
高併發的概念及應對方法
為什麼學習高併發?
作為一名非CS科班出生的同學,在經過多年IT從業之後,明顯能感受到職業生涯發展的後繼無力,由於從事的是傳統金融行業,對應的公司其實內心深處是不重視IT部門的,而我這種IT從業人員雖然已經是團隊或者是部門非常重要的人員,但是最後再發展下去也就是一個業務專家,業務專家本質上的知識不是自身的知識體系,而是公司的知識體系,而只有技術知識體系才是自己的。於是早在18年我就開始了自己的轉型學習之路,前期學習了網路知識、Java併發程式設計,再要想學習JVM時,命運無情的枷鎖打斷了我的學習程序,19年就在沉悶和潛伏中度過,終於到了20年了,也即將邁入而立之年,給自己定個目標,今年上半年一定要轉型完成進入一家心儀的公司,在職業生涯的黃金時期認認真真的再CODE一下。先說一下轉型目標,希望能從事高併發、高效能相關的開發工作,為什麼會定這個目標?除了自己對這個領域感興趣外,確實也能從某些知名大型企業的社會招聘能看到這些領域的需求崗位是比較旺盛的,截圖如下:

什麼是高併發?
再談論什麼是高併發之前,我覺得非常有必要先搞清楚併發、並行和高併發這幾個概念,至少對於非CS科班出身的我,一直就不知道這幾個是什麼高深的內容。
併發、並行和高併發
網易公開課《清華大學公開課:7.3程序的特點》中是這麼定義的併發和並行,併發是指在一個時間段內有多個程序在執行,只不過在人的角度看,因為這個計算機角度的時間實在是太短暫了,人根本就感受不到是多個程序,看起來像是同時進行,這種是併發,而並行指的是在同一時刻有多個程序在同時執行。一個是時間段內發生的,一個是某一時刻發生的,如果是在只有一個CPU的情況下,是無法實現並行的,因為同一時刻只能有一個程序被排程執行,如果此時同時要執行其他程序則必須上下文切換,這種只能稱之為併發,而如果是多個CPU的情況下,就可以同時排程多個程序,這種就可以稱之為並行。從這裡我們可以總結出併發和並行的差異,首先粒度不一樣,併發針對的是時間段,並行針對的是時間點,其次行為也不一樣,併發的動作側重於處理行為,並行的動作側重於執行行為,只不過人的視角和機器的視角差異導致看起來都是同時執行的。
那麼什麼是高併發呢?其實高併發的意思和前面說的併發的意思不止是差了一個“高”字,而是個寬泛得多的概念。高併發是指可以讓軟體系統在一段時間內能夠處理大量的請求。比如每秒鐘可以完成10萬個請求。這是網際網路系統的一個重要的特徵。不像併發說的是“處理”,並行說的是“執行”,高併發說的是最終效果。只要能達到效果,不管怎麼實現都行。因此,極端一點高併發甚至並不一定需要並行,只要處理速度快的足夠滿足要求就可以。如啟動一個nginx的OS程序,它只能用到一個CPU核心,也就不可能並行。但是他如果能每秒能處理10萬個請求,而業務需求只要求8萬個請求就可以了,那麼這個單程序的nginx本身就算高併發了。通過這段話,我們能明白高併發是最終的結果,為了實現這個結果,技術上可能會用到非常多的技術方案,這些技術方案大量應用各種併發的集中人類智慧的各種方法,並儘可能的並行。除了併發和並行,高併發還需要:
- 資料表普遍被分庫分表,否則單機放不下,或者查詢效能不足
- 解決分散式事務
- 因為機器都可能壞,為了保證少數機器壞掉不會影響處理的效能,必須引入HA機制
- 因為系統都有極限,超過極限響應能力就會急劇下降。因此必須引入限流的方案來保護系統
- 這麼複雜的系統會涉及到N個service,N個儲存,N個佇列…… 這些資源的管理又成為了新的問題,這又需要對叢集和服務做管理
- 這麼多服務,肯定要解決分散式的Tracing和報警問題
- ……
到此我們可以知道,高併發其實是一個技術體系,甚至不同的情況下高併發的指標效果還不一樣,為了達到這個效果,我們會使用很多能併發處理的技術,為了能達到這個效果,我們會在應用系統的每一層做不同的處理,為了能達到這個效果,我們還可以根據語言的不同特性來選擇實現最終效果的程式語言。
如何應對高併發?
