left, 2.0f * m_SpatialStep, bottom - top);
XMVECTOR nVec = XMVector3Normalize(XMLoadFloat3(&m_Vertices[i * m_NumCols + j].normal));
XMStoreFloat3(&m_Vertices[i * m_NumCols + j].normal, nVec);
}
}
}
}CpuWavesRender::Draw方法--繪製波浪
這裡的繪製跟之前用的BasicEffect是可以直接適配的,動態頂點緩衝區的更新只需要在資料發生變化時再進行,以減少CPU向GPU的資料傳輸次數:
void CpuWavesRender::Draw(ID3D11DeviceContext* deviceContext, BasicEffect& effect)
{
// 更新動態緩衝區的資料
if (m_isUpdated)
{
m_isUpdated = false;
D3D11_MAPPED_SUBRESOURCE mappedData;
deviceContext->Map(m_pVertexBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData);
memcpy_s(mappedData.pData, m_VertexCount * sizeof(VertexPosNormalTex),
m_Vertices.data(), m_VertexCount * sizeof(VertexPosNormalTex));
deviceContext->Unmap(m_pVertexBuffer.Get(), 0);
}
UINT strides[1] = { sizeof(VertexPosNormalTex) };
UINT offsets[1] = { 0 };
deviceContext->IASetVertexBuffers(0, 1, m_pVertexBuffer.GetAddressOf(), strides, offsets);
deviceContext->IASetIndexBuffer(m_pIndexBuffer.Get(), DXGI_FORMAT_R32_UINT, 0);
effect.SetMaterial(m_Material);
effect.SetTextureDiffuse(m_pTextureDiffuse.Get());
effect.SetWorldMatrix(XMLoadFloat4x4(&m_WorldMatrix));
effect.SetTexTransformMatrix(XMMatrixScaling(m_TexU, m_TexV, 1.0f) * XMMatrixTranslationFromVector(XMLoadFloat2(&m_TexOffset)));
effect.Apply(deviceContext);
deviceContext->DrawIndexed(m_IndexCount, 0, 0);
}GPU計演算法
相比CPU計演算法,GPU計演算法的實現則更為複雜了。因為它不僅需要用到計算著色器,還需要跑到繪製基本物體的特效那邊做一些修改才能用。
HLSL程式碼
首先計算著色器部分完成的是激起波浪和更新波浪的部分,分為兩個函式:
// Waves.hlsli
// 用於更新模擬
cbuffer cbUpdateSettings : register(b0)
{
float g_WaveConstant0;
float g_WaveConstant1;
float g_WaveConstant2;
float g_DisturbMagnitude;
int2 g_DisturbIndex;
float2 g_Pad;
}
RWTexture2D<float> g_PrevSolInput : register(u0);
RWTexture2D<float> g_CurrSolInput : register(u1);
RWTexture2D<float> g_Output : register(u2);
// WavesDisturb_CS.hlsl
#include "Waves.hlsli"
[numthreads(1, 1, 1)]
void CS( uint3 DTid : SV_DispatchThreadID )
{
// 我們不需要進行邊界檢驗,因為:
// --讀取超出邊界的區域結果為0,和我們對邊界處理的需求一致
// --對超出邊界的區域寫入並不會執行
uint x = g_DisturbIndex.x;
uint y = g_DisturbIndex.y;
float halfMag = 0.5f * g_DisturbMagnitude;
// RW型資源允許讀寫,所以+=是允許的
g_Output[uint2(x, y)] += g_DisturbMagnitude;
