
面試官系列,深入資料庫分割槽分庫分表
一、為什麼要分庫分表
軟體時代,傳統應用都有這樣一個特點:訪問量、資料量都比較小,單庫單表都完全可以支撐整個業務。隨著網際網路的發展和使用者規模的迅速擴大,對系統的要求也越來越高。因此傳統的MySQL單庫單表架構的效能問題就暴露出來了。而有下面幾個因素會影響資料庫效能:
- 資料量
MySQL單庫資料量在5000萬以內效能比較好,超過閾值後效能會隨著資料量的增大而變弱。MySQL單表的資料量是500w-1000w之間效能比較好,超過1000w效能也會下降。
- 磁碟
因為單個服務的磁碟空間是有限制的,如果併發壓力下,所有的請求都訪問同一個節點,肯定會對磁碟IO造成非常大的影響。
- 資料庫連線
資料庫連線是非常稀少的資源,如果一個庫裡既有使用者、商品、訂單相關的資料,當海量使用者同時操作時,資料庫連線就很可能成為瓶頸。
為了提升效能,所以我們必須要解決上述幾個問題,那就有必要引進分庫分表,當然除了分庫分表,還有別的解決方案,就是NoSQL和NewSQL,NoSQL主要是MongoDB等,NewSQL則以TiDB為代表。
二、分割槽分庫分表的原理
1、什麼是分割槽、分表、分庫
(1)分割槽
就是把一張表的資料分成N個區塊,在邏輯上看最終只是一張表,但底層是由N個物理區塊組成的,分割槽實現比較簡單,資料庫mysql、oracle等很容易就可支援。
(2)分表
就是把一張表按一定的規則分解成N個具有獨立儲存空間的實體表。系統讀寫時需要根據定義好的規則得到對應的字表明,然後操作它。
(3)分庫
一旦分表,一個庫中的表會越來越多,將整個資料庫比作圖書館,一張表就是一本書。當要在一本書中查詢某項內容時,如果不分章節,查詢的效率將會下降。而同理,在資料庫中就是分割槽。
2、什麼時候使用分割槽?
一張表的查詢速度已經慢到影響使用的時候。
- sql經過優化
- 資料量大
- 表中的資料是分段的
- 對資料的操作往往只涉及一部分資料,而不是所有的資料
最常見的分割槽方法就是按照時間進行分割槽,分割槽一個最大的優點就是可以非常高效的進行歷史資料的清理。
(1)分割槽的實現方式
mysql5自5.1開始對分割槽(Partition)有支援。
(2)分割槽型別
目前MySQL支援範圍分割槽(RANGE),列表分割槽(LIST),雜湊分割槽(HASH)以及KEY分割槽四種。
(3)RANGE分割槽例項
基於屬於一個給定連續區間的列值,把多行分配給分割槽。最常見的是基於時間欄位. 基於分割槽的列最好是整型,如果日期型的可以使用函式轉換為整型。本例中使用to_days函式。
CREATE TABLE my_range_datetime(
id INT,
hiredate DATETIME
)
PARTITION BY RANGE (TO_DAYS(hiredate) ) (
PARTITION p1 VALUES LESS THAN ( TO_DAYS('20171202') ),
PARTITION p2 VALUES LESS THAN ( TO_DAYS('20171203') ),
PARTITION p3 VALUES LESS THAN ( TO_DAYS('20171204') ),
PARTITION p4 VALUES LESS THAN ( TO_DAYS('20171205') ),
PARTITION p5 VALUES LESS THAN ( TO_DAYS('20171206') ),
PARTITION p6 VALUES LESS THAN ( TO_DAYS('20171207') ),
PARTITION p7 VALUES LESS THAN ( TO_DAYS('20171208') ),
PARTITION p8 VALUES LESS THAN ( TO_DAYS('20171209') ),
PARTITION p9 VALUES LESS THAN ( TO_DAYS('20171210') ),
PARTITION p10 VALUES LESS THAN ( TO_DAYS('20171211') ),
PARTITION p11 VALUES LESS THAN (MAXVALUE)
);3、什麼時候分表?
一張表的查詢速度已經慢到影響使用的時候。
- sql經過優化
- 資料量大
- 當頻繁插入或者聯合查詢時,速度變慢
分表後,單表的併發能力提高了,磁碟I/O效能也提高了,寫操作效率提高了
(1)分表的實現方式
需要結合相關中介軟體,需要業務系統配合遷移升級,工作量較大。
三、分庫分表後引入的問題
1、分散式事務問題
如果我們做了垂直分庫或者水平分庫以後,就必然會涉及到跨庫執行SQL的問題,這樣就引發了網際網路界的老大難問題-"分散式事務"。那要如何解決這個問題呢?
