
【大廠面試01期】高併發場景下,如何保證快取與資料庫一致性?
阿新 • • 發佈:2020-06-02
> PS:本文已收錄到1.1K Star數開源學習指南——《大廠面試指北》,如果想要了解更多大廠面試相關的內容及獲取《大廠面試指北》離線PDF版,請掃描下方二維碼碼關注公眾號“大廠面試”,謝謝大家了!專案地址:https://github.com/NotFound9/interviewGuide
**《大廠面試指北》專案截圖:**

**獲取《大廠面試指北》離線PDF版,請掃描下方二維碼關注公眾號“大廠面試”**

### 面試題:高併發場景下,如何保證快取與資料庫一致性?
### 問題分析
我們日常開發中,對於快取用的最多的場景就像下圖一樣,可能僅僅是對資料進行快取,減輕資料庫壓力,縮短介面響應時間。
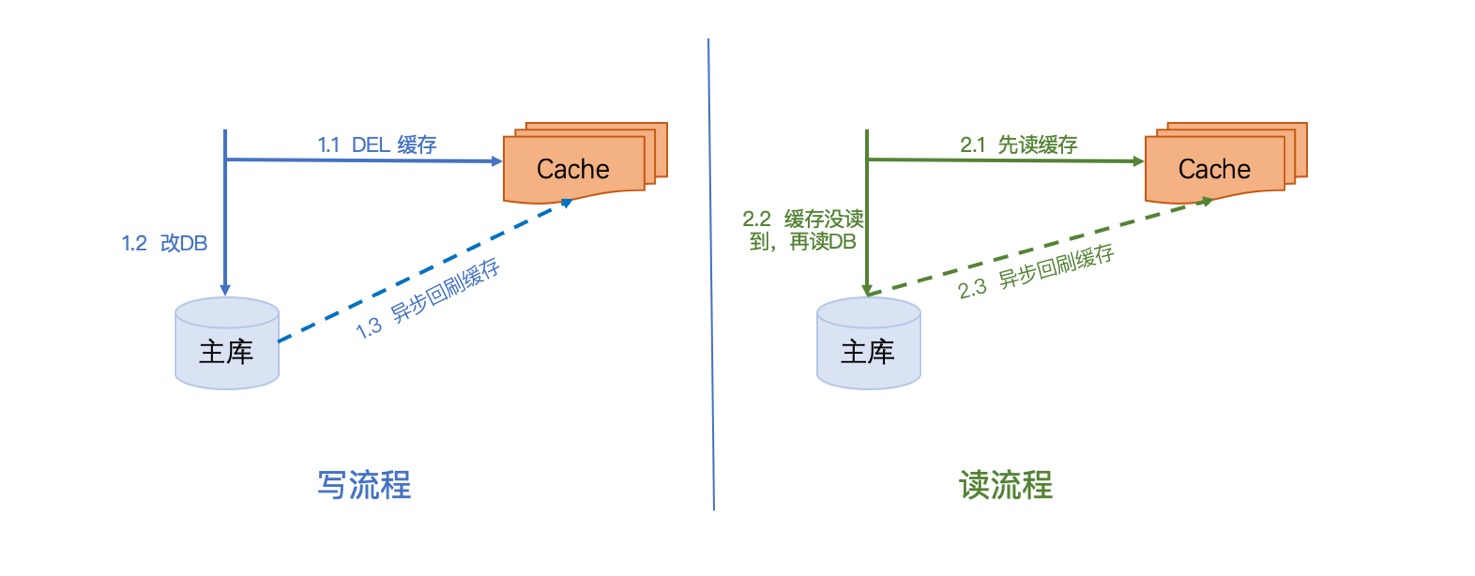
這種方案在不需要考慮高併發得去寫快取,高併發得讀寫快取時,是不會有問題,但是如果是在高併發場景下,要保證快取和資料庫的一致性,至少需要解決以下問題:
#### 高併發寫時的資料不一致問題
高併發讀寫時,請求執行各步驟的順序是不可控的。假設此時有一個請求A,B都在在執行寫流程,請求A是需要將某個資料改成1,請求B是需要將某個資料改為2,執行操作如下時就會導致資料不一致的問題:
1.請求A執行操作1.1刪除快取。
2.請求A執行操作1.2更新資料庫,將值改為1。
3.請求B執行操作1.1刪除快取。
4.請求B執行操作1.2更新資料庫,將值改為2
5.假設說請求B所在伺服器網路延遲比較低,請求B先更新快取,此時快取中的key對應的value是2。
6.請求A更新快取,將快取中B更新的資料進行覆蓋,將key對應的值改為1。
此時資料庫中是B修改後的資料,值為2,而快取中的資料是1,這樣在快取過期錢,使用者讀到的都是髒資料,與資料庫不一致。
#### 高併發讀寫時的資料不一致的問題
高併發讀寫時,請求執行各步驟的順序是不可控的。假設此時有一個請求A在執行寫流程,將原值由1改成2,請求B執行讀流程,執行操作如下時就會導致資料不一致的問題:
1.寫請求A執行1.1操作刪除快取key,value是原值1。
