
奇思妙想-java實現另類的pipeline模式
阿新 • • 發佈:2020-03-22
---
# 磕叨
在公司做專案是見到前輩們寫的一段任務鏈的程式碼,大概如下
```
Runnable task = new TaskA(new TaskB(new TaskC(new taskD())));
task.run();
```
taskA執行run呼叫並完成TaskA宣告的任務邏輯之後,內部會自動呼叫構造引數傳入的TaskB的run方法,過程類似TaskA,TaskB完成之後一樣會呼叫引數傳入的task,直到最後一個沒有帶下一個task類傳入的任務完成,即完成一個管道式呼叫。
愛思考的我在想,可用,不好用重用,於是動手改改。
---
# 準備
經過一段時間開發後,有了一個常用的工具類,方便快速開發,但是這裡用到的東西很少,還是要說明一下,這裡用到一個我稱作ecommon的包,當然我只用了兩個很基礎的額部分。這兩個部分完全可以用你自己的實現,是非常簡單的。
- 函式介面
jdk8之後很方便讓我們寫出lambda,但是我覺得理解起來不直觀,於是自己重寫了 12 個介面,按引數個數和返回型別可以直接根據函式名直接選出你要的。具體在 https://github.com/kimffy24/EJoker/tree/dev/ejoker-common/src/main/java/pro/jiefzz/ejoker/common/system/functional , IVoid打頭的就是無返回的,後面的數字就是要帶多少個引數,引數和返回型別全部都是泛型。1-6個引數已經能包括大部分情況了,需要更多引數的情況完全可以自定義一個上下文傳遞過去。
- 字串填充類
類似`String.format`,但是我不用正則,而是類似slf4j那種,`log.info("This is a template, keyA={}, keyB={}", "valueA", "valueB")` , 類似這種佔位填充。我的實現在 https://github.com/kimffy24/EJoker/blob/dev/ejoker-common/src/main/java/pro/jiefzz/ejoker/common/system/helper/StringHelper.java 的fill方法中。你也可以用 `String.format` 代替。
