
Python爬蟲---爬取騰訊動漫全站漫畫
阿新 • • 發佈:2020-04-25
[TOC]
##操作環境
1. 編譯器:pycharm社群版
2. python 版本:anaconda python3.7.4
3. 瀏覽器選擇:Google瀏覽器
4. 需要用到的第三方模組:requests , lxml , selenium , time , bs4,os
##網頁分析
###明確目標
首先我們開啟[騰訊動漫](https://ac.qq.com/)首頁,分析要抓取的目標漫畫。
找到騰訊動漫的漫畫目錄頁,簡單看了一下目錄,發現全站的漫畫數量超過了三千部(感覺就是爬下來也會把記憶體撐爆)
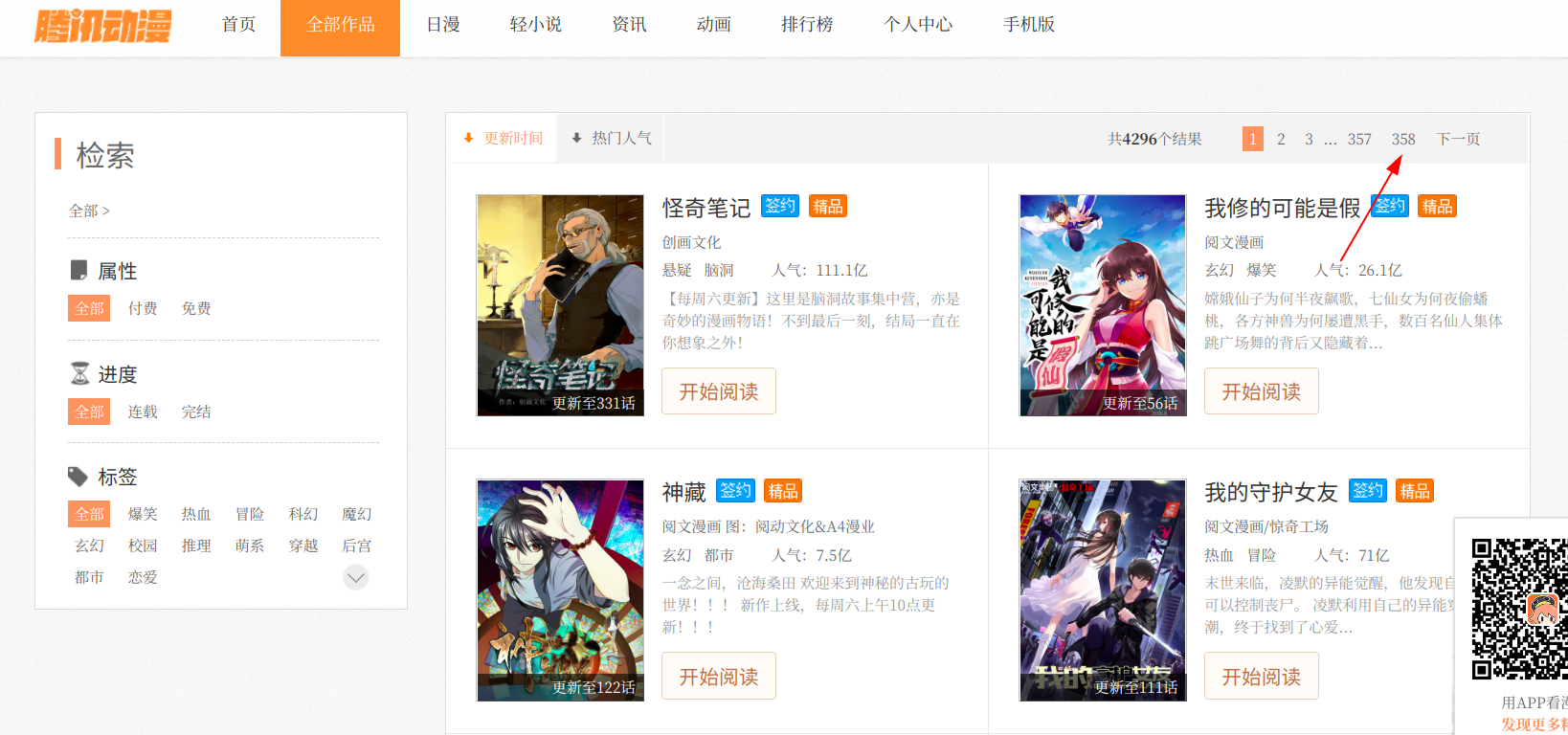
於是我覺得爬取首頁的推薦漫畫會是一個比較好的選擇(爬取全站漫畫只需要稍稍改一下網址構造就可以做到了)
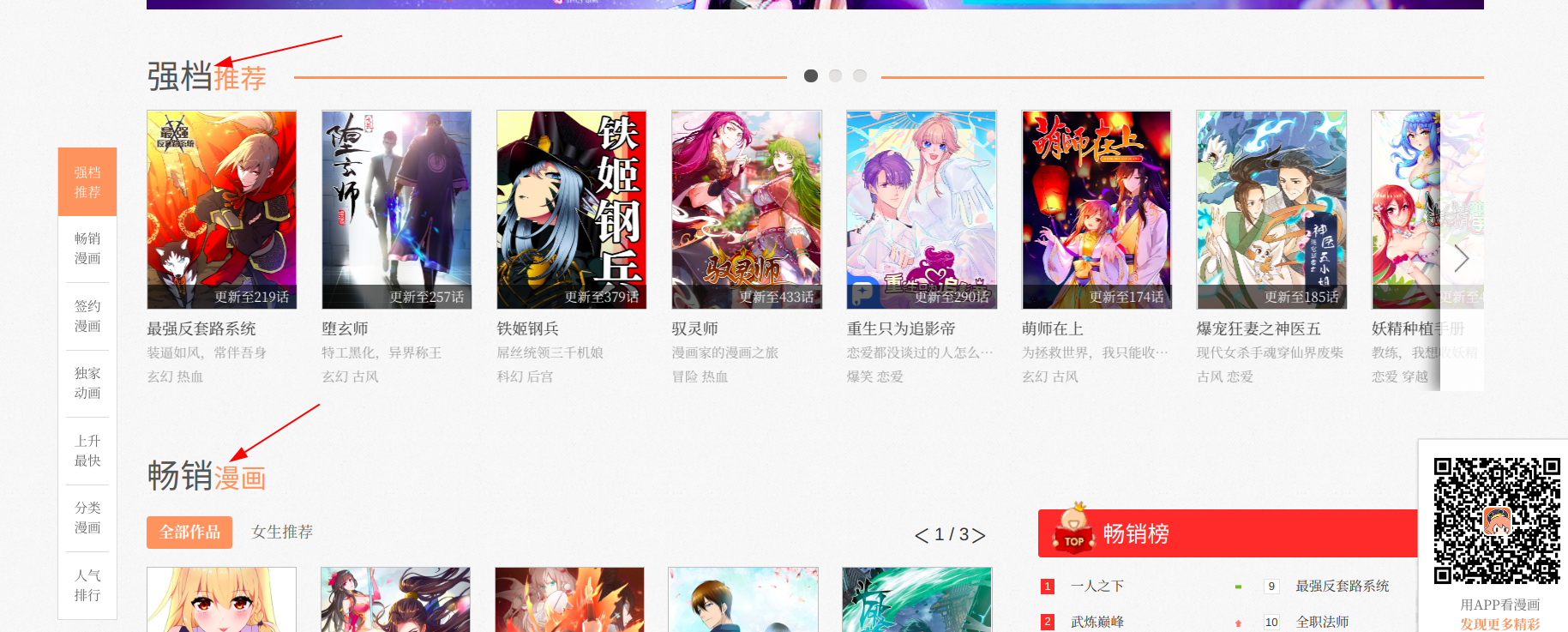
###提取漫畫地址
選定了物件之後,就應該想辦法來搞到漫畫的地址了
右擊檢查元素,粗略看一遍網頁的原始碼,這時我發現裡面有很多連續的標籤,我猜測每部漫畫的地址資訊就儲存在這些標籤裡面

隨便開啟一個《li》標籤,點選裡面包裹的連結地址會跳轉到一個新的網頁,這個網頁正是我想要找的漫畫地址,可以見得我的猜測是正確的,等到實際操作的時候再用表示式提取資訊就非常容易了
###提取漫畫章節地址
進入漫畫的目錄頁,發現一頁最多可以展示20章的漫畫目錄,要想更換顯示還需要點選章節名上面的選項卡來顯示其他章節的地址
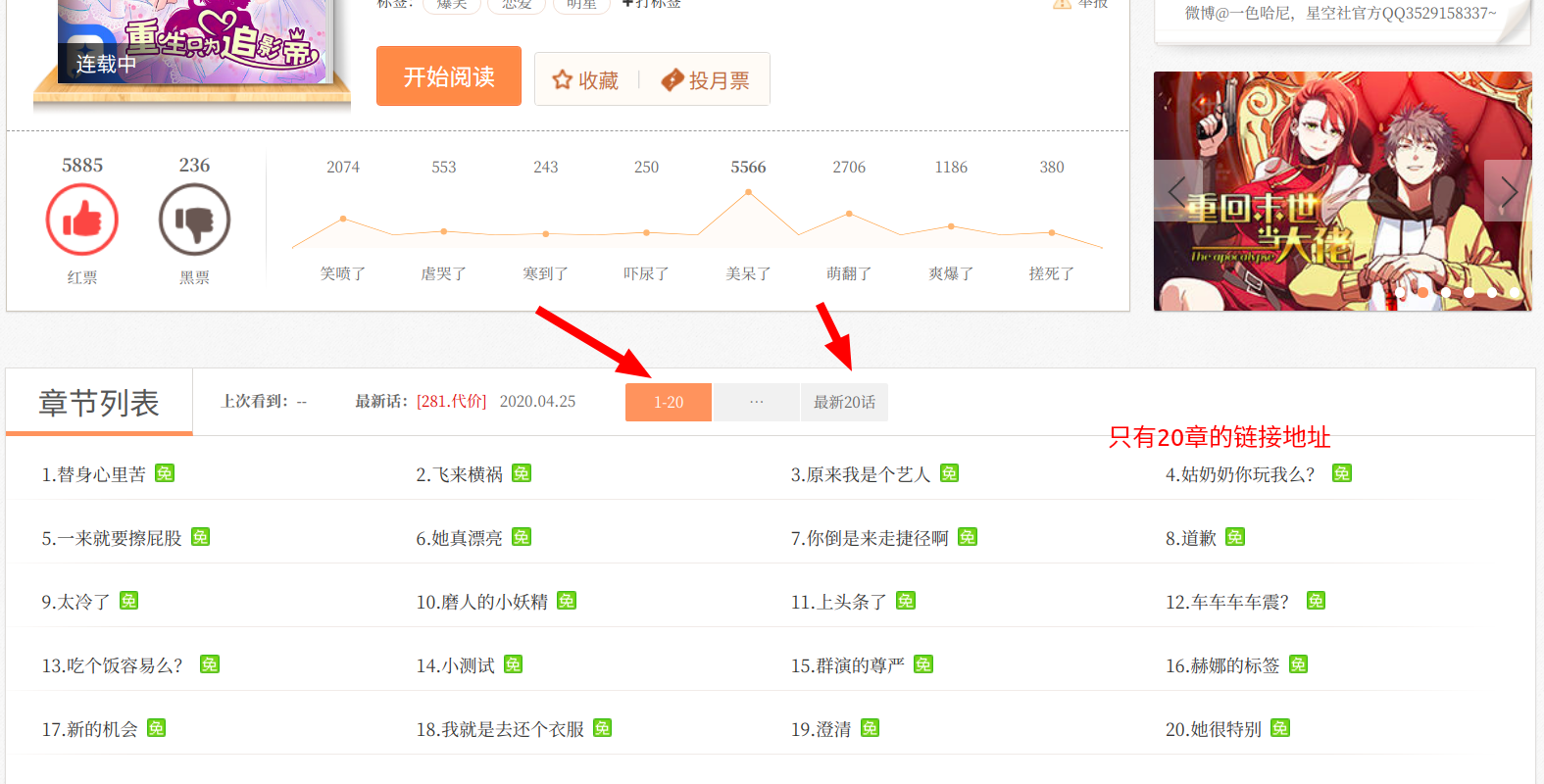
接下來就需要我們來檢查網頁元素想辦法來獲取章節地址了,同樣右擊檢查元素
在看到了原始碼後,我發現了一個非常驚喜的事情,這個原始碼裡面包含這所有的章節連結,而不是通過動態載入來展示的,這就省去了我們提取其他章節連結的功夫,只需要花心思提取漫畫圖片就可以了
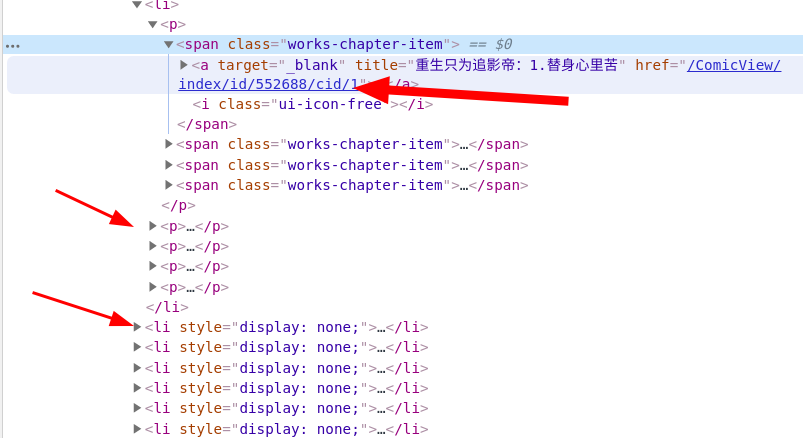
這裡每個《p》標籤下包含了五個《a》標籤,每個《li》標籤下包含了四個《p》標籤,而每個漫畫的連結就存在每個《a》標籤中,可以輕鬆通過語法來提取到每頁的連結資訊
###提取漫畫圖片
