
資料流圖 + 資料字典
阿新 • • 發佈:2020-05-25
## 一、資料流圖和資料字典是用來幹啥的?
> ### 1、資料流圖(Data Flow Diagram, DFD)
>
> > 從"資料(Data)"一詞中我們可以看出它是用來描述資料的,也就是說它的物件(或者說核心)應該是資料,要描述“(資料)是什麼?”;從"流(Flow)"一詞中我們又可以提煉出它的角度是(資料的)傳遞過程與加工,即“(資料)由有哪些屬性構成?從哪兒來?到哪兒去?要幹啥?”;最後著眼"圖(Diagram)"可以得出這是以圖形為基礎的模型,也就是用不同的圖形區分不同的類別。
> >
> > 所以總結起來,一句話概括:資料流圖(DFD)是從==資料(Data)==的==傳遞和加工(Flow)==角度,以==圖形(Diagram)==的方式來表達==系統的邏輯功能、資料在系統內部的邏輯流向和邏輯變換(Flow)==過程。
> >
> > 來,我們先看一個簡單的例項(現在不知道怎麼做很正常,一會兒詳細解釋)。
> >
> > 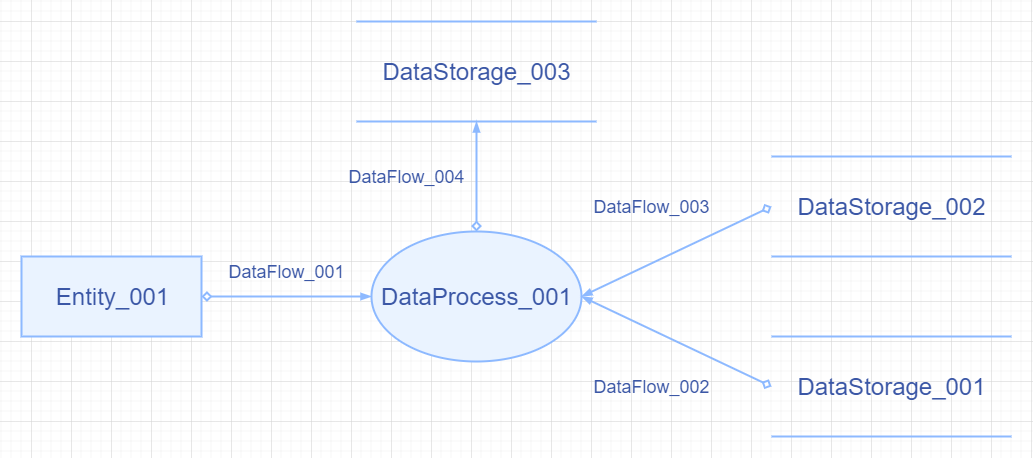 >
>
>
>
>
>
> ### 2、資料字典(Data Dictionary) > > > 大家試想一下,我們現在已經擁有了一張"資料流圖(DFD)",那麼光有這麼一張圖可以嗎?比如說,你知道$Entity\_001$具體是啥嘛?不知道叭,這時肯定有吐槽“那就把名稱加上唄”,但$Entity\_001$僅僅只是一個名稱嘛,既然是一個實體那是不是就還有屬性呢?這時將這些屬性一一標記上去這張圖會是什麼樣,顯然就非常的凌亂。所以我們就用一個代號來表示一個物件(包括實體、資料流、加工、儲存),在圖之外引入新概念——資料字典(DD)來對這些代號進行解釋。下面就來簡單看一下資料字典是什麼。 > > > > 不用多說肯定是一個描述"資料(Data)"的東西,那怎麼描述的呢?答案就是用"==字典(Dictionary)=="。字典是啥,只知道《辭海》、《康熙》或者《牛津》?umm……我可以說這差不多,字典就是一種對映關係,我們小時候“作弊”用的“暗號”就是一個不成文的字典,譬如$X$同學規定撳動一次就選$A$、撳動兩次就選$B$……,那麼我們就可以得到如下的字典: > > > > | 明文(也可以是id號) | 密文(也可以是對對應id號的解釋) | > > | -------------------- | -------------------------------- | > > | 1 | $A$ | > > | 2 | $B$ | > > | …… | …… | > > | 26 | $Z$ | > > > > 所以字典的本質也就是一張表,又由於是對資料流圖的描述,那很自然地就包括如下幾個方面:(Ⅰ)資料項;(Ⅱ)資料結構;(Ⅲ)資料流;(Ⅳ)資料儲存;(Ⅴ)處理過程;這裡先各出一個例項(用上面的資料流圖為例,構造一個合理的、簡化的資料字典): > > > > **(ⅰ)資料項:** > > > > | $ID$ | $Name$ | 含義 | > > | :-----------: | :----------: | :----------------------------: | > > | $studentID$ | 學生的$ID$號 | 對學生實體集有唯一標識的識別符號 | > > | $studentName$ | 學生的姓名 | 每一個學生實體在社會中的代號 | > > > > **(ⅱ)資料結構:** > > > > | $ID$ | $Name$ | 組成(實體的屬性) | > > | :-----------: | :------: | :----------------: | > > | $Entity\_001$ | 學生實體 | $ID$號、姓名 | > > > > **(ⅲ)資料流:** > > > > | $ID$ | $Name$ | > > | :-------------: | :----------: | > > | $DataFlow\_001$ | 排課資訊 | > > | $DataFlow\_002$ | 學生資訊 | > > | $DataFlow\_003$ | 課程資訊 | > > | $DataFlow\_004$ | 學生選課資訊 | > > > > **(ⅳ)資料儲存:** > > > > | $ID$ | $Name$ | > > | :----------------: | :------------------------: | > > | $DataStorage\_001$ | 學生自然情況(學生資訊表) | > > | $DataStorage\_002$ | 課程資訊表 | > > | $DataStorage\_003$ | 學生的選課表 | > > > > **(ⅴ)處理及加工:** > > > > | $ID$ | $Name$ | 處理 | > > | :----------------: | :------: | :----------------------------: | > > | $DataProcess\_001$ | 學生選課 | 記錄學生的$ID$、被選課程的$ID$ |
## 二、詳細介紹資料流圖和資料字典 > ### 1、資料流圖 > > > #### (Ⅰ)資料流圖的基本圖形和符號 > > > > > 我們先從最簡單的圖形分類入手,這裡給出常用的四種基本圖形及其含義【在圖形中標註編號($ID$)或者名稱($name$),或者兩者都標上,這樣看圖的時候既更直觀還容易查詢$ID$索引】: > > > > > > | 圖形(符號) | 類別名稱 | 含義說明 | > > > | :----------------------------------------------------------: | :----------------------------------------------: | :----------------------------------------------------------- | > > > |
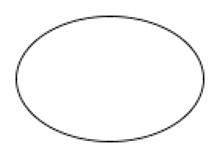 | 資料的加工和處理
| 資料的加工和處理
($Data Process, DP$) | 必須有輸入流和輸出流,缺一不可 | > > > | | 資料的源點或匯點,
| 資料的源點或匯點,
也就是外部實體($Entity$) | 資料加工的一端,要麼提供資料,
要麼彙集資料形成新的外部實體 | > > > |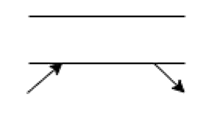 | 資料儲存檔案
| 資料儲存檔案
($DataStorage$) | 資料加工的一端,
可以提供資料或者儲存資料 | > > > | | 資料流
| 資料流
($DataFlow$) | 一邊為實體或者資料儲存檔案,
另一邊為資料的加工和處理,
其名稱清晰表達傳遞的主要資料 | > > > > > > 在加工的時候不可避免會出現多種資料進出的情況,那麼資料流圖是怎樣表示的呢?在做表之前我們先畫出資料加工和資料流的圖【$(\theta_1,\theta_2) \in \theta=\{+, *, \bigoplus\}$】: > > > > > >
> > #### (Ⅱ)資料流圖設計的原則 > > > > > **(1)、任意流不能重名** 因為流的名字即為他們的$ID$號,常識告訴我們不存在兩個完全一樣的物體,為了區分必須避免重名; > > > > > > **(2)、資料守恆原則** 對於任意一個數據處理來說,其全部的輸出資料流中的資料必定能從其輸入資料流中的資料直接獲得。這一原則也說明了資料流是必須與資料處理有關的,應該也只能依附與資料流。我們可以用能量守恆來理解這一原則,將資料儲存和外部實體比作物體、資料比作能量,資料處理即為物體之間的相互作用,只有在物體進行相互作用的時候才會存在能量的流動(傳遞),所以同理可得==只有在資料處理的推動下,資料才得以傳遞,從而形成資料流==。 > > > > > > > ①、外部實體與外部實體之間不存在資料流; > > > > > > > > ②、外部實體與資料儲存之間不存在資料流; > > > > > > > > ③、資料儲存與資料儲存之間不存在資料流; > > > > > > > > ④、資料流必須經過(其中一端為)資料處理(加工); > > > > > > **(3)、守恆加工原則** (前兩條都是針對加工而言) > > > > > > > ①、對於任意一個加工,至少有一個數據輸入流和一個數據輸出流; > > > > > > > > ②、由**任意流不能重名**可以推出:對於任意一個加工,輸入資料流與輸出資料流必須不同名,即使輸入的資料與輸出的資料結構一模一樣,但是這樣的情況常見於向資料儲存檔案寫入資料的時候:由於**資料守恆原則**,資料流必須經過資料加工,但是這樣的資料加工並不會改變資料流中的資料。所以人們規定:**對流進或者流出資料儲存檔案的資料流不需要標註名字**,因為檔案本身就足以說明資料流。所以,如果一種資料流需要被多次引用時可以建立一個臨時的資料儲存(對應的就是記憶體資料庫),這樣就沒有必要為同一種資料流進行標號。另外,當輸入輸出流一模一樣的情況發生在非資料儲存檔案操作時,就要考慮其加工或者資料來源存在的合理性和必要性了,因為這相當於沒有對資料進行處理,屬於冗餘操作; > > > > > > > > ③、資料來源包含資料儲存檔案、最終新形成的外部實體和資料儲存檔案必須與資料來源同級,也就是說**資料流的終點一定是在外部並且指向外部實體或者資料儲存檔案**。因為只要有外部資料流參與,那麼有入必有出,這個出就是指向新形成外部實體或資料檔案的輸出資料流;比如下圖中的資料檔案:$Student\_Course$。 > > > > > > > >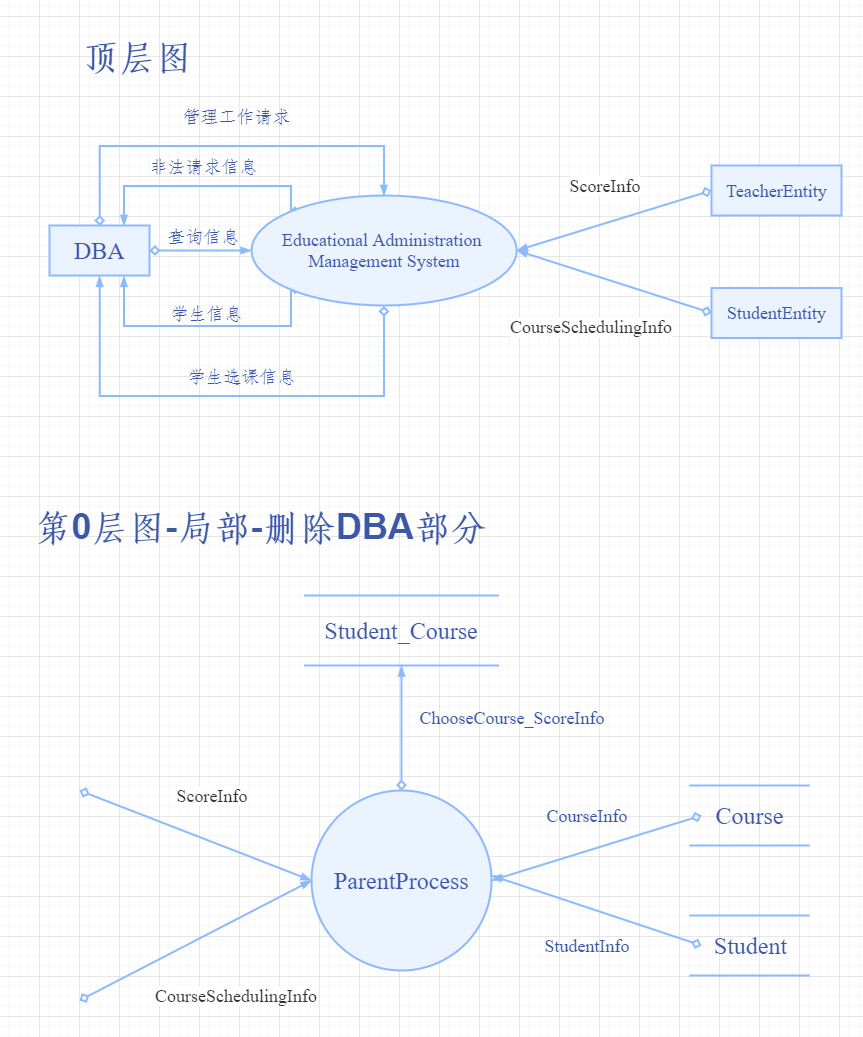
