
利用動態資源分配優化Spark應用資源利用率
背景
在某地市開展專案的時候,發現數據採集,資料探索,預處理,資料統計,訓練預測都需要很多資源,現場資源不夠用。
目前該專案的資源3臺舊的伺服器,每臺的資源 記憶體為128G,cores 為24 (core可暫時忽略,以下僅考慮記憶體即可) 。
案例分析
我們先對任務分別分析,然後分類。
資料採集基於DC,接的是Kafka的源,屬於流式,常駐任務。kafka來新資料時才需要資源,空閒時可釋放。目前佔用的資源情況為:28( topic數)*2(執行緒數)*1G = 56G,且該值會隨著帶採集增量表數量的增加而增加。
資料探索主要是演算法人員使用命令列或是使用智慧融合平臺的相關功能進行資料探索,屬於臨時任務,但會同時有多個併發,且使用的資源跟具體的要處理的資料量和業務有關,一般演算法人員會將此值設定得很大。目前平臺有兩個Thrift server服務,都佔用17G記憶體,共計34G。
預處理單個需要的資源為 4G*4+4G=20G,可併發執行,耗用的資源等於13G*併發數。
資料統計需要的資源為 5G*2+3G=13G,一般十分鐘左右。
演算法訓練需要的資源為12G*3=36G,此為預設值,現場一般都會調得比較高。
演算法預測需要的資源相對較少,此處先忽略。
可以看到任務大體分為以下幾類:
- 常駐任務。此類任務一般在空閒時不需要資源,這是典型的動態資源使用場景。如:流式採集、Thrift Server、演算法訓練平臺的預提交任務等。
- 臨時任務。此類任務又分為兩種:
- 單一任務,且與資料量基本固定。此時需要的資源可以固化下來。另外對優先順序極高的應用也可歸為此類。
- 單一任務,但與資料量相關。如每次面對的資料量不同,典型的應用是統計任務,資料量在不斷增多,且每天的增量不固定,此時可以使用動態資源
- 多個任務。此類任務一般是面臨的場景完全未知,比如說預處理任務、訓練任務。我們不清楚任務的內部詳情,完全無法準確預估資源,只能設定最大值或是每次提交任務都單獨設定。這其實要求使用者有任務調優經驗,對使用者的要求較高。
定時任務。此類任務與臨時任務類似,只是加上了簡單排程功能。如資料統計。
通過分析可以知道,很多Spark應用都是需要動態資源分配的,很多使用者通過UI經常觸發的任務也可使用動態資源規劃在不損失更多資源的情況下變成常駐任務來提高響應速度。
動態資源分配機制
Spark提供了基於應用工作負載來動態分配資源的機制,這意味著應用可以根據需要想資源管理器(比如說YARN)釋放資源和再請求資源。如果多個應用共享資源的話,這個特性是非常有用的。
需要首先說明的是,這套機制的基本單元是Executor,類似於其它產品中的Slot,這裡的單個Executor的資源可通過 spark.executor.memory 和 spark.executor.cores分配配置其佔用的記憶體及核數。
由於無法確切地知道什麼時候需要請求Executor和移除Executor,Spark制定了一套請求和移除的機制。
請求機制。如果檢視佇列中有掛起的任務,且掛起的時間超過
spark.dynamicAllocation.schedulerBacklogTimeout秒,則請求Executor,按輪次請求,每輪按指數增加,如:1, 2, 4, 8 ……移除機制。如果一個Executor空閒時間超過
spark.dynamicAllocation.executorIdleTimeout秒,則移除。需要注意的是,在大多數場景下,這個與請求機制是互斥的,也就是說,如果還有掛起的任務,那就不應該釋放資源。滿足移除機制,還有兩個細節需要處理才能移除Executor。
- 給其他Executor提供shuffle資料服務。Spark系統在執行含shuffle過程的應用時,Executor程序除了執行task,還要負責寫shuffle資料,給其他Executor提供shuffle資料。當Executor程序任務過重,導致GC而不能為其他Executor提供shuffle資料時,會影響任務執行。External shuffle Service是長期存在於NodeManager程序中的一個輔助服務。通過該服務來抓取shuffle資料,減少了Executor的壓力,在Executor GC的時候也不會影響其他Executor的任務執行。我們可以在Executor完成後就移除它,由External shuffle Service給其他Executor繼續提供shuffle資料服務。
快取資料。寫shuffle檔案的時候,Executor也會快取資料到磁碟或記憶體中,一旦Executor移除,這部分資料也會不可訪問,因此只要有快取資料,Executor就不會被移除。設定
spark.dynamicAllocation.cachedExecutorIdleTimeout可在即使有快取資料的情況下也能在超時的時候移除Executor,該值預設為無線大。後續這個可能會被優化,類似於使用External shuffle Service。
動態資源分配配置
配置External shuffle Service
- 修改hadoop-env.sh ,將spark-2.1.0-yarn-shuffle.jar新增到classpath
HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/usr/lib/LOCALCLUSTER/spark/yarn/spark-2.1.0-yarn-shuffle.jar
