
聊一聊那些線性時間複雜度的排序演算法
阿新 • • 發佈:2020-04-07
實際上,基於比較和交換的排序演算法,它們的時間複雜度的下限就是O(nlog2n)。氣泡排序,插入排序等自不必多說,時間複雜度是O(n2),即使強如快速排序,堆排序等也只是達到了O(nlog2n)的複雜度。那麼那些傳說中可以突破O(nlog2n)下限,達到線性時間複雜度O(n)的排序演算法到底是什麼樣的呢,接下來讓我們一探究竟。
# 桶排序
## 基本思想
一句話概括就是,將待排序列中的每一個元素通過設定好的對映函式分配到有限數量的桶中,然後再對每個桶中的元素排序。
基本步驟如下:
1. 準備有限數量的空桶
2. 遍歷待排序列,將每個元素通過對映函式分配到對應的桶中
3. 對每個不是空的桶進行排序
4. 從每個不是空的桶中再依次把元素放回到原來的序列中
桶排序是利用函式的對映完成了元素的劃分,省略了比較交換的步驟,然後再對桶中的少量資料進行排序,這裡的排序可以根據實際需求選擇任意的排序演算法,比如使用快速排序。需要注意的是對映函式的選擇必須保證每個桶是有序的,即一個桶中的所有元素必須大於或小於另一個桶中的所有元素。這樣才能在依次從每個桶中將元素放回到原始序列中時,保證元素的有序性。
## 複雜度與穩定性與優缺點
* 空間複雜度:O(m + n),m表示桶的數量,n表示需要長度為n的輔助空間
* 時間複雜度:O(n)
桶排序的耗時主要是兩個部分:
1. 將待排序列的所有元素對映到桶中,時間複雜度O(n)
2. 對每個桶內元素排序,因為是基於比較的演算法,平均時間複雜度只能達到O(Ni [] buckets = new List[Fun(max, min, array.Length) + 1];
for(int i = 0; i < buckets.Length; i ++){
buckets[i] = new List();
}
for(int i = 0; i < array.Length; i ++){
buckets[Fun(array[i], min, array.Length)].Add(array[i]);
}
int index = 0;
for(int i = 0; i < buckets.Length; i ++){
// 桶內的排序藉助了Sort方法,也可以使用其他排序方法
buckets[i].Sort();
foreach(int item in buckets[i]){
array[index ++] = item;
}
}
}
// 對映函式,可以根據實際需求選擇不同的對映函式
public int Fun(int value, int minValue, int length){
return (value - minValue) / length;
}
```
**【演算法解讀】**
演算法首先確定對映函式`Fun`,函式的返回值就是元素對應桶的下標。然後找到待排序列中的最大值與最小值,並利用最大最小值確定桶排序需要的桶數量。遍歷待排序列的所有元素並通過對映函式`Fun`將它們分配到對應下標的桶中。再依次對每個桶內的所有元素進行排序,這裡的使用的是C#提供的Sort方法(也可以選擇不同的排序方法)。當一個桶內的元素排序完畢後再將其放回到原始序列中。
**【舉個栗子】**
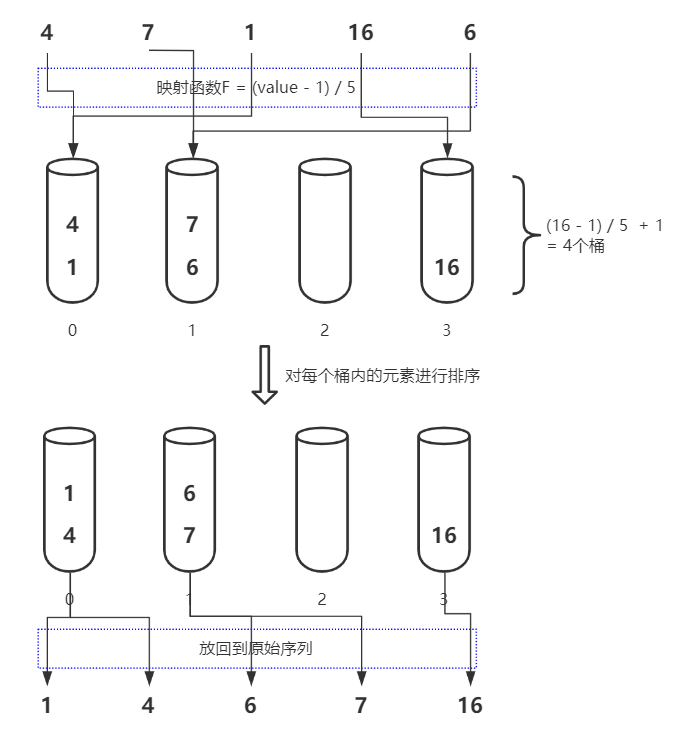
對於待排序列4, 7, 1, 16, 6可以使用下圖表示其桶排序的過程:
# 計數排序
## 基本思想
計數排序可以認為是桶排序的一種特殊實現,如果理解了桶排序的話,計數排序就相對很簡單了。
計數排序要求待排序列的所有元素都是範圍都在[0, max]之間的正整數(當然經過變形也可以是負數,比如通過加上某個值,使所有元素都變為正數)
基本步驟如下:
1. 得到待排序列中的最大值,構建(最大值 + 1)的計數陣列C,可以認為是(最大值 + 1)個桶,只是桶中存放的不再是元素,而是每個元素出現的次數
2. 遍歷待排序列,在計數陣列中統計每個元素出現的次數。出現一個元素i,則以該元素值為索引的位置上計數加1,即C[i] ++
3. 遍歷計數陣列,若C[i] >