
論文翻譯:Generalized end-to-end loss for speaker verification
論文地址:2018_說話人驗證的廣義端到端損失
論文程式碼:https://google.github.io/speaker-id/publications/GE2E/
地址:https://www.cnblogs.com/LXP-Never/p/11799985.html
作者:凌逆戰
摘要
在本論文中,我們提出了一種新的損失函式,稱為廣義端到端( generalized end-to-end,GE2E)損失,使得說話人驗證模型的訓練比以往基於元組的端到端(tuple based end to end,TE2E)損失函式更加有效,與TE2E不同,GE2E損失函式以強調例項的方式更新網路,這些例項在訓練過程的每個步驟中都難以驗證。此外,GE2E損失不需要選擇示例的初始階段。利用這些特性,我們的新損失函式模型使說話人驗證EER降低了10%以上,同時使訓練時間減少了60%。從而學習出一個更好的模型。我們還介紹了MultiReader技術,它允許我們進行域自適應訓練一個更精確的模型,該模型支援多個關鍵字(即OK Google和Hey Google)以及多個方言。
索引詞:Speaker verification, end-to end,MultiReader,key word detection
1 引言
1.1 背景
說話者驗證(SV)是使用語音匹配[1、2]等應用程式根據說話者的已知語音(即註冊說話)驗證說話是否屬於特定說話者的過程。
根據用於註冊和驗證的話語限制,說話人驗證模型通常分為兩類:與文字相關的說話人驗證(TD-SV)和文字無關的說話人驗證(TI-SV)。在TD-SV中,註冊和驗證話語的轉錄本都受到語音的限制,而在TI-SV中,在註冊或驗證話語的轉錄本上沒有詞彙限制,暴露音素和話語持續時間的較大變化[3, 4 ]。在這項工作中,我們主要關注TI-SV和TD-SV的一個子任務,稱為global password TD-SV,其中驗證是基於檢測到的關鍵字,例如OK、Google[5,6]
在以往的研究中,基於i-向量的系統一直是TD-SV和TI-SV應用[7]的主要方法。近年來,更多的努力集中在使用神經網路進行說話人驗證,而最成功的系統是使用端到端訓練[8,9,10,11,12]。在這樣的系統中,神經網路輸出向量通常被稱為嵌入向量(也稱為d-向量)。與i-vector的情況類似,這種嵌入可以用於表示固定維空間中的話語,在固定維空間中,可以使用其他通常更簡單的方法來消除說話者之間的歧義。
1.2 Tuple-Based端到端損失
在前面的工作[13]中,我們提出了基於元組的端到端(TE2E)模型,該模型模擬了訓練過程中執行時註冊和驗證的兩階段過程。在我們的實驗中,TE2E模型與LSTM[14]
對於每個輸入元組,我們計算LSTM的L2歸一化響應:${e_{j~}, (e_{k1},...,e_{kM})}$。這裡每個e是一個固定維度的嵌入向量,它是由LSTM定義的序列到向量的對映產生的。元組的質心$(e_{k1},...,e_{kM})$表示由M個話語構建的聲紋,定義如下:
$$公式1:c_k=E_m[e_{km}]=\frac{1}{M}\sum_{m=1}^Me_{km}$$
相似度由余弦相似度函式定義:
$$公式2:s=w*cos(e_{j~},c_k)+b$$
其中$w$和$b$是可訓練引數,TE2E損失最終定義為:
$$公式3:L_T(e_{j~},c_k)=\delta (j,k)\sigma (s)+(1-\delta (j,k))(1-\sigma (s))$$
