
Python線性資料結構
目錄
- 1 線性資料結構
- 2.內建常用的資料型別
- 2.1 數值型
- 2.2 序列(sequence)
- 2.2.1 list 列表
- 2.2.2 tuple 元組
- 2.2.3 string 字串
- 2.2.4 bytes 位元組
- 2.2.5 bytearray 位元組陣列
python線性資料結構
<center>碼好python的每一篇文章.</center>

1 線性資料結構
本章要介紹的線性結構:list、tuple、string、bytes、bytearray。
線性表:是一種抽象的數學概念,是一組元素的序列的抽象,由有窮個元素組成(0個或任意個)。
線性表又可分為 順序表和連結表。
順序表:一組元素在記憶體中有序的儲存。列表list就是典型的順序表。
連結表:一組元素在記憶體中分散儲存連結起來,彼此知道連線的是誰。
對於這兩種表,陣列中的元素進行查詢、增加、刪除、修改,看看有什麼影響:
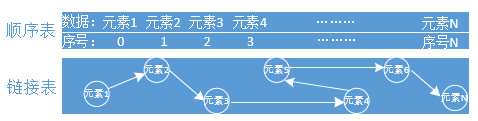
查詢元素
對於順序表,是有序的在記憶體中儲存資料,可快速通過索引編號獲取元素,效率高。。
對於連結表是分散儲存的,只能通過一個個去迭代獲取元素,效率差。
增加元素
對於順序表,如果是在末尾增加元素,對於整個資料表來說沒什麼影響,但是在開頭或是中間插入元素,後面的所有元素都要重新排序,影響很大(想想數百萬或更大資料量)。
對於連結表,不管在哪裡加入元素,不會影響其他元素,影響小。
刪除元素
對於順序表,刪除元素和增加元素有著一樣的問題。
對於連結表,不管在哪裡刪除元素,不會影響其他元素,影響小。修改元素
對於順序表,可快速通過索引獲取元素然後進行修改,效率高。對於連結表,只能通過迭代獲取元素然後進行修改,效率低。
總結:順序表對於查詢與修改效率最高,增加和刪除效率低。連結表則相反。
2.內建常用的資料型別
2.1 數值型
int 整數型別
說明:整數包括負整數、0、正整數(... -2,-1,0,1,2, ...)。
x1 = 1 x2 = 0 x3 = -1 print(type(x1), x1) print(type(x2), x2) print(type(x3), x3) # 輸出結果如下: <class 'int'> 1 <class 'int'> 0 <class 'int'> -1int( )方法:可以將數字或字串轉為整數,預設base=10,表示10進位制,無引數傳入則返回0。
x1 = int() x2 = int('1') x3 = int('0b10',base=2) #base=2,表二進位制,與傳入引數型別一致。 x4 = int(3.14) print(type(x1), x1) print(type(x2), x2) print(type(x3), x3) print(type(x4), x4) # 輸出結果如下: <class 'int'> 0 <class 'int'> 1 <class 'int'> 2 <class 'int'> 3float 浮點型別
說明:由整數和小數部分組成,傳入的引數可以為int、str、bytes、bytearray。x1 = float(1) x2 = float('2') x3 = float(b'3') print(type(x1), x1) print(type(x2), x2) print(type(x3), x3) # 輸出結果如下: <class 'float'> 1.0 <class 'float'> 2.0 <class 'float'> 3.0complex (複數型別)
說明:由實數和虛數部分組成,都是浮點數。
傳入引數可以為
int、str,如果傳入兩參,前面一個為實數部分,後一個引數為虛數部分。x1 = complex(1) x2 = complex(2,2) x3 = complex('3') print(type(x1), x1) print(type(x2), x2) print(type(x3), x3) # 輸出結果如下: <class 'complex'> (1+0j) <class 'complex'> (2+2j) <class 'complex'> (3+0j)bool (布林型別)
說明:為int的子類,返回的是True和False,對應的是1和0。
x1 = bool(0) x2 = bool(1) x3 = bool() x4 = 2 > 1 print(type(x1), x1) print(type(x2), x2) print(type(x3), x3) print(type(x4), x4) # 輸出結果如下: <class 'bool'> False <class 'bool'> True <class 'bool'> False <class 'bool'> True
2.2 序列(sequence)
2.2.1 list 列表
