
領域驅動設計(DDD)實踐之路(一)
本文首發於 vivo網際網路技術 微信公眾號
連結: https://mp.weixin.qq.com/s/gk-Hb84Dt7JqBRVkMqM7Eg
作者:張文博
領域驅動設計(Domain Driven Design,DDD)其實並非新理論,大家可以看看 Eric Evans 編著的《領域驅動設計》原稿首版是2003年,距今已十餘年時間。與現在的分散式、微服務相比,絕對是即將步入中年的“老傢伙”了。
直到近些年微服務理論被提出、被網際網路行業廣泛使用,人們似乎又重新發現了領域驅動設計的價值。所以看起來也確實是因為微服務,領域驅動設計才迎來了第二春。
不過我發現大家對DDD也存有一些誤區,使其漸漸成了一門“高深的玄學”,隨之又被大家束之高閣。我本人在過去兩年多的時間裡,研讀過多本DDD相關的經典論著、也請教過一些資深DDDer,並在專案中實踐過。
不過在初步學習、實踐之後我又帶著疑問與自己的思考重新讀了一遍相關的著述理論。逐漸領悟到DDD作為一種思想,其實離我們很近。
我把自己的學習過程、思考編寫成系列文章,與大家一起探討學習,希望大家能夠有所收穫,當然其中不正確的地方也歡迎大家批評指正。
同時,在文章中我也會引用相關的論著或者一些我認為不錯的案例素材,權當是我們對這些知識的詳細詮釋,在這裡一併對這些DDD前輩的不倦探索表示感謝。

(DDD相關的經典論著)
一、關於DDD的誤區
- DDD是解決大型複雜專案的,我們當前業務比較簡單,不適合DDD。
- DDD要有一個完整的、符合DDD原則的程式碼結構,這可能增加程式碼的複雜度,有可能導致專案進度失控。
- DDD是一種框架,應該包含聚合根、實體、領域事件、倉儲定義、限界上下文等一切DDD所倡導的元素;否則你就不是DDDer。
- DDD需要大家嚴格遵循各自模組的邊界,且存在著過多因為解耦帶來的看似冗餘沒用的程式碼,會降低編碼效率,造成“類膨脹”。
二、DDD離我們很近
DDD是什麼?眾裡尋她千百度,驀然回首,“DDD是一種可以借鑑的思想,而非嚴格遵循的方法論”。
1、領域驅動設計中的領域模型
當我們面向業務開發的過程中,應該首先思考領域模型而不是如何建表。
我聽過太多業務開發的聲音,“面試造航母、工作擰螺絲”,日常工作就是建表寫增刪改查。為什麼會有這樣的認知,其根源在於表驅動設計思想而非領域驅動設計。
前者只能增加資料庫的表數量,而後者才會形成長期的、具有業務意義的模型,這樣的系統生命力才更加長久。我們也才能用工程的方法來編碼,從編碼轉身為業務域的開發專家。

有很多關於領域驅動設計的論述中都並未明確我們如何得到“領域”,只有合理的領域模型才能有效驅動設計開發。所以建好領域模型是關鍵,對於領域模型的思考與技術框架升級同樣重要。我曾經在網際網路部門分享過如何進行領域建模,也歡迎大家與我交流溝通,有興趣的讀者也可以重點閱讀一下《UML和模式應用》相關章節。