# 思路簡述
我們先明確,jdk8以下的情況不作考慮。
pipeline我更多的印象是來自終端上的應用

pipeline是單向的,上個task的輸出作為下個task的輸入,直到沒有下一個task,最後一個task的作用就應該是你期望的。且`後續任務只關心前者的輸出結果,對於的他是誰,怎麼做的,是不關心的`。記為 `Point1`
這個特點是我視為管道與切面或職責鏈模式的區別所在。
首先,我們得有第一推動,讓管道流能有個開始,再就是有中間task,他必定是能接收到上一個任務的輸出的,並且,可能有自帶引數,並且有自己的輸出,最後,有latest的task 與中間task區別在於他不用返回了,latest一般是以副作用的形式實現我們的企圖的,如上圖的 `wc -l` 作為最後一個任務是直接把結果列印到螢幕上,而不是返回一個變數給我們讀取。根據java的強型別屬性,以及剛剛一段的分析,可以得知,有3種類型的任務,開始任務,中間任務,最後任務,並且中間任務的個數是不限的,所有任務至於相鄰的任務有一個關聯點,那就是 ` 前者的輸出型別與後者的輸入型別一致 ` (網文中大部分說自己實現的pipeline的模式都是傳遞Object型別,到各個子任務中自己強轉到需要的型別的,不說好與不好,但我肯定不喜歡)。這個特性記為 `Point2`。
而且,每個子任務,本身是可以帶引數的,這是一個需要支援的點。像上圖命令中的管道,每個子命令(除第一個)都是同時接受前一個命令的輸出作為輸入,且自帶引數的。但是java在這裡其實並不靈活,因此我們約定 `後續任務的第一個引數就是前一個任務的輸入` , 這個約定是直接影響到我們的程式碼實現的。這個特性記為 `Point3`。
另外,管道的入口唯一的,一定是從開始任務往後流的。如果入口不一樣,那麼就是像個不同的管道,他們的意圖以及輸入輸出的期望都是不同的。這個特性記為 `Point4`。
最後,在java中使用,我肯定不能像終端那種,錯了重敲命令就是了,所以需要異常控制以及做一些相鄰任務承上啟下的時刻做點什麼,例如日子列印,斷言等。這個算附加題。
# 提起鍵盤擼
(因為我已經寫完並測試完了,所以我就反過來解析我是怎麼想的了)
這裡以Runnable介面作為基礎介面。給出其中一個測試的例子
