
【原創】Linux Mutex機制分析
阿新 • • 發佈:2020-05-04
# 背景
- `Read the fucking source code!` --By 魯迅
- `A picture is worth a thousand words.` --By 高爾基
說明:
1. Kernel版本:4.14
2. ARM64處理器,Contex-A53,雙核
3. 使用工具:Source Insight 3.5, Visio
# 1. 概述
- `Mutex`互斥鎖是Linux核心中用於互斥操作的一種同步原語;
- 互斥鎖是一種休眠鎖,鎖爭用時可能存在程序的睡眠與喚醒,context的切換帶來的代價較高,適用於加鎖時間較長的場景;
- 互斥鎖每次只允許一個程序進入臨界區,有點類似於二值訊號量;
- 互斥鎖在鎖爭用時,在鎖被持有時,選擇自選等待,而不立即進行休眠,可以極大的提高效能,這種機制(`optimistic spinning`)也應用到了讀寫訊號量上;
- 互斥鎖的缺點是互斥鎖物件的結構較大,會佔用更多的CPU快取和記憶體空間;
- 與訊號量相比,互斥鎖的效能與擴充套件性都更好,因此,在核心中總是會優先考慮互斥鎖;
- 互斥鎖按為了提高效能,提供了三條路徑處理:快速路徑,中速路徑,慢速路徑;
前戲都已經講完了,來看看實際的實現過程吧。
# 2. optimistic spinning
## 2.1 MCS鎖
- 上文中提到過`Mutex`在實現過程中,採用了`optimistic spinning`自旋等待機制,這個機制的核心就是基於`MCS鎖機制`來實現的;
- `MCS鎖機制`是由`John Mellor Crummey`和`Michael Scott`在論文中`《algorithms for scalable synchronization on shared-memory multiprocessors》`提出的,並以他倆的名字來命名;
- `MCS鎖機制`要解決的問題是:在多CPU系統中,自旋鎖都在同一個變數上進行自旋,在獲取鎖時會將包含鎖的`cache line`移動到本地CPU,這種`cache-line bouncing`會很大程度影響效能;
