
高效能記憶體佇列Disruptor--原理分析
阿新 • • 發佈:2020-03-07
## 1、起源
Disruptor最初由lmax.com開發,2010年在Qcon公開發表,並於2011年開源,其官網定義為:“High Performance Inter-Thread Messaging Library”,即:執行緒間的高效能訊息框架。其實JDK已經為我們提供了很多開箱即用的執行緒間通訊的訊息佇列,如:ArrayBlockingQueue、LinkedBlockingQueue、ConcurrentLinkedQueue等,這些都是基於無鎖的CAS設計。
那麼Disruptor為什麼還有存在的意義呢?其實無鎖並不代表沒有競爭,所以當高併發寫或者讀的時候,這些工具類一樣會面臨資源爭用的極限效能問題。而lmax.com作為一家頂級外匯交易商,其交易系統需要處理的併發量非常巨大,對響應延遲也非常敏感。在這種背景下,Disruptor誕生了,它的核心思想就是:把多執行緒併發寫的執行緒安全問題轉化為執行緒本地寫,即:不需要做同步。同時,lmax公司基於Disruptor構建的交易系統也多次斬獲金融界大獎。
## 2、發展
#### 框架很輕量
Disruptor非常輕量,整個框架最新版3.4.2也才`70`多個類,但效能卻非常強悍。得益於其優秀的設計,和對計算機底層原理的運用,官網說的:mechanical sympathy,我翻譯成`硬體偏向`或者`面向硬體程式設計`。同時它跟我們常見的MQ不一樣,這裡說的執行緒間其實就是同一個程序內,不同執行緒間的訊息傳遞,跟JDK中的那些阻塞和併發佇列的用法是一樣的,也就是說它們不會誇程序。
#### 效能很厲害
* 比JDK的ArrayBlockingQueue效能高近一個數量級
* 單執行緒每秒能處理超 `600W` 的資料(處理600W並非是消費者消費完600W的資料,而是說Disruptor能在1秒內將600W資料傳送給消費者,換句話說,不是600W的TPS,而是每秒600W的派發。再有,其實600W是Disruptor剛釋出時硬體的水平了,現在在個人PC上也能輕鬆突破2000W)(為什麼這裡要強調單執行緒呢??為什麼單執行緒的效能反而會更高呢??)
* 基於`事件驅動`模型,不用消費者主動拉取訊息
#### 應用很廣泛
Apache Storm、Apache Camel、Log4j2(見:org.apache.logging.log4j.core.async. AsyncLoggerDisruptor)等都在用。(怎麼最快在你的專案裡用上Disruptor呢?日誌框架換成Log4j2,然後開啟非同步就可以了)
## 3、核心類
主要核心類只有這6個:

簡單使用方法可以參考: [https://github.com/hiccup234/web-advanced/blob/master/disruptor-client/src/main/java/top/hiccup/disruptor/SampleTest.java](https://github.com/hiccup234/web-advanced/blob/master/disruptor-client/src/main/java/top/hiccup/disruptor/SampleTest.java)
## 4、有多快?
JDK自帶的佇列都是優秀程式設計師的智慧結晶,效能也是非常的強悍,下圖是其特點對比和總結:

同時Disruptor在這樣強悍的基礎上把效能提升了近一個數量級,這是非常了不起的(-- 就像要把我的存款增長10倍相對容易,但要讓東哥的身價再漲一番就難了)通過上圖我們可以看到,無鎖的方式一般都是無界的(無法保證佇列的長度在確定的範圍內),加鎖的方式,可以實現有界佇列。
但是,在穩定性要求特別高的系統中,為了防止生產者速度過快,導致記憶體溢位,只能選擇有界佇列。所以我們綜合一下,JDK的一眾佇列中,跟Disruptor最匹配的就是`ArrayBlockingQueue`了。
#### 沒有對比就沒有傷害
這是我本機測試的幾個佇列的效能對比,測試程式見:[https://github.com/hiccup234/web-advanced/tree/master/disruptor-client](https://github.com/hiccup234/web-advanced/tree/master/disruptor-client)
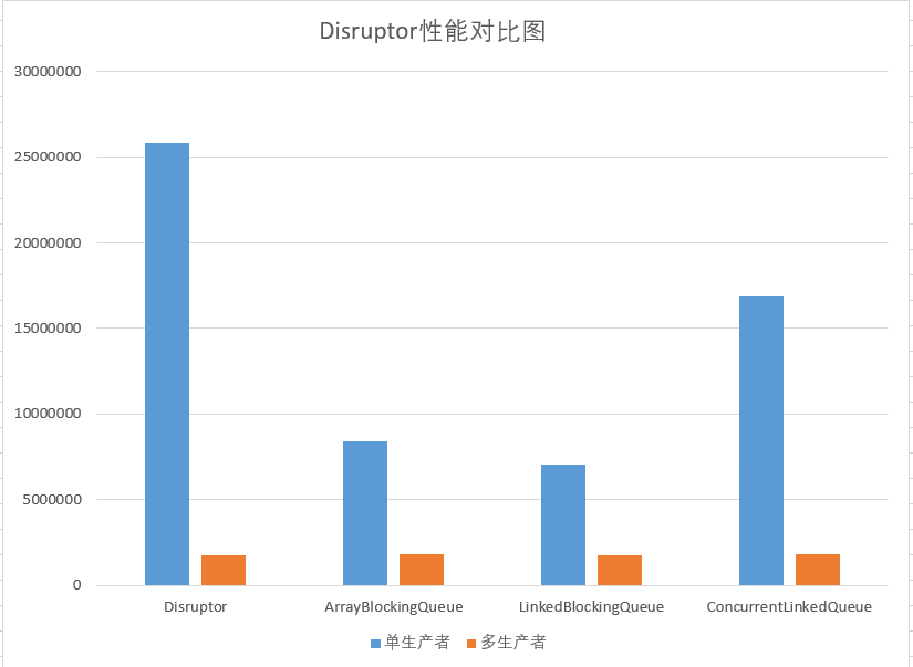
可見Disruptor在單執行緒情況下吞吐量竟能達到2500W以上,遠遠超過其他佇列。在多生產者的情況下,這幾個佇列的吞吐量卻是一樣的(說明佇列在多執行緒環境下,效能瓶頸並不在其本身)
#### 再看Log4j2官網的效能測試截圖:
大家注意最右邊的64執行緒,吞吐量比最左邊的單執行緒高了不少,為什麼這裡多執行緒的吞吐量反而更好?是上面我的多執行緒測試程式有問題嗎?
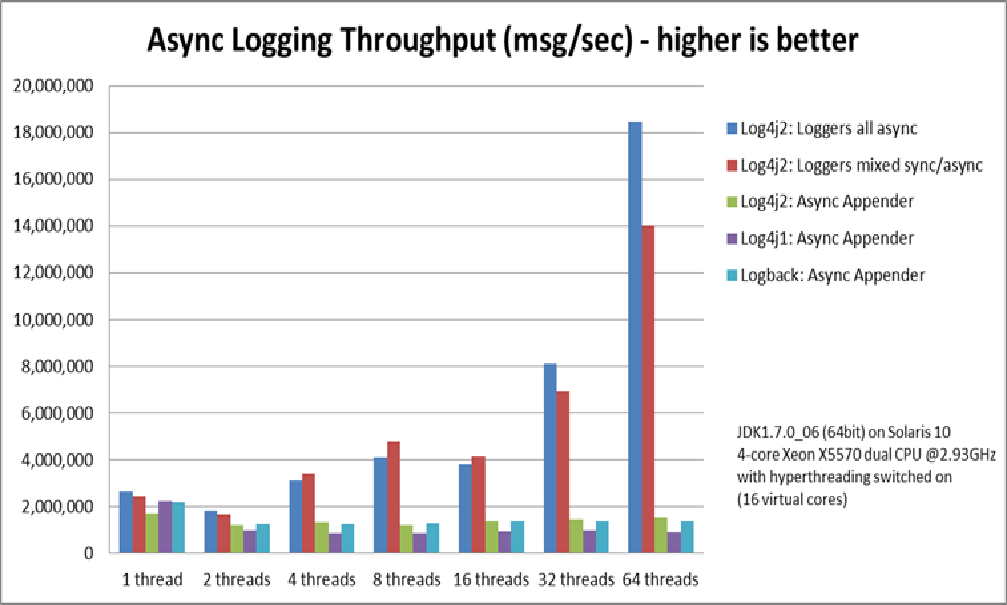
其實不是的,這是Disruptor更有魅力的一個特點:RingBuffer有一個過載的next方法,即:一次為當前執行緒分配多個事件槽,一個執行緒一次性批量生產多個事件。這樣在極限效能的情況下就可以大大減少執行緒間的上下文的切換,畢竟執行緒排程對JVM來說是很重的一個操作,也是上上圖中各佇列的多執行緒效能瓶頸所在。
## 5、為什麼那麼快?
Disruptor為什麼這麼快呢?我主要總結了這3點:
* 預分配
* 無鎖(CAS)以及減小鎖競爭
* 快取行和偽共享
### 預分配思想
預分配其實是一個空間換時間的思想,常見的如:JVM啟動時的堆記憶體分配,執行緒建立物件時堆記憶體中的TLAB分配,Redis中的動態字串結構SDS,甚至Java語言中動態陣列ArrayList等等。
Disruptor中對預分配思想的實踐有:
1. RingBuffer中的`fill`方法,建立Disruptor時就填充整個RingBuffer,而不是每次生產者生產事件時再去建立事件物件(這樣可以避免JVM大量建立和回收物件,對GC造成壓力)
2. 生產者生產事件時,可以一次性取出多個事件槽,批量生產和批量釋出
### 無鎖(CAS)以及減小鎖競爭
其實,在任何併發環境中開銷最大的操作都是:`爭用寫訪問`,因為我們可以把讀和寫分離開,`讀`可以做共享鎖,但是`寫`只能是獨佔。JDK的阻塞佇列包括併發佇列中都存在對寫操作的獨佔訪問,這也是他們的多執行緒效能瓶頸所在。當然,Disruptor中也存在`寫訪問`爭用,但是它通過巧妙的辦法,減弱了這種爭用的激烈程度(RingBuffer的next(int n)就是個例子),而且通過無鎖的CAS操作,避免了龐大的執行緒切換開銷。
Disruptor使用CAS操作的場景,大家可以對比ConcurrentLinkedQueue,這裡就不再贅述了。
### 快取行和偽共享
再看看CPU與記憶體的速度差多少倍?如果說CPU是一輛高速飛奔的高鐵,那麼當前記憶體就像旁邊蹣跚踱步的老人。然而,更氣人的是,CPU的每個指令週期中的讀指令寫資料都要依賴記憶體(與CPU速度對等的是暫存器)。

