
One Stage目標檢測
在計算機視覺中,目標檢測是一個難題。在大型專案中,首先需要先進行目標檢測,得到對應類別和座標後,才進行之後的各種分析。如人臉識別,通常是首先人臉檢測,得到人臉的目標框,再對此目標框進行人臉識別。如果該物體都不能檢測得到,則後續的分析就無從入手。因此,目標檢測佔據著十分重要的地位。在目標檢測演算法中,通常可以分成One-Stage單階段和Two-Stage雙階段。而在實際中,我經常接觸到的是One-Stage演算法,如YOLO,SSD等。接下來,對常接觸到的這部分One-stage單階段目標檢測演算法進行小結。本文one stage檢測演算法包括有YOLO系列,SSD,FSSD,DSOD,Tiny DSOD,RefineNet,FCOS。
YOLO
YOLO可以說是最早的One-stage目標檢測演算法之一,經過作者的優化,存在3個版本。
-
YOLO V1
Yolo v1在《You Only Look Once: Unified, Real-Time Object Detection》中提出。在Yolo之前的目標檢測演算法,如R-CNN系列,其網路相對比較複雜,耗時大,難以優化(因為每個單獨的部分是獨立訓練的)。因此,作者將目標檢測認為是一個獨立的迴歸任務,迴歸每個分離的預測框座標及其對應的類別概率,使其具有以下的優點:
- 執行速度非常快。使用Yolo演算法,其FPS為45,而Fast Yolo的FPS為150。同時,mAP也能達到以往實時目標檢測系統的兩倍。
- 使用全域性資訊進行推理。
- 可以學習到抽象的特徵。
介紹完Yolo的優點後,我們來看看其思想,如下圖所示。首先,Yolo將一張輸入圖片分成S*S格。如果GT框的中心落在某格(grid cell)上,則該格負責預測這個目標。每格會預測B個預測框及B個置信度得分。該置信度得分反映的是該格包含物體的置信度和這個預測框有多準。因此,對於該置信度得分,其定義為$Pr(Object)*IOU^{truth}_{pred}$。如果沒有物體的中心在該格上,則該置信度得分為0;如果有物體的中心在該格上,則我們希望置信度得分等於IOU。因此,對於每個預測框而言,都會預測5個值,分別是中心點$(x,y)$,寬高$(w,h)$,和上述的置信度得分。
對於每格而言,除了預測B個預測框及其置信度外,還會預測C個類別的條件概率$Pr(Class_i|Object)$。以VOC0712為例,就會預測$C=20$個類別的概率。這個概率是條件概率,在存在目標的前提下,其為第i類的概率。每格會共用這樣的概率,與B個預測框無關。在測試階段,每格類別的置信度得分等於類別的條件概率乘以每格預測框的置信度得分:
$$Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_i)*IOU^{truth}_{pred}$$
可以看出,每格類別的置信度不僅表示了這個類別出現的概率,而且也反映了預測框是否擬合GT框。
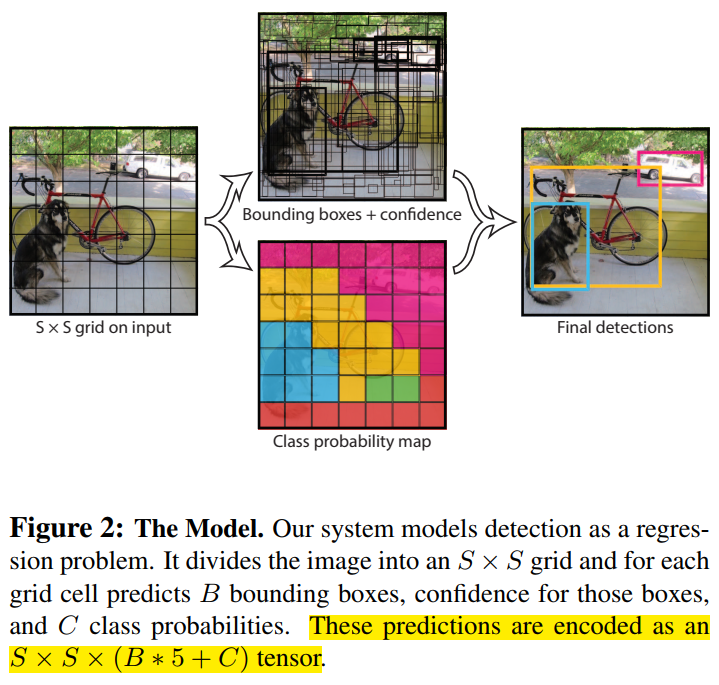
在該論文中,$S=7,B=2$,所以最後輸出的是$7*7*30$的張量,可以看成是49個30維的向量,這30維的向量包含了如下圖的資訊。

值得留意的是,Yolo並沒有預設不同大小的anchor。網路進行前向運算後,每格會輸出2個預測框,將該預測框與GT框進行匹對和計算IOU,此時才能確定使用IOU大的那個預測框來負責預測該物件。因此,Yolo的損失函式是各項誤差平方和的一個加權:
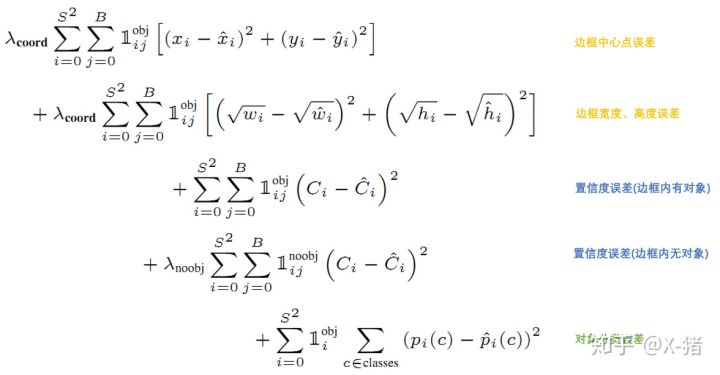
其中,$1^{obj}_i$表示物體的中心是否位於第i格,$1^{obj}_{ij}$表示第i個格子的第j個預測框中存在物件,$1^{noobj}_{ij}$表示第i格子的第j個預測框中不存在物件。損失函式的第一項表示當第i個格子的第j個預測框中存在物件時,其中心點偏移的誤差;第二項表示當第i個格子的第j個預測框中存在物件時,寬高的誤差;第三項表示當第i個格子的第j個預測框中存在物件時,其置信度得分誤差,真實的$C_i$應該等於IOU;第四項表示當第i格子的第j個預測框中不存在物件時,其置信度得分誤差,真實的$C_i$應該等於0;第五項表示當物體中心在第i格時,其類別誤差。其中,還有$\lambda _{coord}$調整預測框位置誤差的權重,$\lambda _{noobject}$調整不存在目標的預測框的置信度權重,一般是調低不存在物件的預測框的置信度誤差的權重。