說明: 列表是由若干元素物件組成,且是有序可變的線性資料結構,使用中括號[ ]表示。
初始化
lst = [] # 空列表方式1 #或者 lst = list() # 空列表方式2 print(type(lst),lst) # 輸入結果如下: <class 'list'> []索引
說明: 使用正索引(從左至右)、負索引(從右至左)訪問元素,時間複雜度為
O(1),效率極高的使用方式。按照給定區間獲取到資料,叫做切片。
正索引:
從左至右,從0開始索引,區間為[0,長度-1],左包右不包。
lst = ['a','b','c','d'] print(lst[0]) # 獲取第一個元素 print(lst[1:2]) # 獲取第二個元素,左包右不包,切片 print(lst[2:]) # 獲取第三個元素到最後一個元素,切片 print(lst[:]) # 獲取所有元素,切片 # 輸出結果如下: a ['c'] ['c', 'd'] ['a', 'b', 'c', 'd']負索引:
從右至左,從-1開始索引,區間為[-長度,-1]
lst = ['a','b','c','d'] print(lst[-1]) print(lst[-2:]) # 輸出結果如下: d ['c', 'd']查詢
index( )方法:
L.index(value, [start, [stop]]) -> integer返回的是索引id,要迭代列表,時間複雜度為O(n)。
lst = ['a','b','c','d'] print(lst.index('a',0,4)) # 獲取區間[0,4]的元素'a'的索引id # 輸出結果如下: 0備註:如果查詢不到元素,則丟擲
ValueError。count( ) 方法:L.count(value) -> integer
返回的是元素出現的次數,要迭代列表,時間複雜度為O(n)。
lst = ['a','b','a','b'] print(lst.count('a')) # 輸出結果如下: 2len( ) 方法:返回的是列表元素的個數,時間複雜度為O(1)。
lst = ['a','b','c','d'] print(len(lst)) # 輸出結果如下: 4備註:所謂的O(n) 是指隨著資料的規模越來越大,效率下降,而O(1)則相反,不會隨著資料規模大而影響效率。
修改
列表是有序可變,所以能夠對列表中的元素進行修改。
lst = ['a','b','c','d'] lst[0] = 'A' print(lst) # 輸出結果如下: ['A', 'b', 'c', 'd']增加
append( ) 方法:
L.append(object) -> None尾部追加元素,就地修改,返回None。
lst = ['a','b','c','d'] lst.append('e') print(lst) # 輸出結果如下: ['a', 'b', 'c', 'd', 'e']insert( )方法:
L.insert(index, object) -> None,在指定索引位置插入元素物件,返回None。
lst = ['a','b','c','d'] lst.insert(0,'A') # 在索引0位置插入'A',原有的元素全部往後移,增加了複雜度 print(lst) # 輸出結果如下: ['A', 'a', 'b', 'c', 'd']extend( )方法:
L.extend(iterable) -> None可以增加多個元素,將可迭代物件的元素追加進去,返回None。
lst = ['a','b','c','d'] lst.extend([1,2,3]) print(lst) # 輸出結果如下: ['a', 'b', 'c', 'd', 1, 2, 3]還可以將列表通過
+和*,拼接成新的列表。lst1 = ['a','b','c','d'] lst2 = ['e','f','g'] print(lst1 + lst2) print(lst1 * 2) # 將列表裡面的元素各複製2份 # 輸出結果如下: ['a', 'b', 'c', 'd', 'e', 'f', 'g'] ['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd']這裡還有一個特別要注意情況如下:
lst1 = [[1]] * 3 # 結果:[[1], [1], [1]] print(lst1) lst1[0][0] = 10 # 結果:[[10], [1], [1]],是這樣嘛?? print(lst1) # 輸出結果如下: [[1], [1], [1]] [[10], [10], [10]] # 為什麼結果會是這個?請往下看列表複製章節,找答案!刪除
remove()方法:
L.remove(value) -> None從左至右遍歷查詢,找到就刪除該元素,返回None,找不到則丟擲
ValueError。lst = ['a','b','c','d'] lst.remove('d') print(lst) # 輸出結果如下: ['a', 'b', 'c'] # 元素'd'已經被刪除pop() 方法:
L.pop([index]) -> item預設刪除尾部元素,可指定索引刪除元素,索引越界丟擲
IndexError。lst = ['a','b','c','d'] lst.pop() print(lst) # 輸出結果如下: ['a', 'b', 'c']clear() 方法:
L.clear() -> None清空列表所有元素,慎用。
lst = ['a','b','c','d'] lst.clear() print(lst) # 輸出結果如下: [] # 空列表了反轉
reverse( ) 方法:
L.reverse()將列表中的元素反轉,返回None。
lst = ['a','b','c','d'] lst.reverse() print(lst) # 輸出結果如下: ['d', 'c', 'b', 'a']排序
sort() 方法:
L.sort(key=None, reverse=False) -> None對列表元素進行排序,預設為升序,reverse=True為降序。
lst = ['a','b','c','d'] lst.sort(reverse=True) print(lst) # 輸出結果如下: ['d', 'c', 'b', 'a']in成員操作
判斷成員是否在列表裡面,有則返回True、無則返回False。
lst = ['a','b','c','d'] print('a' in lst) print('e' in lst) # 輸出結果如下: True False列表複製
說明: 列表複製指的是列表元素的複製,可分為淺copy和深copy兩種。列表元素物件如列表、元組、字典、類、例項這些歸為引用型別(指向記憶體地址),而數字、字串先歸為簡單型別,好讓大家理解。
示例一:這是屬於拷貝嘛?
lst1 = [1,[2,3],4] lst2 = lst1 print(id(lst1),id(lst2),lst1 == lst2, lst2) # id() 檢視記憶體地址 # 輸出結果如下: 1593751168840 1593751168840 True [1, [2, 3], 4]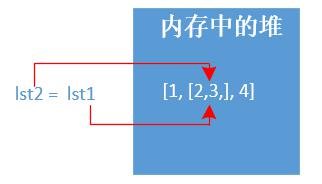
顯然不是屬於任何copy,說白了都是指向同一個記憶體地址。
示例二:淺拷貝copy
說明: 淺拷貝對於
引用型別物件是不會copy的,地址指向仍是一樣。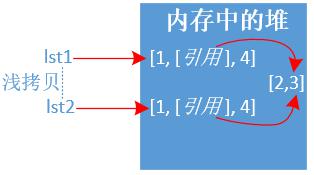
lst1 = [1,[2,3],4] lst2 = lst1.copy() print(id(lst1),id(lst2),lst1 == lst2, lst2) print('=' * 30) lst1[1][0] = 200 # 修改列表的引用型別,所有列表都會改變 print(lst1, lst2) # 輸出結果如下: 1922175854408 1922175854344 True [1, [2, 3], 4] ============================== [1, [200, 3], 4] [1, [200, 3], 4]示例三:深拷貝deepcopy
說明: 深拷貝對於
引用型別物件也會copy成另外一份,地址指向不一樣。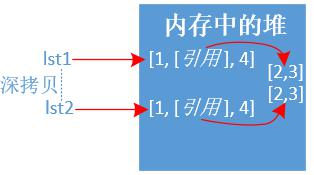
import copy lst1 = [1,[2,3],4] lst2 = copy.deepcopy(lst1) print(id(lst1),id(lst2),lst1 == lst2, lst2) print('=' * 30) lst1[1][0] = 200 # 修改列表的引用型別,不會影響其他列表 print(lst1, lst2) # 輸出結果如下: 2378580158344 2378580158280 True [1, [2, 3], 4] ============================== [1, [200, 3], 4] [1, [2, 3], 4]
2.2.2 tuple 元組
說明: 元組是由若干元素物件組成,且是有序不可變的資料結構,使用小括號( )表示。
初始化
t1 = () # 空元素方式1,一旦建立將不可改變 t2 = tuple() # 空元素方式2,一旦建立將不可改變 t3 = ('a',) # 元組只有一個元素,一定要加逗號',' t4 = (['a','b','c']) # 空列表方式2備註: 元組如果只有一個元素物件,一定要在後面加逗號
,否則變為其他資料型別。索引
同列表一樣,不再過多舉例。t = ('a','b','c','d') print(t[0]) print(t[-1]) # 輸出結果如下: a d查詢
同列表一樣,不再過多舉例。
t = ('a','b','c','d') print(t.index('a')) print(t.count('a')) print(len(t)) # 輸出結果如下: 0 1 4增刪改
