
[深度學習]卷積神經網路:卷積、池化、常見分類網路
卷積
全連線層:將卷積層所有的畫素展開,例如得到一個3072維的向量,然後在向量上進行操作。
卷積層:可以保全空間結構,不是展開成一個長的向量。
卷積操作:將卷積核從影象(或者上一層的feature map)的左上方的邊角處開始,遍歷卷積核覆蓋的所有畫素點。在每一個位置,我們都進行點積運算,每一次運算都會在我們輸出的啟用對映中產生一個值。之後根據stride值,繼續滑動卷積核。例如stride為1時,一個畫素一個畫素地滑動。其本質也是f(x) = f(wx+b)。
卷積層意義:
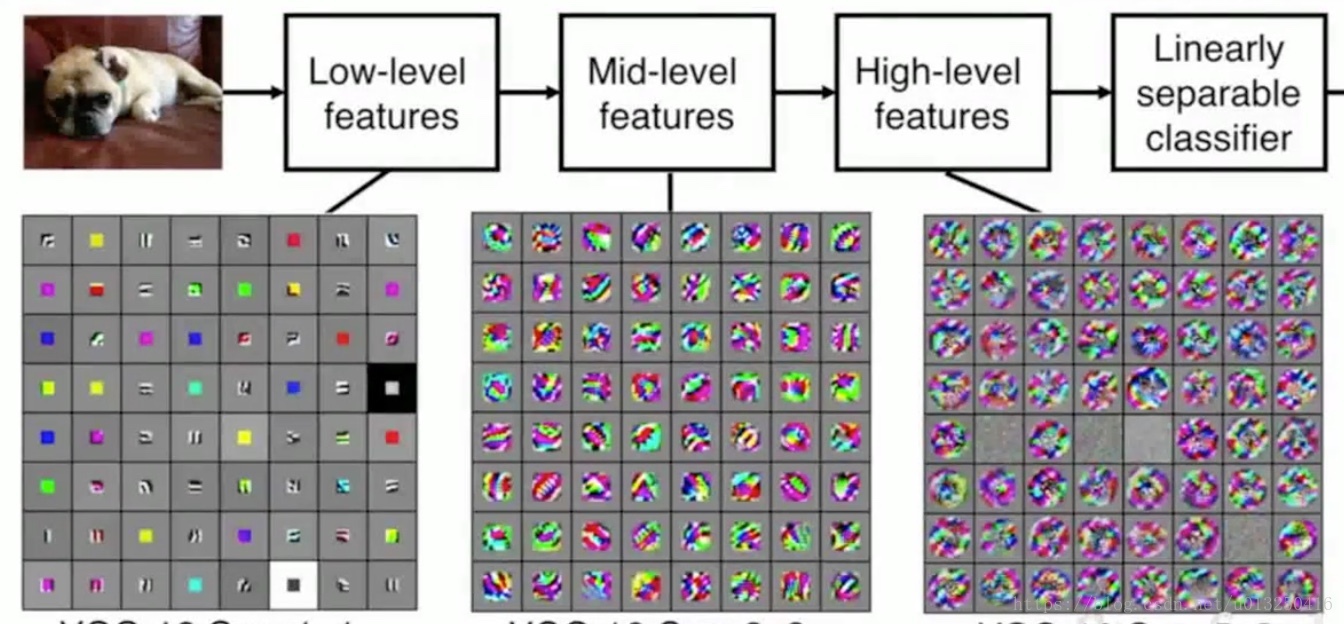
Low-level features:低層特徵一般代表了一些低階的影象特徵,比如一些邊緣特徵;
Mid-level features:中間層可以得到一些更加複雜的影象特徵,比如邊角或者斑點;
High-level features:對於高階的特徵,可以獲得比斑點更加豐富的內容。
這些特徵是一些從簡單到複雜的特徵序列。
Q:零填充是否在角落上增加了一些額外的特徵?
A:在邊緣處是有些人為成分,但是在實際應用中這是合理的。零填充可以避免影象特徵層的尺寸迅速減小,損失特徵資訊。
Q:對於長方形圖片,是否需要使用橫縱不同的步幅?
A:可以這樣做。但是在實際中,我們通常操作方形區域,因此一般在長寬方向上使用同樣的步幅。
Q:如何選擇,保證得到想要的輸出:
A:可以考慮的因素包括:卷積核的大小、卷積核的數量、步長的大小、零填充;通常選擇的卷積核的大小為3*3,5*5,7*7。
Q:Input volume: 32*32*3
10 5*5 filters with stride 1, pad 2
Output size? Number of parameters in this layer?
