
javascript正則表示式入門先了解這些
阿新 • • 發佈:2020-04-01
## 前言
此內容由學習《JavaScript正則表示式迷你書(1.1版)》整理而來(於2020年3月30日看完)。此外還參考了MDN上關於Regex和String的相關內容,還有ECMAScript 6中關於正則的擴充套件內容,但不多。在文章末尾,會放上所有的連結。
迷你書共七章,我都做了相應的標號。不過我將【7】7種方法放在了前面,討論了具體情境下怎麼正確使用函式的問題(其實是我自己一直被這個問題困擾,書上的例子為什麼用這個方法,為什麼這個方法這裡返回這樣,那裡卻不是這樣,把我搞崩潰了),也建議大家先搞懂這個吧。
## 本文重點
+ 正則的 2 種建立
+ 正則的 6 個修飾符(i、g、m、u、y、s)
+ 【7】.用到正則的 7 種方法(RegExp(exec、test),String(search、match、matchAll、replace、split))
+ 正則表示式中的6種結構(字元字面量、字元組、量詞、錨、分組、分支)
+ 【1】.字元匹配:字面量、字元組、量詞。重點還有貪婪匹配與惰性匹配
+ 【2】.位置匹配:^ 、$ 、 \b 、\B 、(?=abc) 、 (?!abc) 的使用
+ 【3】.括號的作用:分組和分支結構。知識點有:分組引用($1的使用)、反向引用(\1的使用)、括號巢狀、括號結合量詞
+ 【4】.回溯原理 (本文大多介紹的是實踐中用的基礎知識,後期對此可能會單獨寫篇,先佔個坑)
+ 【5】.正則的拆分:重點是操作符的優先順序
+ 【6】.正則表示式的構建(本章寫了些提高正則準確性和效率的內容,也先佔個坑)
+ 簡單實用的正則測試器
## 2種建立
語法:/pattern/flags
`var regexp = /\w+/g;`
`var regexp = new RegExp('\\w+','g');`
## 6個修飾符

**重點介紹全域性與非全域性:**
**全域性**就是說在字串中查詢所有與正則式匹配的內容,因此會有>
 到目前為止,我們應該積攢了很多問號了。我學的過程中有以下兩個問題: 1.`/t(e)(st(\d?))/g`和`/t(e)(st(\d?))/`的區別我知道了,但`t(e)(st(\d?))`這是什麼意思呢? 2.上文所謂的“與正則表示式匹配的內容”
## 7種結構 -字元匹配 ### 字面量  ### 字元組 需要強調的是,雖叫字元組(字元類),但只是其中一個字元。 如果字元組裡的字元特別多,可用連字元 `-` 來省略和簡寫(見表格示例)。 示例:全域性匹配,使用`match()`方法返回字串中與表示式匹配的所有內容。`[123]`表示這個位置的字元可以是`1`、`2`、`3`中的任意一個  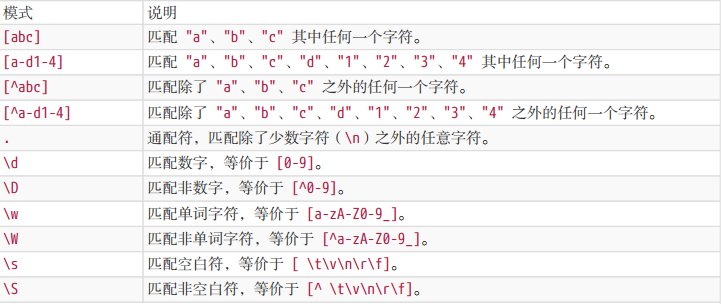 ### 量詞 有了一個字元,那我我們就會考慮到需要它出現幾次,那麼量詞來了。 示例:全域性匹配,使用`match()`方法返回字串中與表示式匹配的所有內容。`b{2,5}`表示字元`b`出現2到5次。   #### 貪婪匹配與惰性匹配  貪婪匹配`/\d{2,5}/` 表示數字連續出現 2 到 5 次,會盡可能多的匹配。你如果有 6 個連續的數字,那我就要我的上限 5 個;你如果只有 3 個連續數字,那我就要3個。想要我只取 2 個,除非你只有兩個。 惰性匹配`/\d{2,5}?/ ` 表示雖然 2 到 5 次都行,當 2 個就夠的時候,我也不貪,我就取兩個。 >對惰性匹配的記憶方式是:量詞後面加個問號,問一問你知足了嗎,你很貪婪嗎?注意是 量詞後面 量詞後面 量詞後面,重要的事說三遍。還是來個例子吧,?與??: `'testtest1test2'.match(/t(e)(st(\d?))/g)` 的結果就是 `[ 'test', 'test1', 'test2' ]` `'testtest1test2'.match(/t(e)(st(\d??))/g)` 的結果就是 `[ 'test', 'test', 'test' ]` ## 7種結構 -位置匹配 ### 位置理解 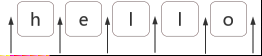 ### 位置特性 **1.對於位置的理解,我們可以理解成空字元 ""。** 因此,把 `/^hello$/` 寫成 `/^^hello$$$/`,是沒有任何問題的。甚至 `/(?=he)^^he(?=\w)llo$\b\b$/`; **2.整體匹配時,自然就需要使用 `^` 和 `$` **  ## 7種結構 - 括號的作用 ### 分組和分支結構 到目前為止,我們對於 `match(/t(e)(st(\d?))