這裡$\sigma (x)=\frac{1}{(1+e^{-x})}$是標準的sigmoid函式,如果$j=k$那麼$\delta (j,k)=1$,否則等於0。當$k=j$時,TE2E的損失函式激勵s值更大。當$k\neq j$時$s$值更小。考慮到正元組和負元組的更新,這個損失函式與FaceNet中的三重損失非常相似[15]。
1.3 綜述
在本文中,我們介紹了我們的TE2E體系結構的一個推廣。這種新的體系結構以一種更有效的方式從不同長度的輸入序列構建元組,顯著提高了TD-SV和TI-SV的效能和訓練速度。本文組織如下:在第2.1節中給出了GE2E損失函式的定義;第2.2節是GE2E更有效更新模型引數的理論依據;第2.3節介紹了一種稱為“MultiReader”的技術,它使我們能夠訓練支援多種關鍵詞和語言的模型;最後,我們在第3節中給出了我們的實驗結果。
2 廣義的端到端模型
廣義端到端(GE2E)訓練是基於一次性處理大量的話語,以包含N個說話者的batch的形式,平均每個說話者發出M個話語,如圖1所示。
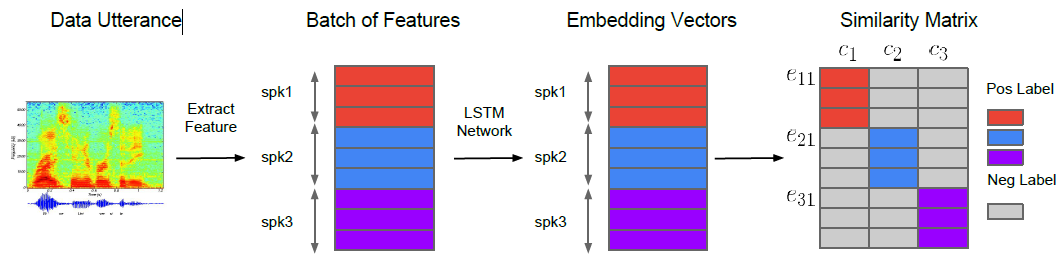
圖1所示。系統概述。不同的顏色表示不同說話者的話語/embeddings(嵌入)。
2.1 訓練模型
我們用N*M個語句來構建一個batch。這些話語來自N個不同的speaker,每個speaker有M個話語。每個特徵向量$x_{ji}$($1\leq j\leq N$和$1\leq i\leq M$)表示從說話人$j$話語$i$中提取的特徵。
與我們之前的工作[13]類似,我們把每一個話語$x_{ji}$提取的特徵輸入到LSTM網路中。線形層作為LSTM層的最後一層,用作資料的變維(把資料轉換成語音幀)。我們將整個神經網路的輸出表示為$f(x_{ji};w)$,其中$w$代表所有神經網路的引數(包括LSTM層和線性層)。嵌入向量(d-vector)定義為網路輸出的L2 歸一化(normalization):
$$公式4:e_{ji}=\frac{f(x_{ji};w)}{||f(x_{ji};w)||_2}$$
其中$e_{ji}$表示第$j$個說話者第$i$個話語的 embedding(嵌入) 向量。第j個說話者的嵌入向量的質心$[e_{j1},...,e_{jm}]$通過公式1被定義為$c_j$。
相似矩陣$S_{ji,k}$定義為每個嵌入向量$e_{ji}$與所有質心$c_k(1\leq j,k\leq N和1\leq i \leq M$之間的縮放餘弦相似性:
$$公式5:S_{ji,k}=w*cos(e_{ji},c_k)+b$$
其中$w$和$b$是可學習:引數,我們將權重約束為正$w>0$,因為當餘弦相似度較大時,我們希望相似度較大。TE2E和GE2E的主要區別如下:
- TE2E的相似度(公式2)是一個標量值,它定義嵌入向量$e_{j~}$和單個元組質心centroid $c_k$之間的相似度。
- GE2E建立了一個相似度矩陣(公式5),定義了每個$e_{ji}$和所有質心centroid $c_k$之間的相似度。
圖1展示了整個過程,包括來自不同說話人的特徵、嵌入向量和相似度評分,用不同的顏色表示。
在訓練中,我們希望每個話語的embedding(嵌入)與所有說話者的centroid(形心)相似,同時遠離其他說話者的centroid。如圖1中的相似矩陣所示,我們希望彩色區域的相似值較大,而灰色區域的相似值較小。圖2以另一種方式說明了相同的概念:我們希望藍色嵌入向量靠近它自己的speaker的形心(藍色三角形),遠離其他的形心(紅色和紫色三角形),特別是最近的那個(紅色三角形)。給定一個嵌入向量$e_{ji}$,所有的centroids(質心)$c_k$,以及相應的相似矩陣$S_{ji,k}$,有兩種方法來實現這個概念:
softmax 我們在$S_{ji,k}$上設定一個softmax,其中$k=1,...,N$,如果$k=j$使輸出等於1,否則使輸出等於0。因此,每個嵌入向量$e_{ji}$上的損失可以定義為:
$$公式6:L(e_{ji})=S_{ji,j}-\log \sum_{k=1}^Nexp(S_{ji,k})$$
這個損失函式意味著我們將每個嵌入向量推到其形心附近,並將其從所有其他形心拉出
Contrast 對比度損失的定義是陽性(positive)對和最積極的陰性(negative)對,如:
$$公式7:\max\limits_{\substack{1\leq k\leq N \\k\neq j}}\sigma (S_{ji,k}})$$
其中$\sigma (x)=\frac{1}{1+e^{-x}}$是sigmoid函式。對於每一個話語,損失中正好增加了兩個部分:
(1)一個正分量,它與嵌入向量和它的真說話人聲紋(形心)之間的正匹配相關。
(2)一個硬 nagative(負)分量,它與嵌入向量和聲紋(形心)之間的負匹配有關,在所有假說話者中相似性最高。
在圖2中,正項對應於將$e_{ji}$(藍色圓)推向$c_j$(藍色三角形)。負項對應於將$e_ji$(藍色圓圈)從$c_k$(紅色三角形)中拉出來,因為$c_k$與$c_{k`}$相比更類似於$e_{ji}$。因此,對比度損失使我們能夠集中於嵌入向量和負質心對。
在我們的實驗中,我們發現GE2E損失的兩種實現都是有用的:contrast 損失在TD-SV中表現更好,而softmax 損失在TI-SV中表現稍好。
此外,我們還觀察到,在計算真正說話者的質心時去掉$e_{ji}$可以使訓練變得穩定,並有助於避免繁瑣的解決方案。因此,雖然我們在計算負相似性$(i.e.,k\neq j)$時仍然使用方程式1,但當$k=j$時,我們使用方程式8:
$$公式8:c_j^{-i}=\frac{1}{M-1}\sum_{m=1\\m\neq i}^Me_{jm}$$
$$公式9:S_{ji,k}=\left\{\begin{matrix}
w*\cos (e_{ji,c_j^{-i}})+b&&k=j\\
w*\cos (e_{ji},c_k)+b&&otherwise
\end{matrix}\right.$$
結合方程式4、6、7和9,最終的GE2E損失$L_G$是相似矩陣上所有損失的總和$(1\leq j\leq N,1\leq i\leq M)$
$$公式10:L_G(x;w)=L_G(S)=\sum_{j,i}L(e_{ji})$$
2.2 TE2E與GE2E的比較
考慮GE2E中的單個batch loss更新:我們有N個說話人,每個說話人有M個話語。每一步更新都會將所有N*M的嵌入向量推向它們自己的中心,並將它們拉離其他中心。
這反映了TE2E損失函式[13]中每個$x_{ji}$的所有可能元組的情況。假設我們在比較說話者$j$時隨機選擇P個話語:
1、Positive 元組:對於$\{x_{ji},(x_{j,i_1},...,x_{j,i_p})\}$,其中$1\leq i_p\leq M$,$p=1,...,P$。有$\begin{pmatrix}M\\ P\end{pmatrix}$個這樣的正元組。
2、Nagative 元組:$\{x_{ji},(x_{k,i_1},...,x_{k,i_p})\},k\neq j$和$1\leq i_p\leq M,p=1,...,P$。對於每一個$x_{ji}$,我們必須與其他所有的N-1給質心進行比較,其中每一組比較都包含$\begin{pmatrix}M\\ P\end{pmatrix}$個元組。
每個正元組與一個負元組進行平衡,因此總數是正元組和負元組的最大數目乘以2。因此,TE2E損失的元組總數為:
$$公式11:
2 \times \max \left(\left(\begin{array}{c}{M} \\{P}\end{array}\right),(N-1)\left(\begin{array}{c}{M} \\{P}\end{array}\right)\right) \geq 2(N-1)
