
Solr搜尋解析及查詢解析器用法概述
一.簡介
大多數查詢都使用 了標準的Solr語法。這種語法是Solr最常見的,由預設查詢解析器負責處理。Solr的預設查詢解析器是Lucene查詢解析器【LuceneQParserPlugin類實現】。Lucene查詢解析器全面支援Lucene語法及Solr的一些專用擴充套件。
二.Lucene查詢解析器語法
1.欄位搜尋
在Solr索引中搜索一個值時,一般來說是在特定欄位上進行查詢。欄位搜尋語法是:欄位名稱+‘:’+搜尋內容,舉例如下:
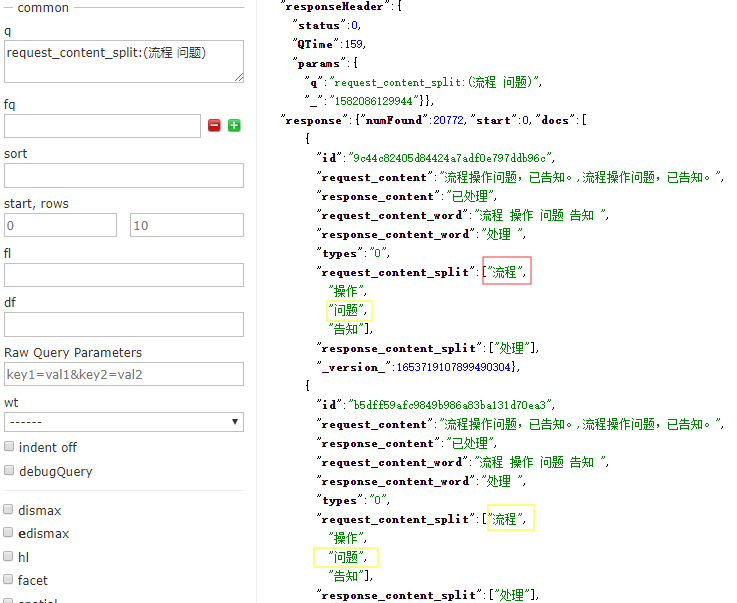
title:solr 或 title:"apache solr" request_content_split:(流程 問題) 備註:括號表示集合,用空格隔開每個元素,預設表示OR的含義
儘管關鍵詞搜尋不明確指定欄位的做法很常見,大需要注意的是,一般在定義的預設欄位上進行關鍵詞搜尋。舉例來說,如果content定義為預設欄位【df=content】,則以下兩個查詢是等價的:
solr 或 content:solr
還需要注意的是,欄位和冒號後面的表示式範圍必須明確定義。以下兩個查詢是等價的【假設df=content】,不過在第一個查詢中使用者可能存在其他意圖。
title:apache solr 或 title:apache content:solr
如果在同一個欄位中搜索多個詞項,使用組合表示式,在欄位搜尋中指定詞項的範圍:
title:(apache solr)
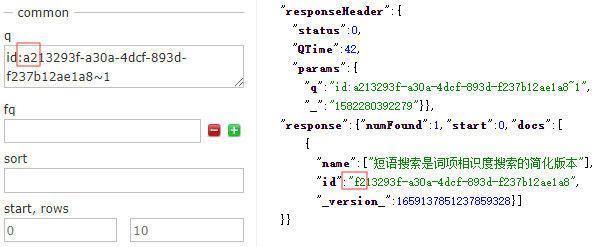
如果嘗試短語搜尋,使用引號【而不是括號】來定義短語範圍,儘管這樣會導致查詢要求短語的所有詞項必須同時出現。
title:"apache solr"
2.必備詞項【使用較少】
為指定一個或多個詞項必須出現,使用一元運算子+來連線詞項。除非文件包含指定的詞項,否則不予匹配。如果匹配的文件必須包含多個詞項,使用二元運算子AND或&&,否則對每個詞項都使用一元運算子+。

如果預設運算子是AND,在沒有指定其他運算子的情況下,每個詞項都要求必備。由於每增加一個必備詞項都會進一步限制文件集中的結果總數,因此通過使用多個必備詞項可以加快查詢速度,從而進一步優化結果數量。
3.可選詞項
相比限制必備欄位的做法,擴大匹配的文件數量則適用於另外一些情況。預設運算子是OR,除非有其他指定,否則每個表示式都是可選的。同樣地,多個表示式之間使用二元運算子OR或||,這表示匹配的文件中至少包含其中一個詞項。

值得注意的是,可選詞項越多會導致匹配文件集越大,OR運算比其它布林運算的執行成本更高。對於關鍵詞搜尋,如果內容數量有限,而且希望以犧牲查準率為代價,確保能夠返回一些結果【更高的查全率】,那麼會考慮使用OR作為預設運算子。由於多個可選詞項的文件匹配通常會導致較高的相關度得分,使用OR作為預設運算子並根據相關度得分排名的話,仍然有可能獲得搜尋結果中最相關的那部分結果。不過,與要求匹配所有關鍵詞不同的是,擴充套件查詢會得到更多一些奇怪的匹配結果。
