
四、歸併排序 && 快速排序
阿新 • • 發佈:2020-06-05
# 一、歸併排序 Merge Sort
## 1.1、實現原理
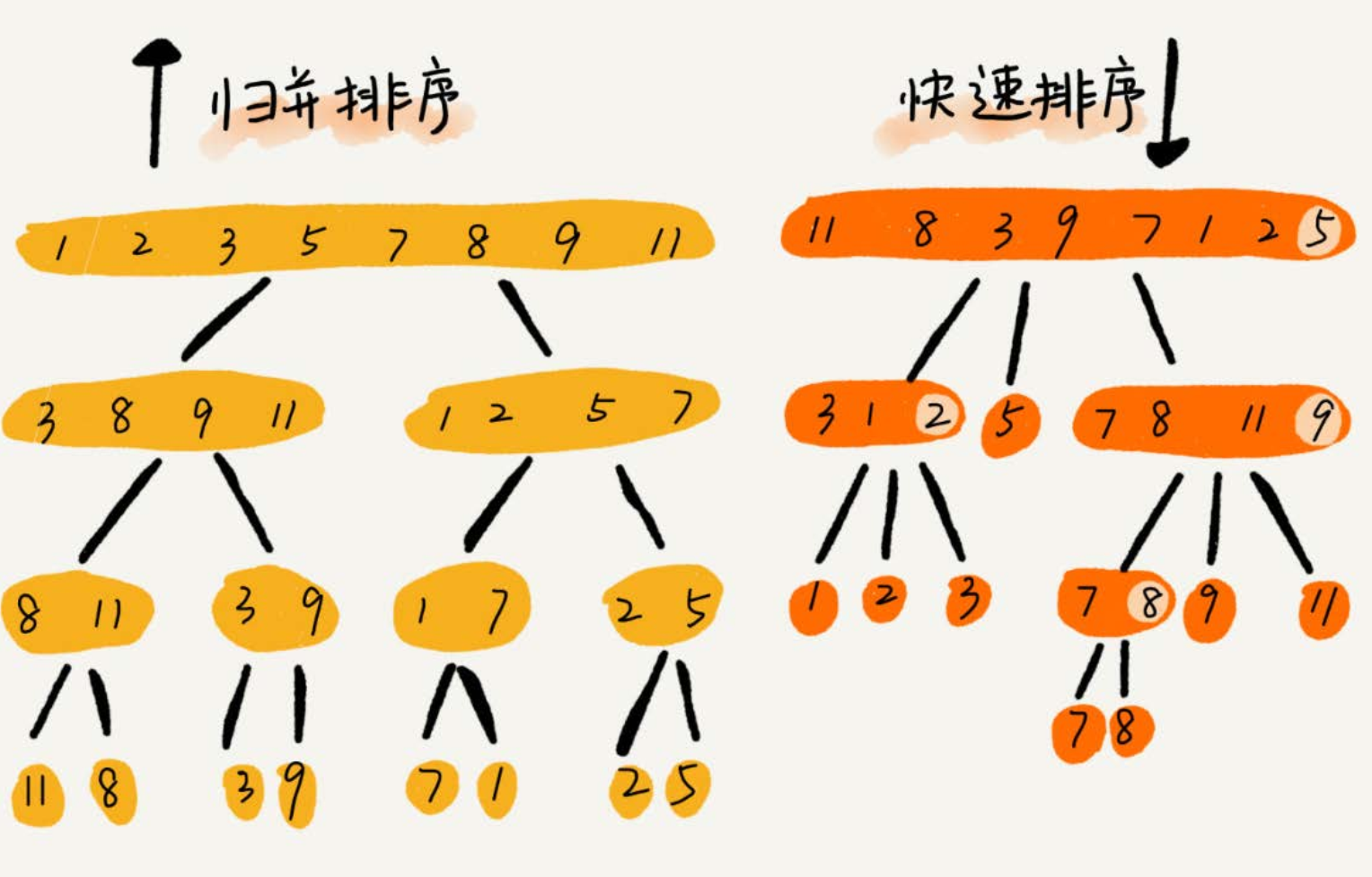
- 如果要排序一個數組,我們先把陣列從中間分成前後兩部分,然後對前後兩部分分別排序,再將排好序的兩部分合並在一起,這樣整個陣列就都有序了。
- 歸併排序使用的就是分治思想。分治,顧名思義,就是**分而治之**,將一個大問題分解成小的子問題來解決。小的子問題解決了,大問題也就解決了。
- 分治思想跟遞迴思想很像。分治演算法一般都是用遞迴來實現的。 分治是一種解決問題的處理思想,遞迴是一種程式設計技巧,這兩者並不衝突。
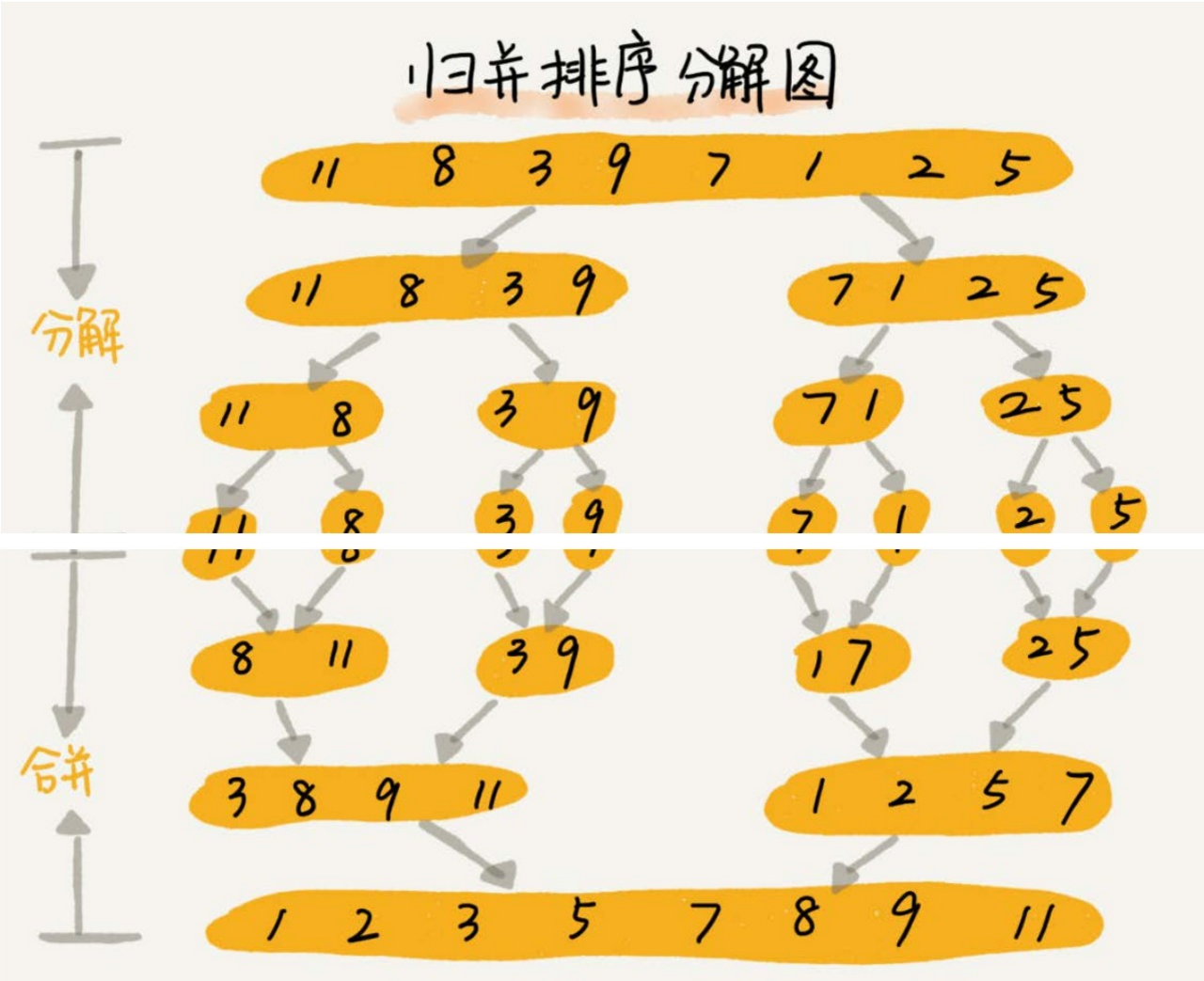 - 寫遞迴程式碼的技巧就是,分析得出遞推公式,然後找到終止條件,最後將遞推公式翻譯成遞迴程式碼。所以,要想寫出歸併排序的程式碼,我們先寫出歸併排序的遞推公式。
- 遞推公式:erge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
- 終止條件:p >= r 不用再繼續分解
- merge_sort(p…r)表示,給下標從 p 到 r 之間的陣列排序。
- 我們將這個排序問題轉化為了兩個子問題, merge_sort(p…q) 和 merge_sort(q+1…r),其中下標 q 等於 p 和 r 的中間位置,也就是 (p+r)/2。
- 當下標從 p 到 q 和從 q+1 到 r 這兩個子陣列都排好序之後,我們再將兩個有序的子數組合並在一起,這樣下標從 p 到 r 之間的資料就也排好序了。
- 實現思路如下:
````java
/**
* 歸併排序
* @param arr 排序資料
* @param n 陣列大小
*/
public static void merge_sort(int[] arr, int n) {
merge_sort_c(arr, 0, n - 1);
}
// 遞迴呼叫函式
