
資料競賽實戰(5)——方圓之外
前言
1,背景介紹
這裡給出六千張影象做為訓練集。每個影象中只要一個圖形,要麼是圓形,要是是正方形。你的任務是根據這六千張圖片訓練出一個二元分類模型,並用它在測試集判斷每個影象中的形狀是圓還是方;測試集中有些影象既不是圓也不是方,也請將其甄別出來。
2,任務型別
二元分類,異常檢測,影象識別
3,資料檔案說明
資料檔案分為三個:
train.csv 訓練集 檔案大小為34.7MB
test.csv 預測集 檔案大小為30.0MB
sample_submit.csv 提交示例 檔案大小為40KB
4,資料變數說明

訓練集中共有6000個灰度影象,預測集中有5191個灰度影象。每個影象中都會含有大量的噪點。影象的解析度為40*40,也就是40*40的矩陣,每個矩陣以行向量的形式被存放在train.csv和test.csv中。train.csv和test.csv中每行資料代表一個影象,也就是說每行都有1600個特徵。
訓練集中的影象是圓形或者方形,測試集中的影象除了圓形和方形,還有非圓非方的異形。

任務是提交預測集中每個影象的標籤(而非概率),以0表示圓,1表示方,2表示異形。格式應該與sample_submit.csv 一致。
train.csv 和 test.csv 均為逗號分隔形式的檔案。在python中可以通過如下形式讀取:
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
5,評估方法
提交的結果為每行的預測標籤,也就是0,1,2 。評價方法為準確率。
您提交的結果為每行樣本(每個樣本)的預測標籤,0表示圓形,1表示方形,2表示異形。
6,解題思路
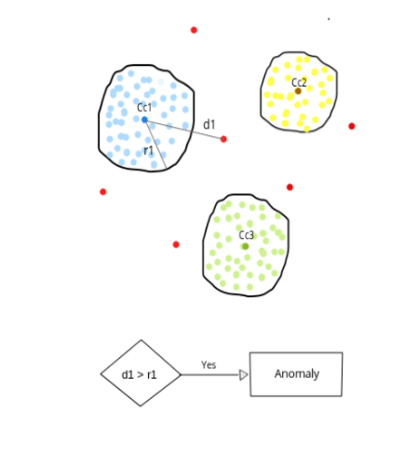
6.1 KNN做異常檢測思路:
如何用K Means做非監督的異常檢測(outlier anomaly detection)?
類似於one-class SVM,先用乾淨的資料(沒有異常點)得到一個K Means。然後把測試集(包含異常點)根據之前KMeans的結果進行聚類,如果一個點距離它最近的中心超過之前訓練集裡的最大距離的話,就判斷它為異常點。
參考文獻: https://www.cnblogs.com/rongyux/p/5967470.html
http://www.bubuko.com/infodetail-1156495.html
https://www.docin.com/p-1298017248.html
這種方法簡單,但是效果可能不是很好,這裡我試驗過了,就不貼程式碼了,程式碼在GitHub上,想看的可以去看。
6.2 相當於檢測 out of distribution 的資料
可以參考uncertainty measure的方法,去年nips專門有專題解決uncertainty measure的問題。
可以參考:https://arxiv.org/abs/1610.02136
https://nips.cc/Conferences/2019/Schedule?showParentSession=15553
6.3 兩分類來做
大概的思路這裡說一下。
我打算結合之前的二分類,做一個二元分類,當閾值低於某個點的時候,我們設定其為第三類。下面我會嘗試,看看效果如何。
6.4 三分類來做
我在知乎提問過,總的來說,各路大神的建議都是三分類,我就嘗試了三分類來做。
知乎連結:https://www.zhihu.com/question/366130808
大概建議最多的就是三分類了。所以我打算嘗試一下。
7,兩分類來做
參考地址:資料競賽實戰(2)——形狀識別:是方還是圓
為什麼想到這樣做呢?我們慢慢來。
首先之前的二分類訓練集只有兩類影象,要麼是圓形,要麼是方形,我通過資料檢視的影象如下:
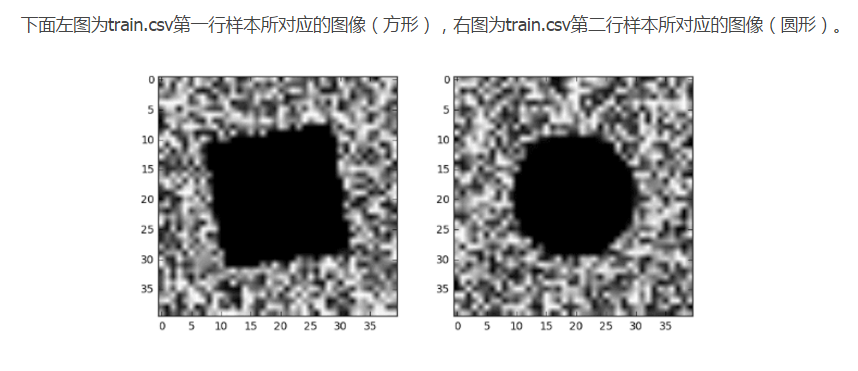
如何通過Python進行矩陣與影象之間的轉換,我之前的部落格裡面有,這裡不再贅述。
而我們這次訓練集中也是隻有兩類影象,要麼是圓形,要麼是方形,我們檢視資料如下:

從肉眼來看,特徵還是很明顯的。我們利用上面部落格中的卷積神經網路進行二元分類。
首先,我們跑一下第一個資料的二元分類,資料我們叫 datain,當然第二次資料我們稱為 dataout。第一次的資料毫無疑問是沒有任何問題的,但是這裡就再跑一邊。
程式碼如下:
# _*_coding:utf-8_*_
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras import backend as K
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.ndimage import median_filter
import matplotlib.pyplot as plt
def load_train_test_data(train, test):
np.random.shuffle(train)
labels = train[:, -1]
test = np.array(test)
data, data_test = data_modify_suitable_train(train, True), data_modify_suitable_train(test, False)
train_x, test_x, train_y, test_y = train_test_split(data, labels, test_size=0.33) # test_size=0.7
return train_x, train_y, test_x, test_y, data_test
def data_modify_suitable_train(data_set=None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
# data = data_set[:, 0: data_set.shape[1] - 1]
data = data_set[:, 0: -1]
print(data.shape)
else:
data = data_set
data = np.array([np.reshape(i, (40, 40)) for i in data])
# data = np.array([median_filter(i, size=(3, 3)) for i in data])
# data = np.array([(i > 10) * 100 for i in data])
data = np.array([np.reshape(i, (i.shape[0], i.shape[1], 1)) for i in data])
return data
def f1(y_true, y_pred):
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall))
def bulit_model(train, test):
model = Sequential()
model.add(Convolution2D(filters=8,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
# 完成模型的搭建後,使用.compile方法來編譯模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def train_models(train, test, batch_size=64, epochs=20, model=None):
train_x, train_y, test_x, test_y, t = load_train_test_data(train, test)
# print(train_x.shape, train_y.shape, test_x.shape, test_y.shape, t.shape)
if model is None:
model = bulit_model(train, test)
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
print("刻畫損失函式在訓練與驗證集的變化")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
# ##### 注意這個t
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
pred = np.array(pred_prob > 0.5).astype(int)
score = model.evaluate(test_x, test_y, batch_size=batch_size)
print('score is %s' % score)
print("刻畫預測結果與測試結果")
return pred
if __name__ == '__main__':
train = pd.read_csv('datain/train.csv')
test = pd.read_csv('datain/test.csv')
# train = train.iloc[:,1:]
# test = test.iloc[:,1:]
# print(type(train))
train = np.array(train.drop('id', axis=1))
test = np.array(test.drop('id', axis=1))
# print(type(train))
pred = train_models(train, test)
# submit = pd.read_csv('dataout/sample_submit.csv')
# submit['y'] = pred
# submit.to_csv('my_CNN_prediction.csv', index=False)
我們訓練到最後一輪,發現loss越來越小,acc已經等於1,f1 score也等於1。
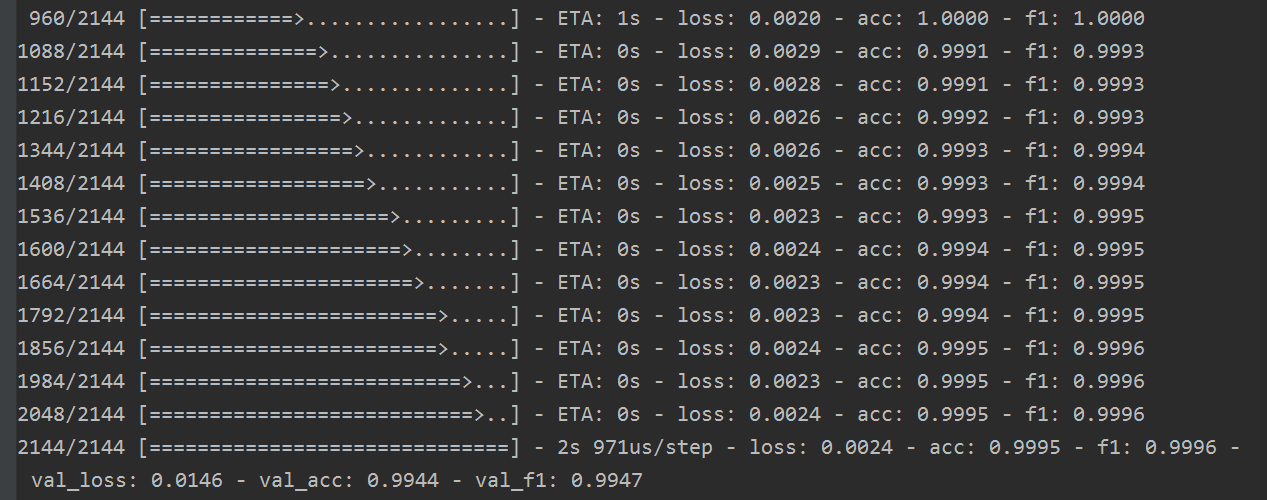
下圖為損失函式在訓練集合驗證集中的變化:
效果不錯。
下面我們直接更改資料集,看第二個只有方圓的資料集的效果如何。
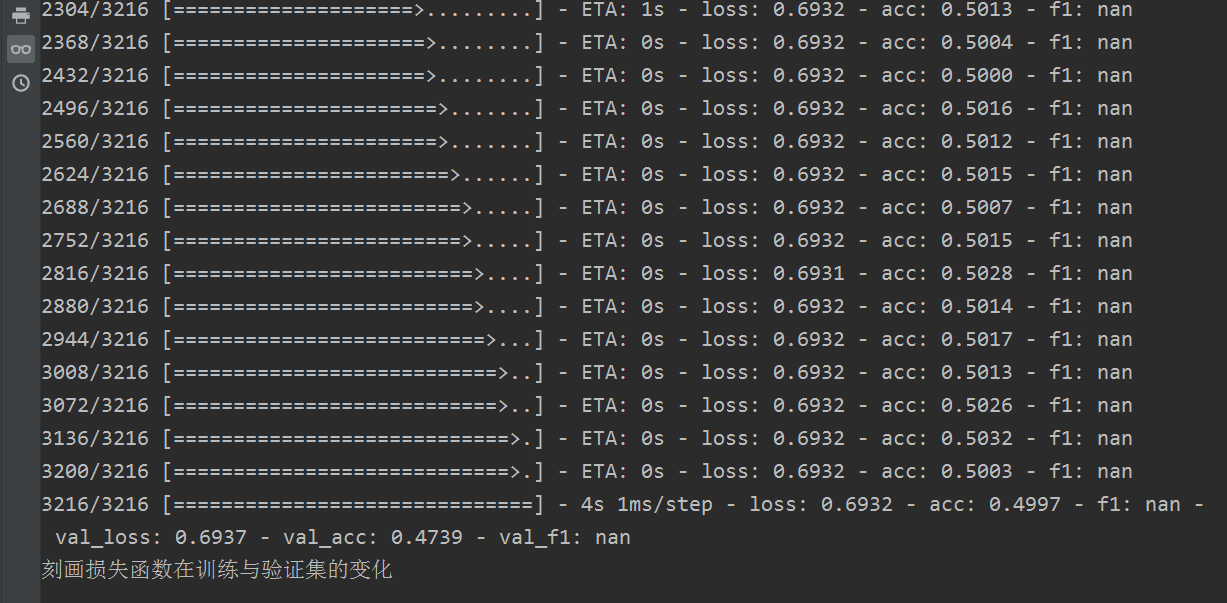
下圖為刻畫損失函式在訓練與驗證集的變化
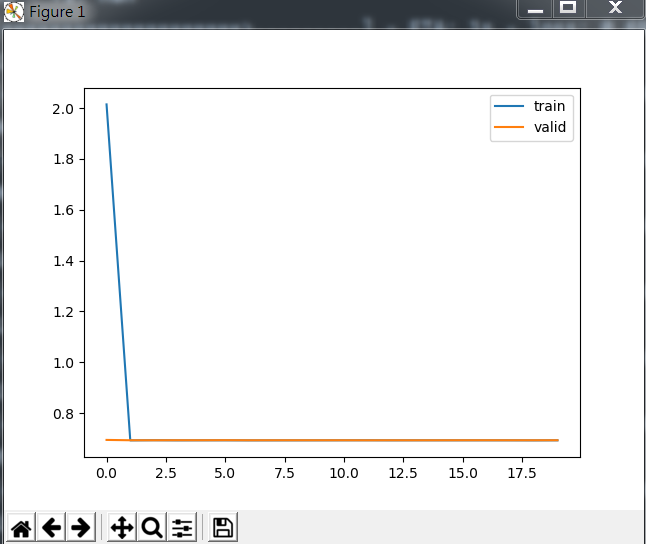
我們會發現效果極其的差,也就是很不好,loss遲遲降不下來,acc也上不去。所以我們需要對資料進行預處理。
7.1 對資料進行預處理
從上面兩個訓練的結果來看,第一個效果很好,第二個效果不好,這是為什麼呢?雖然我們人眼很容易的區分了出來,但是機器卻區分不開,所以當資料直接訓練出問題的時候,我們則需要對資料進行預處理了。包括降噪等。
下面我們對影象進行預處理的過程如下:
- 1,利用中值濾波(median filter)進行降噪
- 2,利用閾值分割法(threshold segmentation)生成掩膜(binary mask)
- 3,利用形態閉合(morphology closing)來填充圖中的小洞
下面來測試一下:
from skimage.restoration import (denoise_tv_chambolle, denoise_bilateral,
denoise_wavelet, estimate_sigma)
from scipy import ndimage, misc
import statistics
import scipy
def my_preprocessing(I,show_fig=False):
I_median=ndimage.median_filter(I, size=5)
mask=(I_median<statistics.mode(I_median.flatten()));
I_out=scipy.ndimage.morphology.binary_closing(mask,iterations=2)
if(np.mean(I_out[15:25,15:25].flatten())<0.5):
I_out=1-I_out
if show_fig:
fig= plt.figure(figsize=(8, 4))
plt.gray()
plt.subplot(2,4,1)
plt.imshow(I)
plt.axis('off')
plt.title('Image')
plt.subplot(2,4,2)
plt.imshow(I_median)
plt.axis('off')
plt.title('Median filter')
plt.subplot(2,4,3)
plt.imshow(mask)
plt.axis('off')
plt.title('Mask')
plt.subplot(2,4,4)
plt.imshow(I_out)
plt.axis('off')
plt.title('Closed mask')
fig.tight_layout()
plt.show()
return I_out
I_out=my_preprocessing(x_test[5],True);
結果如下:

當我們對影象進行處理,我們發現想很明顯,就只是做了中值濾波效果都出來了。這下加入資料預處理,我們來看看所有的效果,包括上一篇是方還是圓的文章中,我們做了中值濾波加二值化,效果很好,這一篇我們加了掩膜,這裡做一個測試,我想看看中值濾波加二值化在此篇文章中的效果如何,並且看看掩膜對於上一篇文字中的資料的效果如何呢?
程式碼如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.ndimage import median_filter
import statistics
from scipy import ndimage
def loadData(trainFile, show_fig=False):
train = pd.read_csv(trainFile)
data = np.array(train.iloc[0, 1:-1])
origin_data = np.reshape(data, (40, 40))
# 做了中值濾波
median_filter_data = np.array(median_filter(origin_data, size=(3, 3)))
# 二值化
# binary_data = np.array((origin_data > 127) * 256)
binary_data = np.array((origin_data > 1) * 256)
# 利用閾值分割法生成掩膜
mask = (median_filter_data < statistics.mode(median_filter_data.flatten()))
# 利用形態閉合來填充圖中的小洞
binary_closing_data = ndimage.morphology.binary_closing(mask, iterations=2)
if(np.mean(binary_closing_data[15:25, 15:25].flatten()) < 0.5):
binary_closing_data = 1-binary_closing_data
if show_fig:
# fig = plt.figure(figsize=(8, 4))
plt.subplot(1, 5, 1)
plt.gray()
plt.imshow(origin_data)
plt.axis('off')
plt.title('origin photo')
plt.subplot(1, 5, 2)
plt.imshow(median_filter_data)
plt.axis('off')
plt.title('median filter photo')
plt.subplot(1, 5, 3)
plt.imshow(binary_data)
plt.axis('off')
plt.title('binary photo')
plt.subplot(1, 5, 4)
plt.imshow(mask)
plt.axis('off')
plt.title('mask photo')
plt.subplot(1, 5, 5)
plt.imshow(binary_closing_data)
plt.axis('off')
plt.title('binary_closing photo')
if __name__ == '__main__':
trainFile = 'dataout/train.csv'
loadData(trainFile, True)
對於上一節的資料效果如下:

對於上一節的資料,做二值處理,效果就很明顯了,再加上掩膜,很明顯畫蛇添足了。
我們看這一節的效果:

對於此節的資料,做掩膜效果明顯,但是單純的二值處理,效果根本不好。
所以這裡得出一個結論,就是對於不同的資料集要做不同的處理,具體如何處理呢?這是個玄學問題。我會繼續尋找其規律,找到了必定寫出來。
7.2 模型訓練
好了,下面就測試測試,測試資料的時候,我們就不需要使用掩膜對第一個資料進行處理了,從處理圖片就可以看出效果一點也不好,而使用二值對第一個資料處理,在之前的博文裡面全部分析過,這裡不再贅述了。
所以這裡測試的是使用掩膜對這篇博文的資料做二值分類,看效果如何。
程式碼如下:
# _*_coding:utf-8_*_
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras import backend as K
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.ndimage import median_filter
import matplotlib.pyplot as plt
import scipy
from scipy import ndimage, misc
import statistics
def load_train_test_data(train, test):
np.random.shuffle(train)
# train = train[:, :-1]
labels = train[:, -1]
test = np.array(test)
# print(train.shape, test.shape, labels.shape) # (6000, 1600) (5191, 1600) (6000,)
data, data_test = data_modify_suitable_train(train, True), data_modify_suitable_train(test, False)
# print(data.shape, data_test.shape)
# train = train.reshape([train.shape[0], 40, 40])
# test = test.reshape([test.shape[0], 40, 40])
# data, data_test = batch_preprocessing(train), batch_preprocessing(test)
# # print(data.shape, data_test.shape) # (6000, 40, 40) (5191, 40, 40)
# 注意這裡需要新增一個維度
data, data_test = np.expand_dims(data, 3), np.expand_dims(data_test, 3)
# print(data.shape, data_test.shape)
train_x, test_x, train_y, test_y = train_test_split(data, labels, test_size=0.33) # test_size=0.7
return train_x, train_y, test_x, test_y, data_test
def data_test(train, test):
np.random.shuffle(train)
train = train[:, :-1]
labels = train[:, -1]
test = np.array(test)
# print(train.shape, test.shape, labels.shape) # (6000, 1600) (5191, 1600) (6000,)
train = train.reshape([train.shape[0], 40, 40])
test = test.reshape([test.shape[0], 40, 40])
data = my_preprocessing(train[1])
all_data = batch_preprocessing(data_set=train)
# data = data_modify_suitable_train(train, True)
print(data.shape, type(data)) # (40, 40) <class 'numpy.ndarray'>
print(all_data.shape, type(all_data))
plt.gray()
plt.imshow(all_data[1])
plt.axis('off')
plt.title('origin photo')
def my_preprocessing(I, show_fig=False):
I_median = ndimage.median_filter(I, size=5)
mask = (I_median < statistics.mode(I_median.flatten()))
I_out = scipy.ndimage.morphology.binary_closing(mask, iterations=2)
if (np.mean(I_out[15:25, 15:25].flatten()) < 0.5):
I_out = 1 - I_out
if show_fig:
fig = plt.figure(figsize=(8, 4))
plt.gray()
plt.subplot(2, 4, 1)
plt.imshow(I)
plt.axis('off')
plt.title('Image')
plt.subplot(2, 4, 2)
plt.imshow(I_median)
plt.axis('off')
plt.title('Median filter')
plt.subplot(2, 4, 3)
plt.imshow(mask)
plt.axis('off')
plt.title('Mask')
plt.subplot(2, 4, 4)
plt.imshow(I_out)
plt.axis('off')
plt.title('Closed mask')
fig.tight_layout()
plt.show()
return I_out
def batch_preprocessing(data_set):
zero_data = np.zeros_like(data_set)
data_n = data_set.shape[0]
for i in range(data_n):
zero_data[i] = my_preprocessing(data_set[i])
return zero_data
def data_modify_suitable_train(data_set=None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
# data = data_set[:, 0: data_set.shape[1] - 1]
data = data_set[:, 0: -1]
print(data.shape)
else:
data = data_set
data = np.array([np.reshape(i, (40, 40)) for i in data])
print('data', data.shape)
# median_data = np.array([median_filter(i, size=(5, 5)) for i in data])
# print('median', median_data.shape)
# mask = (median_data < statistics.mode(median_data.flatten()))
# print('mask', mask.shape)
# res_data = ndimage.morphology.binary_closing(mask, iterations=2)
# if (np.mean(res_data[15:25, 15:25].flatten()) < 0.5):
# res_data = 1 - res_data
# print('res_data', res_data.shape)
zero_data = np.zeros_like(data)
data_n = data.shape[0]
for i in range(data_n):
zero_data[i] = my_preprocessing(data[i])
return zero_data
# data = np.array([(i > 10) * 100 for i in data])
# data = np.array([np.reshape(i, (i.shape[0], i.shape[1], 1)) for i in res_data])
# data = np.array([np.reshape(i, (i.shape[0], i.shape[1])) for i in res_data])
# return data
def f1(y_true, y_pred):
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall))
def built_model():
model = Sequential()
model.add(Convolution2D(filters=8,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
# 完成模型的搭建後,使用.compile方法來編譯模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def built_model_plus():
n_filter = 32
# 序貫模型是多個網路層的線性堆疊,也就是“一條道走到黑”
model = Sequential()
# 通過 .add() 方法一個個的將 layer加入模型中
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
# final layer using softmax
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def train_models(train, test, batch_size=64, epochs=20, model=None):
train_x, train_y, test_x, test_y, t = load_train_test_data(train, test)
# print(train_x.shape, train_y.shape, test_x.shape, test_y.shape, t.shape)
if model is None:
model = built_model_plus()
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
print("刻畫損失函式在訓練與驗證集的變化")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
# ##### 注意這個t
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
pred = np.array(pred_prob > 0.5).astype(int)
score = model.evaluate(test_x, test_y, batch_size=batch_size)
print('score is %s' % score)
print("刻畫預測結果與測試結果")
return pred
if __name__ == '__main__':
trainFile = 'dataout/train.csv'
testFile = 'dataout/test.csv'
submitfile = 'dataout/sample_submit.csv'
train = pd.read_csv(trainFile)
test = pd.read_csv(testFile)
train = np.array(train.drop('id', axis=1))
test = np.array(test.drop('id', axis=1))
# print(train.shape, test.shape) # (6000, 1601) (5191, 1600)
# load_train_test_data(train, test)
# data test
# data_test(train, test)
# load_train_test_data(train, test)
# print('over')
pred = train_models(train, test)
# submit = pd.read_csv('dataout/sample_submit.csv')
# submit['y'] = pred
# submit.to_csv('my_CNN_prediction.csv', index=False)
訓練結果如下(這個是build_model_plus):