怎麼將漫畫的圖片地址提取出來並儲存到本地,這是這個程式碼的難點和核心
先是開啟漫畫,這個漫畫頁應該是被加上了某些措施,所以它沒辦法使用右鍵檢視網頁原始碼,但是使用快捷鍵[ctrl + shift +i]是可以看到的
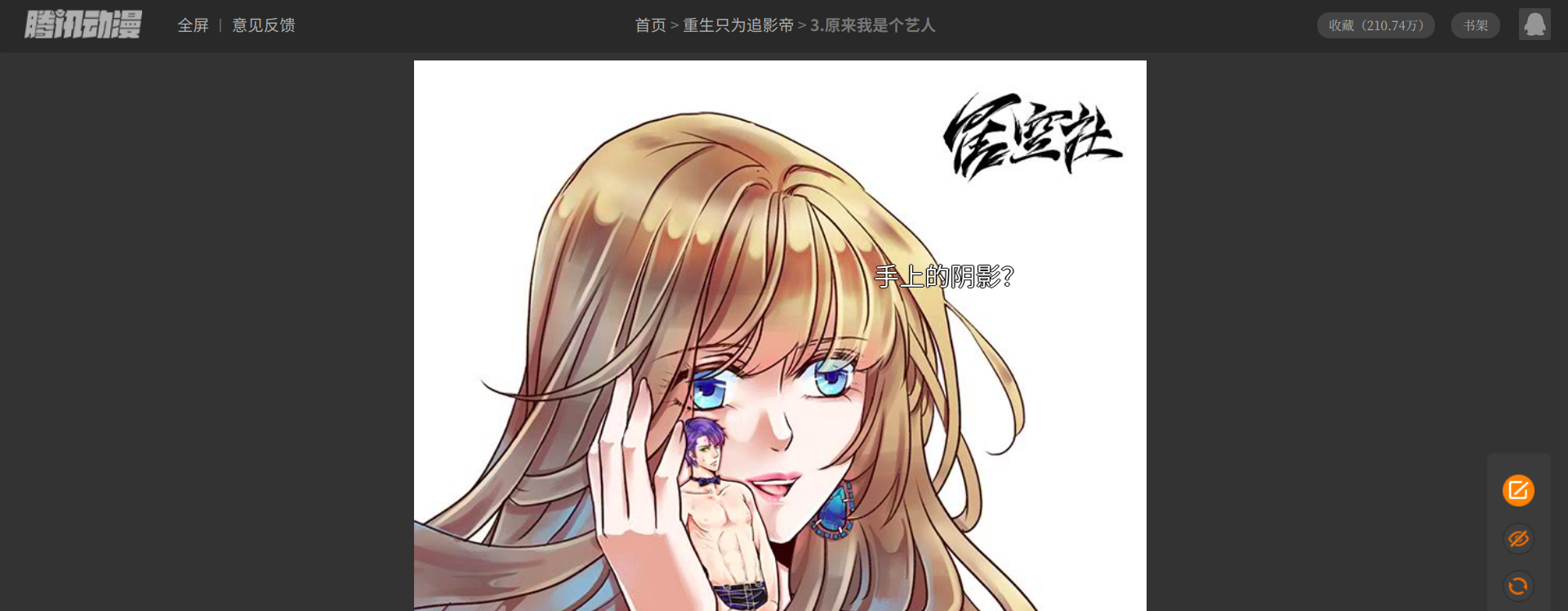
按下[ctrl + shift + i],檢查元素

通過第一次檢查,可以發現網頁的元素中只有前幾張圖片的地址資訊,後面的資訊都為字尾.gif的檔案表示,這些gif檔案就是圖片的載入動畫
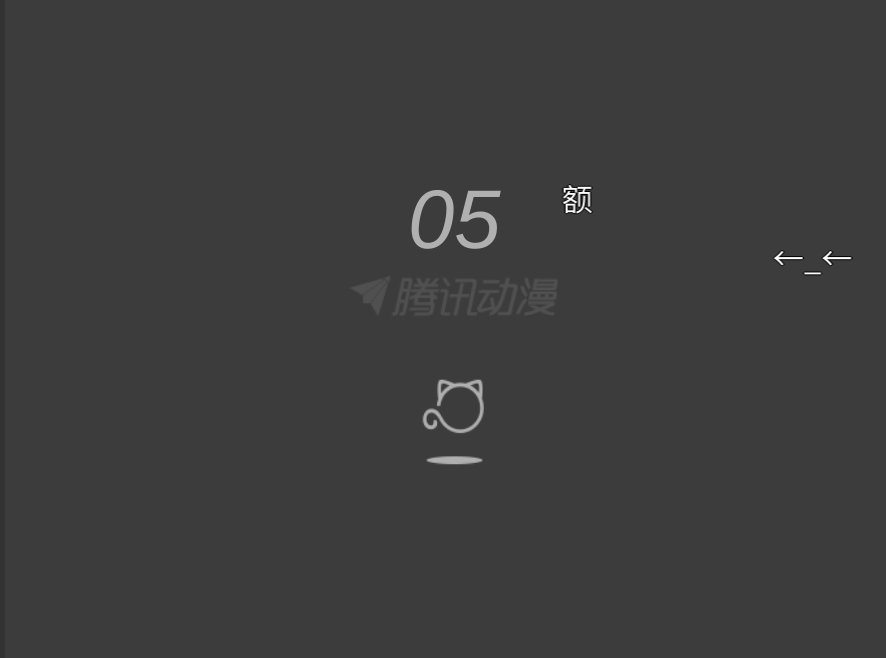
接著向下滑動到底部,等待圖片全部顯示出來再次檢查元素
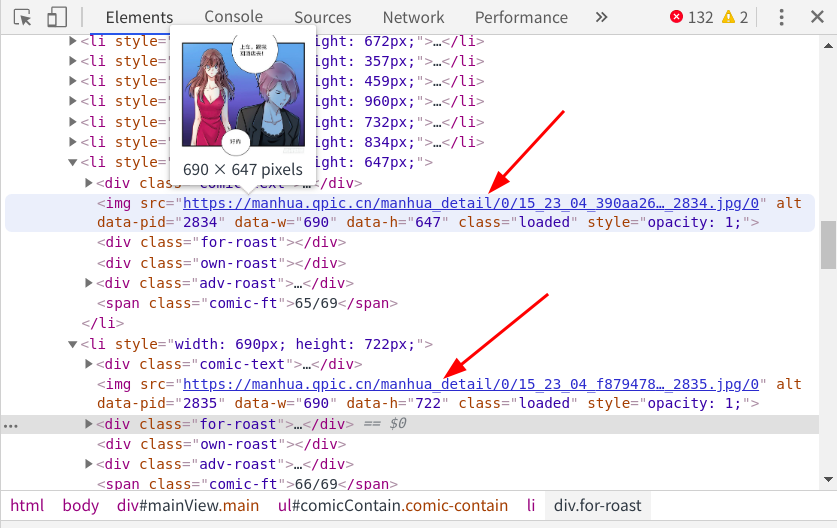
現在所有的漫畫圖片全部顯示出來,下方並無.gif 的檔案,由此可知,騰訊動漫是以js非同步載入來顯示圖片的,要想獲取頁面的全部圖片,就必須要滑動滾動條,將全部的圖片載入完成再進行提取,這裡我選擇selenium模組和chromedriver來幫助我完成這些操作。下面開始進行程式碼的編寫。
##編寫程式碼
###匯入需要的模組
```
import requests
from lxml import etree
from selenium import webdriver #selenium模擬操作
from time import sleep
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options #谷歌無頭瀏覽器
import os
```
###獲取漫畫地址
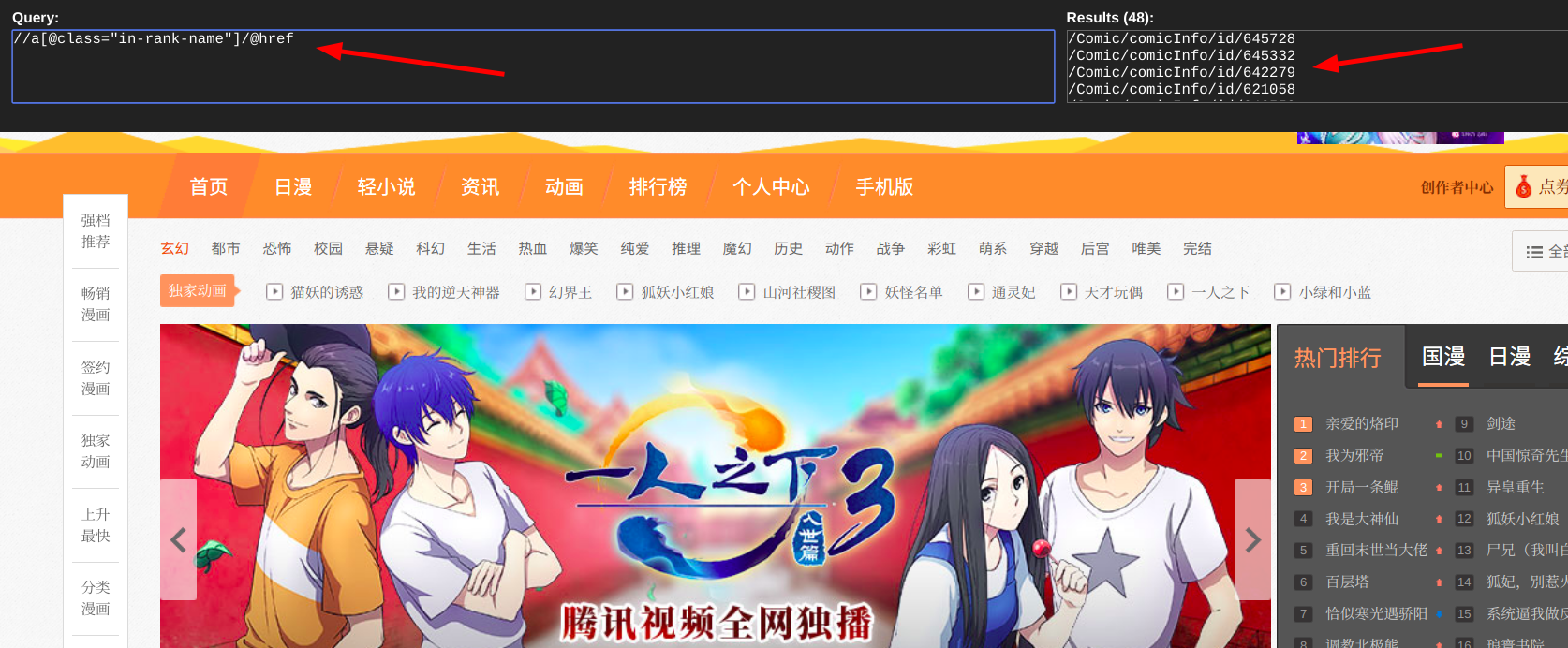
這裡我使用的是xpath提取漫畫地址資訊,在谷歌瀏覽器中使用xpath helper外掛輔助編寫xpath表示式
```
#開啟騰訊動漫首頁
url = 'https://ac.qq.com/'
#給網頁傳送請求
data = requests.get(url).text
#將網頁資訊轉換成xpath可識別的型別
html = etree.HTML(data)
#提取到每個漫畫的目錄頁地址
comic_list = html.xpath('//a[@class="in-rank-name"]/@href')