public static void merge_sort_c(int[] arr, int p, int r) {
// 遞迴終止條件
if (p >= r) {
return;
}
// 取p到r之間的中間位置q
int q = (p + r) / 2;
// 分治遞迴
merge_sort_c(arr, p, q);
merge_sort_c(arr, q + 1, r);
// 將 arr[p...q] 和 arr[q+1...r] 合併為 arr[p...r]
merge(arr[p...r],arr[p...q],arr[q + 1...r]);
}
````
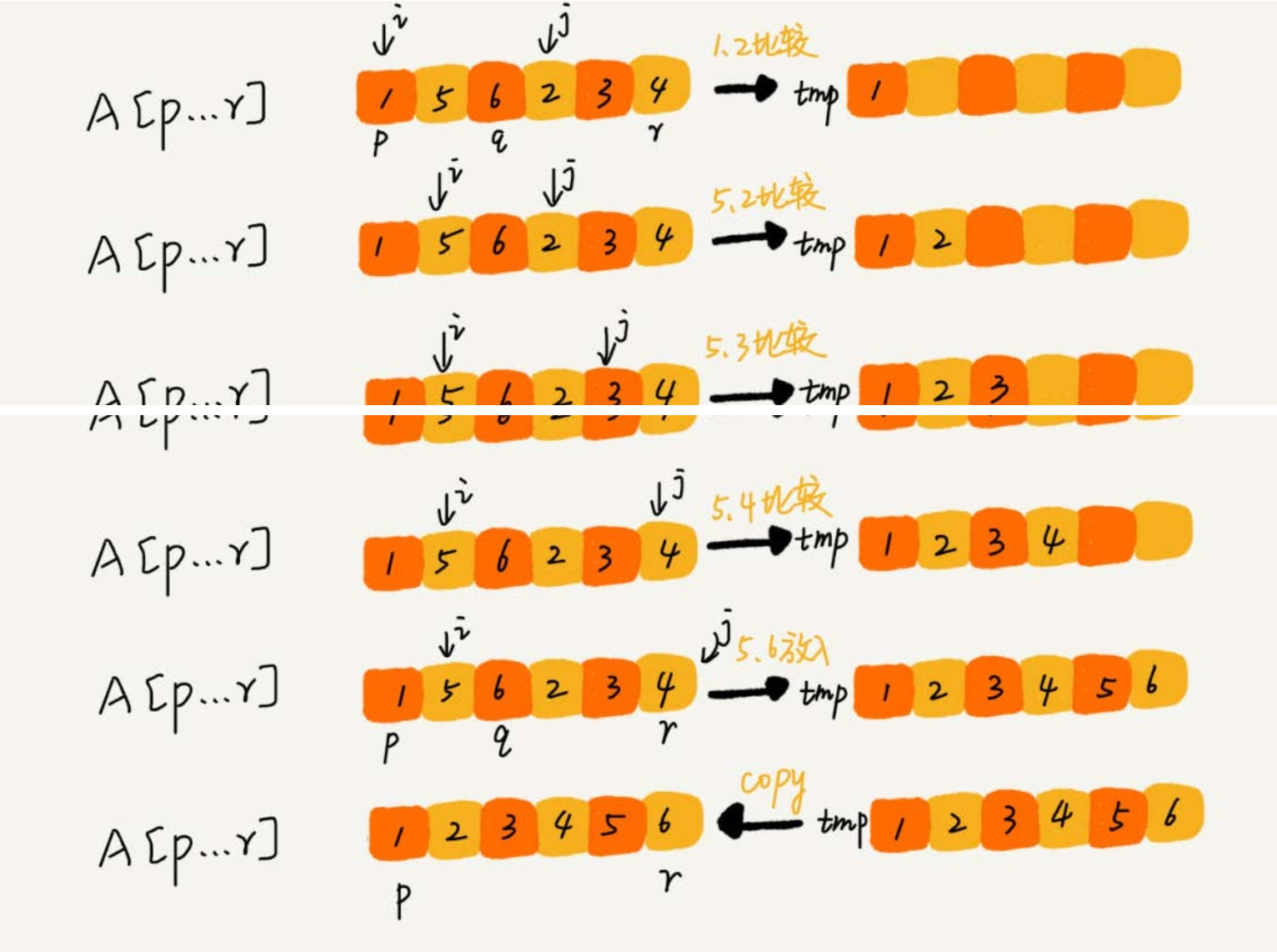
- merge(arr[p...r], arr[p...q], arr[q + 1...r]) 這個函式的作用就是,將已經有序的 arr[p…q] 和 arr[q+1…r] 合併成一個有序的陣列,並且放入 arr[p…r]。
- 如下圖所示,我們申請一個臨時陣列 tmp,大小與 arr[p…r] 相同。
- 我們用兩個遊標 i 和 j,分別指向 arr[p…q] 和 arr[q+1…r] 的第一個元素。
- 比較這兩個元素 arr[i] 和 arr[j],如果 arr[i] <= arr[j],我們就把 arr[i] 放入到臨時陣列 tmp,並且 i 後移一位,否則將 arr[j] 放入到陣列 tmp,j 後移一位。
- 繼續上述比較過程,直到其中一個子陣列中的所有資料都放入臨時陣列中,再把另一個數組中的資料依次加入到臨時陣列的末尾,這個時候,臨時陣列中儲存的就是兩個子數組合並之後的結果了。
- 最後再把臨時陣列 tmp 中的資料拷貝到原陣列 arr[p…r] 中。
- 寫遞迴程式碼的技巧就是,分析得出遞推公式,然後找到終止條件,最後將遞推公式翻譯成遞迴程式碼。所以,要想寫出歸併排序的程式碼,我們先寫出歸併排序的遞推公式。
- 遞推公式:erge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
