
資料來源管理 | 關係型分庫分表,列式庫分散式計算
本文原始碼:GitHub·點這裡 || GitEE·點這裡
一、資料拆分概念
1、場景描述
隨著業務發展,資料量的越來越大,業務系統越來越複雜,拆分的概念邏輯就應運而生。資料層面的拆分,主要解決部分表資料過大,導致處理時間過長,長期佔用連結,甚至出現大量磁碟IO問題,嚴重影響效能;業務層面拆分,主要解決複雜的業務邏輯,業務間耦合度過高,容易引起雪崩效應,業務庫拆分,微服務化分散式,也是當前架構的主流方向。
2、基本概念
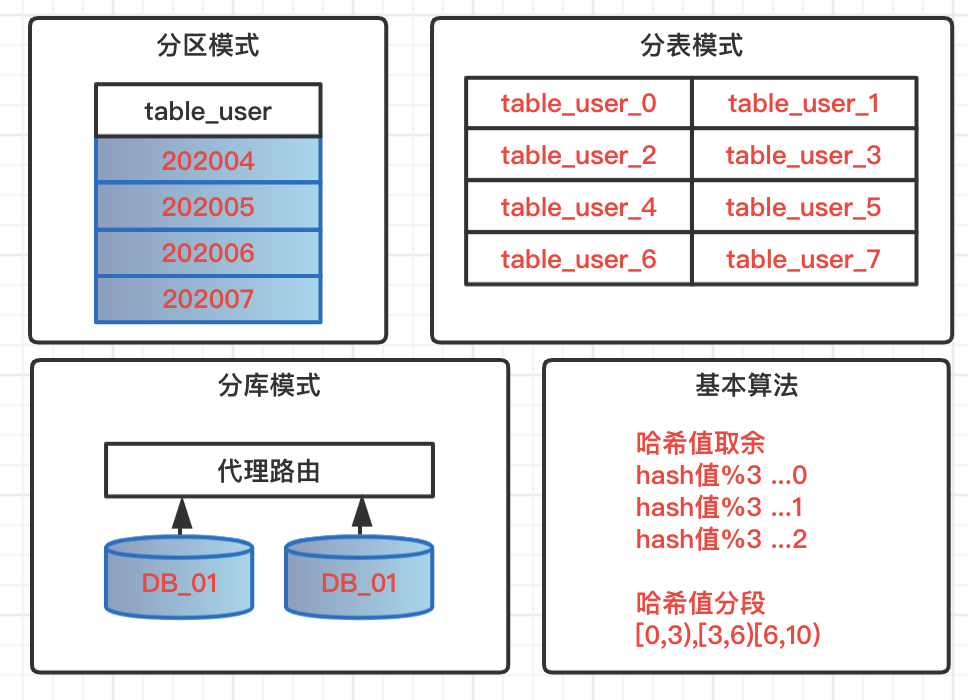
分割槽模式
針對資料表做分割槽模式,所有資料,邏輯上還存在一張表中,但是物理堆放不在一起,會根據一定的規則堆放在不同的檔案中。查詢資料的時候必須按照指定規則觸發分割槽,才不會全表掃描。不可控因素過多,風險過大,一般開發規則中都是禁止使用表分割槽。
分表模式
單表資料量過大,一般情況下單表資料控制在300萬,這裡的常規情況是指欄位個數,型別都不是極端型別,查詢也不存在大量鎖表的操作。超過該量級,這時候就需要分表操作,基於特定策略,把資料路由到不同表中,表結構相同,表名遵循路由規則。
分庫模式
在系統不斷升級,複雜化場景下,業務不好管理,個別資料量大業務影響整體效能,這時候可以考慮業務分庫,大資料量場景分庫分表,減少業務間耦合度,高併發大資料的資源佔用情況,實現資料庫層面的解耦。在架構層面也可以服務化管理,保證服務的高可用和高效能。
常用演算法
- 雜湊值取餘:根據路由key的雜湊值餘數,把資料分佈到不同庫,不同表;
- 雜湊值分段:根據路由key的雜湊值分段區間,實現資料動態分佈;
這兩種方式在常規下都沒有問題,但是一旦分庫分表情況下資料庫再次飽和,需要遷移,這時候影響是較大的。
二、關係型分庫
1、分庫基本邏輯
基於一個代理層(這裡使用Sharding-Jdbc中介軟體),指定分庫策略,根據路由結果,找到不同的資料庫,執行資料相關操作。
2、資料來源管理
把需要分庫的資料來源統一管理起來。
@Configuration public class DataSourceConfig { // 省略資料來源相關配置 /** * 分庫配置 */ @Bean public DataSource dataSource (@Autowired DruidDataSource dataZeroSource, @Autowired DruidDataSource dataOneSource, @Autowired DruidDataSource dataTwoSource) throws Exception { ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration(); shardJdbcConfig.getTableRuleConfigs().add(getUserTableRule()); shardJdbcConfig.setDefaultDataSourceName("ds_0"); Map<String,DataSource> dataMap = new LinkedHashMap<>() ; dataMap.put("ds_0",dataZeroSource) ; dataMap.put("ds_1",dataOneSource) ; dataMap.put("ds_2",dataTwoSource) ; Properties prop = new Properties(); return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop); } /** * 分表配置 */ private static TableRuleConfiguration getUserTableRule () { TableRuleConfiguration result = new TableRuleConfiguration(); result.setLogicTable("user_info"); result.setActualDataNodes("ds_${1..2}.user_info_${0..2}"); result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_phone", new DataSourceAlg())); result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_phone", new TableSignAlg())); return result; } }
3、指定路由策略
- 路由到庫
根據分庫策略的值,基於hash演算法,判斷路由到哪個庫。has演算法不同,不但影響庫的操作,還會影響資料入表的規則,比如偶數和奇數,導致入表的奇偶性。
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
