
Web Scraper 高階用法——利用正則表示式篩選文字資訊 | 簡易資料分析 17
阿新 • • 發佈:2020-03-18

這是簡易資料分析系列的**第 17 篇**文章。
學習了這麼多課,我想大家已經發現了,web scraper 主要是用來爬取**文字資訊**的。
在爬取的過程中,我們經常會遇到一個問題:網頁上的資料比較髒,我們只需要裡面的一部分資訊。比如說要抓取 電影的評價人數,網頁中抓到的原始資料是 `1926853人評價`,但是我們期望只抓取數字,把 `人評價` 這三個漢字丟掉。

這種類似的操作在 Excel 可以利用公式等工具處理,其實在 web scraper 裡,也有一個利器,那就是**正則表示式**。
正則表示式是一個非常強大工具,它主要是用來**處理文字資料**的,常用來**匹配**、**提取**和**替換**文字,在計算機程式中有非常廣泛的應用。
web scraper 中也內建了正則表示式工具,但只提供了**提取**的功能。雖然功能有所殘缺,對於 web scraper 使用者來說完全夠用了,畢竟 web scraper 的定位就是不會寫程式碼的小白,我們只需要學習最基礎的知識就可以了。
## 1.正則表示式初嘗
我們先用 web scraper 初步嘗試一下正則表示式。這裡還是用豆瓣電影做例子,我們先選擇電影的評價人數,預覽圖是這個樣子的:
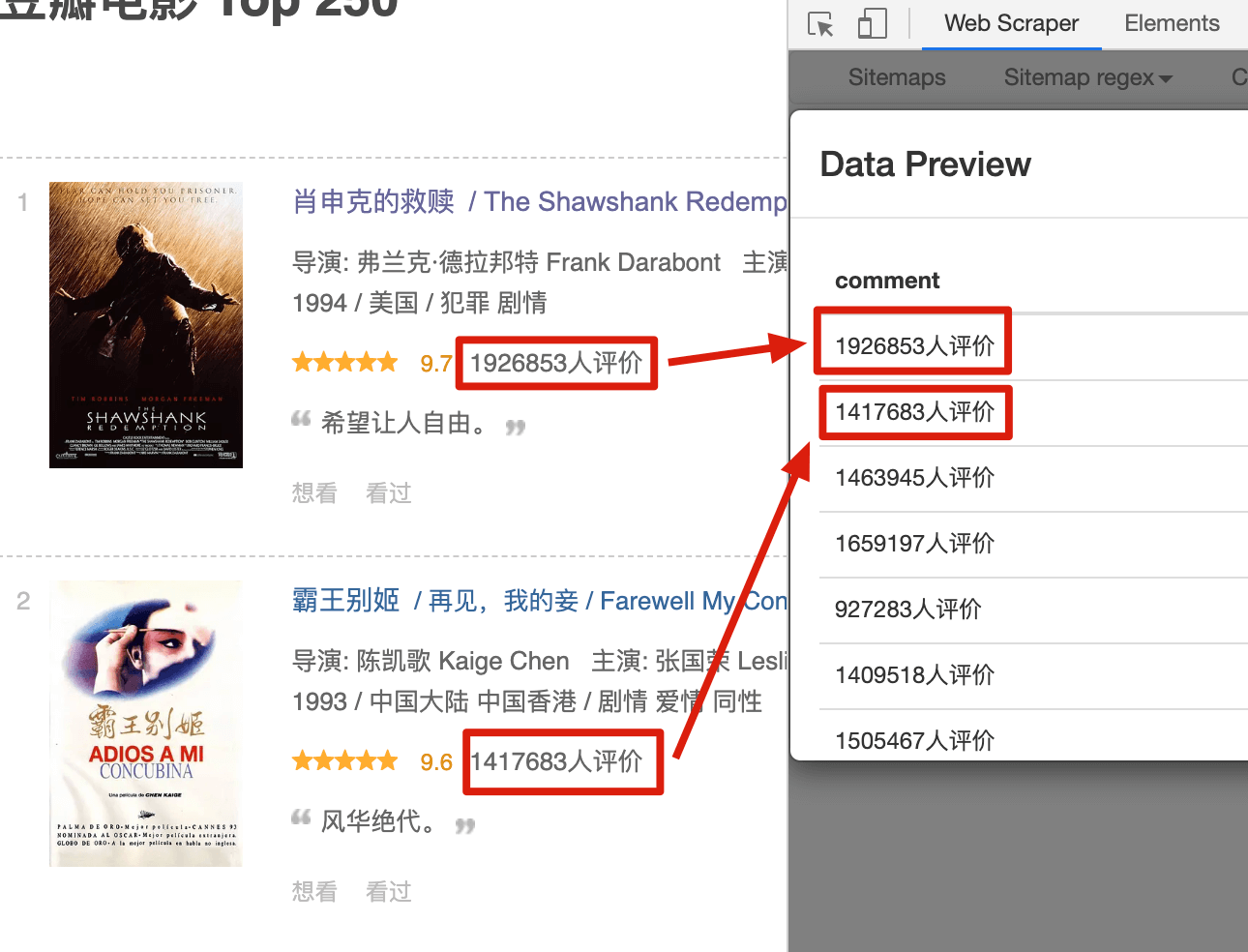
Text 選擇器有個 `Regex` 的輸入框,這個就是輸入正則表示式的地方。我們輸入 `[0-9]`,然後再點選預覽,是這個樣子的:

這時候你應該就明白了, `[0-9]` 就是匹配**一個**數字的意思。如果我們要匹配**多個**數字呢?很簡單,後面再加個「 `+` 」號就好。把 `[0-9]+` 輸入進去,預覽一下:

很明顯,所有的數字都匹配出來了。
## 2.正則表示式字元簇
上面講了用 `[0-9]` 匹配數字,我們想一下日常用到的文字資訊,不外乎這幾種:數字、小寫字母、大些字母,漢字,特殊字元(比如說各種計量單位、下劃線回車等符號) 。
正則表示式裡都有匹配這些字元的方法,下面我用一個表格列舉出來:
| 字元簇 | 匹配 |
| ----------------- | -------------------------------------------- |
| `[0-9]` | 匹配所有的數字 |
| `[1-9]` | 匹配 1 到 9 |