- `MCS鎖機制`的核心思想:每個CPU都分配一個自旋鎖結構體,自旋鎖的申請者(`per-CPU`)在`local-CPU變數`上自旋,這些結構體組建成一個連結串列,申請者自旋等待前驅節點釋放該鎖;
- `osq(optimistci spinning queue)`是基於MCS演算法的一個具體實現,並經過了迭代優化;
## 2.2 osq流程分析
`optimistic spinning`,樂觀自旋,到底有多樂觀呢?當發現鎖被持有時,`optimistic spinning`相信持有者很快就能把鎖釋放,因此它選擇自旋等待,而不是睡眠等待,這樣也就能減少程序切換帶來的開銷了。
看一下資料結構吧:
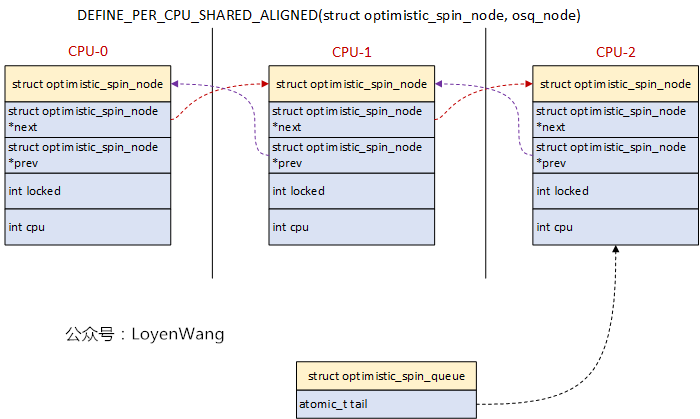
`osq_lock`如下:
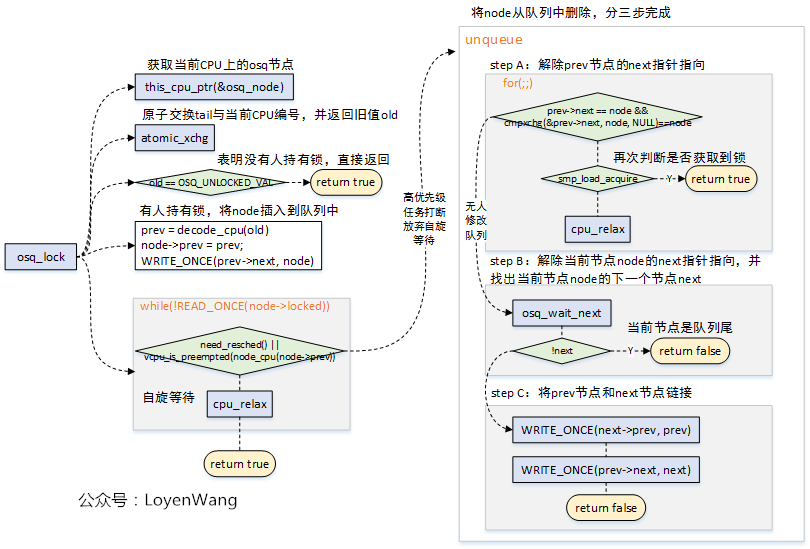
- osq加鎖有幾種情況:
1. 無人持有鎖,那是最理想的狀態,直接返回;
2. 有人持有鎖,將當前的Node加入到OSQ佇列中,在沒有高優先順序任務搶佔時,自旋等待前驅節點釋放鎖;
3. 自旋等待過程中,如果遇到高優先順序任務搶佔,那麼需要做的事情就是將之前加入到OSQ佇列中的當前節點,從OSQ佇列中移除,移除的過程又分為三個步驟,分別是處理prev前驅節點的next指標指向、當前節點Node的next指標指向、以及將prev節點與next後繼節點連線;
- 加鎖過程中使用了原子操作,來確保正確性;
`osq_unlock`如下:
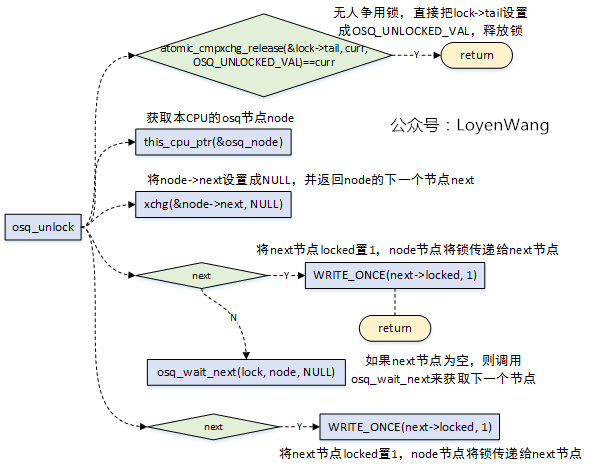
- 解鎖時也分為幾種情況:
1. 無人爭用該鎖,那直接可以釋放鎖;
2. 獲取當前節點指向的下一個節點,如果下一個節點不為NULL,則將下一個節點解鎖;
3. 當前節點的下一個節點為NULL,則呼叫`osq_wait_next`,來等待獲取下一個節點,並在獲取成功後對下一個節點進行解鎖;