元組是
不可變型別,不能增刪改元素物件。但是要注意如下場景:
元組中的元素物件(記憶體地址)不可變,引用型別可變。----這裡又出現引用型別的情況了。
# 元組的元組不可修改(即記憶體地址) t = ([1],) t[0]= 100 print(t) # 結果報錯了 TypeError: 'tuple' object does not support item assignment ############################################ # 元組裡面的引用型別物件可以修改(如嵌套了列表) t = ([1],2,3) t[0][0] = 100 # 對元組引用型別物件的元素作修改 print(t) # 輸出結果如下: ([100], 2, 3)
2.2.3 string 字串
說明: 字串是由若干字元組成,且是有序不可變的資料結構,使用引號表示。
初始化
多種花樣,使用單引號、雙引號、三引號等。name = 'tom' age = 18 str1 = 'abc' # 單引號字串 str2 = "abc" # 雙引號字串 str3 = """I'm python""" # 三引號字串 str4 = r"c:\windows\note" # r字首,沒有轉義(轉義字元不生效) str5 = f'{name} is {age} age.' # f字首,字串格式化,v3.6支援 print(type(str1), str1) print(type(str2), str2) print(type(str3), str3) print(type(str4), str4) print(type(str5), str5) # 輸出結果如下: <class 'str'> abc <class 'str'> abc <class 'str'> I'm python <class 'str'> c:\windows\note <class 'str'> tom is 18 age.索引
同列表一樣,不再過多舉例。
str = "abcdefg" print(str[0]) print(str[-1]) # 輸出結果如下: a g連線
通過加號
+將多個字串連線起來,返回一個新的字串。str1 = "abcd" str2 = "efg" print(str1 + str2) # 輸出結果如下: abcdefgjoin( ) 方法:
S.join(iterable) -> strs表示分隔符字串,iterable為可迭代物件字串,結果返回字串。
str = "abcdefg" print('->'.join(str)) # 輸出結果如下: a->b->c->d->e->f->g字元查詢
find( ) 方法:
S.find(sub[, start[, end]]) -> int從左至右查詢子串sub,也可指定區間,找到返回正索引,找不到則返回
-1。str = "abcdefg" print(str.find('a',0,7)) print(str.find('A')) # 輸出結果如下: 0 -1rfind( ) 方法:
S.rfind(sub[, start[, end]]) -> int從右至左查詢子串sub,也可指定區間,找到返回正索引,找不到則返回
-1。str = "abcdefg" print(str.rfind('a')) print(str.rfind('A')) # 輸出結果如下: 0 -1還有
index()和find()類似,不過找不到會拋異常,不建議使用。像
s.count()還可以統計字元出現的次數。像
len(s)還可以統計字串的長度。分割
split( ) 方法:
S.split(sep=None, maxsplit=-1) -> list of stringssep表示分隔符,預設為空白字串,maxsplit=-1表示遍歷整個字串,最後返回列表。
str = "a,b,c,d,e,f,g" print(str.split(sep=',')) # 輸出結果如下: ['a', 'b', 'c', 'd', 'e', 'f', 'g']rsplit( ) 方法與上面不同就是,從右至左遍歷。
splitlines() 方法:
S.splitlines([keepends]) -> list of strings按行來切割字串,keepends表示是否保留行分隔符,最後返回列表。
str = "a\nb\nc\r\nd" print(str.splitlines()) print(str.splitlines(keepends=True)) # 輸出結果如下: ['a', 'b', 'c', 'd'] ['a\n', 'b\n', 'c\r\n', 'd']partition() 方法 :
S.partition(sep) -> (head, sep, tail)從左至右查詢分隔符,遇到就分割成頭、分隔符、尾的三元組,返回的是一個元組tuple。
