
十分鐘搞懂Elasticsearch數字搜尋原理
阿新 • • 發佈:2020-04-27
>**更多精彩內容請看我的**[**個人部落格**](http://sunshuyi.vip?hmsr=cnblog&hmpl=es%2Dnumeric&hmcu=home&hmkw=home&hmci=none)或者**掃描二維碼,關注微信公眾號**:**佛西先森**
>
## 前言
Elasticsearch誕生的本意是為了解決文字搜尋太慢的問題,ES會預設將所有的輸入內容當作字串來理解,對於欄位型別是keyword或者text的資料比較友好。但是如果輸入的型別是數字,ES還會把數字當作字串嗎?排序問題還有範圍查詢問題怎麼解決呢?這篇文章就簡單介紹了ES對於數字型別(numeric)資料的處理,能讓你大漲姿勢
## 簡介
Elasticsearch專為字串搜尋而生,在建立索引的時候針對字串進行了非常多的優化,在對字串進行準確匹配或者字首匹配等匹配的時候效率是很高的。ES底層把**所有的資料**都會當成字串,其中就包括數字——所有的數字在ES底層都是會以字串的形式儲存。
這就和我們通常理解的數字就不一樣了,在MySQL或者各種程式語言比如Java、Python中,數字比如int型別就是4個位元組呀!最高位符號位,後面的位數按照二進位制進行儲存,還能有其他的表示方式?
出現這個現象的原因就是ES和MySQL或者Java中對數字的需求不一樣了。在程式語言中,數字要經常參與計算比如加減乘除還有移位以及**比較大小**操作,這個時候用int這種原生的方式是簡單直接效率高的;在MySQL中,索引是以B+樹的形式儲存,每次查詢某一個數字都要在樹中把**整個數字**和分隔節點進行**比較操作**,直到找到最後的目標資料節點。
可以看到直接使用int的本身的結構來儲存的優勢就是**直接比較大小**的效率非常高(空間消耗小也是另外一個優勢),但是如果進行**範圍查詢**,就會有問題了。比如在MySQL的組合查詢中如果出現範圍查詢,那麼很有可能出現範圍查詢後面的索引是不生效的(具體的MySQL的組合查詢的原理可以在網上看看),也就是說範圍查詢可能會**降低查詢效能**;在程式語言中的集合的範圍查詢就只能遍歷所有的元素,一一比較大小,沒有優化。
ES的出現為解決範圍查詢提供了一個新的思路——為不同精度範圍內的資料直接建立索引,把符合範圍查詢要求的資料聚合到一個索引上面,在搜尋的時候把大的搜尋範圍拆分成**很多小的範圍索引**,直接用term搜尋就可以找到符合要求的所有文件。
emmm...是不是有點抽象╮(╯_╰)╭
比如想搜尋在`[300,500]`內的文件並且事先已經把值在`[300,400]`之間的文件索引到了`3`、`[400,500]`之間的文件索引到了`4`,那麼就直接通過term查詢取出`3`和`4`對應的文件id列表並且進行`or`操作就可以了,簡單直接高效。
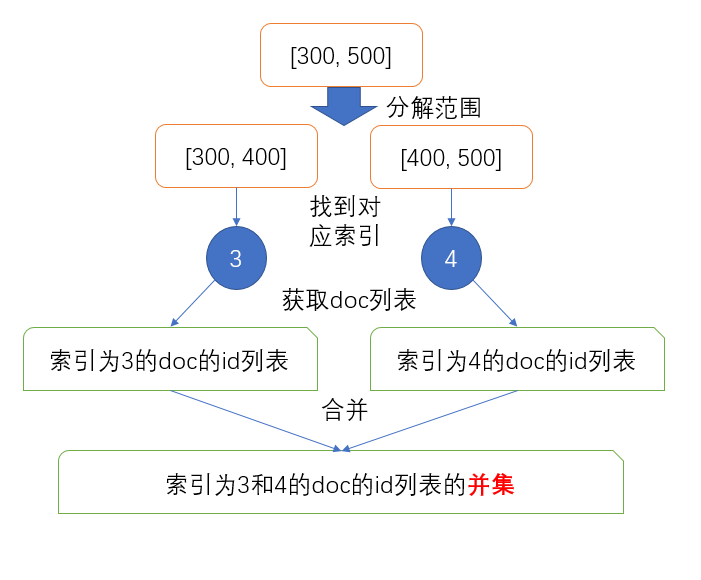
原理雖然簡單,不過實現起來還是有些困難需要解決的。