- 從解鎖的情況可以看出,這個過程相當於鎖的傳遞,從上一個節點傳遞給下一個節點;
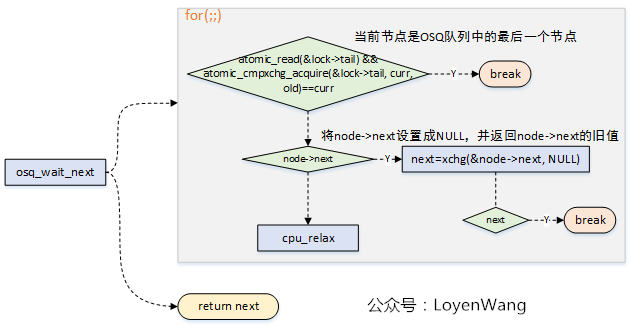
在加鎖和解鎖的過程中,由於可能存在操作來更改osq佇列,因此都呼叫了`osq_wait_next`來獲取下一個確定的節點:
# 3. mutex
## 3.1 資料結構
終於來到了主題了,先看一下資料結構:
```c
struct mutex {
atomic_long_t owner; //原子計數,用於指向鎖持有者的task struct結構
spinlock_t wait_lock; //自旋鎖,用於wait_list連結串列的保護操作
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */ //osq鎖
#endif
struct list_head wait_list; //連結串列,用於管理所有在該互斥鎖上睡眠的程序
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
```
在使用`mutex`時,有以下幾點需要注意的:
- 一次只能有一個程序能持有互斥鎖;
- 只有鎖的持有者能進行解鎖操作;
- 禁止多次解鎖操作;
- 禁止遞迴加鎖操作;
- mutex結構只能通過API進行初始化;
- mutex結構禁止通過`memset`或者拷貝來進行初始化;
- 已經被持有的mutex鎖禁止被再次初始化;
- mutex不允許在硬體或軟體上下文(`tasklets, timer`)中使用;
## 3.2 加鎖流程分析
從`mutex_lock`加鎖來看一下大概的流程:
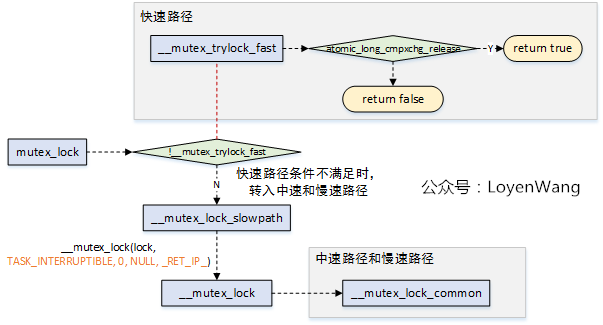
- `mutex_lock`為了提高效能,分為三種路徑處理,優先使用快速和中速路徑來處理,如果條件不滿足則會跳轉到慢速路徑來處理,慢速路徑中會進行睡眠和排程,因此開銷也是最大的。