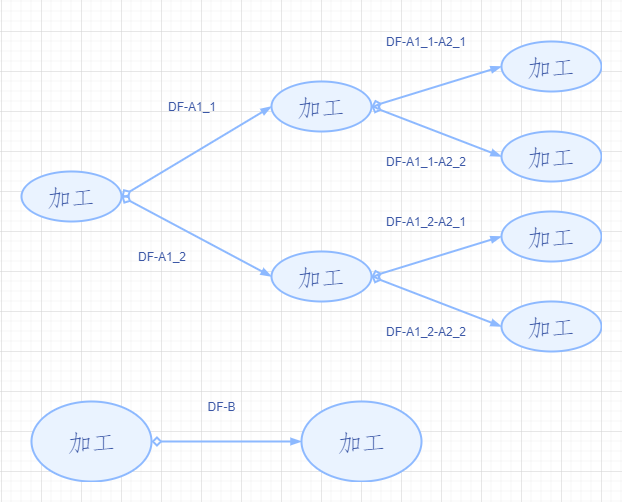 > > > >
> > > > > (ⅰ)$DF-A$系列與$DF-B$系列相互獨立;
> > > > >
> > > > > (ⅱ)$DF-A1$系列之間($DF-A1\_1$與$DF-A1\_2$)相互獨立;
> > > > >
> > > > > (ⅲ)彼此的後繼之間($DF-A1\_1$與$DF-A1\_2-A2$系列、$DF-A1\_2$與$DF-A1\_1-A2$系列、$DF-A1\_1-A2$系列與$DF-A1\_2-A2$系列)相互獨立。
> > > >
> > > > ⑦、很容易被忽視的一點:資料儲存不可能憑空出現在資料庫管理系統中,必須通過作業系統從磁碟中讀取相應的檔案載入記憶體,當對資料儲存檔案操作完成之後,再寫入磁碟。但是正是因為所有的資料流圖都有這一類資料流,所以常常被作為枝節被省略,這導致在研究細節的時候發現很多資料流圖都沒有遵守守恆加工原則;所以完整的資料流圖應該是這樣(用虛線表示省略的):
> > > >
> > > >
> > > >
> > > > > (ⅰ)$DF-A$系列與$DF-B$系列相互獨立;
> > > > >
> > > > > (ⅱ)$DF-A1$系列之間($DF-A1\_1$與$DF-A1\_2$)相互獨立;
> > > > >
> > > > > (ⅲ)彼此的後繼之間($DF-A1\_1$與$DF-A1\_2-A2$系列、$DF-A1\_2$與$DF-A1\_1-A2$系列、$DF-A1\_1-A2$系列與$DF-A1\_2-A2$系列)相互獨立。
> > > >
> > > > ⑦、很容易被忽視的一點:資料儲存不可能憑空出現在資料庫管理系統中,必須通過作業系統從磁碟中讀取相應的檔案載入記憶體,當對資料儲存檔案操作完成之後,再寫入磁碟。但是正是因為所有的資料流圖都有這一類資料流,所以常常被作為枝節被省略,這導致在研究細節的時候發現很多資料流圖都沒有遵守守恆加工原則;所以完整的資料流圖應該是這樣(用虛線表示省略的):
> > > >
> > > >  > > > >
> > > > 這個時候我們就可以理解為:從作業系統中讀取的檔案與外部實體給予的資訊進行組合(資料加工),最後形成了新的檔案並寫入磁碟中。
> > >
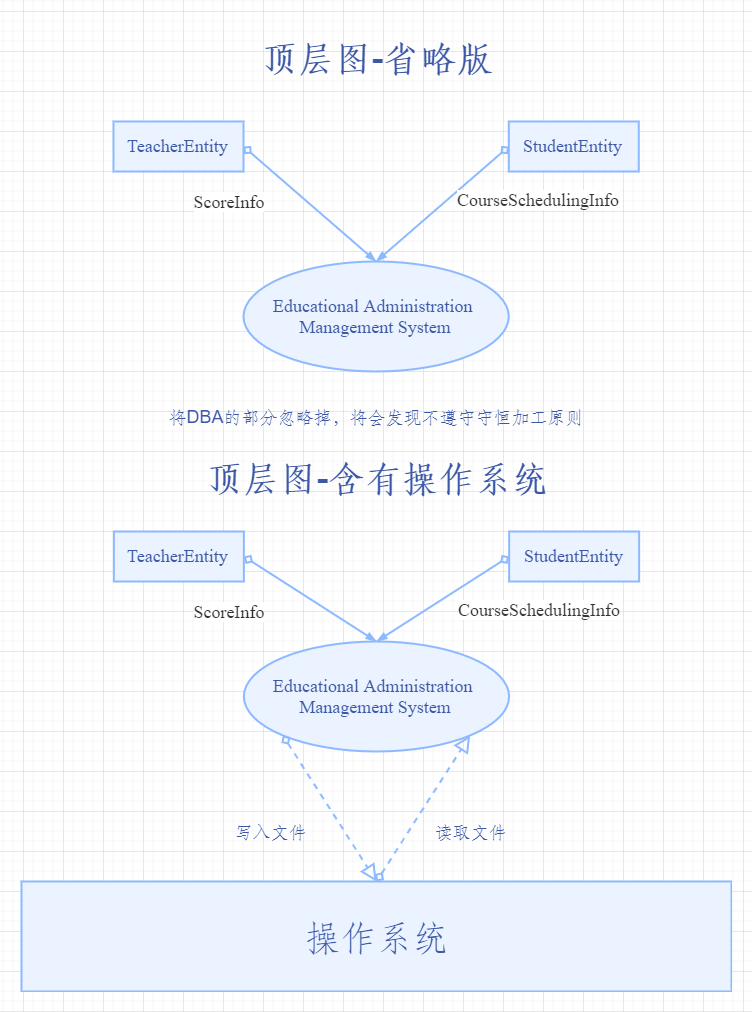
> > > **(4)、父圖與子圖應該統一輸入輸出流:** 父圖可以看做是一個整體,也就是一個黑盒子,其中包含了很多個子圖,那麼子圖的輸入輸出流當然就源自黑盒子(父圖);比如學生選課後出了成績:
> > >
> > >
> > > >
> > > > 這個時候我們就可以理解為:從作業系統中讀取的檔案與外部實體給予的資訊進行組合(資料加工),最後形成了新的檔案並寫入磁碟中。
> > >
> > > **(4)、父圖與子圖應該統一輸入輸出流:** 父圖可以看做是一個整體,也就是一個黑盒子,其中包含了很多個子圖,那麼子圖的輸入輸出流當然就源自黑盒子(父圖);比如學生選課後出了成績:
> > >
> > >  > > >
> > > 一共分了兩個區域(上下),上部分為整體的區域性資料流圖,資料處理由一個父圖構成;下部分即為父圖中更加細節的子圖資料流圖。這個時候我們可以看到父圖由外部資料流($CourseSchedulingInfo$、$ScoreInfo$、$CourseInfo$、$StudentInfo$)的參與產生了一個新的資料儲存($Student\_Course$),必須將其提出放在父圖的外部,如果不這樣做的話就會違反**守恆加工原則**。由父圖子圖流一致原則我們可以得出另一重要的原則:**加工細節隱蔽原則**,就是說沒有必要一味地對父圖進行拆分,可以適當地只保留父圖不去關心子圖的內在聯絡(類比整體法)。
> > >
> > > **(5)、簡化加工之間的關係** 加工間的資料流越少,各個加工就越相對獨立、耦合度就越低,如果資料流很多的話,雖然可以實現較為複雜的功能但是也增加了運維成本,甚至可能造成動一發而牽全身的混亂局面。這就要求我們做到**==先抓住主要矛盾,暫時忽略枝節==**。
> > >
> > > **(6)、均勻分解父圖** 儘量不要出現對資料處理分解的兩極化,比如一個分了七八層而另一個只分了兩三層,這樣會造成輕重不一的局面存在考慮不周的潛在隱患。
> > >
> > > **(7)、是資料流而不是控制流** 資料流是控制流上的操作表示,只有在控制流上進行的資料流分析才有價值。也就是說資料流圖只需要表達出資料的結構、來源、流向、加工,並不關心資料流在融入控制層之後進行的邏輯處理與程式跳轉的結果(程式元素邏輯執行的先後順序)。
> >
> > 在這些原則中==最重要==的當屬:**保持父圖與子圖平衡**,**保持資料平衡**,**加工細節隱蔽**。
>
> > >
> > > 一共分了兩個區域(上下),上部分為整體的區域性資料流圖,資料處理由一個父圖構成;下部分即為父圖中更加細節的子圖資料流圖。這個時候我們可以看到父圖由外部資料流($CourseSchedulingInfo$、$ScoreInfo$、$CourseInfo$、$StudentInfo$)的參與產生了一個新的資料儲存($Student\_Course$),必須將其提出放在父圖的外部,如果不這樣做的話就會違反**守恆加工原則**。由父圖子圖流一致原則我們可以得出另一重要的原則:**加工細節隱蔽原則**,就是說沒有必要一味地對父圖進行拆分,可以適當地只保留父圖不去關心子圖的內在聯絡(類比整體法)。
> > >
> > > **(5)、簡化加工之間的關係** 加工間的資料流越少,各個加工就越相對獨立、耦合度就越低,如果資料流很多的話,雖然可以實現較為複雜的功能但是也增加了運維成本,甚至可能造成動一發而牽全身的混亂局面。這就要求我們做到**==先抓住主要矛盾,暫時忽略枝節==**。
> > >
> > > **(6)、均勻分解父圖** 儘量不要出現對資料處理分解的兩極化,比如一個分了七八層而另一個只分了兩三層,這樣會造成輕重不一的局面存在考慮不周的潛在隱患。
> > >
> > > **(7)、是資料流而不是控制流** 資料流是控制流上的操作表示,只有在控制流上進行的資料流分析才有價值。也就是說資料流圖只需要表達出資料的結構、來源、流向、加工,並不關心資料流在融入控制層之後進行的邏輯處理與程式跳轉的結果(程式元素邏輯執行的先後順序)。
> >
> > 在這些原則中==最重要==的當屬:**保持父圖與子圖平衡**,**保持資料平衡**,**加工細節隱蔽**。
>
>
> ### 2、資料字典 > > > #### (Ⅰ)資料字典的用途與組成 > > > > 根據之前的分析,我們可以得出:資料字典的就是對資料流圖中出現的所有被命名的圖形元素在資料字典中作為一個詞條加以定義,使每個圖形元素的名稱都有一個確切的解釋。 > > > > 最初只給了二級表頭,現在給出更加精細的三級表頭,畫一個[思維導圖](https://www.jianguoyun.com/p/DZMHKMwQ3sG6CBjFkpsD)會更加清晰。 > > > >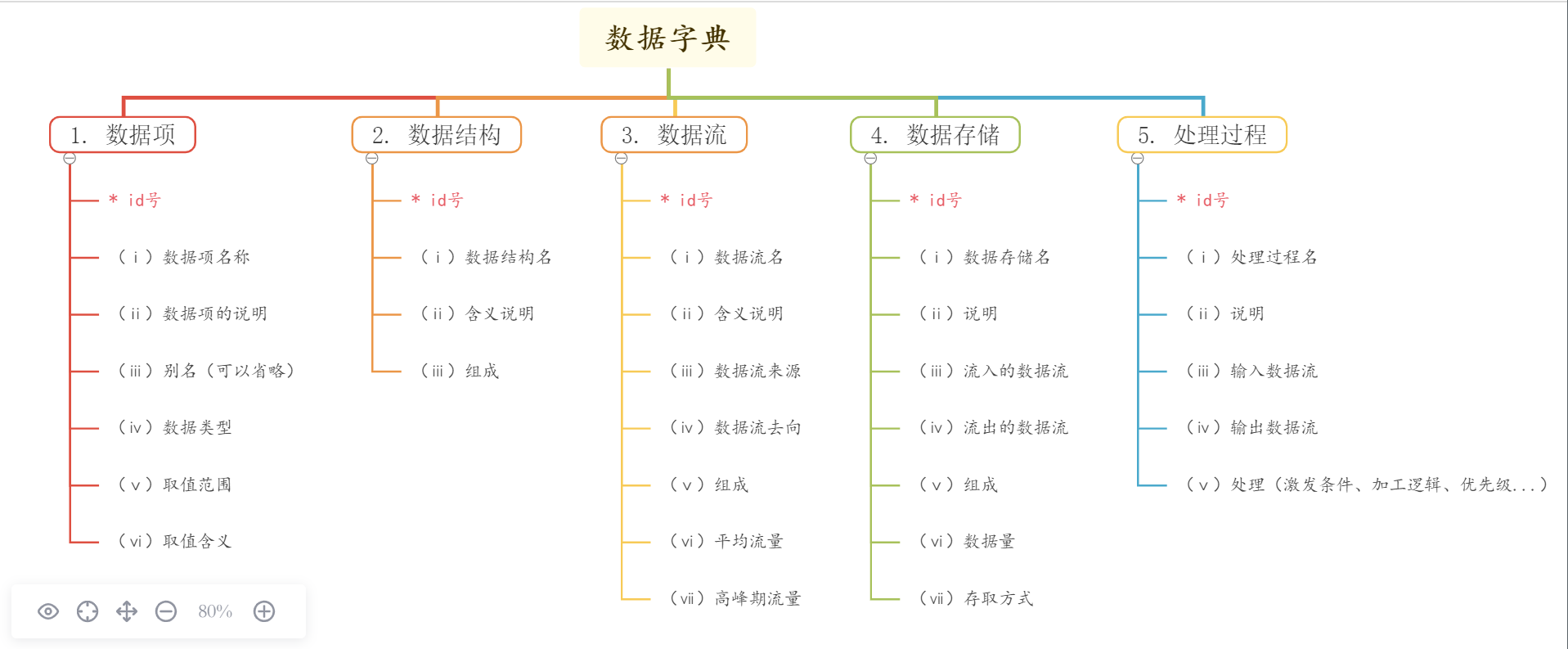 > >
> > 具體例項請看傳送門:[資料字典舉例](https://wenku.baidu.com/view/63a49142cf84b9d528ea7ac0.html?fr=search)。(想要$PDF$版的可以私聊哦)
> >
> >
> > 具體例項請看傳送門:[資料字典舉例](https://wenku.baidu.com/view/63a49142cf84b9d528ea7ac0.html?fr=search)。(想要$PDF$版的可以私聊哦)
> >