Yolo v1的不足:
- 當密集場景或者小目標時,檢測效果不佳。因為一個格子只負責預測兩個框,一個類別。
- 定位誤差大。
- 召回率低。
參考資料:
- https://zhuanlan.zhihu.com/p/46691043
-
YOLO V2
Yolo v2在《YOLO9000: Better, Faster, Stronger》中提出。為了解決Yolo v1的不足,作者使用了融合了多種思路來提高了網路的效能,使得mAP得到大幅度提升;為了加快推理速度,使用新的模型結構;為了能檢測出更多的物件,提出了新的聯合訓練機制,結合分類資料集(如ImageNet)和檢測資料集(如COCO和VOC),使得YOLO V2能檢測出更多的類別。
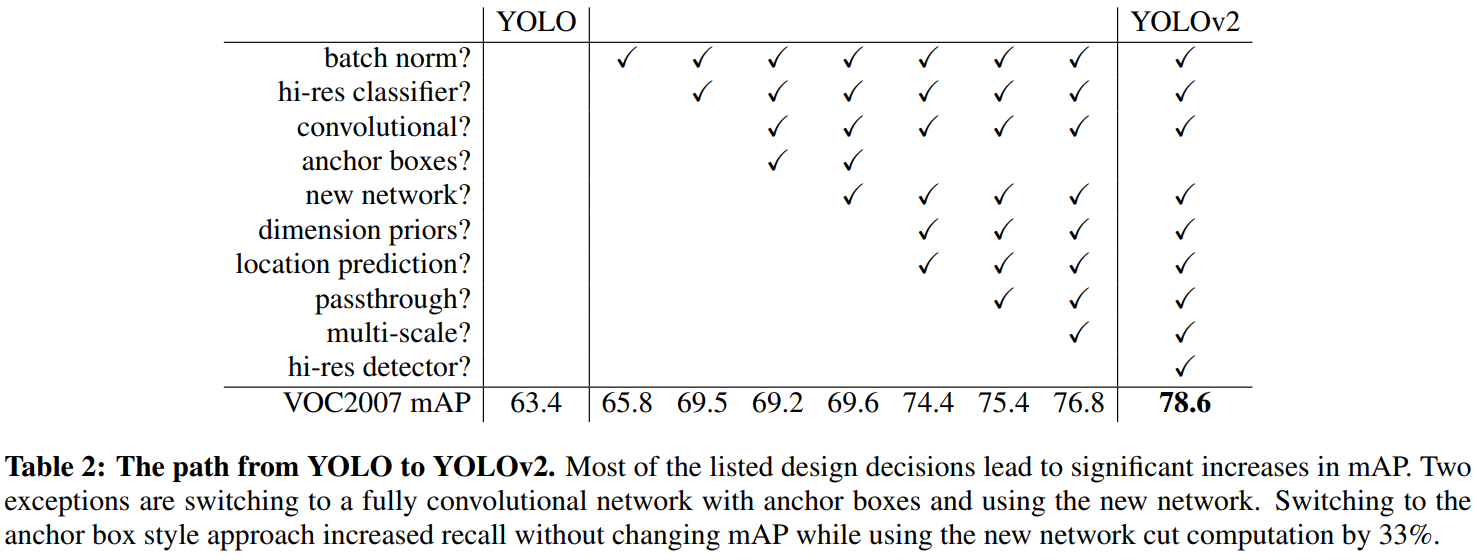
在提高網路效能上,作者使用了以下的思路:
- Batch Normalization。在所有卷積層後面加上BN層,使得Yolo演算法有2%的mAP提升。同時,因為有了BN層,可以去除dropout層。
- High Resolution Classifier。在Yolo v1中,先使用224*224的輸入圖片訓練分類網路,然後再使用448*448的輸入圖片訓練檢測網路。這樣意味著Yolo v1必須同時切換去檢測任務和調整網路以適應新的輸入。因此,在v2版本中,直接使用448*448的輸入圖片先訓練分類網路,然後再微調網路來適應檢測任務。
- Convolutional with anchor boxes。在Yolo v1中,每個cell中預測兩個預測框,這兩個預測框是直接對座標和置信度進行預測的。在v2版本中,借鑑了錨點框的思想,對每個cell設定錨點框,對錨點框的偏差進行預測。這樣能簡化問題,而且使網路更容易學習。
- Dimension clusters。使用聚類演算法來設計錨點框。在Faster R-CNN中,錨點框是手工設計,這樣的設計方式不一定很好適配檢測任務。如果錨點框的初始化設定比較好,能使網路更容易得到好的檢測結果。因此,使用k-means聚類演算法來設計錨點框。在聚類演算法中,最重要的是如何設計兩個框之間的“距離”,這裡使用$d(box,centroid)=1-IOU(box,centroid)$作為距離度量的方式,當IOU越大時,兩個框之間的“距離”越小。在v2版本中,使用5種邊框種類就能與Faster RCNN中的9種邊框種類的效果相近。(同時,在工作中我也發現,一個較好的錨點框設定,能較大幅度提高檢測效果)
- Direct location prediction。在Faster RCNN中,由於沒有對預測框進行限制,所以預測框的中心可能會出現在任何位置,導致訓練早期不穩定。因此,Yolo v2在使用錨點框後,對錨點框的預測進行了限制,將預測框的中心約束在該cell中。
- Fine-Grained Features。與SSD不同,Yolo v2使用一種不同的方式來提高小目標的檢測效果,引入了pass through層來保留更加細節的資訊。具體做法是,在最後一個pool層之前,其特徵圖大小是26*26*512,將其一拆成四,變成13*13*2048,直接傳遞到pool層之後,與13*13*1024的特徵圖進行concat起來,構成13*13*3072的特徵圖。
- Multi-Scale Training。由於Yolo v2只有卷積層和池化層,所以其對輸入圖片的大小沒有限制。作者想讓Yolo具有更強大的魯棒性,所以使用不同大小的輸入圖片來訓練網路,每訓練10個batch,就隨機更換輸入圖片的尺寸。這種做法,有點類似影象金字塔。