print(comic_list)
```
print一下輸出的comic_list,提取成功

###提取漫畫的內容頁
內容頁的提取也很簡單,就像上面的分析一樣,使用簡單的xpath語法即可提取

然後我們再將漫畫的名字提取出來,方便為儲存的資料夾命名
```
#遍歷提取到的資訊
for comic in comic_list:
#拼接成為漫畫目錄頁的網址
comic_url = url + str(comic)
#從漫畫目錄頁提取資訊
url_data = requests.get(comic_url).text
#準備用xpath語法提取資訊
data_comic = etree.HTML(url_data)
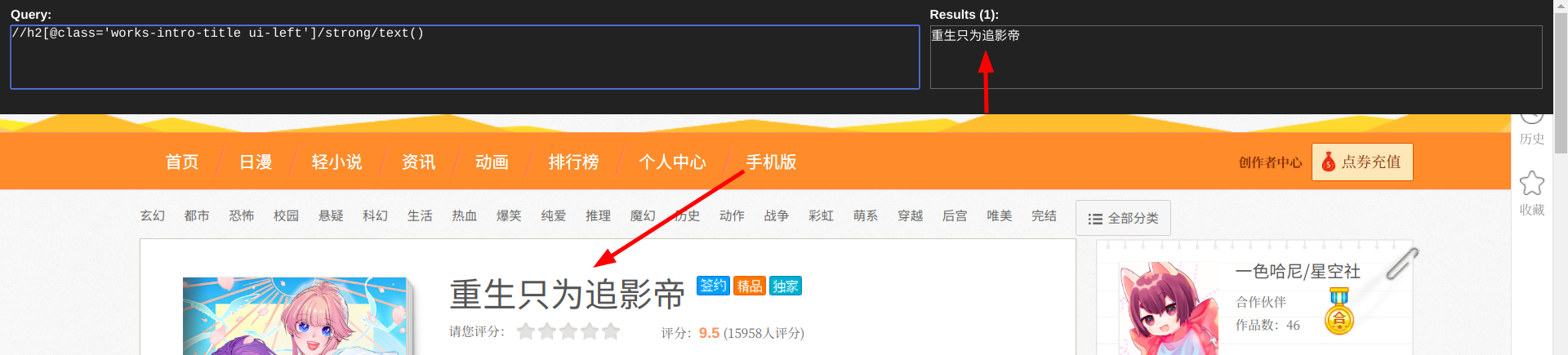
#提取漫畫名--text()為提取文字內容
name_comic = data_comic.xpath("//h2[@class='works-intro-title ui-left']/strong/text()")
#提取該漫畫每一頁的地址
item_list = data_comic.xpath("//span[@class='works-chapter-item']/a/@href")
print(name_comic)
print(item_list)
```
print列印的資訊:

###提取章節名
剛剛我們輸出的是漫畫頁的地址欄位,但是通過這些欄位並不能請求到資訊,還需在前面加上域名才可以構成一個完整的網址
提取章節名是為了在漫畫名的資料夾下再為每個章節建立一個資料夾儲存漫畫圖片
```
for item in item_list:
#拼接每一章節的地址
item_url = url + str(item)
#print(item_url)
#請求每一章節的資訊
page_mes = requests.get(item_url).text
#準備使用xpath提取內容
page_ming = etree.HTML(page_mes)
#提取章節名
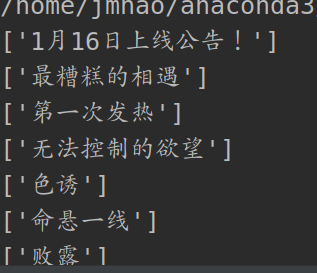
page_name = page_ming.xpath('//span[@class="title-comicHeading"]/text()')