- 終止條件:p >= r 不用再繼續分解
- merge_sort(p…r)表示,給下標從 p 到 r 之間的陣列排序。
- 我們將這個排序問題轉化為了兩個子問題, merge_sort(p…q) 和 merge_sort(q+1…r),其中下標 q 等於 p 和 r 的中間位置,也就是 (p+r)/2。
- 當下標從 p 到 q 和從 q+1 到 r 這兩個子陣列都排好序之後,我們再將兩個有序的子數組合並在一起,這樣下標從 p 到 r 之間的資料就也排好序了。
- 實現思路如下:
````java
/**
* 歸併排序
* @param arr 排序資料
* @param n 陣列大小
*/
public static void merge_sort(int[] arr, int n) {
merge_sort_c(arr, 0, n - 1);
}
// 遞迴呼叫函式
public static void merge_sort_c(int[] arr, int p, int r) {
// 遞迴終止條件
if (p >= r) {
return;
}
// 取p到r之間的中間位置q
int q = (p + r) / 2;
// 分治遞迴
merge_sort_c(arr, p, q);
merge_sort_c(arr, q + 1, r);
// 將 arr[p...q] 和 arr[q+1...r] 合併為 arr[p...r]
merge(arr[p...r],arr[p...q],arr[q + 1...r]);
}
````
- merge(arr[p...r], arr[p...q], arr[q + 1...r]) 這個函式的作用就是,將已經有序的 arr[p…q] 和 arr[q+1…r] 合併成一個有序的陣列,並且放入 arr[p…r]。
- 如下圖所示,我們申請一個臨時陣列 tmp,大小與 arr[p…r] 相同。
- 我們用兩個遊標 i 和 j,分別指向 arr[p…q] 和 arr[q+1…r] 的第一個元素。