其中/usr/lib/LOCALCLUSTER/spark/為Spark home目錄 - 修改yarn-site.xml:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle**,spark_shuffle**</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>- 修改
yarn-env.sh中的YARN_HEAPSIZE變數,預設值為1000(Mb)。提升這個變數的值可以避免shuffle時的GC問題。 - 重啟所有節點的nodemanager服務
- 重啟相關需要動態資源分配的服務
配置Spark程式
此處僅列出最常用的引數,具體見附錄一
| 屬性 | 預設值 | 說明 |
|---|---|---|
| spark.executor.memory | 1G | 單個executor的記憶體,推薦1G,由於動態資源分配是基於Executor的,單個Executor的記憶體不宜過大。 |
| spark.yarn.executor.memoryOverhead或spark.executor.memoryOverhead | executorMemory * 0.10, with minimum of 384 | 分配給單個executor的堆外記憶體 ,一個Executor可用的記憶體為 spark.executor.memory + spark.executor.memoryOverhead |
| spark.executor.cores | 1 | 單個executor可用核數,與可並行執行的任務數相關,多個任務共享spark.executor.memory,增大可提供並行度,也會加大OOM的風險 |
| spark.dynamicAllocation.enabled | false | 啟用動態資源分配,必須設定為true |
| spark.shuffle.service.enabled | false | 啟用外部shuffle服務,必須設定為true |
| spark.dynamicAllocation.minExecutors | 0 | 最小可用cores,建議設定成1 |
| spark.dynamicAllocation.maxExecutors | infinity | 最大可用cores,必須設定 |
一個實際的應用如下:
/usr/lib/LOCALCLUSTER/SERVICE-SPARK-retro/sbin/start-thriftserver.sh \
--name "Awaken Insight Thrift Server" \
--master yarn-client --queue applications-retro \
--conf spark.driver.memory=10g
--conf spark.yarn.executor.memoryOverhead=2048
--conf spark.eventLog.enabled=false \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.minExecutors=1 \
--conf spark.dynamicAllocation.maxExecutors=12 \
--conf spark.executor.memory=1g \
--conf spark.executor.cores=1可在spark-default.conf 下配置類似引數,可對所有應用生效 。(不推薦)
更好地使用動態資源分配
由於動態資源分配思想其實是建議將單個Executor的資源設定一個比較小的值,如1G。而實際上此值一般設定得比較大,主要是為了防止OOM。那為了更好地使用動態資源分配,必須解決此問題。
Executor OOM類錯誤 (錯誤程式碼 137、143等)一般是由於堆記憶體 已達上限,Task需要更多的記憶體,而又得不到足夠的記憶體而導致。因此,解決方案要從增加每個Task的記憶體使用量,滿足任務需求 或 降低單個Task的記憶體消耗量,從而使現有記憶體可以滿足任務執行需求兩個角度出發。因此:
- 增加單個task的記憶體使用量
- 增加
spark.executor.memory,使每個Task可使用記憶體增加。 - 降低Executor的可用Core的數量
spark.executor.cores, 使Executor中同時執行的任務數減少,在總資源不變的情況下,使每個Task獲得的記憶體相對增加。
- 降低單個Task的記憶體消耗量
降低單個Task的記憶體消耗量可從配製方式和調整應用邏輯兩個層面進行優化:
配置方式
減少每個Task處理的資料量,可降低Task的記憶體開銷,在Spark中,每個partition對應一個處理任務Task, 因此,在資料總量一定的前提下,可以通過增加partition數量的方式來減少每個Task處理的資料量,從而降低Task的記憶體開銷。針對不同的Spark應用型別,存在不同的partition調整引數如下:- P = spark.default.parallism (非SQL應用) 有父RDD的,以他們的partition數為主,沒有的(如parallelize)取決於所有numExcutors*executorCore,最小為2.