A:Output size : (32+2*2-5)/1+1=32, 32 * 32 * 10
Parameters: 每一個卷積核的引數:5*5*3+1=76(包含偏差項)
10個卷積核的引數:76*10=760
公式:對於W1*H1*D1的輸入,卷積核的數量為K,卷積核的大小為F,stride為S, padding 為 P。
那麼輸出W2*H2*D2滿足:
W2 = (W1 + 2*P – F) / S + 1;
H2= (H2 + 2*P – F) / S +1;
D2 = K
Q:如何憑著直觀感覺來確定所使用的步長呢?
A:引數數量、模型尺寸、過擬合之間的平衡。
卷積特徵
在處理影象時,我們常把影象表示為畫素的向量,所以一個1000×1000的影象,就有1000000個輸入向量,如果此時下一層的隱藏層中有1000000個神經元,採用BP神經網路的全連線,兩層之間將會有1000000×1000000個連線,此時,引數集合會過於龐大以至於難以訓練。
卷積神經網路通過區域性感知、權值共享以及多卷積核,解決了引數龐大的問題。
1、區域性感知
卷積網路通過區域性感受野和權值共享來降低引數數目。首先來看區域性感受野。一般認為人對外界的認知是從區域性到全域性的,而影象的空間聯絡也是區域性的畫素聯絡較為緊密,而距離較遠的畫素相關性則較弱。因此,每個神經元其實沒有必要對全域性影象進行感知,只需要對區域性進行感知,然後在更高層將區域性的資訊綜合起來就得到了全域性的資訊。也就是說,區域性感受野指的是卷積層的神經元只和上一層的特徵層(feature map)的區域性相聯絡。還是上面那個例子,設每個神經元的感受野為10×10,那麼兩層的連線數為100×1000000,引數減少了四個數量級。將區域性特徵提取合併成整體特徵的過程,我們稱之為卷積(加權的滑動平均)。
2、權值共享