print(page_name)
```
列印章節名:
###獲取漫畫源網頁程式碼
這個部分的程式碼是這個程式碼的核心部分,也是花費時間最久的部分
首先我們知道通過正常的方式沒有辦法請求到所有的圖片地址資訊,若是使用抓包方法會變得非常難分析,所以我採用的是模擬瀏覽器滑動的方法來獲得圖片的地址資訊
為了方便看到結果,先將webdriver設定為有介面模式,等到實現想要的功能之後,再將它隱藏起來
```
#webdriver位置
path = r'/home/jmhao/chromedriver'
#瀏覽器引數設定
browser = webdriver.Chrome(executable_path=path)
#開始請求第一個章節的網址
browser.get(item_url)
#設定延時,為後續做緩衝
sleep(2)
#嘗試執行下列程式碼
try:
#設定自動下滑滾動條操作
for i in range(1, 100):
#滑動距離設定
js = 'var q=document.getElementById("mainView").scrollTop = ' + str(i * 1000)
#執行滑動選項
browser.execute_script(js)
#延時,使圖片充分載入
sleep(2)
sleep(2)
#將開啟的介面截圖儲存,證明無介面瀏覽器確實打開了網頁
browser.get_screenshot_as_file(str(page_name) + ".png")
#獲取當前頁面原始碼
data = browser.page_source
#在當前資料夾下建立html檔案,並將網頁原始碼寫入
fh = open("dongman.html", "w", encoding="utf-8")
#寫入操作
fh.write(data)
#關掉瀏覽器
fh.close()
# 若上述程式碼執行報錯(大概率是由於付費漫畫),則執行此部分程式碼
except Exception as err:
#跳過錯誤程式碼
pass
```
執行之後會自動開啟漫畫的內容頁,並拖動右側的滑動條(模擬了手動操作,緩慢拖動是為了讓圖片充分載入),其中的sleep方法和網速有一定的關係,網速好的可以適當減少延時的時間,網速差可適當延長