- P = spark.sql.shuffle.partition (SQL 應用) 預設值200
通過增加P的值,可在一定程度上使Task現有記憶體滿足任務執行
注: 當調整一個引數不能解決問題時,上述方案應進行協同調整
- P = spark.default.parallism (非SQL應用) 有父RDD的,以他們的partition數為主,沒有的(如parallelize)取決於所有numExcutors*executorCore,最小為2.
調整應用邏輯
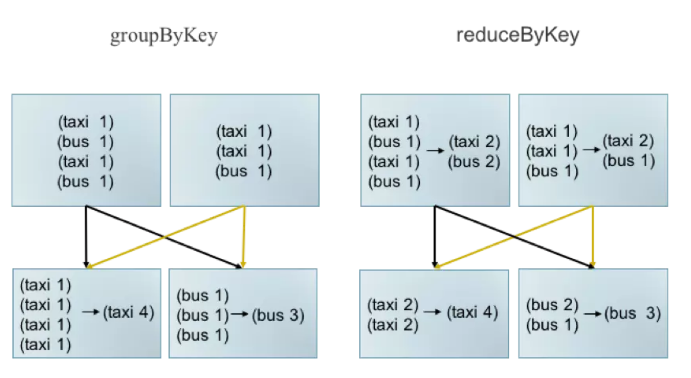
Executor OOM 一般發生Shuffle階段,該階段需求計算記憶體較大,且應用邏輯對記憶體需求有較大影響,下面舉例就行說明:- 選擇合適的運算元。 如:groupByKey 轉換為 reduceByKey
一般情況下,groupByKey能實現的功能使用reduceByKey均可實現,而ReduceByKey存在Map端的合併,可以有效減少傳輸頻寬佔用及Reduce端記憶體消耗。
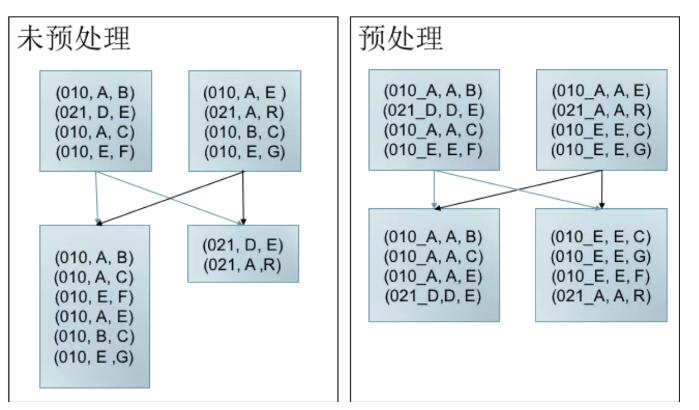
資料傾斜預處理
資料傾斜是指任務間處理的資料量存大較大的差異。
如左圖所示,key 為010的資料較多,當發生shuffle時,010所在分割槽存在大量資料,不僅拖慢Job執行(Job的執行時間由最後完成的任務決定)。 而且導致010對應Task記憶體消耗過多,可能導致OOM. 而右圖,經過預處理(加鹽,此處僅為舉例說明問題,解決方法不限於此)可以有效減少資料傾斜導致 的問題
- 選擇合適的運算元。 如:groupByKey 轉換為 reduceByKey
注:上述舉例僅為說明調整應用邏輯可以在一定程式上解決OOM問題,解決方法不限於上述舉例
動態資源分配效果
本文主要針對 1051847284 條過車記錄(約10億)進行如下操作,分別記錄時間。
| 型別 | SQL |
|---|---|
| count | select count(1) from sparta_pass_di |
| 全域性排序 | select * from sparta_pass_di order by passTime desc limit 10 |
| 聚合排序 | select plateNo, count(1) as cnt from sparta_pass_di group by plateNo order by cnt desc limit 10; |
| 過濾查詢 | select * from sparta_pass_di where plateNo = '粵GU54MX' limit 10; |
Thrift server V.S. spark sql
以融合平臺的Thrift Server為例,先簡單對比Thrift server與spark sql之間的效能差異,如下圖結果可知,總資源一致的情況下基本沒有太大差異:
| sql/命令/時間 | spark-sql --master yarn-client --driver-memory 10G --driver-cores 1 --executor-memory 6G --executor-cores 1 --num-executors 2 --conf spark.sql.shuffle.partition=500 | start-thriftserver.sh --master yarn-client --driver-memory 10G --num-executors 2 --conf spark.driver.memory=10g --executor-memory 6g --conf spark.sql.shuffle.partition=500 |
|---|---|---|
| select count(1) from sparta_pass_di | 6 s | 7 s |
| select * from sparta_pass_di order by passTime desc limit 10 | 21 min | 20 min |
| select plateNo, count(1) as cnt from sparta_pass_di group by plateNo order by cnt desc limit 10; | 2.0 min | 1.4 min |
| select * from sparta_pass_di where plateNo = '粵GU54MX' limit 10; | 0.4 s | 0.3 s |