權值共享(也就是卷積操作)減少了權值(引數)數量,降低了網路複雜度,可以看成是特徵提取的方式。其中隱含的原理是:影象中的一部分的統計特性與其他部分是一樣的。這意味著我們在某一部分學習的特徵,也能用到另一部分上。所以對於整個影象上的所有位置,我們都能使用同樣的學習特徵。在上面的那次卷積中,每個神經元都會與100個畫素點連線,也就是說每個神經元有100個連線引數,不妨設這1000000個神經元都具有相同的連線引數(這個引數集合就是我們所說的卷積核),那麼這次卷積的引數只有100個。
3、多卷積核
經過上面兩輪化簡,一個卷積核卷積後,只能得到一個方面的特徵。若需要多方面的特徵,只需要新增多個卷積核。而這個新增的數量一般不會對引數的個數造成多大量級上的變化。假設有30個卷積核,那麼引數的個數就是30×100。
通過區域性感知、引數共享、多卷積核,卷積神經網路不僅將減少的引數的數量,還在某種程度上達到了位移、尺度、形變的不變性,能夠更有效的提取特徵。
3、池化
在通過卷積獲得了特徵之後,下一步我們希望利用這些特徵去做分類。人們可以用所有提取到的特徵去訓練分類器,例如softmax分類器。但這樣做的話,會面臨計算量的挑戰,並且容易出現過擬合。
前面我們使用卷積後的特徵,是因為影象具有一種“靜態性”的屬性,這也就意味著在一個影象區域有用的特徵極有可能在另一個區域同樣適用。因此,為了描述大的影象,可以對不同位置的特徵進行聚合統計,如計算平均值或者是最大值。例如:最大池化把輸入的影象分割為不重疊的矩陣,每一個子區域都輸出最大值。
通過對影象不同位置的特徵進行聚合(即我們所說的池化),池化層的影象會具有更低的維度,也不易產生過擬合的現象。
池化層:池化和普通的卷積操作一樣,也是一種降取樣的方式,可以讓所生成的表示更小更容易控制。不會做深度方向上的池化處理,只做平面上的的池化,所以池化操作輸入的深度和輸出的深度是一樣的。
常見的池化方式:最大池化、平均池化。對於池化,通常設定步長,使它們沒有任何重疊。一般不在池化層填零,只做降取樣處理。
常見的分類卷積神經網路
1.LeNet
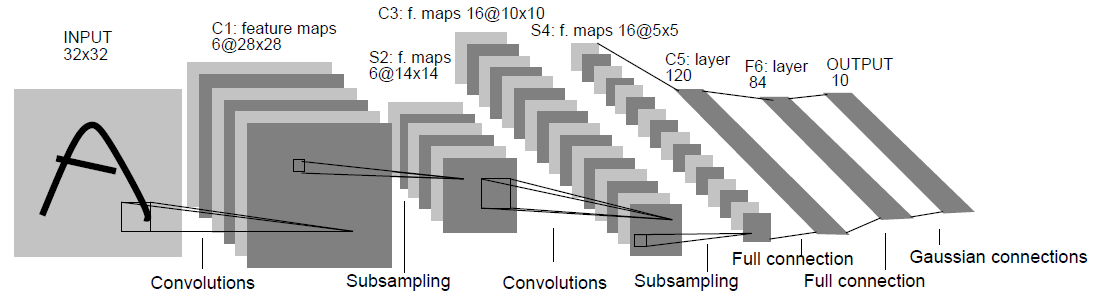
input:32*32,卷積層使用的卷積核大小均為5*5,stride=1。
應用:數字識別領域。
2.AlexNet
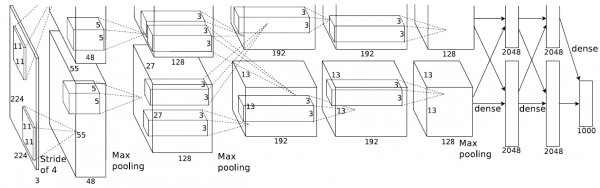