將上述的思想融合起來,最終的實驗效果如下圖所示。實驗效果的增幅還是挺明顯的,將v2提高了近15個點的mAP。
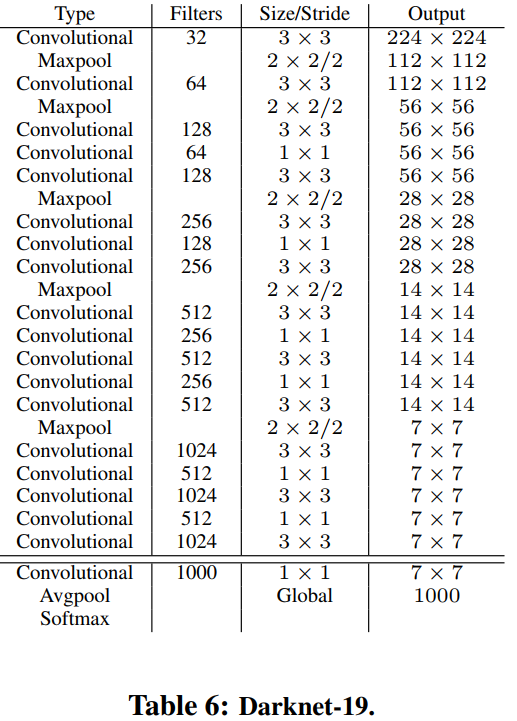
作者不僅想讓Yolo v2的mAP更高,而且還想讓其更快。在v1中,使用的網路結構是基於Inception的,其速度比VGG快,但效能略遜色於VGG。因此,作者提出了新的分類網路,Darknet-19,作為Yolo v2的主幹網路,如下圖所示。該網路中含有19個卷積層和5個池化層。
YOLO v2的訓練主要包括三個階段。第一階段就是先在ImageNet分類資料集上預訓練Darknet-19,此時模型輸入為224*224 ,共訓練160個epochs。然後第二階段將網路的輸入調整為448*448 ,繼續在ImageNet資料集上finetune分類模型,訓練10個epochs,此時分類模型的top-1準確度為76.5%,而top-5準確度為93.3%。第三個階段就是修改Darknet-19分類模型為檢測模型,移除最後一個卷積層、global avgpooling層以及softmax層,並且新增了三個 3*3*1024卷積層,同時增加了一個pass through層,最後使用 1*1 卷積層輸出預測結果,輸出的channels數為:num_anchors*(5+num_classes) ,和訓練採用的資料集有關係。由於anchors數為5,對於VOC資料集(20種分類物件)輸出的channels數就是125,最終的預測矩陣T的shape為 (batch_size, 13, 13, 125),可以先將其reshape為 (batch_size, 13, 13, 5, 25) ,其中 T[:, :, :, :, 0:4] 為邊界框的位置和大小$(t_x,t_y,t_w,t_y)$,T[:, :, :, :, 4] 為邊界框的置信度,而 T[:, :, :, :, 5:] 為類別預測值。
在VOC資料集中,只有20類物體可以進行檢測。但實際生活中,物體的類別數是遠遠大於20種的。因此作者想結合分類資料集和檢測資料集來進行聯合訓練,使得檢測的類別數能大幅度提高。這種聯合訓練方式的基本思想是,如果是檢測樣本,其loss就包含分類誤差和定位誤差;如果是分類樣本,其loss就只包含分類誤差。
由於我沒有對這一塊做過多研究,瞭解不深。但該方法最主要的是構建Word Tree。因為資料集的不同,導致每個標籤之間不是互斥的,存在包含關係,例如在COCO資料集中的一個類別是“狗”,而在ImageNet中包含了多種狗的標籤。所以,通過構建word tree來將所有標籤資訊串聯起來,類似於“樹”的結構,父節點包含了不同類別的子結構。
參考資料:
- https://zhuanlan.zhihu.com/p/47575929
-
YOLO V3
Yolo v3提出於《YOLOv3: An Incremental Improvement》中,在v2版本上,進一步進行了改進,總體來說,改進力度有限,下面來分別看看這些改進措施。
首先,在預測類別時,不使用softmax,而是使用logistic進行預測。因為這樣有利於多標籤預測。當使用複雜領域的資料集時,可能會出現標籤不互斥的情況(如woman和person),使用多標籤的方法會更加有利於模型,即使用logistic
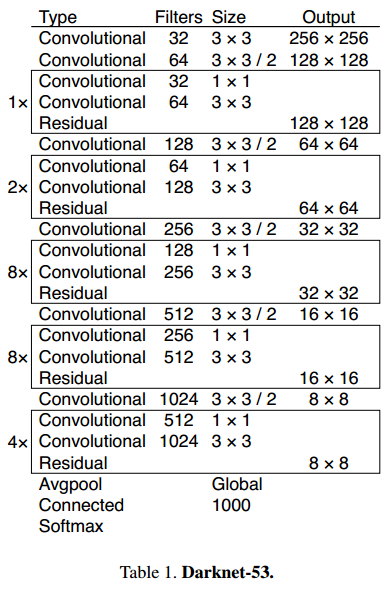
第二,使用了新的網路Darknet-53,如下圖所示。在v2中,使用的backbone是Darknet-19,而在v3中,不僅網路層數增加了,而且還借鑑了ResNet的思想,使用多個連續的3*3和1*1卷積層,並且帶有shortcut連線。根據作者提供的實驗比較,在ImageNet中,Darknet-53具有與ResNet-152相似的準確率,但速度是其兩倍。
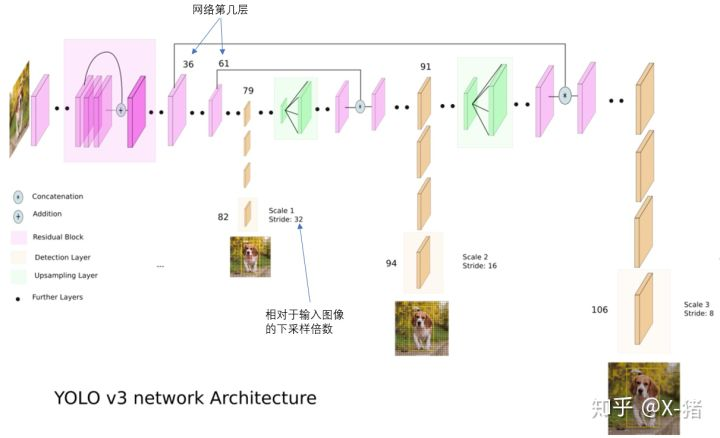
