
【科普】神經網路中的隨機失活方法
阿新 • • 發佈:2020-04-05
## 1. Dropout
如果模型引數過多,而訓練樣本過少,容易陷入過擬合。過擬合的表現主要是:在訓練資料集上loss比較小,準確率比較高,但是在測試資料上loss比較大,準確率比較低。Dropout可以比較有效地緩解模型的過擬合問題,起到正則化的作用。
Dropout,中文是隨機失活,是一個簡單又機器有效的正則化方法,可以和L1正則化、L2正則化和最大範數約束等方法互為補充。
在訓練過程中,Dropout的實現是讓神經元以超引數 $p$ 的概率停止工作或者啟用被置為0,
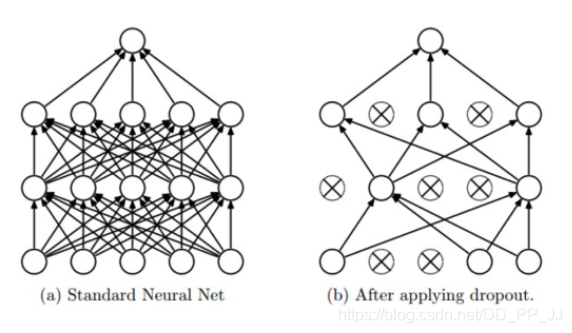
**在訓練過程中**,Dropout會隨機失活,可以被認為是對完整的神經網路的一些子集進行訓練,每次基於輸入資料只更新子網路的引數。

**在測試過程中**,不進行隨機失活,而是將Dropout的引數p乘以輸出。
再來看Dropout論文中涉及到的一些實驗:
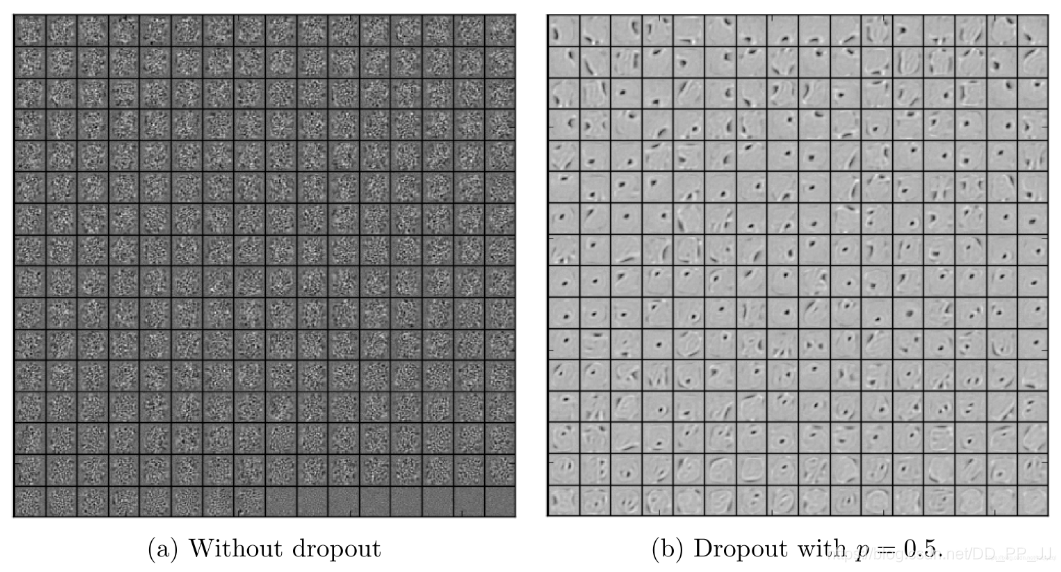
上圖是作者在MNIST資料集上進行的Dropout實驗,可以看到Dropout可以破壞隱藏層單元之間的協同適應性,使得在使用Dropout後的神經網路提取的特徵更加明確,增加了模型的泛化能力。
另外可以從神經元之間的關係來解釋Dropout,使用Dropout能夠隨機讓一些神經元臨時不參與計算,這樣的條件下可以**減少神經元之間的依賴**,權值的更新不再依賴固有關係的隱含節點的共同作用,這樣會迫使網路去學習更加魯棒的特徵。
再看一組實驗,在隱藏層神經元數目不變的情況下,調節引數p,觀察對訓練集和測試集上效果的影響。
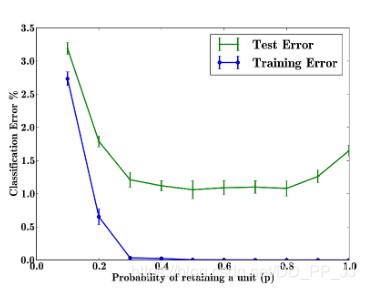
以上實驗是對MNIST資料集進行的實驗,隨著p的增加, 測試誤差先降後升,p在[0.4, 0.8]之間的時候效果最好,通常p預設值會被設為0.5。
還有一組實驗是通過調整資料集判斷Dropout對模型的影響:
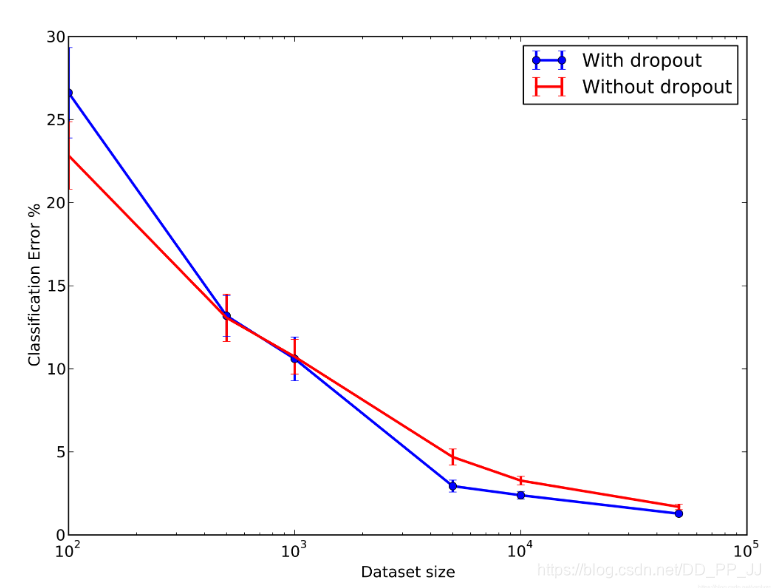
在資料量比較少的時候,Dropout並沒有給模型帶來效能上的提升,但是在資料量變大的時候,Dropout則會帶來比較明顯的提升,這說明Dropout有一定正則化的作用,可以防止模型過擬合。
在pytorch中對應的Dropout實現如下:
```python
>>> m = nn.Dropout(p=0.2)
>>> input = torch.randn(20, 16)
>>> output = m(input)
```
torch.nn.Dropout(p=0.5, inplace=False)
- **p** – probability of an element to be zeroed. Default: 0.5
