
【nodejs 爬蟲】使用 puppeteer 爬取鏈家房價資訊
阿新 • • 發佈:2020-04-07
# 使用 puppeteer 爬取鏈家房價資訊
[toc]
此文記錄了使用 `puppeteer` 庫進行動態網站爬取的過程。
## 頁面結構
[地址](https://wh.lianjia.com/chengjiao/)
鏈家的歷史成交記錄頁面在這裡,它是`後臺渲染模式`,無法通過監聽和模擬 `xhr 請求`來快速獲取,只能想辦法分析它的頁面結構,進行元素提取。
頁面通過分頁進行管理,例如其第二頁連結為`https://wh.lianjia.com/chengjiao/baibuting/pg2/`,遍歷分頁沒問題了。
有問題的是,通過首頁可以看到它的歷史資訊有 5 萬多條,一頁有 30 條,但它的主頁只顯示了 100 頁,沒辦法通過遍歷分頁獲取全部資料。
好在,鏈家提供了篩選器。經過測試,使用街道級的區域篩選可以滿足分頁的限制。
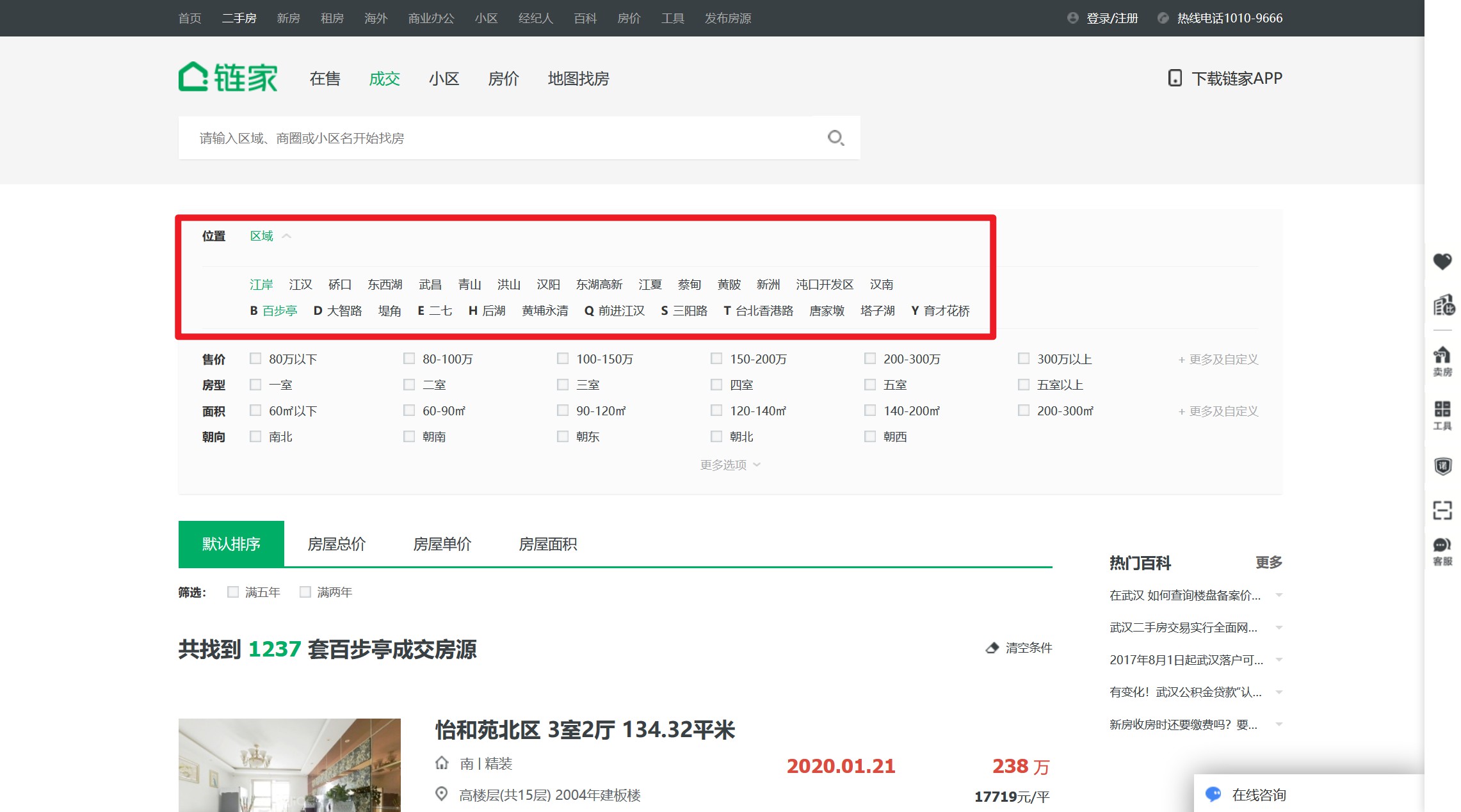
那麼爬取思路就是,遍歷`區級`按鈕,在每個區級按鈕下面遍歷其`街道按鈕`,在每個街道按鈕下,遍歷其每個分頁。
## 爬蟲庫
nodejs 領域的爬蟲庫,比較常用的有 `cheerio`、`pupeteer`。其中,`cheerio`一般用作靜態網頁的爬取,`pupeteer` 常用作爬取動態網頁。
雖然鏈家網頁是後臺靜態生成的,但是考慮到要對頁面進行操作(*點選其區域選擇器*),因此優先考慮選用 `pupeteer` 庫。
### pupeteer 庫
pupeteer 庫是谷歌瀏覽器在17年自行開發Chrome Headless特性後,與之同時推出的。本質上就是一個不含介面的瀏覽器,有點像電腦的終端,所有操作都通過程式碼進行操作。