### 3.2.1 fast-path
- 快速路徑是在`__mutex_trylock_fast`中實現的,該函式的實現也很簡單,直接呼叫`atomic_long_cmpxchg_release(&lock->owner, 0UL, curr)`函式來進行判斷,如果`lock->owner == 0`表明鎖未被持有,將`curr`賦值給`lock->owner`標識`curr`程序持有該鎖,並直接返回;
- `lock->owner`不等於0,表明鎖被持有,需要進入下一個路徑來處理了;
### 3.2.2 mid-path
- 中速路徑和慢速路徑的處理都是在`__mutex_lock_common`中實現的;
- `__mutex_lock_common`的傳入引數為(`lock, TASK_INTERRUPTIBLE, 0, NULL, _RET_IP_, false`),該函式中很多路徑覆蓋不到,接下來的分析也會剔除掉無效程式碼;
中速路徑的核心程式碼如下:
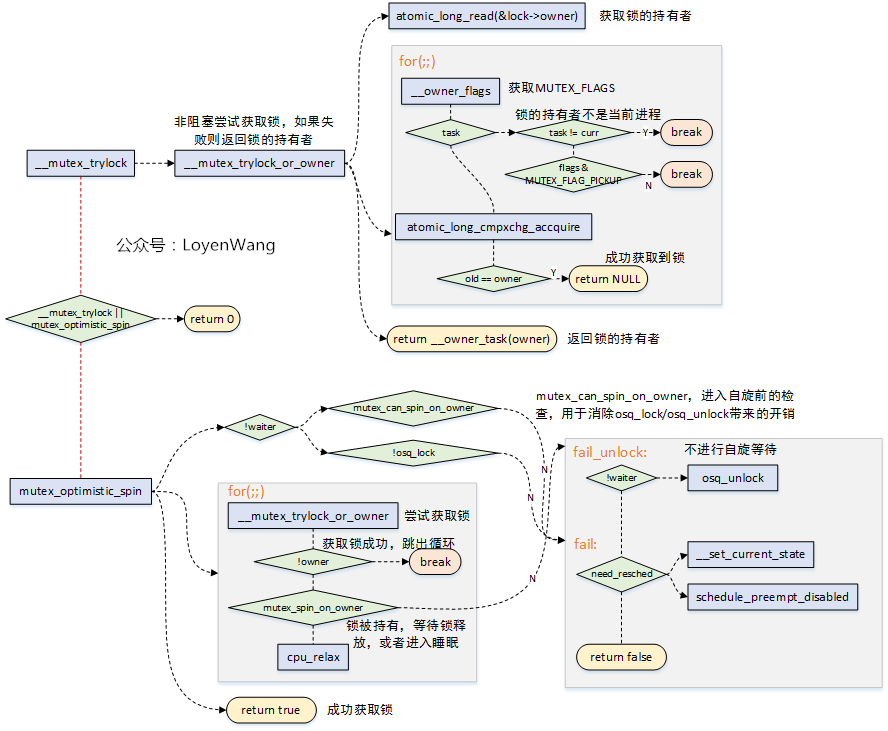
- 當發現mutex鎖的持有者正在執行(另一個CPU)時,可以不進行睡眠排程,而可以選擇自選等待,當鎖持有者正在執行時,它很有可能很快會釋放鎖,這個就是樂觀自旋的原因;
- 自旋等待的條件是持有鎖者正在臨界區執行,自旋等待才有價值;
- `__mutex_trylock_or_owner`函式用於嘗試獲取鎖,如果獲取失敗則返回鎖的持有者。互斥鎖的結構體中`owner`欄位,分為兩個部分:1)鎖持有者程序的task_struct(由於L1_CACHE_BYTES對齊,低位位元沒有使用);2)`MUTEX_FLAGS`部分,也就是對應低三位,如下:
1. `MUTEX_FLAG_WAITERS`:位元0,標識存在非空等待者連結串列,在解鎖的時候需要執行喚醒操作;
2. `MUTEX_FLAG_HANDOFF`:位元1,表明解鎖的時候需要將鎖傳遞給頂部的等待者;
3. `MUTEX_FLAG_PICKUP`:位元2,表明鎖的交接準備已經做完了,可以等待被取走了;