2.讀請求B執行2.1操作發現快取中沒有資料,就去執行2.2操作讀資料庫,讀到舊資料,值為1。
3.寫請求A執行1.2操作更新資料庫,將資料由1改為2。
4.寫請求A執行1.3操作更新快取,此時快取中的資料key對應的value是2。
5.讀請求B執行2.3操作更新快取,將之前讀到的舊資料1設定到快取中,此時快取中的資料key對應的value是1。
所以如果說讀請求B所在伺服器網路延遲比較高,去執行2.3操作比寫請求A晚,就會導致寫請求A更新完快取後,讀請求B使用之前讀到的舊資料去更新快取,此時快取中資料就與資料庫中的不一致。
### 解決方案
保證資料一致性,網上有很多種方案,例如:
1.先刪除快取,再更新資料庫。
2.先更新資料庫,再刪除快取。
3.先刪除快取,再更新資料庫,然後非同步延遲一段時間再去刪一次快取。
但是這些方案都是存在各種各樣的問題,這裡篇幅有限,只給出目前相對正確的三套方案,目前的這些方案也有自己的侷限性。
### 方案1.寫請求序列化
#### 寫請求
1.寫請求更新之前先獲取分散式鎖,獲得之後才能去資料庫更新這個資料,獲取不到就進行等待,超時後就返回更新失敗。
2.更新完之後去重新整理快取,如果重新整理失敗,放到記憶體佇列中進行重試(重試時取資料庫最新資料更新快取)。
#### 讀請求
讀請求發現快取中沒有資料時,直接去讀取資料庫,讀完更新快取。
#### 總結
這種技術方案通過對寫請求的實現序列化來保證資料一致性,但是會導致吞吐量變低。比較適合銀行相關的業務,因為對於銀行專案來說,保證資料一致性比可用性更加重要,就像是去存款機存錢,取錢時,為了保證賬戶安全,都是會讓使用者執行操作後,等待一段時間才能獲得反饋,這段時間其實取款機是不可用的。
### 方案2.先更新資料庫,非同步刪除快取,刪除失敗後重試
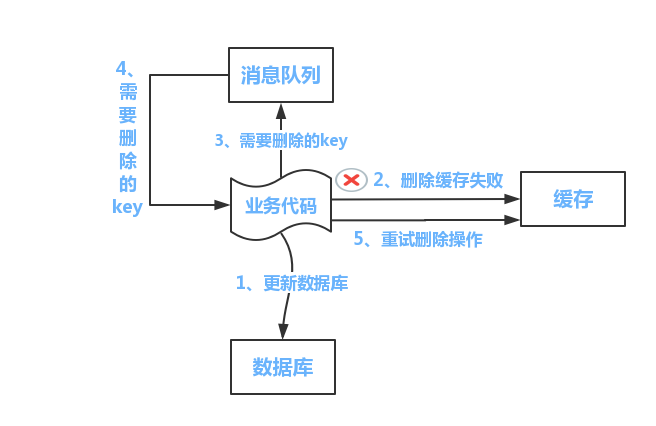
1.先更新資料庫
2.非同步刪除快取(如果資料庫是讀寫分離的,那麼刪除快取時需要延遲刪除,否則可能會在刪除快取時,從庫還沒有收到更新後的資料,其他讀請求就去從庫讀到舊資料然後設定到快取中。)
3.刪除快取失敗時,將刪除的key放到記憶體佇列或者是訊息佇列中進行非同步重試
#### 發散思考
> 在更新完資料庫後,我們為什麼不直接更新,而是採用刪除快取呢?
