
1、Hbase原理分析
一、Hbase介紹
1.1、對Hbase的認識
- HBase作為面向列的資料庫執行在HDFS之上,HDFS缺乏隨機讀寫操作,HBase正是為此而出現。
- HBase參考 Google 的 Bigtable 實現,以鍵值對的形式儲存。專案的目標就是快速在主機內數十億行資料中定位所需的資料並訪問它。
- HBase是建立在HDFS之上的分散式面向列的資料庫;屬於KV結構資料(V可以隨便存,結構化資料和非結構化資料都可以),原生不支援標準SQL。
- HBase可以提供快速隨機訪問海量結構化資料。
- 它利用了Hadoop的檔案系統(HDFS)提供的容錯能力。
- Hive 和 Hbase都是作用在hdfs之上的。
- Hive :適合統計分析。Hive 執行的是mapreduce任務,延遲高。
- Hbase:適合大資料量查詢,不適合統計分析。Hbase是鍵值對儲存,可以快速返回資料。
1.2、Hbase資料單元
- RowKey:是Byte array,是表中每條記錄的“主鍵”,按照字典順序排序,唯一,方便快速查詢,Rowkey的設計非常重要;
- Column Family:列族,擁有一個名稱(string),包含一個或者多個相關列;
- Column:屬於某一個columnfamily,familyName:columnName,每條記錄可動態新增;
- Version Number:版本號,型別為Long,預設值是系統時間戳Timestamp,可由使用者自定義;用於標記同一份資料的不同版本。