String dataName = "ds_" + ((hash % 2) + 1) ;
LOG.debug("分庫演算法資訊:{},{},{}",names,value,dataName);
return dataName ;
}
}
- 路由到表
根據分表策略的配置,基於hash演算法,判斷路由到哪張表。
public class TableSignAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableSignAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
String tableName = "user_info_" + (hash % 3) ;
LOG.debug("分表演算法資訊:{},{},{}",names,value,tableName);
return tableName ;
}
}
上述就是基於ShardingJdbc分庫分表的核心操作流程。
三、列式庫統計
1、列數資料
在相對龐大的資料分析時,通常會選擇生成一張大寬表,並且存放到列式資料庫中,為了保證高效率執行,可能會把資料分到不同的庫和表中,結構一樣,基於多執行緒去統計不同的表,然後合併統計結果。
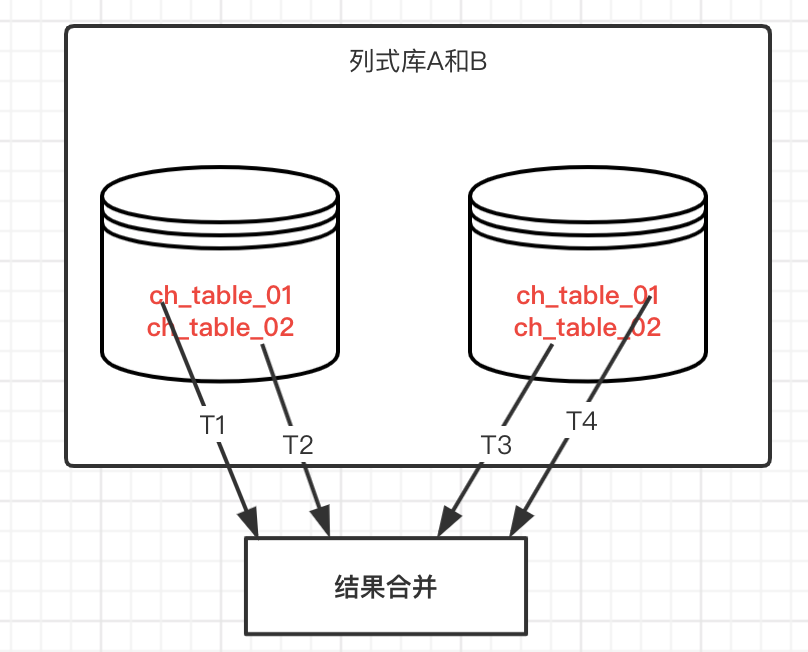
基本原理:多執行緒併發去執行不同的表的統計,然後彙總統計,相對而言統計操作不難,但是需要適配不同型別的統計,比如百分比,總數,分組等,編碼邏輯相對要求較高。
2、列式資料來源
基於ClickHouse資料來源,演示案例操作的基本邏輯。這裡管理和配置庫表。
核心配置檔案
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
# ClickHouse資料01
ch-data01:
driverClassName: ru.yandex.clickhouse.ClickHouseDriver
url: jdbc:clickhouse://127.0.0.1:8123/query_data01
tables: ch_table_01,ch_table_02
# ClickHouse資料02
ch-data02:
driverClassName: ru.yandex.clickhouse.ClickHouseDriver
url: jdbc:clickhouse://127.0.0.1:8123/query_data02
tables: ch_table_01,ch_table_02
核心配置類
@Component
public class ChSourceConfig {
public volatile Map<String, String[]> chSourceMap = new HashMap<>();
public volatile Map<String, Connection> connectionMap = new HashMap<>();
@Value("${spring.datasource.ch-data01.url}")
private String dbUrl01;
@Value("${spring.datasource.ch-data01.tables}")
private String tables01 ;
@Value("${spring.datasource.ch-data02.url}")
private String dbUrl02;
@Value("${spring.datasource.ch-data02.tables}")
private String tables02 ;
@PostConstruct
public void init (){
try{
Connection connection01 = getConnection(dbUrl01);
if (connection01 != null){
chSourceMap.put(connection01.getCatalog(),tables01.split(","));
connectionMap.put(connection01.getCatalog(),connection01);
}
Connection connection02 = getConnection(dbUrl02);
if (connection02 != null){
chSourceMap.put(connection02.getCatalog(),tables02.split(","));
connectionMap.put(connection02.getCatalog(),connection02);
}
} catch (Exception e){e.printStackTrace();}
}
private synchronized Connection getConnection (String jdbcUrl) {
try {
DriverManager.setLoginTimeout(10);