這樣,我們就可以在對網站進行檢索之前,操作指定元素滾動到底部,以觸發更多資訊。或者在需要翻頁的時候,操作程式碼對翻頁按鈕進行點選,然後對翻頁後的頁面進行相關處理。
## 實現
這是其 [git 地址](https://github.com/puppeteer/puppeteer),這是其[中文教程](https://zhaoqize.github.io/puppeteer-api-zh_CN/)。
### 開啟待爬頁面
```js
// 1. 引包
const puppeteer = require('puppeteer');
// 2. 在非同步環境中執行(pupeteer 所有操作都是非同步實現的)
(async ()=>{
// 建立瀏覽器視窗
const browser = await puppeteer.launch({
headless: false, // 有介面模式,可以檢視執行詳情
});
// 建立標籤頁
const page = await browser.newPage();
// 進入待爬頁面
await page.goto('https://wh.lianjia.com/chengjiao/');
// 遍歷頁面
})()
```
這樣就成功在 `pupeteer` 中開啟鏈家網站了。
光開啟是不夠的,我們期待的是在網頁中操作篩選按鈕,獲取每個街道的頁面,以便我們遍歷其分頁進行查詢。
### 遍歷區級頁面
我們首先要找到區級按鈕,並點選它。
**標準思路**
```js
(async ()=>{
// ......
// 使用選擇器