| `[a-z]` | 匹配所有的小寫字母 |
| `[A-Z]` | 匹配所有的大寫字母 |
| `sky` | 匹配 `sky` 這個單詞,其餘文字同理 |
| `天空` | 匹配 `天空` 這個詞,其餘文字同理 |
| `[\u4e00-\u9fa5]` | 匹配所有的漢字(絕大部分情況下可以匹配成功) |
| `[ \f\r\t\n]` | 匹配所有的空白字元 |
上面列舉了一些常用的,其實這些規則可以組合起來,比如說 `[a-z]` 和 `[A-Z]` 組合起來,就是 `[a-zA-Z]`,表示匹配所有的字母。這些組合也有一些簡寫,我這裡也列舉一些:
| 字元簇 | 匹配 |
| ------ | ------------------------------------------------------------ |
| `\w` | 匹配字母、數字、下劃線。等價於 `[A-Za-z0-9_]` |
| `\W` | 匹配**非**字母、數字、下劃線 |
| `\s` | 匹配任何空白字元,包括空格、製表符、換頁符等等。等價於 `[ \f\n\r\t\v]` |
| `\S` | 匹配任何**非**空白字元 |
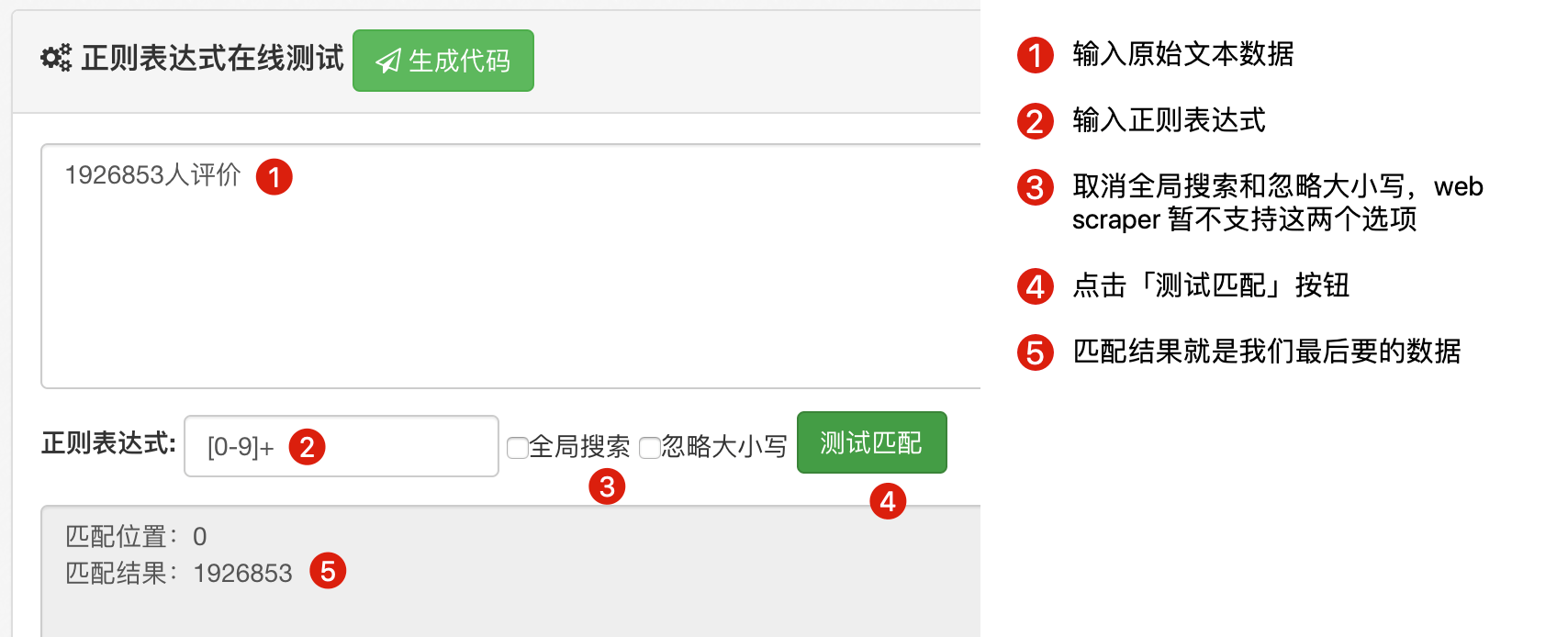
基本上掌握以上內容就能匹配絕大多數字符了,這裡我推薦一個正則練習網站:
http://c.runoob.com/front-end/854
按照下圖所示就可以練習正則匹配了:
結合前面的例子,我們知道這些規則只能匹配一個字元,如何匹配多個字元?這就要學習**正則表示式限定符**。
## 3.正則表示式限定符
我們已經知道在 [0-9] 後面加個加號「`+`」就可以匹配多個字元了,其實還有很多限定符,詳情可見下圖表格:
| 限定符 | 匹配解釋 | 原始資料 | 例子 |
| ------- | ------------------------------------------------------------ | ---------- | ------------------------------------------------------------ |
| `{n}` | n 是一個非負整數。匹配確定的 n 次 | 100001 | `10{2}`,表示 0 這個字元匹配 2 次,匹配結果是 100 |