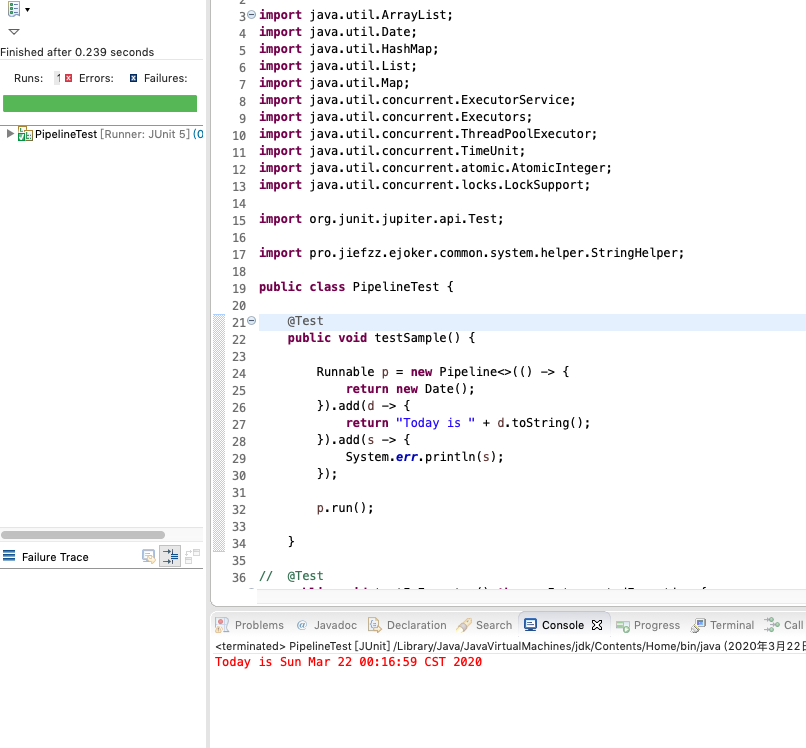
這裡初始任務是給出一個日期,中間任務是拼接成人類友好的1句話,最終任務是直接列印到螢幕。(現實中要實現這樣一句話,當然是直接擼啦。這裡只是為了演示),看看Pipeline初始任務的定義
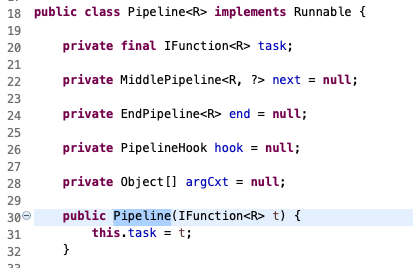
先不看其他屬性,看構造方法,傳入一個 `IFunction` ,按照準備一節的定義,他是一個返回型別為宣告泛型R,且無引數輸入的閉包函式(或稱作lambda表示式)。對照上面PipelineTest中就是那個 `() -> { return new Date(); }` , (得益於jdk8的型別推斷,在 `new Pipeline<>` 構造時,不用再宣告其泛型,編譯器能根據閉包函式的return型別推斷出這裡是個Date型別)。`next`, `end` 是指明管道的下接任務,這可以看出管道是極其類似於任務鏈/職責鏈的(需要注意`next`和`end`同時`只能有個一個存在`)。hook是異常管理以及任務間承接時做一個切面方法的,argCxt是記下傳遞引數,方便hook中的方法使用(這個是因為java需要的,跟管道模式並沒有關係)。
再看add方法的一個過載,新增並返回中間task

add方法傳入一個`IFunction1`的閉包(lambda),尾數為1,意味著接受一個 `R` 型別的輸入,並在方法升聲明瞭 `RT` ,以 `RT` 型別作為輸出。其中 `R` 的泛型宣告在類上,就是與構造方法的 `R` 是同一個型別。而 `RT` 的具體型別的推斷會根據具體的lambda的返回型別決定。這裡add方法會返回剛剛構造出來的中間任務的宣告物件。add方法需要保證當前任務是沒被宣告過後續任務的。
再看MiddlePipeline類的定義
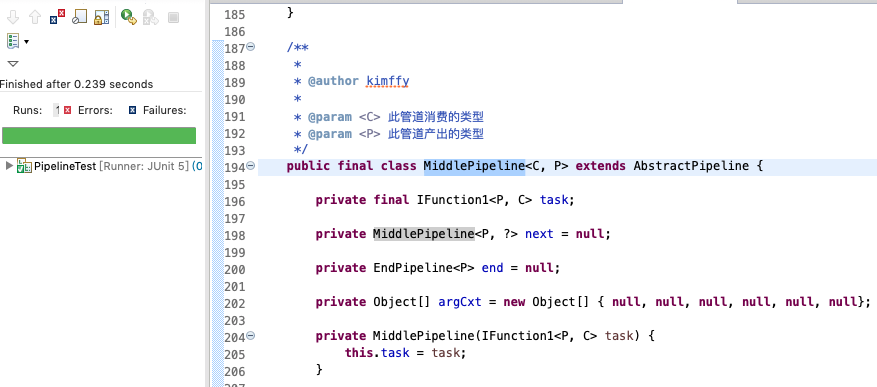
先看構造方法,他就是接受add方法傳入的閉包。他聲明瞭兩個泛型變數 分別是 ``,其中 `C`代表他的輸入型別, `P`代表的他的產出型別。同初始任務一樣,他也有`next` 和 `end` 指明他的管道後接任務(`next`)。可以注意到這裡的 `next` 和初始任務的屬性 `next` 的產出型別都是被放上了泛型萬用字元 `?` ,是因為任務並沒辦法知道他的子任務的產出型別的(後面會再說一下這個問題)。
