
MongoDB -> kafka 高效能實時同步(採集)mongodb資料到kafka解決方案
寫這篇部落格的目的
讓更多的人瞭解 阿里開源的MongoShake可以很好滿足mongodb到kafka高效能高可用實時同步需求(專案地址:https://github.com/alibaba/MongoShake,下載地址:https://github.com/alibaba/MongoShake/releases)。至此部落格就結束了,你可以愉快地啃這個專案了。還是一起來看一下官方的描述:
MongoShake is a universal data replication platform based on MongoDB's oplog. Redundant replication and active-active replication are two most important functions. 基於mongodb oplog的叢集複製工具,可以滿足遷移和同步的需求,進一步實現災備和多活功能。
沒有標題的標題
哈哈,有興趣聽我囉嗦的可以往下。最近,有個實時增量採集mongodb資料(資料量在每天10億條左右)的需求,需要先調研一下解決方案。我分別百度、google了mongodb kafka sync 同步 採集 實時等 關鍵詞,寫這篇部落格的時候排在最前面的當屬kafka-connect(官方有實現https://github.com/mongodb/mongo-kafka,其實也有非官方的實現)那一套方案,我對kafka-connect相對熟悉一點(不熟悉的話估計編譯部署都要花好一段時間),沒測之前就感覺可能不滿足我的採集效能需求,測下來果然也是不滿足需求。後來,也看到了https://github.com/rwynn/route81
這次可能也提醒我下次要多往下找找,說不定有些好東西未必排在最前面幾個。
之後在github上搜in:readme mongodb kafka sync,讓我眼前一亮。
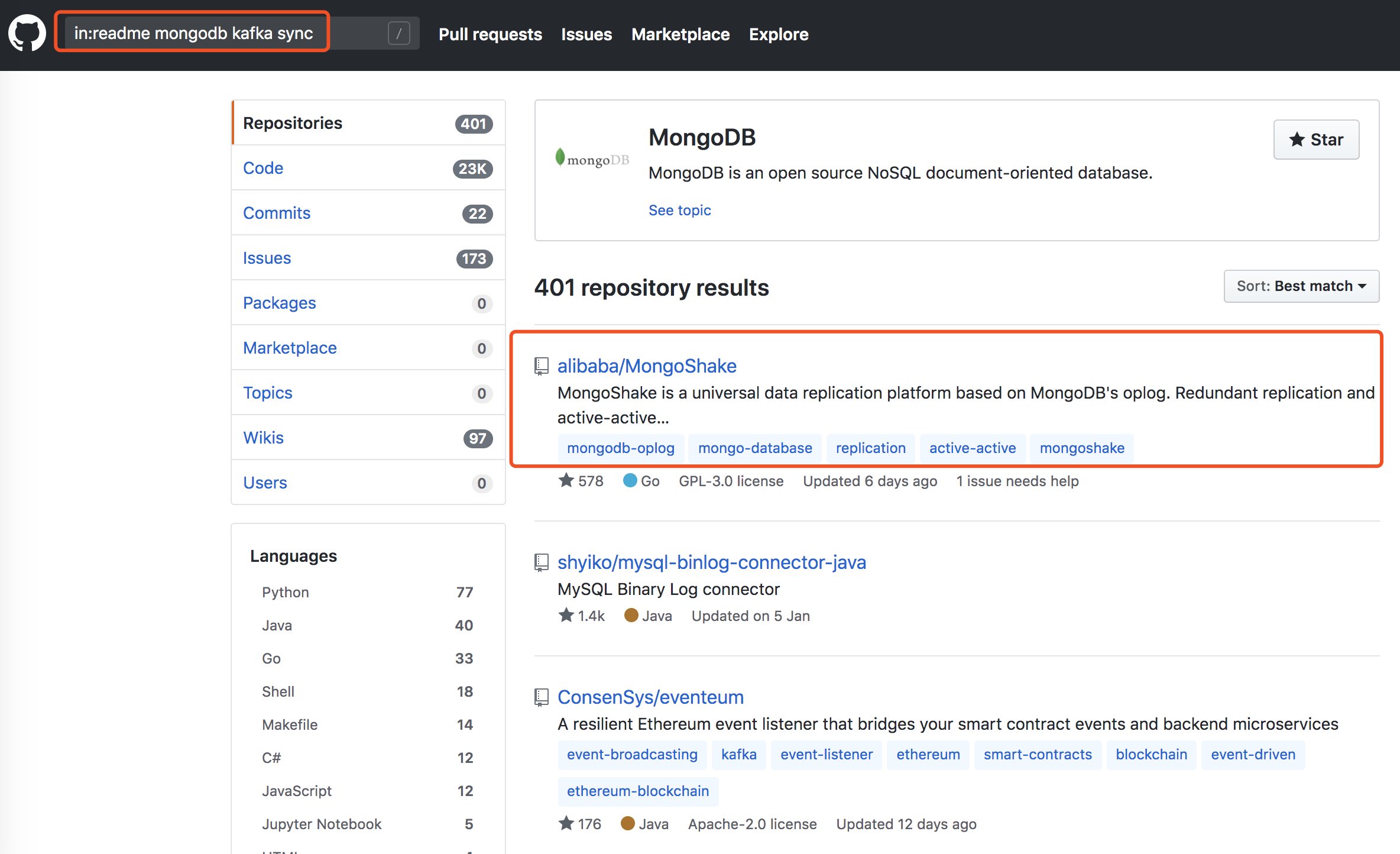
點進去快速讀了一下readme,正是我想要的(後面自己實際測下來確實高效能、高可用,滿足我的需求),官方也提供了MongoShake的效能測試報告。
這篇部落格不講(也很大可能是筆者技術太渣,無法參透領會(●´ω`●))MongoShake的架構、原理、實現,如何高效能的,如何高可用的等等。就一個目的,希望其他朋友在搜尋實時同步mongodb資料
MongoShake的解決方案可以排在最前面(實力所歸,誰用誰知道,獨樂樂不如眾樂樂,故作此部落格),避免走彎路、繞路。
初次使用MongoShake值得注意的地方
資料處理流程
v2.2.1之前的MongoShake版本處理資料的流程:
MongoDB(資料來源端,待同步的資料)