在這一節,我會概括性的總結我所學習的應對高併發的方式方法,之所以說是概括性,是因為高併發這個領域涉及的技術和知識點都不是可以速成的,也不是我這個傳統IT行業從業人員實踐所得,而是從網路、書本中獲取的其他人的經驗總結,後續我會從中選取高併發中的連線處理、RPC相關內容做一個較為深入的學習和總結,希望以此作為突破口,實現自己上半年的目標。
從一個完整的HTTP請求說起
高併發意味著單位時間內系統能處理的請求數很高,也就是說系統所能承載的HTTP請求很多,那要應對高併發,就要從HTTP請求處理層面開始,如下是我理解的一個完整的HTTP請求所經歷的流程:
1、DNS域名解析
將請求域名解析為IP地址。
2、與IP地址對應的伺服器網絡卡建立連線,TCP的三次握手,連線建立並佔用
3、伺服器作業系統通過連線讀取和處理請求
3.1 從連線中讀取位元組流(IO密集)
3.2 將讀取到的位元組流轉換成HTTP請求(CPU密集)
4、伺服器作業系統將HTTP請求轉發給WEB Server或者Application Server
4.1 Application在開發邏輯架構中一般會分層,分為表現層、業務層和持久層
5、Application進行業務邏輯處理並準備響應Response
6、Response準備完成,Response通過網絡卡回寫到使用者的瀏覽器(IO密集)
7、TCP連線三次揮手,斷開連線
從這個過程中,我們對一個HTTP的請求能有一個感性的認識,基於這個感性的認識,我們能知道這裡面幾個關鍵的點:域名解析、連線處理、系統分層,從這幾個關鍵點其實就可以提取出一些應對方法。
域名解析
域名解析這個環節有一個應對高併發的方法就是CDN,CDN 就是將靜態的資源分發到位於多個地理位置機房中的伺服器上,因此它能很好地解決資料就近訪問的問題,也就加快了靜態資源的訪問速度。搭建CDN主要有兩個關鍵點,一是如何將使用者的請求對映到 CDN 節點上,二是如何根據使用者的地理位置資訊選擇到比較近的節點。
將使用者的請求對映到 CDN 節點其實就是域名解析(DNS)的過程,DNS解析的過程大致如下:
首先檢視本機的host檔案,檢視是否有該域名對應的IP地址;
如果沒有就請求Local DNS是否有域名解析結果的快取,如果有就返回標識是否從非權威DNS返回的結果;
如果還是沒有就進入DNS迭代查詢的過程,先查詢根DNS的地址(如.com/.cn/.org), 再請求頂級DNS得到二級域名伺服器地址(如baidu.com);再從二級域名伺服器中查詢到 子域名對應的 IP 地址(如www.baidu.com),返回這個 IP 地址的同時標記這個結果是來自於權威 DNS 的結果,同時寫入 Local DNS 的解析結果快取,這樣下一次的解析同一個域名就不需要做 DNS 的迭代查詢了。
根據使用者的地理位置資訊選擇到比較近的節點則是GSLB的作用,GSLB(Global Server Load Balance,全域性負載均衡)的含義是對於部署在不同地域的伺服器之間做負載均衡,下面可能管理了很多的本地負載均衡元件。它有兩方面的作用:一方面,它是一種負載均衡伺服器,指的是讓流量平均分配使得下面管理的伺服器的負載更平均;另一方面,它還需要保證流量流經的伺服器與流量源頭在地緣上是比較接近的。
連線處理
這一節,我們關注網路連線處理IO層面的一些應對之策。
Tomcat如何應對
實際工作當中,Tomcat作為容器承擔著與使用者建立連線、解析請求、轉發請求、回寫響應的工作,Connector作為Tomcat兩個核心元件之一,主要任務是實際負責接收瀏覽器發來的連線請求,建立一個Request和Response物件分別用於和請求端交換資料,把產生的Request和Response物件傳給後續處理這個請求的工作執行緒。先給個結論,預設情況下Tomcat7.0應對大量連線的能力不如Tomcat8.5,為什麼呢?可以來看下Connector中關於protocol的設定:
7.0 protocol- The default value is HTTP/1.1 which uses an auto-switching mechanism to select either a blocking Java based connector or an APR/native based connector.