靜態資源分配 V.S. 動態資源分配
在上述前提下,對比靜態資源分配和動態資源分配之間的差異,可以看到在明顯耗時的全域性排序耗時明顯更短,其餘效能差距不大,但是空閒資源會被釋放。
| sql/命令/時間 | spark-sql --driver-memory 10G --driver-cores 1 --executor-memory 1G --executor-cores 1 --num-executors 12 --conf spark.sql.shuffle.partition=500 | start-thriftserver.sh --driver-memory 10G --driver-cores 1 --conf spark.dynamicAllocation.enabled=true --conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=12 --conf spark.executor.memory=1g --conf spark.executor.cores=1 --conf spark.sql.shuffle.partition=500 |
|---|---|---|
| select count(1) from sparta_pass_di | 8 s | 10 s |
| select * from sparta_pass_di order by passTime desc limit 10 | 11 min | 4.1 min |
| select plateNo, count(1) as cnt from sparta_pass_di group by plateNo order by cnt desc limit 10; | 57 s | 51 s |
| select * from sparta_pass_di where plateNo = '粵GU54MX' limit 10; | 0.5 s | 0.5 s |
shuffle.partition 多 V.S. 少
spark.sql.shuffle.partition的預設值為200,增加spark.sql.shuffle.partition到500,沒有看到明顯的效能提升
| sql/命令/時間 | spark-sql --master yarn-client --driver-memory 10G --driver-cores 1 --executor-memory 6G --executor-cores 1 --num-executors 2 \ | spark-sql --master yarn-client --driver-memory 10G --driver-cores 1 --executor-memory 6G --executor-cores 1 --num-executors 2 --conf spark.sql.shuffle.partition=500 |
|---|---|---|
| select count(1) from sparta_pass_di | 9 s | 6 s |
| select * from sparta_pass_di order by passTime desc limit 10 | 23 min | 21 min |
| select plateNo, count(1) as cnt from sparta_pass_di group by plateNo order by cnt desc limit 10; | 1.6 min | 2.0 min |
| select * from sparta_pass_di where plateNo = '粵GU54MX' limit 10; | 0.3 s | 0.4 s |
階段性總結一下,動態資源分配在簡單任務效能與靜態資源分配差不多,在複雜任務中效能提升較多,可能是由於常駐的外部shuffle服務帶來的效能提升,需要進一步測試驗證。而由於實際應用中executor記憶體都分配得較大,總資源一定的情況下,使得任務的並行度較小,任務執行更慢(21 min V.S. 4.1 min)。通過增加spark.sql.shuffle.partition來提升任務並行度,沒有看到明顯的效能提升。
可能約束
- 流式採集使用DC,是否可用動態分配。當前DC並未使用Spark,動態資源分配可能需要額外的開發。
- 演算法引擎的資源管控可能會失效。由於資源未知,只設定了範圍([最小值,最大值]),那資源管控到底以哪一個為主?