g_Output[uint2(x + 1, y)] += halfMag;
g_Output[uint2(x - 1, y)] += halfMag;
g_Output[uint2(x, y + 1)] += halfMag;
g_Output[uint2(x, y - 1)] += halfMag;
}// WavesUpdate.hlsl
#include "Waves.hlsli"
[numthreads(16, 16, 1)]
void CS( uint3 DTid : SV_DispatchThreadID )
{
// 我們不需要進行邊界檢驗,因為:
// --讀取超出邊界的區域結果為0,和我們對邊界處理的需求一致
// --對超出邊界的區域寫入並不會執行
uint x = DTid.x;
uint y = DTid.y;
g_Output[uint2(x, y)] =
g_WaveConstant0 * g_PrevSolInput[uint2(x, y)].x +
g_WaveConstant1 * g_CurrSolInput[uint2(x, y)].x +
g_WaveConstant2 * (
g_CurrSolInput[uint2(x, y + 1)].x +
g_CurrSolInput[uint2(x, y - 1)].x +
g_CurrSolInput[uint2(x + 1, y)].x +
g_CurrSolInput[uint2(x - 1, y)].x);
}由於全部過程交給了GPU完成,現在我們需要有三個UAV,兩個用於輸入,一個用於輸出。並且由於我們指定了執行緒組內部包含16x16個執行緒,在C++初始化GpuWavesRender時,我們也應該指定行頂點數和列頂點數都為16的倍數。
此外,因為GPU對邊界外的良好定義,這使得我們不需要約束呼叫Disturb的索引條件。
緊接著就是要修改BasicEffect裡面用到的頂點著色器以支援計算著色器的位移貼圖:
#include "LightHelper.hlsli"
Texture2D g_DiffuseMap : register(t0); // 物體紋理
Texture2D g_DisplacementMap : register(t1); // 位移貼圖
SamplerState g_SamLinearWrap : register(s0); // 線性過濾+Wrap取樣器
SamplerState g_SamPointClamp : register(s1); // 點過濾+Clamp取樣器
cbuffer CBChangesEveryInstanceDrawing : register(b0)
{
matrix g_World;
matrix g_WorldInvTranspose;
matrix g_TexTransform;
}
cbuffer CBChangesEveryObjectDrawing : register(b1)
{
Material g_Material;
}
cbuffer CBChangesEveryFrame : register(b2)
{
matrix g_View;
float3 g_EyePosW;
float g_Pad;
}
cbuffer CBDrawingStates : register(b3)
{
float4 g_FogColor;
int g_FogEnabled;
float g_FogStart;
float g_FogRange;
int g_TextureUsed;
int g_WavesEnabled; // 開啟波浪繪製
float2 g_DisplacementMapTexelSize; // 位移貼圖兩個相鄰畫素對應頂點之間的x,y方向間距
float g_GridSpatialStep; // 柵格空間步長
}
cbuffer CBChangesOnResize : register(b4)
{
matrix g_Proj;
}
cbuffer CBChangesRarely : register(b5)
{
DirectionalLight g_DirLight[5];
PointLight g_PointLight[5];
SpotLight g_SpotLight[5];
}
struct VertexPosNormalTex
{
float3 PosL : POSITION;
float3 NormalL : NORMAL;
float2 Tex : TEXCOORD;
};
struct InstancePosNormalTex
{
float3 PosL : POSITION;
float3 NormalL : NORMAL;
float2 Tex : TEXCOORD;
matrix World : World;
matrix WorldInvTranspose : WorldInvTranspose;
};
struct VertexPosHWNormalTex
{