- 比較這兩個元素 arr[i] 和 arr[j],如果 arr[i] <= arr[j],我們就把 arr[i] 放入到臨時陣列 tmp,並且 i 後移一位,否則將 arr[j] 放入到陣列 tmp,j 後移一位。
- 繼續上述比較過程,直到其中一個子陣列中的所有資料都放入臨時陣列中,再把另一個數組中的資料依次加入到臨時陣列的末尾,這個時候,臨時陣列中儲存的就是兩個子數組合並之後的結果了。
- 最後再把臨時陣列 tmp 中的資料拷貝到原陣列 arr[p…r] 中。
 ````java
/**
* 分割槽函式方式二
* @param arr 陣列
* @param p 上標
* @param r 下標
* @return 函式返回pivot的下標
*/
public static int partition2(int[] arr, int p, int r) {
int pivot = arr[r];
int i = p;
for (int j = p; j < r; j++) {
if (arr[j] < pivot) {
if (i == j) {
++i;
} else {
int tmp = arr[i];
arr[i++] = arr[j];
arr[j] = tmp;
}
}
}
int tmp = arr[i];
arr[i] = arr[r];
arr[r] = tmp;
return i;
}
````
## 2.2、效能分析
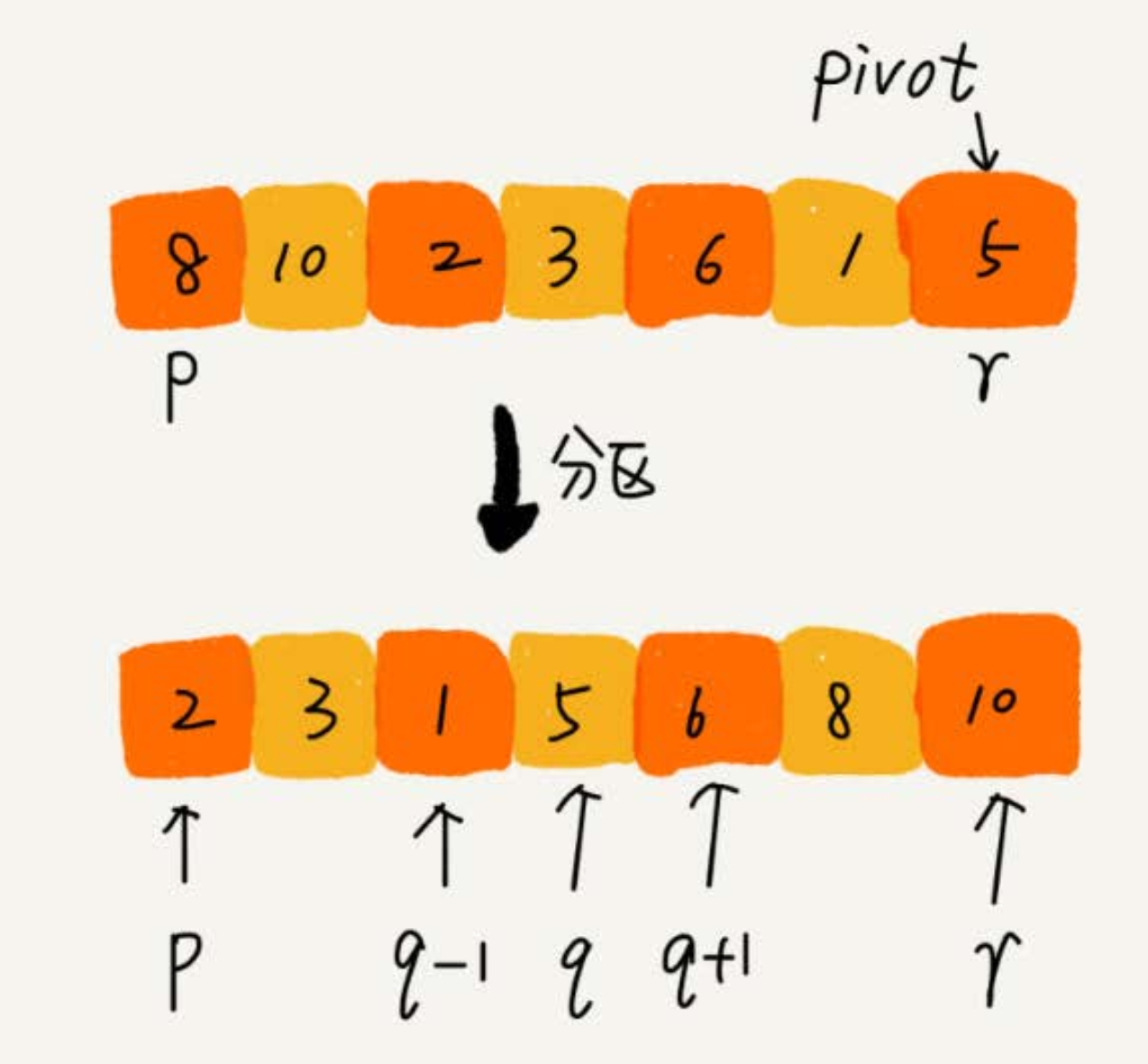
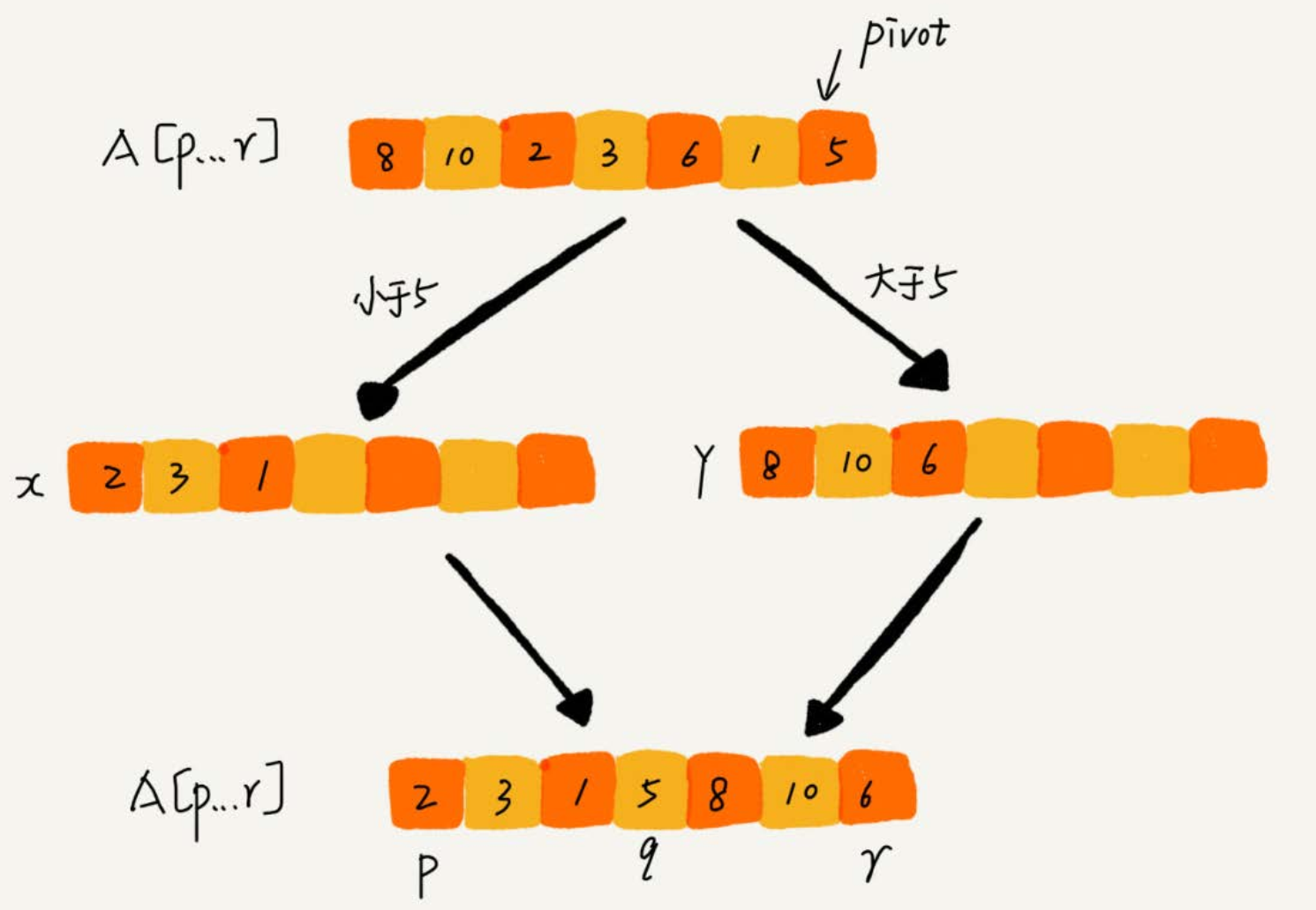
- 因為分割槽的過程涉及交換操作,如果陣列中有兩個相同的元素,比如序列 6, 8, 7, 6, 3, 5, 9, 4,在經過第一次分割槽操作之後,兩個 6 的相對先後順序就會改變。所以,快速排序並**不是穩定的排序演算法**。
- 按照上面的第二種分割槽方式,快速排序只涉及交換操作,所以**空間複雜度為 Q(1),是原地排序演算法**。
- **時間複雜度為 Q(nlogn),最差為Q(n²)**。