總結
本案例針對現場出現的資源不足問題做了分析,對任務進行了分類,然後引入動態分配機制,對融合平臺的Thrift Server做了幾組測試,可以看到動態資源分配優勢較大,建議推廣。
參考文獻
- https://spark.apache.org/docs/latest/job-scheduling.html
- https://spark.apache.org/docs/latest/running-on-yarn.html#configuring-the-external-shuffle-service
- https://dzone.com/articles/spark-dynamic-allocation
- https://www.jianshu.com/p/10e91ace3378
附錄一、動態資源分配引數說明
Dynamic Allocation (https://spark.apache.org/docs/latest/configuration.html#dynamic-allocation)
| Property Name | Default | Meaning |
|---|---|---|
spark.dynamicAllocation.enabled |
false | Whether to use dynamic resource allocation, which scales the number of executors registered with this application up and down based on the workload. For more detail, see the description here. This requires spark.shuffle.service.enabled to be set. The following configurations are also relevant: spark.dynamicAllocation.minExecutors, spark.dynamicAllocation.maxExecutors, and spark.dynamicAllocation.initialExecutors spark.dynamicAllocation.executorAllocationRatio |
spark.dynamicAllocation.executorIdleTimeout |
60s | If dynamic allocation is enabled and an executor has been idle for more than this duration, the executor will be removed. For more detail, see this description. |
spark.dynamicAllocation.cachedExecutorIdleTimeout |
infinity | If dynamic allocation is enabled and an executor which has cached data blocks has been idle for more than this duration, the executor will be removed. For more details, see this description. |
spark.dynamicAllocation.initialExecutors |
spark.dynamicAllocation.minExecutors |
Initial number of executors to run if dynamic allocation is enabled. If --num-executors (or spark.executor.instances) is set and larger than this value, it will be used as the initial number of executors. |
spark.dynamicAllocation.maxExecutors |
infinity | Upper bound for the number of executors if dynamic allocation is enabled. |
spark.dynamicAllocation.minExecutors |
0 | Lower bound for the number of executors if dynamic allocation is enabled. |
spark.dynamicAllocation.executorAllocationRatio |
1 | By default, the dynamic allocation will request enough executors to maximize the parallelism according to the number of tasks to process. While this minimizes the latency of the job, with small tasks this setting can waste a lot of resources due to executor allocation overhead, as some executor might not even do any work. This setting allows to set a ratio that will be used to reduce the number of executors w.r.t. full parallelism. Defaults to 1.0 to give maximum parallelism. 0.5 will divide the target number of executors by 2 The target number of executors computed by the dynamicAllocation can still be overridden by the spark.dynamicAllocation.minExecutors and spark.dynamicAllocation.maxExecutors settings |
spark.dynamicAllocation.schedulerBacklogTimeout |
1s | If dynamic allocation is enabled and there have been pending tasks backlogged for more than this duration, new executors will be requested. For more detail, see this description. |
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout |
schedulerBacklogTimeout |
Same as spark.dynamicAllocation.schedulerBacklogTimeout, but used only for subsequent executor requests. For more detail, see this description. |
本文由部落格一文多發平臺 OpenWrite 釋出!