
編譯原理之語法分析-自下而上分析(四)
(一)LR(k)專案
LR(k)專案與之前SLR(1)中的專案有所不同,LR(k)專案是一個二元組[ 產生式,終結符 ]的形式
定義:使得每個專案都附帶有k個終結符,專案是二元組,一般形式是[ A->α· β ,a1 a2 ....ak],這樣的專案稱為LR(k)專案。k越大,LR(k)專案越多。
-
-
- 顯然,從定義中我們能得出A->α· β是一個LR(0)專案,因為它後邊二元組的終結符個數為0。
- a1 a2 ..... ak是終結符,稱為向前搜尋符串(展望串)
- α處於棧頂位置
- 圓點後邊的輸入可以匹配 β a1 a2 ..... ak
-
(二)LR(1)專案
定義:我們只對k<=1的情形感興趣,通過向前搜尋一個符號就可以確定移進或歸約,如果K=1,即LR(1)專案,[ A->α· β ,a ]。
-
-
- 對於任何移進或待約專案[ A->α· β ,a](β != ε),搜尋符串a沒有任何作用。
- 向前搜尋符a僅對歸約專案[ A->α β · ,a]有意義。
- 當它所屬的狀態呈現在棧頂且後續的輸入符號為a時,才可以把棧頂上的αβ歸約為A。
- 當歸約A->αβ(第i個產生式)時,a時前看符號。把ri填入到ACITON[ s,a ]中。
-
LR(1)專案的構造:
-
-
- 對於專案[ A->α ·Bβ,a ],新增[ B->γ ,b ] 到專案集,b屬於First(βa)。
- 與LR(0)相比,僅有閉包的計算方法不同。
- 為構造有效的LR(1)專案集族我們需要兩個函式CLOSURE和GO。
-
CLOSEURE(I)的定義:

GO的定義:

(三)構造LR(1)文法分析表
下圖中有一增廣文法,求出它的專案集。

老規矩,直接上答案圖,然後按步驟講解。
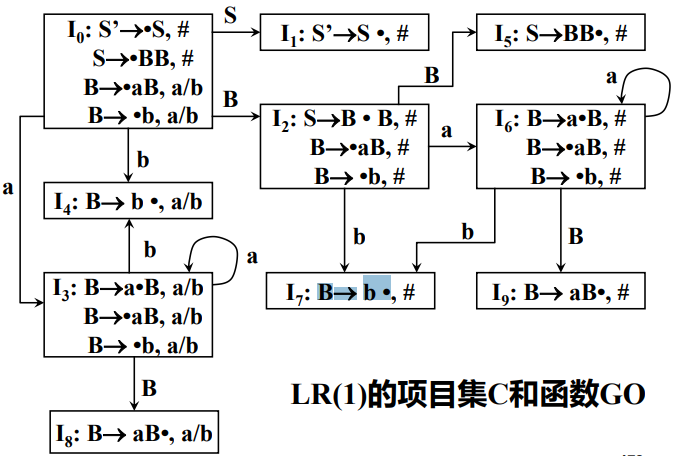
- 從S' -> ·S且專案集編號為0開始,S'為開始符號,二元組終結符部分是#,所以二元組為[ S' -> ·S,# ]。
-
-
- 根據定義,圓點後為S(非終結符),將S -> ·BB加入0號專案集,因為S->·BB中的S是從S'->S而來的,在二元組 [S'->·S,# ]求出Follow(S) = { # },所以得出二元組[ S->·BB,# ]
- 根據定義,圓點後為B(非終結符),將B -> ·aB加入0號專案集,求出S -> ·BB圓點後第一個符號(第一個B)的Follow集,或求出圓點後從第二個符號開始的(第二個B開始)的First集。求出First(B,#)={a,b},(注意First(B)中的B是S -> ·BB中的第二個B),所以得出二元組[ B -> ·aB,a | b ]。
- 將B->B -> ·b加入0號專案集,(注意這裡產生式左部的B,也是來自於S->·BB中的第一個B),因此我們只需要求出Follow(第一個B)或者First(第二個B,#)即可,得出First(B)={a,b},加入二元組[ B->·b, a | b ]
- 至此0號專案集已經完成
-
2.專案集0輸入符號B進入專案集2,從S->B·B開始,這裡的S來自於專案集0中的[S->·BB,#],而S->·BB來自於[ S'->·S,# ],因此專案集2中加入二元組[ S->B·B ,#]。
-
-
- 根據定義,S->B·B中,圓點後為非終結符,加入B -> ·aB,而產生式左部的B來自於專案集2中[ S->B·B ,# ]中的第二個B,所以求出Follow(第二個B)={ # },或First(#)={ # },所以加入二元組[ B -> ·aB ,#]。
- 專案集2加入B->·aB之後還需要加入B->·b,這個B同樣來自於專案集2中[ S->B·B ,# ]中的第二個B,所以求出Follow(第二個B)={ # },或First(#)={ # },所以加入二元組[ B->·b ,#]。
- 至此2號專案集已經完成
-
3. 專案集0輸入符號a進入專案集3,從B->a·B開始,產生式左部的B來自於專案集0中的[ B->·aB,a | b],而B->·aB又來自於S->·BB,所以求出Follow(第一個B)={ a,b }或First(第二個B,#)={ a,b },所以專案集3中加入[ B->a·B ,a | b]
-
-
- 根據定義,B->a·B中圓點後為非終結符,加入B->·aB,繼續找出產生式左部B的來源,來自於專案集3中[ B->a·B,a | b ]求出Follow(B)={a , b},First(a|b)={a,b},因此專案集3中加入二元組[B->·aB,a | b]。
- 同樣專案集3加入B->·b,繼續找出產生式左部B的來源,來自於專案集3中[ B->a·B,a | b ]求出Follow(B)={a , b},First(a|b)={a,b},因此專案集3中加入二元組[B->·b,a | b]。
- 至此3號專案集已經完成
-
因為專案集過多,這裡只選出具有代表性的三個專案集解釋,其他專案集可按該思路得出。
總結:有一產生式 S -> xxx(x代表任意終結符或非終結符),就去查詢該S的來源,然後找到源二元組[ E->x·SA,abc ]之後,求出Follow(S),或 First(Aabc)即可。
下圖是該文法的LR(1)分析表
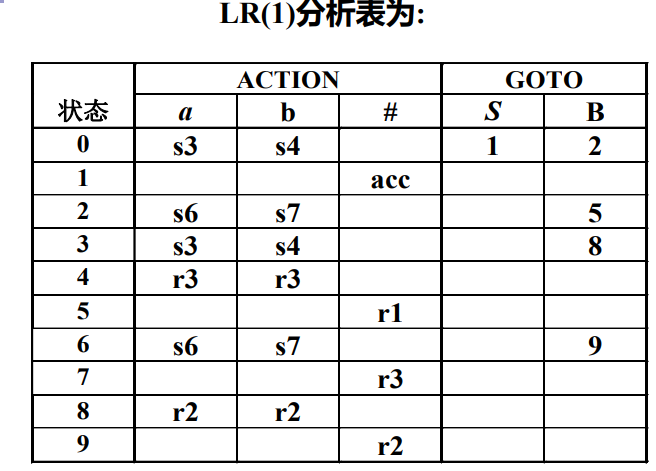
可以發現歸約專案集為4、5、7、8、9,而再檢視對應的的LR(1)專案集可以看出來:
-
-
- 4號專案集終結符為a,b,因此在ab所在列填入r3(Ri中的 i 為文法編號,第一個圖)。
- 5號專案集終結符只有#,因此只在#所在列填寫r1。
- 7號專案集終結符只有#,因此只在#所在列填寫r3。
- 8號專案集終結符為a,b,因此在ab所在列填入r2。
- 9號專案集終結符只有#,因此只在#所在列填寫r2。
-
表中其餘內容與LR(0)和SLR(1)基本一致,這裡就不再介紹。至此LR(1)分析表就構造完成。
對於該文法再給出LR(0)和SLR(1)分析表,可以做一下對比理解,自己推下3個分析表如何構造:


最後給出三個分析表演算法的系統語言:



到此為止,就已經完成LR(0)、SLR(1)、LR(1)分析表的構造以及流程。
總結一下三個表流程(重點、重點、重點!!!):
- 構造增廣文法。
- 根據增廣文法列出專案集
- 構造NFA(該步驟可以省略)
- 構造LR(0)DFA(這一步非常重要,如果DFA構造錯誤則分析表會出錯,LR(0)和SLR(1)的DFA一樣,LR(1)的DFA中產生式後需要計算終結符 )
- 判斷是不是LR(0)文法,如果存在衝突則下一步,如果不存在衝突則該文法是LR(0)文法。(是LR(0)文法則一定是SLR(1)和LR(1)文法)
- 判斷衝突能否用SLR(1)的解決方法消除,如果能消除則是SLR(1)文法,如果不是則下一步
- 根據LR(0)的DFA或SLR(1)的DFA(一元組形式)計算每個產生式的展望串,從而得出LR(1)的DFA(二元組形式)。
- 根據衝突專案集中終結符去判斷能否消除衝突,如果S-R或R-R衝突的兩個二元組中的終結符沒有交集則視為可以消除衝突,如果不能消除至此則該文法不屬於上述3個文法的任意一個。
LALR文法就不再介紹了,如果有興趣可以檢視一下其他優秀的部落格,至此自下而上分析法就已經介紹完畢(該部落格為個人學習總結,如果錯誤或異議歡迎指出,謝謝。)