> > #### (Ⅱ)資料結構的描述 > > > > > 在資料字典中最特殊的當屬資料結構了,因為資料結構是描述其他字典條目的基礎,所以準確來說,資料字典中應該是包含下面4種條目: > > > > > > > ①、資料項條目:資料型別、取值範圍……等; > > > > > > > > ②、資料流條目:定義、給出組成資料流的資料項(利用資料結構描述); > > > > > > > > ③、檔案條目:定義、給出組成檔案的資料項(利用資料結構描述); > > > > > > > > ④、加工條目:加工條目必須具備**原子性**,給出說明(激發條件、邏輯、處理順序……等); > > > > > > 我們言歸正傳,資料結構的描述通常採用如下表中的符號: > > > > > > | 符號 | 含義 | 說明 | > > > | :----------------------: | :---------------------------------: | ---------------------------------------- | > > > | = | 被定義為(賦值) | $x=a$,$x$由且僅由$a$構成 | > > > | + | 與 | $x=a+b$,$x$由$a$和$b$構成 | > > > | […\|…]或者[…, …] | 或 | $x=[a,b]$,$x$由$a$或者$b$構成 | > > > | $m${…}$n$、{…}$_{N}^{M}$ | 重複($m,n$的預設值為0和$+\infty$) | $x=3\{a\}6、\{a\}_3^6$,$a$可以重複3~5次 | > > > | (…) | 可選(非必須項) | $x=(a)$,$a$可以出現在$x$中 | > > > | "…" | 基本資料元素 | $x="a"$,$x$取值為$a$的資料元素 | > > > | ·· | 連線 | $x=a··f$,$x$由$a\sim f$組成 | > > > > > > 比如我們要表示學生這個實體集(或者學生表)時,就可以這樣: > > > > > > $StudentEntity=studentID+studentName+studentIDCard+studentSex+\{studentInterest\}+(studentInfo)$, > > > > > > 再比如我們新建一個可以實現查詢的任務,包括查詢學生資訊、課程資訊以及學生選課資訊,這是當資料庫管理員(或者教務系統管理員)向教務管理系統發出查詢請求(資料流)的時候就可以這樣表示: > > > > > > $selectRequestInfo=[selectStudentInfo\ |\ selectCourseInfo\ |\ selectStudent\_CourseInfo]+\{IllegalRequest\}$,
## 三、資料流圖 & 資料字典 綜合應用問題 > ### 1、需求 > > > 某教務管理系統的主要功能為:師生教學管理和資訊查詢。對於新招的師生,系統按照既定的法則自動生成師生的編號,並和他們的基本資訊一起分別寫入學生檔案和教師檔案,同樣適用於新開設的課程。 > > > > #### (Ⅰ)師生教學管理功能:新增師生和課程、登出師生和課程、學生選課出成績 > > > > > **(1)、新增師生和課程** 新招師生和課程的時候需要分別編制《入校學生單》、《新招教師單》以及《新開設課程單》以便直接對新增物件進行管理與研究,然後將資訊分別寫入《學生表》、《教師表》和《課程表》。 > > > > > > > ①、《入校學生單》:$ID$號、姓名、身份證、出生年月日、性別、入校時間; > > > > > > > > ②、《新招教師單》:$ID$號、姓名、身份證、出生年月日、性別、新招時間; > > > > > > > > ③、《新開設課程單》:$ID$號、課程名、課時、上課資訊(日期時間教室列表)、新開設時間; > > > > > > **(2)、登出師生和課程** 學生畢業、老師退休以及課程結課的時候需要分別編制《學生畢業單》、《老師退休單》、《課程結課單》,然後分別修改《學生表》、《教師表》、《課程表》中的登出時間以及是否登出(預設值為$NO$,現改為$YES$)。 > > > > > > > ①、《學生畢業單》:$ID$號、畢業時間、是否畢業(只能填寫$YES$,用於覆蓋《學生表》); > > > > > > > > ②、《老師退休單》:$ID$號、退休時間、是否退休(只能填寫$YES$,用於覆蓋《教師表》); > > > > > > > > ③、《課程結課單》:$ID$號、結課時間、是否結課(只能填寫$YES$,用於覆蓋《課程表》); > > > > > > **(3)、學生選課出成績** 學生選課時需要編制《學生選課申請單》和《學生最新選課單》。 > > > > > > > ①、《學生選課申請提交單》:學生的$ID$號、課程的$ID$號、選課權重 > > > > > > > > ②、《學生最新選課單》:學生的$ID$號、課程的$ID$號、選課權重; > > > > > > 假設選課權重在同一學號記錄中不能重複,且為[1, 6]之間的整數,當學生提交《學生選課申請單》時系統給出選項,學生自行選擇,即限定每個學生的選課門數最多為6門。此外系統應該有三層過濾網(這三層過濾可以放置在一個加工中——加工細節隱蔽原則): > > > > > > > (ⅰ)系統首先通過聚合運算檢查在《學生最新選課單》中該學生的選課門數是否為6,若不是則允許將該學生《學生選課申請提交單》的選課資訊新增至《學生最新選課單》;若是則拒絕新增。 > > > > > > > > (ⅱ)如果選課門數小於6則進行衝突檢查,查詢《學生選課表》中該學號對應的選課課程號集合,再在《課程表》中查詢"上課資訊"這一欄位,然後與該學生新選課程的上課資訊進行比對。若這時沒有衝突才能將《學生選課申請提交單》的選課資訊寫入《學生最新選課單》;若有衝突則拒絕寫入。 > > > > > > > > (ⅲ)排處第一層衝突之後,系統應該檢查該學生所有新選課程的"上課資訊"進行比對,並按照選課權重選取權重最大的課程,其他與之相沖突的選課記錄將被刪去。 > > > > > > 經過系統的三層排除衝突之後的《學生最新選課單》方能寫入《學生選課表》。之後學生考試填寫試卷,教師批閱提供分數資訊,將分數資訊與選課資訊合併存入《學生選課表》。 > >
> > #### (Ⅱ)資訊查詢功能:查詢教師學生和課程的基本資訊、學生成績 > > > > > **(1)、查詢教師的基本資訊** 可以查詢到教師的基本資訊; > > > > > > **(2)、查詢學生的基本資訊** 可以查詢到學生的基本資訊; > > > > > > **(3)、查詢課程的基本資訊** 可以查詢到課程的基本資訊; > > > > > > **(4)、查詢學生成績的基本資訊** 可以查詢到學生選課的資訊以及學生在此課程中的分數情況; >
>
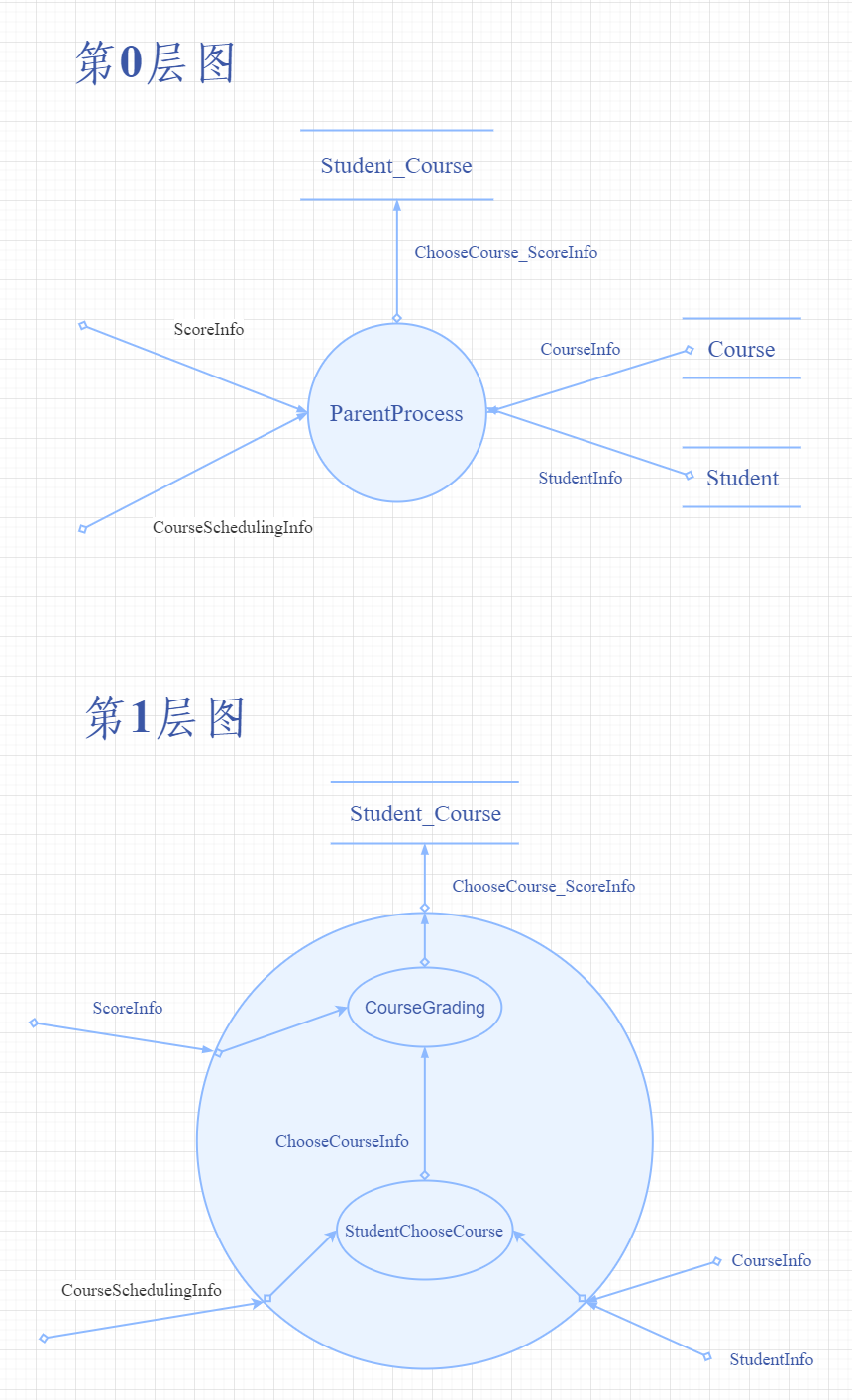
> ### 2、資料流圖 > > #### (Ⅰ)頂層圖: > >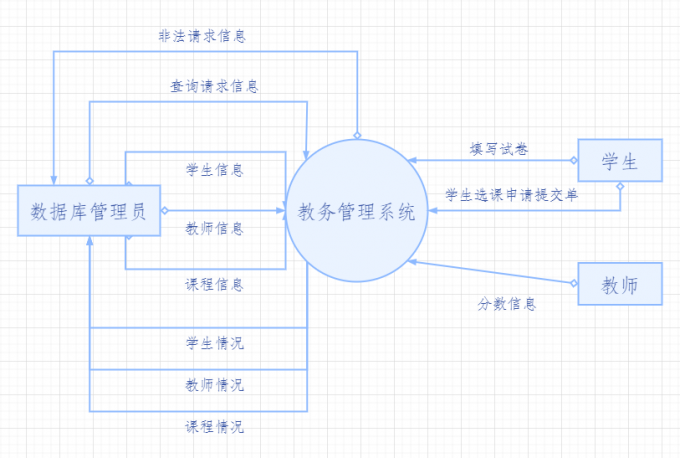 >
> #### (Ⅱ)第0層圖:
>
>
>
> #### (Ⅱ)第0層圖:
>
> 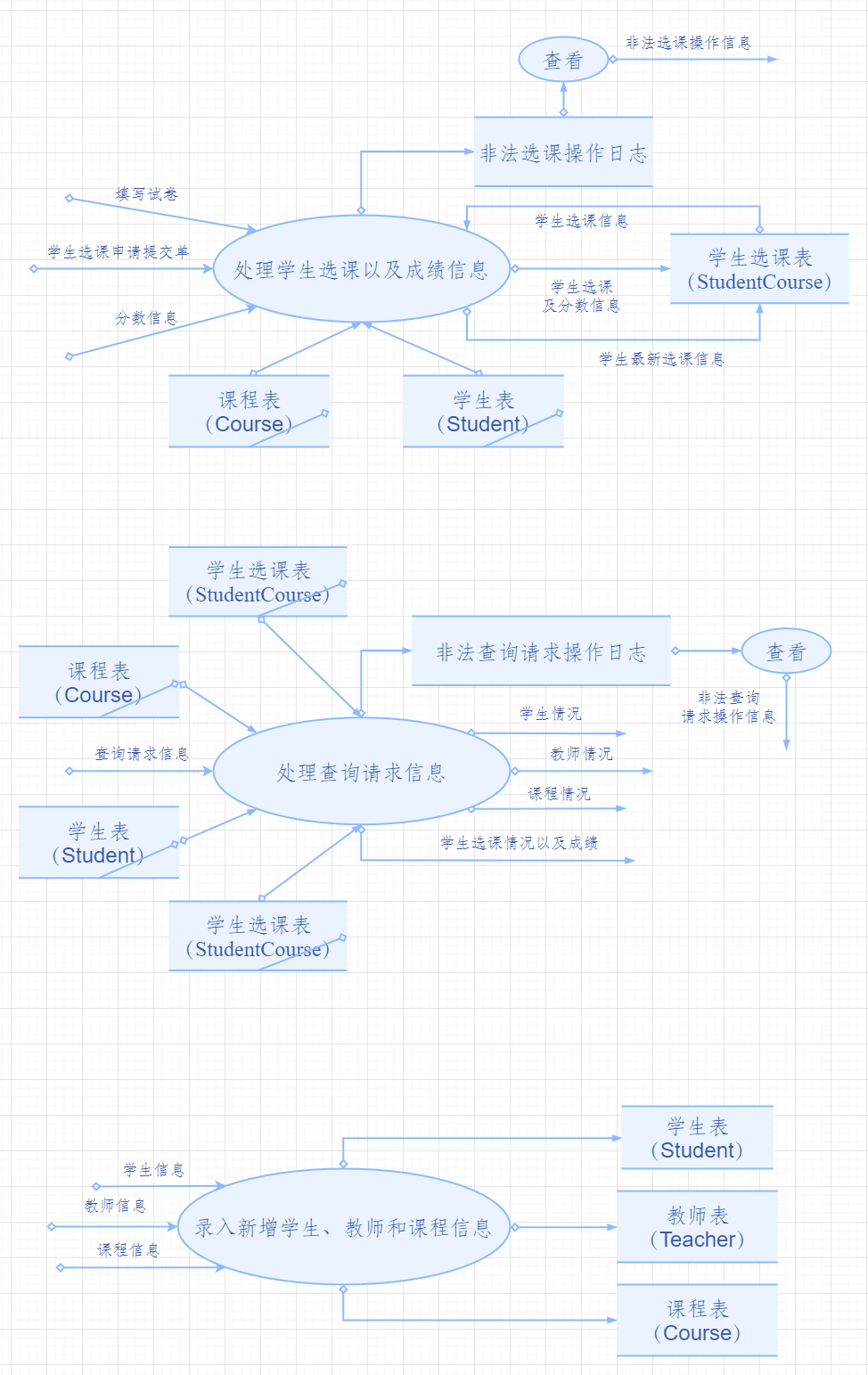 >
> #### (Ⅲ)加工的分解:
>
> > **(ⅰ)對處理學生選課以及成績資訊的分解:**
> >
> >
>
> #### (Ⅲ)加工的分解:
>
> > **(ⅰ)對處理學生選課以及成績資訊的分解:**
> >
> > 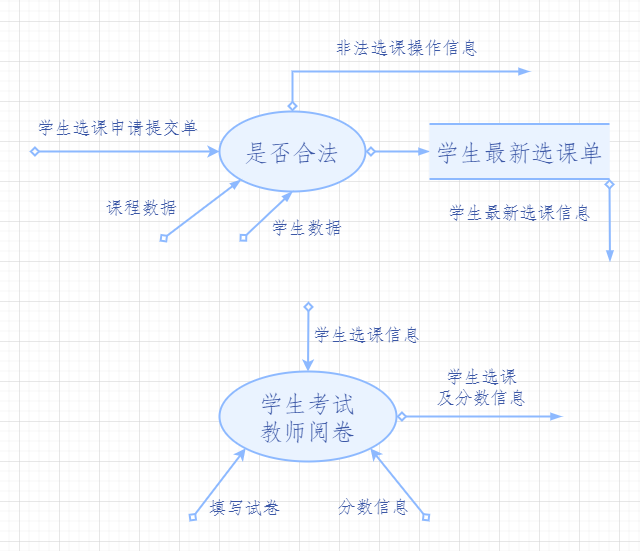 >
>
>
>
>
> ### 3、資料字典
>
> $Excel$檢視傳送門:[資料字典-教務管理系統部分功能](https://kdocs.cn/l/scw5fPmz7?f=111)
>
> $Excel$下載傳送門:[資料字典-教務管理系統部分功能](https://attachments-cdn.shimo.im/A3d7KVSCARChFNTO.xlsx)。
## 四、資料字典的補充
資料字典不單單是用於解釋資料流圖,還能在資料儲存檔案設計的時候提供援助。當現實世界中的主體有不斷變化的屬性時(屬性的數量和屬性的取值),尤其是變化得非常頻繁的時候,就會引入資料字典輔助資料表設計。
這裡簡單地介紹一下由[$rongwenbin$先生](https://blog.csdn.net/rongwenbin)總結的兩種用於輔助設計資料庫表的資料字典,原文傳送門:[資料字典](https://blog.csdn.net/rongwenbin/article/details/47086415)。為了更好理解我將先生用到的例項換做我們常見的教務管理系統,其主要功能為管理並查詢學生、教師、課程……等實體集的基本資訊。
在構建資料庫管理系統之前,我先將兩種資料字典擺出來:
> (Ⅰ)將主體的屬性編碼(設定每一個屬性$ID$號),並將這些$ID$號放入獨立的資料庫表中作為主鍵,其對應的值就是屬性的取值;(這對應於資料庫表規範化中的模式分解)
>
> (Ⅱ)將結構(模式)相同的資料庫表整合在一起,用統一的編碼規範設定$ID$號並將其作為主鍵,對應的值為屬性的名稱以及屬性的取值;(這對應於資料庫表規範化中的模式合併)
我們來看這樣一個需求:假設我們已經設計出了該教務管理系統的邏輯模型初稿,其中有一個模式為“學生(學號,姓名,系別名稱)”。在這一模式中體現出了“學生”實體和“學生屬於系別”聯絡,雖然一箭雙鵰提高了查詢的效率,但是這裡很明視訊記憶體在一個問題:**系別的名稱如果更改,則學生表中的"系別名稱"屬性的取值都要做出相應的調整**,這系別名稱還好,如果是國籍呢,比如前蘇聯到俄羅斯,這就要涉及到上億份資料。怎樣解決這一問題呢?先生指出我們可以參考(Ⅰ)資料字典,新建一張《系別表》,其中存放"系別$ID$"和"系別名稱",這樣在學生表中直接引入外來鍵"系別$ID$"即可,這是更改系別名稱就只用在《系別表》中更改"系別名稱"而"系別$ID$"不用改,保證了《學生表》的穩定性。上述文字轉換為資料表的動態變換就是:
更改之前的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別名稱 |
| --------- | ---- | ------------ |
| 180502304 | BN2U | 地理資訊系統 |
更改之後的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別$ID$ |
| --------- | ---- | -------- |
| 180502304 | BN2U | 001 |
新建的《系別表》及例項:
| 系別$ID$ | 系別名稱 |
| -------- | ------------ |
| 001 | 地理資訊系統 |
根據上級的命令更改資料,將“地理資訊系統”改為“地理資訊科學”這樣的話就會有:
更改之後的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別$ID$ |
| --------- | ---- | -------- |
| 180502304 | BN2U | 001 |
新建的《系別表》及例項:
| 系別$ID$ | 系別名稱 |
| -------- | ------------ |
| 001 | 地理資訊科學 |
顯然《學生表》沒有任何改動。
這樣很$nice$但是有沒有想過如果一個主體中的屬性不是兩三個,而是幾十個甚至上百個,那麼每一次查詢都涉及到上百個奪標連線操作,這時的查詢效率簡直不敢恭維。於是先生又提出了第二種方案:(Ⅱ)資料字典,將屬性資料表進行合併,但是並不是將所有的資料表進行合併,而是針對模式(結構)一樣的一組表。這樣就能將查詢所涉及到的表大幅度的減少,從而提高了查詢的效率。下面我們來看一個案例,解釋(Ⅰ)的缺點和(Ⅱ)。
我們現在有一個需求:假設我們更新了模式,最後變為“學生(學號,姓名,證件型別,證件號,國籍,民族,系別名稱,政治面貌)”,根據(Ⅰ)的分解,我們可以將模式繼續升級為“學生(學號,姓名,證件型別$ID$,國籍$ID$,民族$ID$,系別$ID$,政治面貌$ID$)”、“證件型別(證件型別$ID$,證件型別,證件號)”、“國籍(國籍$ID$,國籍)”、“民族(民族$ID$,民族名稱)”、“系別(系別$ID$,系別名稱)”、“政治面貌(政治面貌$ID$,政治面貌名稱)”,就這樣一直被分解,如果只是5個左右的表那查詢起來也不是很費勁,但是一個學生顯然不可能只有這樣幾個屬性,所以如果繼續分解下去就會帶來過於沉重的查詢計算量。
既然我們的目的是為了提高查詢效率,那個合併資料表顯然是一個不錯的選擇,但是我們知道一個數據表的模式是定死了的,並且屬性的取值是必須規定在同一個域,所以只有表結構相同、對應屬性的取值範圍相同的表才能夠合併。我們將目光轉移至分解之後的屬性表,發現除了《證件型別》這張表之外都很相似,模式都是“屬性的名稱(ID,屬性的值)”,那我們就可以合併了。回過頭看《證件型別》這張表,不難發現"證件號"可以作為主碼,從而代替"證件型別$ID$",這樣《證件型別》表的模式為“證件型別(證件號,證件型別)”。這時我們整合這些屬性表,得到一個新的表模式“屬性(屬性$ID$號,屬性分類$ID$號,屬性取值)”,構造一個例項:
《系統屬性程式碼表》
| 屬性$ID$號 | 屬性分類 | 屬性取值 |
| ---------- | -------- | ------------------ |
| 001 | 身份證 | xxxxxx20010202xxxx |
| 002 | 身份證 | xxxxxx20000302xxxx |
| 003 | 暫居證 | yyyyyy |
| 004 | 國籍 | 中國 |
| 005 | 國籍 | 薩摩亞 |
| 006 | 國籍 | 美國 |
| 007 | 系別 | 地理資訊科學 |
| 008 | 政治面貌 | 團員 |
| 009 | 政治面貌 | 黨員 |
| …… | …… | …… |
《學生表》
| 學生$ID$ | 學生姓名 |
| --------- | -------- |
| 180502304 | BN2U |
| 180502305 | $\pi$ |
| 180502302 | $e$ |
《屬性表》
| 學生$ID$ | 屬性$ID$ |
| --------- | -------- |
| 180502304 | 001 |
| 180502304 | 004 |
| 180502304 | 007 |
| 180502304 | 008 |
| 180502302 | 002 |
| 180502302 | 004 |
| …… | …… |
這樣在查詢任意一個學生的時候最多也就是3張表的查詢,一張差姓名、另外兩張查詢其他屬性$ID$以及對應的內容,這樣查詢效率是不是就大大提升了呢?但是細心的同學會發現這樣做的後果就是造成了最開始的問題:對資料庫進行更改很麻煩。所以這裡我想做的一點補充就是:這兩種資料字典的思想要相結合,我們可以在需求分析階段調查不易改變的屬性名稱,將這些屬性名稱利用(Ⅱ)資料字典整合成為一張表;相應地將容易改變的屬性名稱利用(Ⅰ)資料字典構造一張新的屬性表。就拿上面這個例子來說,對於“國籍”、“證件型別”、“民族”、“政治面貌”對於我們來說在相當長的一段時期內屬性的名稱是不會變化的(可能我們會變成黨員,但是團員還是叫做團員),而“系別”可能就會有所調整,所以我們可以構建這樣4張表:“學生(學號,姓名)”、“系別(系別$ID$,系別名稱)”、“系統屬性程式碼(屬性$ID$號,屬性分類,屬性取值)”、“屬性表(學生$ID$ ,$ID$屬性$ID$)”,其中表示系的時候在《系統屬性程式碼表》中體現:
《系統屬性程式碼表》
| 屬性$ID$號 | 屬性分類 | 屬性取值 |
| ---------- | -------- | -------- |
| 001 | 系 | 001 |
| 002 | 系 | 004 |
| 003 | 國籍 | 中國 |
《系別表》
| 系別$ID$ | 系別名稱 |
| -------- | -------------- |
| 001 | 食品科學與工程 |
| 004 | 地理資訊科學 |
>
>
>
>
>
> ### 3、資料字典
>
> $Excel$檢視傳送門:[資料字典-教務管理系統部分功能](https://kdocs.cn/l/scw5fPmz7?f=111)
>
> $Excel$下載傳送門:[資料字典-教務管理系統部分功能](https://attachments-cdn.shimo.im/A3d7KVSCARChFNTO.xlsx)。
## 四、資料字典的補充
資料字典不單單是用於解釋資料流圖,還能在資料儲存檔案設計的時候提供援助。當現實世界中的主體有不斷變化的屬性時(屬性的數量和屬性的取值),尤其是變化得非常頻繁的時候,就會引入資料字典輔助資料表設計。
這裡簡單地介紹一下由[$rongwenbin$先生](https://blog.csdn.net/rongwenbin)總結的兩種用於輔助設計資料庫表的資料字典,原文傳送門:[資料字典](https://blog.csdn.net/rongwenbin/article/details/47086415)。為了更好理解我將先生用到的例項換做我們常見的教務管理系統,其主要功能為管理並查詢學生、教師、課程……等實體集的基本資訊。
在構建資料庫管理系統之前,我先將兩種資料字典擺出來:
> (Ⅰ)將主體的屬性編碼(設定每一個屬性$ID$號),並將這些$ID$號放入獨立的資料庫表中作為主鍵,其對應的值就是屬性的取值;(這對應於資料庫表規範化中的模式分解)
>
