
Paper慢慢讀 - AB實驗人群定向 Double Machine Learning
Hetergeneous Treatment Effect旨在量化實驗對不同人群的差異影響,進而通過人群定向/數值策略的方式進行差異化實驗,或者對實驗進行調整。Double Machine Learning把Treatment作為特徵,通過估計特徵對目標的影響來計算實驗的差異效果。
Machine Learning擅長給出精準的預測,而經濟學更注重特徵對目標影響的無偏估計。DML把經濟學的方法和機器學習相結合,在經濟學框架下用任意的ML模型給出特徵對目標影響的無偏估計
HTE其他方法流派詳見因果推理的春天-實用HTE論文GitHub收藏
核心論文
V. Chernozhukov, D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, and a. W. Newey. Double Machine Learning for Treatment and Causal Parameters. ArXiv e-prints 文章連結
背景
HTE問題可以用以下的notation進行簡單的抽象
- Y是實驗影響的核心指標
- T是treatment,通常是0/1變數,代表樣本進入實驗組還是對照組,對隨機AB實驗\(T \perp X\)
- X是Confounder,可以簡單理解為未被實驗干預過的使用者特徵,通常是高維向量
- DML最終估計的是\(\theta(x)\),也就是實驗對不同使用者核心指標的不同影響
\[ \begin{align} Y &= \theta(x) T + g(X) + \epsilon &\text{where }E(\epsilon |T,X) = 0 \\ T &= f(X) + \eta &\text{where } E(\eta|X) = 0 \\ \end{align} \]
最直接的方法就是用X和T一起對Y建模,直接估計\(\theta(x)\)。但這樣估計出的\(\theta(x)\)往往是有偏的,偏差部分來自於對樣本的過擬合,部分來自於\(\hat{g(X)}\)估計的偏差,假定\(\theta_0\)是引數的真實值,則偏差如下
\[ \sqrt{n}(\hat{\theta}-\theta_0) = (\frac{1}{n}\sum{T_i^2})^{-1}\frac{1}{\sqrt{n}}\sum{T_iU_i} +(\frac{1}{n}\sum{T_i^2})^{-1}(\frac{1}{\sqrt{n}}\sum{T_i(g(x_i) -\hat{g(x_i)})}) \]
DML模型
DML模型分為以下三個步驟
步驟一. 用任意ML模型擬合Y和T得到殘差\(\tilde{Y},\tilde{T}\)
\[ \begin{align} \tilde{Y} &= Y - l(x) &\text{ where } l(x) = E(Y|x)\\ \tilde{T} &= T - m(x) &\text{ where } m(x) = E(T|x)\\ \end{align} \]
步驟二. 對\(\tilde{Y},\tilde{T}\)用任意ML模型擬合\(\hat{\theta}\)
\(\theta(X)\)的擬合可以是引數模型也可以是非引數模型,引數模型可以直接擬合。而非引數模型因為只接受輸入和輸出所以需要再做如下變換,模型Target變為\(\frac{\tilde{Y}}{\tilde{T}}\), 樣本權重為\(\tilde{T}^2\)
\[ \begin{align} & \tilde{Y} = \theta(x)\tilde{T} + \epsilon \\ & argmin E[(\tilde{Y} - \theta(x) \cdot \tilde{T} )^2]\\ &E[(\tilde{Y} - \theta(x) \cdot \tilde{T} )^2] = E(\tilde{T}^2(\frac{\tilde{Y}}{\tilde{T}} - \theta(x))^2) \end{align} \]