str = "a*b*c*d" print(str.partition('*')) # 輸出結果如下: ('a', '*', 'b*c*d')rpartition() 方法 :
S.rpartition(sep) -> (head, sep, tail)與上方法不同,就是從右至左,不過這個比較常用,可以獲取字尾部分資訊。
str1 = "http://www.python.org:8843" str2 = str1.rpartition(':') port = str2[-1] print(port)替換
replace() 方法:
S.replace(old, new[, count]) -> str遍歷整個字串,找到全部替換,count表示替換次數,預設替換全部,最後返回一個
新的字串。str = "www.python.org" print(str.replace('w','m')) # 返回的是一個新的字串 print(str) # 字串不可變,保持原樣 # 輸出結果如下: mmm.python.org www.python.org移除
strip() 方法:
S.strip([chars]) -> str在字串兩端移除指定的
字符集chars, 預設移除空白字元。str = " * www.python.org *" print(str.strip("* ")) # 去掉字串首尾帶有星號'*' 和 空白' ' # 輸出結果如下: www.python.org還有
lstrip()和rstrip分別是移除字串左邊和右邊字符集。首尾判斷
startswith() 方法:
S.startswith(prefix[, start[, end]]) -> bool預設判斷字串開頭是否有指定的字元prefix,也可指定區間。
str = "www.python.org" print(str.startswith('www',0,14)) print(str.startswith('p',0,14)) # 輸出結果如下: True Falseendswith() 方法:
S.endswith(suffix[, start[, end]]) -> bool預設判斷字串結尾是否有指定的字元suffix,也可指定區間。
str = "www.python.org" print(str.startswith('www',0,14)) print(str.startswith('p',0,14)) # 輸出結果如下: True Falsestr = "www.python.org" print(str.endswith('g',11,14)) # 輸出結果如下: True格式化
c風格格式化:

格式字串:使用%s(對應值為字串),%d(對應值為數字)等等,還可以在中間插入修飾符%03d。
被格式的值:只能是一個物件,可以是元組或是字典。
name = "Tom" age = 18 print("%s is %d age." % (name,age)) # 輸出結果如下: Tom is 18 age.format格式化:

格式字串:使用花括號{ }, 花括號裡面可以使用修飾符。
被格式的值:*args為可變位置引數,**kwargs為可變關鍵字引數。
# 位置傳參 print("IP={} PORT={}".format('8.8.8.8',53)) # 位置傳參 print("{Server}: IP={1} PORT={0}".format(53, '8.8.8.8', Server='DNS Server')) # 位置和關鍵字傳參傳參 # 輸出結果如下: IP=8.8.8.8 PORT=53 DNS Server: IP=8.8.8.8 PORT=53# 浮點數 print("{}".format(0.123456789)) print("{:f}".format(0.123456789)) # 小數點預設為6位 print("{:.2f}".format(0.123456789)) # 取小數點後兩位 print("{:15}".format(0.123456789)) # 寬度為15,右對齊 # 輸出結果如下: 0.123456789 0.123457 # 為什麼是這個值?大於5要進位 0.12 0.123456789 # 左邊有4個空格其他常用函式
str = "DianDiJiShu" print(str.upper()) # 字母全部轉化為大寫 print(str.lower()) # 字母全部轉化為小寫 # 輸出結果如下: DIANDIJISHU diandijishu
2.2.4 bytes 位元組
bytes和 bytearray從python3引入的兩種資料型別。
在計算機的世界裡,機器是以0 和 1 組成的,也叫二進位制(位元組)來通訊的,這套編碼我們叫做ASCII編碼。
所以機器通訊的語言就叫做機器語言。然而我們人類想要跟機器通訊,那麼需要怎麼做呢?