# 三、兩者對比
````java
/**
* 分割槽函式方式二
* @param arr 陣列
* @param p 上標
* @param r 下標
* @return 函式返回pivot的下標
*/
public static int partition2(int[] arr, int p, int r) {
int pivot = arr[r];
int i = p;
for (int j = p; j < r; j++) {
if (arr[j] < pivot) {
if (i == j) {
++i;
} else {
int tmp = arr[i];
arr[i++] = arr[j];
arr[j] = tmp;
}
}
}
int tmp = arr[i];
arr[i] = arr[r];
arr[r] = tmp;
return i;
}
````
## 2.2、效能分析
- 因為分割槽的過程涉及交換操作,如果陣列中有兩個相同的元素,比如序列 6, 8, 7, 6, 3, 5, 9, 4,在經過第一次分割槽操作之後,兩個 6 的相對先後順序就會改變。所以,快速排序並**不是穩定的排序演算法**。
- 按照上面的第二種分割槽方式,快速排序只涉及交換操作,所以**空間複雜度為 Q(1),是原地排序演算法**。
- **時間複雜度為 Q(nlogn),最差為Q(n²)**。
# 三、兩者對比
 | | 歸併排序 | 快速排序 |
| ---- | ---- | ---- |
| 排序思想 | 處理過程**由下到上,先處理子問題,然後在合併** | **由上到下,先分割槽,在處理子問題** |
| 穩定性 | 是 | 否 |
| 空間複雜度 | Q(n) | Q(1) 原地排序演算法 |
| 時間複雜度 | 都為 O(nlogn) | 平均為 O(nlogn),最差為 O(n²) |
- 歸併之所以是非原地排序演算法,主要原因是合併函式無法在原地執行。快速排序通過設計巧妙的原地分割槽函式,可以實現原地排序,解決了歸併排序佔用太多記憶體的問題。