第三,利用多尺度資訊來進行預測。這裡借用一下這位博主的圖,其整體的網路結構,如下圖所示。在v3中,利用了不同尺度的資訊進行預測,我認為作者的這種方式,其應該是借鑑了FPN的思想。使用3個尺度的特徵圖進行預測,如圖上黃色方塊表示的一樣,在第79層後,進行上取樣,上取樣得到的特徵圖與第61層的特徵圖進行融合,再進行上取樣,與第36層的特徵圖融合。
第四,使用K-means聚類得到錨點框的尺寸。和v2版本採用方法一致,v3這裡使用了3個不同尺寸的特徵圖進行預測,在每層特徵圖中使用3種不同尺寸的錨點框,如下圖所示。為小尺寸的特徵圖分配大尺寸的錨點框,適合檢測大目標;為大尺寸的特徵圖分配小尺寸的錨點框,適合檢測小目標。

以COCO為例,v3使用3個特徵圖來進行預測,每個特徵圖會對應3種錨點框,因此,對於每層特徵圖,其輸出的tensor為$N*N*[3*(4+1+80)]$,其中,$N$表示特徵圖的尺寸,$3$表示3個錨點框,$4$表示4個座標值,$1$表示是否包含物體的置信度(v3的置信度貌似與v1中的置信度不一樣),$80$表示COCO資料集的類別總數。
參考資料:
- https://zhuanlan.zhihu.com/p/49556105
SSD
SSD演算法提出於《SSD:Single Shot MultiBox Detector》 中,同樣是一篇非常經典的one stage目標檢測演算法,其框架也衍生出了很多系列。之前,我曾經對SSD進行過總結和程式碼復現,想仔細瞭解的可以參考來閱讀以下,這裡主要是概括性回顧以下。
如下圖所示,是SSD的框架網路,其使用了6個不同尺寸的特徵圖來進行預測,分別是$(38*38),(19*19),(10*10),(5*5),(3*3),(1*1)$。這6個特徵層會分別經過3*3的卷積後分成分類頭和檢測頭,分別用於預測座標偏差值和類別置信度(包含背景)。相比於YOLO V1和YOLO V2,SSD使用了多個特徵層,更適合檢測多種不同尺度的目標。
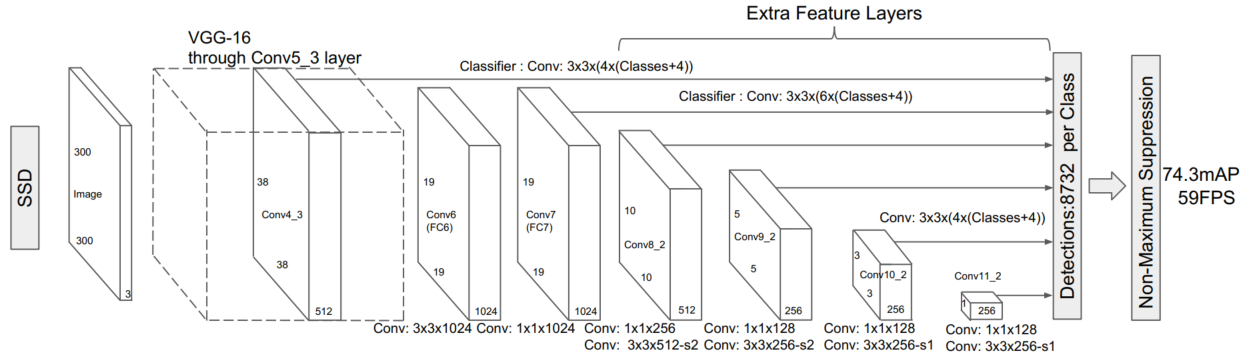
其次,在這6個不同尺寸的特徵圖中,還使用了不同大小和寬高比的錨點框。每個特徵圖使用不同於其他層的錨點框尺寸,而在該尺寸上又設定4種或者6種不同的寬高比。在大尺寸特徵圖是同小尺寸的錨點框,來檢測小目標;在小尺寸的特徵圖使用大尺寸的錨點框,來檢測大目標。這樣的設定方式,往後很多SSD系列都採取這種方式。因此,整個SSD中,會檢測8732個錨點框的座標偏差值和類別置信度。
第三,使用了OHEM進行難例挖掘,來緩解正負樣本的不平衡。在SSD中,並沒有使用所有的負樣本,而是將這些匹配上背景的樣本根據置信度損失進行降序排列,將損失較大的樣本認為是難例(hard negative),需要模型重點學習。選取損失最大的前N個樣本作為負樣本,正樣本與負樣本的比例控制在1:3左右,對於那些沒有選上的樣本,label設定成-1,不參與訓練當中。
作者還強調了資料增強對網路效能有著明顯提升。可以這麼理解,通過資料增強,間接提高了資料量和樣本之間的多樣性,從而提高了模型的魯棒性。另外,空洞卷積同樣可以提高了SSD的mAP,通過空洞卷積,是能在引數量不變的前提下感受野變大,使網路能“看”到的東西更多。
FSSD
FSSD提出於《FSSD: Feature Fusion Single Shot Multibox Detector》中,使用了輕量化的FPN接面構,來提高SSD的小目標檢測效果。
在SSD中,對小目標的檢測效果不佳,召回率低。因為小目標通常是淺層網路來進行預測的,特徵抽象能力不足,缺乏語義資訊;其次,小目標檢測通常嚴重依賴於上下文資訊。因此,FPN的提出是為了使淺層特徵和深層特徵進行融合,更好的輔助淺層特徵來進行目標檢測,進而提高小目標的檢測效果。FPN的結構如下圖的(c)所示。(b)是YOLO v1和v2系列的結構示意圖;(d)是SSD系列的結構示意圖。

在FPN接面構中,右邊的特徵層是隻由上一層的右邊特徵層和同一層的左邊特徵層進行融合的,缺乏不同層特徵層之間的融合;其次,上一層的右邊特徵層和同一層的左邊特徵層的融合是十分耗時的。因此,在FPN的基礎上,作者提出了一種輕量化的FPN接面構,與SSD進行結合,構成了FSSD,如上圖的(e)所示。FSSD的主要思想是,以合適的方式一次性融合所有不同層級的特徵層,然後基於此特徵層來生成特徵金字塔。