8.5 protocol- The default value is HTTP/1.1 which uses an auto-switching mechanism to select either a Java NIO based connector or an APR/native based connector.
APR/native全稱Apache Portable Runtime,由Apache基金會提供維護支援,非tomcat自帶的元件,需要獨立安裝,能應對大量的連線,但是如果在未安裝該元件的情況下,我們可以發現預設情況下7.0使用的是blocking Java而8.5使用的是Java NIO,由此是不是可以猜想是IO處理方式的不同決定了應對高併發的效果不一樣。
IO模型
在繼續探討連線處理層面的應對之策前,我們先來回顧一下Unix環境下的網路IO模型。
阻塞式IO模型(blocking I/O):
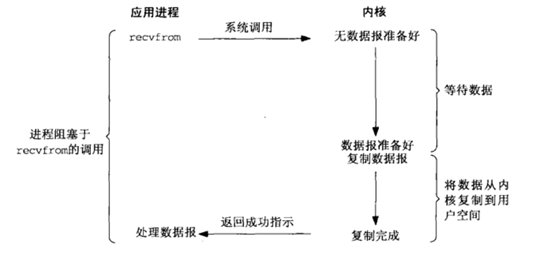
程序阻塞呼叫,一旦執行緒建立過多,執行緒的建立銷燬成本高,執行緒本身的記憶體佔用大,CPU不斷的進行執行緒的上下文切換。
非阻塞式IO模型(nonblocking I/O):
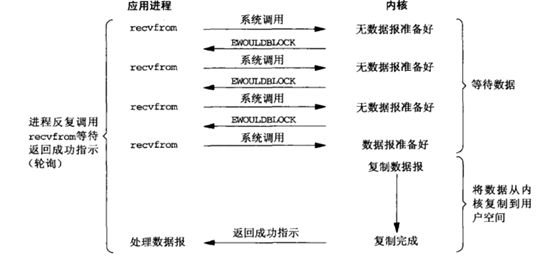
應用執行緒在IO資料準備階段,忙等待。
IO多路複用模型(I/O multiplexing):
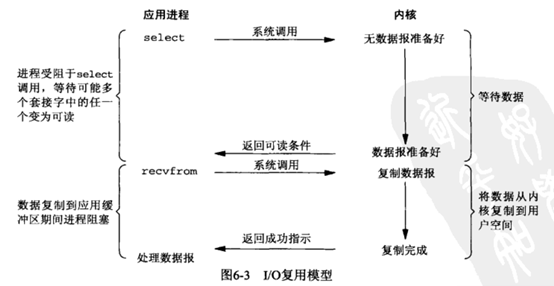
相對於同步阻塞IO模型,藉由作業系統提供的select/poll功能使用少量執行緒管理大量連線,使用者程序通過select/poll獲取當前實際ready的socket,然後在程序中阻塞的將核心態拷貝到使用者態。在Linux系統中,有更高效的epoll實現。實際使用中,socket常會被設定成以non-blocking方式訪問。
訊號驅動式IO模型(signal-driven IO):

非同步IO模型(asynchronous I/O):

IO模型區別總覽:

Java NIO
在瞭解完網路IO模型之後,我們再回來看下Tomcat中的Java NIO是如何體現這個IO模型的。
Java NIO中的三個核心概念:Channel、Selector和ByteBuffer。
Channel是可IO操作的硬體、檔案、socket、其他程式元件的包裝。
Selector是select/poll/epoll包裝。
ByteBuffer是資料容器,和Channel成對出現,資料只能從Channel中讀取和寫入。
JDK1.4引入的NIO,Selector使用Linux poll實現。
JDK6 & JDK 5 update 9支援epoll(Linux Kernel >= 2.6)。
JDK7 支援NIO2,引入非同步IO的四個通道:
AsynchronousSocketChannel
AsynchronousServerSocketChannel
AsynchronousFileChannel
AsynchronousDatagramChannel
值得注意的是,這四個通道執行在Linux中仍是通過epoll實現,並非真正意義的非同步IO。
至此我們可以知道我們工作中經常使用的Tomcat是如何在IO模型上應對高併發了。
再談Tomcat 執行緒模型
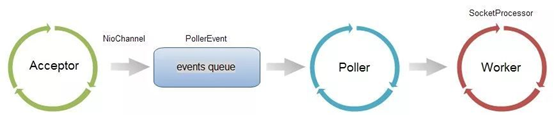
Acceptor負責接收Socket並將之封裝為NioChannel,通過NioChannel的register註冊到Poller中。
Poller實際是基於Java NIO Selector實現的,主要功能為獲取當前可讀取的NioChannel並將其分發給實際的Worker。
Worker是實際負責請求處理的執行緒池,將請求轉發給應用層處理。
一個新的問題
高併發帶來的請求流量都很大,巨大的流量衝擊到Tomcat後,如果Worker處理不過來,系統會發生什麼呢?