$$
公式11的下界出現在$P=M$時。因此,GE2E中的每個$x_{ji}$更新至少與TE2E中的兩個(N-1)步驟相同。上面的分析說明了為什麼GE2E比TE2E更有效地更新模型,這與我們的經驗觀察一致:GE2E在更短的時間內收斂到更好的模型(詳見第3節)。
2.3 訓練MultiReader
考慮以下情況:我們關心小資料集$D_1$模型的應用。同時,我們有一個更大的資料集$D_2$在一個類似的,但不是相同的領域。我們想要在$D_2$的幫助下,訓練一個在$D_1$資料集上表現良好的模型:
$$公式12:
L\left(D_{1}, D_{2} ; \mathbf{w}\right)=\mathbb{E}_{x \in D_{1}}[L(\mathbf{x} ; \mathbf{w})]+\alpha \mathbb{E}_{x \in D_{2}}[L(\mathbf{x} ; \mathbf{w})]
$$
這類似於正則化技術:在正規正則化中,我們使用$\alpha||w||_2^2$對模型進行正則化。但在這裡,我們使用$E_{x\in D_2}[L(x;w)]$進行正則化。當資料集$D_1$沒有足夠的資料時,在$D_1$上訓練網路會導致過度擬合。要求網路在$D_2$上也表現得相當好有助於使網路正規化。
這可以概括為組合K個不同的、可能極不平衡的資料來源:$D_1,...,D_K$。我們給每個資料來源分配一個權重$\alpha_k$,表示該資料來源的重要性。在訓練過程中,在每個步驟中,我們從每個資料來源中提取一batch(批)/一tuple(組)話語,並計算聯合損失:$L(D_1,...,D_K)=\sum_{k=1}^K\alpha_kE_{x_k\in D_k}[L(x_k;w)]$,其中每個$L(x_k;w)$是等式10中定義的損失。
3 實驗
在我們的實驗中,特徵提取過程與[6]相同。首先將音訊訊號轉換為寬為25ms,步長為10ms的幀。然後我們提取40維的log-mel-filterbank能量作為每個幀的特徵。對於TD-SV應用程式,關鍵字檢測和說話人驗證都使用相同的功能。關鍵字檢測系統只會將包含關鍵字的幀傳遞給說話者驗證系統。這些幀構成一個固定長度(通常為800ms)的段。對於TI-SV應用,我們通常在語音活動檢測(VAD)後提取隨機定長片段,並使用滑動視窗方法進行推理(在第3.2節中討論)。
我們的產品系統使用帶有projection[16]的三層LSTM。嵌入向量(d-向量)大小與LSTM projection(投影)大小相同。對於TD-SV,我們使用了128個隱藏節點,投影大小為64。對於TI-SV,我們使用了768個隱藏節點,投影大小為256。當訓練GE2E模型時,每批包含N = 64個說話者,M = 10個說話者。我們使用初始學習率0.01用SGD訓練網路,每30M步減少一半。將梯度的l2範數裁剪為3[17],將LSTM中投影節點的梯度比例尺設定為0.5。關於比例因子$(w,b)$在損失函式中,我們還觀察到一個好的初值是$(w,b) = (10,-5)$,較小的梯度scale 0.01有助於平滑收斂。
3.1 文字依賴說話人驗證
雖然現有的語音助手通常只支援一個關鍵字,但研究表明,使用者更希望同時支援多個關鍵字。對於谷歌Home的多使用者,同時支援兩個關鍵字:OK谷歌和Hey谷歌。