FSSD的網路結構如下圖所示。作者認為當特徵圖的尺寸小於$10*10$時,資訊特徵太少,對特徵融合增益不大,因此,使用了conv3_3,conv4_3,fc_7和conv7_2四個特徵層來進行融合(圖中只畫了3個)。首先對這4個特徵層進行$1*1$卷積來降低通道數,降低到256維。然後以conv4_3的特徵圖尺寸$38*38$為基礎,其它特徵層進行下采樣或者上取樣來是特徵圖的尺寸變成$38*38$,至此,所有圖中黃色的特徵圖都有了相同的特徵圖空間尺寸了。

然後對這4個黃色特徵圖進行融合,融合方式有兩種:concat或者ele-sum。通過實驗發現,concat的效果更好。因此,將這4個黃色特徵圖進行concat起來,構成了$38*38*1024$的tensor。由於不同層的特徵圖的分佈是不一致的,因此,對這$38*38*1024$的tensor進行BN操作。最後對融合後的特徵層進行下采樣(論文中使用bottlenet結構來進行下采樣),產生綠色的特徵層,使用這些不同尺寸的綠色特徵層來進行目標檢測。
最終實驗表明在犧牲少量速度的前提下,FSSD的mAP比原版的SSD要高,特別是對小目標的召回率提高了很多。
DSOD
DSOD提出於《DSOD: Learning Deeply Supervised Object Detectors from Scratch》中。目前,大部分目標檢測演算法都需要使用預訓練模型來提高檢測效果。但是由於分類任務和檢測任務的損失函式的類別分佈不同,使用預訓練模型會引入學習偏差;同時當分類場景和檢測場景具有很大差異時,使用預訓練模型的效果也不佳。因此,最好的辦法是對檢測網路進行從頭訓練,不使用預訓練模型。為此,作者提出了DSOD模型來解決從頭開始訓練的問題。
DSOD的結構如下圖的右邊所示,左邊是SSD的網路結構,右邊是DSOD的網路結構。可以看出,DSOD的結構與SSD十分類似,但其主幹網路是DenseNet。前面兩個特徵層是DenseNet主幹網路生成的,第1個特徵層一路直接送到預測中,另外一路經過pool和conv層後,與第2個特徵成concat後再送入預測。隨後,會分成2條支路,一路流經pool和conv來進行dowm-sample,另外一路輸入到$1*1$和$3*3$的卷積中;兩路進行concat後再送入預測。

最後,作者總結了下,解決從頭訓練問題的幾條原則:
- Proposal-free。作者發現,當使用了SS演算法或者RPN演算法來推薦候選區域時,不使用預訓練模型會導致模型不收斂。這可能是由於ROI pooling引起的問題,因為ROI pooling從推薦候選區域中生成特徵,但這樣會阻礙梯度平滑地從region-level回傳到卷積特徵圖中。
- Deep Supervison。深度監督網路,如Inception,DenseNet等,能直接監控更多的隱藏層,而不只是監督最後的輸出層。在proposal-free檢測框架中,包含了分類損失和定位損失,因此需要增加側路層來為每個隱藏層引入“共同”的目標。而DenseNet網路使用了skip connections,網路學習一半特徵、複用一半特徵,因此所有隱藏層能夠通過目標函式來接收到額外的監督。
- Stem Block。作者通過更換DenseNet的Stem Block,可以明顯提高檢測效能。新的Stem Block能夠減少原始輸入圖片的特徵損失。
- Dense Prediction Structure。在DSOD中,除了第一個特徵層外,其餘特徵層均是學習一半特徵,複用一半特徵。這樣的方式能夠產生更高精度的結構。
綜上所述,作者利用DenseNet作為主幹網路,提出了DSOD演算法,解決了從頭訓練的問題。
Tiny DSOD
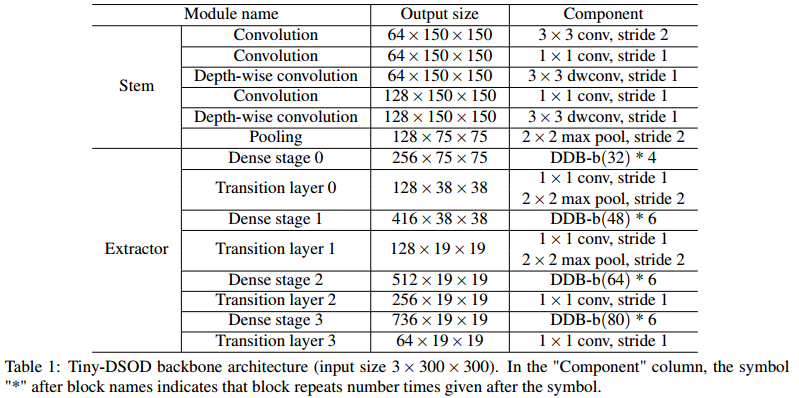