- **inplace** – If set to `True`, will do this operation in-place. Default: `False`
對input沒有任何要求,也就是說Linear可以,卷積層也可以。
## 2. Spatial Dropout
普通的Dropout會將部分元素失活,而Spatial Dropout則是隨機將部分割槽域失失活, 這部分參考參考文獻中的【2】,簡單理解就是通道隨機失活。一般很少用普通的Dropout來處理卷積層,這樣效果往往不會很理想,原因可能是卷積層的啟用是空間上關聯的,使用Dropout以後資訊仍然能夠通過卷積網路傳輸。而Spatial Dropout直接隨機選取feature map中的channel進行dropout,可以讓channel之間減少互相的依賴關係。
在pytorch中對應Spatial Dropout實現如下:
torch.nn.Dropout2d(*p=0.5*, *inplace=False*)
- **p** (*python:float**,* *optional*) – probability of an element to be zero-ed.
- **inplace** (*bool**,* *optional*) – If set to `True`, will do this operation in-place
對輸入輸出有一定要求:
- input shape: (N, C, H, W)
- output shape: (N, C, H, W)
```python
>>> m = nn.Dropout2d(p=0.2)
>>> input = torch.randn(20, 16, 32, 32)
>>> output = m(input)
```
此外對3D feature map中也有對應的torch.nn.Dropout3d函式,和以上使用方法除輸入輸出為(N, C, D, H, W)以外,其他均相同。
## 3. Stochastic Depth
在DenseNet之前提出,隨機將ResNet中的一部分Res Block失活,實際操作和Dropout也很類似。在訓練的過程中任意丟失一些Block, 在測試的過程中使用所有的block。使用這種方式, 在訓練時使用較淺的深度(隨機在resnet的基礎上跳過一些層),在測試時使用較深的深度,較少訓練時間,提高訓練效能,最終在四個資料集上都超過了ResNet原有的效能(cifar-10, cifar-100, SVHN, imageNet)
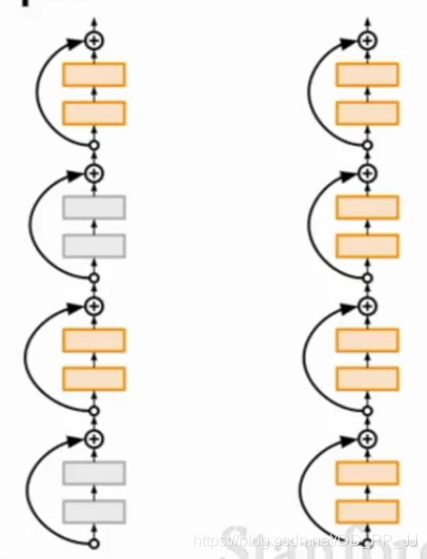
詳解請看[卷積神經網路學習路線(十一)| Stochastic Depth(隨機深度網路)]( https://mp.weixin.qq.com/s?__biz=MzA4MjY4NTk0NQ==&mid=2247484504&idx=1&sn=93613f5abd6f88724be500ef319ddadf&chksm=9f80becea8f737d8e7bd16e7bcd2d6683222f2ca0e301000f0c7996a66c934e909a01f7e5a8f&scene=21#wechat_redirect )