/g)`應該完全理解了(包括 `match()`的使用,全域性修飾符`g`,表示字元組的`\d`和表示量詞的`?`,且也知道了這是貪婪匹配)。那麼,裡面的括號又表示什麼意思呢?這就涉及到分組捕獲了。 以日期為例,假設要匹配的格式是 `yyyy-mm-dd` 的: 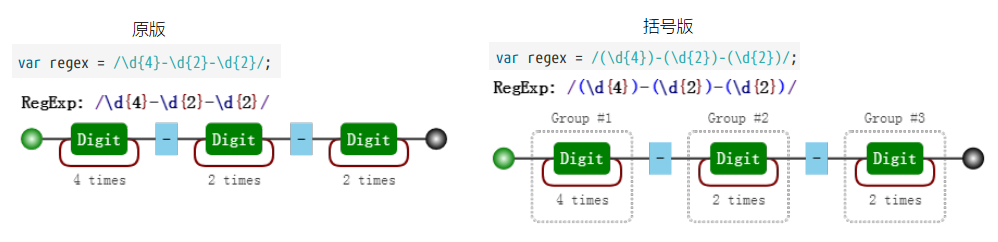 對比這兩個視覺化圖片,我們發現,與前者相比,後者多了分組編號,如 Group #1,**這樣正則就能在匹配表示式的同時,還能得到我們想要從匹配項中捕獲的分組內容。即用 `()` 括起來的內容**。到此為止,`t(e)(st(\d?))`涉及到的分組捕獲知識點也就結束了。 再介紹下分支結構,由於操作符 `|` 的優先順序最低,因此需要將其放於括號中: **分支結構形如`(regex1|regex2)`,字面意思,即這裡可以匹配 `regex1`或者 `regex2`之一,捕獲分組的時候也是二者之一 **,例子: 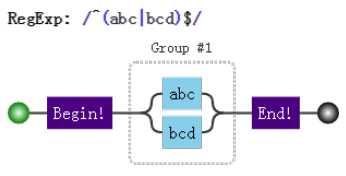 ### 引用分組 使用相應 API 來引用分組。 #### 提取資料  #### 替換replace  當第二個引數是字串時,如下的字元有特殊的含義。其中,第二個是 `$&`:  ### 反向引用分組 除了使用相應 API 來引用分組,也可以在正則本身裡引用分組。但只能引用之前出現的分組,即反向引用。 以前面的日期為例,假設我們想要求分割符前後一致怎麼辦?即杜絕 `2016-06/12`這樣中間分割符不一致的情況,此時需要使用反向引用: 注意裡面的 \1,表示的引用之前的那個分組 `(-|\/|\.)`。不管它匹配到什麼(比如 -),\1 都匹配那個同樣的具體某個字元。 我們知道了 \1 的含義後,那麼 \2 和 \3 的概念也就理解了,即分別指代第二個和第三個分組。需要注意: 1. `\10`表示第十個分組,如果真要匹配 `\1` 和 `0` 的話,使用 `(?:\1)0` 或者 `\1(?:0)`。 2. 反向引用引用不存在的分組時候,匹配 反向引用的字元本身。例如 `\2`,就匹配 `"\2"`。  ### 分組括號巢狀 針對 `"1231231233".match(/^((\d)(\d(\d)))\1\2\3\4$/)` 的視覺化形式如下,一目瞭然: 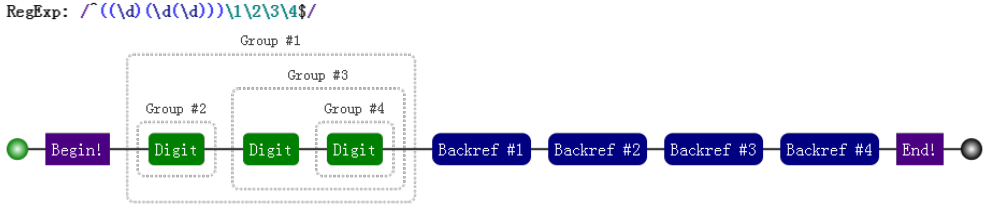 ### 分組括號結合量詞 分組後面有量詞的話,分組最終捕獲到的資料是最後一次的匹配。分組引用與反向引用都是這樣例子:  ### 非捕獲括號 如果只想要括號最原始的功能,但不會引用它,即,既不在 API 裡引用,也不在正則裡反向引用。 可以使用非捕獲括號 `(?:p)` 和 `(?:p1|p2|p3)`,如下程式碼,執行`matchAll()`,雖然有括號,但不會得到捕獲的分組內容。  ## 正則的拆分 不僅要求自己能解決問題,還要看懂別人的解決方案。程式碼是這樣,正則表示式也是這樣。如何能正確地把一大串正則拆分成一塊一塊的,成為了破解“天書”的關鍵。 這裡,我們來分析一個正則 `/ab?(c|de*)+|fg/`:  >思考下: `/^abc|bcd$/` 和 `/^(abc|bcd)$/`。 `/^[abc]{3}+$/` 和 `/^([abc]{3})+$/` ## 操作符優先順序  ### 操作符轉義 所有操作符都需要轉義 `^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、- ,`
 到這裡,對正則表示式也算是入了個小門了,即對正則的一些基本操作也有了瞭解,也能看懂別人的正則表示式,就算是copy也能靈活的改動了。
## 簡單實用的正則測試器 效果圖: 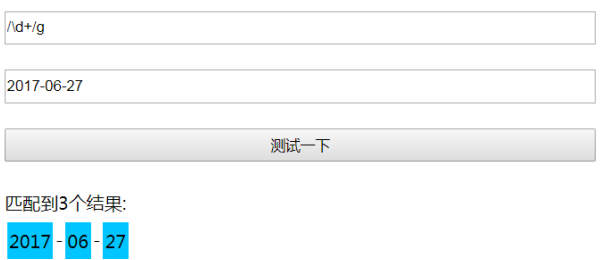 原始碼:[git](https://github.com/adagiomin/Resource/blob/master/%E7%AE%80%E5%8D%95%E5%AE%9E%E7%94%A8%E7%9A%84%E6%AD%A3%E5%88%99%E6%B5%8B%E8%AF%95%E5%99%A8.html) ## 相關連結 [老姚 《JavaScript 正則表示式迷你書》下載](https://github.com/qdlaoyao/js-regex-mini-book) [阮一峰《ECMAScript 6 入門 - 正則的擴充套件》](https://es6.ruanyifeng.com/#docs/regex) [MDN RegExp.prototype.exec()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec) [MDN