Input: 227*227*3
第一層:96個11*11,stride=4的卷積核
第一層的輸出:特徵層大小為(227-11)/4+1=55,輸出為55*55*96
第一層的引數數目:96*(11*11*3+1)
每一個卷積核都要處理一個11*11*3的資料塊,也就是分別對每一個通道的資料進行處理,然後將不同通道處理後的資料進行相加。
第二層:3*3, stride = 2
池化層沒有引數
3.ZFNet
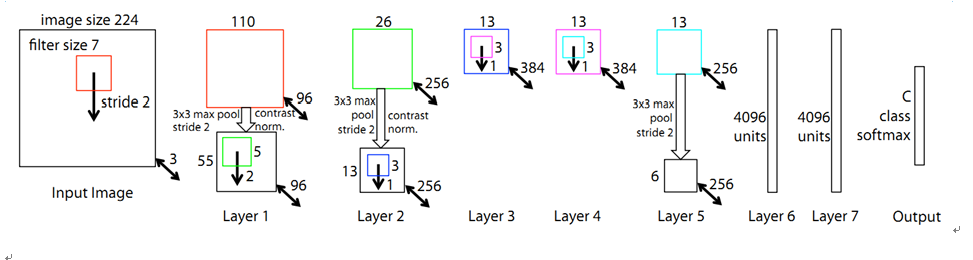
對比AlexNet在卷積核大小、卷積核數量、步長上改進
4.GooLeNet
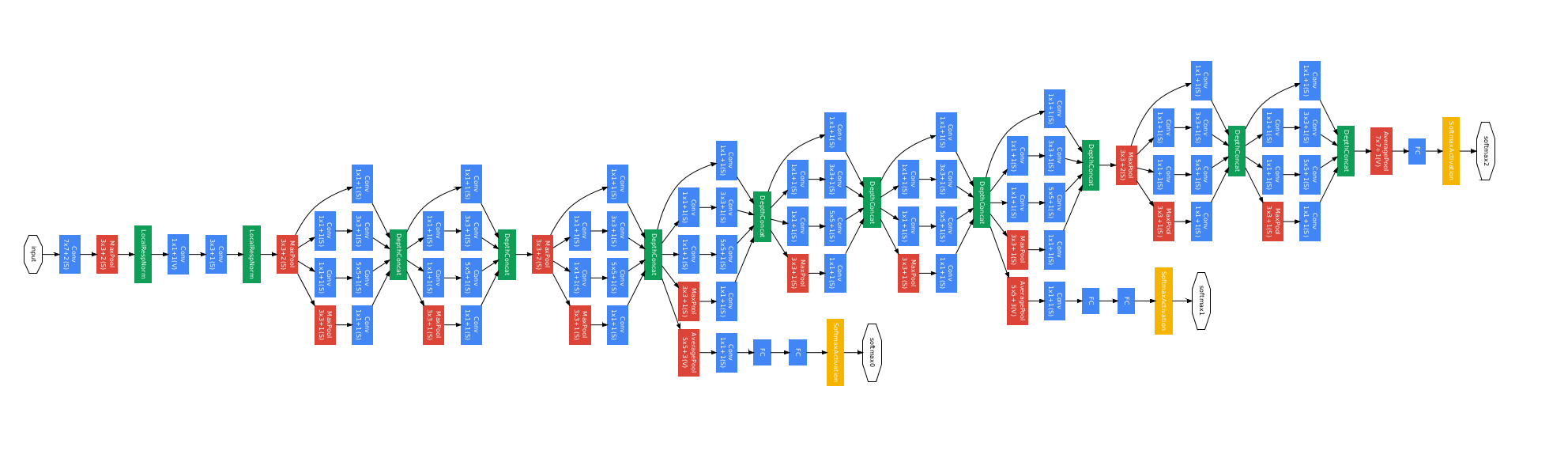
一共22層。
設計思想:Inception模組。
使用inception模組,然後每個inception模組的頂部進行輸出合併。
dinception模組:對進入相同層的相同輸入,並行應用不同類別的濾波操作。也就是,對輸入進行不同的卷積操作,如1*1卷積,3*3卷積,5*5卷積,也有池化操作,這樣就可以利用相同的輸入,得到不同的輸出。在inception模組的頂部,將所有的濾波器輸出在深度層面上串聯在一起,得到一個張量輸出。這個張量將進入下一層。
簡單描述,就是用不同的操作得到不同的輸出,然後將這些輸出串聯在一起。

解決深度帶來的計算資源消耗問題:
由於在inception模組中,我們通過保留相同的尺寸來擴充深度。因此,經過每一個inception模組,特徵層的深度只能疊加。深度過大,會帶來巨大的計算資源消耗問題。
那麼,如何解決這個問題呢?
通過增加一層瓶頸層並且嘗試在卷積運算之前降低特徵圖的維度。
例如:在卷積運算之前,使用1*1*32卷積核,將輸入深度投影到一個更低的維度,相當於對特徵圖進行了一次線性組合。
可以使用其他的方法進行降維,為什麼還要使用1*1卷積核呢?
因為1*1卷積層是和其他層一樣的卷積網路,僅僅需要訓練這些核心網路,再通過反向傳播這個網路,即可得到訓練。
5.VGGNet