- 歸併排序演算法是一種在任何情況下時間複雜度都比較穩定的排序演算法,這也使它存在致命的缺點,即歸併排序不是原地排序演算法,空間複雜度比較高,是 O(n)。正因為此,它也沒有快排應用
| | 歸併排序 | 快速排序 |
| ---- | ---- | ---- |
| 排序思想 | 處理過程**由下到上,先處理子問題,然後在合併** | **由上到下,先分割槽,在處理子問題** |
| 穩定性 | 是 | 否 |
| 空間複雜度 | Q(n) | Q(1) 原地排序演算法 |
| 時間複雜度 | 都為 O(nlogn) | 平均為 O(nlogn),最差為 O(n²) |
- 歸併之所以是非原地排序演算法,主要原因是合併函式無法在原地執行。快速排序通過設計巧妙的原地分割槽函式,可以實現原地排序,解決了歸併排序佔用太多記憶體的問題。
- 歸併排序演算法是一種在任何情況下時間複雜度都比較穩定的排序演算法,這也使它存在致命的缺點,即歸併排序不是原地排序演算法,空間複雜度比較高,是 O(n)。正因為此,它也沒有快排應用
- 寫遞迴程式碼的技巧就是,分析得出遞推公式,然後找到終止條件,最後將遞推公式翻譯成遞迴程式碼。所以,要想寫出歸併排序的程式碼,我們先寫出歸併排序的遞推公式。
- 遞推公式:erge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
- 終止條件:p >= r 不用再繼續分解
- merge_sort(p…r)表示,給下標從 p 到 r 之間的陣列排序。
- 我們將這個排序問題轉化為了兩個子問題, merge_sort(p…q) 和 merge_sort(q+1…r),其中下標 q 等於 p 和 r 的中間位置,也就是 (p+r)/2。
- 當下標從 p 到 q 和從 q+1 到 r 這兩個子陣列都排好序之後,我們再將兩個有序的子數組合並在一起,這樣下標從 p 到 r 之間的資料就也排好序了。
- 實現思路如下:
````java
/**
* 歸併排序
* @param arr 排序資料
* @param n 陣列大小