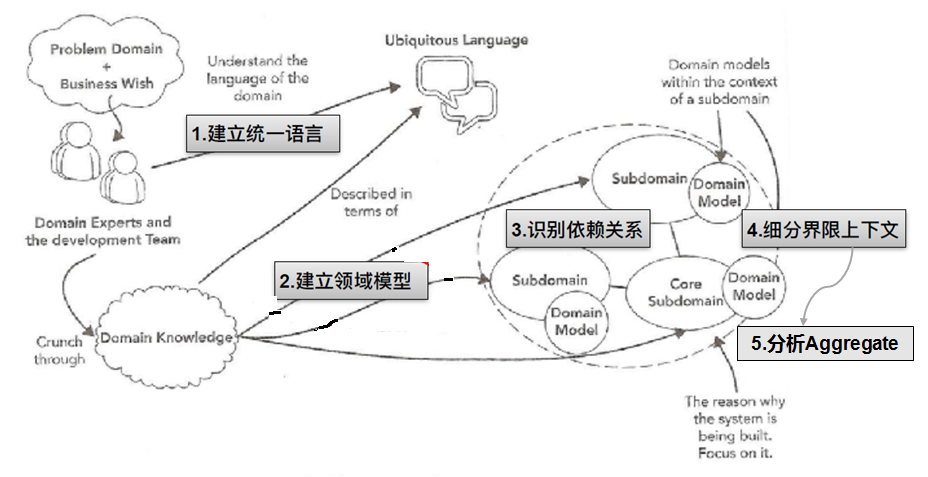
2、架構與解耦
在討論DDD之前我們先來討論一下“解耦”,這個詞是我們在日常編碼時候經常提及的詞語。一個具有工匠精神的程式設計師一定會在程式碼審查階段對一些巨無霸函式或者類進行拆分,使各部分的功能更加聚焦、降低耦合。
另一方面,在架構方面我們也會重視“解耦”,因為一個模組之間隨意耦合的系統將是所有人的噩夢之源。因此,除了整潔的程式碼我們還需要關注整潔的架構。
架構的三要素:職責明確的模組或者元件、元件間明確的關聯關係、約束和指導原則。內聚的元件一定有明確的邊界,而這個明確的邊界必然作為相關的約束指導今後的發展。
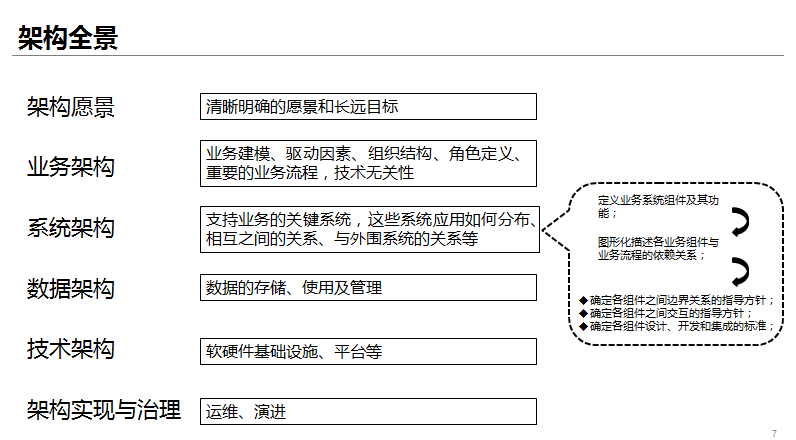
3、從分層架構到六邊形架構
3.1 分層架構
分層架構是運用最為廣泛的架構模式,幾乎每個軟體系統都需要通過層來隔離不同的關注點,以此應對不同需求的變化,使得這種變化可以獨立進行;各個層、甚至同一層中的各個元件都會以不同速率發生變化。
這裡所謂的“以不同速率發生變化”,其實就是引起變化的原因各有不同,這正好是單一職責原則(Single-Responsibility Principle,SRP)的體現。即“一個類應該只有一個引起它變化的原因”,換言之,如果有兩個引起類變化的原因,就需要分離。
單一職責原則可以理解為架構原則,這時要考慮的就不是類,而是層次。例如網路七層協議是一個定義的非常好的、經典的分層架構,簡單、易於學習理解,最終被廣泛使用進而大大推動了網路通訊的發展。
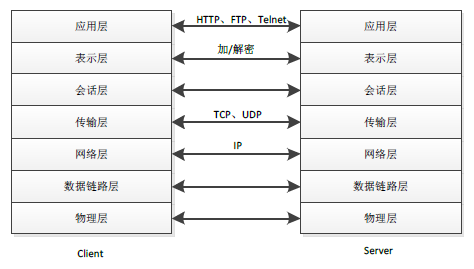
通常情況下,我們會把軟體系統分為這幾個層:UI介面(或者接入層)、應用獨有的業務邏輯、領域普適的業務邏輯、資料庫等。
接下來,還有什麼不同原因的變更呢?答案正是這些業務邏輯本身!在每一層內部,不同的業務場景發生變化的原因、頻次也都不同,不同的場景我們分別定義為業務用例。由此,我們可以總結出一個模式:在將系統水平切分成多個分層的同時,按用例將其切分成多個垂直切片。這樣做的好處就是對單個用例的修改並不會影響其他用例。
如果我們同時對支援這些用例的UI和資料庫也進行了分組,那麼每個用例使用各自的UI表現與資料庫,這樣就做到了自上而下的解耦。另一方面,有層次就有依賴。在OSI協議中,上層透明的依賴下層。但是在軟體架構中,我們更強調“依賴抽象”。即元件A依賴B的功能,我們的做法是在A中定義其需要用到的介面,由B去實現對應介面能力,這樣就做到了可插拔,將來我們可以把B替換為同樣實現了介面能力的元件C而對系統不會造成影響。
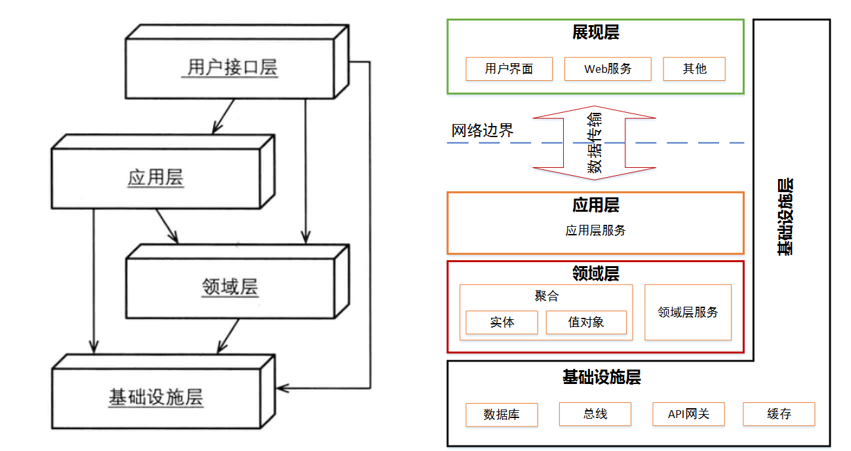
3.2 整潔架構
