
負載均衡服務之HAProxy基礎配置(二)
前文我們聊了下haproxy的global配置段中的常用引數的說明以及使用,回顧請參考https://www.cnblogs.com/qiuhom-1874/p/12763245.html;今天我們來說說haproxy的代理配置段中比較重要的引數配置的用法;
代理配置段中分三段配置,第一段是defaults配置段,這一段我們在上一篇部落格中也說過,主要用於定義一些預設引數配置;第二段是frontend配置段,該段主要用來定義haporxy面向客戶端怎樣提供服務的;比如監聽在那個地址的那個埠啊,排程那個後端伺服器組呀等等;第三段就是後端伺服器的配置段,通常frontend和backend是聯合使用,也就是說frontend必須呼叫一個已經定義好的backend這樣才能夠完全的把使用者的請求排程到對應伺服器或者伺服器組上;而對於listen來講,它更像一個代理的角色,它既可以定義前端對於使用者端監聽地址資訊,同時它也能定義後端server的屬性;簡單講listen指令融合了frontend和backend的功能;瞭解瞭如何定義前端監聽地址以及後端被代理的server的方式後,接下來我們一一來看下代理配置段中的配置;
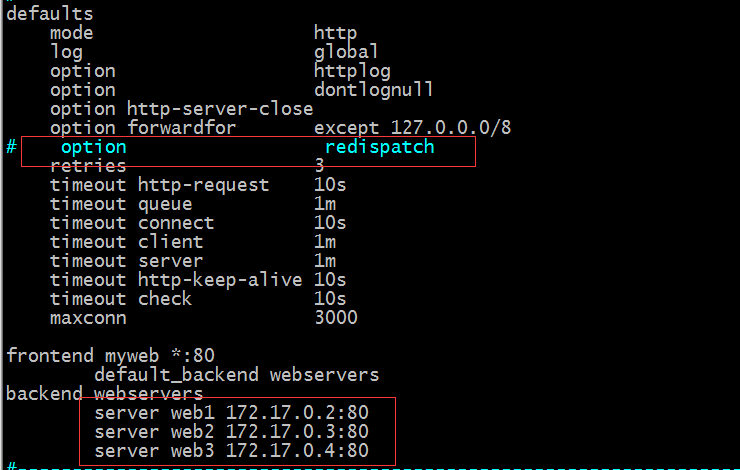
defaults裡的配置
mode:該指令用於指定haporxy的工作型別的;http表示haproxy基於http協議代理後端伺服器,這也是預設haproxy的工作型別;如果我們在後端backend或listen中沒有配置haporxy的工作型別,預設就會繼承defaults裡的配置;tcp表示haproxy基於tcp協議代理後端伺服器響應客戶端請求;
option redispatch :當後端server宕機後,強制把請求定向到其他健康的伺服器上;正是因為這個引數,就確保了使用者端請求不會被排程到一個宕機的伺服器上;
示例:我們把option redispatch 這個配置註釋掉,重啟haproxy,然後把後端容器給停掉一臺,看看haproxy會不會把對應的請求排程到停掉的server上呢?
提示:我們只是註釋了option redispatch 這段配置;對於後端伺服器並沒有人為手動的去修改;正常情況下,三臺伺服器如果都是正常的情況,是能夠輪詢的方式響應客戶端請求的;現在我們把後端伺服器停一臺看看使用者的請求會不會排程到停掉的那臺伺服器上呢?