4.短語搜尋【使用較少,且必須使用在使用了分詞器的欄位上】
如果想要匹配彼此相鄰的多個詞項,使用引號把它們括起來視為一個短語。此查詢表示式不能保證匹配出完全一樣的文字,被搜尋欄位可能包含對短語中詞項進行修改的分析器。最合理的特定短語搜尋不應該匹配無關的短語。短語搜尋適用於內容中特定欄位和多詞名稱的處理。
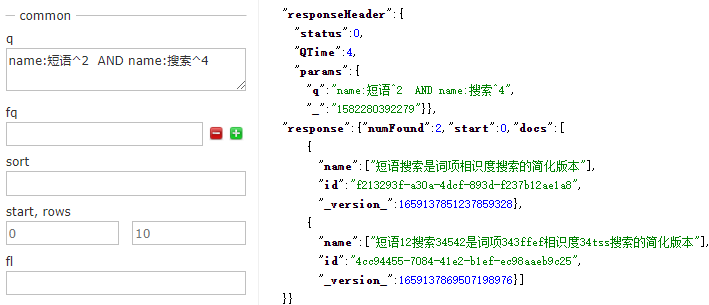
5.組合表示式【常用】
為處理任意複雜的布林子句,Solr使用括號將查詢表示式組合在一起。
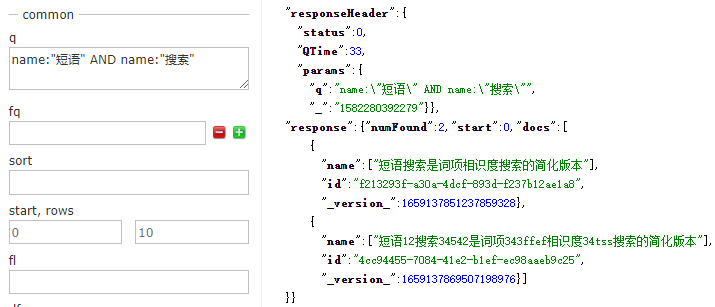
組合表示式可以設定表示式的上下文,例如,指明在同一個欄位中搜索多個單詞。組合表示式可以任意巢狀。
6.詞項鄰近度
短語搜尋是詞項相似度搜索的簡化版本。通過新增波浪線和詞項位置距離數搜尋位置相近的詞項,不一定是相鄰的。
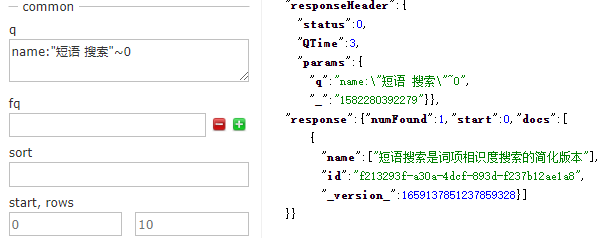
短語搜尋是詞項位置距離為0的鄰近搜尋。
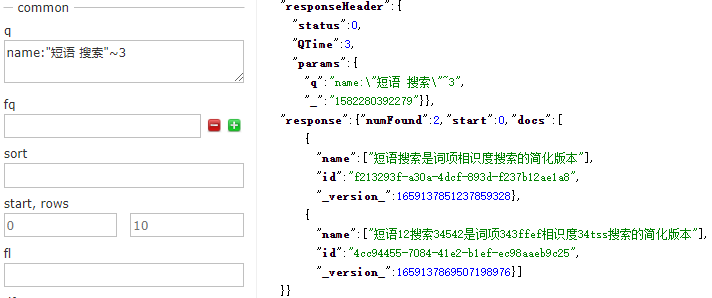
詞項距離為3表示查詢兩詞之間詞項距離<=3的搜尋,兩詞項交換位置相當於移動了兩個詞項位置。
指定足夠大的有效鄰近值,可以匹配出文件中任意位置的詞項,這與AND查詢效果類似。詞項鄰近度查詢還有一個副作用,在文件中詞項越靠近,該鄰接查詢對應的相關度得分就越高。與組合查詢相比,當詞項距離較大時,使用鄰近詞搜尋花費成本更高。
7.字元鄰近
不僅可以在詞項之間進行鄰近搜尋,還可以對詞項中的字元進行基於編輯距離的搜尋,找到拼寫相似的詞項。字元鄰近搜尋的語法與詞項鄰近搜尋類似,由於字元鄰近搜尋處理的是一個詞項,因此不帶引號。
1表示與搜尋詞項最多有一個字元的差距,包括多一個字元,少一個字元和一個字元不一樣三種情況。
8.排除詞項
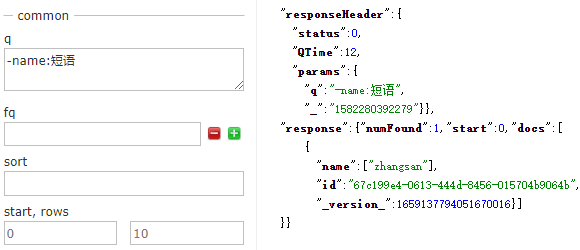
有時我們需要從查詢中明確排除特定詞項。在表示式上使用一元運算子-【減號】或在表示式之間使用NOT布林運算子來排除詞項。
或

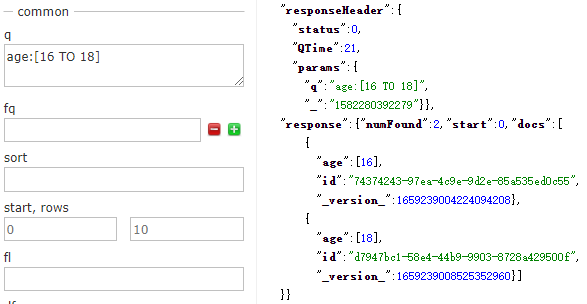
9.區間搜尋【方括號為閉區間,花括號為開區間】
有時候我們不希望查詢表示式只匹配出一個值,而是匹配出值的整個區間。區間可以是數值區間、日期區間或字串區間。區間搜尋能夠找到指定的一組值,其語法為欄位名加冒號再加一個方括號。
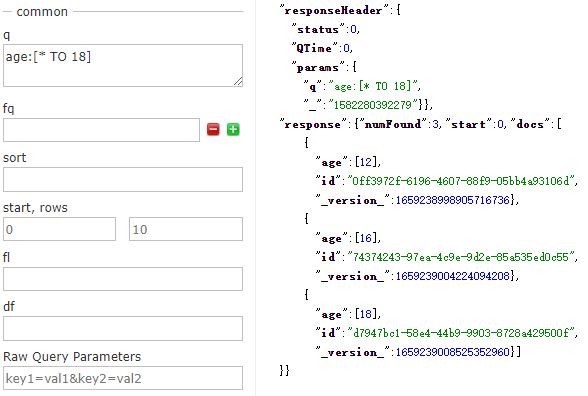
如果沒有指定區間的最大值和最小值,則需要對開區間的上限和下線使用萬用字元*
10.萬用字元搜尋
