
第一節——詞向量與ELmo(轉)
最近在家聽貪心學院的NLP直播課。都是比較基礎的內容。放到部落格上作為NLP 課程的簡單的梳理。
本節課程主要講解的是詞向量和Elmo。核心是Elmo,詞向量是基礎知識點。
Elmo 是2018年提出的論文 《Deep contextualized word representtations》,在這篇論文中提出了很重要的思想Elmo,Elmo 是一種基於特徵的語言模型,用預訓練的語言模型,生成更好的特徵。
Elmo是一種新型深度語境化詞表徵,可對詞進行復雜特徵(如句法和語義)和詞在語言語境中的變化進行建模(即對多義詞進行建模)。我們的詞向量是深度雙向語言模型biLM內部狀態的函式,在一個大型文字語料庫中預訓練而成。
Elmo的主要做法是先訓練一個完整的語言模型,再用這個語言模型去處理需要訓練的文字,生成相應的詞向量,所以在文中一直強調Elmo的模型對同一個字的不同句子中能生成不同的詞向量。
在講ELmo之前 我們先回顧一下詞向量和語言模型,因為ELmo的提出 就是因為就語言模型的詞向量 有一些缺點(主要是無法解決一詞多意的問題),所以提出雙向-深度-LSTM 的Elmo模型。這裡的‘雙向’是一個拼接而已,不是真正意義上的雙向,所以XLNET 有permutation的改進實現真正的根據上下文內容的雙向, 這裡的‘深度’ 是橫向和縱向的深度,因為深度 每層可以學習到不同的點,並且越深的層學的東西越具體。
1.詞向量與語言模型
NLU 文字的量化表示方式

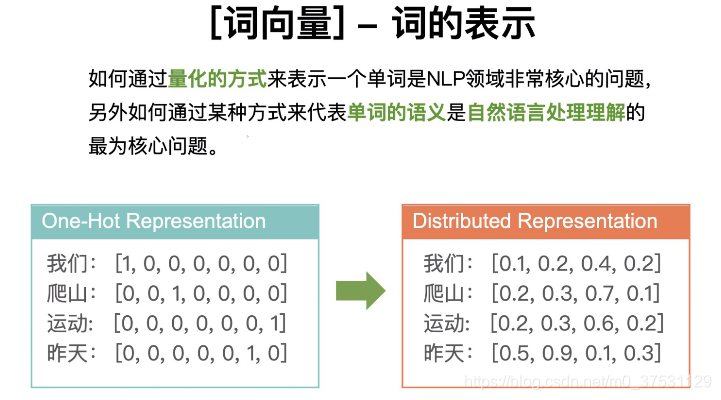
獨熱編碼:能否表示單詞之間的相似度? — 不能。因為通過任何一種方式(餘弦相似度等)無法計算兩兩向量的相似度。
所以我們有了 詞向量 (分散式表示的詞向量)
獨熱編碼: 稀疏向量,並且都是正交的。
詞向量:稠密向量,分散式詞向量。
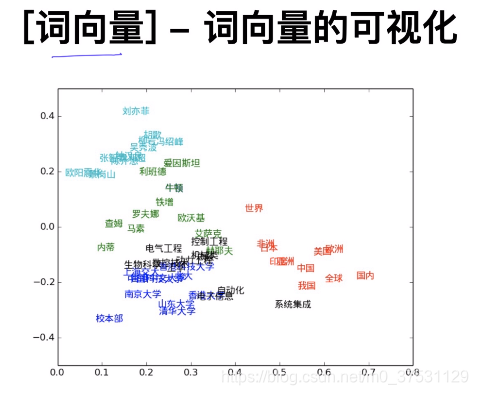
類似的單詞 都是聚集在一起的。當我們提取出某些詞向量時,我們可以通過視覺化來呈現出他們的關係。 視覺化 T-SNE (sklearn裡面有)這是一種降維的演算法(針對詞向量一般用TSNE),其他降維演算法有PCA 等。