分層架構中給人的感覺是每一層都同樣重要,但如果我們把關注的重點放在領域層,同時把依賴關係按照業務由重到輕形成一個以領域層為中心的環,即演變為一種整潔的架構風格。這裡不是說其他層不重要,僅僅是為了凸顯承載了業務核心的領域能力。
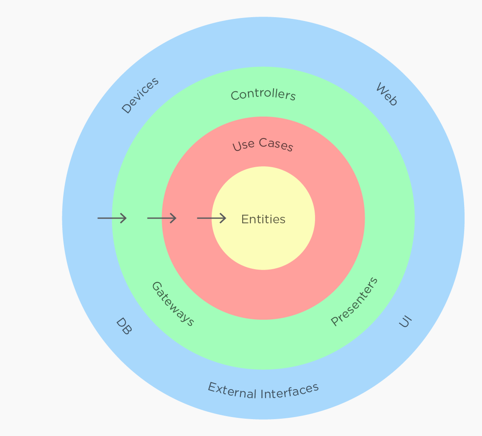
整潔架構最主要原則是依賴原則,它定義了各層的依賴關係,越往裡,依賴越低,程式碼級別越高。外圓程式碼依賴只能指向內圓,內圓不知道外圓的任何事情。一般來說,外圓的宣告(包括方法、類、變數)不能被內圓引用。同樣的,外圓使用的資料格式也不能被內圓使用。
整潔架構各層主要職能如下:
-
Entities:實現領域核心心業務邏輯,它封裝了企業級的業務規則。一個 Entity 可以是一個帶方法的物件,也可以是一個數據結構和方法集合。一般我們建議建立充血模型。
-
Use Cases:實現與使用者操作相關的服務組合與編排,它包含了應用特有的業務規則,封裝和實現了系統的所有用例。
-
Interface Adapters:它把適用於 Use Cases 和 entities 的資料轉換為適用於外部服務的格式,或把外部的資料格式轉換為適用於 Use Casess 和 entities 的格式。
-
Frameworks and Drivers:這是實現所有前端業務細節的地方,UI,Tools,Frameworks 等以及資料庫等基礎設施。
3.3 六邊形架構
我們把整潔架構的外部依賴按照其輸入輸出功能、資源型別進行整合。將儲存、中介軟體、與其他系統的整合、http呼叫分別暴露一個埠。則會演變成下面的架構圖。
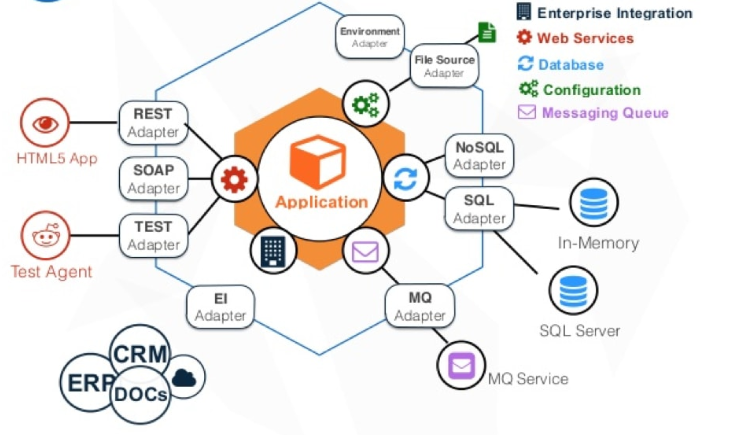
“Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.”“系統能平等地被使用者、其他程式、自動化測試或指令碼驅動,也可以獨立於其最終的執行時裝置和資料庫進行開發和測試”這是六邊形的精髓。
該架構由埠和介面卡組成,所謂埠是應用的入口和出口,在許多語言中,它以介面的形式存在。例如以取消訂單為例,“傳送訂單取消通知”可以被認為是一個出口埠,訂單取消的業務邏輯決定了何時呼叫該埠,訂單資訊決定了埠的輸入,而埠為上游的訂單相關業務遮蔽了其實現細節。
而介面卡分為兩種,主介面卡(別名Driving Adapter)代表使用者如何使用應用,從技術上來說,它們接收使用者輸入,呼叫埠並返回輸出。Rest API是目前最常見的應用使用方式,以取消訂單為例,該介面卡實現Rest API的Endpoint,並呼叫入口埠OrderService,當然service內部可能傳送OrderCancelled事件。同一個埠可能被多種介面卡呼叫,本場景的取消訂單也可能會被實現訊息協議的Driving Adapter呼叫以便非同步取消訂單。