- Value(Cell):具體的值,Byte array;
- 總之,在一個HBase:
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是鍵值對的集合。
- 建表時:指定表的列族,列自己插入資料時動態建立
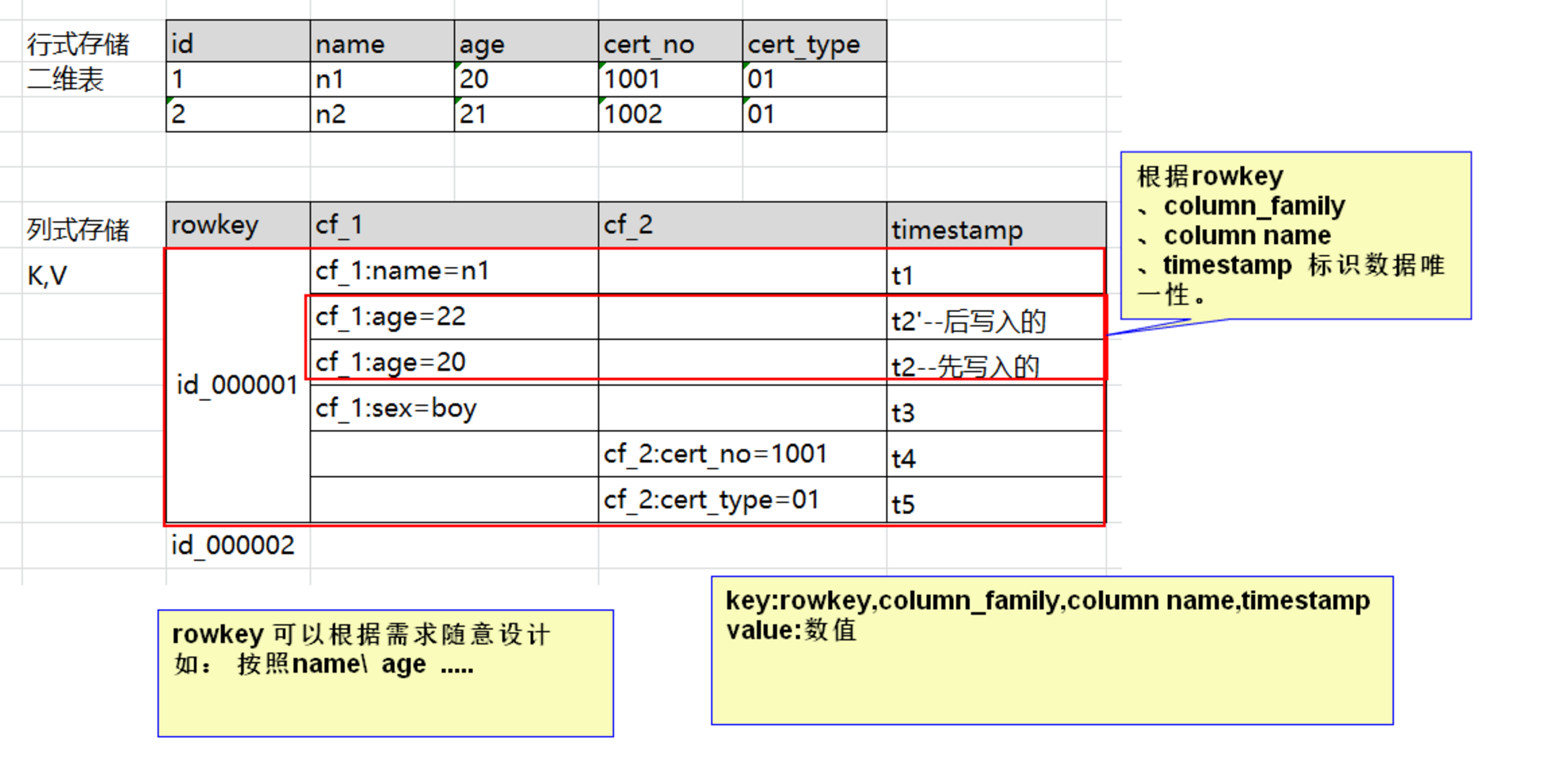
1.3、Hbase物理儲存結構
- 每個column family儲存在HDFS上的一個單獨檔案中,空值不會被儲存;

-
Key 和 Version number在每個 column family中均有一份;
-
HBase 為每個值維護了多級索引,即:<key, column family, column name, timestamp>;
-
在物理層面上,表格的資料是通過StoreFile來儲存的,每個StoreFile相當於一個可序列化的Map,Map的key和value都是可解釋型字元陣列;
-
Column Family是一組Column的組合,在HBase中,Schema的定義主要為Column Family的定義,同大多數nosql資料庫一樣,HBase也是支援自由定義Schema,但是前提要先定義出具體的Column Family,而在隨後的column定義則沒有任何約束;其次,HBase的訪問許可權控制,磁碟及記憶體統計等功能都是基於Column Family層面完成的;