有些情況下使用者需要對Solr索引中單詞或短語的變體進行匹配。對於使用者輸入的大多數關鍵詞而言,詞幹提取這類技術讓萬用字元搜尋變得沒那麼重要了,然而對於查詢以特定字符集開頭的文件或替代單個字元的操作,萬用字元搜尋還是還有用武之地的。
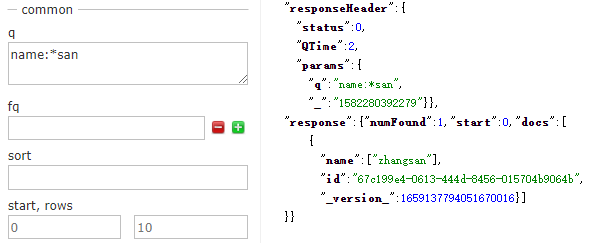
11.權重表示式
如果表示式後面指定了一個插入號【^】,無論是詞項、短語還是組合表示式,都可以調整相關度權重。
12.特殊字元轉義【分詞器欄位除外】
Solr中有些字元是保留字元,也就是說,它們被當做查詢語法進行解析,而不是作為搜尋詞項。包括:
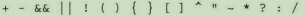
如果要搜尋保留字元,必須將保留字元用引號括起來,或者使用反斜槓對其進行轉義。關鍵詞中處理保留字元的推薦做法是在傳入Solr之前去除沒有搜尋價值的保留字元,或者對它們依次使用反斜槓進行轉義。

當搜尋欄位為分詞器欄位時,保留字元會被分詞過濾掉,因此搜尋時不加保留字元也可以搜尋到!

相關推薦
Solr搜尋解析及查詢解析器用法概述
一.簡介 大多數查詢都使用 了標準的Solr語法。這種語法是Solr最常見的,由預設查詢解析器負責處理。Solr的預設查詢解析器是Lucene查詢解析器【LuceneQParserPlugin類實現】。Lucene查詢解析器全面支援Lucene語法及Solr的一些專用擴充套件。 二.Lucene查詢解析器
29--aspectj-autoproxy解析及Spring解析自定義標籤
前兩個小節已經介紹了AOP的一些基礎知識回顧並對靜態代理、JDK動態代理、CGLIB動態代理做了一些簡單的介紹,本節介紹AOP標籤的解析過程。 1.aspectj-autoproxy標籤簡介 使用註解方式應用aop需要在配置檔案中配置<aop:aspect
32--aspectj-autoproxy解析及Spring解析自定義標籤
前面的章節已經介紹了AOP的相關概念和一些知識點,接下來我們就要開始分析SpringAOP的原始碼了,接下來的分析都基於@AspectJ註解。雖然@AspectJ是基於註解的方式實現AOP,但還是要在配置檔案中配置<aop:aspectj-autoprox
Solr查詢配置及優化【eDisMax查詢解析器】
一.簡介 Lucene查詢解析器語法支援建立任意複雜的布林查詢,但還有一些缺點,它不是使用者查詢處理的理想解決方案。這裡面最大的問題是Lucene查詢解析器的語法要求嚴格,一旦破壞就會丟擲異常。指望使用者在輸入關鍵詞時能夠理解Lucene查詢語法並始終能輸入完美的查詢表示式,這顯然是不合理的。這意味著,L
Solr Dismax查詢解析器-深入分析
Solr 支援多種查詢解析,給搜尋引擎開發人員提供靈活的查詢解析。Solr 中主要包含這幾個查詢解析器:標準查詢解析器、DisMax 查詢解析器,擴充套件 DisMax 查詢解析器(eDisMax) Dismax Dismax handler比standard han
