
武漢新型冠狀病毒 - 資料採集、模型預測
關於武漢新型冠狀病毒的資料採集、模型預測
武漢加油、湖北加油、中國加油!!!
專案背景
2020年開年爆發的武漢新型冠狀病毒,新的一年相信對於大家來說都是地獄模式開局,對於我本人也是如此,打亂了很多計劃,有些不知所措,但是災難面前,唯有同舟共濟,對此我個人是樂觀的,中華民族是不服輸的民族,上下5000年曆史,比這大的災難比比皆是,但是我們依然屹立於此,依然活躍於世界舞臺,這充分證明了中華民族的韌性,中國萬歲;
之前看到丁香園上有實時的動態資料,就想著拉下來進行分析挖掘預測,第一版之前跑了兩天後停止了,因為當時資料格式變化比較大,從2月5號開始第二版資料採集指令碼,指令碼很簡單,目前採集間隔是10分鐘,不是每10分鐘都會採集,這取決於資料是否有變動,這裡主要展示資料採集指令碼以及一個簡單的基於prophet的確診、疑似、死亡、治癒的預測;
資料採集
資料基於丁香園的實時動態資料,感謝資料展示分享,對於大家瞭解疫情的實時情況真的幫助很大,各種資料視覺化展示,大家也可以點進去看看,做的還是比較精細的,顆粒度最低可以到某個市的某個區,這也證明中國目前在全國統籌方面的能力在日益完善,當然還有很長的路要走,畢竟咱們的目標是星辰大海;
採集方式:主要資料分兩部分,一部分是全國的整體情況,一部分是各省市情況,這兩部分都處於script元素內,因此其實只需要找到對應的script元素,對於內容文字做擷取後,轉為json物件即可直接讀取內部內容,而整體結構也是簡潔明瞭,相信大家都能搞定的,下面是我的採集指令碼,可以直接copy執行的,大家需要注意的主要以下幾個點:1. 首先同級目錄建立data_new資料夾,2. 一些註釋要開啟,主要是兩部分註釋是給csv檔案寫頭行的,所以我寫過一次就註釋了,第一次執行需要開啟,後續註釋掉就行,我主要獲取五類資料:城市名、確診數、疑似數(這個只在全國部分有,各省市是沒有的)、死亡數、治癒數;
#!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup as BS import json import time import sys,os reload(sys) sys.setdefaultencoding('utf-8') while(True): try: r = requests.get('https://3g.dxy.cn/newh5/view/pneumonia_peopleapp?from=timeline&isappinstalled=0') soup = BS(r.content, 'html.parser') _cn_data = soup.find('script',id='getStatisticsService').get_text() _s = _cn_data.index('{', _cn_data.index('{')+1) _e = _cn_data.index('catch')-1 _china = json.loads(_cn_data[_s:_e]) _timestamp = _china['modifyTime'] _cc,_sc,_dc,_cuc = _china['confirmedCount'],_china['suspectedCount'],_china['deadCount'],_china['curedCount'] print _timestamp,_cc,_sc,_dc,_cuc if open('data_new/湖北省.csv').readlines()[-1].split(',')[0]==str(_timestamp): #if False: print('data not flush') else: #row = 'timestamp,confirmedCount,suspectedCount,curedCount,deadCount' #os.system('echo '+row+' >> data_new/中國.csv') row = ','.join([str(_timestamp),str(_cc),str(_sc),str(_cuc),str(_dc)]) os.system('echo '+row+' >> data_new/中國.csv') _data = soup.find('script',id='getAreaStat').get_text() _data = _data[_data.find('['):_data.rfind(']')+1] _provinces = json.loads(_data) for _province in _provinces: print _timestamp,_province['provinceName'],_province['provinceShortName'],_province['confirmedCount'],_province['suspectedCount'],_province['curedCount'],_province['deadCount'],len(_province['cities']) _fn = _province['provinceName']+'.csv' #row = 'timestamp,provinceName,cityName,confirmedCount,suspectedCount,curedCount,deadCount,locationId' #os.system('echo '+row+' >> data_new/'+_fn) for _city in _province['cities']: row = ','.join([str(_timestamp),_province['provinceName'],_city['cityName'],str(_city['confirmedCount']),str(_city['suspectedCount']),str(_city['curedCount']),str(_city['deadCount']),str(_city['locationId'])]) os.system('echo '+row+' >> data_new/'+_fn) except Exception as e: print(e) pass time.sleep(60*10) # 10分鐘flush一次
再次感謝丁香園的同學們,對於資料沒有做太多保護處理,當然希望大家能夠妥善使用;
疫情資料分析
這部分的程式碼在這裡,大家可以隨便取之食用,用的資料是WHO釋出的全球資料,顆粒度是天,單位是省,分析主要是兩部分第一部分是中國各省情況,第二部分是中國整體情況;
中國各省情況 - 確診人數、死亡/確診、治癒/確診
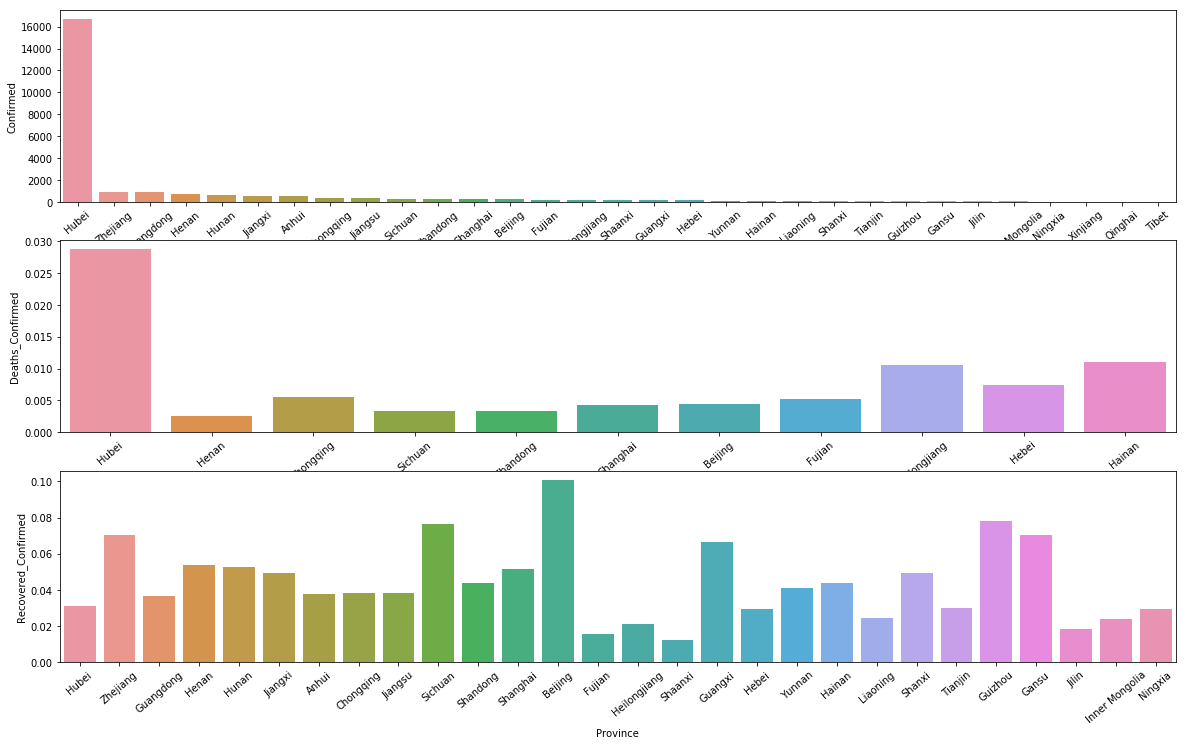
可以看到,死亡率最高的依然是湖北,不得不說,這次國家採取的措施對於全國、世界是好事,但是對於整個湖北、武漢人民卻承受了太多太多,我想大家都欠他們一聲“你們辛苦了”;
中國整體趨勢 - 確診、死亡、治癒的趨勢圖,死亡率、治癒率、死亡/治癒
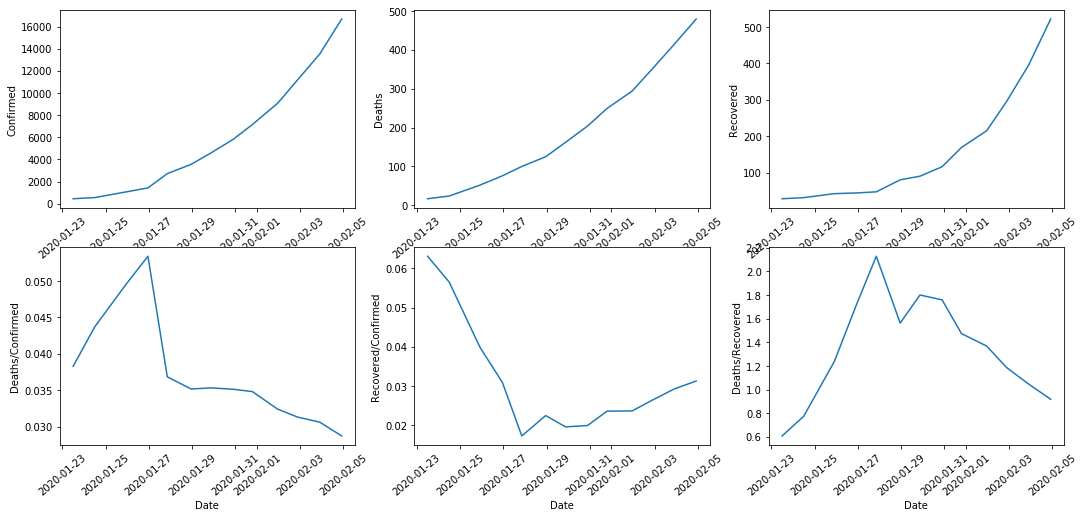
可以看到,確診、死亡、治癒人數曲線圖依然沒有緩和的趨勢,但是好訊息是治癒率在上升,而死亡率在下降,這一點從死亡/治癒的先升後降中也能看到;
確診、疑似、死亡、治癒預測
這裡我只用到了全國的總資料做預測,實際上因為指令碼獲取的也有各城市的情況,大家一樣可以對資料來源做一點點修改,就可以做大家感興趣(比如家鄉、工作地、女朋友所在地)等做預測了,還有一個問題需要大家注意,瀏覽資料時會看到資料有一個跳變的過程,這是因為丁香園的資料來源於國家相關部分,而這些資料的釋出應該是有固定時間點的,所以會出現兩個相鄰資料之間,突然增長了一大段的情況,正常,不需要太驚訝;