*/
public static void merge_sort(int[] arr, int n) {
merge_sort_c(arr, 0, n - 1);
}
// 遞迴呼叫函式
public static void merge_sort_c(int[] arr, int p, int r) {
// 遞迴終止條件
if (p >= r) {
return;
}
// 取p到r之間的中間位置q
int q = (p + r) / 2;
// 分治遞迴
merge_sort_c(arr, p, q);
merge_sort_c(arr, q + 1, r);
// 將 arr[p...q] 和 arr[q+1...r] 合併為 arr[p...r]
merge(arr[p...r],arr[p...q],arr[q + 1...r]);
}
````
- merge(arr[p...r], arr[p...q], arr[q + 1...r]) 這個函式的作用就是,將已經有序的 arr[p…q] 和 arr[q+1…r] 合併成一個有序的陣列,並且放入 arr[p…r]。
- 如下圖所示,我們申請一個臨時陣列 tmp,大小與 arr[p…r] 相同。
- 我們用兩個遊標 i 和 j,分別指向 arr[p…q] 和 arr[q+1…r] 的第一個元素。
- 比較這兩個元素 arr[i] 和 arr[j],如果 arr[i] <= arr[j],我們就把 arr[i] 放入到臨時陣列 tmp,並且 i 後移一位,否則將 arr[j] 放入到陣列 tmp,j 後移一位。
- 繼續上述比較過程,直到其中一個子陣列中的所有資料都放入臨時陣列中,再把另一個數組中的資料依次加入到臨時陣列的末尾,這個時候,臨時陣列中儲存的就是兩個子數組合並之後的結果了。
- 最後再把臨時陣列 tmp 中的資料拷貝到原陣列 arr[p…r] 中。
````java
/**
* 分割槽函式方式二
* @param arr 陣列
* @param p 上標
* @param r 下標
