
深度學習-卷積神經網路-演算法比較
阿新 • • 發佈:2020-07-18
# Convolutional Neural Networks(CNN)
## Abstract
隨著深度學習的發展,學術界造就了一個又一個優秀的神經網路,目前,最受歡迎的神經網路之一則是卷積神經網路,儘管有時它出現讓我們無法理解的黑盒子現象,但它依然是值得我們去探索的,**CNN**的設計也遵循了**活生物體的視覺**處理過程。
首先分析一下人腦的神經元(人腦視覺系統)。

人腦神經元資訊處理過程包括接受輸入,處理,輸出這麼三個階段。對應到一個神經元上就是樹突,胞體,軸突。
**神經網路**仿照人腦的神經元結構之間的聯絡,當某個神經元的**軸突電訊號強度**達到一定程度時,就會觸發將訊號**傳遞**到下一個神經元。在傳遞的過程中加上一些對資料處理的操作,從而達到處理傳遞資訊的目的。其中的訊號正是將資料抽象過後的數值或者多維矩陣。
**卷積神經網路**,在CNN出現之前,對於人工智面臨著兩大難題:
- 影象需要處理的資料量太大,導致成本很高,效率很低
- 影象在數字化的過程中很難保留原有的特徵,導致影象處理的準確率不高
**需要處理的資料量太大**。由於影象是由畫素構成的,每個畫素又是由多種顏色構成的。
幾乎任何一張圖片都是 1000×1000 畫素以上的, 每個畫素都有RGB 3個引數來表示顏色資訊。這樣就需要處1000×1000×3個引數,因此訓練任務太過複雜, **CNN** 解決的第一個問題就是「**將複雜問題簡化**」,通過**卷積**/**池化**的方式把大量引數降維成少量引數,再做處理。更重要的是:我們在大部分場景下,降維並不會影響結果。比如10000畫素的圖片縮小成2000畫素,並不影響肉眼認出來圖片中是一隻貓還是一隻狗,機器也是如此。
**保留影象特徵**。圖片數字化的傳統方式我們簡化一下,就類似下圖的過程:
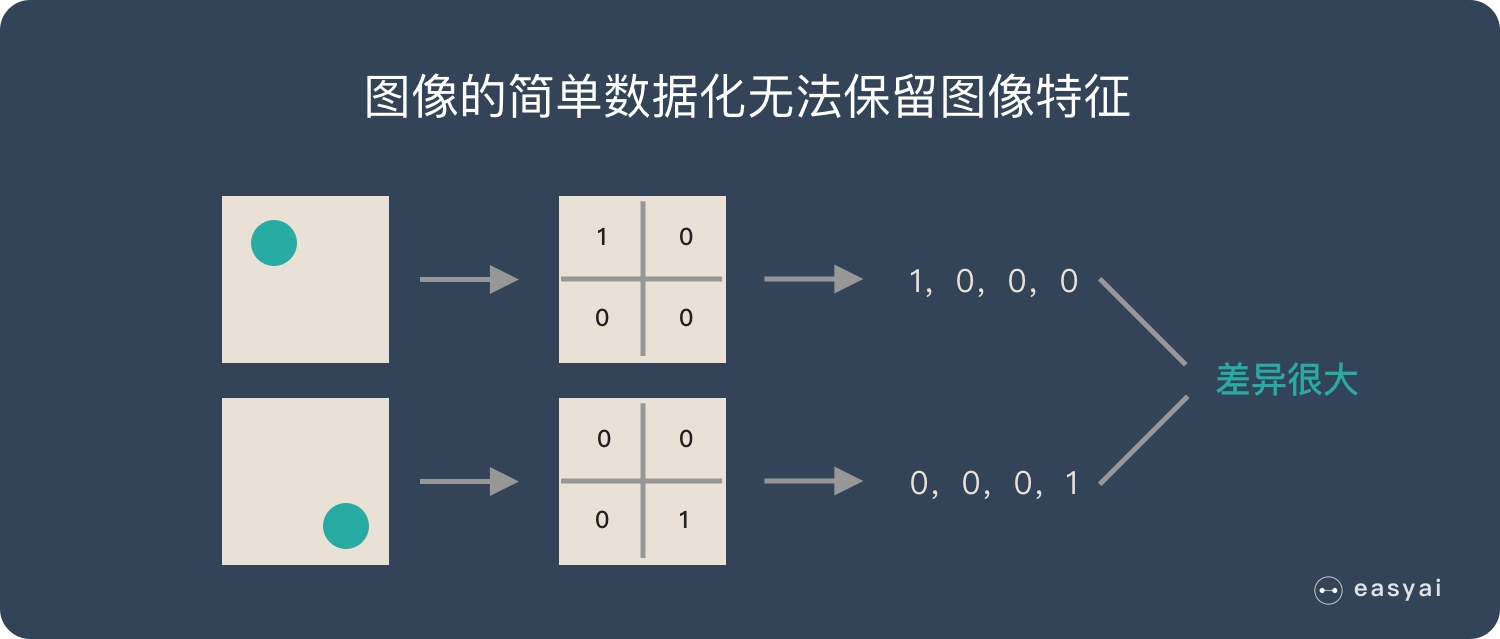
假如有圓形是1,沒有圓形是0,那麼圓形的位置不同就會產生完全不同的資料表達。但是從視覺的角度來看,影象的內容(本質)並沒有發生變化,只是位置發生了變化。所以當我們移動影象中的物體,用傳統的方式的得出來的引數會**差異很大**!這是不符合影象處理的要求的。而 **CNN** 解決了這個問題,它用類似視覺的方式保留了影象的特徵,當影象做翻轉,旋轉或者變換位置時,它也能有效的識別出來是類似的影象。
## Introduction
卷積神經網路(Convolutional Neural Network, CNN)是一種**前饋**神經網路,同時結合了多層感知器,多層感知器通常是指完全連線的網路,也就是說,一層中的每個神經元都與下一層中的所有神經元相連。這些網路的“**完全連線**”使它們易於**過度擬合**資料。正則化的典型方法包括向損失函式新增某種形式的權重度量。CNN採用不同的正規化方法:它們利用資料中的分層模式,並使用更小和更簡單的模式組合更復雜的模式。與其他**影象分類演算法**相比,CNN使用的預處理相對較少。這意味著網路將學習傳統演算法中[手工設計](https://en.wikipedia.org/wiki/Feature_engineering)的**過濾器**。與特徵設計中的先驗知識和人工無關的這種獨立性是主要優勢。
典型的CNN訓練主要由三層結構組成
- 卷積層
- 池化層
- 全連線層