## 數字直接變成字串的問題
ES並沒有直接把數字變成字串,也沒有對每個數字建立簡單的索引,因為這兩種做法可能會帶來一些問題。
### 字串比較
首先最大的問題是數字變成字串之後如何進行比較,如果直接是把十進位制的數字變成字串,排序按照**字典序**(lexicographic)比較(預設所有的term都是按照字典序比較大小),會有不同位數比較的問題。比如搜尋`[423,642]`內的文件,`5`也會被算在內,因為字典序`"5"`比`"423"`大,比`"642"`小。
這個問題的一個解決方案是在每個數字變成字串的時候在前面填充`0`,把`5`變成`005`,這樣就能正確比較大小了,這也是舊版本的ES採用的解決方案。但是每次把int轉化成string的時候要填充多少個0呢?太多了佔空間,太少了又可能因為數字太長影響比較,比如最多隻填充2個0,對於`1000`以下的數字沒有問題,當數字大於`1000`了,個位數填充2個0就不夠用了。
### 獲取的範圍過多
另一個問題是範圍內的term過多帶來的效能下降。比如現在有很多文件,其中索引的數字的列表為`[421,423,445,446,448,521,522,632,633,634,641,642,644]`一共13個term,如果我們想要查詢`[423,642]`之間的所有的文件,需要取出一共11個term,然後用這些term去搜索對應的文件。
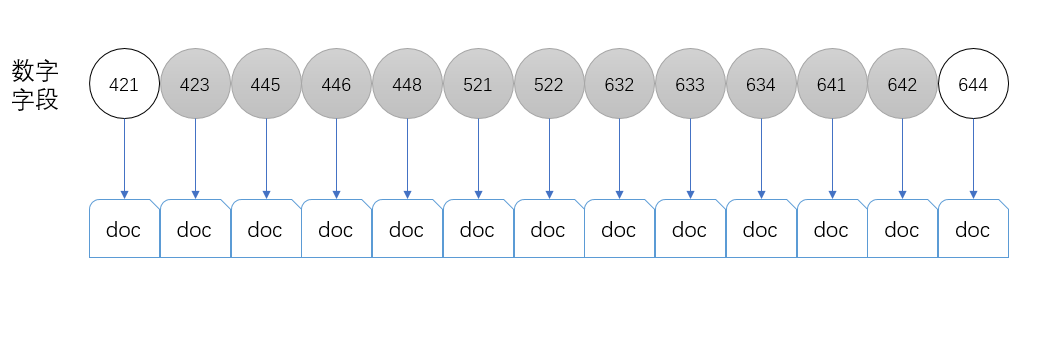
當範圍越來越大,需要的term的數量就越來越多,查詢的效能就會不斷下降。
## ES是怎麼把數字變成字串
先來解決第一個問題,數字怎麼變成字串。
十進位制的數字有填充問題,如果變成了**二進位制**,再進行詞典序比較,不就沒有問題了嗎?Perfect,似乎問題完美的解決了。
哥麼你就沒有考慮過負數的感受嗎?

二進位制的int保證是32位,對於**正數和正數**的比較或者**負數和負數**的比較是沒有問題的,可是正數和負數的比較就不行了。正數的最高位是0,負數的最高位是1,直接比較,負數永遠大於正數。這個時候ES採用的方法是把正數最高位變成1,負數最高位變成0,這樣正數用於大於負數,問題就解決了。
int型別解決了,float呢?由於浮點數在Java中的表示方法,最高位符號位,23~30位是指數位,0~22是尾數,如果直接把一個**正的**float當作int型別來比較好像也沒有什麼問題,指數位高的,當然大;指數相同,尾數大的也自然數字就大,所以正浮點型可以**直接**當成int轉化。但是負數就不行了,指數越大,數字越小,尾數越大,數字也越小。ES給出的解決方案是直接對低31位每一位取反,1變成0,0變成1,這樣負數的float就可以比較大小了。總結就是**正float**當int用,**負float**低31位取反後當成int用。
對於long和double型別,也是同樣的道理,只不過32位變成了64位。
你以為就這樣變成了二進位制字串了嗎?不,還沒有,沒有這麼簡單。
剛才是把int變成了二進位制的字串,一個字元只儲存0和1不覺得浪費嗎?一個int要用32個字元也就是32個位元組儲存,暴殄天物呀!