| `{n,m}` | m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次 | 100001 | `10{2,3}`,表示 0 這個字元最少匹配 2 次且最多匹配 3 次,匹配結果是 1000 |
| `{n,}` | n 是一個非負整數。至少匹配 n 次 | 100001 | `10{2,}`,表示 0 這個字元至少匹配 2 次,匹配結果是 10000 |
| `+` | 匹配前面的子表示式**一次或多次**,等價於 `{1,}` | z,zo,zoo | `zo+` 能匹配「zo」以及「zoo」,但不能匹配「z」 |
| `*` | 匹配前面的子表示式**零次或多次**,等價於 `{0,}` | z,zo,zoo | `zo*` 能匹配「z」、「zo」以及「zoo」 |
| `?` | 匹配前面的子表示式**零次或一次**,等價於 `{0,1}` | z,zo,zoo | `zo?` 能匹配「z」以及「zo」,但不能匹配「zoo」 |
## 4.實戰練習
學到這裡,正則表示式可以算是入門了,我們可以上手幾個真實的例子練習一下:
**1.提取價格標籤中的數字**
假設 web scraper 爬到的文字資訊是 `價格:12.34 ¥`,我們要把 `12.34` 提取出來。這個這個文本里有 5 類資料:
- 漢字:`價格`
- 標點符號:`:`
- 數字 `12` 和 `34`
- 小數點:`.`
- 特殊字元:`¥`
首先我們匹配小數點前的數字 `12`,因為價格什麼數字可以能出現,而且位數一般都大於 1 位,所以我們用 `[0-9]+` 來匹配;考慮到小數點「`.`」在正則表示式裡有特殊含義,我們需要小數點前面加反斜槓 `\` 表示轉義,用 `\.` 匹配;小數部分同理,也用 `[0-9]+` 匹配。
把這三部分組合在一起,即「`[0-9]+\.[0-9]+`」,這個表示式可以用一個圖來表示:
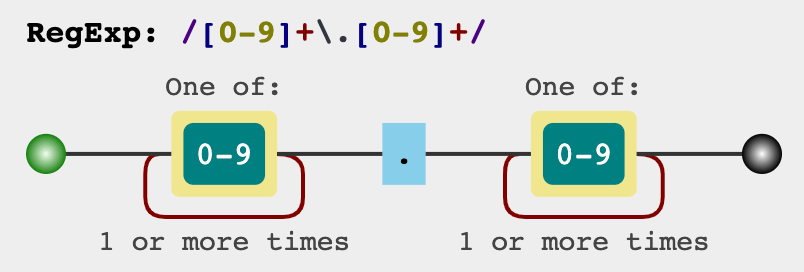
上面就是我們寫出的匹配正則,可以放在剛剛推薦的網站上驗證一下:

**2.匹配日期**
假設 web scraper 爬到的文字資訊是 `日期:2020-02-02[星期日]`,我們要把 `2020-02-02[星期日]` 提取出來。我們把這個文字分解一下:
- 描述資訊 `日期:` 不匹配,需要丟棄掉
- 年,一般是 4 位,可以用 `[0-9]{4}` 匹配
- 月,一般是 2 位,可以用 `[0-9]{2}` 匹配