Java中compareTo用法及原始碼解析
最近遇到一個問題,在日期比較的時候,很麻煩,因為日期比較沒有大於等於,只有大於或者小於,這就導致在比較時間的時候特別麻煩,而且還要由string轉成date格式才能比較,下面是我使用compareTo比較時間字串的程式碼: String putStartTime = Date
排序演算法: 三大中級排序演算法,原理解析及用法
三大中級演算法 難度 ★★ 演算法複雜度O(nlogn) 一般情況下排序時間: 快速排序< 歸併排序 < 堆排序 快速排序: 缺點極端情況下效率低 堆排序: 缺點在快的排序演算法中相對慢 歸併排序: 缺點要有額外記憶體空間 快速
balance transfer程式碼解析及api深度追蹤(七)查詢交易
一程式碼解析 var queryChaincode = function(peer, channelName, chaincodeName, args, fcn, username, org) { var channel = helper.getChannelF
css3屬性box-sizing:border-box 用法解析及經常使用的場景
響應式Web設計經常需要我們通過百分比設定元件寬度。如果我們不考慮邊框,那麼很容易就可以實現,但如果你給每一列以及總寬度都採用百分比設定,那這個時候固定的邊框大小就會出來搗亂。下面我們將看到一組方法去解決這個問題,你會學到如何建立一個流式佈局,而不用擔心額外的邊框以及內邊距。
C++中static_cast, dynamic_cast, const_cast用法/使用情況及區別解析
目錄 首先回顧一下C++型別轉換: C++型別轉換分為:隱式型別轉換和顯式型別轉換 第1部分. 隱式型別轉換 又稱為“標準轉換”,包括以下幾種情況: 1) 算術轉換(Arithmetic conversion) : 在混合型別的算術表示式
蜂鳴器實現音樂播放及應用解析、程式碼實現
兩者區別 首先,需要說明的是,這裡的“源”不是指電源。而是指震盪源。 無源蜂鳴器的特點是: 1、 無源內部不帶震盪源,所以如果用直流訊號無法令其鳴叫。必須用2K~5K的方波(建議使用PWM)去驅動它 &nbs
Postgre查詢優化器--上篇 原理解析
本章節將從原始碼的角度來分析PG優化器的原理,工作方式,本文大部分內容來自 李海翔 《資料庫優化器的藝術》 PG的查詢執行過程 從表象來分析PG的查詢執行過程,從而深入理解架構層次,從PG的查詢執行過程分為4個階段,跟mysql的過程有點類似 語法分析階段,語義分析階段,優化階段,這
html中標籤用法解析及如何設定checkbox複選框的預設選中狀態