在寫拖動滑動條的程式碼時,我嘗試了非常多種拖動寫法,也模擬了按下方向鍵的操作,可是隻有這一種方法使用成功了。我認為失敗的原因可能是剛開啟介面的時候會有一個導航條擋住滑塊,導致無法定位到滑塊的座標(因為我用其他網頁測試的時候都是可以拖動的)

使用的try是為了防止有一些章節會彈出付費視窗,導致程式報錯,使後續無法執行,即遇到會報錯的情況就跳過此段程式碼,執行except中的選項
這段程式執行完之後有一個dongman.html檔案儲存在當前資料夾下,裡面就包含了所有圖片的url,接下來只要讀取這個檔案的內容就可以提取到所有的漫畫地址了
###下載漫畫圖片
當我們儲存完網頁的原始碼之後,接下來的操作就變得簡單了 我們要做的就是提取檔案內容,將圖片下載到本地
```
#用beautifulsoup開啟本地檔案
html_new = BeautifulSoup(open('dongman.html', encoding='utf-8'), features='html.parser')
#提取html檔案中的主體部分
soup = html_new.find(id="mainView")
#設定變數i,方便為儲存的圖片命名
i = 0
#提取出主體部分中的img標籤(因為圖片地址儲存在img標籤中)
for items in soup.find_all("img"):
#提取圖片地址資訊
item = items.get("src")
#請求圖片地址
comic_pic = requests.get(item).content
#print(comic_pic)
#嘗試提取圖片,若發生錯誤則跳過
try:
#開啟資料夾,將圖片存入
with open('comic/' + str(name_comic) + '/' + str(page_name) + '/' + str(i + 1) + '.jpg', 'wb') as f:
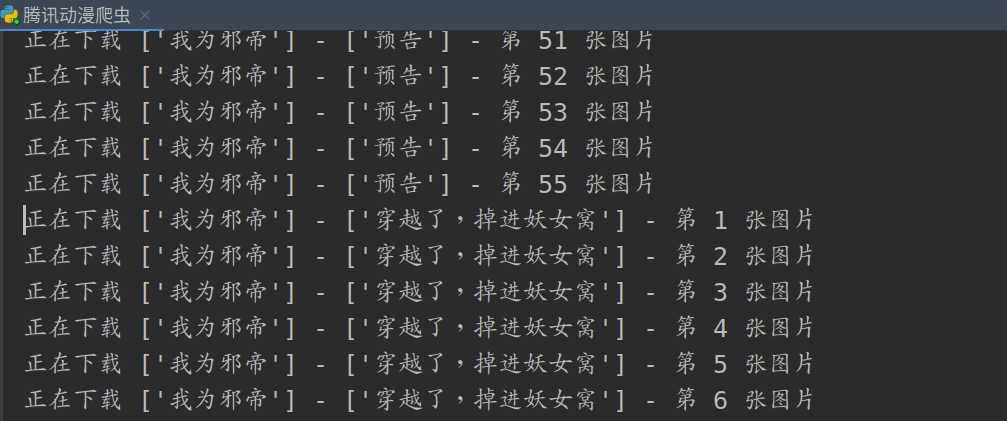
#print('正在下載第 ', (i + 1), ' 張圖片中')
print('正在下載' , str(name_comic) , '-' , str(page_name) , '- 第' , (i+1) , '張圖片')
#寫入操作
f.write(comic_pic)