/* page.$$() 會在頁面執行 document.querySelectorAll,並返回 ElementHandle 物件的陣列
page.$() 執行 document.querySelector,返回 ElementHandle 物件
*/
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
await district.click() // 模擬點選頁面物件
// 遍歷街道
}
})
```
第一想法大概是這樣寫,通過選擇器拿到所有按鈕,然後挨個點選。
恭喜,收到報錯一枚。
`Error: Execution context was destroyed, most likely because of a navigation.`
說你的執行上下文被幹掉了,可能是因為頁面的導航。
為了弄清這個問題,我們有必要先看一下`Execution context`是什麼東東。
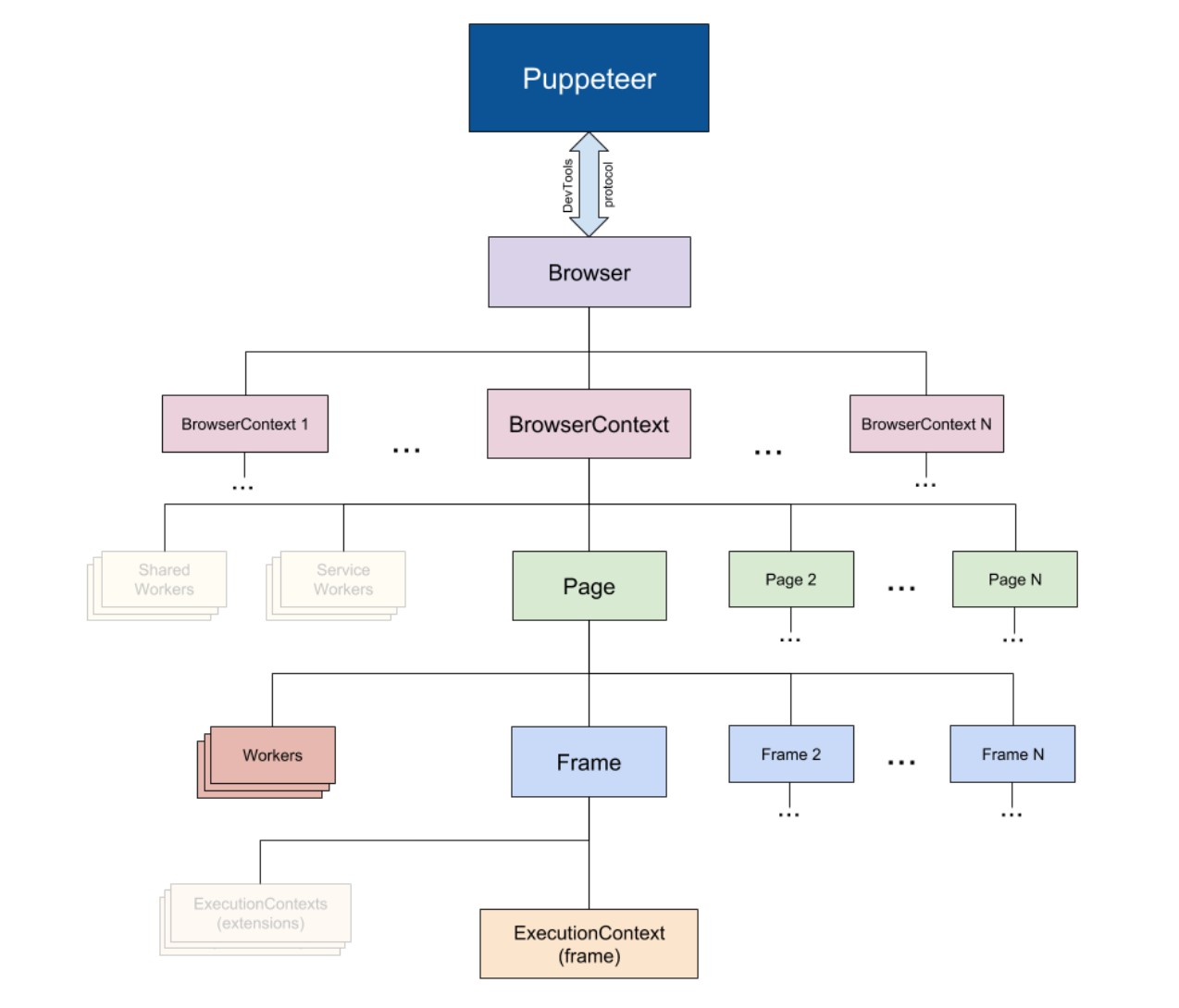
這是 `pupeteer` 內部的組織結構,一個 `page` 下面有很多個 `Frame` `,一個Frame` 下面有一個 `Execution context`。
我們這個報錯剛好就是在點選第二個按鈕時觸發的。
那就瞭然了。點選第一下導航成功, `page` 就變了,而你的第二個 `district` 還在依賴之前的那個 `page` ,結果找不到 `Execution context` ,然後就報錯了。
如何解決呢?
有兩個思路。
#### 方法一
將區級按鈕的連結快取下來,這樣在遍歷跳轉的時候,它就不會依賴 `原page` 。
```js
(async ()=>{
// ......