那麼如何解決CPU與記憶體如此大的速度差異呢?聰明的電腦科學家早就想到了辦法:加一個快取層,即CPU快取記憶體。
加了快取後又引出另外一個問題:區域性性原理,即2/8原則,80%的計算用20%的指令訪問20%的資料。同時,CPU讀快取記憶體和讀記憶體的速度差了100倍,所以快取的命中率越高系統的效能越厲害。快取記憶體的存放一般都是按快取行(一個快取行64Byte)管理的,同一個快取行裡不同資料存在偽共享的問題,具體描述大家可以參考[https://github.com/hiccup234/misc/blob/master/src/main/java/top/hiccup/jdk/vm/jmm/FalseSharingTest.java](https://github.com/hiccup234/misc/blob/master/src/main/java/top/hiccup/jdk/vm/jmm/FalseSharingTest.java)
那麼Disruptor是怎麼解決偽共享的問題呢?答案是:快取行填充,其實這不是Disrutpor的發明,我們開啟老點的JDK的JUC包下的Exchanger就可以看到大神Doug Lea的神來之筆:

新版的JDK已經換成了@sun.misc.Contended註解,也更優雅。
### 再談RingBuffer
RingBuffer是整個Disruptor的精神核心所在,通過檢視原始碼,我們可以知道RingBuffer是要利用快取行來守護indexMask、entries、bufferSize、sequencer不被偽共享換出。


Ringbuffer是一個首尾相連的環,或者叫迴圈佇列,但是它自己沒有尾指標,跟正常的迴圈佇列不一樣,底層資料結構採用陣列實現。
1. 減少競爭點,比如不刪除資料,所以不需要尾指標(整個佇列的尾指標由消費者維護)
2. 重複利用陣列,不需要GC事件物件
3. 使用陣列儲存資料,可以利用CPU快取每次都載入一個cacheline的特性,同時也可以避開偽共享的問題
## 6、總結
Disruptor其實還有一些其他的特性,如:Sequences(類似AtomicLong)、Sequencer、多播事件(類似MQ的Fanout交換機)以及RingBuffer持有的首指標,消費者持有的尾指標的控制和同步問題等等,大家可以對照原始碼分析和整理。