- `mutex_optimistic_spin`用於執行樂觀自旋,理想的情況下鎖持有者執行完釋放,當前程序就能很快的獲取到鎖。實際需要考慮,如果鎖的持有者如果在臨界區被排程出去了,`task_struct->on_cpu == 0`,那麼需要結束自旋等待了,否則豈不是傻傻等待了。
1. `mutex_can_spin_on_owner`:進入自旋前檢查一下,如果當前程序需要排程,或者鎖的持有者已經被排程出去了,那麼直接就返回了,不需要做接下來的`osq_lock/oqs_unlock`工作了,節省一些額外的overhead;
2. `osq_lock`用於確保只有一個等待者參與進來自旋,防止大量的等待者蜂擁而至來獲取互斥鎖;
3. `for(;;)`自旋過程中呼叫`__mutex_trylock_or_owner`來嘗試獲取鎖,獲取到後皆大歡喜,直接返回即可;
4. `mutex_spin_on_owner`,判斷不滿足自旋等待的條件,那麼返回,讓我們進入慢速路徑吧,畢竟不能強求;
### 3.2.3 slow-path
慢速路徑的主要程式碼流程如下:
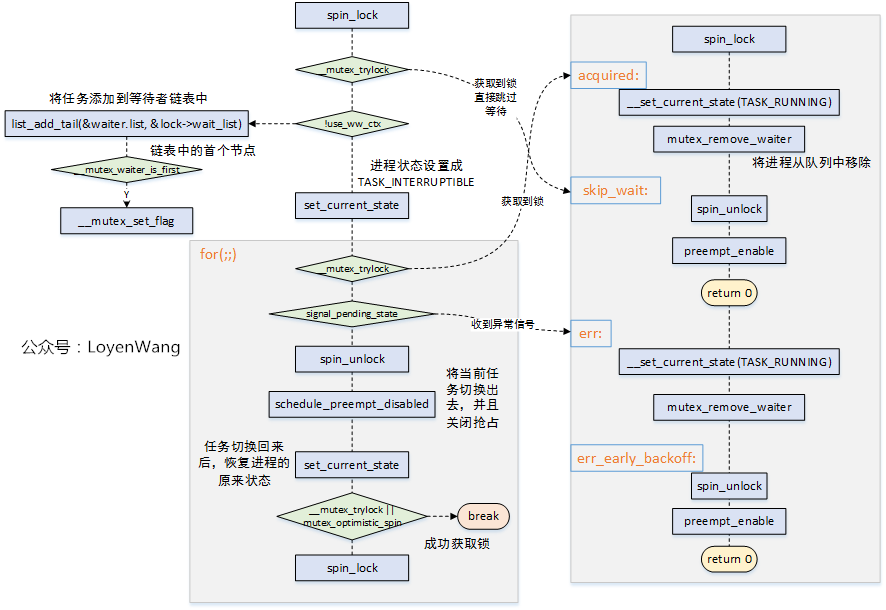
- 從`for(;;)`部分的流程可以看到,當沒有獲取到鎖時,會呼叫`schedule_preempt_disabled`將本身的任務進行切換出去,睡眠等待,這也是它慢的原因了;
## 3.3 釋放鎖流程分析
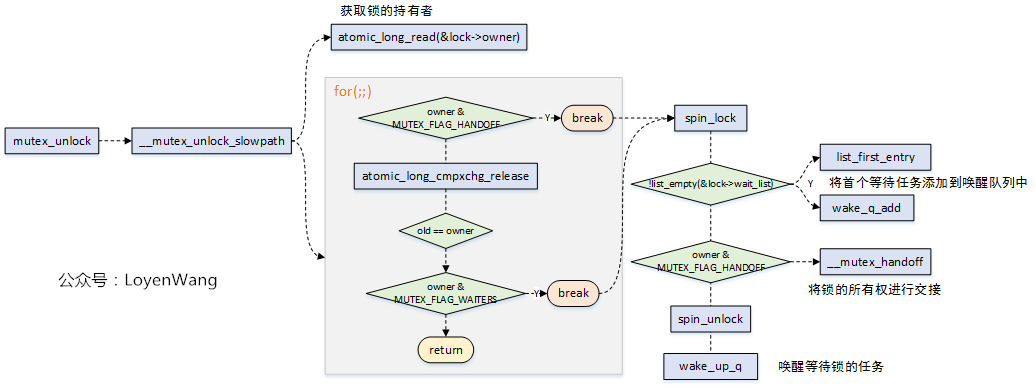
- 釋放鎖的流程相對來說比較簡單,也分為快速路徑與慢速路徑,快速路徑只有在除錯的時候開啟;
- 慢速路徑釋放鎖,針對三種不同的`MUTEX_FLAG`來進行判斷處理,並最終喚醒等待在該鎖上的任務;
# 參考
[Generic Mutex Subsystem](https://www.kernel.org/doc/html/latest/locking/mutex-design.html)
[MCS locks and qspinlocks](https://lwn.net/Articles/590243/)
歡迎關注個人公眾號,持續分享核心相關文章