提示:現在我們可以看到web2的狀態是退出狀態,不能夠響應客戶端的請求的;接下來我們用瀏覽器訪問haproxy對外提服務的IP地址和埠;看看是否把使用者請求排程到宕機的主機上

提示:可以看到haproxy還是把使用者端請求往宕機的主機上排程;我們把option redispatch 配置開啟,然後重啟haproxy,在看看會不會把使用者請求排程到宕機的主機上

提示:我們開啟option redispatch 配置,然後重啟haproxy;對於web2現在還是宕機的狀態,我們再用瀏覽器訪問,看看這次會不會把使用者請求排程到宕機的web2上呢

提示:我們把option redispatch 配置加上後,我們用瀏覽器訪問haproxy的80埠,它不會把使用者端請求排程到web2上去,原因就是因為檢測web2沒有通過,強制把請求排程到下一個伺服器上去了;之所以我們看到中間有一段時間要等,是因為haproxy在對web2進行檢測;
option abortonclose:當伺服器負載很高的時候,自動結束掉當前佇列處理比較久的連結;
option http-keep-alive 60:開啟會話保持,並設定時長為60s
option forwardfor:開啟IP透傳;這個引數的意思是把客戶端的源ip資訊通過X-Forwarded-For首部傳給後端server,後端server可通過撲捉haproxy發來的請求報文,把對應X-Forwarded-For首部的值記錄下來;通常需要後端伺服器更改日誌格式,把對應首部的值加入到日誌中顯示;
示例:配置後端server記錄haproxy發來的請求報文中X-Forwarded-For首部的值;

提示:我們在web1上修改了httpd的日誌格式,讓第一個欄位記錄X-Forwarded-For首部的值;然後讓httpd重讀配置檔案;接下來我們就可以用瀏覽器訪問haproxy,看看web1是否能夠把客戶端的源ip記錄下來
提示:可以看到當haproxy把我們的請求排程到web1上時,對應web1的日誌就會把X-Forwarded-For的值記錄下來;這個首部的值就是記錄客戶端的源ip地址的;這樣一來我們後端server上的日誌就不再只有haproxy代理的的地址了;
timeout connect 60s:轉發客戶端請求到後端server的最長連線時間;這個時間是定義代理連線後端伺服器的超時時長;
timeout server 600s :轉發客戶端請求到後端服務端的超時超時時長;這個時間是服務端響應代理的超時時長;
timeout client 600s :與客戶端的最長空閒時間;
timeout http-keep-alive 120s:session 會話保持超時時間,範圍內會轉發到相同的後端伺服器;
timeout check 5s:對後端伺服器的檢測超時時間;
retries 3:定義重試次數;
maxconn 3000:server的最大連線數(通常這個會配置在各server後面,用來指定該server的最大連線數)
以上就是haproxy defaults配置段的常用配置說明和使用;接下來我們來說一下frontend 配置段和backend配置段
frontend配置段裡的指令配置
bind:該指令用於指定繫結IP和埠的,通常用於frontend配置段中或listen配置段中;用法是bind [IP]:<PORT>,……
示例:

提示:以上配置表示前端監聽80埠和8080埠,這兩個埠都可以把使用者端請求代理到後端指定的伺服器組上進行響應;
測試:重啟haproxy 用瀏覽器訪問192.168.0.22:8080埠,看看是否能夠響應?