次介面卡(別名Driven Adapter)實現應用的出口埠,向外部工具執行操作,例如向MySQL執行SQL,儲存訂單;使用Elasticsearch的API搜尋產品;使用郵件/簡訊傳送訂單取消通知。有別於傳統的分層形象,形成一個六邊形,因此也會稱作六邊形架構。
4、DDD是一種思想
我愚昧的認為,DDD即業務+解耦。大道至簡、多麼熟悉的場景,因為這就是我們在做的事情,只不過我們可能過於關注使用了什麼技術框架、用了哪些中介軟體、寫了哪些通用的class。
實際上DDD如同辯證唯物主義思想一樣,哪怕我們在軟體專案的某一個環節用到了,只要這個思想為我們解決了實際問題就夠了。我們沒有必要為了DDD而去DDD,我們一定是從問題中來再回到問題中去。
三、DDD有什麼用
藉助DDD可以改變開發者對業務領域的思考方式,要求開發者花費大量的時間和精力來仔細思考業務領域,研究概念和術語,並且和領域專家交流以發現,捕捉和改進通用語言,甚至發現模型乃至系統架構層面的不合理之處。當然有可能你的團隊中並沒有相關業務的專家,那麼此時你自己必須成為業務專家。
通常來說我們可以將DDD的業務價值總結為以下幾點:
-
你獲得了一個非常有用的領域模型;
-
你的業務得到了更準確的定義和理解;
-
領域專家可以為軟體設計做出貢獻;
-
更好的使用者體驗;
-
清晰的模型邊界;
-
更好的企業架構;
-
敏捷、迭代式和持續建模;
-
使用戰略和戰術新工具;
四、如何DDD
通過前面的論述,你腦海裡面一定閃爍幾個詞語“領域模型”“解耦”“依賴抽象”“邊界”。這些通用的分析方法一定是放之四海而皆有效的。所以我認為當你按照這幾個原則進行思考的時候就已經在DDD的路上向前邁進了一步,接下來我們結合界限上下文、Repository這兩個最容易被大家所忽略的地方來進一步闡述。
在這些步驟都做完以後,你再決定接下來如何去編碼開發。不過我敢肯定,你在這個過程中已經得到了很多高業務價值的東西。
接下來如何去實現,你可以根據實際情況。我覺得戰略DDD比戰術DDD更重要,我想這就是DDD作為一種思想的神奇所在。如同金庸筆下的少林絕學易筋經一樣,一套並無明確招式的內功心法卻能打遍武林。
1、界限上下文
領域中還同時存在問題空間(problem space)和解決方案空間(solution space)。在問題空間中,我們思考的是業務所面臨的挑戰,而在解決方案空間中,我們思考如何實現軟體以解決這些業務挑戰。
-
問題空間是領域的一部分,對問題空間的開發將產生一個新的核心域。對問題空間的評估應該同時考慮已有子域和額外所需子域。因此,問題空間是核心域和其他子域的組合。問題空間中的子域通常隨著專案的不同而不同,他們各自關注於當前的業務問題,這使得子域對於問題空間的評估非常有用。子域允許我們快速地瀏覽領域中的各個方面,這些方面對於解決特定的問題是必要的。
-
解決方案空間包含一個或多個界限上下文,即一組特定的軟體模型。這是因為界限上下文是一個特定的解決方案,用以解決問題。