三個重要的tomcat connector引數:acceptCount,maxConnections,maxThreads
若沒有空閒的Worker(即到達了maxThreads),新來的請求不得不接受長時間的等待,一直等到有新的Worker為止。
更多的請求到達,Acceptor發現建立的NioChannel抵達maxConnections時,阻塞。
更多的請求到達,OS層面的連線仍會繼續進行,抵達acceptCount時,OS拒絕連線,Client端顯示Connection refused。
這個時候一個新的應對方式也就產生了-非同步化。
基於Servlet API的非同步方式
在servlet3.0引入了基於servlet API實現的非同步處理方案,流程圖如下:

Tomcat的工作執行緒(Worker)在支援非同步的Servlet中通過呼叫如下命令開啟非同步處理:
AsyncContext ServletRequest.startAsync(Request request,Response response)
Tomcat的工作執行緒會將當前的request,response物件的引用放入AsyncContext中,並將AsyncContext交付給一個新的執行緒處理,保持response的開啟狀態,然後立即返回Tomcat工作執行緒池等待處理其他的請求。
新的執行緒應該是什麼?
新的執行緒是業務執行緒池產生的,並且不是一個執行緒池,而是根據業務設計的多級執行緒池組。例如區分核心業務和非核心業務執行緒池。通過執行緒池的隔離,保證非核心業務的抖動不會影響到核心業務,另一個好處就是保留對業務執行緒池的監控、運維、降級等。新的執行緒主要做業務處理,通過response回寫響應並且關閉response。
AsyncContext.complete()
Spring 3.2開始支援Servlet 3.0,通過非同步化,我們將解析和業務處理徹底剝離,同時業務處理間區分不同的執行緒池保證隔離性。
非同步處理不會降低響應的時間,但是會提高吞吐量,從而應對高併發。
Reactive Stack
一個相對於servlet-stack獨立的全新的技術棧reactive stack:Spring-WebFlux。

從圖中可以看出這個全新的stack是基於Reactive Streams。
最後總結一下,連線處理層面應對高併發的思路就是:
阻塞變非阻塞,同步變非同步,核心就是充分利用單機效能,壓榨CPU。
系統分層
這一節,我們將從系統分層這個層面來看每一層可以採用的應對之策。
業務層
本節主要關注在業務層,面對高併發場景下對於業務邏輯實現相關的處理方案。
快取
快取是一種儲存資料的元件,它的作用就是讓對資料的請求能更快的返回。高併發的場景下,如果能快速的返回請求所需要的資料,對於系統持久層是一種相當好的保護措施,對於系統來說也能提升吞吐量。常見的快取技術有靜態快取、分散式快取和熱點本地快取。
靜態快取在 Web 1.0 時期是非常著名的,它一般通過生成 Velocity 模板或者靜態 HTML 檔案來實現靜態快取,在 Nginx 上部署靜態快取可以減少對於後臺應用伺服器的壓力。這種快取只能針對靜態資料來快取,對於動態請求就無能為力了。那麼我們如何針對動態請求做快取呢?這時你就需要分散式快取了。
分散式快取效能強勁,通過一些分散式的方案組成叢集可以突破單機的限制。所以在整體架構中,分散式快取承擔著非常重要的角色。
對於靜態的資源的快取可以選擇靜態快取,對於動態的請求可以選擇分散式快取,那麼什麼時候要考慮熱點本地快取呢?答案是當我們遇到極端的熱點資料查詢的時候。熱點本地快取主要部署在應用伺服器的程式碼中,用於阻擋熱點查詢對於分散式快取節點或者資料庫的壓力。
訊息佇列
系統的初級階段基本上是讀多寫少,所以在應對高併發時業務層會先加入快取元件,希望通過快取阻擋大量的讀請求。隨著系統的不斷髮展,高併發系統開始湧入大量的寫請求,此時會使用到訊息佇列來應對高併發的場景。