本文導語: html中<checkbox>標籤用法解析及如何設定checkbox複選框的預設選中狀態(由www.169it.com蒐集整理)html中複選框Checkbox物件代表一個 HTML 表單中的 一個選擇框。html中複選框Checkbox物件的屬性屬性 描述a...
ORMLite完全解析(三)官方文件第三章、自定義查詢構造器 Custom Query Builder
接著上一篇,下面是第三章的翻譯整理,理解錯誤的地方還請批評指正。 第三章、 自定義查詢構造器 3.1 查詢構造器基礎 下面是使用查詢構造器建立自定義查詢語句的基本步驟。首先,以java常量的形式為屬性設定列名,便於使用它 們進行
關於react-redux中的connect用法介紹及原理解析
關於react-redux的一個流程圖 流程圖 connect用法介紹 connect方法宣告: connect([mapStateToProps], [mapDispatchToProps], [mergeProps],[options]) 作用:連線Reac
Solr 6.0 學習(八) SolrDispatchFilter原始碼解析及solr擴充套件
SolrDispatchFilter做了什麼 我們釋出好我們的solr6.X之後我們可以看到專案下web.xml中一段配置 <!-- Any path (name) registered in solrconfig.xml will be
Android Multimedia框架總結(八)Stagefright框架之AwesomePlayer及資料解析器
前言:前面一篇分析了mediaplayerservice及MediaPlayer中的CS模型,但是對於如何能把資料解析出來,渲染到最終的SurfaceView上顯示,並且播放起來,我們依然還不得而知,從今天開始,就開始介紹多媒體框架中資料解析->解碼-
SQL中SUBSTRING函式的用法及例項解析
一、定義:SQL 中的 substring 函式是用來擷取字串中的一部分字元。這個函式的名稱在不同的資料庫中不完全一樣。 MySQL: SUBSTR( ), SUBSTRING( ) Oracle: SUBSTR( ) SQL Server: SUB
SQL join,left join ,right join , inner join , outer join用法解析及HIVE join 優化
Sql程式碼 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) join的快取和任務轉換 hive轉換多表join時,如果每個表在join字句中,使用的都是同
Solr中域及動態域、複製域、域的型別解析
solr中使用的域必須在schema.xml檔案中配置!!!域、動態域、複製域的定義均在schema.xml檔案中。1、<field>標籤定義域引數:indexed:是否索引 stored:是否儲存、 required:是否必須