#更改圖片名,防止新下載的圖片覆蓋原圖片
i += 1
#若上述程式碼執行報錯,則執行此部分程式碼
except Exception as err:
#跳過錯誤程式碼
pass
```
###下載結果
到了這裡程式碼就寫完了,來看一下執行結果:
開啟資料夾看到:

##完整程式碼
```
import requests
from lxml import etree
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options
import os
#開啟騰訊動漫首頁
url = 'https://ac.qq.com/'
#給網頁傳送請求
data = requests.get(url).text
#將網頁資訊轉換成xpath可識別的型別
html = etree.HTML(data)
#提取到每個漫畫的目錄頁地址
comic_list = html.xpath('//a[@class="in-rank-name"]/@href')
#print(comic_list)
#遍歷提取到的資訊
for comic in comic_list:
#拼接成為漫畫目錄頁的網址
comic_url = url + str(comic)
#從漫畫目錄頁提取資訊
url_data = requests.get(comic_url).text
#準備用xpath語法提取資訊
data_comic = etree.HTML(url_data)
#提取漫畫名--text()為提取文字內容
name_comic = data_comic.xpath("//h2[@class='works-intro-title ui-left']/strong/text()")
#提取該漫畫每一頁的地址
item_list = data_comic.xpath("//span[@class='works-chapter-item']/a/@href")
# print(name_comic)
# print(item_list)
#以漫畫名字為資料夾名建立資料夾
os.makedirs('comic/' + str(name_comic))
#將一本漫畫的每一章地址遍歷
for item in item_list:
#拼接每一章節的地址