> (Ⅱ)將結構(模式)相同的資料庫表整合在一起,用統一的編碼規範設定$ID$號並將其作為主鍵,對應的值為屬性的名稱以及屬性的取值;(這對應於資料庫表規範化中的模式合併)
我們來看這樣一個需求:假設我們已經設計出了該教務管理系統的邏輯模型初稿,其中有一個模式為“學生(學號,姓名,系別名稱)”。在這一模式中體現出了“學生”實體和“學生屬於系別”聯絡,雖然一箭雙鵰提高了查詢的效率,但是這裡很明視訊記憶體在一個問題:**系別的名稱如果更改,則學生表中的"系別名稱"屬性的取值都要做出相應的調整**,這系別名稱還好,如果是國籍呢,比如前蘇聯到俄羅斯,這就要涉及到上億份資料。怎樣解決這一問題呢?先生指出我們可以參考(Ⅰ)資料字典,新建一張《系別表》,其中存放"系別$ID$"和"系別名稱",這樣在學生表中直接引入外來鍵"系別$ID$"即可,這是更改系別名稱就只用在《系別表》中更改"系別名稱"而"系別$ID$"不用改,保證了《學生表》的穩定性。上述文字轉換為資料表的動態變換就是:
更改之前的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別名稱 |
| --------- | ---- | ------------ |
| 180502304 | BN2U | 地理資訊系統 |
更改之後的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別$ID$ |
| --------- | ---- | -------- |
| 180502304 | BN2U | 001 |
新建的《系別表》及例項:
| 系別$ID$ | 系別名稱 |
| -------- | ------------ |
| 001 | 地理資訊系統 |
根據上級的命令更改資料,將“地理資訊系統”改為“地理資訊科學”這樣的話就會有:
更改之後的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別$ID$ |
| --------- | ---- | -------- |
| 180502304 | BN2U | 001 |
新建的《系別表》及例項:
| 系別$ID$ | 系別名稱 |
| -------- | ------------ |
| 001 | 地理資訊科學 |
顯然《學生表》沒有任何改動。
這樣很$nice$但是有沒有想過如果一個主體中的屬性不是兩三個,而是幾十個甚至上百個,那麼每一次查詢都涉及到上百個奪標連線操作,這時的查詢效率簡直不敢恭維。於是先生又提出了第二種方案:(Ⅱ)資料字典,將屬性資料表進行合併,但是並不是將所有的資料表進行合併,而是針對模式(結構)一樣的一組表。這樣就能將查詢所涉及到的表大幅度的減少,從而提高了查詢的效率。下面我們來看一個案例,解釋(Ⅰ)的缺點和(Ⅱ)。
我們現在有一個需求:假設我們更新了模式,最後變為“學生(學號,姓名,證件型別,證件號,國籍,民族,系別名稱,政治面貌)”,根據(Ⅰ)的分解,我們可以將模式繼續升級為“學生(學號,姓名,證件型別$ID$,國籍$ID$,民族$ID$,系別$ID$,政治面貌$ID$)”、“證件型別(證件型別$ID$,證件型別,證件號)”、“國籍(國籍$ID$,國籍)”、“民族(民族$ID$,民族名稱)”、“系別(系別$ID$,系別名稱)”、“政治面貌(政治面貌$ID$,政治面貌名稱)”,就這樣一直被分解,如果只是5個左右的表那查詢起來也不是很費勁,但是一個學生顯然不可能只有這樣幾個屬性,所以如果繼續分解下去就會帶來過於沉重的查詢計算量。
既然我們的目的是為了提高查詢效率,那個合併資料表顯然是一個不錯的選擇,但是我們知道一個數據表的模式是定死了的,並且屬性的取值是必須規定在同一個域,所以只有表結構相同、對應屬性的取值範圍相同的表才能夠合併。我們將目光轉移至分解之後的屬性表,發現除了《證件型別》這張表之外都很相似,模式都是“屬性的名稱(ID,屬性的值)”,那我們就可以合併了。回過頭看《證件型別》這張表,不難發現"證件號"可以作為主碼,從而代替"證件型別$ID$",這樣《證件型別》表的模式為“證件型別(證件號,證件型別)”。這時我們整合這些屬性表,得到一個新的表模式“屬性(屬性$ID$號,屬性分類$ID$號,屬性取值)”,構造一個例項:
《系統屬性程式碼表》
| 屬性$ID$號 | 屬性分類 | 屬性取值 |
| ---------- | -------- | ------------------ |
| 001 | 身份證 | xxxxxx20010202xxxx |
| 002 | 身份證 | xxxxxx20000302xxxx |
| 003 | 暫居證 | yyyyyy |
| 004 | 國籍 | 中國 |
| 005 | 國籍 | 薩摩亞 |
| 006 | 國籍 | 美國 |
| 007 | 系別 | 地理資訊科學 |
| 008 | 政治面貌 | 團員 |
| 009 | 政治面貌 | 黨員 |
| …… | …… | …… |
《學生表》
| 學生$ID$ | 學生姓名 |
| --------- | -------- |
| 180502304 | BN2U |
| 180502305 | $\pi$ |
| 180502302 | $e$ |
《屬性表》
| 學生$ID$ | 屬性$ID$ |
| --------- | -------- |
| 180502304 | 001 |
| 180502304 | 004 |
| 180502304 | 007 |
| 180502304 | 008 |
| 180502302 | 002 |
| 180502302 | 004 |
| …… | …… |
這樣在查詢任意一個學生的時候最多也就是3張表的查詢,一張差姓名、另外兩張查詢其他屬性$ID$以及對應的內容,這樣查詢效率是不是就大大提升了呢?但是細心的同學會發現這樣做的後果就是造成了最開始的問題:對資料庫進行更改很麻煩。所以這裡我想做的一點補充就是:這兩種資料字典的思想要相結合,我們可以在需求分析階段調查不易改變的屬性名稱,將這些屬性名稱利用(Ⅱ)資料字典整合成為一張表;相應地將容易改變的屬性名稱利用(Ⅰ)資料字典構造一張新的屬性表。就拿上面這個例子來說,對於“國籍”、“證件型別”、“民族”、“政治面貌”對於我們來說在相當長的一段時期內屬性的名稱是不會變化的(可能我們會變成黨員,但是團員還是叫做團員),而“系別”可能就會有所調整,所以我們可以構建這樣4張表:“學生(學號,姓名)”、“系別(系別$ID$,系別名稱)”、“系統屬性程式碼(屬性$ID$號,屬性分類,屬性取值)”、“屬性表(學生$ID$ ,$ID$屬性$ID$)”,其中表示系的時候在《系統屬性程式碼表》中體現:
《系統屬性程式碼表》
| 屬性$ID$號 | 屬性分類 | 屬性取值 |
| ---------- | -------- | -------- |
| 001 | 系 | 001 |
| 002 | 系 | 004 |
| 003 | 國籍 | 中國 |
《系別表》
| 系別$ID$ | 系別名稱 |
| -------- | -------------- |
| 001 | 食品科學與工程 |
| 004 | 地理資訊科學 |
資料流圖 && 資料字典就到這了,不知道你們有沒有弄懂?(反正我是明白了【狗頭保命】)
>
>
> > ### 2、資料字典(Data Dictionary) > > > 大家試想一下,我們現在已經擁有了一張"資料流圖(DFD)",那麼光有這麼一張圖可以嗎?比如說,你知道$Entity\_001$具體是啥嘛?不知道叭,這時肯定有吐槽“那就把名稱加上唄”,但$Entity\_001$僅僅只是一個名稱嘛,既然是一個實體那是不是就還有屬性呢?這時將這些屬性一一標記上去這張圖會是什麼樣,顯然就非常的凌亂。所以我們就用一個代號來表示一個物件(包括實體、資料流、加工、儲存),在圖之外引入新概念——資料字典(DD)來對這些代號進行解釋。下面就來簡單看一下資料字典是什麼。 > > > > 不用多說肯定是一個描述"資料(Data)"的東西,那怎麼描述的呢?答案就是用"==字典(Dictionary)=="。