語言模型的目標是最大的話 一句話的 概率的。
基於前面幾個單詞預測下一個單詞 這就是語言模型。

語言模型的基礎:鏈式法則,馬爾科夫,N元組,平滑方式,困惑度。
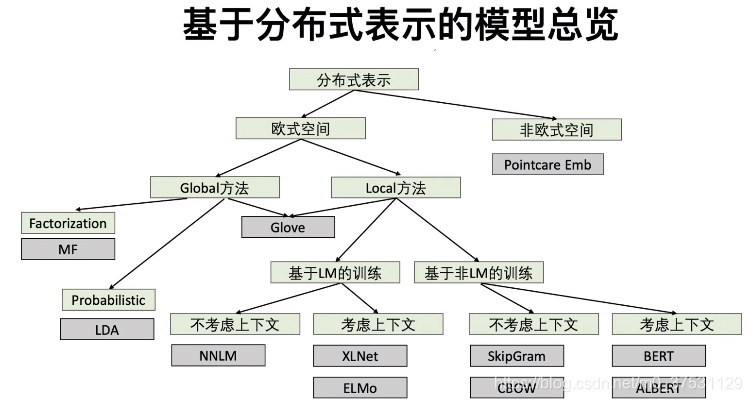
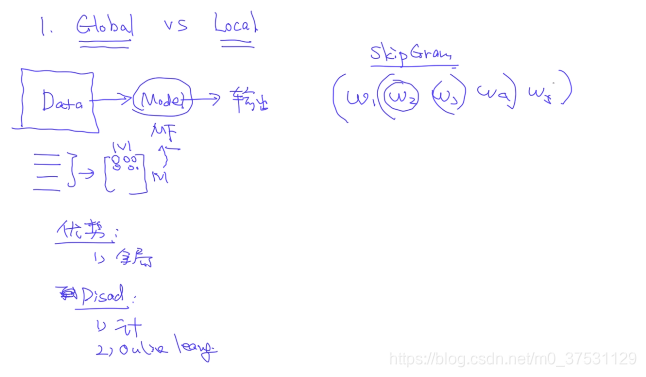
Global 方法:全域性方法
Local 方法: 區域性方法
基於LM的訓練:基於語言模型的訓練
基於非LM的訓練:基於非語言模型的訓練
1 Global vs Local
Global: 優勢:全域性. 缺點:計算量大,有新的文字的時候 需要更新。
Local: Skip Gram
- 基於LM vs 非基於LM

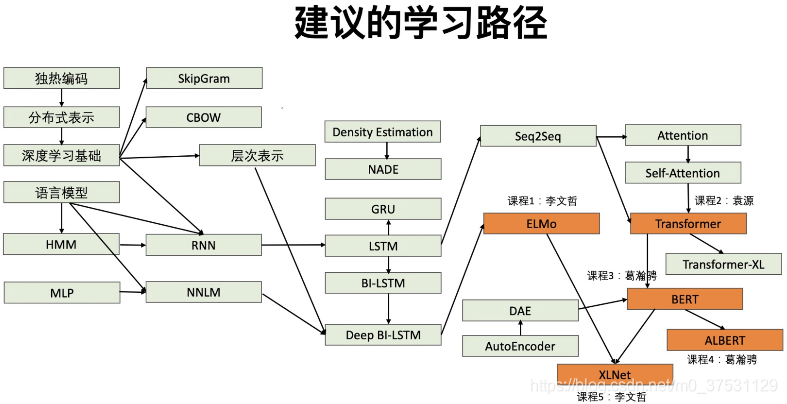
對於Elmo: 語言模型-NNLM-層次表示-HMM-RNN-LSTM-BiLSTM-DeepBiLSTM-ELMO
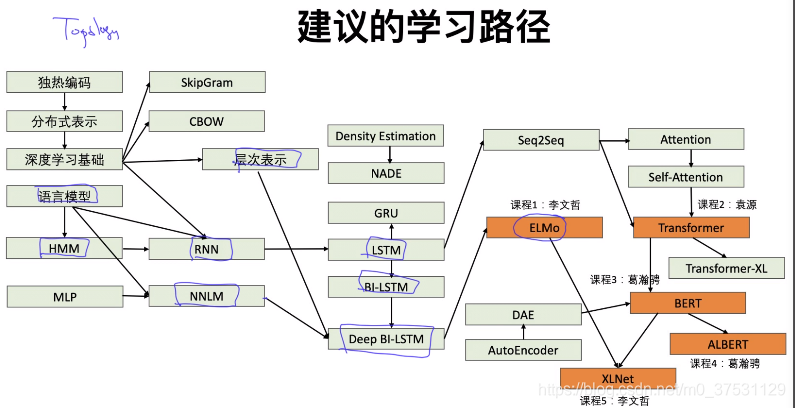
2.學習不同語境下的語義表示