-
HBase提供基於Cell的版本管理功能,版本號預設通過timestamp來標識,並且呈倒序排列;
二、Hbase原理分析
HBase採用Master/Slave(主僕結構)架構搭建叢集,它隸屬於Hadoop生態系統,由以下型別節點組成:
- HMaster節點
- HRegionServer節點
- ZooKeeper叢集
- 而在底層,它將資料儲存於HDFS中,因而涉及到HDFS的NameNode、DataNode等
總體結構如下:
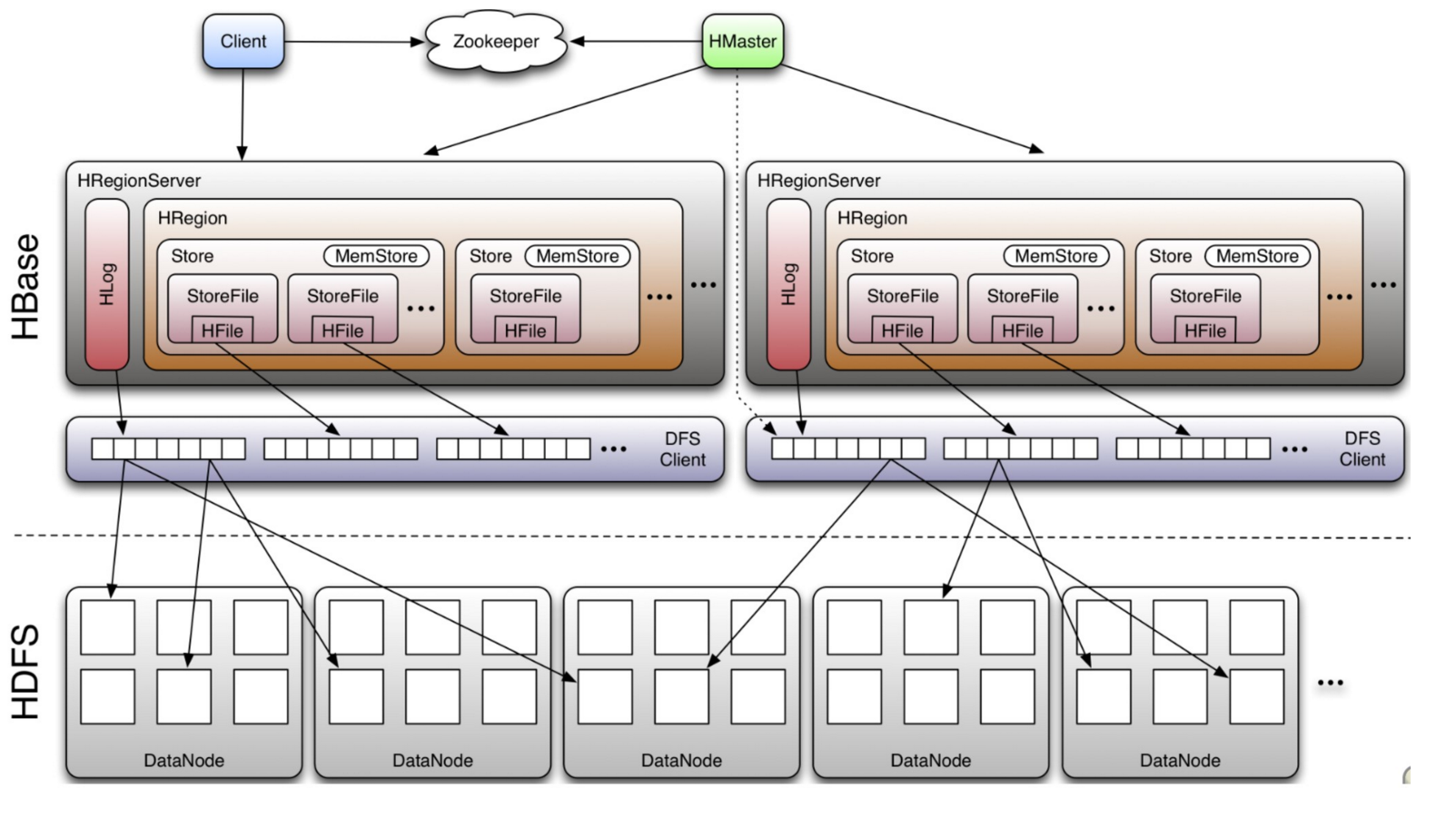
2.1、Client
- 使用HBase RPC機制與HMaster和HRegionServer進行通訊;
- Client與HMaster進行通訊進行管理類操作;
- Client與HRegionServer進行資料讀寫類操作;
2.2、HMaster
HMaster沒有單點問題,HBase中可以啟動多個HMaster,通過Zookeeper保證總有一個Master在執行。
HMaster主要負責Table和Region的管理工作:
- 管理使用者對錶的增刪改查操作DDL;
- 管理HRegionServer的負載均衡,調整Region分佈;
- Region Split後,負責新Region的分佈;
- 在HRegionServer停機後,負責失效HRegionServer上Region 的遷移;