item_url = url + str(item)
#print(item_url)
#請求每一章節的資訊
page_mes = requests.get(item_url).text
#準備使用xpath提取內容
page_ming = etree.HTML(page_mes)
#提取章節名
page_name = page_ming.xpath('//span[@class="title-comicHeading"]/text()')
#print(page_name)
#再以章節名命名一個資料夾
os.makedirs('comic/' + str(name_comic) + '/' + str(page_name))
#以下為程式碼的主體部分
#設定谷歌無介面瀏覽器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#webdriver位置
path = r'/home/jmhao/chromedriver'
#瀏覽器引數設定
browser = webdriver.Chrome(executable_path=path, options=chrome_options)
#開始請求第一個章節的網址
browser.get(item_url)
#設定延時,為後續做緩衝
sleep(2)
#browser.get_screenshot_as_file(str(page_name) + ".png")
#嘗試執行下列程式碼
try:
#設定自動下滑滾動條操作
for i in range(1, 100):
#滑動距離設定
js = 'var q=document.getElementById("mainView").scrollTop = ' + str(i * 1000)
#執行滑動選項
browser.execute_script(js)
#延時,使圖片充分載入
sleep(2)
sleep(2)
#將開啟的介面截圖儲存,證明無介面瀏覽器確實打開了網頁
browser.get_screenshot_as_file(str(page_name) + ".png")
#獲取當前頁面原始碼
data = browser.page_source
#在當前資料夾下建立html檔案,並將網頁原始碼寫入