## 4. DropBlock
一句話概括就是: 在每個feature map上按spatial塊隨機設定失活。
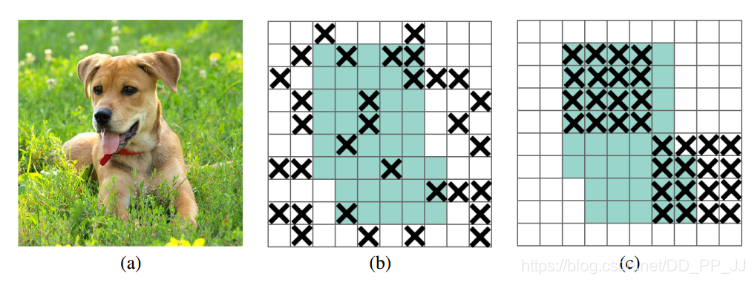
Dropout對卷積層的效果沒那麼好(見圖(b))。文章認為是由於每個feature map中的點都對應一個感受野範圍,僅僅對單個畫素位置進行Dropout並不能降低feature map學習的特徵範圍,網路依然可以通過失活位置相鄰元素學習對應的語義資訊。所以作者提出一塊一塊的失活(見圖(c)), 這種操作就是DropBlock.
DropBlock有三個重要的引數:
- block size控制block的大小
- *γ* 控制有多少個channel要進行DropBlock
- keep prob類別Dropout中的p,以一定的概率失活
經過實驗,可以證明block size控制大小最好在7x7, keep prob在整個訓練過程中從1逐漸衰減到指定閾值比較好。
## 5. Cutout
Cutout和DropBlock非常相似,也是一個非常簡單的正則化手段,下圖是論文中對CIFAR10資料集進行的處理,移除輸入圖片中的一塊連續區域。

此外作者也針對移除塊的大小影響進行了實驗,如下圖:
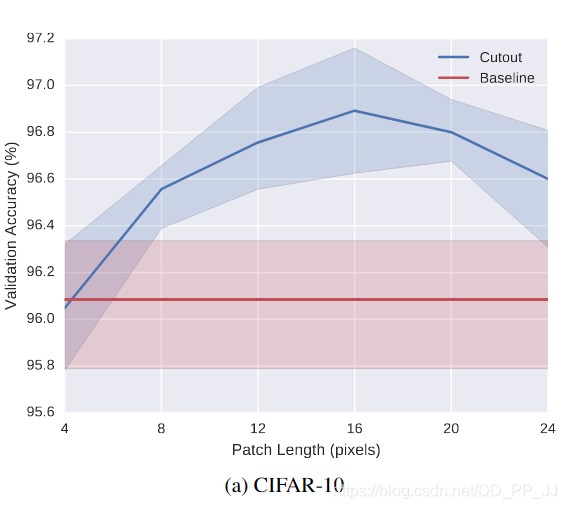
可以看出,對CIFAR-10資料集來說,隨著patch length的增加,準確率是先升後降。
可見在使用了Cutout後可以提高神經網路的魯棒性和整體效能,並且這種方法還可以和其他正則化方法配合使用。不過如何選取合適的Patch和資料集有非常強的相關關係,如果想用Cutout進行實驗,需要針對Patch Length做一些實驗。
擴充套件:最新出的一篇Attentive CutMix中的有一個圖很吸引人。作者知乎親自答: https://zhuanlan.zhihu.com/p/122296738

Attentive CutMix具體做法如下如所示: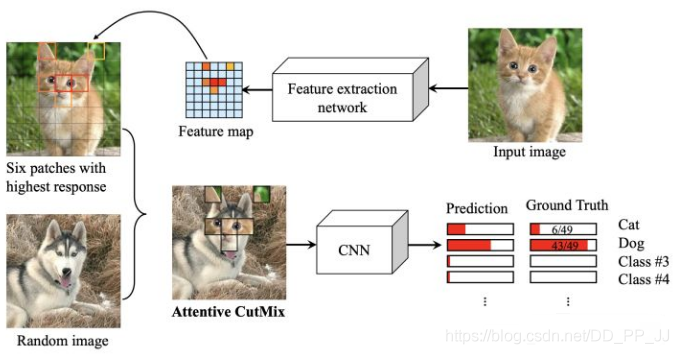
將原圖劃分為7x7的格子,然後通過一個小的網路得到熱圖,然後計算49個格子中top N個置信度最高的格子, 從輸入圖片中將這些網格對應的區域裁剪下來,覆蓋到另一張待融合的圖片上,用於訓練神經網路。Ground Truth 的Label 也會根據融合的圖片的類別和剪下的區域的大小比例而相應修改。至於上圖貓和狗面部的重合應該是一個巧合。
## 6. DropConnect
DropConnect也是Dropout的衍生品,兩者相似處在於都是對全連線層進行處理(DropConnect只能用於全連線層而Dropout可以用於全連線層和卷積層),兩者主要差別在於:
- Dropout是對啟用的activation進行處理,將一些啟用隨機失活,從而讓神經元學到更加獨立的特徵,增加了網路的魯棒性。
- DropConnect則是對連結矩陣的處理,具體對比可以看下圖。
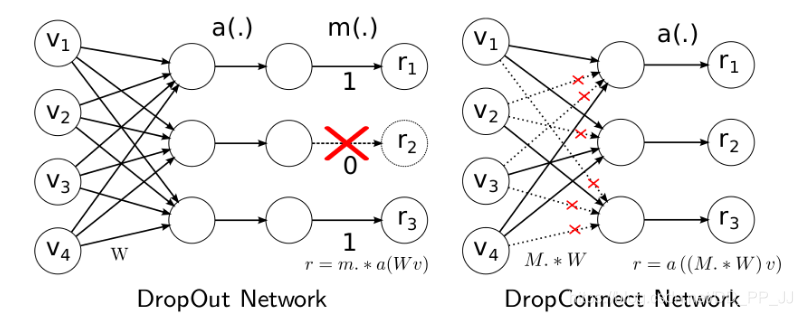
DropConnect訓練的時候和Dropout很相似,是隨機取樣一個矩陣M作為Mask 矩陣(值為0或者1),然後施加到W上。
## 7. 總結
本文屬於一篇的科普文,其中有很多細節、公式還需要去論文中仔細品讀。
在CS231N課程中,講到Dropout的時候引申出來了非常多的這種類似的思想,其核心就是減少神經元互相的依賴,從而提升模型魯棒性。和Dropout的改進非常相似的有Batch Normalization的一系列改進(這部分啟發自知乎@mileistone):
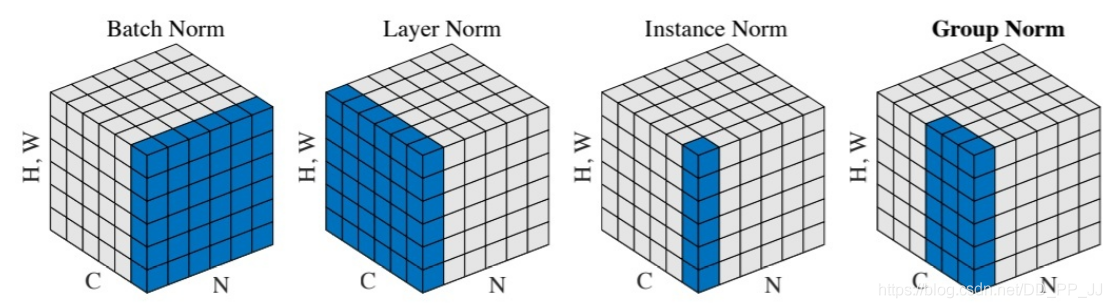
一個feature map的shape為[N, C, H, W]
- Batch Norm是從NHW三個維度進行歸一化
- Layer Norm是從CHW三個維度進行歸一化
- Instance Norm是從HW兩個維度進行歸一化
- Group Nrom是從$C_{part}HW$上做歸一化,將C分為幾個獨立的部分。
與之類似的Drop系列操作(shape=[N, C, H, W]):
- Dropout是將NCHW中所有的特徵進行隨機失活,以畫素為單位。
- Spatial Dropout是隨機將CHW的特徵進行隨機失活,以channel為單位。
- DropBlock是隨機將$C[HW]_{part}$的特徵進行隨機失活,以HW中一部分為單位。
- Stochastic Depth是隨機跳過一個Res Block, 單位更大。
## 8. 參考文獻
【1】 Dropout: A simple way to prevent neural networks from overfitting
【2】 Efficient object localization using convolutional networks.
【3】 Deep networks with stochastic depth.
【4】 DropBlock: A regularization method for convolutional networks.
【5】 Improved regularization of convolutional neural networks with cutout
【6】 Regularization of Neural Network using DropConnect
【7】Attentive CutMix: https://arxiv.org/pdf/2003.13048.pdf
【8】 https://www.zhihu.com/question/30