提示:可以看到我們用瀏覽器訪問8080也是能夠正常響應的;
除此以外,前端監聽埠我們也可以不用bind引數指定 我們直接在frontend 或listen名字後面加要監聽的地址和埠即可,如下所示

提示:listen的配置也是支援以上兩種的形式去監聽埠的;通常不寫IP地址表示監聽本機所以ip地址對應的埠;
balance:指定後端伺服器組內的伺服器排程演算法;這個指令只能用於listen和backend或者defaults配置段中;
roundrobin:動態輪詢;支援權重的執行時調整,支援慢啟動,每個後端中最多支援4095個server;什麼意思呢?動態調整權重就是說不重啟服務的情況下調整權重;慢啟動說的是,前端的流量不會一下子全部給打進來,而是一部分一部分的打到後端伺服器上;這樣可以有效防止流量過大時一下子把後端伺服器壓垮的情況;後端最多支援4095個server表示在一個backend或listen中使用該演算法最多隻能定義4095個server;通常對於生產環境這個也是夠用了;
static-rr:靜態輪詢,不支援權重的執行時調整,不支援慢啟動;這也是靜態演算法的確定;但這種演算法對後端server沒有限制;
leastconn:最少連線演算法;該演算法本質上同static-rr沒有太多的不同,通常情況下static-rr用於短連線場景中;而leastconn多用於長連線的場景中,如MySQL、LDAP等;
first:根據伺服器在列表中的位置,自上而下進行排程;前面伺服器的連線數達到上限,新請求才會分配給下一臺服務;
source:源地址hash演算法;類似LVS中的sh演算法;hash類的演算法動態與否取決於hash-type的值;如果我們定義hash-type的值為map-based(除權取餘法)就表示該演算法是靜態演算法,靜態演算法就不支援慢啟動,動態調整權重;如果hash-type的值是consistent(一致性雜湊)就表示該演算法是動態演算法,支援慢啟動,動態權重調整;
uri:對URI的左半部分做hash計算,並由伺服器總權重相除以後派發至某挑出的伺服器;這裡說一下一個完整的rul的格式;<scheme>://[user:password@]<host>:<port>[/path][;params][?query][#frag]其中scheme,host,port這三項是必須有的,其他可有可無;這裡說的uri就是指[/path][;params][?query][#frag]這一部分,而uri的左半部份指的是[/path][;params];所以uri演算法是對使用者請求的資源路徑+引數做hash計算;
url_param:對使用者請求的uri的<params>部分中的引數的值作hash計算,並由伺服器總權重相除以後派發至某挑出的伺服器;通常用於追蹤使用者,以確保來自同一個使用者的請求始終發往同一個Backend Server;
hdr(<name>):對於每個http請求,此處由<name>指定的http首部將會被取出做hash計算; 並由伺服器總權重相除以後派發至某挑出的伺服器;沒有有效值的會被輪詢排程; 如hdr(Cookie)使用cookie首部做hash,把同一cookie的訪問始終排程到某一臺後端伺服器上;
示例:使用uri演算法,並指定使用一致性hash演算法
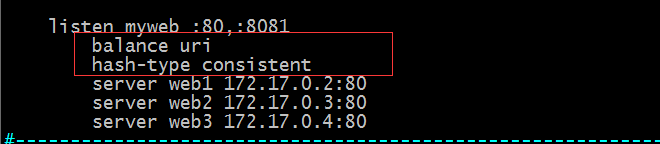
提示:這樣配置後,使用者訪問80埠的某一個uri始終會發往同一臺伺服器上;不管是那個使用者去訪問都會被排程到同一臺伺服器上進行響應
我們在後端伺服器上提供一些預設的頁面,分別用不同的客戶主機去訪問相同的rul看看haproxy會怎麼排程?