RegExp.prototype.test()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec) [MDN String.prototype.search()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/search) [MDN String.prototype.match()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/match) [MDN String.prototype.matchAll()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/matchAll) [MDN String.prototype.replace()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/replace) [MDN String.prototype.split()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Strin
 到目前為止,我們應該積攢了很多問號了。我學的過程中有以下兩個問題: 1.`/t(e)(st(\d?))/g`和`/t(e)(st(\d?))/`的區別我知道了,但`t(e)(st(\d?))`這是什麼意思呢? 2.上文所謂的“與正則表示式匹配的內容”
## 7種結構 -字元匹配 ### 字面量  ### 字元組 需要強調的是,雖叫字元組(字元類),但只是其中一個字元。 如果字元組裡的字元特別多,可用連字元 `-` 來省略和簡寫(見表格示例)。 示例:全域性匹配,使用`match()`方法返回字串中與表示式匹配的所有內容。`[123]`表示這個位置的字元可以是`1`、`2`、`3`中的任意一個   ### 量詞 有了一個字元,那我我們就會考慮到需要它出現幾次,那麼量詞來了。 示例:全域性匹配,使用`match()`方法返回字串中與表示式匹配的所有內容。`b{2,5}`表示字元`b`出現2到5次。   #### 貪婪匹配與惰性匹配  貪婪匹配`/\d{2,5}/` 表示數字連續出現 2 到 5 次,會盡可能多的匹配。你如果有 6 個連續的數字,那我就要我的上限 5 個;你如果只有 3 個連續數字,那我就要3個。想要我只取 2 個,除非你只有兩個。 惰性匹配`/\d{2,5}?/ ` 表示雖然 2 到 5 次都行,當 2 個就夠的時候,我也不貪,我就取兩個。 >對惰性匹配的記憶方式是:量詞後面加個問號,問一問你知足了嗎,你很貪婪嗎?注意是 量詞後面 量詞後面 量詞後面,重要的事說三遍。還是來個例子吧,?與??: `'testtest1test2'.match(/t(e)(st(\d?))/g)` 的結果就是 `[ 'test', 'test1', 'test2' ]` `'testtest1test2'.match(/t(e)(st(\d??))/g)` 的結果就是 `[ 'test', 'test', 'test' ]` ## 7種結構 -位置匹配 ### 位置理解  ### 位置特性 **1.對於位置的理解,我們可以理解成空字元 ""。** 因此,把 `/^hello$/` 寫成 `/^^hello$$$/`,是沒有任何問題的。甚至 `/(?=he)^^he(?=\w)llo$\b\b$/`; **2.整體匹配時,自然就需要使用 `^` 和 `$` **  ## 7種結構 - 括號的作用 ### 分組和分支結構 到目前為止,我們對於 `match(/t(e)(st(\d?))/g)`應該完全理解了(包括 `match()`的使用,全域性修飾符`g`,表示字元組的`\d`和表示量詞的`?`,且也知道了這是貪婪匹配)。那麼,裡面的括號又表示什麼意思呢?這就涉及到分組捕獲了。 以日期為例,假設要匹配的格式是 `yyyy-mm-dd` 的:  對比這兩個視覺化圖片,我們發現,與前者相比,後者多了分組編號,如 Group #1,**這樣正則就能在匹配表示式的同時,還能得到我們想要從匹配項中捕獲的分組內容。即用 `()` 括起來的內容**。到此為止,`t(e)(st(\d?))`涉及到的分組捕獲知識點也就結束了。 再介紹下分支結構,由於操作符 `|` 的優先順序最低,因此需要將其放於括號中: **分支結構形如`(regex1|regex2)`,字面意思,即這裡可以匹配 `regex1`或者 `regex2`之一,捕獲分組的時候也是二者之一 **,例子:  ### 引用分組 使用相應 API 來引用分組。 #### 提取資料  #### 替換replace  當第二個引數是字串時,如下的字元有特殊的含義。其中,第二個是 `$&`:  ### 反向引用分組 除了使用相應 API 來引用分組,也可以在正則本身裡引用分組。但只能引用之前出現的分組,即反向引用。 以前面的日期為例,假設我們想要求分割符前後一致怎麼辦?即杜絕 `2016-06/12`這樣中間分割符不一致的情況,此時需要使用反向引用: 注意裡面的 \1,表示的引用之前的那個分組 `(-|\/|\.)`。不管它匹配到什麼(比如 -),\1 都匹配那個同樣的具體某個字元。 我們知道了 \1 的含義後,那麼 \2 和 \3 的概念也就理解了,即分別指代第二個和第三個分組。需要注意: 1. `\10`表示第十個分組,如果真要匹配 `\1` 和 `0` 的話,使用 `(?:\1)0` 或者 `\1(?:0)`。 2. 反向引用引用不存在的分組時候,匹配 反向引用的字元本身。例如 `\2`,就匹配 `"\2"`。  ### 分組括號巢狀 針對 `"1231231233".match(/^((\d)(\d(\d)))\1\2\3\4$/)` 的視覺化形式如下,一目瞭然:  ### 分組括號結合量詞 分組後面有量詞的話,分組最終捕獲到的資料是最後一次的匹配。分組引用與反向引用都是這樣例子:  ### 非捕獲括號 如果只想要括號最原始的功能,但不會引用它,即,既不在 API 裡引用,也不在正則裡反向引用。 可以使用非捕獲括號 `(?:p)` 和 `(?:p1|p2|p3)`,如下程式碼,執行`matchAll()`,雖然有括號,但不會得到捕獲的分組內容。  ## 正則的拆分 不僅要求自己能解決問題,還要看懂別人的解決方案。程式碼是這樣,正則表示式也是這樣。如何能正確地把一大串正則拆分成一塊一塊的,成為了破解“天書”的關鍵。 這裡,我們來分析一個正則 `/ab?(c|de*)+|fg/`:  >思考下: `/^abc|bcd$/` 和 `/^(abc|bcd)$/`。 `/^[abc]{3}+$/` 和 `/^([abc]{3})+$/` ## 操作符優先順序  ### 操作符轉義 所有操作符都需要轉義 `^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、- ,`
 到這裡,對正則表示式也算是入了個小門了,即對正則的一些基本操作也有了瞭解,也能看懂別人的正則表示式,就算是copy也能靈活的改動了。
## 簡單實用的正則測試器 效果圖:  原始碼:[git](https://github.com/adagiomin/Resource/blob/master/%E7%AE%80%E5%8D%95%E5%AE%9E%E7%94%A8%E7%9A%84%E6%AD%A3%E5%88%99%E6%B5%8B%E8%AF%95%E5%99%A8.html) ## 相關連結 [老姚 《JavaScript 正則表示式迷你書》下載](https://github.com/qdlaoyao/js-regex-mini-book) [阮一峰《ECMAScript 6 入門 - 正則的擴充套件》](https://es6.ruanyifeng.com/#docs/regex) [MDN RegExp.prototype.exec()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec) [MDN RegExp.prototype.test()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec) [MDN String.prototype.search()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/search) [MDN String.prototype.match()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/match) [MDN String.prototype.matchAll()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/matchAll) [MDN String.prototype.replace()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/replace) [MDN String.prototype.split()](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Strin