- 把人類的語言編碼成機器能夠識別的語言,通常叫做編碼(字串轉換為ASCII碼)。
- 把機器的語言解碼成人類能夠識別的語言,通常叫做解碼(ASCII碼轉換為字串)。
至今現代編碼的發展史過程大概是這樣的:ASCII(1位元組) -> unicode(2~4位元組) -> utf-8(1~6位元組),utf8是多位元組編碼,一般使用1~3位元組,特殊使用4位元組(一般中文使用3位元組),向下相容ASCII編碼。
中國也有屬於自己的編碼:gbk
ASCII碼錶常用的必須牢記(整理部分):
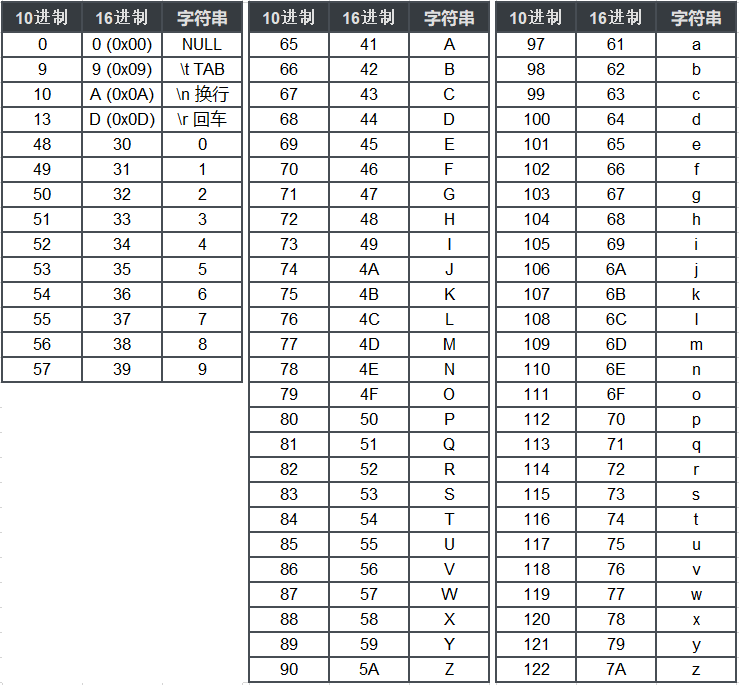
詳細ASCII碼下載連結:
連結:https://pan.baidu.com/s/1fWVl57Kqmv-tkjrDKwPvSw 提取碼:tuyz所以,機器上的進位制就是位元組,1位元組等於8位,例如:十進位制2,用2進位制和16進製表示:
# 二進位制
0000 0010 # 一個位元組bytes
# 16進位制,機器基本都是顯示16進位制
0x2bytes 是不可變型別
bytes() # 空bytes,一旦建立不可改變
bytes(int) # 指定位元組的大小,用0填充
bytes(iterable_of_ints) # [0.255]整數的可迭代物件
bytes(string, encoding[, errors]) # 等價於string.encoding(),字串編碼成位元組
bytes(bytes_or_buffer) # 複製一份新的位元組物件初始化
b1 = bytes() b2 = bytes(range(97,100)) b3 = bytes(b2) b4 = bytes('123',encoding='utf-8') b5 = b'ABC' b6 = b'\xe4\xbd\xa0\xe5\xa5\xbd'.decode('utf-8') print(b1, b2, b3, b4, b5, b6, sep='\n') # 輸出結果如下: b'' b'abc' b'abc' b'123' b'ABC' 你好
2.2.5 bytearray 位元組陣列
bytearray 是可變陣列,可以進行增刪改操作,類似列表。
bytearray() # 空bytearray,可改變
bytearray(iterable_of_ints) # [0.255]整數的可迭代物件
bytearray(string, encoding[, errors]) # 等價於string.encoding(),字串編碼成位元組
bytearray(bytes_or_buffer) # 複製一份新的位元組陣列物件
bytearray(int) # 指定位元組的大小,用0填充增刪改
# 初始化 b = bytearray() print(b) # 輸出結果如下: bytearray(b'') #-------------------------- # 增加元素物件 b.append(97) print(b) b.extend([98,99]) print(b) # 輸出結果如下: bytearray(b'a') bytearray(b'abc') #-------------------------- # 插入元素物件 b.insert(0,65) print(b) # 輸出結果如下: bytearray(b'Aabc') #-------------------------- # 刪除元素物件 b.pop() print(b) # 輸出結果如下: bytearray(b'Aab')
今天就到這了,下一回合咱再接著嘮嗑 set (集合)和 dict (字典) ,敬請耐心等待。