基於Distributional Hypothesis
– Skip-Gram
句子: 詞向量 訓練 方法 有 兩種
單詞: W1 W2 W3 W4 W5
windows = 1
假設已知 w2, 預測出 w1 和 w3
目標函式:Maximize P(w2|w1)P(w1|w2)P(w3|w2)P(w2…)
– CBOW:
通過 w1 和 w3 預測 w2
目標函式: Maximize P(w2| w1,w3) P(w3| w2,w4)…
Language Model + HMM
– NNLM:
目標函式: Maximize P(w2|w1)P(w3|w2)

上面句子裡面的Back 是不同的意思。
理解詞向量 在不同語境下的含義 就是我們的目標。所以有了Elmo,Bert 等模型。


正確答案是 ABCD。
A是一種比較直觀的 可行方案,每個單詞多意,那麼可以對應多個詞向量。當然方法可行,不過具體執行問題有可能也很懂。
B和C是相關的。example: I back my car, I heart my back. 首先對back計算一個基準向量 H_back 一對一的,如何計算2個back這個句子裡面的含義分別是什麼? H_back + ▲(基於上下文的偏移)

3.基於LSTM 的詞向量學習

- 基於LSTM 作為基石
- 深度,層次
LSTM 來源於RNN, 因為RNN有些梯度爆咋的問題,所以提出了LSTM。
目標函式 是一個 語言模型,輸出層 通過softmax 獲取 期望輸出向量,然後 期望輸出 和實際值(熱獨編碼) 計算交叉熵,反向傳播。
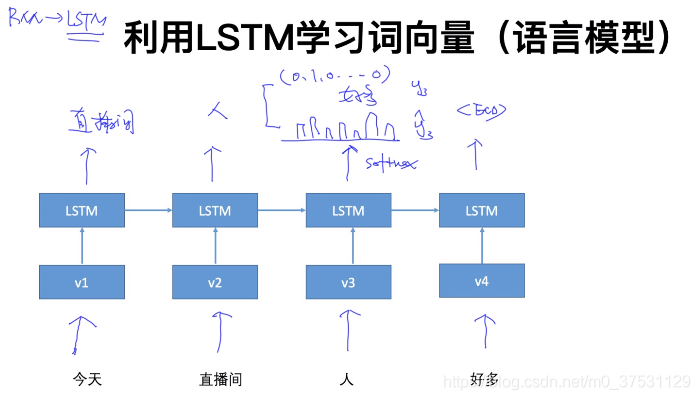
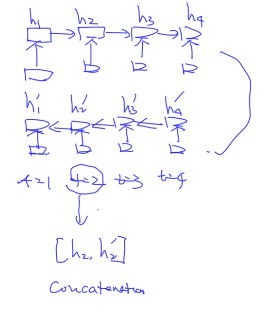
下面是兩個獨立的 LSTM。不是一個真正的雙向LSTM。
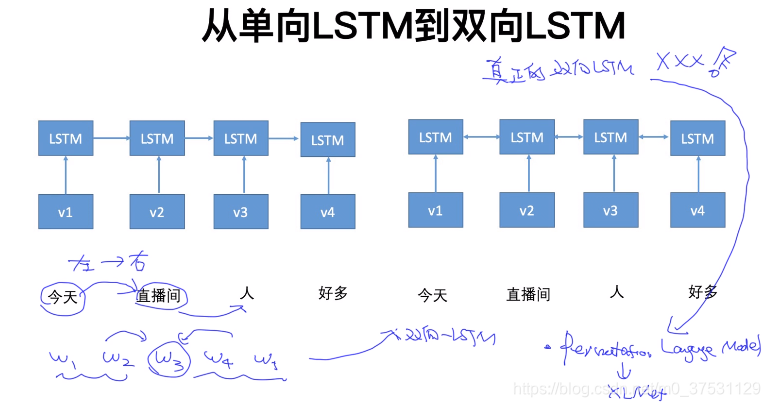
為什麼不是真正的雙向 是因為只是把前向和反向 拼接起來的結果,不是完整意義上的雙向。 所以後面Permutation(XLNET) 可以認為是真正的雙向
4.深度學習中的層次表示以及Deep BI-LSTM
深度 : 可以從縱向和橫向上深度。
層次表示 可以看出 每層學出來的結果是不一樣的。