Tiny DSOD提出於《Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages》。目前很多目標檢測演算法對計算資源有限的硬體裝置都不太有友好,因此,作者在DSOD的基礎上,提出了輕量化的目標檢測網路Tiny DSOD。該Tiny DSOD引入了兩個創新且高效的結構:depthwise dense block (DDB)和depthwise feature-pyramid-network (D-FPN)。
首先,在DSOD中,使用的主幹網路是DenseNet,其結構如下圖所示。輸入分成兩路,經過$1*1*C$和$3*3*C/4$的卷積後,輸出C/4個通道的tensor,然後與輸入進行concat。這樣做的計算成本大。
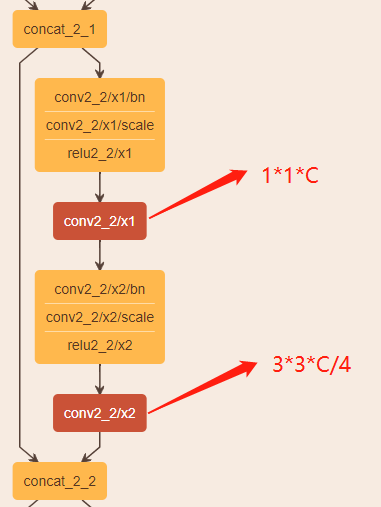
受到MobileNet的啟發,作者將深度可分離卷積融合進DenseNet中,並命名為DDB結構。該DDB結構有兩種形式,如下圖所示。其中,DDB-a中含有倒殘差結構的思想,先將有n個通道的輸入擴大至$w*n$個通道,$w$表示人為設定的超參,用於控制擴張倍數;然後進行$3*3$的卷積;接著進行$1*1$的卷積,但通道數降至$g$;最後將兩者進行concat,形成$n+g$個通道的特徵圖。可以認為$g$表示DDB-a的增長率。但是,這種結構DDB-a的複雜度是$O(L^3g^2)$,隨著網路層數$L$的增加,計算資源消耗也會快速增加,所以要控制增長率$g$,將$g$約束在較小的值。然而,增長率$g$較小,又會使模型的泛化能力變差。
基於上述的考慮,又提出了DDB-b這種結構。輸入首先會壓縮成$g$維,然後進行$3*3$的卷積,最後將兩者進行concat起來,形成$n+g$維的輸出。因此,整體的複雜度為$O(L^2g^2)$。在實驗中發現,DDB-b這種結構不僅更加高效,而且在資源有限的情況下準確率更高。因此,在Tiny DSOD中,使用了DDB-b這種結構。

因此,Tiny DSOD的網路結構如下圖所示。對於增長率$g$值而言,作者採用了淺層網路使用小$g$值、深層網路採用大$g$值得策略。因為淺層網路的特徵圖尺寸大,需要消耗更多的計算資源,而$g$值比較小時,能節省部分計算計算。
Tiny DSOD的另外一個結構是D-FPN,如下圖所示。結合了FPN的思想,設計了一種輕量化的D-FPN接面構,來使深層次的語義資訊與淺層特徵進行融合。這裡的downsample結構與DSOD的結構類似,利用多分枝思想,融合不同感受野的資訊,但是與DSOD不同的是,輸出的通道維數變小了和使用了深度可分離卷積。

綜上所示,在DSOD基礎上,Tiny DSOD融合了DDB結構和FPN接面構,降低計算資源的前提下,同時也提高檢測效果。
RefineDet
RefineDet提出於《Single-Shot Refinement Neural Network for Object Detection》中。總所周知,two stage目標檢測器能實現較高的精度,而FPS較慢;one stage目標檢測器的FPS很高,但卻犧牲一定精度。two stage能取得較高的精度,是因為:
- 使用了二級結構的取樣結構來解決正負樣本不平衡問題;
- 對預測框進行兩次迴歸;
- 使用兩段特徵來描述物體。
因此,作者對one stage和two stage目標檢測器進行取長補短,提出了RefineDet,結構如下圖所示,能實現比two stage檢測器更高的精度,且能保持較好的執行效率。其中,主要由兩個模組組成:anchor refiement module (ARM)和object detection module (ODM)。

ARM模組主要負責:
- 識別和移除負例錨點框,以此來為分類器減少搜尋空間;
- 大致地錨點框的位置和大小,為接下來的迴歸提供更好的初始化。
ARM模組會先對錨點框進行判斷,判斷錨點框內是否含有物體,屬於二分類;然後再粗調錨點框的位置,來傳遞給ODM來進一步二次迴歸。其實這ARM的作用,有點類似Faster R-CNN中的RPN模組。如果ARM中預測出該錨點框屬於背景的置信度大於一定閾值時,就會忽略這個錨點框。也就是ARM模組只會給ODM模組傳遞粗調過的難負例錨點框和粗調過的正錨點框。