再看add方法的一個另一個過載,新增並返回最終task

類似返回中間態的task,只不過這裡用了無返回的閉包。
再看EndPipeline類的定義

最終task的定義清爽很多,他只關心輸入,並執行。並且他沒有後續任務。
再來補充下AbstractPipeline的解析

這個寫法是為了實現`Point4`所描述的事的,只要是同一個pipeline上的task所有入口都是初始任務上的那個`run`方法。(為了省事實現,後續任務的基類和所有派生類都是初始任務的非靜態內部類)
再看看初版版本run方法
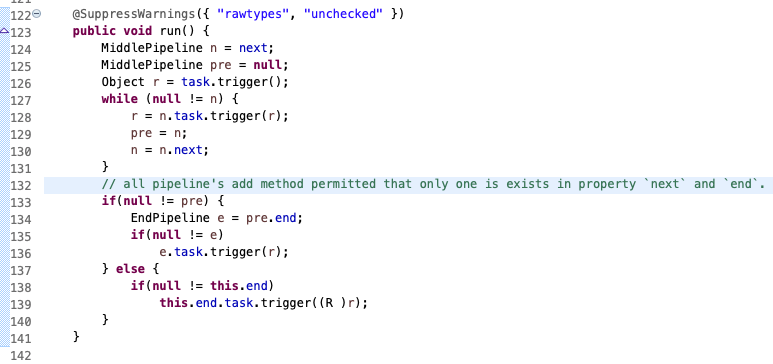
邏輯很簡單,執行初始任務,得到結果,然後找後續任務,把結果作為輸入來執行後續任務,(其中迴圈時滿足上一個輸出作為下一個輸入),直到有一個管道類的中間態任務為`null`,然後判斷最終任務是否為`null` ,非空則執行它。
需要說明一下這裡用 `@SuppressWarnings` 壓制了警告,是因為確信java編譯器能確保連續兩個add進來的task之間的輸入輸出的型別關係是一致的(這一點,如果不一致,在編寫程式碼時IDE就會報錯了)。
到此,一個簡單的java實現的pipeline模式基本可以用,跑最開始那個demoTest是沒有問題了。
再給一個樣例demo
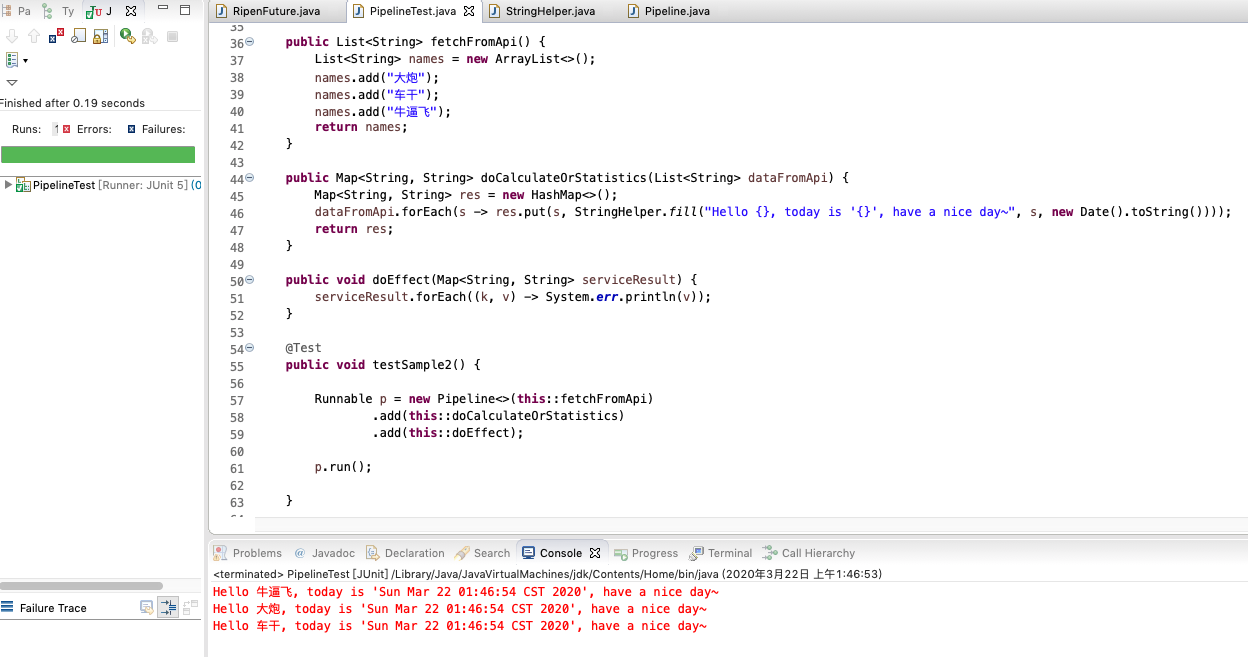
管道中的3個方法的職責就如他的名字那樣(實現上我這裡只是簡單的new一下),然後同過Pipeline類以及它的add方法串起來,執行結果如紅色部分。聰明的人肯定能想到,那麼像那個java的stream的?嗯很像,stream是類似把元素放到單個跑到上,按照定義那樣的自己跑到終點(這也是使用方程式碼方便地切換到並行流的原因,因為邏輯一致,當然,併發問題是另一個層面的問題)。
而pipeline則橫向的一階段一階段地執行,如果要增加吞吐量怎麼搞?聰明的你肯定能想到分片了,這樣走下去就跟parallelstream的意圖不謀而合了。那麼還有別的好處嗎?嗯,你想想Mock測試?職責上有沒有讓你更好切分了(正如這裡命令的方法名那這樣)?