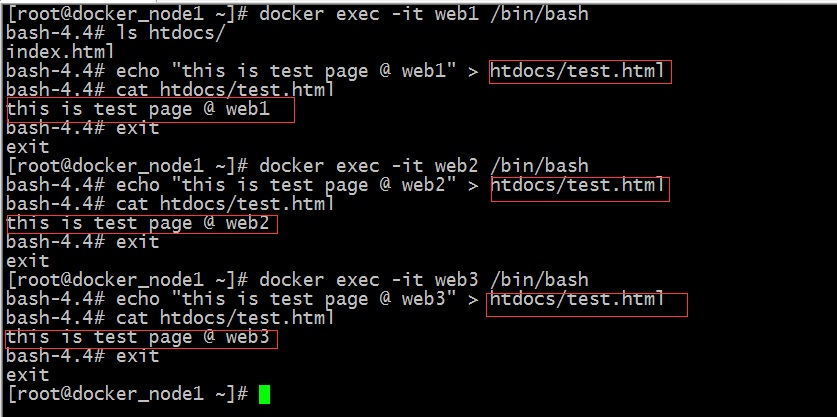
提示:在三個容器內部分別新建了一個test.html的檔案,其內容都是不相同的;接下來我們用瀏覽器訪問/test.html看看會怎麼排程

提示:可以看到我們不管是用windows上的瀏覽器訪問還是用Linux中的curl訪問 都是被排程到web1上去了;其他演算法我這裡就不過多去測試了,有興趣的小夥伴可自己動手去試試,看看效果;
default_backend <backend>:設定預設的backend,用於frontend中;
use_backend <backend>:呼叫對應的backend,用於frontend中;
示例:

提示:以上配置表示使用者訪問80埠或8081埠,都會被排程到webservs這個後端伺服器組上進行響應;
server <name> <address>[:[port]] [param*]:定義後端主機的各伺服器及其選項;name表示伺服器在haproxy上的內部名稱;出現在日誌及警告資訊中;address表示伺服器地址,支援使用主機名;port:埠對映;省略時,表示同bind中繫結的埠;param表示引數;常用的引數有如下幾個:
maxconn <maxconn>:當前server的最大併發連線數;
backlog <backlog>:當前server的連線數達到上限後的後援佇列長度;
backup:設定當前server為備用伺服器;和nginx裡的sorry server 是一樣的;
cookie <value>:為當前server指定其cookie值,用於實現基於cookie的會話黏性;
disabled:標記為不可用;相當於nginx裡的down;
redir <prefix>:將發往此server的所有GET和HEAD類的請求重定向至指定的URL;
weight <weight>:權重,預設為1;
on-error <mode>:後端服務故障時採取的行動策略;策略有如下幾種:
fastinter:表示縮短健康狀態檢測間的時長;
fail-check:表示即健康狀態檢測失敗,也要檢測;這是預設策略;
sudden-death:模擬一個致命前的失敗的健康檢查,一個失敗的檢查將標記伺服器關閉,強制fastinter
mark-down:立即標記伺服器不可用,並強制fastinter;
check:對當前server做健康狀態檢測;
addr :檢測時使用的IP地址;
port :針對此埠進行檢測;
inter <delay>:連續兩次檢測之間的時間間隔,預設為2000ms;
rise <count>:連續多少次檢測結果為“成功”才標記伺服器為可用;預設為2;
fall <count>:連續多少次檢測結果為“失敗”才標記伺服器為不可用;預設為3;
示例:
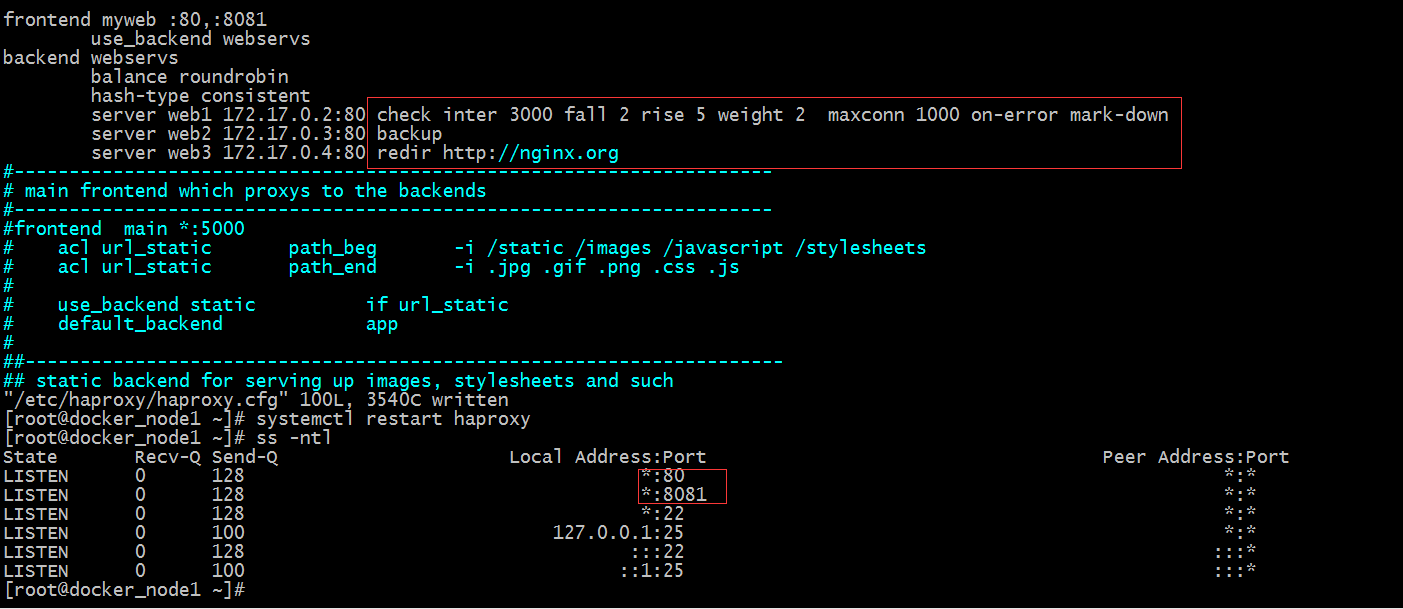
提示:以上配置表示對web1進行健康狀態檢測 每隔3000毫秒檢測一次,檢測2次失敗就立刻標記為不可用,並強制縮短檢測間隔時長;權重為2,意思是該伺服器被排程兩次,其他伺服器排程一次;最大連線為1000;web2配置為backup角色,只有當web1和web3宕機後,web2才被排程;訪問web3的請求直接重定向到http://nginx.org上響應;接下來我們如果訪問haproxy的80或8081埠,應該是可以訪問到web1和web3;如果web1和web3宕機後,web2就會被排程;
測試:在web1和web3都正常的情況下,看看web2是否被排程?
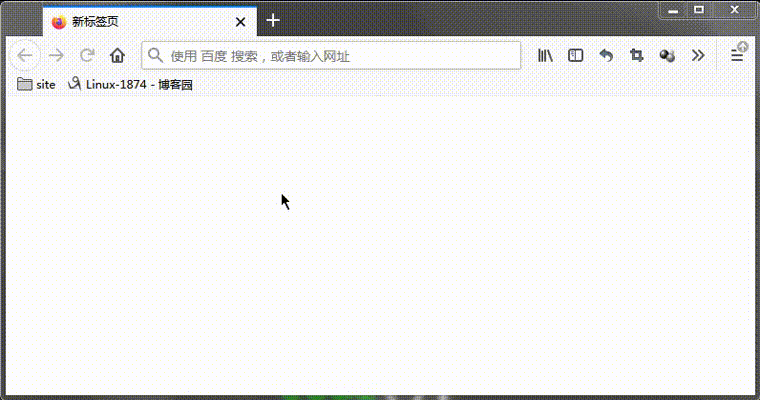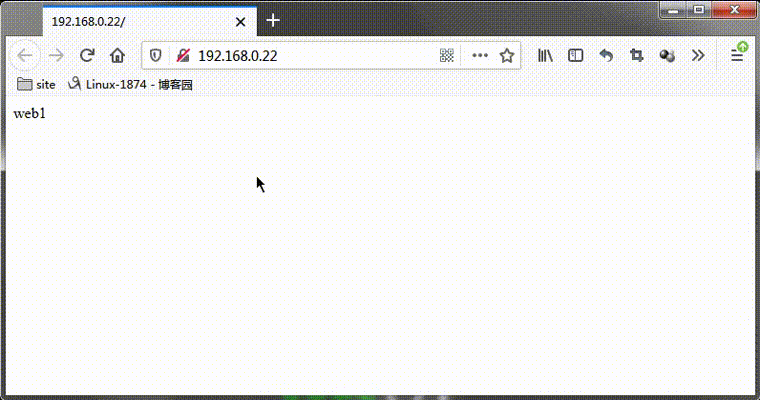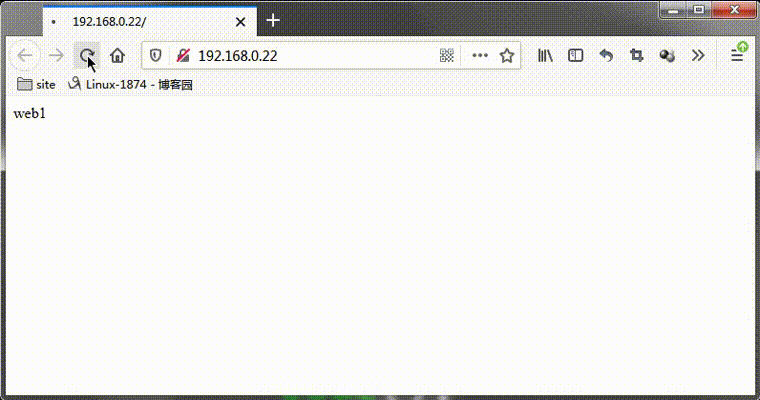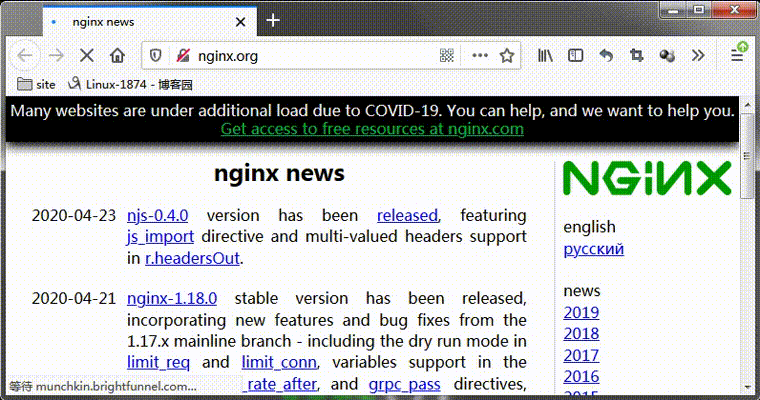