通常,我們希望將子域一對一地對應到限界上下文。這種做法顯式地將領域模型分離到不同的業務板塊中,並將問題空間和解決方案空間融合在一起。
但是在實踐中,這種做法並不總是可能的,想像一下,誰沒有維護過“毛線團”系統,現在我們就要藉助界限上下文來安全的、合理的、快速的理順這堆交織不清的關係。
很多書籍或者文章講解DDD,總是說突出應該怎麼構建程式碼包結構,使用什麼技術框架。我認為這是不完全適用的,所以我會花較多時間來闡述一下如何藉助界限上下文來理順這堆“毛線團”。
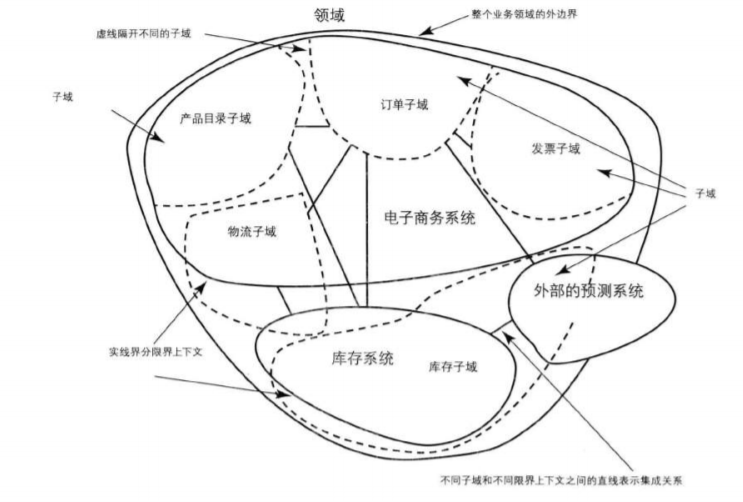
我直接使用了《實現領域驅動設計》的相關章節的配圖,權當是我對這個圖的註釋吧。
遺留的電子商務系統是個典型的“大線團”,我們按照經驗將其在邏輯上拆解為:產品目錄子域、訂單子域、fa票子域,當然你也可以拆解出更多的子域,甚至將產品目錄子域繼續向下分解為類目子域、商品子域(虛線是邏輯子域)。另外還有一個專門用於庫存管理的庫存系統、以及用於銷售預測的預測系統。
由於歷史原因電商系統裡面也存在物流相關的業務邏輯,同時物流又不可避免的作用於庫存邏輯之上。而往往最難以把握的就是這部分相交的地方,這才是實際的專案場景,我們通常做法是將其歸併為一個新的履約系統,作為一個支撐子域去輔助主要的電商系統。
當然,隨著業務不斷髮展,我們的履約模式(比如支援同城當日達、商家倉儲發貨、電商集貨倉發貨、退貨等等)、庫存型別(調撥庫存、越庫操作、臨期庫存、殘次庫存等等)越來越複雜,我們考慮將其再向下分解為履約系統2.0、庫存系統2.0。
核心就是我們可以在概念上使用多個子域來分解較大的界限上下文,也可以將多個分散的界限上下文包含在同一個新的子域當中,最終做到“子域和界限上下文一一對應”。我個人覺得,這個過程是最考驗內功心法的地方。
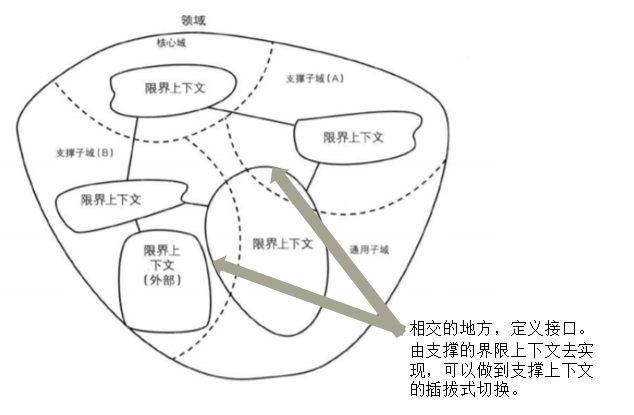
上面我們已經說了會拆解出來新的子域,目的使“整潔乾淨”的界限上下文能夠一對一的解決這個子域對應的問題空間,但是隨著拆解就必然導致“關聯關係”。因為要解決問題空間,必須使用對應的子域,你可以把它拆解出去,但是它始終存在於依賴網中。
我們通用的做法是在相交的地方,定義介面。由支撐的界限上下文去實現,可以做到支撐上下文的插拔式切換。這裡仍然是我們強調的“依賴抽象”“解耦”。
2、Repository
“對於每種需要進行全域性訪問的物件,我們都應該建立另一個物件來作為這些物件的提供方,就像是在記憶體中訪問這些物件的集合一樣。為這些物件建立一個全域性介面以供客戶端訪問。為這些物件建立新增和刪除方法……
此外,我們還應該提供能夠按照某種指定條件來查詢這些物件的方法……只為聚合建立資源庫”引用自《領域驅動設計》。大家和我的疑問一樣,Repository是什麼?DAO與Repository什麼區別?為什麼需要Repository?