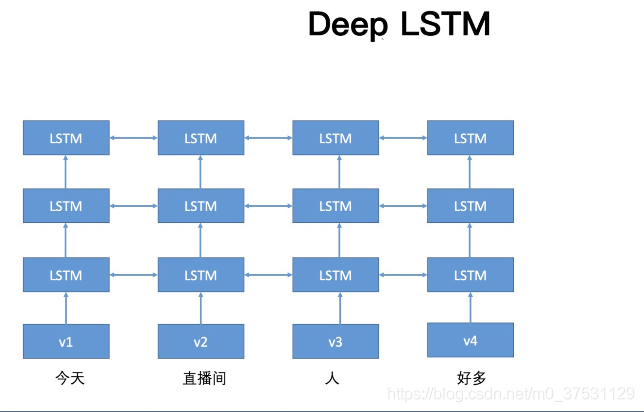
這個就是Deep-bi-LSTM
基於LM方式來訓練。
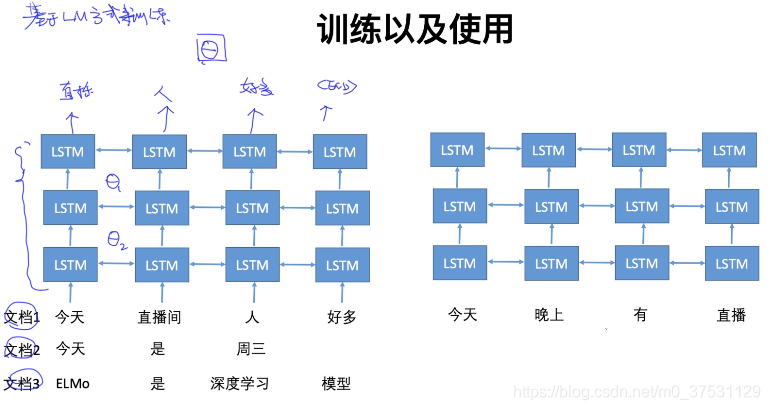
5.ELMO模型
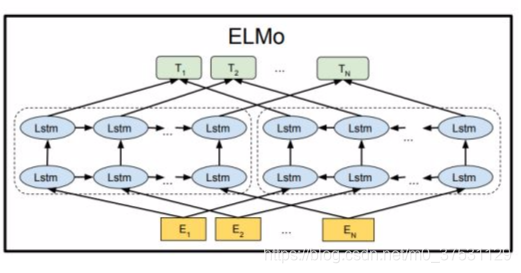
Elmo 使用的是一個雙向的LSTM語言模型,由一個前向和一個後向語言模型構成,目標函式就是取這兩個方向語言模型的最大似然。
語言模型的雙向體現在對句子的建模:給定一個N個token的句子, t1,t2,t3...tN。
前向語言模型:從歷史資訊預測下一個詞,即從給定的歷史資訊$(t_1,…,t_{k-1}) $ 建模下一個token 預測 tk的概率 (這是前向LSTM)
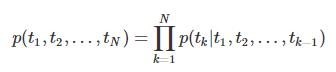
對於一個L層的LSTM, 設其輸入是xkLM(token embedding)每一層都會輸出一個context-dependent representation (hk,jLM), LSTM的最後一層輸出為(hk,LLM),該輸出會在Softmax layer被用來預測下一個token tk+1
後向語言模型:從未來資訊預測上一個詞,即從給定的未來(tk+1,...tN)建模上一個token tk的概率(反向LSTM)
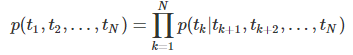
對於一個L層的LSTM, 設其輸入是xkLM(token embedding)每一層都會輸出一個context-dependent representation 反向的(hk,jLM), LSTM的最後一層輸出為反向的(hk,LLM),該輸出會在Softmax layer被用來預測下一個token tk−1
雙向語言模型是前向、後向的一個綜合,通過兩個方向的對數極大似然估計來完成:
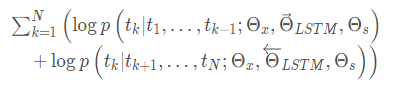
其中:
- Θx是token embedding
- Θs代表softmax layer的引數
biLM利用了biLSTM,biLSTM在前向和後向兩個方向上共享了部分權重
對於一個token,ELMo會計算2L+1 個representation(輸入的一個token embedding和前向、後向的2L個representation):
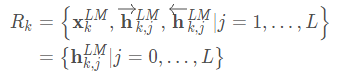
其中:
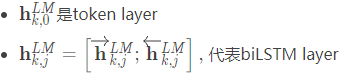
在下游任務中,ELMo將R的所有層壓縮成一個向量ELMok=E(Rk;Θe) ,在最簡單的情況下,也可以只使用最後一層E(Rk)=hk,LLM
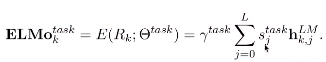
其中