提示:可以看到web2是沒有被排程的,web1被排程兩次後,直接跳過web2,排程web3去了;
測試:把web1和web3停了,看看web2是否被排程?

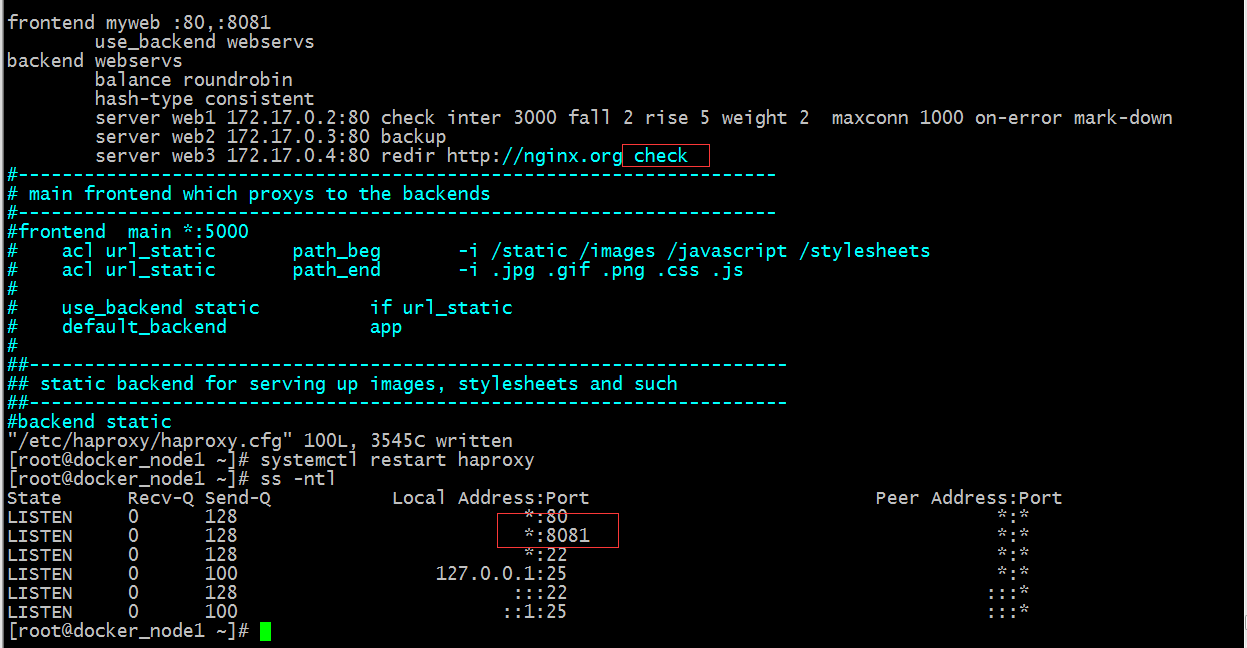
提示:我們把web1和web3給停了,用瀏覽器訪問,它還是跳轉了;這說明redir不關心所在server是否存活;要想backup被啟用必須讓haproxy知道對應後端伺服器組裡是否有活躍的伺服器,如果有,它就不會啟用backup,如果沒有就會啟用;但現在haproxy不知道,原因是web3壓根沒有做健康狀態檢測;所以要想啟用backup,我們需要在web3上配置一個check即可;但是這樣一來,跳轉就失效了;如下
提示:我們在web3上加入健康狀態檢測後服務能夠正常起來;用瀏覽器訪問backup是被激活了,但是web3上線後,對應跳轉就失效了;如下
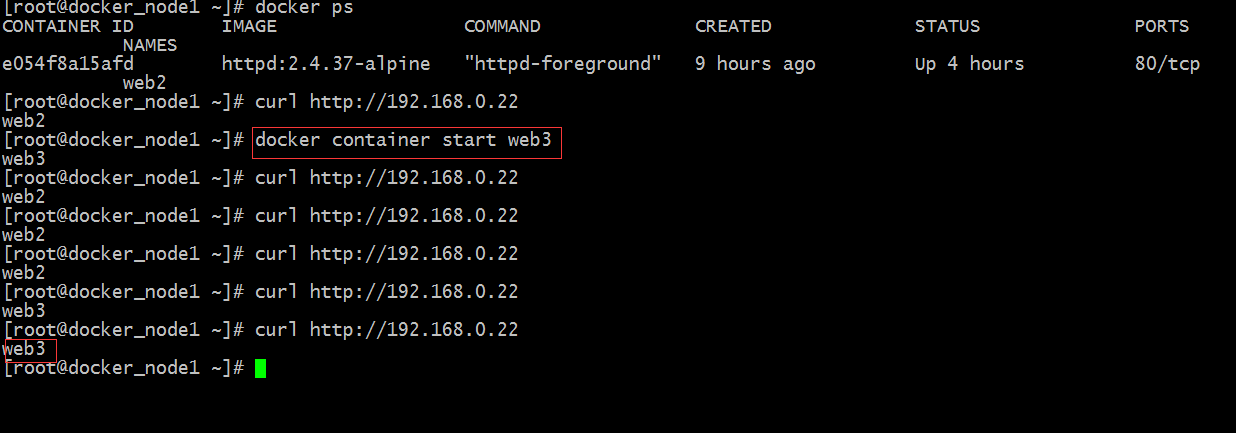
總結一點:redir和check不能同時使用,同時使用redir優先順序小於chec