1.使用分散式事務中介軟體 2.使用MySQL自帶的針對跨庫的事務一致性方案(XA),不過效能要比單庫的慢10倍左右。3.能否避免掉跨庫操作(比如將使用者和商品放在同一個庫中)
2、跨庫join的問題
分庫分表後表之間的關聯操作將受到限制,我們無法join位於不同分庫的表,也無法join分表粒度不同的表, 結果原本一次查詢能夠完成的業務,可能需要多次查詢才能完成。粗略的解決方法: 全域性表:基礎資料,所有庫都拷貝一份。 欄位冗餘:這樣有些欄位就不用join去查詢了。 系統層組裝:分別查詢出所有,然後組裝起來,較複雜。
3、橫向擴容的問題
當我們使用HASH取模做分表的時候,針對資料量的遞增,可能需要動態的增加表,此時就需要考慮因為reHash導致資料遷移的問題。
4、結果集合並、排序的問題
因為我們是將資料分散儲存到不同的庫、表裡的,當我們查詢指定資料列表時,資料來源於不同的子庫或者子表,就必然會引發結果集合並、排序的問題。如果每次查詢都需要排序、合併等操作,效能肯定會受非常大的影響。走快取可能一條路!
四、分庫分表中介軟體設計
分表又分為單庫分表(表名不同)和多庫分表(表名相同),不管使用哪種策略都還需要自己去實現路由,制定路由規則等,可以考慮使用開源的分庫分表中介軟體,無侵入應用設計,例如淘寶的tddl等。
分庫分表中介軟體全部可以歸結為兩大型別:
- CLIENT模式;
- PROXY模式;
CLIENT模式代表有阿里的TDDL,開源社群的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已經支援了proxy模式)。
架構如下:

PROXY模式代表有阿里的cobar,民間組織的MyCAT。架構如下:
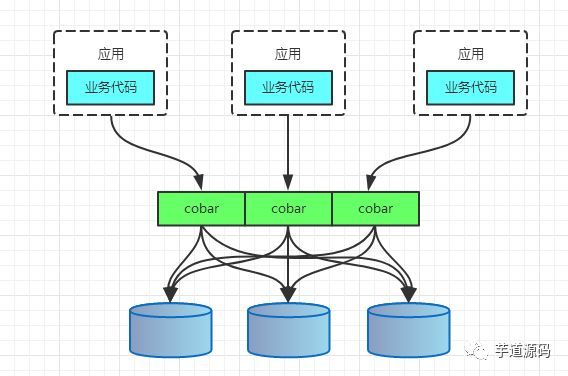
無論是CLIENT模式,還是PROXY模式。幾個核心的步驟是一樣的:SQL解析,重寫,路由,執行,結果歸併。
五、分庫分表常用中介軟體
目前應用比較多的基本有以下幾種,
- TDDL
- Sharding-jdbc
- Mycat
- Cobar
1、TDDL
淘寶團隊開發的,屬於 client 層方案。支援基本的 crud 語法和讀寫分離,但不支援 join、多表查詢等語法。
2、Sharding-jdbc
噹噹開源的,屬於 client 層方案,目前已經更名為 ShardingSphere。SQL 語法支援也比較多,沒有太多限制,支援分庫分表、讀寫分離、分散式 id 生成、柔性事務(最大努力送達型事務、TCC 事務)。
3、Cobar
阿里 b2b 團隊開發和開源的,屬於 proxy 層方案,就是介於應用伺服器和資料庫伺服器之間。應用程式通過 JDBC 驅動訪問 Cobar 叢集,Cobar 根據 SQL 和分庫規則對 SQL 做分解,然後分發到 MySQL 叢集不同的資料庫例項上執行。
4、Mycat
基於 Cobar 改造的,屬於 proxy 層方案,支援的功能完善,社群活躍。
六、常見分表、分庫常用策略
- 平均進行分配hash(object)%N(適用於簡單架構)。
- 按照權重進行分配且均勻輪詢。
- 按照業務進行分配。
- 按照一致性hash演算法進行分配(適用於叢集架構,在叢集中節點的新增和刪除不會造成資料丟失,方便資料遷移)。
七、全域性ID生成策略
1、自動增長列
優點:資料庫自帶功能,有序,效能佳。
缺點:單庫單表無妨,分庫分表時如果沒有規劃,ID可能重複。
解決方案,一個是設定自增偏移和步長。
- 假設總共有 10 個分表
- 級別可選: SESSION(會話級), GLOBAL(全域性)
- SET @@SESSION.auto_increment_offset = 1; ## 起始值, 分別取值為 1~10