-->MongoShake(對應的是collector.linux程序,作用是採集)
-->Kafka(raw格式,未解析的帶有header+body的資料)
-->receiver(對應的是receiver.linux程序,作用是解析,這樣下游元件就能拿到比如解析好的一條一條的json格式的資料)
-->下游元件(拿到mongodb中的資料用於自己的業務處理)
v2.2.1之前MongoShake的版本解析入kafka,需要分別啟collector.linux和receiver.linux程序,而且receiver.linux需要自己根據你的業務邏輯填充完整,然後編譯出來,預設只是把解析出來的資料打個log而已
src/mongoshake/receiver/replayer.go中的程式碼如圖:
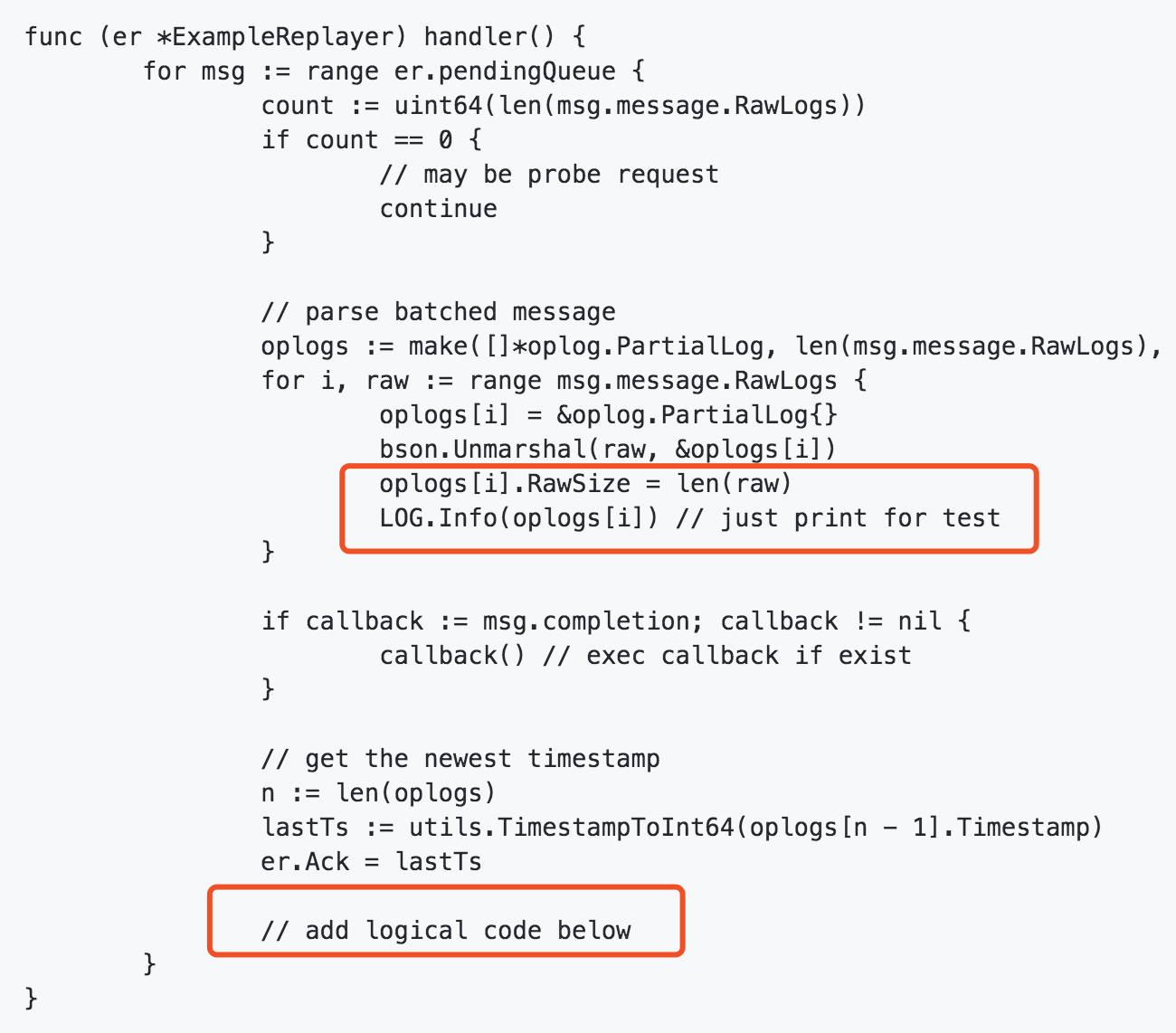
詳情見:https://github.com/alibaba/MongoShake/wiki/FAQ#q-how-to-connect-to-different-tunnel-except-direct
v2.2.1版本MongoShake的collector.conf有一個配置項tunnel.message
# the message format in the tunnel, used when tunnel is kafka.
# "raw": batched raw data format which has good performance but encoded so that users
# should parse it by receiver.
# "json": single oplog format by json.
# "bson": single oplog format by bson.
# 通道資料的型別,只用於kafka和file通道型別。
# raw是預設的型別,其採用聚合的模式進行寫入和
# 讀取,但是由於攜帶了一些控制資訊,所以需要專門用receiver進行解析。
# json以json的格式寫入kafka,便於使用者直接讀取。
# bson以bson二進位制的格式寫入kafka。
tunnel.message = json- 如果選擇的
raw格式,那麼資料處理流程和上面之前的一致(MongoDB->MongoShake->Kafka->receiver->下游元件) - 如果選擇的是
json、bson,處理流程為MongoDB->MongoShake->Kafka->下游元件
v2.2.1版本設定為json處理的優點就是把以前需要由receiver對接的格式,改為直接對接,從而少了一個receiver,也不需要使用者額外開發,降低開源使用者的使用成本。
簡單總結一下就是:
raw格式能夠最大程度的提高效能,但是需要使用者有額外部署receiver的成本。json和bson格式能夠降低使用者部署成本,直接對接kafka即可消費,相對於raw來說,帶來的效能損耗對於大部分使用者是能夠接受的。
高可用部署方案
我用的是v2.2.1版本,高可用部署非常簡單。collector.conf開啟master的選舉即可:
# high availability option.
# enable master election if set true. only one mongoshake can become master
# and do sync, the others will wait and at most one of them become master once
# previous master die. The master information stores in the `mongoshake` db in the source
# database by default.
# 如果開啟主備mongoshake拉取同一個源端,此引數需要開啟。
master_quorum = true
# checkpoint儲存的地址,database表示儲存到MongoDB中,api表示提供http的介面寫入checkpoint。
context.storage = database同時我checkpoint的儲存地址預設用的是database,會預設儲存在mongoshake這個db中。我們可以查詢到checkpoint記錄的一些資訊。
rs0:PRIMARY> use mongoshake
switched to db mongoshake
rs0:PRIMARY> show collections;
ckpt_default
ckpt_default_oplog
election
rs0:PRIMARY> db.election.find()
{ "_id" : ObjectId("5204af979955496907000001"), "pid" : 6545, "host" : "192.168.31.175", "heartbeat" : NumberLong(1582045562) }我在192.168.31.174,192.168.31.175,192.168.31.176上總共啟了3個MongoShake例項,可以看到現在工作的是192.168.31.175機器上程序。自測過程,高速往mongodb寫入資料,手動kill掉192.168.31.175上的collector程序,等192.168.31.174成為master之後,我又手動kill掉它,最終只保留192.168.31.176上的程序工作,最後統計資料發現,有重採資料現象,猜測有例項還沒來得及checkpoint就被kill掉了。