非同步解耦和削峰填谷是訊息佇列的主要作用,其中非同步處理可以簡化業務流程中的步驟,提升系統性能;削峰填谷可以削去到達秒殺系統的峰值流量,讓業務邏輯的處理更加緩和;解耦可以將系統和其他系統解耦開,這樣一個系統的任何變更都不會影響到另一個系統。
業務拆分
正常情況下,初期為了系統能儘快上線,都會是以單體架構的形式出現,而隨著流量和請求的增多,單體架構開始出現一些問題:
資料庫連線數可能會成為系統的瓶頸;
內部成員的溝通成本問題;
程式碼提交,分支管理,專案編譯等問題;
模組相互依賴,強耦合,一旦出問題容易牽一髮而動全身;
………
這個時候,為了系統能達到支撐高併發的效果,便會對系統做業務拆分,以應對上述眾多問題,拿我們保險系統來說,最早期的保險核心系統,其實契約、保全、財務、理賠甚至是各種報表都是集中在一個系統中,雖然保險是一個低頻行為,不太具有高併發的特性,但是在系統發展的過程中,也會有類似的拆分,將契約、保全、財務、理賠等從一個系統拆分成多個系統,而高併發系統則是使用了更細粒度的拆分,以提供服務的形式來應對高併發,在流量高峰期可以動態擴容,平穩流量,避免系統崩潰。
RPC
服務拆分之後,原本的單體系統就會變成分散式系統,原來在同一個程序裡面兩個方法呼叫就會變成跨程序跨網路的兩個方法呼叫,此時就會引入RPC框架來解決跨網路通訊問題。RPC框架封裝了網路呼叫的細節,可以實現像呼叫本地服務一樣呼叫遠端部署的服務。
一個完整的RPC的步驟如下:
在一次 RPC 呼叫過程中,客戶端首先會將呼叫的類名、方法名、引數名、引數值等資訊,序列化成二進位制流;
然後客戶端將二進位制流通過網路傳送給服務端;
服務端接收到二進位制流之後將它反序列化,得到需要呼叫的類名、方法名、引數名和引數值,再通過動態代理的方式呼叫對應的方法得到返回值;
服務端將返回值序列化,再通過網路傳送給客戶端;
客戶端對結果反序列化之後,就可以得到呼叫的結果了。
從這個過程中,我們可以提取出RPC的核心過程就是網路傳輸和序列化。其中網路傳輸可以選擇Netty,而序列化則可以選擇Thrift或者Protobuf。
RPC能夠解決服務之間跨網路通訊的問題,但是對於RPC來說,又是如何知道自己該呼叫誰或者誰會呼叫自己呢?這個時候就會引入註冊中心來解決這個問題,比如ZooKeeper、ETCD、Eureka等。
API閘道器
API 閘道器(API Gateway)不是一個開源元件,而是一種架構模式,它是將一些服務共有的功能整合在一起,獨立部署為單獨的一層,用來解決一些服務治理的問題。你可以把它看作系統的邊界,它可以對出入系統的流量做統一的管控。對於高併發系統,API閘道器的搭建是非常有必要的,因為它可以實現如下作用:
1、提供客戶端一個統一的接入地址,API 閘道器可以將使用者的請求動態路由到不同的業務服務上,並且做一些必要的協議轉換工作。在系統中,微服務對外暴露的協議可能不同:有些提供的是 HTTP 服務;有些已經完成 RPC 改造,對外暴露 RPC 服務;有些遺留系統可能還暴露的是 Web Service 服務。API 閘道器可以對客戶端遮蔽這些服務的部署地址以及協議的細節,給客戶端的呼叫帶來很大的便捷。
2、在 API 閘道器中,可以植入一些服務治理的策略,比如服務的熔斷、降級、流量控制和分流等等。
3、客戶端的認證和授權的實現,也可以放在 API 閘道器中。不同型別的客戶端使用的認證方式是不同的。手機 APP 可以使用 Oauth 協議認證,HTML5 端和 Web 端使用 Cookie 認證,內部服務使用自研的 Token 認證方式。這些認證方式在 API 閘道器上可以得到統一處理,應用服務不需要了解認證的細節。
4、API 閘道器還可以做一些與黑白名單相關的事情,比如針對裝置 ID、使用者 IP、使用者 ID 等維度的黑白名單。