float4 PosH : SV_POSITION;
float3 PosW : POSITION; // 在世界中的位置
float3 NormalW : NORMAL; // 法向量在世界中的方向
float2 Tex : TEXCOORD;
};
然後是修改BasicObject_VS.hlsl。因為水面是單個物體,不需要改到BasicInstance_VS.hlsl裡面:
// BasicObject_VS.hlsl
#include "Basic.hlsli"
// 頂點著色器
VertexPosHWNormalTex VS(VertexPosNormalTex vIn)
{
VertexPosHWNormalTex vOut;
// 繪製水波時用到
if (g_WavesEnabled)
{
// 使用對映到[0,1]x[0,1]區間的紋理座標進行取樣
vIn.PosL.y += g_DisplacementMap.SampleLevel(g_SamLinearWrap, vIn.Tex, 0.0f).r;
// 使用有限差分法估算法向量
float du = g_DisplacementMapTexelSize.x;
float dv = g_DisplacementMapTexelSize.y;
float left = g_DisplacementMap.SampleLevel(g_SamPointClamp, vIn.Tex - float2(du, 0.0f), 0.0f).r;
float right = g_DisplacementMap.SampleLevel(g_SamPointClamp, vIn.Tex + float2(du, 0.0f), 0.0f).r;
float top = g_DisplacementMap.SampleLevel(g_SamPointClamp, vIn.Tex - float2(0.0f, dv), 0.0f).r;
float bottom = g_DisplacementMap.SampleLevel(g_SamPointClamp, vIn.Tex + float2(0.0f, dv), 0.0f).r;
vIn.NormalL = normalize(float3(-right + left, 2.0f * g_GridSpatialStep, bottom - top));
}
matrix viewProj = mul(g_View, g_Proj);
vector posW = mul(float4(vIn.PosL, 1.0f), g_World);
vOut.PosW = posW.xyz;
vOut.PosH = mul(posW, viewProj);
vOut.NormalW = mul(vIn.NormalL, (float3x3) g_WorldInvTranspose);
vOut.Tex = mul(float4(vIn.Tex, 0.0f, 1.0f), g_TexTransform).xy;
return vOut;
}可以看到,頂點y座標的值和法向量的計算都移步到了頂點著色器上。
因為我們對位移貼圖的取樣是要取出與當前頂點相鄰的4個頂點對應的4個畫素,故不能使用含有線性插值法的取樣器來取樣。因此我們還需要在RenderStates.h中新增點過濾+Clamp取樣:
ComPtr<ID3D11SamplerState> RenderStates::SSPointClamp = nullptr; // 取樣器狀態:點過濾與Clamp模式
// ...
D3D11_SAMPLER_DESC sampDesc;
ZeroMemory(&sampDesc, sizeof(sampDesc));
// 點過濾與Clamp模式
sampDesc.Filter = D3D11_FILTER_MIN_MAG_MIP_POINT;
sampDesc.AddressU = D3D11_TEXTURE_ADDRESS_CLAMP;
sampDesc.AddressV = D3D11_TEXTURE_ADDRESS_CLAMP;
sampDesc.AddressW = D3D11_TEXTURE_ADDRESS_CLAMP;
sampDesc.ComparisonFunc = D3D11_COMPARISON_NEVER;
sampDesc.MinLOD = 0;
sampDesc.MaxLOD = D3D11_FLOAT32_MAX;
HR(device->CreateSamplerState(&sampDesc, SSPointClamp.GetAddressOf()));
GpuWavesRender類
GpuWavesRender類定義如下:
class GpuWavesRender : public WavesRender
{
public:
GpuWavesRender() = default;
~GpuWavesRender() = default;
// 不允許拷貝,允許移動