return DriverManager.getConnection(jdbcUrl);
} catch (Exception e) {
e.printStackTrace();
}
return null ;
}
}
3、基本任務類
既然基於多執行緒統計,自然需要一個執行緒任務類,這裡演示count統計模式。輸出單個執行緒統計結果。
public class CountTask implements Callable<Integer> {
private Connection connection ;
private String[] tableArray ;
public CountTask(Connection connection, String[] tableArray) {
this.connection = connection;
this.tableArray = tableArray;
}
@Override
public Integer call() throws Exception {
Integer taskRes = 0 ;
if (connection != null){
Statement stmt = connection.createStatement();
if (tableArray.length>0){
for (String table:tableArray){
String sql = "SELECT COUNT(*) AS countRes FROM "+table ;
ResultSet resultSet = stmt.executeQuery(sql) ;
if (resultSet.next()){
Integer countRes = resultSet.getInt("countRes") ;
taskRes = taskRes + countRes ;
}
}
}
}
return taskRes ;
}
}
4、執行緒結果彙總
這裡主要啟動執行緒的執行,和最後把每個執行緒的處理結果進行彙總。
@RestController
public class ChSourceController {
@Resource
private ChSourceConfig chSourceConfig ;
@GetMapping("/countTable")
public String countTable (){
Set<String> keys = chSourceConfig.chSourceMap.keySet() ;
if (keys.size() > 0){
ExecutorService executor = Executors.newFixedThreadPool(keys.size());
List<CountTask> countTasks = new ArrayList<>() ;
for (String key:keys){
Connection connection = chSourceConfig.connectionMap.get(key) ;
String[] tables = chSourceConfig.chSourceMap.get(key) ;
CountTask countTask = new CountTask(connection,tables) ;
countTasks.add(countTask) ;
}
List<Future<Integer>> countList = Lists.newArrayList();
try {
if (countTasks.size() > 0){
countList = executor.invokeAll(countTasks) ;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
Integer sumCount = 0 ;
for (Future<Integer> count : countList){
try {
Integer countRes = count.get();
sumCount = sumCount + countRes ;
} catch (Exception e) {e.printStackTrace();}
}
return "sumCount="+sumCount ;
}
return "No Result" ;
}
}
5、最後總結
關係型分庫,還是列式統計,都是基於特定策略把資料分開,然後路由找到資料,執行操作,或者合併資料,或者直接返回資料。
四、原始碼地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推薦閱讀:資料管理
| 序號 | 標題 |
|---|---|
| 01 | 資料來源管理:主從庫動態路由,AOP模式讀寫分離 |
| 02 | 資料來源管理:基於JDBC模式,適配和管理動態資料來源 |
| 03 | 資料來源管理:動態許可權校驗,表結構和資料遷移流程 |