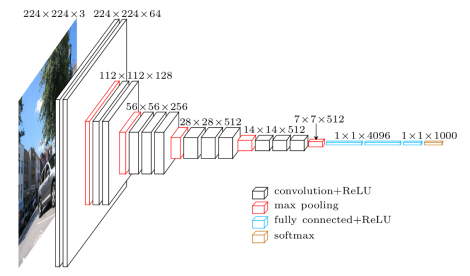
卷積層:3*3 conv stride 1, pad 1
池化層:2*2 max pool stride 2
更深的網路以及更小的卷積核
網路只關注相鄰的畫素
為什麼使用小的卷積核?
當使用小的卷積核,可以保持較小的引數量,從而使用更深的網路和更多的卷積核。例如3個3*3的卷積核效果好於1個7*7卷積核。
6.ResNet
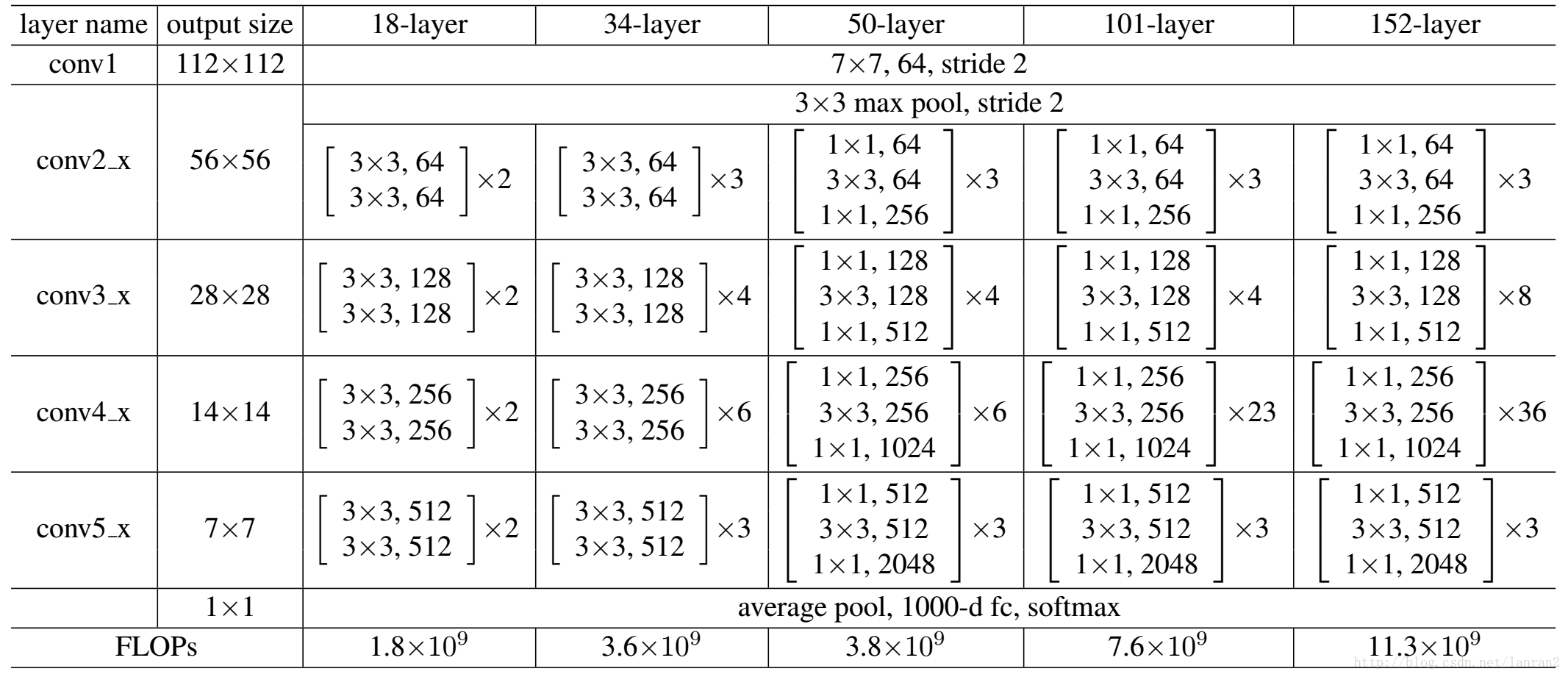
Q:當我們在普通卷積神經網路上堆疊越來越多的層時,到底會發生什麼?
A:對於普通的卷積網路而言,56層的網路效果不如20層的網路。ResNet的創造者假設這是一個優化問題。相比於淺層網路,深層網路更難優化。理由是,一個深層的網路至少能和一個更淺的模型表現得一樣好。
可以構造一個解決方案,一個更淺的網路,通過恆等對映,把這些拷貝到剩下的深層中。通過這個解決方案,可以使深層的網路表現的和淺層的網路一樣好。
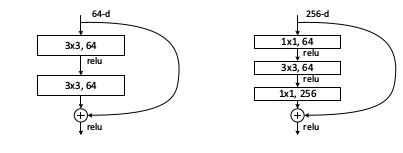
殘差網路思想:
輸入x,輸出F(x) = H(x) - x。(原輸出:H(x),也就是經過深度神經網路得到的x的非線性變換)
我們不是直接學習輸出H(x),而是學習殘差F(x) = H(x)-x。不是直接學習H(x),而是學習當我們移動到下一層時,需要在輸入上加上或者減去什麼。可以認為這是一種輸入的修正。F(x)就是我們所說的殘差。通過學習F(x),使得每一層的輸出更接近x,它更像是修正x,而不是完全學習它應該是怎麼樣的。
作者假設學習殘差比直接學習對映更容易。如果真的這個恆等對映是最好的,則我們只是將F(x)壓縮變形為0,這個似乎更容易學習。
每個殘差塊都是兩個3*3的卷積層。
類似GoogleNet,resnet也使用類似的瓶頸來提高效率。
7.ResNeXt
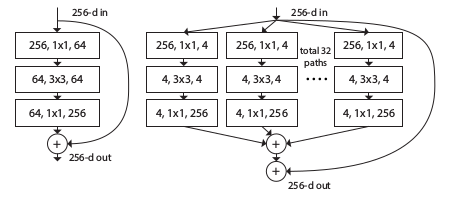
增加ResNet的寬度,不是通過增加捲積核來增加殘差模組的寬度,而是在每個殘差模組內建立多分支。這些分支的總和被稱為基數。