而ODM模組主要負責將粗調過的錨點框來對其進行二次座標迴歸和類別預測。如圖中綠色帶星星的方塊圖,星星表示粗調後的錨點框,傳遞給ODM,ODM在這基礎上來進一步預測。
同時,作者還借鑑了FPN的思想,設計了transfer connection block (TCB)來將ARM中的特徵傳遞給ODM,可以看到,其將深層語義與淺層語義進行融合,這樣應該會進一步提高模型的效能。
FCOS
FCOS提出於《FCOS: Fully Convolutional One-Stage Object Detection》中,是一種anchor-free的檢測模型。目前,大部分檢測模型都是基於預設的錨點框,如SSD系列,作者就思考:目標檢測演算法是否一定需要錨點框才能取得較好的效能?而基於錨點框的目標檢測演算法,具有以下的不足:
- 錨點框的數量、寬高比和尺寸都對檢測的效果有很大影響,因此這些超參都需要進行調整;
- 即使錨點框經過了進行設計,檢測器也很難去處理具有較大形狀變化的物體,如小目標;
- 為了提高召回率,基於錨點框的檢測器需要在原圖上放置很多密集的錨點框,也就是需要密集取樣。但大部分錨點框都是負樣本,從而又會引起正負樣本之間的不平衡;
- 錨點框通常需要涉及到複雜的計算,例如IOU計算。
因此,作者基於全卷積網路,提出FOCS檢測模型。該FCOS會在每層特徵圖的每個特徵點上預測四維向量和類別,如下圖的左邊所示。這四維向量是$(l,t,r,b)$,分別表示該點到檢測框四條邊的相對距離。同時,當該畫素點遠離GT框的中心點位置時,會產生很多低質量的預測框。為了抑制這些低質量的預測框,在網路中引入了一個分支“center-ness”,來預測畫素點到目標框中心的偏移程度,以此來降低低質量預測框的權重。

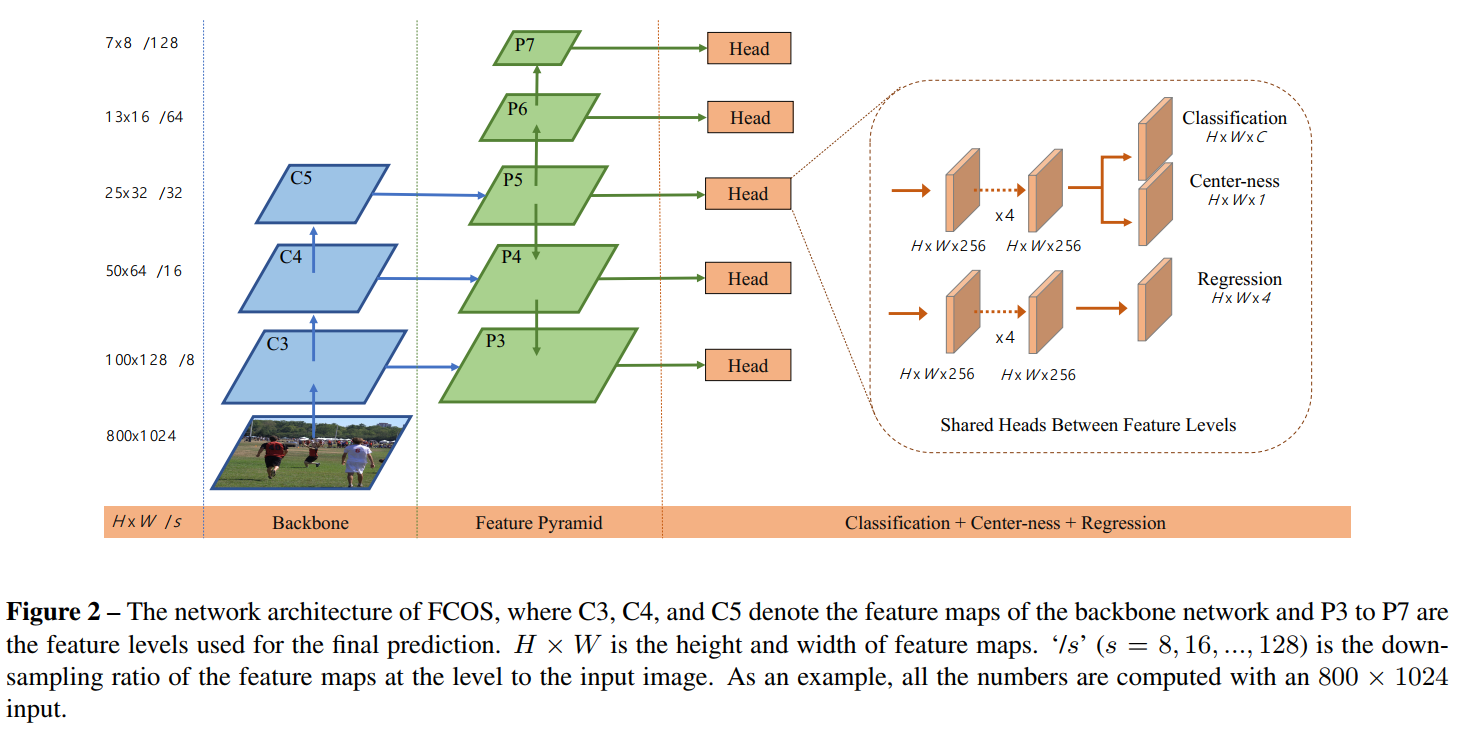
因此,FCOS的網路結構,如下圖所示。FCOS結合了FPN模組,並對FPN模組進行了相應的修改,$(P6,P7)$是通過$P5$下采樣得到的。然後會分成分類頭和迴歸頭,分別是4組卷積。最後在分類頭處,還有一個Center-ness的分支。
對於特徵圖$F_i$的每個位置$(x,y)$,會映射回原圖的$\left (\left \lfloor \frac{s}{2} \right \rfloor +xs,\left \lfloor \frac{s}{2} \right \rfloor +ys\right )$,其中$s$表示該特徵層的下采樣率。當映射回去後,如果該點位於GT框內,則認為其是正樣本,與GT框的標籤一致,直接進行迴歸與預測。如果改變位於多個GT框的交集區域,就將該點指定給面積最小的那個GT框。由於迴歸的值總是正值,因此在迴歸頭處採用了$e^x$對座標值進行對映。使用anchor-free這種方式,使負樣本的數量減少,有利於正負樣本之間的平衡。同時,對於anchor-based的方式,每個特徵點有6個或者9個錨點框需要預測,而anchor-free則只需迴歸一次,整體輸出少了9倍左右。
在FCOS中的FPN起到了很重要的作用,主要解決了以下兩個大問題:
- 當特徵圖的下采樣率(即stride)較大時,可能會導致較低的最大可能召回率(BPR)。在anchor-based中,可以通過降低IOU得分來緩解這個問題。而對於FCOS來說,直覺上來說,BPR可能會比anchor-based的檢測器要低,因為如果下采樣後,對應的點都找不到了,就無法映射回原圖,就回歸不了了。但作者通過大量實驗證明,即使是很大的下采樣率,使用了FPN的FCOS依然能擁有不錯的BPR,甚至超越了RetinaNet。所以,BPR對於FCOS來說不是問題。(這裡的結論是作者通過實驗做出來的,和對照組的網路配置有關,感覺上FCOS在這方面應該確實是不如anchor-based檢測器的。)
- 在多個GT框交集的區域,會出現混淆的現象,即不確定該點應該回歸哪個GT框。在這個問題上,作者依然通過實驗證明,對於FCOS來說,使用了FPN同樣能較好解決這個問題。(感覺作者沒有解釋清楚這個原因。)