fh = open("dongman.html", "w", encoding="utf-8")
#寫入操作
fh.write(data)
#關掉無介面瀏覽器
fh.close()
#下面的操作為開啟儲存的html檔案,提取其中的圖片資訊,並儲存到資料夾中
#用beautifulsoup開啟本地檔案
html_new = BeautifulSoup(open('dongman.html', encoding='utf-8'), features='html.parser')
#提取html檔案中的主體部分
soup = html_new.find(id="mainView")
#設定變數i,方便為儲存的圖片命名
i = 0
#提取出主體部分中的img標籤(因為圖片地址儲存在img標籤中)
for items in soup.find_all("img"):
#提取圖片地址資訊
item = items.get("src")
#請求圖片地址
comic_pic = requests.get(item).content
#print(comic_pic)
#嘗試提取圖片,若發生錯誤則跳過
try:
#開啟資料夾,將圖片存入
with open('comic/' + str(name_comic) + '/' + str(page_name) + '/' + str(i + 1) + '.jpg', 'wb') as f:
#print('正在下載第 ', (i + 1), ' 張圖片中')
print('正在下載' , str(name_comic) , '-' , str(page_name) , '- 第' , (i+1) , '張圖片')
#寫入操作
f.write(comic_pic)
#更改圖片名,防止新下載的圖片覆蓋原圖片
i += 1
#若上述程式碼執行報錯,則執行此部分程式碼
except Exception as err:
#跳過錯誤程式碼
pass
# 若上述程式碼執行報錯(大概率是由於付費漫畫),則執行此部分程式碼
except Exception as err:
#跳過錯誤程式碼
pass
```
github:https://github.com/jjjjmhao/Sprider/commit/16d15a34d722f3c50060f9f3015c9ff57