// 使用選擇器
/* page.$$eval('選擇器', callback(eles)) 會在page頁面內部執行 Array.from(document.querySelectorAll(selector)),然後把陣列引數傳給 callback
*/
let districts = await page.$$eval('div[data-role=ershoufang]>div>a',links=>{
// 對傳進來的元素處理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
for(let district of districts){
await page.goto(district) // 使用 page.goto() 替代點選
// 遍歷街道
}
})
```
這裡需要特殊解釋的是,對於頁面的操作如點選按鈕、導航連結等等都是在 `node` 裡完成的。而**在頁面之中的操作,比如讀取元素的某個屬性,是在瀏覽器的引擎裡處理的**,類似於 `html` 檔案中 `script` 標籤裡的指令碼。
對於 pupeteer ,它的指令碼檔案一般都被包裹在 `*.*eval()` 之中,譬如`page.evaluate(pageFunction[, ...args])`、 `page.$eval(selector,pageFunction, ...args)`、`elementHandle.$eval(selector, pageFunction, ...args)`。
**在這種指令碼中,無法訪問 `node` 環境下的全域性變數,除非你傳引數進去**:
```js
let name = 'bug'
page.$eval('id',(ele/* 這個引數是該方法自身返回的所選擇元素 */, nodeParam)=>{
console.log(nodeParam) // 'bug'
},name)
```
#### 方法二
另一個辦法,就是在進行連結跳轉時,不在 `原page` 直接跳,而是新開一個 `page2` 頁面。這樣你就不能使用點選,而是獲取其連結。
```js
(async ()=>{
// 新建一個標籤頁用來做跳轉快取
const page2 = await browser.newPage();
// ......
// 仍使用原方法獲取元素
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
let link = (await district.getProperty('href'))._remoteObject.value // 獲取屬性
await page2.goto(link) // 在新頁面跳轉,原 page 不變
// 遍歷街道
}
})
```
這兩種辦法都可行,不過第一種辦法似乎更簡單一點,將每個按鈕的連結都快取過後,似乎也沒有再保留 `原page` 的必要。
總之呢,我們現在已經能夠遍歷各個區級頁面了!
### 遍歷街道頁面
以下操作均在遍歷`區級頁面`的 `for` 迴圈中書寫。
操作與遍歷區級頁面類似,首先找到街道按鈕,然後迴圈跳轉。這裡的跳轉邏輯也跟上述類似,要麼選擇快取其連結,要麼新開一個 `page3` 做分頁迴圈。
我喜歡快取,畢竟新開頁面也要耗記憶體不是?
```js
(async ()=>{
let streets = await page.$$eval(
'div[data-role=ershoufang] div:last-child a', (links => {
// 對傳進來的元素處理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
)
for(let street of streets){
await page.goto(street) // 使用 page.goto() 替代點選
// 遍歷頁碼
}
})
```
### 遍歷分頁
因為分頁的連結處理比較簡單,遞增就可以了。
有個小問題,我們如何確定迴圈結束。
有幾個思路,
**第一**,街道首頁會顯示該區域共有多少套房,每個分頁是 `30` 套,除一下就可以了。
**第二**,我們可以獲取分頁按鈕的最後一個數值,不過遺憾的是最後一個數值大部分情況下是 `下一頁`,鑑於此我們也許可以做個 `while` 迴圈,當該分頁的最後一個按鈕不是 `下一頁` 時表示遍歷結束。但對於房數比較少的區域,也許只有兩三頁,本來就沒有`下一頁` 按鈕,那就會直接跳過漏爬。
**第三**,檢視一下頁面結構。以上都是從渲染過後的頁面上看到的資訊,而在頁面結構上也許有 `totalPage` 之類的欄位。仔細看了下分頁元件,果然在標籤屬性裡有總頁數。
以上思路中,第二個大概是最二的,然而我就是用的這個方法…出了好多低階錯誤,才換。其實第二個只要簡單優化一下也可以用,比如獲取分頁按鈕的最後一個,如果是`下一頁`,就獲取它前面的兄弟元素,還是能輕鬆得到總頁數。
總之讓我們用最簡單的吧:
```js
// 遍歷頁碼
let totalPage = await page.$eval('div.house-lst-page-box',el => {
return JSON.parse(el.getAttribute('page-data')).totalPage
})
for (let i = 1; i <= totalPage; i++) {
// 這裡的一個小優化,因為街道首頁即是第一頁,沒必要再跳
if(i >