GpuWavesRender(const GpuWavesRender&) = delete;
GpuWavesRender& operator=(const GpuWavesRender&) = delete;
GpuWavesRender(GpuWavesRender&&) = default;
GpuWavesRender& operator=(GpuWavesRender&&) = default;
// 要求頂點行數和列數都能被16整除,以保證不會有多餘
// 的頂點被劃入到新的執行緒組當中
HRESULT InitResource(ID3D11Device* device,
const std::wstring& texFileName, // 紋理檔名
UINT rows, // 頂點行數
UINT cols, // 頂點列數
float texU, // 紋理座標U方向最大值
float texV, // 紋理座標V方向最大值
float timeStep, // 時間步長
float spatialStep, // 空間步長
float waveSpeed, // 波速
float damping, // 粘性阻尼力
float flowSpeedX, // 水流X方向速度
float flowSpeedY); // 水流Y方向速度
void Update(ID3D11DeviceContext* deviceContext, float dt);
// 在頂點[i][j]處激起高度為magnitude的波浪
// 僅允許在1 < i < rows和1 < j < cols的範圍內激起
void Disturb(ID3D11DeviceContext* deviceContext, UINT i, UINT j, float magnitude);
// 繪製水面
void Draw(ID3D11DeviceContext* deviceContext, BasicEffect& effect);
void SetDebugObjectName(const std::string& name);
private:
struct {
DirectX::XMFLOAT4 waveInfo;
DirectX::XMINT4 index;
} m_CBUpdateSettings; // 對應Waves.hlsli的常量緩衝區
private:
ComPtr<ID3D11Texture2D> m_pNextSolution; // 快取下一次模擬結果的y值二維陣列
ComPtr<ID3D11Texture2D> m_pCurrSolution; // 儲存當前模擬結果的y值二維陣列
ComPtr<ID3D11Texture2D> m_pPrevSolution; // 儲存上一次模擬結果的y值二維陣列
ComPtr<ID3D11ShaderResourceView> m_pNextSolutionSRV; // 快取下一次模擬結果的y值著色器資源檢視
ComPtr<ID3D11ShaderResourceView> m_pCurrSolutionSRV; // 快取當前模擬結果的y值著色器資源檢視
ComPtr<ID3D11ShaderResourceView> m_pPrevSolutionSRV; // 快取上一次模擬結果的y值著色器資源檢視
ComPtr<ID3D11UnorderedAccessView> m_pNextSolutionUAV; // 快取下一次模擬結果的y值無序訪問檢視
ComPtr<ID3D11UnorderedAccessView> m_pCurrSolutionUAV; // 快取當前模擬結果的y值無序訪問檢視
ComPtr<ID3D11UnorderedAccessView> m_pPrevSolutionUAV; // 快取上一次模擬結果的y值無序訪問檢視
ComPtr<ID3D11Buffer> m_pVertexBuffer; // 當前模擬的頂點緩衝區
ComPtr<ID3D11Buffer> m_pIndexBuffer; // 當前模擬的索引緩衝區
ComPtr<ID3D11Buffer> m_pConstantBuffer; // 當前模擬的常量緩衝區
ComPtr<ID3D11ComputeShader> m_pWavesUpdateCS; // 用於計算模擬結果的著色器
ComPtr<ID3D11ComputeShader> m_pWavesDisturbCS; // 用於激起水波的著色器
ComPtr<ID3D11ShaderResourceView> m_pTextureDiffuse; // 水面紋理
};其中m_pNextSolution、m_pCurrSolution、m_pPrevSolution都為2D位移貼圖,它們不僅可能會作為計算著色器的輸入、輸出(UAV),還可能會作為提供給頂點著色器的位移y輸入用於計算(SRV)。
GpuWavesRender::Disturb方法--激起波浪