使用了FPN的FCOS,需要在不同特徵層處預測不同大小的物體。不像anchor-based那樣,為每層特徵層指定不同大小的錨點框。FCOS則是首先為每個特徵圖的位置點計算需要回歸的距離$(l^*,t^*,r^*,b^*)$。當$m_{i-1}<max(l^*,t^*,r^*,b^*)<m_i$時,才會認為該點是正樣本,送入迴歸。其中,$m_i$表示第$i$層特徵圖的最大回歸距離。即迴歸的4個值中的最大值需要位於兩個特徵層的最大回歸距離之間。也可以理解成該特徵層只對大小為$[m_{i-1},m_i]$的物體進行迴歸。當這個最大值超出最大回歸距離範圍之間時,就認為是負樣本,不進行訓練。這樣做是因為應該對迴歸進行限制,不可能無限制的迴歸,進行大值迴歸可能效果不好,與錨點框的思想一致。
在最後進行預測和迴歸的時候,FPN中不同特徵層共享同一個head(即那4組卷積),這樣做不僅節省了引數,而且還提高了檢測效能。但是,不同特徵層用來回歸不同尺寸的目標,讓所有特徵層共享一個head似乎不太合理。因此,作者使用了一組可以訓練的變數$s_i$來為每層特徵層自動調整指數函式的底,所以,在迴歸頭處使用的指數函式不再是$e^x$,而是$e^{s_ix}$。
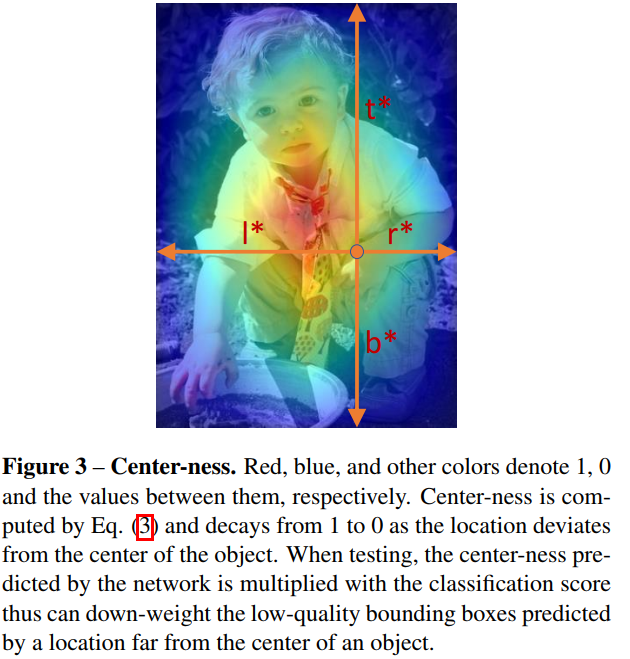
即使使用了FPN,FCOS的效能依然與anchor-based的檢測器有差距,原因是遠離目標中的為位置會產生大量低質量的預測框,就是離目標中心越遠,預測框的效果反而更差。因此,作者想要在不引入超參的情況下,抑制這些低質量的檢測框,其做法就是引入了一條分支Center-ness。這條Center-ness分支輸出一個$H\times W\times 1$的tensor,表示該點到目標中心點的“距離權重”,如下圖所示,“距離權重”的值在$[0,1]$之間。在測試的時候,最終輸出的分數應該是Center-ness與分類置信度的得分進行相乘。所以,Center-ness能起到降低遠離目標中心的得分權重的作用。而Center-ness的另一種替代形式是隻使用真實框中心的附近點作為正樣本,人為引入一個超參來抑制遠距離的特徵點的影響。作者發現,將這兩種方式進行結合起來使用,能取得更佳的效果。
$$centerness^*=\sqrt{\frac{min(l^*,r^*)}{max(l^*,r^*)}\times \frac{min(t^*,b^*)}{max(t^*,b^*)}}$$
最終損失函式的組成應該有3部分,分別是置信度損失、迴歸損失和centerness損失(二值交叉熵損失)。其中,$\lambda $和$\alpha $分別平衡兩者的權重。可以看出,損失函式中都是隻是用正樣本參與計算。在原始碼中計算損失函式時,centerness層的值除了計算二值交叉熵損失外,還會與迴歸損失進行結合,降低遠離中心點的特徵點的迴歸損失。而在測試時,centerness層的值直接與置信度相乘,使用相乘後的置信度來進行後處理。
$$Loss=\frac{1}{N_{pos}}\sum_{x,y}L_{cls}(p_{x,y},c^*_{x,y})+\frac{\lambda }{N_{pos}}\sum_{x,y}\mathbb{I}_{c^*_{x,y}}L_{reg}(t_{x,y},t^*_{x,y})+\alpha L_{center-ness}(d,d^*)$$
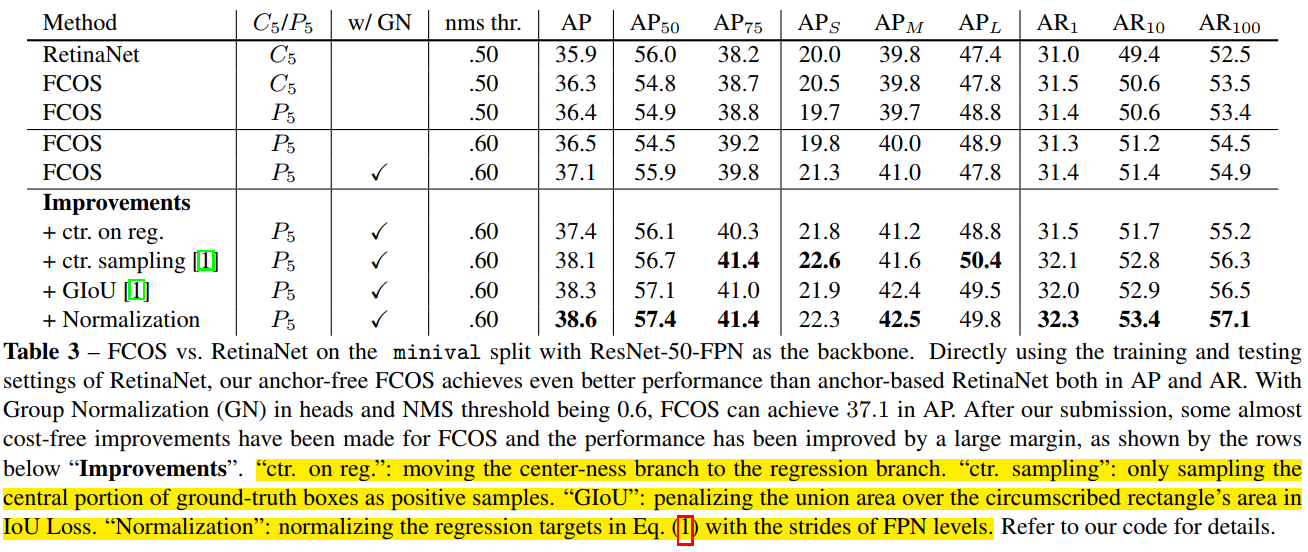
下圖是FCOS演算法的效能,可以看出,在不採取改進措施的前提下,FCOS已經能和RetinaNet媲美了。在使用了(a)center-ness層放在迴歸頭處、(b)只在目標框的中心附近取樣、(c)使用GIOU作為迴歸損失函式、(d)標準化目標迴歸函式,等改進措施後,效能更是進一步提高。
參考資料:
- FCOS : 找到訣竅了,anchor-free的one-stage目標檢測演算法也可以很準 | ICCV 2019
- FCOS演算法詳解
- FCOS原始碼
以上我是在覺得在one stage目標檢測中比較經典的演算法,為此特意準備回顧了一下。歡迎批評指