全國確診人數實際情況(2020/02/05到2020/02/09)+預測(實際資料後24小時)
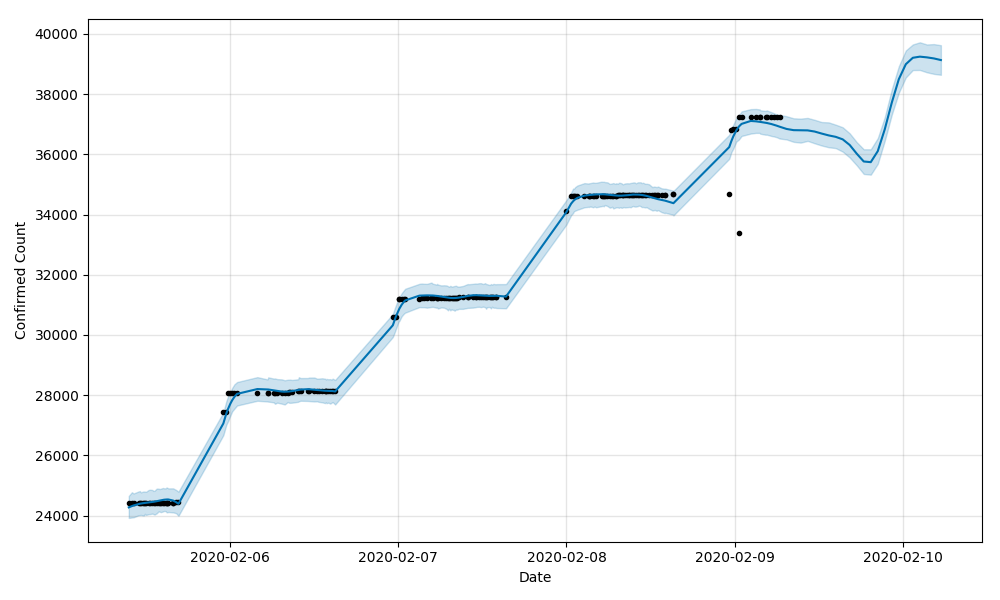
橫座標是時間,縱座標是人數,右側沒有點的部分的線就是往後24小時的預測人數,可以看到明顯的階梯狀,這個我看了資料後大概是這麼理解的,只有治癒人數是一天內多次有效更新的,其他確診、疑似、死亡基本一天內的資料變動不大,所以看起來會有階梯狀;
疑似
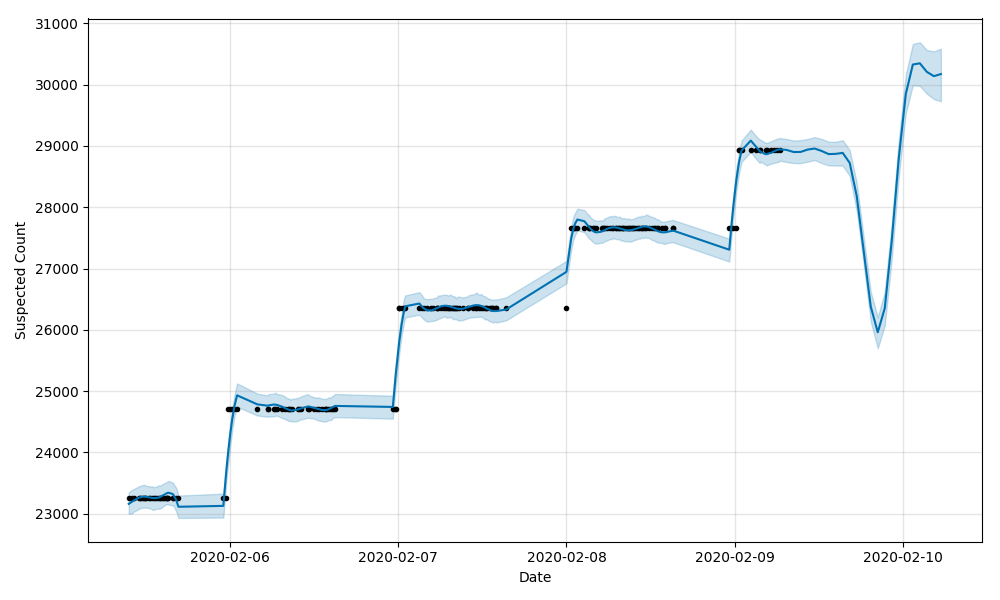
死亡
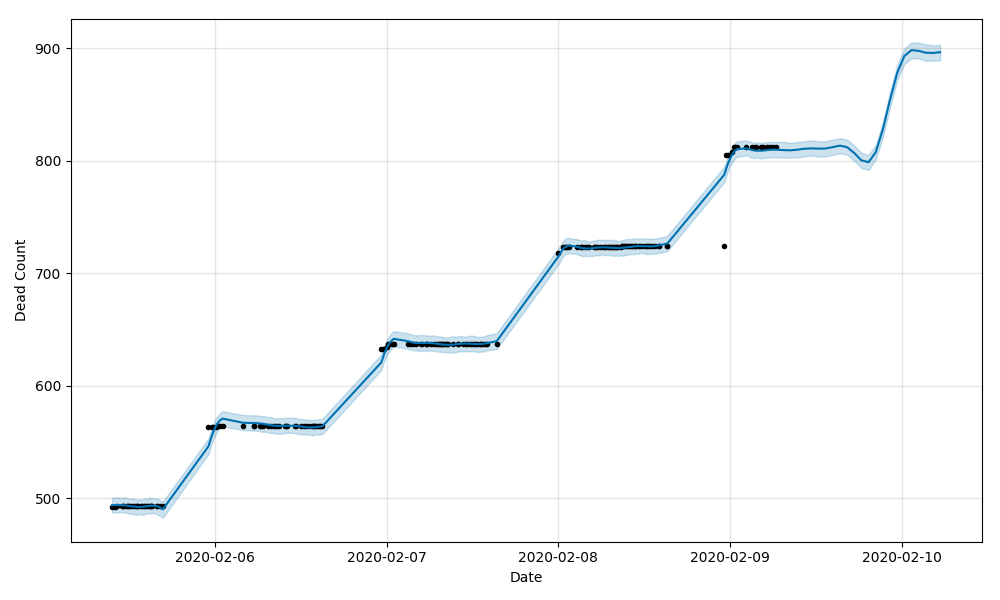
治癒

把治癒的情況放到了最後,是想強調一下,大家對這次疫情要有足夠的信心,看目前的資料上升趨勢,情況正在逐步得到控制,當然也不可以掉以輕心,隔離依然是最最重要且有效的手段,每個人都做好自己的工作,我相信疫情結束的那一天很快就會到來;
預測部分的程式碼
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
df_train = pd.read_csv('./中國.csv', parse_dates=['timestamp'])
df_train['timestamp'] = df_train['timestamp'].apply(lambda ts:pd.Timestamp(int(ts), unit='ms'))
#df_train.sort_values(['timestamp'],inplace=True)
# confirmedCount
df_train_confirmed = df_train[['timestamp','confirmedCount']].copy()
df_train_confirmed = df_train_confirmed.rename(index=str, columns={"timestamp": "ds", "confirmedCount": "y"})
# suspectedCount
df_train_suspected = df_train[['timestamp','suspectedCount']].copy()
df_train_suspected = df_train_suspected.rename(index=str, columns={"timestamp": "ds", "suspectedCount": "y"})