### **Convolution(卷積層)**
對CNN模型進行實現時,輸入的資料為形狀(影象數量)x(影象高度)x(影象寬度)x(影象深度)。然後,在經過**卷積層**後,影象將被抽象為**特徵圖**,其形狀(影象數量)x(特徵圖高度)x(特徵圖寬度)x(特徵圖通道)。神經網路中的卷積層應具有以下屬性:
- 由寬度和高度(超引數)定義的卷積核。
- 輸入通道和輸出通道的數量(超引數)。
- 卷積過濾器(輸入通道)的深度必須等於輸入要素圖的通道數(深度)。
### **Pooling(池化)**
池化層通過將一層神經元簇的輸出組合到下一層中的單個神經元中來減少資料的大小。池化層包括區域性或全域性池化層,區域性池合併了通常為2 x 2的小簇。全域性池作用於卷積層的所有神經元。池化方式又有兩種:最大池化和平均池化
- 最大池化
取上一層中每個神經元簇的**最大值**來作為下一層神經元簇的特徵
- 平均池化
取上一層中每個神經元簇的**平均值**來作為下一層神經元簇的特徵
下圖以最大池化為例

### **Fully Connected(全連線層)**
**全連線層**,上一層的每個神經元都會連線到下一層每個神經元,因此該層的處理又與全連線神經網路類似。

## Development Overview
從1959年,Hubel & Wiesel發現動物視覺皮層中的細胞負責檢測**感受野**(receptive fields)中的光線。論文:Receptive fields and functional architecture of monkey striate cortex(1968)
1980年,Kunihiko Fukushima提出**新認知機**(neocognitron),被認為是CNN的前身。論文:A self-organizing neural network model for a mechanism of visual pattern recognition(1982)
1990年,LeCun建立了CNN的現代框架。論文:Handwritten digit recognition with a back-propagation network(1989NIPS)
1998年,LeCun改進CNN,他們開發了一個名為**LeNet-5**的多層人工神經網路,可以對手寫數字進行分類。與其他神經網路一樣,LeNet-5具有多個層,可以通過反向傳播演算法進行訓練。它可以獲得原始影象的有效表示,這使得從原始畫素直接識別視覺模式成為可能,而且很少進行預處理。論文:Gradient-based learning applied to document recognition(1998)
1990年,Zhang使用一個平移不變性的人工神經網路(**SIANN**),識別影象的字元。但由於當時缺乏大量的訓練資料和計算能力,他們的網路在更復雜的問題,例如大規模的影象和視訊分類方面不能很好地執行。論文:Parallel distributed processing model with local space-invariant interconnections and its optical architecture(1990)
2015年,Krizhevsky提出一個經典的CNN架構,即**AlexNet**。它顯示了在影象分類任務上根據以前方法的重大改進,在整體結構上與LeNet-5類似,但深度更深。論文:Imagenet large scale visual recognition challenge(2015IJCV)
**CNN每一階段的發展,都對訓練的複雜度進行了降低,辨識能力提高。**
## Comparison
**LeNet-5**的出現可以說標誌著現代CNN模型發展的開端,以至於有了後來的**AlexNet**。相比於**LeNet-5**,AlexNet有更深的結構,用多層小的卷積來替代大卷積。
### Common
**LeNet-5**雖然出現較早,但其結構並不缺少,包括卷積層-池化層-全連線層三層結構,**AlexNet**與其總體結構也是十分相似的。
### Difference
首先,AlexNet最明顯的特徵是用多層小的卷積核來代替原來較大的卷積核,這使得AlexNet有更高的準確率。