如果喜歡的我的文章,歡迎關注我的公眾號:點滴技術,掃碼關注,不定期分享

相關推薦
Python線性資料結構
目錄 1 線性資料結構 2.內建常用的資料型別 2.1 數值型 2.2 序列(sequence) 2.2.1 list 列表 2.2.2 tuple 元組 2.
基本線性資料結構的Python實現
本篇主要實現四種資料結構,分別是陣列、堆疊、佇列、連結串列。我不知道我為什麼要用Python來幹C乾的事情,總之Python就是可以幹。 所有概念性內容可以在參考資料中找到出處 陣列 陣列的設計 陣列設計之初是在形式上依賴記憶體分配而成的,所以必須在使用前預先請求空間。這使得陣
(python)資料結構------列表
一、數字的處理函式 (一)int() 取整數部分,與正負號無關,舉例如下: 1 print(int(-3.6), int(-2.5), int(-1.4)) 2 print(int(3.6), int(2.5), int(1.4))執行結果如下: -3 -2 -1 3 2 1 (二)/
(python)資料結構---字典
一、描述 由鍵值key-value組成的資料的集合 可變、無序的,key不可以重複 字典的鍵key要可hash(列表、字典、集合不可雜湊),不可變的資料結構是可雜湊的(字串、元組、物件、bytes) 字典的值value可以是任意的資料型別 二、字典的相關操作 1、訪問字典的值val
(python)資料結構---集合
一、描述 set翻譯為集合 set是可變的、無序的、不可重複的 set的元素要求可哈西(不可變的資料型別可哈西,可變的資料型別不可雜湊) set是無序的,因此不可以索引,也不可以修改 線型結構的查詢時間複雜度是O(n),隨著資料的增大而效率下降;set、dict內部使用hash值作為k
python初級資料結構(list,tuple,dict)(補充筆記,初級)
List: 遞推式構造列表(List Comprehension),例: list = [x*2 for x in lm] 切片list[start: stop: step] sort 和 sorted: sort會改變list(in-place),而sorted返回排序好的列表(retu
python 中資料結構的儲存方法
python中的一切都是物件,任何自定義的資料結構都可以寫成類 一、線性表 1.陣列實現 list, import array, np.array Python中list實現為動態陣列,而不是連結串列? 常用方法 append,extend, insert ,remove …
python-11 資料結構 - 集合
分類 可變集合: 建立 字面量建立 {值} 值: 整形 字串 元組 只能是固定型別,不可以是列表,可以是元組 >>> {1,2,3,} {1, 2, 3} >>> {1,"s"} {1, 's'} >&
python-11 資料結構 - 字典
字典 建立: 1.字面量 >>> {"you":90,"liang":80} {'you': 90, 'liang': 80} 2. 通過dict函式建立: 2.1 用列表來建立 >>> dict1 = dict([["you",9
python-12 資料結構 字串