可以看出,ELMo是biLM多層輸出的線性組合。

在監督NLP任務中使用Elmo
在supervised NLP tasks中使用ELMo, 給定N個token的句子,supervised NLP處理的標準過程的輸入是context-independent token詞向量xk,加入ElMo有兩種方式:
- 直接將ELMo詞向量ELMok和普通詞向量xk 拼接得到[xk;ELMoktask],作為模型的輸入。
- 將ELMo詞向量ELMok 和隱藏層輸出hk 進行拼接得到[hk;ELMoktask]
(一個單詞在語境下的表示 就是所有層的加權平均。
在預訓練好這個語言模型之後,ELMo就是根據公式來用作詞表示,其實就是把這個雙向語言模型的每一中間層進行一個求和。最簡單的也可以使用最高層的表示來作為ELMo。然後在進行有監督的NLP任務時,可以將ELMo直接當做特徵拼接到具體任務模型的詞向量輸入或者是模型的最高層表示上。)
6.總結
- ELMo的假設前提一個詞的詞向量不應該是固定的,所以在一詞多意方面ELMo的效果一定比word2vec要好。
- word2vec的學習詞向量的過程是通過中心詞的上下視窗去學習,學習的範圍太小了,而ELMo在學習語言模型的時候是從整個語料庫去學習的,而後再通過語言模型生成的詞向量就相當於基於整個語料庫學習的詞向量,更加準確代表一個詞的意思。
- ELMo還有一個優勢,就是它建立語言模型的時候,可以運用非任務的超大語料庫去學習,一旦學習好了,可以平行的運用到相似問題。

Bert 是 AutoEncoder 通過上下文來預測中間mask單詞,損失函式是ADE的損失函式,不是交叉熵損失。Bert 模型不是基於語言模型的,只是基於ADE。
Elmo 是基於語言模型的。