2.3、HRegionServer
HBase中最核心的模組;
- 維護region,處理對這些region的IO請求;
- Regionserver負責切分在執行過程中變得過大的region;
- 一個HRegionServer包括多個HRegion和一個Hlog
HRegion介紹
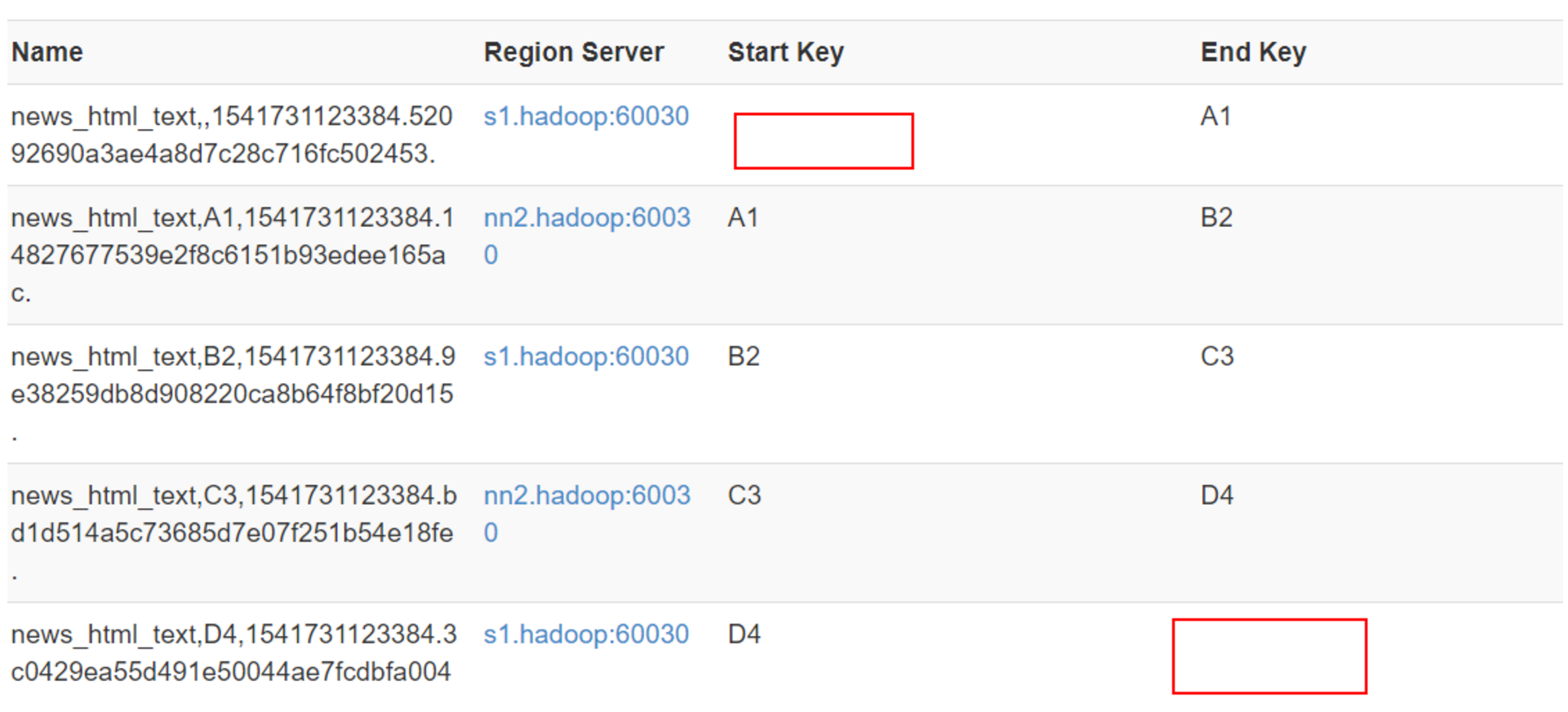
HBase使用RowKey將表水平切割成多個HRegion,從HMaster的角度,每個HRegion都紀錄了它的StartKey和EndKey(第一個HRegion的StartKey為空,最後一個HRegion的EndKey為空),由於RowKey是排序的,因而Client可以通過HMaster快速的定位每個RowKey在哪個HRegion中。(通俗理解:就是通過StartKey和Endkey將rowkey按照順序儲存)

檢視web UI
HregionServer詳解
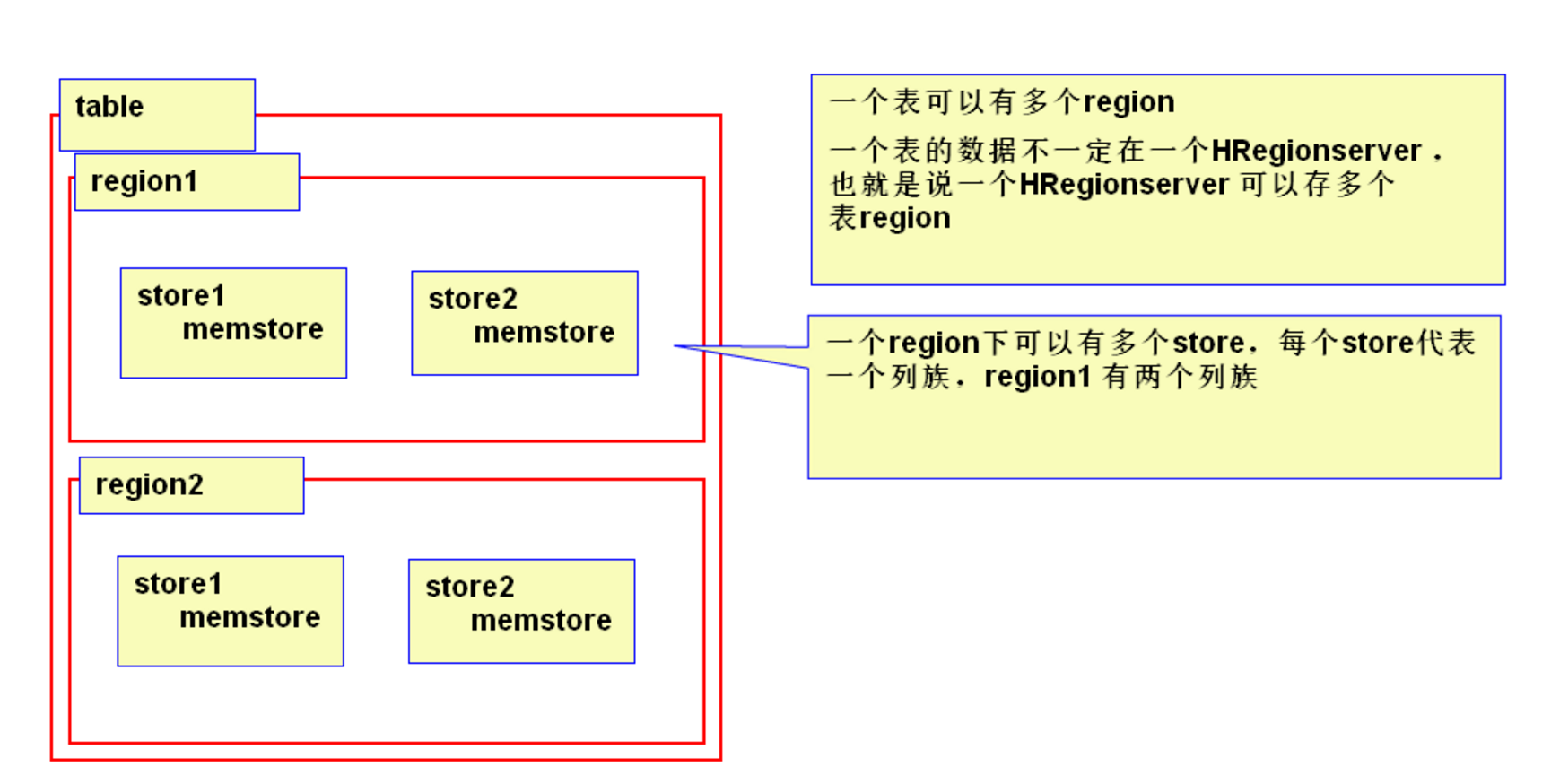
- HRegionServer一般和DataNode在同一臺機器上執行,實現資料的本地性。
- HRegionServer內部管理了一系列HRegion物件,每個HRegion對應了Table中的一個Region。
- 一個Table可以有一個或多個Region,他們可以在一個相同的HRegionServer上,也可以分佈在不同的HRegionServer上,一個HRegionServer可以有多個HRegion,他們分別屬於不同的Table。