Java的1個int佔4個位元組,1個char是2個位元組,1個int用2個char不就行了。但是Java使用Unicode字符集來儲存字串,ES用UTF8編碼儲存Unicode字元,對於0~127使用1個位元組,大於127一般2個位元組,漢字通常3個位元組,這樣的話1個int用2個char表示,最多需要6個位元組(這裡int雖然不是漢字,但是在變成char之後有可能在Unicode字符集中表示某一個漢字)
ES表示還能做的更好,上面不是說0~127只用一個位元組嗎?好,我就把int切分之後的大小限制在127以內(原來預設切分是4組8位的二進位制數字)。127是7位二進位制數字,int是32位的,那就把32位的int變成由4、7、7、7、7這5組二進位制組成,最後這個字串只需要5個位元組就可以了,和上面的6個位元組相比,空間利用率**提高了17%**!

## 數字的索引是什麼樣子
上面說到的另外一個問題是查詢term數量太多的問題,解決方案就是用空間換時間,通過**字首聚合部分的term**來達到。
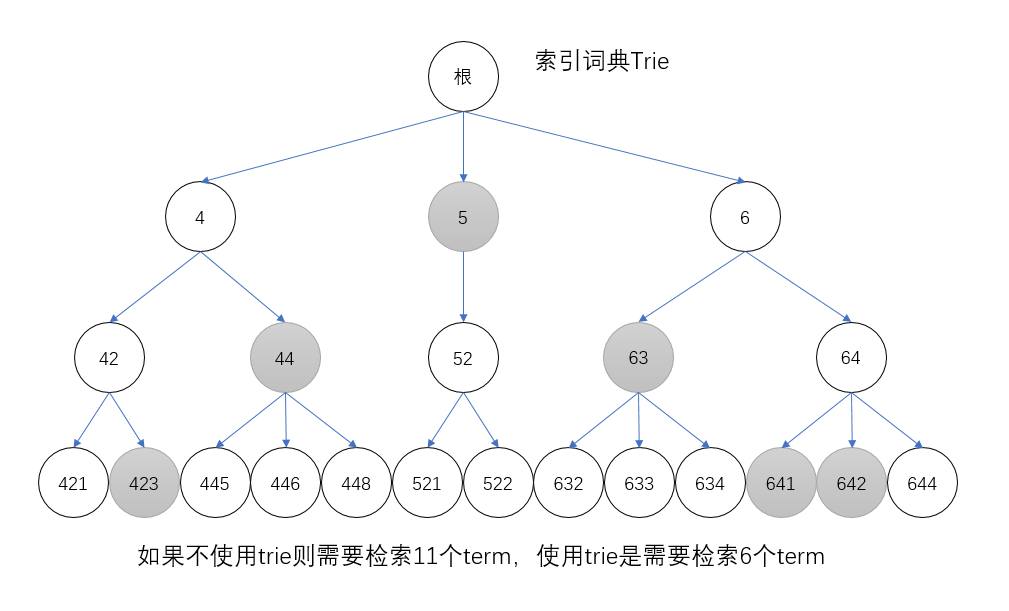
這裡的聚合的實現方式是採用trie的資料結構,比如445、446和448這個三個term,可以聚合到44這個term的下面,節點44包含的文件的id列表應該是所有子節點的並集,這樣原先需要的11個term就可以減少2個。同理對於其他的term也進行合併,合併之後`[423,642]`查詢就只需要6個term,**效率提高了一倍**!