---
# 進一步完善
上面一節基本上能把 `Point1` 、 `Point2`的一半 、 `Point3` 、 `Point4` 實現了,剩下 `Point2`中說到的,除了接收前一個任務的輸入,還允許管道宣告時傳入引數的這個功能,以及那個附加題說到的java應用上的妥協。
### pipeline宣告上附帶引數
這個時候就要好好用到 `準備` 一節中的那些 `函式介面` 了。說起來並不好解析,但是如果你瞭解過curry柯里化這個概念的話,那一看圖你就懂了,看圖。
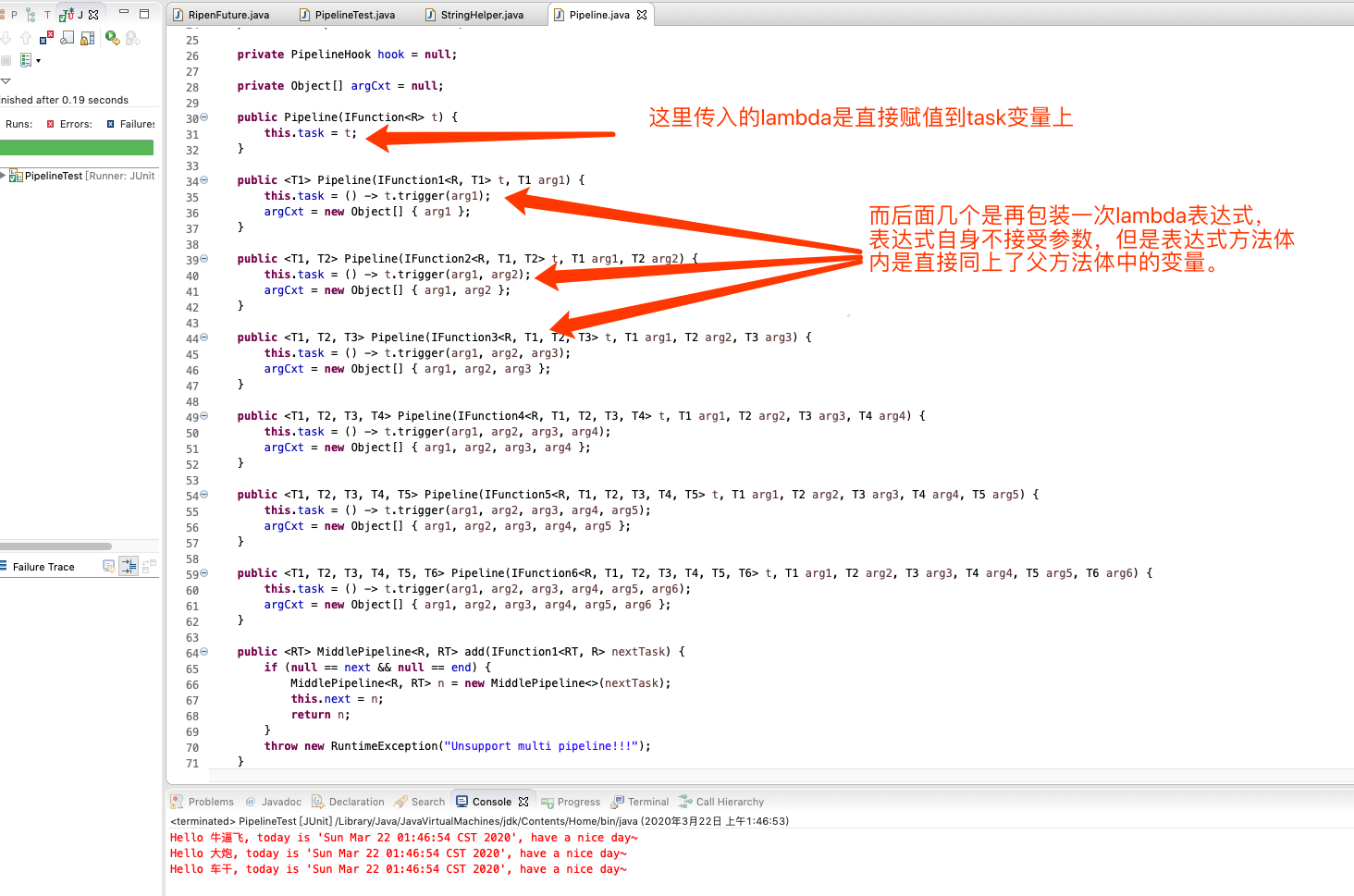
就是把帶引數的lambda重新包裝一次為不帶引數的lambda表示式。後面middlePipeline的帶引數部分則是重新封裝為一個只接受一個引數且返回型別相同的lambda表示式,這是類似的。