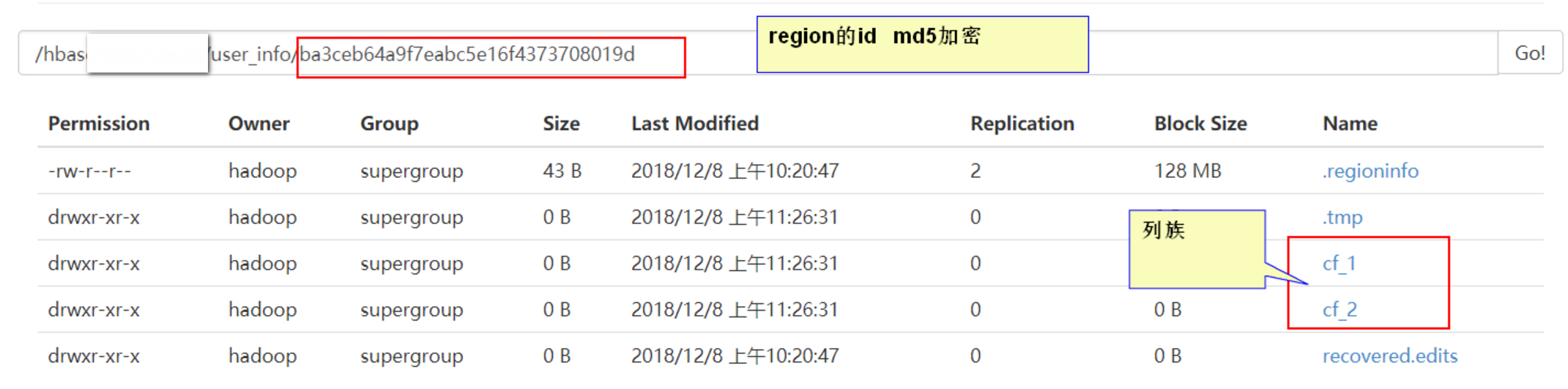
- HRegion由多個Store(HStore)構成,每個HStore對應了一個Table在這個HRegion中的一個Column Family,即每個Column Family就是一個集中的儲存單元,因而最好將具有相近IO特性的Column儲存在一個Column Family,以實現高效讀取。
- 每個HRegionServer中都會有一個HLog物件。HLog是一個實現Write Ahead Log的類,每次使用者操作寫入Memstore的同時,也會寫一份資料到HLog檔案,HLog檔案定期會滾動出新,並刪除舊的檔案(已持久化到StoreFile中的資料)。
- 引入HLog原因:
- 災難恢復。在分散式系統環境中,無法避免系統出錯或者宕機,一旦HRegionServer意外退出,MemStore中的記憶體資料就會丟失,引入HLog就是防止這種情況。
- 一個HStore由一個MemStore 和0個或多個StoreFile組成。
- MemStore:
- 是一個寫快取(In Memory Sorted Buffer),所有資料的寫在完成WAL日誌寫後,會寫入MemStore中,由MemStore根據一定的演算法將資料Flush到底層HDFS檔案中(HFile),通常每個HRegion中的每個 Column Family有一個自己的MemStore。
- StoreFile:
- 用於儲存HBase的資料(Cell/KeyValue)。在HFile中的資料是按RowKey、Column Family、Column排序,對相同的Cell(即這三個值都一樣),則按timestamp倒序排列。
2.4、Zookeeper
- ZooKeeper為HBase叢集提供協調服務,它管理著HMaster和HRegionServer的狀態(available/alive等),並且保證叢集中只有一個HMaster,會在它們宕機時通知給其他HMaster,從而可以實現HMaster之間的故障轉移;
- 實時監控HRegionServer的上線和下線資訊,並實時通知給HMaster;
- 儲存HBase的Meta Table(hbase:meta)的位置,Meta Table表儲存了叢集中所有使用者HRegion的位置資訊,且不能split;
- Zookeeper的引入使得Master不再是單點故障;
在zookeeper的節點中:
/hbasae/master:來表示Active的HMaster;
如果當前Active的HMaster宕機,則該節點消失,因而其他HMaster得到通知,而將自身轉換成Active的HMaster,在變為Active的HMaster之前,它會建立在/hbase/back-masters/下建立自己的Ephemeral節點;
&n