步驟三. Cross-fitting
DML保證估計無偏很重要的一步就是Cross-fitting,用來降低overfitting帶來的估計偏差。先把總樣本分成兩份:樣本1,樣本2。先用樣本1估計殘差,樣本2估計\(\hat{\theta}^1\),再用樣本2估計殘差,樣本1估計$ \hat{\theta}^2$,取平均得到最終的估計。當然也可以進一步使用K-Fold來增加估計的穩健性。
\[
\begin{align}
sample_1, sample_2 &= \text{sample_split} \\
\theta &= \hat{\theta}^1 + \hat{\theta}^2 \\
\end{align}
\]
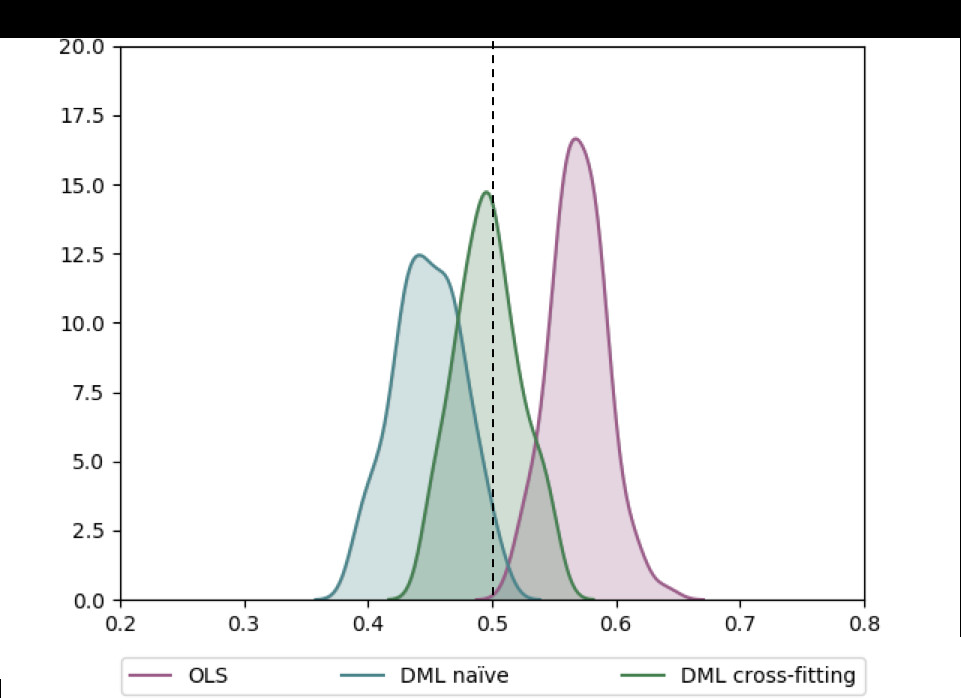
Jonas在他的部落格裡比較了不使用DML,使用DML但是不用Cross-fitting,以及使用Cross-fitting的估計效果如下
從GMM的角度來理解
Generalized Method of Moments廣義矩估計 (GMM)在經濟學領域用的更多,在論文裡乍一看到moment condition琢磨半天也沒想起來,索性在這裡簡單的回顧下GMM的內容。
啥是矩估計呢?可以簡單理解是用樣本的分佈特徵來估計總計分佈,分佈特徵由\(E((x-a)^K)\),樣本的K階矩來抽象,一階矩就是均值,二階原點矩就是方差。舉幾個例子吧~
例如,總體樣本服從\(N(\mu, \sigma^2)\)就有兩個引數需要估計,那麼就需要兩個方程來解兩個未知數,既一階矩條件\(\sum{x_i}-\mu=0\)和二階矩條件\(\sum{x_i^2} - \mu^2 - \sigma^2=0\)。
再例如OLS,\(Y=\beta X\)可以用最小二乘法來求解\(argmin (Y-\beta X)^2\),但同樣可以用矩估計來求解\(E(X(Y-\beta X))=0\)。實則最小二乘只是GMM的一個特例。
那針對HTE問題,我們應該選擇什麼樣的矩條件來估計\(\theta\)呢?
直接估計\(\theta\)的矩條件如下
\(E(T(Y-T\theta_0-\hat{g_0(x)}))=0\)
DML基於殘差估計的矩條件如下
\(E([(Y-E(Y|X))-(T-E(T|X))\theta_0](T-E(T|X)))=0\)
作者指出DML的矩條件服從Neyman orthogonality條件,因此即便\(g(x)\)估計有偏,依舊可以得到無偏的\(\theta\)的估計。
參考材料&開原始碼
- V. Chernozhukov, M. Goldman, V. Semenova, and M. Taddy. Orthogonal Machine Learning for Demand Estimation: High Dimensional Causal Inference in Dynamic Panels. ArXiv e-prints, December 2017.
- V. Chernozhukov, D. Nekipelov, V. Semenova, and V. Syrgkanis. Two-Stage Estimation with a High-Dimensional Second Stage. 2018.
- Microsoft 因果推理開原始碼 EconML
- Double Machine Learning 開原始碼 MLInference
- https://www.linkedin.com/pulse/double-machine-learning-approximately-unbiased-jonas-vetterle/
- https://www.zhihu.com/question/41312883