首先,Repository 是一個獨立的層,介於領域層與資料對映層(資料訪問層)之間。
它的存在讓領域層感覺不到資料訪問層的存在,它提供一個類似集合的介面提供給領域層進行領域物件的訪問。Repository 是倉庫管理員,領域層需要什麼東西只需告訴倉庫管理員,由倉庫管理員把東西拿給它,並不需要知道東西實際放在哪。其核心還是“解耦”,所以我們應該明確領域層只應該使用Repository獲取物件。
接下來,看看DAO與Repository什麼區別。
我的理解是這樣,你可以將Repository當作 DAO 來看待,但是請注意一點,在設計Repository時,我們應該採用面向集合的方式,而不是面向資料訪問的方式。這有助於你將自己的領域當作模型來看待,而不是 CRUD 操作;Repository是面向領域的,Repository定義的目的不是DB驅動的,Repository管理的資料的最小粒度是聚合根,這兩點和DAO有很大不同。
通常我們建議把Repository定義為一個集合並且只提供類似集合的介面,比如Add,Remove,Get這種操作。一言以蔽之,我們要用集合的思想來操作聚合根,而不是傳統的面向DB的CRUD方法。
最後來看看為什麼需要Repository,我理解還是“解耦”。當我們把Repository想象成一個資源庫,也不關心背後的持久化,這些也不是DDD該思考的東西,我們可以用mysql來實現,也可以用mongo,甚至redis。尤其是當我們在更換底層儲存時候,領域層以及相關的服務並無任何影響。
以下是程式碼示例:
package zwb.ddd.repository.sample.domain;
import zwb.ddd.repository.sample.domain.model.BaseAggregateRoot;
import java.util.List;
/**
* BaseAggregateRoot領域模型的基類,BaseSpecification適用於較為複雜的查詢場景。
* @author wenbo.zhang
* @date 2019-11-20
*/
public interface IRepository<T extends BaseAggregateRoot, Q extends BaseSpecification> {
T ofId(String id);
void add(T t);
void remove(String id);
List<T> querySpecification(Q q);
}
實現類:
package zwb.ddd.repository.sample.infrastructure;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import zwb.ddd.repository.sample.domain.IRepository;