- SET @@SESSION.auto_increment_increment = 10; ## 步長增量
如果採用該方案,在擴容時需要遷移已有資料至新的所屬分片。
另一個是全域性ID對映表。
- 在全域性 Redis 中為每張資料表建立一個 ID 的鍵,記錄該表當前最大 ID;
- 每次申請 ID 時,都自增 1 並返回給應用;
- Redis 要定期持久至全域性資料庫。
2、UUID(128位)
在一臺機器上生成的數字,它保證對在同一時空中的所有機器都是唯一的。通常平臺會提供生成UUID的API。
UUID 由4個連字號(-)將32個位元組長的字串分隔後生成的字串,總共36個位元組長。形如:550e8400-e29b-41d4-a716-446655440000。
UUID 的計算因子包括:乙太網卡地址、納秒級時間、晶片ID碼和許多可能的數字。
UUID 是個標準,其實現有幾種,最常用的是微軟的 GUID(Globals Unique Identifiers)。
- 優點:簡單,全球唯一;
- 缺點:儲存和傳輸空間大,無序,效能欠佳。
3、COMB(組合)
組合 GUID(10位元組) 和時間(6位元組),達到有序的效果,提高索引效能。
4、Snowflake(雪花) 演算法
Snowflake 是 Twitter 開源的分散式 ID 生成演算法,其結果為 long(64bit) 的數值。
其特性是各節點無需協調、按時間大致有序、且整個叢集各節點單不重複。
該數值的預設組成如下(符號位之外的三部分允許個性化調整):
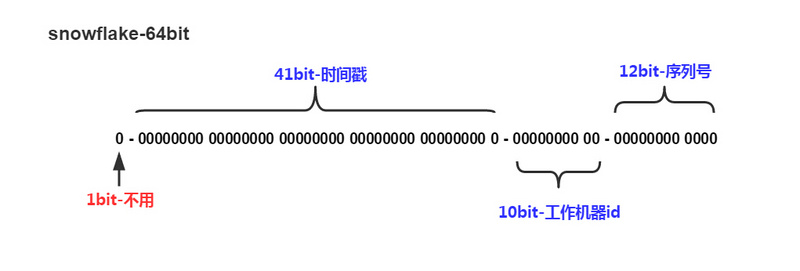
- 1bit: 符號位,總是 0(為了保證數值是正數)。
- 41bit: 毫秒數(可用 69 年);
- 10bit: 節點ID(5bit資料中心 + 5bit節點ID,支援 32 * 32 = 1024 個節點)
- 12bit: 流水號(每個節點每毫秒內支援 4096 個 ID,相當於 409萬的 QPS,相同時間內如 ID 遇翻轉,則等待至下一毫秒)
八、優雅實現分庫分表的動態擴容
優雅的設計擴容縮容的意思就是 進行擴容縮容的代價要小,遷移資料要快。
可以採用邏輯分庫分表的方式來代替物理分庫分表的方式,要擴容縮容時,只需要將邏輯上的資料庫、表改為物理上的資料庫、表。
第一次進行分庫分表時就多分幾個庫,一個實踐是利用32 * 32來分庫分表,即分為32個庫,每個庫32張表,一共就是1024張表,根據某個id先根據先根據資料庫數量32取模路由到庫,再根據一個庫的表數量32取模路由到表裡面。
剛開始的時候,這個庫可能就是邏輯庫,建在一個mysql服務上面,比如一個mysql伺服器建了16個數據庫。
如果後面要進行拆分,就是不斷的在庫和mysql例項之間遷移就行了。將mysql伺服器的庫搬到另外的一個伺服器上面去,比如每個伺服器建立8個庫,這樣就由兩臺mysql伺服器變成了4臺mysql伺服器。我們系統只需要配置一下新增的兩臺伺服器即可。
比如說最多可以擴充套件到32個數據庫伺服器,每個資料庫伺服器是一個庫。如果還是不夠?最多可以擴充套件到1024個數據庫伺服器,每個資料庫伺服器上面一個庫一個表。因為最多是1024個表麼。
這麼搞,是不用自己寫程式碼做資料遷移的,都交給dba來搞好了,但是dba確實是需要做一些庫表遷移的工作,但是總比你自己寫程式碼,抽資料導資料來的效率高得多了。
哪怕是要減少庫的數量,也很簡單,其實說白了就是按倍數縮容就可以了,然後修改一下路由規則。
參考文件
shardingsphere.apache.org
深度認識 Sharding-J