5、在 API 閘道器中也可以做一些日誌記錄的事情,比如記錄 HTTP 請求的訪問日誌。
持久層
本節主要關注在高併發場景下,資料持久化層所需要關注的內容。
讀寫分離
持久層最先可能會用到的應對高併發的方法就是讀寫分離。對於高併發系統來說,一開始都是讀多寫少,大量的讀請求經過業務層到達持久層之後對資料庫產生了極大的壓力,此時就會準備一個和生產庫一致的資料庫來單獨接收處理讀請求,一般這個叫做從庫,也會被稱為讀庫,高併發流量中的讀請求會被引流到從庫,而寫請求還是在主庫寫,主庫和從庫之間依靠主從複製機制來確保兩個庫的資料近乎實時一致,這樣使用者在讀請求的時候幾乎發現不了資料的不一致。
分庫分表
讀寫分離主要是為了應對讀請求,那如果寫請求的流量大,此時又會有什麼應對的方案呢?常見的一種處理方法就是分庫分表。
分庫分表是一種常見的將資料分片的方式,它的基本思想是依照某一種策略將資料儘量平均地分配到多個數據庫節點或者多個表中。不同於主從複製時資料是全量地被拷貝到多個節點,分庫分表後,每個節點只儲存部分的資料,這樣可以有效地減少單個數據庫節點和單個數據表中儲存的資料量,在解決了資料儲存瓶頸的同時也能有效地提升資料查詢的效能。同時,因為資料被分配到多個數據庫節點上,那麼資料的寫入請求也從請求單一主庫變成了請求多個數據分片節點,在一定程度上也會提升併發寫入的效能。
資料庫分庫分表的方式有兩種:一種是垂直拆分,另一種是水平拆分。垂直拆分的原則一般是按照業務型別來拆分,核心思想是專庫專用,將業務耦合度比較高的表拆分到單獨的庫中。比如前面業務拆分時提到的將保險核心拆成契約、保全、財務和理賠等各大核心繫統,這就是一種垂直拆分。和垂直拆分的關注點不同,垂直拆分的關注點在於業務相關性,而水平拆分指的是將單一資料表按照某一種規則拆分到多個數據庫和多個數據表中,關注點在資料的特點。拆分的規則有下面這兩種:
- 按照某一個欄位的雜湊值做拆分,這種拆分規則比較適用於實體表,比如說使用者表,內容表,我們一般按照這些實體表的 ID 欄位來拆分。
- 另一種比較常用的是按照某一個欄位的區間來拆分,比較常用的是時間欄位。你知道在內容表裡面有“建立時間”的欄位,而我們也是按照時間來檢視一個人釋出的內容。我們可能會要看昨天的內容,也可能會看一個月前釋出的內容,這時就可以按照建立時間的區間來分庫分表,比如說可以把一個月的資料放入一張表中,這樣在查詢時就可以根據建立時間先定位資料儲存在哪個表裡面,再按照查詢條件來查詢。
NoSQL
讀寫分離和分庫分表是改善資料庫持久層應對併發能力的利器,但是在高併發的持續不斷的積累下,傳統關係型資料庫已經很難應對資料量上的瓶頸,此時便可以利用NoSQL來幫助解決這些問題,因為它有著天生分散式的能力,能夠提供優秀的讀寫效能,可以很好地補充傳統關係型資料庫的短板。
本文從巨集觀上描述了高併發的概念及相關的應對方法,或概括性、或略微詳細的描述了自己的理解,後續我會選擇裡面我感興趣的NIO、RPC等連線處理和服務相關的領域做較為深入的學習和總結。
參考資料:
https://www.zhihu.com/question/307100151?utm_source=wechat_timeline
http://tomcat.apache.org/tomcat-7.0-doc/config/http.html
http://tomcat.apache.org/tomcat-8.5-doc/config/http.html
https://docs.spring.io/spring-framework/docs/5.0.0.BUILD-SNAPSHOT/spring-framework-reference/html/web-reactive.html
極客時間《高併發系統40問》
《UNIX Network Programming.Volume 1.Third Edition.The Sockets Networking API》
&n