然而聚合也是要講道理的,把445、446和448聚合到44以及把44聚合到4相當於是把數字除以10,精度就是10。但是並不是一直都希望這個精度是10,也可以設定為100(精度相對應的降低,節約索引空間)等等。ES提供了precisionStep來定製化這個精度,不過不是針對十進位制,而是二進位制的位數。比如precisionStep設定為4,那麼在二進位制位裡面每隔4位(相當於十進位制的16)就建立一個字首聚合索引。
比如對於二進位制數字`0100 0011 0001 1010`,當precisionStep為4的時候,會建立4個索引——`0100 0011 0001 1010`、`0100 0011 0001`、`0100 0011`以及`0100`(最高的4位),這四個索引相當於從trie的子節點一直到根節點
精度越高(precisionStep越小)索引就越大,查詢速度越快;精度越低,索引越小,相對查詢速度比較慢。
比如對於long型別的資料,precisionStep是4的時候,最多需要同時搜尋465個term;precisionStep是2的時候,最多隻要189個term。不過並不能絕對的說精度越高越好,因為查詢這些term需要的時間也會相應增加。實際上最佳的precisionStep還是要根據業務情況測試得出。
上面根據precisionStep建立索引的過程中有一個特殊的分詞器來幫助拆分,比如把`423`拆成`423`、`42`以及`4`。不過分詞器會同樣的把`4`拆分成`4`,那怎麼區分`423`的`4`和`4`的`4`呢?
那就需要額外的空間來區分這兩個`4`,ES給出的解決方案是在這兩個數字前面加上一個字首`shift`表示偏移量。比如`423`的`4`,`shift`是`2`(`423`的`42`的`shift`是`1`,`423`的`shift`是`0`);而`4`的`4`,`shift`是`0`,所以前者的`4`比後者的要大。分詞之後的term在每次比較之前都會先比較`shift`,`shift`越大,相應的term也越大,避免的重複的問題。
總結上面建立索引的過程:當一個文件進來的時候,有一個數字`423`需要建立索引,於是先把這個int資料轉化成字串,再用一個特殊的分詞器根據精度把`423`分成對應的三個term`423`、`42`和`4`,並且附上對應的字首`shift`,接下來在trie中找到這幾個term,把穩定的id新增到這幾個term的文件id列表裡面(如果不存在就建立這個term)。
## 查詢原理
清楚了數字型別的資料的索引機制之後,範圍查詢的原理就比較簡單了。
比如有一個範圍`[423, 642]`,要找到欄位大於等於423並且小於等於642的文件。
1. 先在索引的trie裡面找到這兩個term以及**範圍內的兄弟節點**,分別是trie的兩個葉節點423、641和642
2. 從葉節點向上縮小範圍,對兩個數字分別除以10加一和減一之後查詢範圍為`[43,63]`,此時的`shift`是1,得到這一層級的“葉子節點”以及範圍內的兄弟節點是44和63
3. 再從這一層向上,兩個數字除以10,分別加一減一,得到範圍`[5,5]`,`shift`為2,這就是最後的節點了,term是5
4. 上面三個步驟得到最後需要的term是423、44、5、63、641和642
上面是用十進位制舉得一個例子,在二進位制裡面也是同樣的道理,這裡就不囉嗦了。實際上在ES實現裡面用了很多位操作,效率相比於使用十進位制要高很多,感興趣的同學可以去看原始碼,在`LegacyNumericUtils`類的`splitRange`方法裡面。
## 總結
總的來說,Elasticsearch對於數字型別資料的索引和搜尋不同於傳統的MySQL或者Java等程式語言,採用了獨特的字串儲存以及Trie資料結構儲存索引的方式。
ES先將輸入的數字進行預處理,把float和double分別對映成int和long,原來是int和long型別的則保持不變
然後把輸入的整型數字切分成許多組由最長7位二進位制數字組成的二進位制串,每組二進位制數字都是一個Unicode字元,整體連起來變成一個Unicode字串
接下來根據precisionStep把這個字串數字分詞成很多term,並附上字首shift
根據這些term建立索引詞典,詞典的結構類似於一個trie
範圍查詢的時候根據trie把所謂的範圍區間劃分成離散的term字串,這些term指向的文件的並集就是範圍查詢的結果
## One more thing
謝謝各位大佬看完了這篇文章,在這裡我很遺憾的通知您,以上提到的ES數字型別資料處理的方式已經被廢棄了