* @return 函式返回pivot的下標
*/
public static int partition2(int[] arr, int p, int r) {
int pivot = arr[r];
int i = p;
for (int j = p; j < r; j++) {
if (arr[j] < pivot) {
if (i == j) {
++i;
} else {
int tmp = arr[i];
arr[i++] = arr[j];
arr[j] = tmp;
}
}
}
int tmp = arr[i];
arr[i] = arr[r];
arr[r] = tmp;
return i;
}
````
## 2.2、效能分析
- 因為分割槽的過程涉及交換操作,如果陣列中有兩個相同的元素,比如序列 6, 8, 7, 6, 3, 5, 9, 4,在經過第一次分割槽操作之後,兩個 6 的相對先後順序就會改變。所以,快速排序並**不是穩定的排序演算法**。
- 按照上面的第二種分割槽方式,快速排序只涉及交換操作,所以**空間複雜度為 Q(1),是原地排序演算法**。
- **時間複雜度為 Q(nlogn),最差為Q(n²)**。
# 三、兩者對比
| | 歸併排序 | 快速排序 |
| ---- | ---- | ---- |
| 排序思想 | 處理過程**由下到上,先處理子問題,然後在合併** | **由上到下,先分割槽,在處理子問題** |
| 穩定性 | 是 | 否 |
| 空間複雜度 | Q(n) | Q(1) 原地排序演算法 |
| 時間複雜度 | 都為 O(nlogn) | 平均為 O(nlogn),最差為 O(n²) |
- 歸併之所以是非原地排序演算法,主要原因是合併函式無法在原地執行。快速排序通過設計巧妙的原地分割槽函式,可以實現原地排序,解決了歸併排序佔用太多記憶體的問題。
- 歸併排序演算法是一種在任何情況下時間複雜度都比較穩定的排序演算法,這也使它存在致命的缺點,即歸併排序不是原地排序演算法,空間複雜度比較高,是 O(n)。正因為此,它也沒有快排應用