# deadCount
df_train_dead = df_train[['timestamp','deadCount']].copy()
df_train_dead = df_train_dead.rename(index=str, columns={"timestamp": "ds", "deadCount": "y"})
# curedCount
df_train_cured = df_train[['timestamp','curedCount']].copy()
df_train_cured = df_train_cured.rename(index=str, columns={"timestamp": "ds", "curedCount": "y"})
# test
df_test = pd.DataFrame({})
df_test['ds'] = pd.date_range(start=df_train_confirmed.ds.max(), freq="H", periods=24)
m = Prophet()
#m.fit(df_train_confirmed)
#m.fit(df_train_suspected)
#m.fit(df_train_dead)
m.fit(df_train_cured)
forecast = m.predict(pd.concat([df_train_confirmed[['ds']],df_test[['ds']]]))
#print forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
m.plot(forecast)
plt.xlabel('Date')
plt.ylabel('Cured Count')
plt.show()最後
引用一句WHO的話:
We must remember that these are people, not numbers.
翻譯過來意思是:我們必須記住這不是數字,而是人。
希望疫情結束後,每個人都能見到自己的親人、朋友、同事、每一個自己關心的人,能夠給他們一個擁抱,謝謝他們還能陪伴自己,謝謝他們沒有拋下自己。
最後的最後
大家可以到我的Github上看看有沒有其他需要的東西,目前主要是自己做的機器學習專案、Python各種指令碼工具、資料分析挖掘專案以及Follow的大佬、Fork的專案等:
https://github.com/NemoHoHaloAi