**LeNet-5**最初主要用於影象識別,若按照處理過程來分析**LeNet-5**,其共有八層:
- ### Input層-輸入層
輸入影象的尺寸統一歸一化為32*32
- ### C1層-卷積層
對輸入影象進行第一次卷積運算(使用 6 個大小為 5×5 的卷積核),得到6個C1特徵圖(6個大小為28*28的 feature maps, 32-5+1=28)
- ### S2層-池化層(下采樣層)
第一次卷積之後緊接著就是池化運算,使用 2*2核 進行池化,於是得到了S2(6@14×14)
- ### C3層-卷積層
利用前六個C3特徵,從三個連續子集中獲取輸入S2中的功能圖。接下來的六個從第四個的不連續子集開始。最後一個從所有S2特徵對映中獲取輸入。因此C3層有1516個可訓練引數和151600個連線,下圖引自**LeNet-5 paper**。

- ### S4層-池化層(下采樣層)
S4是pooling層,視窗大小仍然是2*2,共計16個feature map,C3層的16個10x10的圖分別進行以2x2為單位的池化得到16個5x5的特徵圖
- ### C5層-卷積層
C5層是一個卷積層。由於S4層的16個圖的大小為5x5,與卷積核的大小相同,所以卷積後形成的圖的大小為1x1。
- ### F6層-全連線層
全連線到下一層
- ### Output層-全連線層
全連線輸出層,輸出結果
下圖引自**LeNet-5 paper**

**可總結出LeNet-5卷積層的引數較少,這也是由卷積層的特性即區域性連線與共享權值所決定**
**AlexNet**是在**LeNet-5**的基礎上加深了網路的結構,學習更豐富更高維的影象特徵
- **使用層疊的卷積層**-(卷積層+卷積層+池化層來提取影象的特徵)
- **使用Dropout抑制過擬合**
以0.5的概率,將每個隱層神經元的輸出設定為零。
- 使用資料增強**Data Augmentation**抑制過擬合
通過訓練資料進行自我變換的方式進行擴充資料規模,以提高演算法的識別準確率
- 水平翻轉影象
- 給影象增加隨機的色彩
- 使用Relu啟用函式替換之前的sigmoid的作為啟用函式
Sigmoid 是常用的非線性的啟用函式,用0-1區間的值來壓縮特徵,假若有個比較大的特徵值9999,我們也需要把它壓縮到0-1,這就使得壓縮過強

**Relu**是分段線性函式,所有的負值和0為0,所有的正值不變,這種操作被稱為**單側抑制**

- 發現使用 ReLU 得到的SGD的收斂速度會比 sigmoid/tanh 快很多。
- 多GPU訓練
### Conclusion
**AlexNet 優勢在於:網路增大(5個卷積層+3個全連線層+1個softmax層),同時解決過擬合,並且利用多GPU加速計算。**
## Summary
##### References
[[1]Gradient-Based-Learning-Applied-to-Document-Recognition](https://www.researchgate.net/profile/Yann_Lecun/publication/2985446_Gradient-Based_Learning_Applied_to_Document_Recognition/links/0deec519dfa1983fc2000000/Gradient-Based-Learning-Applied-to-Document-Recognition.pdf)
[[2]ImageNet Large Scale Visual Recognition Challenge](https://www.researchgate.net/profile/Hao_Su8/publication/265295439_ImageNet_Large_Scale_Visual_Recognition_Challenge/links/54cbd6a90cf29ca810f452