啟用多個關鍵字的說話人驗證介於TD-SV和TI-SV之間,因為文字既不受單個短語的約束,也不完全不受約束。我們使用MultiReader技術解決了這個問題(第2.3節)。與更簡單的方法(如直接混合多個數據源)相比,MultiReader有很大的優勢,它可以處理不同資料來源大小不平衡的情況。在我們的案例中,我們有兩個用於數量的資料來源:1)一個來自匿名使用者查詢的“OK Google”資料集,其中約有150M條語音和約630K個說話人;2)一個混合的“OK/Hey Google”資料集,其中約有1.2M條語音和約1800個說話人。第一個資料集比第二個資料集大125倍的話語數和35倍的說話人數。
為了評估,我們報告了四種情況的等錯誤率(EER):用任一關鍵字註冊,並驗證任一關鍵字。所有的評價資料集都是從665個說話者中手動收集的,平均每個說話者有4.5個登記話語和10個評價話語。結果如表1所示。正如我們所看到的,MultiReader在所有四種情況下都帶來了大約30%的相對改進。
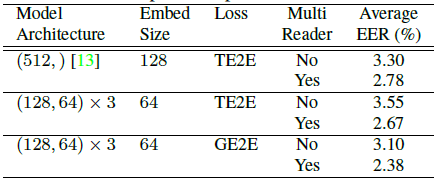
我們還對一個更大的資料集進行了更全面的評估,該資料集來自約83K個不同的說話人和環境條件,包括匿名日誌和手動收集。我們平均每個說話者使用7.3註冊話語和5個評價話語。表2總結了使用和不使用MultiReader設定訓練的不同損失函式的平均能效比。基線模型是具有512個節點和128個嵌入向量大小的單層LSTM[13]。第二和第三行模型架構是三層LSTM。比較第2行和第3行,我們發現GE2E比TE2E好10%左右。與表1類似,這裡我們還看到,使用MultiReader時,該模型的效能明顯更好。雖然沒有顯示在表中,但也值得注意的是,GE2E模型的訓練時間比TE2E少了約60%。
表1:MultiReader vs directly mixing multiple data sources
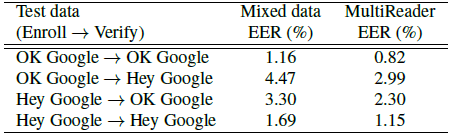
表2:文字依賴的說話人驗證EER
3.2 文字獨立說話人驗證
在TI-SV訓練中,我們將訓練話語分成更小的片段,我們稱之為部分話語。雖然我們不要求所有的部分話語都具有相同的長度,但同一batch的所有部分話語必須具有相同的長度。因此,對於每一批資料,我們在$[lb;ub]=[140;180]$幀內隨機選擇一個時間長度t,並強制該批中的所有部分語句都是長度t(如圖3所示)。
在推理過程中,我們對每一個話語應用一個固定大小的滑動視窗$(lb+ub)/2=160$幀,50%重疊。我們計算每個視窗的d-vector。最後一個與話語相關的d向量是通過L2規範化視窗相關的d向量,然後取元素相關的平均值(如圖4所示)生成的。
我們的TI-SV模型是對來自18K個說話人的大約36M個話語進行訓練的,這些話語是從匿名日誌中提取的。為了評估,我們使用了另外1000個演講者,平均每個演講者有6.3條註冊話語和7.2條評估話語。表3顯示了不同訓練損失函式之間的效能比較。第一列是softmax,它預測訓練資料中所有揚聲器的揚聲器標籤。第二列是用TE2E損失訓練的模型。第三列是用GE2E損失訓練的模型。如表所示,GE2E的效能優於softmax和TE2E,EER效能改善大於10%。此外,我們還觀察到,GE2E訓練比其他損失函式快約3倍。
表3:文字無關的說話人驗證EER(%)

4 總結
在本文中,我們提出了廣義端到端(GE2E)損失函式來更有效地訓練說話人驗證模型。理論和實驗結果都驗證了該損失函式的優越性。我們還引入了MultiReader技術來組合不同的資料來源,使我們的模型能夠支援多個關鍵字和多種語言。通過結合這兩種技術,我們得到了更精確的說話人驗證模型。
5 參考文獻
[1] Yury Pinsky, “Tomato, tomahto.google home now supports multiple users,”https://www.blog.google/products/assistant/tomato-tomahtogoogle-home-now-supports-multiple-users, 2017.