來一個測試看看,並附上圖中說明
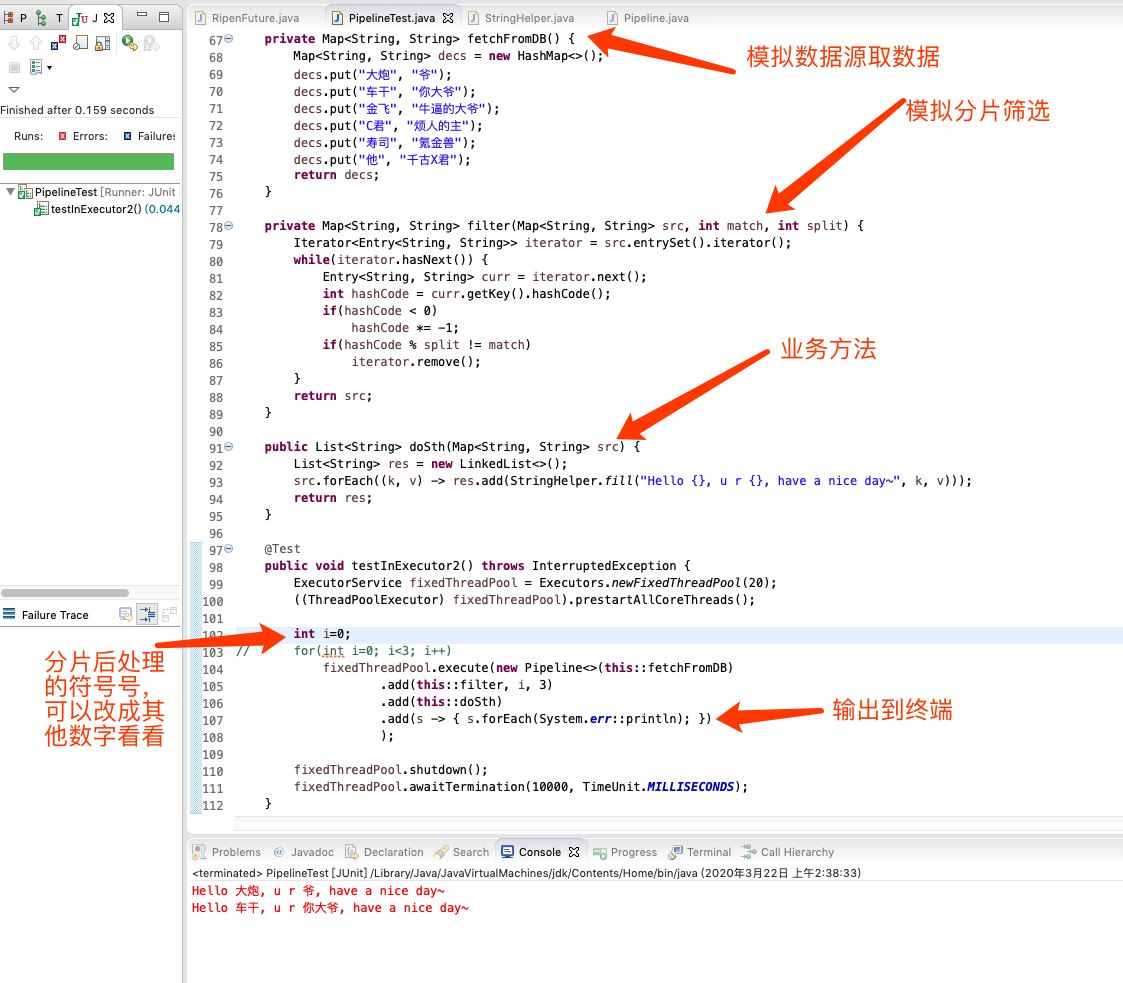
### 對java友好支援
附加題說的這個就跟簡單了,找個地方分別設定好兩個玩意,在對應的地方執行他們就是了
```
public class PipelineHook {
private boolean preventThrow = false;
// 異常發生時執行此表示式
public final IVoidFunction3 exceptionHandler;
// 呼叫後續任務錢執行此lambda表示式
public final IVoidFunction1