字典是啥,只知道《辭海》、《康熙》或者《牛津》?umm……我可以說這差不多,字典就是一種對映關係,我們小時候“作弊”用的“暗號”就是一個不成文的字典,譬如$X$同學規定撳動一次就選$A$、撳動兩次就選$B$……,那麼我們就可以得到如下的字典: > > > > | 明文(也可以是id號) | 密文(也可以是對對應id號的解釋) | > > | -------------------- | -------------------------------- | > > | 1 | $A$ | > > | 2 | $B$ | > > | …… | …… | > > | 26 | $Z$ | > > > > 所以字典的本質也就是一張表,又由於是對資料流圖的描述,那很自然地就包括如下幾個方面:(Ⅰ)資料項;(Ⅱ)資料結構;(Ⅲ)資料流;(Ⅳ)資料儲存;(Ⅴ)處理過程;這裡先各出一個例項(用上面的資料流圖為例,構造一個合理的、簡化的資料字典): > > > > **(ⅰ)資料項:** > > > > | $ID$ | $Name$ | 含義 | > > | :-----------: | :----------: | :----------------------------: | > > | $studentID$ | 學生的$ID$號 | 對學生實體集有唯一標識的識別符號 | > > | $studentName$ | 學生的姓名 | 每一個學生實體在社會中的代號 | > > > > **(ⅱ)資料結構:** > > > > | $ID$ | $Name$ | 組成(實體的屬性) | > > | :-----------: | :------: | :----------------: | > > | $Entity\_001$ | 學生實體 | $ID$號、姓名 | > > > > **(ⅲ)資料流:** > > > > | $ID$ | $Name$ | > > | :-------------: | :----------: | > > | $DataFlow\_001$ | 排課資訊 | > > | $DataFlow\_002$ | 學生資訊 | > > | $DataFlow\_003$ | 課程資訊 | > > | $DataFlow\_004$ | 學生選課資訊 | > > > > **(ⅳ)資料儲存:** > > > > | $ID$ | $Name$ | > > | :----------------: | :------------------------: | > > | $DataStorage\_001$ | 學生自然情況(學生資訊表) | > > | $DataStorage\_002$ | 課程資訊表 | > > | $DataStorage\_003$ | 學生的選課表 | > > > > **(ⅴ)處理及加工:** > > > > | $ID$ | $Name$ | 處理 | > > | :----------------: | :------: | :----------------------------: | > > | $DataProcess\_001$ | 學生選課 | 記錄學生的$ID$、被選課程的$ID$ |
## 二、詳細介紹資料流圖和資料字典 > ### 1、資料流圖 > > > #### (Ⅰ)資料流圖的基本圖形和符號 > > > > > 我們先從最簡單的圖形分類入手,這裡給出常用的四種基本圖形及其含義【在圖形中標註編號($ID$)或者名稱($name$),或者兩者都標上,這樣看圖的時候既更直觀還容易查詢$ID$索引】: > > > > > > | 圖形(符號) | 類別名稱 | 含義說明 | > > > | :----------------------------------------------------------: | :----------------------------------------------: | :----------------------------------------------------------- | > > > |
| 資料的加工和處理($Data Process, DP$) | 必須有輸入流和輸出流,缺一不可 | > > > |
| 資料的源點或匯點,也就是外部實體($Entity$) | 資料加工的一端,要麼提供資料,
要麼彙集資料形成新的外部實體 | > > > |
| 資料儲存檔案($DataStorage$) | 資料加工的一端,
可以提供資料或者儲存資料 | > > > |
| 資料流($DataFlow$) | 一邊為實體或者資料儲存檔案,
另一邊為資料的加工和處理,
其名稱清晰表達傳遞的主要資料 | > > > > > > 在加工的時候不可避免會出現多種資料進出的情況,那麼資料流圖是怎樣表示的呢?在做表之前我們先畫出資料加工和資料流的圖【$(\theta_1,\theta_2) \in \theta=\{+, *, \bigoplus\}$】: > > > > > >
> > #### (Ⅱ)資料流圖設計的原則 > > > > > **(1)、任意流不能重名** 因為流的名字即為他們的$ID$號,常識告訴我們不存在兩個完全一樣的物體,為了區分必須避免重名; > > > > > > **(2)、資料守恆原則** 對於任意一個數據處理來說,其全部的輸出資料流中的資料必定能從其輸入資料流中的資料直接獲得。這一原則也說明了資料流是必須與資料處理有關的,應該也只能依附與資料流。我們可以用能量守恆來理解這一原則,將資料儲存和外部實體比作物體、資料比作能量,資料處理即為物體之間的相互作用,只有在物體進行相互作用的時候才會存在能量的流動(傳遞),所以同理可得==只有在資料處理的推動下,資料才得以傳遞,從而形成資料流==。 > > > > > > > ①、外部實體與外部實體之間不存在資料流; > > > > > > > > ②、外部實體與資料儲存之間不存在資料流; > > > > > > > > ③、資料儲存與資料儲存之間不存在資料流; > > > > > > > > ④、資料流必須經過(其中一端為)資料處理(加工); > > > > > > **(3)、守恆加工原則** (前兩條都是針對加工而言) > > > > > > > ①、對於任意一個加工,至少有一個數據輸入流和一個數據輸出流; > > > > > > > > ②、由**任意流不能重名**可以推出:對於任意一個加工,輸入資料流與輸出資料流必須不同名,即使輸入的資料與輸出的資料結構一模一樣,但是這樣的情況常見於向資料儲存檔案寫入資料的時候:由於**資料守恆原則**,資料流必須經過資料加工,但是這樣的資料加工並不會改變資料流中的資料。所以人們規定:**對流進或者流出資料儲存檔案的資料流不需要標註名字**,因為檔案本身就足以說明資料流。所以,如果一種資料流需要被多次引用時可以建立一個臨時的資料儲存(對應的就是記憶體資料庫),這樣就沒有必要為同一種資料流進行標號。另外,當輸入輸出流一模一樣的情況發生在非資料儲存檔案操作時,就要考慮其加工或者資料來源存在的合理性和必要性了,因為這相當於沒有對資料進行處理,屬於冗餘操作; > > > > > > > > ③、資料來源包含資料儲存檔案、最終新形成的外部實體和資料儲存檔案必須與資料來源同級,也就是說**資料流的終點一定是在外部並且指向外部實體或者資料儲存檔案**。因為只要有外部資料流參與,那麼有入必有出,這個出就是指向新形成外部實體或資料檔案的輸出資料流;比如下圖中的資料檔案:$Student\_Course$。 > > > > > > > >
> > > >
> > > > > (ⅰ)$DF-A$系列與$DF-B$系列相互獨立;
> > > > >
> > > > > (ⅱ)$DF-A1$系列之間($DF-A1\_1$與$DF-A1\_2$)相互獨立;
> > > > >
> > > > > (ⅲ)彼此的後繼之間($DF-A1\_1$與$DF-A1\_2-A2$系列、$DF-A1\_2$與$DF-A1\_1-A2$系列、$DF-A1\_1-A2$系列與$DF-A1\_2-A2$系列)相互獨立。
> > > >
> > > > ⑦、很容易被忽視的一點:資料儲存不可能憑空出現在資料庫管理系統中,必須通過作業系統從磁碟中讀取相應的檔案載入記憶體,當對資料儲存檔案操作完成之後,再寫入磁碟。但是正是因為所有的資料流圖都有這一類資料流,所以常常被作為枝節被省略,這導致在研究細節的時候發現很多資料流圖都沒有遵守守恆加工原則;所以完整的資料流圖應該是這樣(用虛線表示省略的):
> > > >
> > > >
> > > >
> > > > 這個時候我們就可以理解為:從作業系統中讀取的檔案與外部實體給予的資訊進行組合(資料加工),最後形成了新的檔案並寫入磁碟中。
> > >
> > > **(4)、父圖與子圖應該統一輸入輸出流:** 父圖可以看做是一個整體,也就是一個黑盒子,其中包含了很多個子圖,那麼子圖的輸入輸出流當然就源自黑盒子(父圖);比如學生選課後出了成績:
> > >
> > >
> > >
> > > 一共分了兩個區域(上下),上部分為整體的區域性資料流圖,資料處理由一個父圖構成;下部分即為父圖中更加細節的子圖資料流圖。這個時候我們可以看到父圖由外部資料流($CourseSchedulingInfo$、$ScoreInfo$、$CourseInfo$、$StudentInfo$)的參與產生了一個新的資料儲存($Student\_Course$),必須將其提出放在父圖的外部,如果不這樣做的話就會違反**守恆加工原則**。由父圖子圖流一致原則我們可以得出另一重要的原則:**加工細節隱蔽原則**,就是說沒有必要一味地對父圖進行拆分,可以適當地只保留父圖不去關心子圖的內在聯絡(類比整體法)。