import zwb.ddd.repository.sample.domain.BaseSpecification;
import zwb.ddd.repository.sample.domain.model.BaseAggregateRoot;
import zwb.ddd.repository.sample.domain.model.Customer;
import zwb.ddd.repository.sample.domain.model.CustomerSpecification;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* @author wenbo.zhang
* @date 2019-11-20
*/
@Component
public class CustomerRepository implements IRepository {
/**
* Repository其具體實現上層是無感知的,如果以後我們要切換為redis、mysql只需要修改這一層即可。
*/
Map<String, Customer> customerMap = new ConcurrentHashMap<>();
@Override
public Customer ofId(String id) {
return customerMap.get(id);
}
@Override
public void add(BaseAggregateRoot aggregateRoot) {
if (!(aggregateRoot instanceof Customer)) {
return;
}
Customer customer = (Customer) aggregateRoot;
customerMap.put(customer.getId(), customer);
}
@Override
public void remove(String id) {
customerMap.remove(id);
}
/**
* 我們在Specification裡面定義更加複雜的查詢條件
*
* @param specification 此處舉例:基於id批量查詢
* @return
*/
@Override
public List<Customer> querySpecification(BaseSpecification specification) {
List<Customer> customers = new ArrayList<>();
if (!(specification instanceof CustomerSpecification)) {
return customers;
}
if (CollectionUtils.isEmpty(specification.getIds())) {