一般操作 >>> str1="hello" >>> 2*str1 'hellohello' >>> min(str1) 'e' 編碼和解碼 >>> str1 = "編碼和解碼" >>>
Python的資料結構(列表,集合,元組)
Python也算是現學現用,針對資料結構,我覺得必須掌握的就這三種:列表,集合,元組 列表[ ]: 列表的申明和訪問 #!/usr/bin/python3 list =[] list1 = ['Google', 'Runoob', 1997, 2000]; list2 = [1, 2,
Python語言資料結構和語言結構(2)
1. Python預備基礎 變數的命名 變數命名規則主要有以下幾條: 變數名只能包含字母、數字和下劃線,其中下劃線和字母可以開頭,數字不行,即info_1可以,而1_info不行; 變數名內不能包含空格,可以用下劃線替代,即info_1,而非info 1; 不能與Pyt
線性資料結構——線性表
資料結構 資料結構可以用一個二元組來定義,DataStructure = (D,S)。其中D是資料元素的有限集,S是D上關係的集合。這個定義是數學上一種描述,這裡的關係代表著資料元素之間的邏輯關係,即邏輯結構,通常指集合、線性表、樹、圖四種結構。另一方面,某種資料結構關係在
python與資料結構-單鏈表
https://www.bilibili.com/video/av21540971/?p=10 1、python 中變數標識的本質 python 中等號的本質就是一個"引用連結”(變數皆指標),【與c和c++不一樣,c、c++是&表示地址,指標】 2、 3、遍歷連結串列
python之資料結構
•列表 •元組 •字典 •集合 一、列表 •列表是Python中非常重要的資料型別,通常作為函式的返回型別。 •列表由一組元素組成。列表可包含任何型別的值:數字、字串甚至序列。 •列表是可變的,即可以在不復制的情況下新增、刪除或修改列表元素。 1.列表的建立
python-8 資料結構
容器: 序列(列表元組) 對映(字典) 集合 在python中 沒有陣列 用系列資料型別代替陣列 系列資料型別 系列資料型別 python中最簡單的資料結構 可以包含一個或者多個元素 這
強烈推薦一本免費演算法書《用Python解決資料結構與演算法問題》
學 Python 僅僅只學 Python 語法和 API 是遠遠不夠的,掌握演算法和資料結構這種永遠都不會過時的核心技能才是決定一個程式設計師職業發展的關鍵因素。演算法和資料結構對專業程式設計師來說重要性不言而喻,同樣一個問題,不同演算法效率可謂千差萬別。在問題規模很小的時候你可能感知不到,
2018年秋招面試常見python和資料結構知識點總結
python中的深拷貝和淺拷貝的定義: 在python中物件的賦值就是物件的引用,當建立一個物件把他賦值給另一個變數時,Python只是拷貝了物件的引用而已。 淺拷貝:拷貝了最外圍物件本身,內部的元素只是拷貝了一個引用而已,也就是隻複製物件,物件的引用不復制。
python-11 資料結構
字典 建立: 1.字面量 >>> {"you":90,"liang":80} {'you': 90, 'liang': 80} 2. 通過dict函式建立: 2.1 用列
Python實現資料結構佇列約瑟夫環問題
問題描述: 人們站在一個等待被處決的圈子裡。 計數從圓圈中的指定點開始,並沿指定方向圍繞圓圈進行。 在跳過指定數量的人之後,執行下一個人。 對剩下的人重複該過程,從下一個人開始,朝同一方向跳過相同數量