- 日,一般是 2 位,可以用 `[0-9]{2}` 匹配
- 星期,多個漢字,可以用 `[\u4e00-\u9fa5]+` 匹配
- 分隔符 `-`,可以直接用「`-`」匹配
- 分隔符 `[` 和 `]`,為了避免和正則表示式裡的 `[]` 撞車,我們可以在前面加反斜槓 `\` 表示轉義,用 `\[ ` 和 `\]` 匹配
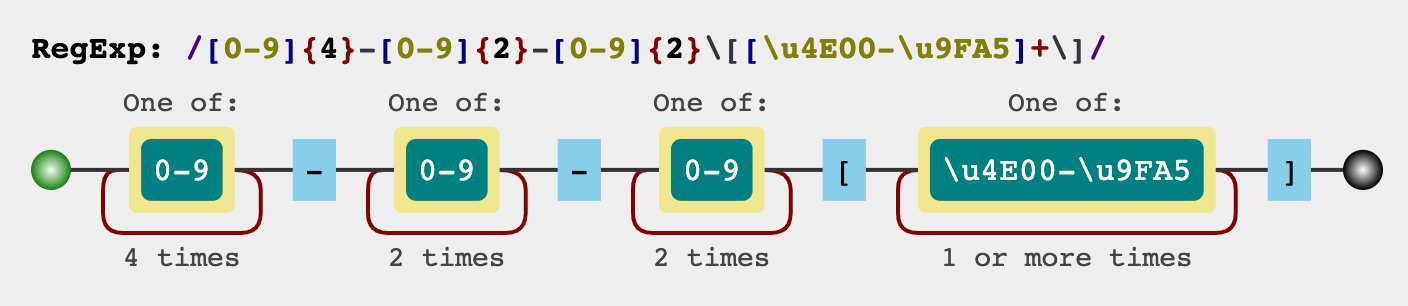
把上面的分析結果綜合一下,就是
`[0-9]{4}-[0-9]{2}-[0-9]{2}\[[\u4e00-\u9fa5]+\]`
看上去還是挺複雜的,但是如果按上面的分析步驟一步一步來,你會發現匹配規則其實還是比較清晰的。
同樣我們可以用一張圖來表示上面的正則表示式:
## 5.進階學習
本篇教程只是正則的入門學習,很多知識點還沒有講到。如果你對此感興趣,可以去下面幾個網站學習:
**1.**[**菜鳥教程:正則表示式**](https://www.runoob.com/regexp/regexp-tutorial.html)
繼續深入學習的一個網站,不過想成為高手,還得多加練習
**2.**[**正則表示式線上測試**](http://c.runoob.com/front-end/854)
可以測試自己寫的正則是否正確的一個網站,而且網頁末有常用的正則表示式,很多可以直接複製黏貼來用。
**3.[Regulex](https://jex.im/regulex/#!flags=&re=^(a|b)*%3F%24) 和 [RegExr](https://regexr.com/)**
可以視覺化的顯示自己的正則匹配規則,教程中我就用了 regulex 生成正則匹配規則圖。
## 6.溫馨提示(踩坑預警)
我看了 web scraper 的原始碼,它的正則表示式支援不完全,目前只支援**提取**文字的功能:

他欠缺的功能有:
- 全域性匹配不支援
- 忽略大小寫不支援
- 不支援分組提取,預設返回第一個匹配值
- 不支援文字替換
如果有以上的需求,可能要藉助 Excel 等工具來支援。
## 7.聯絡我
因為文章發在各大平臺上,賬號較多不能及時回覆評論和私信,有問題可關注公眾號 ——「鹵代烴實驗室」,(或 wx 搜尋 sky-chx)關注上車防失聯。
![img](https://image-1255652541.cos.ap-shanghai.myqcloud.com/images/201907092200