return customers;
}
specification.getIds().forEach(id -> {
if (ofId(id) != null) {
customers.add(ofId(id));
}
});
return customers;
}
}在日常專案中我們使用mybatis,所以在Repository中會使用mybatis的DAO來進行操作,下圖是一個涉及到訂購的複雜場景。
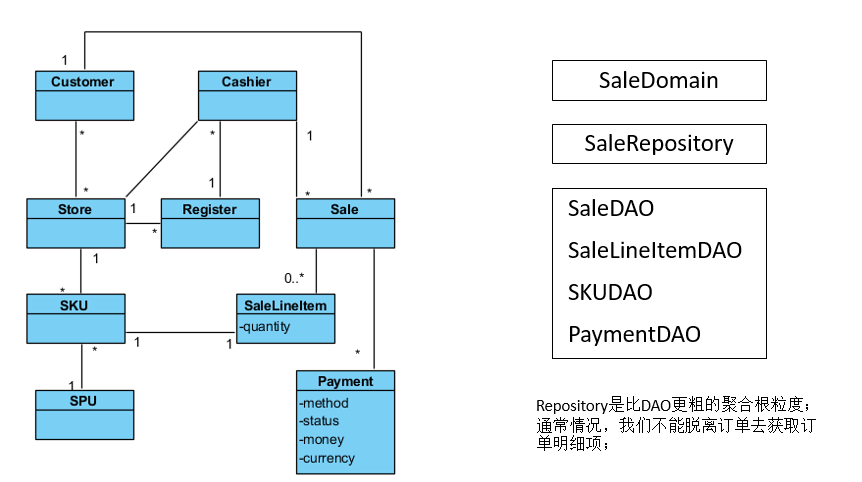
五、實踐:某加盟業務的戰略DDD重構
我們舉一個加盟業務來描述一下界限上下文的劃分,如下圖業務流程應該比較清晰,但是涉及一些術語,因此先把重要的術語定義清楚、降低大家的認知差異。

通用術語:
-
進件:金融領域術語,進件是指把資料準備好後提交給貸款公司或銀行的系統裡面,叫做進件,進件後銀行或貸款公司就會開始稽核這個貸款了。
-
特約商戶:金融術語,指銀行、其他金融機構和財務公司發行的信用卡作為一種支付手段在流通中被接受並願意為其提供服務的各種單位。簡而言之,指與銀行簽定受理卡業務協議並同意用銀行卡進行商務結算的商戶。
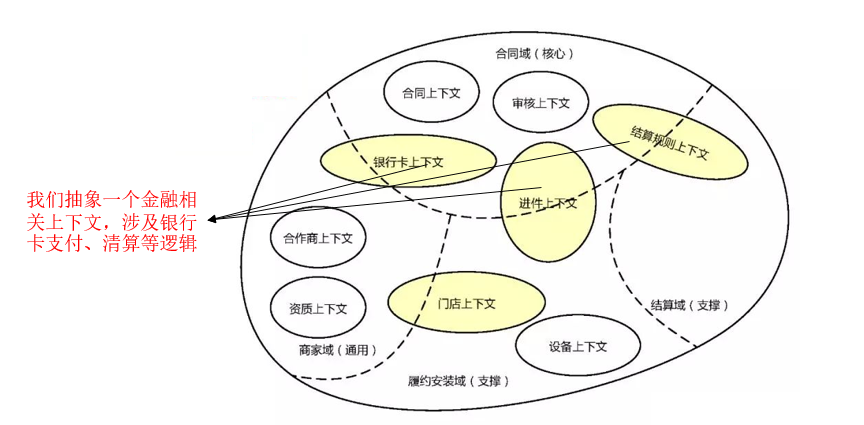
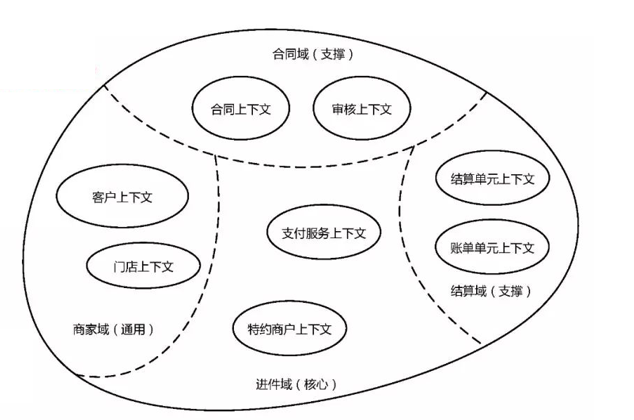
上圖的1.0版本,銀行卡、進件、結算規則都跨越了問題域,因此我們對其抽象“支付”“特約商戶”上下文,如下圖。
這裡有人會有疑問,“特約商戶”“商家”什麼關係,是否應該把“特約商戶”歸屬為“商家域”,這只是字面意思的相似,“特約商戶”是進件審批以後形成的支付相關的業務。當然“商家域”會使用到“特約商戶”的能力。
因為進件邏輯複雜因此我們以進件為中心來畫出了這樣的上下文。另一方面從狀態流轉來說,“銀行進件”是一個重要節點,代表平臺、商家的一些權益即將生效,因此以此為核心也是有必要的。
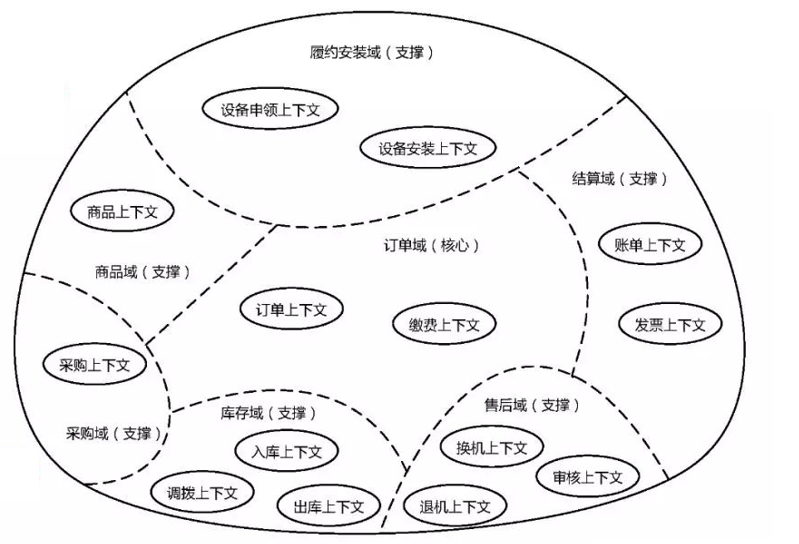
隨著店鋪外賣團購業務的發展,我們需要一個領域能力更豐富的履約安裝域,能夠進行社群配送、售後維修等。不可避免地將與訂單、fa票、庫存、售後等業務都有關係,因此以訂單為中心構建了下面的上下文。
六、結語
考慮到篇幅以及內容繁多,領域層相關的內容會在後面的文章中繼續講解。
本文主要講述了戰略層面的DDD原則,相對來說較為抽象,但這是最考驗內功、最不可忽視的環節。
再次強調一點,實踐DDD絕不是參照一套網上的程式碼結構,依葫蘆畫瓢去重寫自己的系統,這一定是失敗的。建議大家按照本文所講述的原則、方法去思考自己的系統,當你領悟其精髓以後一定能夠“笑傲程式碼”,掌握解決軟體核心複雜性的內功心法。

更多內容敬請關注 vivo 網際網路技術 微信公眾號

注:轉載文章請先與微訊號:labs2020 聯絡。