計算工作都交給GPU了,這裡CPU也就負責提供所需的內容,然後再排程計算著色器即可。最後一定要把繫結到CS的UAV撤下來,避免資源同時作為一個地方的輸入和另一個地方的輸出。
void GpuWavesRender::Disturb(ID3D11DeviceContext* deviceContext, UINT i, UINT j, float magnitude)
{
// 更新常量緩衝區
D3D11_MAPPED_SUBRESOURCE mappedData;
m_CBUpdateSettings.waveInfo = XMFLOAT4(0.0f, 0.0f, 0.0f, magnitude);
m_CBUpdateSettings.index = XMINT4(j, i, 0, 0);
deviceContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData);
memcpy_s(mappedData.pData, sizeof m_CBUpdateSettings, &m_CBUpdateSettings, sizeof m_CBUpdateSettings);
deviceContext->Unmap(m_pConstantBuffer.Get(), 0);
// 設定計算所需
deviceContext->CSSetShader(m_pWavesDisturbCS.Get(), nullptr, 0);
ID3D11UnorderedAccessView* m_UAVs[1] = { m_pCurrSolutionUAV.Get() };
deviceContext->CSSetConstantBuffers(0, 1, m_pConstantBuffer.GetAddressOf());
deviceContext->CSSetUnorderedAccessViews(2, 1, m_UAVs, nullptr);
deviceContext->Dispatch(1, 1, 1);
// 清除繫結
m_UAVs[0] = nullptr;
deviceContext->CSSetUnorderedAccessViews(2, 1, m_UAVs, nullptr);
}GpuWavesRender::Update方法--更新波浪
需要注意的是,這三個位移貼圖是迴圈使用的。排程完成之後,原本是上一次模擬的紋理將用於等待下一次模擬的輸出,而當前模擬的紋理則變成上一次模擬的紋理,下一次模擬的紋理則變成了當前模擬的紋理。這種迴圈交換方式稱之為Ping-Pong交換:
void GpuWavesRender::Update(ID3D11DeviceContext* deviceContext, float dt)
{
m_AccumulateTime += dt;
m_TexOffset.x += m_FlowSpeedX * dt;
m_TexOffset.y += m_FlowSpeedY * dt;
// 僅僅在累積時間大於時間步長時才更新
if (m_AccumulateTime > m_TimeStep)
{
// 更新常量緩衝區
D3D11_MAPPED_SUBRESOURCE mappedData;
m_CBUpdateSettings.waveInfo = XMFLOAT4(m_K1, m_K2, m_K3, 0.0f);
deviceContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData);
memcpy_s(mappedData.pData, sizeof m_CBUpdateSettings, &m_CBUpdateSettings, sizeof m_CBUpdateSettings);
deviceContext->Unmap(m_pConstantBuffer.Get(), 0);
// 設定計算所需
deviceContext->CSSetShader(m_pWavesUpdateCS.Get(), nullptr, 0);
deviceContext->CSSetConstantBuffers(0, 1, m_pConstantBuffer.GetAddressOf());
ID3D11UnorderedAccessView* pUAVs[3] = { m_pPrevSolutionUAV.Get(), m_pCurrSolutionUAV.Get(), m_pNextSolutionUAV.Get() };
deviceContext->CSSetUnorderedAccessViews(0, 3, pUAVs, nullptr);
// 開始排程
deviceContext->Dispatch(m_NumCols / 16, m_NumRows / 16, 1);
// 清除繫結
pUAVs[0] = pUAVs[1] = pUAVs[2] = nullptr;