> > >
> > > **(5)、簡化加工之間的關係** 加工間的資料流越少,各個加工就越相對獨立、耦合度就越低,如果資料流很多的話,雖然可以實現較為複雜的功能但是也增加了運維成本,甚至可能造成動一發而牽全身的混亂局面。這就要求我們做到**==先抓住主要矛盾,暫時忽略枝節==**。
> > >
> > > **(6)、均勻分解父圖** 儘量不要出現對資料處理分解的兩極化,比如一個分了七八層而另一個只分了兩三層,這樣會造成輕重不一的局面存在考慮不周的潛在隱患。
> > >
> > > **(7)、是資料流而不是控制流** 資料流是控制流上的操作表示,只有在控制流上進行的資料流分析才有價值。也就是說資料流圖只需要表達出資料的結構、來源、流向、加工,並不關心資料流在融入控制層之後進行的邏輯處理與程式跳轉的結果(程式元素邏輯執行的先後順序)。
> >
> > 在這些原則中==最重要==的當屬:**保持父圖與子圖平衡**,**保持資料平衡**,**加工細節隱蔽**。
> >
> ### 2、資料字典 > > > #### (Ⅰ)資料字典的用途與組成 > > > > 根據之前的分析,我們可以得出:資料字典的就是對資料流圖中出現的所有被命名的圖形元素在資料字典中作為一個詞條加以定義,使每個圖形元素的名稱都有一個確切的解釋。 > > > > 最初只給了二級表頭,現在給出更加精細的三級表頭,畫一個[思維導圖](https://www.jianguoyun.com/p/DZMHKMwQ3sG6CBjFkpsD)會更加清晰。 > > > >
> >
> > 具體例項請看傳送門:[資料字典舉例](https://wenku.baidu.com/view/63a49142cf84b9d528ea7ac0.html?fr=search)。(想要$PDF$版的可以私聊哦)
> > > > #### (Ⅱ)資料結構的描述 > > > > > 在資料字典中最特殊的當屬資料結構了,因為資料結構是描述其他字典條目的基礎,所以準確來說,資料字典中應該是包含下面4種條目: > > > > > > > ①、資料項條目:資料型別、取值範圍……等; > > > > > > > > ②、資料流條目:定義、給出組成資料流的資料項(利用資料結構描述); > > > > > > > > ③、檔案條目:定義、給出組成檔案的資料項(利用資料結構描述); > > > > > > > > ④、加工條目:加工條目必須具備**原子性**,給出說明(激發條件、邏輯、處理順序……等); > > > > > > 我們言歸正傳,資料結構的描述通常採用如下表中的符號: > > > > > > | 符號 | 含義 | 說明 | > > > | :----------------------: | :---------------------------------: | ---------------------------------------- | > > > | = | 被定義為(賦值) | $x=a$,$x$由且僅由$a$構成 | > > > | + | 與 | $x=a+b$,$x$由$a$和$b$構成 | > > > | […\|…]或者[…, …] | 或 | $x=[a,b]$,$x$由$a$或者$b$構成 | > > > | $m${…}$n$、{…}$_{N}^{M}$ | 重複($m,n$的預設值為0和$+\infty$) | $x=3\{a\}6、\{a\}_3^6$,$a$可以重複3~5次 | > > > | (…) | 可選(非必須項) | $x=(a)$,$a$可以出現在$x$中 | > > > | "…" | 基本資料元素 | $x="a"$,$x$取值為$a$的資料元素 | > > > | ·· | 連線 | $x=a··f$,$x$由$a\sim f$組成 | > > > > > > 比如我們要表示學生這個實體集(或者學生表)時,就可以這樣: > > > > > > $StudentEntity=studentID+studentName+studentIDCard+studentSex+\{studentInterest\}+(studentInfo)$, > > > > > > 再比如我們新建一個可以實現查詢的任務,包括查詢學生資訊、課程資訊以及學生選課資訊,這是當資料庫管理員(或者教務系統管理員)向教務管理系統發出查詢請求(資料流)的時候就可以這樣表示: > > > > > > $selectRequestInfo=[selectStudentInfo\ |\ selectCourseInfo\ |\ selectStudent\_CourseInfo]+\{IllegalRequest\}$,
## 三、資料流圖 & 資料字典 綜合應用問題 > ### 1、需求 > > > 某教務管理系統的主要功能為:師生教學管理和資訊查詢。對於新招的師生,系統按照既定的法則自動生成師生的編號,並和他們的基本資訊一起分別寫入學生檔案和教師檔案,同樣適用於新開設的課程。 > > > > #### (Ⅰ)師生教學管理功能:新增師生和課程、登出師生和課程、學生選課出成績 > > > > > **(1)、新增師生和課程** 新招師生和課程的時候需要分別編制《入校學生單》、《新招教師單》以及《新開設課程單》以便直接對新增物件進行管理與研究,然後將資訊分別寫入《學生表》、《教師表》和《課程表》。 > > > > > > > ①、《入校學生單》:$ID$號、姓名、身份證、出生年月日、性別、入校時間; > > > > > > > > ②、《新招教師單》:$ID$號、姓名、身份證、出生年月日、性別、新招時間; > > > > > > > > ③、《新開設課程單》:$ID$號、課程名、課時、上課資訊(日期時間教室列表)、新開設時間; > > > > > > **(2)、登出師生和課程** 學生畢業、老師退休以及課程結課的時候需要分別編制《學生畢業單》、《老師退休單》、《課程結課單》,然後分別修改《學生表》、《教師表》、《課程表》中的登出時間以及是否登出(預設值為$NO$,現改為$YES$)。 > > > > > > > ①、《學生畢業單》:$ID$號、畢業時間、是否畢業(只能填寫$YES$,用於覆蓋《學生表》); > > > > > > > > ②、《老師退休單》:$ID$號、退休時間、是否退休(只能填寫$YES$,用於覆蓋《教師表》); > > > > > > > > ③、《課程結課單》:$ID$號、結課時間、是否結課(只能填寫$YES$,用於覆蓋《課程表》); > > > > > > **(3)、學生選課出成績** 學生選課時需要編制《學生選課申請單》和《學生最新選課單》。 > > > > > > > ①、《學生選課申請提交單》:學生的$ID$號、課程的$ID$號、選課權重 > > > > > > > > ②、《學生最新選課單》:學生的$ID$號、課程的$ID$號、選課權重; > > > > > > 假設選課權重在同一學號記錄中不能重複,且為[1, 6]之間的整數,當學生提交《學生選課申請單》時系統給出選項,學生自行選擇,即限定每個學生的選課門數最多為6門。此外系統應該有三層過濾網(這三層過濾可以放置在一個加工中——加工細節隱蔽原則): > > > > > > > (ⅰ)系統首先通過聚合運算檢查在《學生最新選課單》中該學生的選課門數是否為6,若不是則允許將該學生《學生選課申請提交單》的選課資訊新增至《學生最新選課單》;若是則拒絕新增。 > > > > > > > > (ⅱ)如果選課門數小於6則進行衝突檢查,查詢《學生選課表》中該學號對應的選課課程號集合,再在《課程表》中查詢"上課資訊"這一欄位,然後與該學生新選課程的上課資訊進行比對。若這時沒有衝突才能將《學生選課申請提交單》的選課資訊寫入《學生最新選課單》;若有衝突則拒絕寫入。 > > > > > > > > (ⅲ)排處第一層衝突之後,系統應該檢查該學生所有新選課程的"上課資訊"進行比對,並按照選課權重選取權重最大的課程,其他與之相沖突的選課記錄將被刪去。 > > > > > > 經過系統的三層排除衝突之後的《學生最新選課單》方能寫入《學生選課表》。之後學生考試填寫試卷,教師批閱提供分數資訊,將分數資訊與選課資訊合併存入《學生選課表》。 > >
> > #### (Ⅱ)資訊查詢功能:查詢教師學生和課程的基本資訊、學生成績 > > > > > **(1)、查詢教師的基本資訊** 可以查詢到教師的基本資訊; > > > > > > **(2)、查詢學生的基本資訊** 可以查詢到學生的基本資訊; > > > > > > **(3)、查詢課程的基本資訊** 可以查詢到課程的基本資訊; > > > > > > **(4)、查詢學生成績的基本資訊** 可以查詢到學生選課的資訊以及學生在此課程中的分數情況; >
>
> ### 2、資料流圖 > > #### (Ⅰ)頂層圖: > >