這是因為直接更新快取的話,在高併發場景下,有多個更新請求時,難以保證後更新資料庫的請求會後更新快取,也就是上面的高併發寫問題。如果採用刪除快取,可以讓下次讀時讀取資料庫,更新快取,保證一致性。
### 方案3.業務專案更新資料庫,其他專案訂閱binlog更新
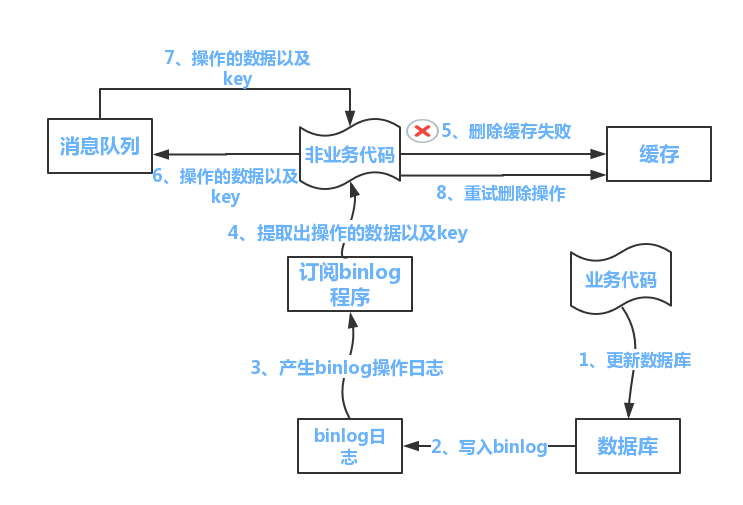
1.業務專案直接更新資料庫。
2.cannal專案會讀取資料庫的binlog,然後解析後發訊息到kafka。
3.然後快取更新專案訂閱topic,從kafka接收到更新資料庫操作的訊息後,更新快取,更新快取失敗時,新建非同步執行緒去重試或者將操作發到訊息佇列,後續再進行處理。
#### 總結:
但是這種方案在更新資料庫後,快取中還是舊值,必須等快取更新專案消費訊息後,更新快取,快取中才是最新值。所以更新操作完成與更新生效之間會有一定的延遲。
### 最後
大家有了解其他的技術方案,歡迎進群一起討論!
> 評論裡面有朋友問延時雙刪策略是什麼?
這裡解釋一下:延時雙刪策略就是先刪除快取,再更新資料庫,再非同步過一小段時間後刪除快取(時間取決於MySQL主從同步的時間)。
是因為MySQL如果是讀寫分離時(寫請求寫主庫,讀請求讀從庫),我們更新主庫後,需要一段時間,從庫才會收到更新。
如果是寫請求更新主庫後,第二次立即刪除快取,MySQL從庫還沒有收到更新,還是舊資料,那麼讀請求直接從庫讀到舊資料,設定到快取的資料就是舊資料,就會資料不一致,所以這也是延時雙刪策略提出的初衷。

參考連結:
https://www.cnblogs.com/-wenli/p/11474164.html
https://www.cnblogs.com/rjzheng/p/9041