deviceContext->CSSetUnorderedAccessViews(0, 3, pUAVs, nullptr);
//
// 對緩衝區進行Ping-pong交換以準備下一次更新
// 上一次模擬的緩衝區不再需要,用作下一次模擬的輸出緩衝
// 當前模擬的緩衝區變成上一次模擬的緩衝區
// 下一次模擬的緩衝區變換當前模擬的緩衝區
//
auto resTemp = m_pPrevSolution;
m_pPrevSolution = m_pCurrSolution;
m_pCurrSolution = m_pNextSolution;
m_pNextSolution = resTemp;
auto srvTemp = m_pPrevSolutionSRV;
m_pPrevSolutionSRV = m_pCurrSolutionSRV;
m_pCurrSolutionSRV = m_pNextSolutionSRV;
m_pNextSolutionSRV = srvTemp;
auto uavTemp = m_pPrevSolutionUAV;
m_pPrevSolutionUAV = m_pCurrSolutionUAV;
m_pCurrSolutionUAV = m_pNextSolutionUAV;
m_pNextSolutionUAV = uavTemp;
m_AccumulateTime = 0.0f; // 重置時間
}
}GpuWavesRender::Draw方法--繪製波浪
跟CPU的繪製區別基本上就在註釋部分了:
void GpuWavesRender::Draw(ID3D11DeviceContext* deviceContext, BasicEffect& effect)
{
UINT strides[1] = { sizeof(VertexPosNormalTex) };
UINT offsets[1] = { 0 };
deviceContext->IASetVertexBuffers(0, 1, m_pVertexBuffer.GetAddressOf(), strides, offsets);
deviceContext->IASetIndexBuffer(m_pIndexBuffer.Get(), DXGI_FORMAT_R32_UINT, 0);
effect.SetWavesStates(true, 1.0f / m_NumCols, 1.0f / m_NumCols, m_SpatialStep); // 開啟波浪繪製
effect.SetMaterial(m_Material);
effect.SetTextureDiffuse(m_pTextureDiffuse.Get());
effect.SetTextureDisplacement(m_pCurrSolutionSRV.Get()); // 需要額外設定位移貼圖
effect.SetWorldMatrix(XMLoadFloat4x4(&m_WorldMatrix));
effect.SetTexTransformMatrix(XMMatrixScaling(m_TexU, m_TexV, 1.0f) * XMMatrixTranslationFromVector(XMLoadFloat2(&m_TexOffset)));
effect.Apply(deviceContext);
deviceContext->DrawIndexed(m_IndexCount, 0, 0);
effect.SetTextureDisplacement(nullptr); // 解除佔用
effect.SetWavesStates(false); // 關閉波浪繪製
effect.Apply(deviceContext);
}演示
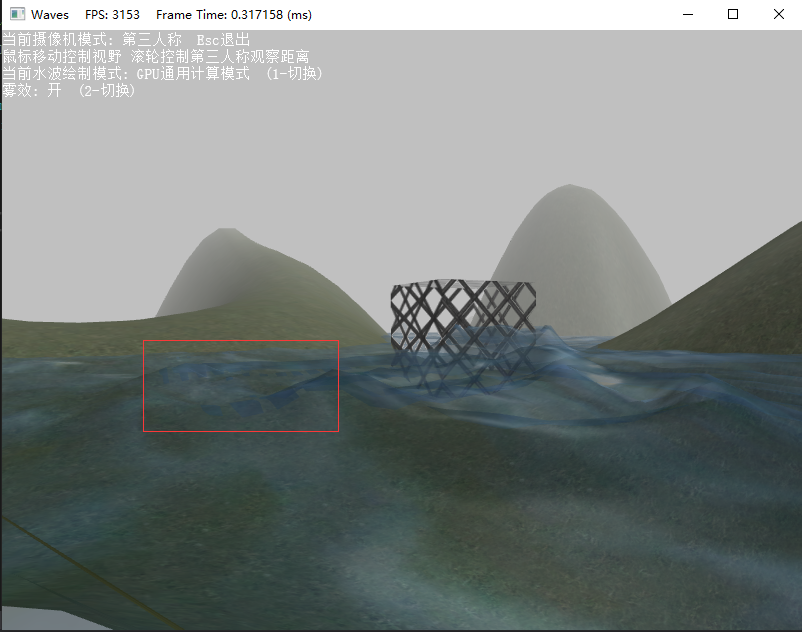
從這一章開始我帶著我的光追顯示卡來跑渲染效果了(相比以前的整合顯示卡),幀數會有明顯的提升
下圖演示了GPU繪製的水波效果。由於限制了10M上傳,只能勉強看到這一小段了。

測試幀數如下:
| GPU通用計算模式 | CPU動態更新模式 | |
|---|---|---|
| Debug x64模式 | 3500 | 27 |
| Release x64模式 | 4200 | 3900 |
Debug的話又是vector那邊惹出的問題,忽略不計。
只不過當前的樣例跟龍書的樣例都沒有處理好視角帶來的過度混合問題,個人暫時也沒有解決的辦法:
練習題
- 不要在山體高於水面的頂點激起波浪。
- 修改波浪的初始引數,觀察效果上有什麼不同。
參考資料
本文的演算法實現參考的是 Mathematics for 3D Game Programming and Computer Graphics, Third Edition,書內頁碼443開始。群內可以下載。
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什麼問題也可以在這裡彙報