下圖為損失函式在訓練與驗證集的變化:
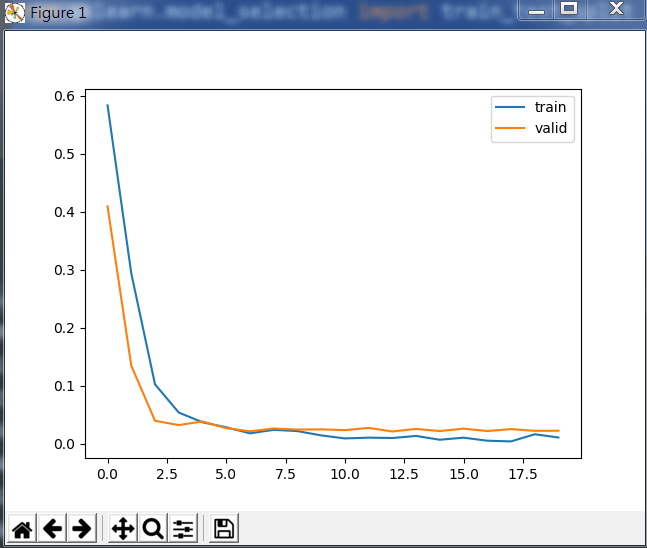
下面是 (build_model)的效果:
下圖為損失函式在訓練與驗證集的變化:

效果不如上一個好。所以我們採用plus的模型。
下面我們做兩分類模型,閾值設定為0.3和0.7,程式碼如下:
# ##### 注意這個t
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
# pred = np.array(pred_prob > 0.5).astype(int)
# score = model.evaluate(test_x, test_y, batch_size=batch_size)
# print('score is %s' % score)
# print("刻畫預測結果與測試結果")
for i in range(pred_prob.shape[0]):
if pred_prob[i][0] > 0.7:
pred_prob[i][0] = 1
elif pred_prob[i][0] < 0.3:
pred_prob[i][0] = 0
else:
pred_prob[i][0] = 2
return pred_prob.astype(int)
結果如下:

講道理,效果讓我意想不到啊,還是很不錯的。
8,三分類來做
測試了兩分類,下面就實驗一下triplet 。
8.1 知識儲備
這裡學習一下 sklearn.preprocessing.MultiLabelBinarizer 函式。
參考地址:https://blog.csdn.net/kancy110/article/details/75094179
多標籤二值化:klearn.preprocessing.MultiLabelBinarizer(classes=None, sparse_output=False) classes_屬性:若設定classes引數時,其值等於classes引數值,否則從訓練集統計標籤值
測試1,當classes採用預設值,classes_屬性值從訓練集中統計標籤值。
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
mlb.fit_transform([(1,2), (3, 4), (5, 6), (7, )])
Out[4]:
array([[1, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 1]])
mlb.classes_
Out[5]: array([1, 2, 3, 4, 5, 6, 7])
測試2,設定classes引數,classes_屬性值等於classes引數值
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer(classes=[2,3,4,5,6])
mlb.fit_transform([(1,2), (3, 4), (5, 6), (7, )])
D:\anaconda3\envs\python36\lib\site-packages\sklearn\preprocessing\label.py:951: UserWarning: unknown class(es) [1, 7] will be ignored
.format(sorted(unknown, key=str)))
Out[8]:
array([[1, 0, 0, 0, 0],
[0, 1, 1, 0, 0],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 0]])
mlb.classes_
Out[9]: array([2, 3, 4, 5, 6])
8.2 資料處理
資料處理我們這裡和上面一樣,首先是中值濾波降噪,利用閾值分割法生成掩膜,利用形態閉合來填充圖中的小洞。上面都有過程,這裡不再贅述。
我們說的要人工從測試集中挑選了訓練集中並未出現過的標籤的幾個樣本,加入訓練集中,這裡採用五個。
首先需要找到五個異常的樣本,後面我們可以增加到10個。
測試集的下標是從0開始的,我們就從第一個開始,找10個。


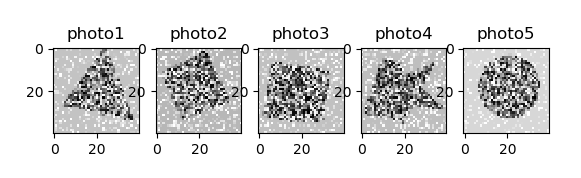

我這都是按照順序找的,分別是0, 1, 4, 10, 13。
還有作者找的五個異形分別是 4949, 4956, 4973, 4988:

這裡附上,我的檢查程式碼
import pandas as pd
import matplotlib.pyplot as plt
def seek_abnormal(testFile, show_fig=True):
data = pd.read_csv(testFile)
data1 = np.array(data.iloc[0:, 1:])
# print(data1.shape) # (5191, 1600)
# data2 = np.array(data)
# data2 = data2[0:, 1:]
photo1 = np.reshape(data1[949], (40, 40))
photo2 = np.reshape(data1[956], (40, 40))
photo3 = np.reshape(data1[973], (40, 40))
photo4 = np.reshape(data1[974], (40, 40))
photo5 = np.reshape(data1[988], (40, 40))
if show_fig:
plt.subplot(1, 5, 1)
plt.gray()
plt.imshow(photo1)
plt.title('photo1')
plt.subplot(1, 5, 2)
plt.gray()
plt.imshow(photo2)
plt.title('photo2')
plt.subplot(1, 5, 3)
plt.gray()
plt.imshow(photo3)
plt.title('photo3')
plt.subplot(1, 5, 4)
plt.gray()
plt.imshow(photo4)
plt.title('photo4')
plt.subplot(1, 5, 5)
plt.gray()
plt.imshow(photo5)
plt.title('photo5')
if __name__ == '__main__':
testFile = 'dataout/test.csv'
# 查詢異形圖片
seek_abnormal(testFile)
下面需要將異形資料加入到訓練集中,程式碼如下:
# 人工從測試集中挑選訓練集中並未出現過的標籤樣本,加入訓練集中
def add_other_sample_func(train_prc, labelMat, test_prc):
# 五個異形在原資料中對應的下標
# 手動檢視測試集中的影象,並且增加了五個異性,放入訓練集中
num_anno = 5
anno_inx = np.array([4949, 4956, 4973, 4974, 4988])
# anno_idx = np.array([4000, 4001, 4004, 4010, 4013])
anno_inx = anno_inx[::-1]
anno_inx_add = anno_inx[:num_anno] # array([4988, 4974, 4973, 4956, 4949])
x_train_prc_anno = train_prc
y_train_anno = labelMat.reshape([-1, 1])
x_add = test_prc[anno_inx_add]
y_add = np.ones([num_anno, 1])*2
'''
array([[2.],
[2.],
[2.],
[2.],
[2.]])
'''
# 對異形進行過取樣
# for i in range(4000/num_anno):
for i in range(800):
x_train_prc_anno = np.append(x_train_prc_anno, x_add, axis=0)
y_train_anno = np.append(y_train_anno, y_add, axis=0)
x_train_prc_anno, y_train_anno = shuffle(x_train_prc_anno, y_train_anno, random_state=0)
mlb1 = MultiLabelBinarizer()
y_train_mlb = mlb1.fit_transform(y_train_anno)
return x_train_prc_anno, y_train_mlb, test_prc
8.3 資料增廣
在資料樣本較小時,我們也會進行資料增廣。那我們採用的時Keras中的圖片生成器ImageDataGenerator。

用以生成一個batch的影象資料,支援實時資料提升。訓練時該函式會無限生成資料,直到達到規定的epoch次數為止。
引數:


方法如下:

使用 .flow() 的例子
而本文中生成資料的程式碼如下(類似於上面):
datagen = ImageDataGenerator(
rotation_range=180, # 整數,資料提升時圖片隨機轉動的角度
width_shift_range=0.1, # 浮點數,圖片寬度的某個比例,資料提升時圖片水平便宜的幅度
height_shift_range=0.1, # 浮點數,圖片高度的某個比例,資料提升時圖片豎直偏移的幅度
horizontal_flip=True # 布林值,進行隨機水平翻轉
)
# 訓練模型的同時進行資料增廣
# flow(self, X, y batch_size=21, shuffle=True, seed=None,save_to_dir=None, save_prefix='' save_format='jpeg')
# 接收 numpy陣列和標籤為引數,生成經過資料提升或標準化後的batch資料,並在一個無線迴圈中不斷的返回 batch資料
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=len(x_train) / batch_size, epochs=epochs,
class_weight=class_weight,
validation_data=datagen.flow(x_train, y_train,
batch_size=batch_size),
validation_steps=1)
8.4 模型訓練
卷積神經網路(CNN)一般包括卷積層,池化層,全連線層,有時候為了防止過擬合,我們也會加入dropout層。
此程式碼為標杆模型的程式碼:
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras.optimizers import Adam
from keras import backend as K
from keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import statistics
from scipy import ndimage
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.utils import shuffle
SEED = 0
tf.random.set_random_seed(SEED)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1,
inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
def load_DateSet(TrainFile, TestFile):
traindata = pd.read_csv(TrainFile)
testdata = pd.read_csv(TestFile)
dataMat_origin, testMat_origin = np.array(traindata.drop('id', axis=1)), np.array(testdata.drop('id', axis=1))
dataMat, labelMat, testMat = dataMat_origin[:, 0:-1], dataMat_origin[:, -1], testMat_origin
# print(dataMat.shape, labelMat.shape, testMat.shape)
# 將矩陣轉化為(40, 40) 的格式
dataMat = np.array([np.reshape(i, (40, 40)) for i in dataMat])
testMat = np.array([np.reshape(i, (40, 40)) for i in testMat])
# return dataMat_origin, testMat_origin, dataMat, labelMat, testMat
return dataMat, labelMat, testMat
def my_preprocessing(I, show_fig=False):
# data = np.array([ndimage.median_filter(i, size=(3, 3)) for i in data])
# data = np.array([i > 10]*100 for i in data)
I_median = ndimage.median_filter(I, size=5)
mask = (I_median < statistics.mode(I_median.flatten()))
I_out = ndimage.morphology.binary_closing(mask, iterations=2)
if (np.mean(I_out[15:25, 15:25].flatten()) < 0.5):
I_out = 1 - I_out
if show_fig:
fig = plt.figure(figsize=(8, 4))
plt.gray()
plt.subplot(1, 4, 1)
plt.imshow(I) # 原圖
plt.axis('off')
plt.title('Image')
plt.subplot(1, 4, 2)
plt.imshow(I_median) # 中值濾波處理
plt.axis('off')
plt.title("Median filter")
plt.subplot(1, 4, 3)
plt.imshow(mask) # 新增掩膜
plt.axis('off')
plt.title('Mask')
plt.subplot(1, 4, 4)
plt.imshow(I_out) # 形態閉合處理
plt.axis('off')
plt.title('Closed mask')
fig.tight_layout()
plt.show()
return I_out
# return I_median
def batch_preprocessing(dataMat, labelMat, testMat):
train_prc = np.zeros_like(dataMat)
test_prc = np.zeros_like(testMat)
for i in range(dataMat.shape[0]):
train_prc[i] = my_preprocessing(dataMat[i])
for i in range(testMat.shape[0]):
test_prc[i] = my_preprocessing(testMat[i])
# print("over ...")
return train_prc, labelMat, test_prc
# 人工從測試集中挑選訓練集中並未出現過的標籤樣本,加入訓練集中
def add_other_sample_func(train_prc, labelMat, test_prc):
# 五個異形在原資料中對應的下標
# 手動檢視測試集中的影象,並且增加了五個異性,放入訓練集中
num_anno = 5
anno_inx = np.array([4949, 4956, 4973, 4974, 4988])
anno_inx = anno_inx[::-1]
anno_inx_add = anno_inx[:num_anno] # array([4988, 4974, 4973, 4956, 4949])
x_train_prc_anno = train_prc
y_train_anno = labelMat.reshape([-1, 1])
x_add = test_prc[anno_inx_add]
y_add = np.ones([num_anno, 1])*2
# 對異形進行過取樣
# for i in range(4000/num_anno):
for i in range(800):
x_train_prc_anno = np.append(x_train_prc_anno, x_add, axis=0)
y_train_anno = np.append(y_train_anno, y_add, axis=0)
x_train_prc_anno, y_train_anno = shuffle(x_train_prc_anno, y_train_anno, random_state=0)
mlb1 = MultiLabelBinarizer()
y_train_mlb = mlb1.fit_transform(y_train_anno)
return x_train_prc_anno, y_train_mlb, test_prc
def built_model():
n_filter = 32
# 序貫模型是多個網路層的線性堆疊,也就是“一條道走到黑”
model = Sequential()
# 通過 .add() 方法一個個的將 layer加入模型中
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
# final layer using softmax
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0003),
metrics=['accuracy'])
model.summary()
return model
def train_model(x_train, y_train, x_test, batch_size=64, epochs=20, model=None,
class_weight={0: 1., 1: 1., 2: 10.}):
if np.ndim(x_train) < 4:
x_train = np.expand_dims(x_train, 3)
x_test = np.expand_dims(x_test, 3)
if model is None:
model = built_model()
datagen = ImageDataGenerator(
rotation_range=180, # 整數,資料提升時圖片隨機轉動的角度
width_shift_range=0.1, # 浮點數,圖片寬度的某個比例,資料提升時圖片水平便宜的幅度
height_shift_range=0.1, # 浮點數,圖片高度的某個比例,資料提升時圖片豎直偏移的幅度
horizontal_flip=True # 布林值,進行隨機水平翻轉
)
# 訓練模型的同時進行資料增廣
# flow(self, X, y batch_size=21, shuffle=True, seed=None,save_to_dir=None, save_prefix='' save_format='jpeg')
# 接收 numpy陣列和標籤為引數,生成經過資料提升或標準化後的batch資料,並在一個無線迴圈中不斷的返回 batch資料
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=len(x_train) / batch_size, epochs=epochs,
class_weight=class_weight,
validation_data=datagen.flow(x_train, y_train,
batch_size=batch_size),
validation_steps=1)
print("Loss on training and testing")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
pred_prob_train = model.predict(x_train, batch_size=batch_size, verbose=1)
pred_train = np.array(pred_prob_train > 0.5).astype(int)
pred_prob_test = model.predict(x_test, batch_size=batch_size, verbose=1)
pred_test = np.array(pred_prob_test > 0.5).astype(int)
y_test_hat = pred_test[:, 1] + pred_test[:, 2] * 2
y_train_hat = pred_train[:, 1] + pred_train[:, 2] * 2
return y_train_hat, y_test_hat, history
if __name__ == '__main__':
trainFile = 'dataout/train.csv'
testFile = 'dataout/test.csv'
submitfile = 'dataout/sample_submit.csv'
epochs = 100
# 考慮到異性並不多,所以設定如下權重,來解決非平衡下的分類
class_weight = {0: 1., 1: 1., 2: 10.}
dataMat, labelMat, testMat = load_DateSet(trainFile, testFile)
# 資料預處理
# I_out = my_preprocessing(testMat[5], True)
train_prc, labelMat, test_prc = batch_preprocessing(dataMat, labelMat, testMat)
x_train_prc_anno, y_train_mlb, test_prc = add_other_sample_func(train_prc, labelMat, test_prc)
y_train_hat, y_test_hat, hisory = train_model(x_train_prc_anno, y_train_mlb, test_prc,
epochs=epochs, batch_size=64, class_weight=class_weight)
# 提交結果,檢視精度
submit = pd.read_csv(submitfile)
submit['y'] = y_test_hat
submit.to_csv('my_cnn_prediction3.csv', index=False)
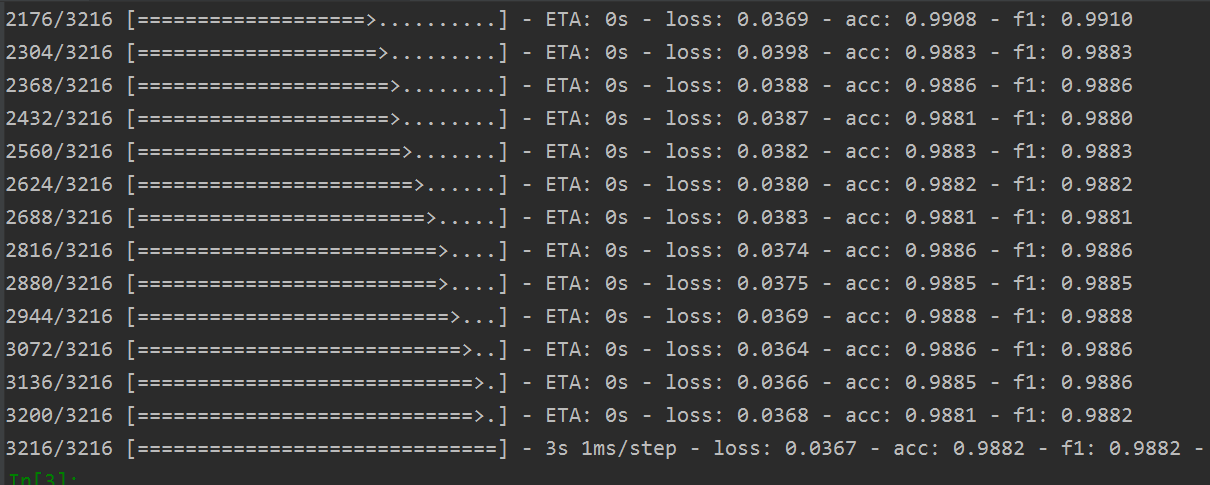
損失函式在訓練和驗證集的變化如下:
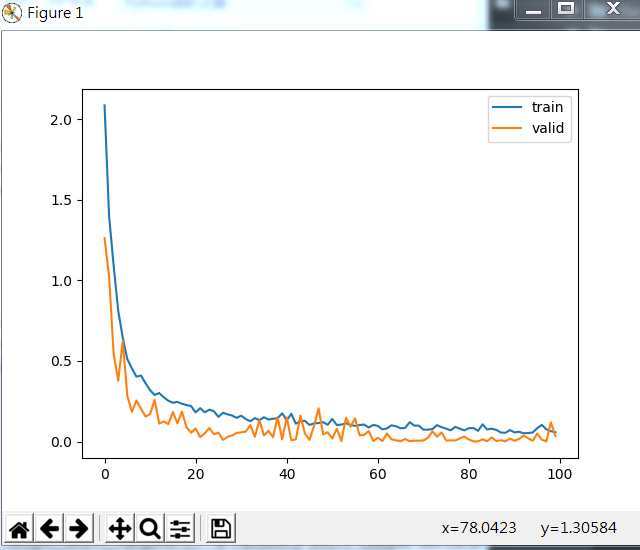
其訓練結果如下: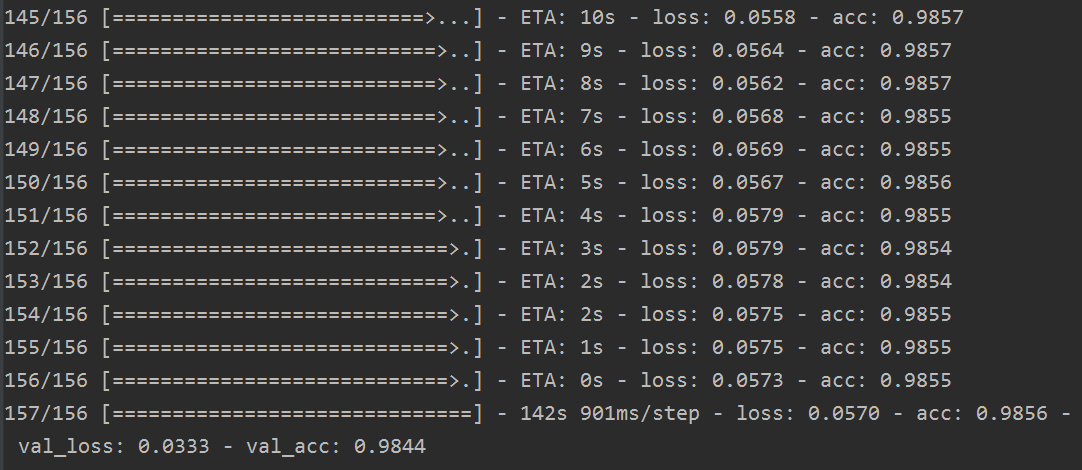
其程式碼的結果為:

再跑一邊,提交的結果是:

看來模型訓練這塊是有點玄學問題哈。
我將標杆模型中的增強資料改為我增加的五個異形,損失函式在訓練和驗證集的變化如下:
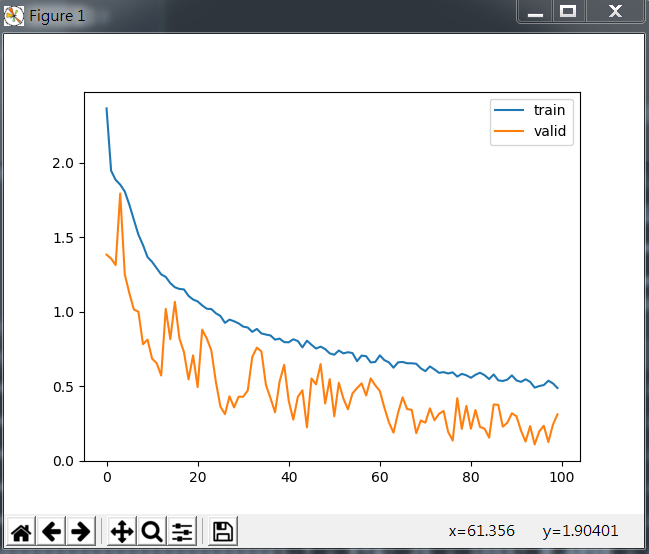
其訓練結果如下:
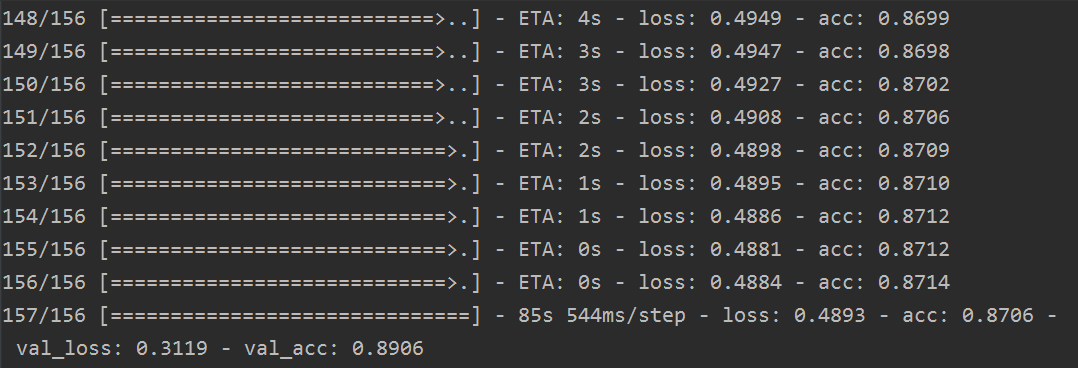
提交的結果如下:

從結果來看,效果不是很好,按理說,明明是異形資料的擴增,為什麼效果反而不好呢?我仔細找了一下原因,發現 [4000, 4001, 4004, 4010, 4013] 的圖片如下:

根本就不是異形,真的是我的失誤。
下面我將 0,1, 4, 10, 13 的圖片展示如下(這個才是我找出來的異形):

下面將這幾個異形重寫寫入,進行程式碼訓練,其損失函式在驗證集合測試集的變化如下:
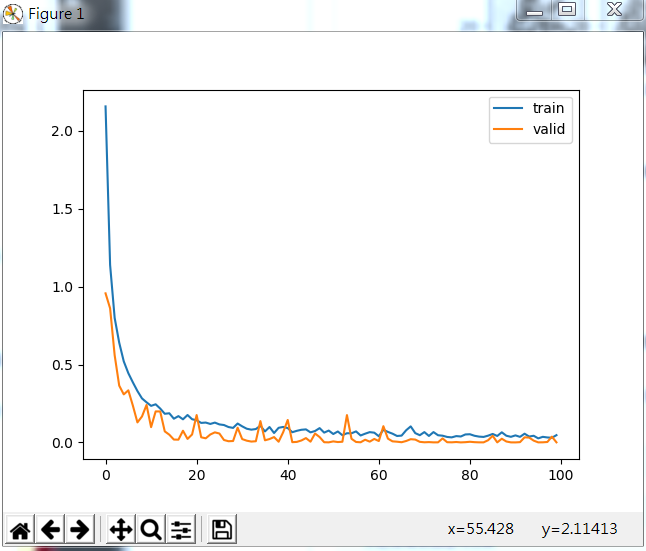
部分訓練結果如下:
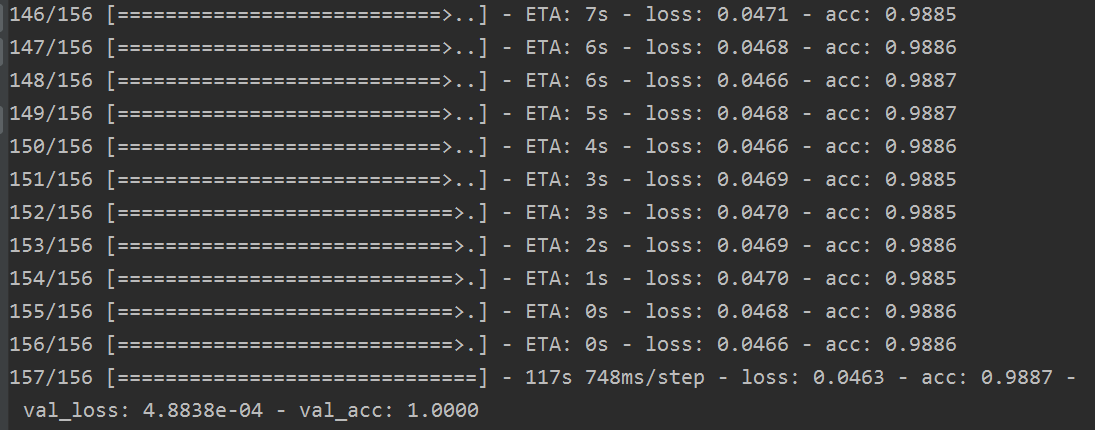
這時候提交的結果還沒下來,但是單從loss和acc上,我感覺比標杆模型的結果好點。
結果如下:

果然,增強了,可以可以。
我將異形樣本增強,增加到10個,也就是將原標杆的異形和我找的異形合併,增加異形樣本量,再對資料進行擴增,看看效果。這裡程式碼我在原始碼基礎上修改了,這裡不再貼程式碼了。
直接看訓練集和測試集的損失圖:
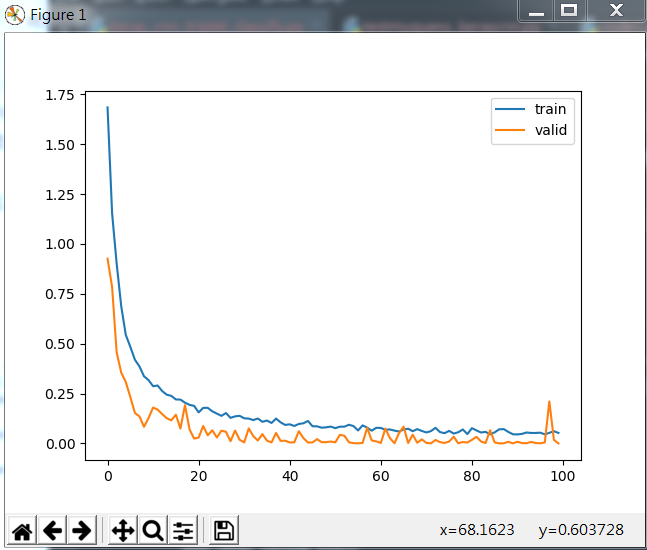
部分訓練結果:
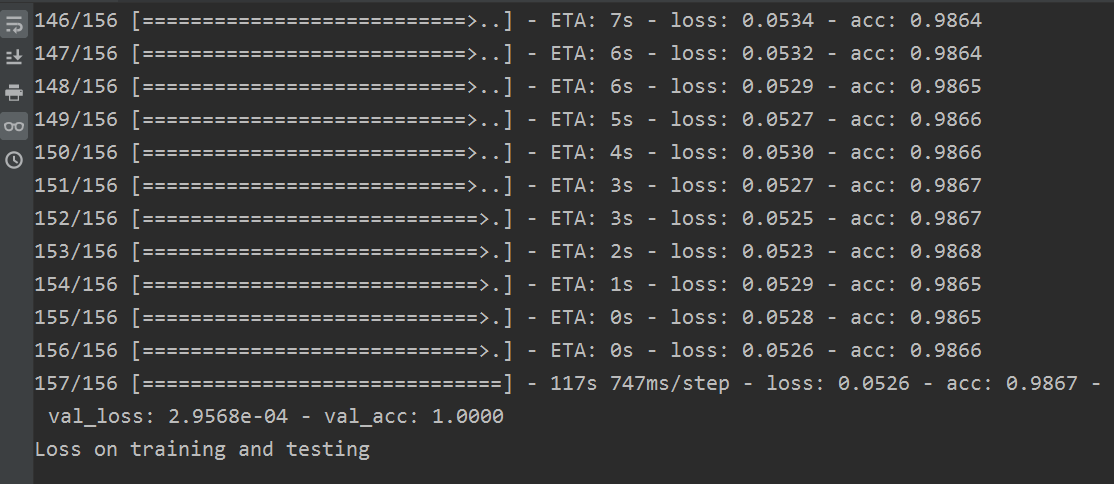
結果如下:

都第二名了,試試衝一下第一名。那麼提高的的方面肯定有幾個方面:
- 1就是增加資料預處理的方式,使得特徵更加明顯,但是這種我還沒有想出來更好的
- 2就是給修改模型,增加捲積層,或者使用VGG,ResNet等網路,但是這種網路太大了,我也就不試了。
- 3,就是做三分類的時候,增加異常樣本,我再試著加10個異常樣本吧。
從上面繼續,21開始: 23 27


2444

2524 2533 2554
4413 4533
2938
936
隨機找了10個。分別是:
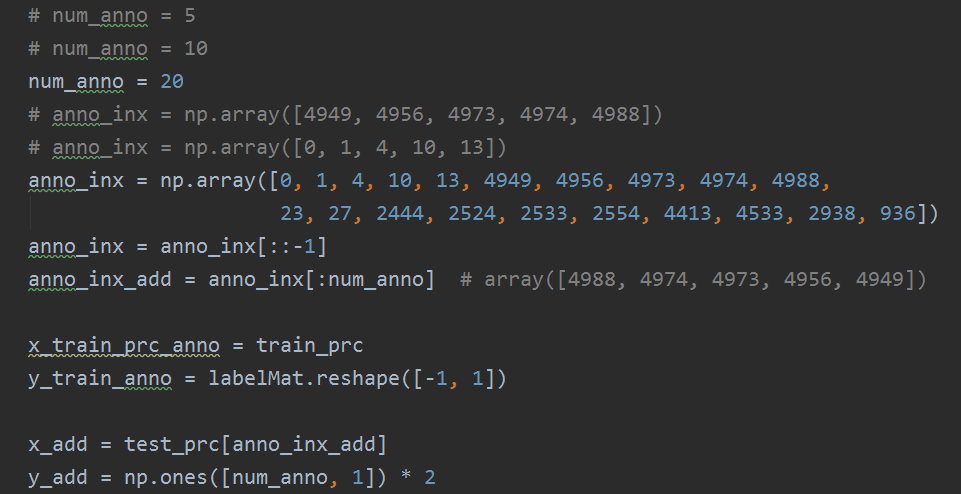

訓練集和測試集的損失圖如下:
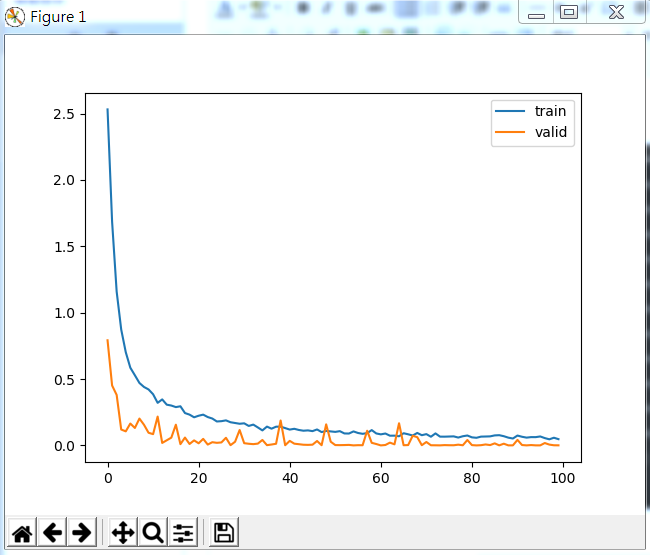
部分訓練過程如下:
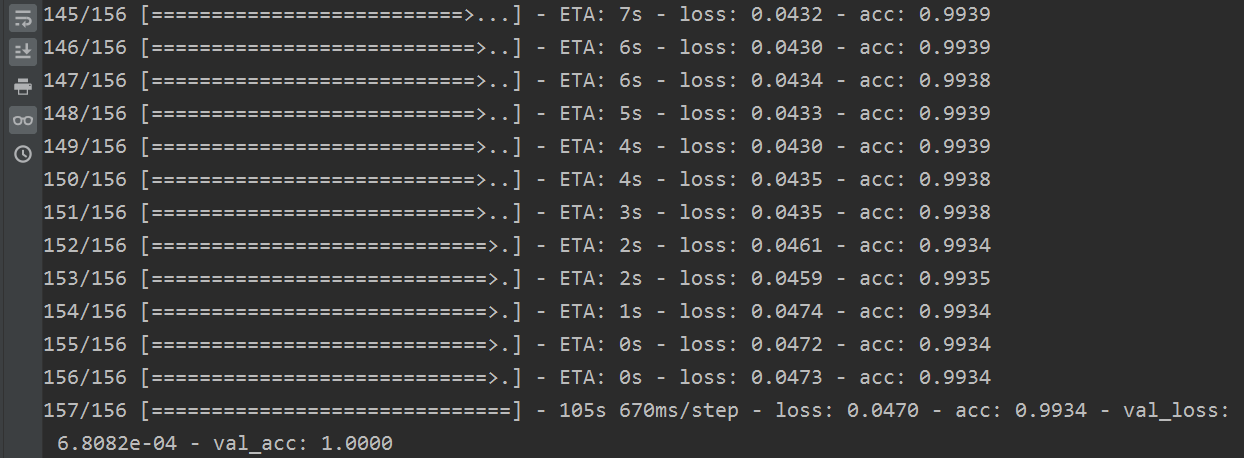
結果如下:

準確率確實有所提高,如果還想再提高,當然可以對模型進行修改,這裡就不做了,掌握了方法就不再浪費時間了。
完整程式碼,請移步小編的GitHub
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/sofasofa-learn
&n