>
> #### (Ⅱ)第0層圖:
>
>
>
> #### (Ⅲ)加工的分解:
>
> > **(ⅰ)對處理學生選課以及成績資訊的分解:**
> >
> >
>
>
>
>
>
> ### 3、資料字典
>
> $Excel$檢視傳送門:[資料字典-教務管理系統部分功能](https://kdocs.cn/l/scw5fPmz7?f=111)
>
> $Excel$下載傳送門:[資料字典-教務管理系統部分功能](https://attachments-cdn.shimo.im/A3d7KVSCARChFNTO.xlsx)。
## 四、資料字典的補充
資料字典不單單是用於解釋資料流圖,還能在資料儲存檔案設計的時候提供援助。當現實世界中的主體有不斷變化的屬性時(屬性的數量和屬性的取值),尤其是變化得非常頻繁的時候,就會引入資料字典輔助資料表設計。
這裡簡單地介紹一下由[$rongwenbin$先生](https://blog.csdn.net/rongwenbin)總結的兩種用於輔助設計資料庫表的資料字典,原文傳送門:[資料字典](https://blog.csdn.net/rongwenbin/article/details/47086415)。為了更好理解我將先生用到的例項換做我們常見的教務管理系統,其主要功能為管理並查詢學生、教師、課程……等實體集的基本資訊。
在構建資料庫管理系統之前,我先將兩種資料字典擺出來:
> (Ⅰ)將主體的屬性編碼(設定每一個屬性$ID$號),並將這些$ID$號放入獨立的資料庫表中作為主鍵,其對應的值就是屬性的取值;(這對應於資料庫表規範化中的模式分解)
>
> (Ⅱ)將結構(模式)相同的資料庫表整合在一起,用統一的編碼規範設定$ID$號並將其作為主鍵,對應的值為屬性的名稱以及屬性的取值;(這對應於資料庫表規範化中的模式合併)
我們來看這樣一個需求:假設我們已經設計出了該教務管理系統的邏輯模型初稿,其中有一個模式為“學生(學號,姓名,系別名稱)”。在這一模式中體現出了“學生”實體和“學生屬於系別”聯絡,雖然一箭雙鵰提高了查詢的效率,但是這裡很明視訊記憶體在一個問題:**系別的名稱如果更改,則學生表中的"系別名稱"屬性的取值都要做出相應的調整**,這系別名稱還好,如果是國籍呢,比如前蘇聯到俄羅斯,這就要涉及到上億份資料。怎樣解決這一問題呢?先生指出我們可以參考(Ⅰ)資料字典,新建一張《系別表》,其中存放"系別$ID$"和"系別名稱",這樣在學生表中直接引入外來鍵"系別$ID$"即可,這是更改系別名稱就只用在《系別表》中更改"系別名稱"而"系別$ID$"不用改,保證了《學生表》的穩定性。上述文字轉換為資料表的動態變換就是:
更改之前的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別名稱 |
| --------- | ---- | ------------ |
| 180502304 | BN2U | 地理資訊系統 |
更改之後的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別$ID$ |
| --------- | ---- | -------- |
| 180502304 | BN2U | 001 |
新建的《系別表》及例項:
| 系別$ID$ | 系別名稱 |
| -------- | ------------ |
| 001 | 地理資訊系統 |
根據上級的命令更改資料,將“地理資訊系統”改為“地理資訊科學”這樣的話就會有:
更改之後的資料庫表《學生表》及例項:
| 學號 | 姓名 | 系別$ID$ |
| --------- | ---- | -------- |
| 180502304 | BN2U | 001 |
新建的《系別表》及例項:
| 系別$ID$ | 系別名稱 |
| -------- | ------------ |
| 001 | 地理資訊科學 |
顯然《學生表》沒有任何改動。
這樣很$nice$但是有沒有想過如果一個主體中的屬性不是兩三個,而是幾十個甚至上百個,那麼每一次查詢都涉及到上百個奪標連線操作,這時的查詢效率簡直不敢恭維。於是先生又提出了第二種方案:(Ⅱ)資料字典,將屬性資料表進行合併,但是並不是將所有的資料表進行合併,而是針對模式(結構)一樣的一組表。這樣就能將查詢所涉及到的表大幅度的減少,從而提高了查詢的效率。下面我們來看一個案例,解釋(Ⅰ)的缺點和(Ⅱ)。
我們現在有一個需求:假設我們更新了模式,最後變為“學生(學號,姓名,證件型別,證件號,國籍,民族,系別名稱,政治面貌)”,根據(Ⅰ)的分解,我們可以將模式繼續升級為“學生(學號,姓名,證件型別$ID$,國籍$ID$,民族$ID$,系別$ID$,政治面貌$ID$)”、“證件型別(證件型別$ID$,證件型別,證件號)”、“國籍(國籍$ID$,國籍)”、“民族(民族$ID$,民族名稱)”、“系別(系別$ID$,系別名稱)”、“政治面貌(政治面貌$ID$,政治面貌名稱)”,就這樣一直被分解,如果只是5個左右的表那查詢起來也不是很費勁,但是一個學生顯然不可能只有這樣幾個屬性,所以如果繼續分解下去就會帶來過於沉重的查詢計算量。
既然我們的目的是為了提高查詢效率,那個合併資料表顯然是一個不錯的選擇,但是我們知道一個數據表的模式是定死了的,並且屬性的取值是必須規定在同一個域,所以只有表結構相同、對應屬性的取值範圍相同的表才能夠合併。我們將目光轉移至分解之後的屬性表,發現除了《證件型別》這張表之外都很相似,模式都是“屬性的名稱(ID,屬性的值)”,那我們就可以合併了。回過頭看《證件型別》這張表,不難發現"證件號"可以作為主碼,從而代替"證件型別$ID$",這樣《證件型別》表的模式為“證件型別(證件號,證件型別)”。這時我們整合這些屬性表,得到一個新的表模式“屬性(屬性$ID$號,屬性分類$ID$號,屬性取值)”,構造一個例項:
《系統屬性程式碼表》
| 屬性$ID$號 | 屬性分類 | 屬性取值 |
| ---------- | -------- | ------------------ |
| 001 | 身份證 | xxxxxx20010202xxxx |
| 002 | 身份證 | xxxxxx20000302xxxx |
| 003 | 暫居證 | yyyyyy |
| 004 | 國籍 | 中國 |
| 005 | 國籍 | 薩摩亞 |
| 006 | 國籍 | 美國 |
| 007 | 系別 | 地理資訊科學 |
| 008 | 政治面貌 | 團員 |
| 009 | 政治面貌 | 黨員 |
| …… | …… | …… |
《學生表》
| 學生$ID$ | 學生姓名 |
| --------- | -------- |
| 180502304 | BN2U |
| 180502305 | $\pi$ |
| 180502302 | $e$ |
《屬性表》
| 學生$ID$ | 屬性$ID$ |
| --------- | -------- |
| 180502304 | 001 |
| 180502304 | 004 |
| 180502304 | 007 |
| 180502304 | 008 |
| 180502302 | 002 |
| 180502302 | 004 |
| …… | …… |
這樣在查詢任意一個學生的時候最多也就是3張表的查詢,一張差姓名、另外兩張查詢其他屬性$ID$以及對應的內容,這樣查詢效率是不是就大大提升了呢?但是細心的同學會發現這樣做的後果就是造成了最開始的問題:對資料庫進行更改很麻煩。所以這裡我想做的一點補充就是:這兩種資料字典的思想要相結合,我們可以在需求分析階段調查不易改變的屬性名稱,將這些屬性名稱利用(Ⅱ)資料字典整合成為一張表;相應地將容易改變的屬性名稱利用(Ⅰ)資料字典構造一張新的屬性表。就拿上面這個例子來說,對於“國籍”、“證件型別”、“民族”、“政治面貌”對於我們來說在相當長的一段時期內屬性的名稱是不會變化的(可能我們會變成黨員,但是團員還是叫做團員),而“系別”可能就會有所調整,所以我們可以構建這樣4張表:“學生(學號,姓名)”、“系別(系別$ID$,系別名稱)”、“系統屬性程式碼(屬性$ID$號,屬性分類,屬性取值)”、“屬性表(學生$ID$ ,$ID$屬性$ID$)”,其中表示系的時候在《系統屬性程式碼表》中體現:
《系統屬性程式碼表》
| 屬性$ID$號 | 屬性分類 | 屬性取值 |
| ---------- | -------- | -------- |
| 001 | 系 | 001 |
| 002 | 系 | 004 |
| 003 | 國籍 | 中國 |
《系別表》
| 系別$ID$ | 系別名稱 |
| -------- | -------------- |
| 001 | 食品科學與工程 |
| 004 | 地理資訊科學 |
資料流圖 && 資料字典就到這了,不知道你們有沒有弄懂?(反正我是明白了【狗頭保命】)