[2] Mihai Matei, “Voice match will allow google home to recognize your voice,”https://www.androidheadlines.com/2017/10/voice-matchwill-allow-google-home-to-recognize-your-voice.html, 2017.
[3] Tomi Kinnunen and Haizhou Li, “An overview of textindependent speaker recognition: From features to supervectors,” Speech communication, vol. 52, no. 1, pp. 12–40, 2010.
[4] Fr´ed´eric Bimbot, Jean-Franc¸ois Bonastre, Corinne Fredouille,Guillaume Gravier, Ivan Magrin-Chagnolleau, Sylvain Meignier, Teva Merlin, Javier Ortega-Garc´ıa, Dijana Petrovska-Delacr´etaz, and Douglas A Reynolds, “A tutorial on text-independent speaker verification,” EURASIP journal on applied signal processing, vol. 2004, pp. 430–451, 2004.
[5] Guoguo Chen, Carolina Parada, and Georg Heigold, “Smallfootprint keyword spotting using deep neural networks,” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 4087–4091.
[6] Rohit Prabhavalkar, Raziel Alvarez, Carolina Parada, Preetum Nakkiran, and Tara N Sainath, “Automatic gain control and multi-style training for robust small-footprint keyword spotting with deep neural networks,” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on.IEEE, 2015, pp. 4704–4708.
[7] Najim Dehak, Patrick J Kenny, R´eda Dehak, Pierre Dumouchel, and Pierre Ouellet, “Front-end factor analysis for speaker verification,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2011.
[8] Ehsan Variani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Javier Gonzalez-Dominguez, “Deep neural networks for small footprint text-dependent speaker verification,” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 4052–4056.
[9] Yu-hsin Chen, Ignacio Lopez-Moreno, Tara N Sainath, Mirk´o Visontai, Raziel Alvarez, and Carolina Parada, “Locallyconnected and convolutional neural networks for small footprint speaker recognition,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
[10] Chao Li, Xiaokong Ma, Bing Jiang, Xiangang Li, Xuewei Zhang, Xiao Liu, Ying Cao, Ajay Kannan, and Zhenyao Zhu,“Deep speaker: an end-to-end neural speaker embedding system,” CoRR, vol. abs/1705.02304, 2017.
[11] Shi-Xiong Zhang, Zhuo Chen, Yong Zhao, Jinyu Li, and Yifan Gong, “End-to-end attention based text-dependent speaker verification,” CoRR, vol. abs/1701.00562, 2017.
[12] Seyed Omid Sadjadi, Sriram Ganapathy, and Jason W. Pelecanos,“The IBM 2016 speaker recognition system,” CoRR,vol. abs/1602.07291, 2016.
[13] Georg Heigold, Ignacio Moreno, Samy Bengio, and Noam Shazeer, “End-to-end text-dependent speaker verification,”in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE, 2016, pp. 5115–5119.
[14] Sepp Hochreiter and J¨urgen Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780,1997.
[15] Florian Schroff, Dmitry Kalenichenko, and James Philbin,“Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 815–823.
[16] Has¸im Sak, Andrew Senior, and Franc¸oise Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling,” in Fifteenth Annual Conference of the International Speech Communication Association, 2014.
[17] Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio, “Understanding the exploding gradient problem,” CoRR, vol.abs/1211.5063, 2012.
&n