
怎麼訓練出一個NB的Prophet模型
阿新 • • 發佈:2020-07-21

上篇《神器の爭》主要是介紹Prophet的特點以及prophet入門的一些注意事項,但離真正的實際運用還有段距離。本篇主要講解實際運用中Prophet調參的主要步驟以及一些本人實際經驗。
## 一 引數理解篇
```
class Prophet(object):
def __init__(
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
stan_backend=None
):
```
### 1.1 趨勢引數
| 引數 | 描述 |
|-------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| growth | growth是指模型的趨勢函式,目前取值有2種,linear和logistic |
| changepoints | Changepoint是指一個特殊的日期,在這個日期,模型的趨勢將發生改變。而changepoints是指潛在changepoint的所有日期,如果不指明則模型將自動識別。 |
| n_changepoints | 最大的Changepoint的數量。如果changepoints不為None,則本引數不生效。 |
| changepoint_range | 是指changepoint在歷史資料中出現的時間範圍,與n_changeponits配合使用,changepoint_range決定了changepoint能出現在離當前時間最近的時間點,changepont_range越大,changepoint可以出現的距離現在越近。當指定changepoints時,本引數不生效 |
| changepoint_prior_scale | 設定自動突變點選擇的靈活性,值越大越容易出現changepoint |
#### 1.1.1 growth
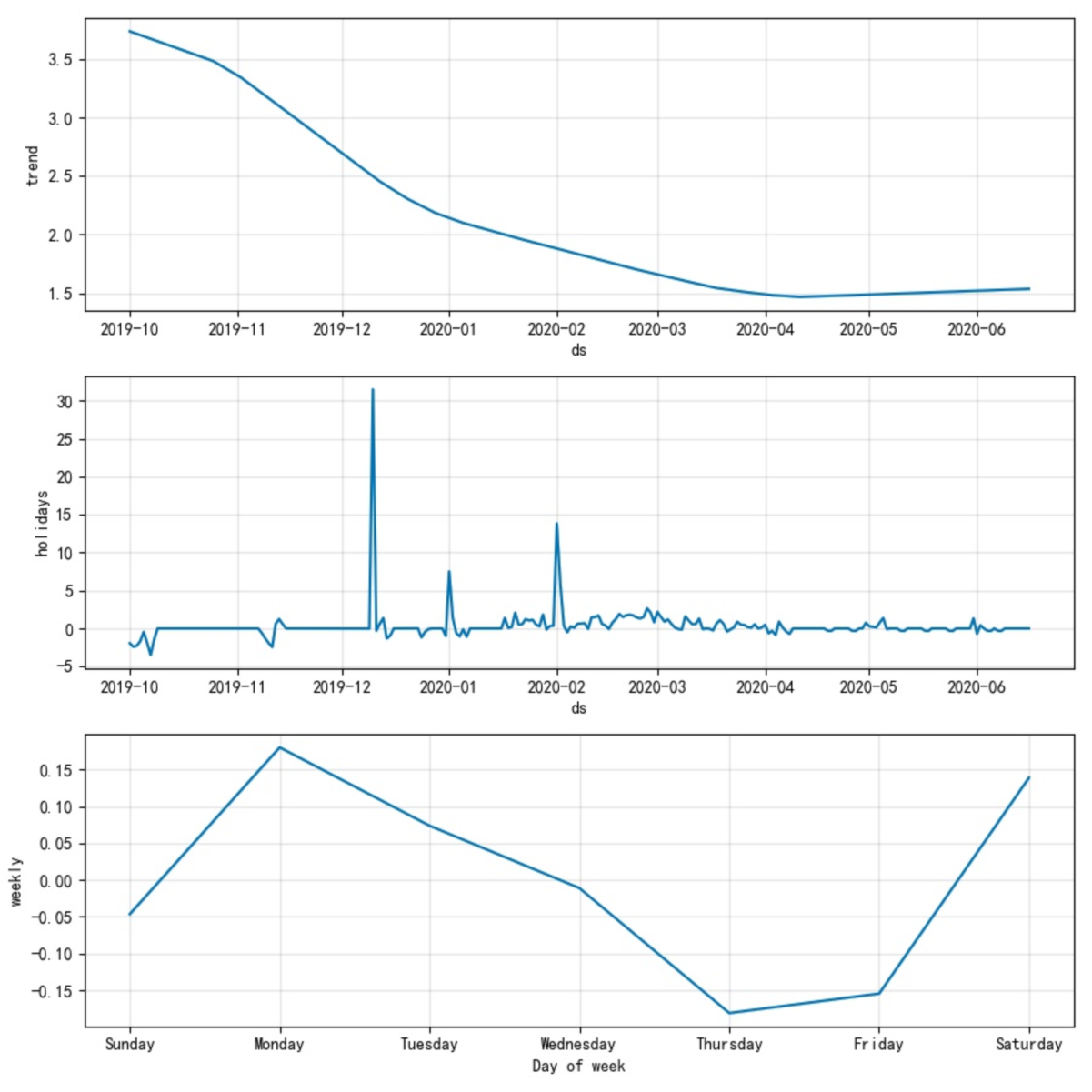
> growth是指模型的趨勢函式,目前取值有2種,linear和logistic,分別**如圖1-1**及**圖1-2**所示。趨勢會在changepoint處出現突變點。
|  |
|------------------------------------------|
| **圖1-1 linear趨勢** |
|  |
| **圖1-2 logistic趨勢** |
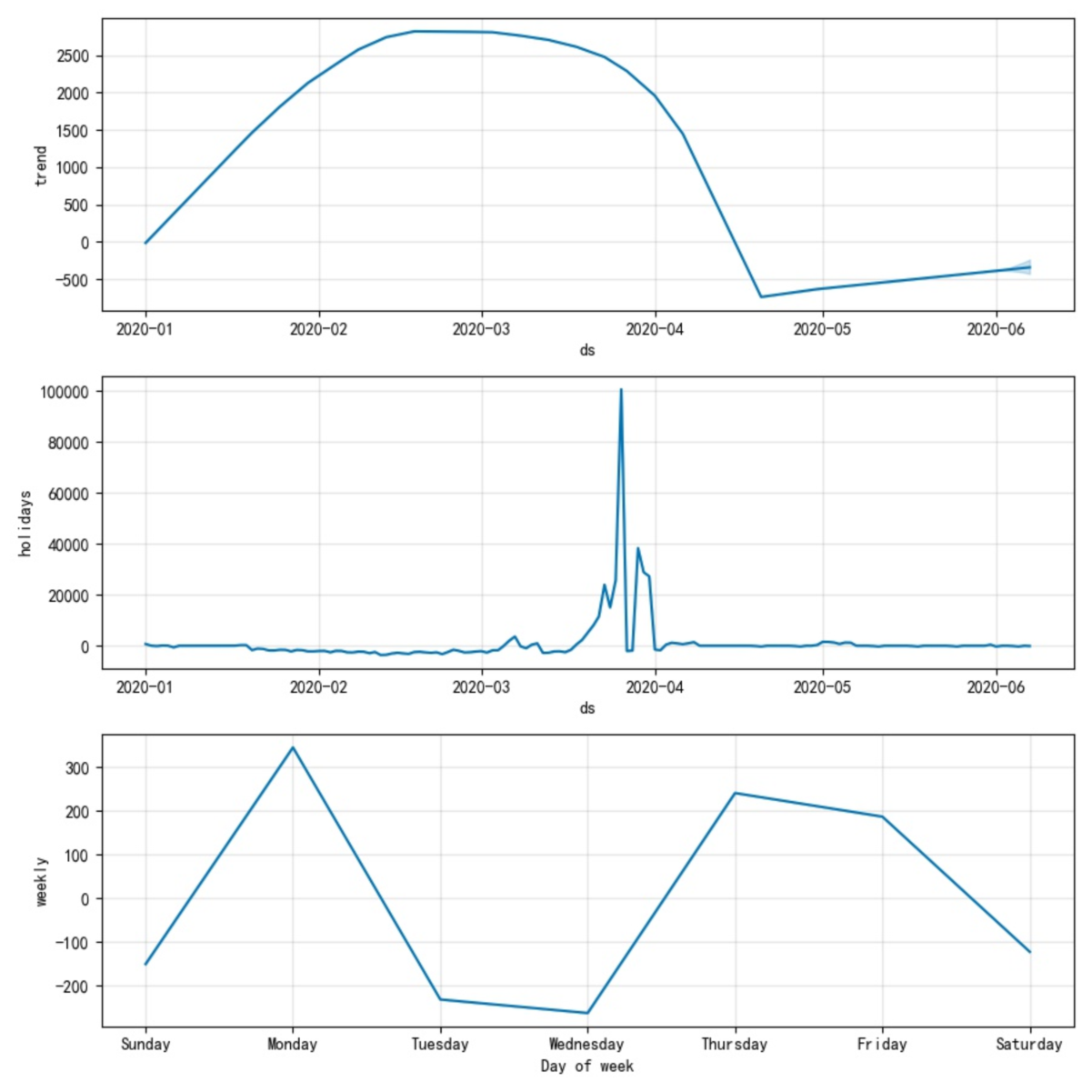
細心的同學可能會問,可不可能出現同一個模型既有linear趨勢,又有logistic趨勢,就像下面這樣:
|  |
|------------------------------------------|
| 圖1-3 |
在這裡福布溼要給大家糾正下這個錯覺,請大家記住Prophet的趨勢模型要麼是linear要麼是logistic。而上圖之所以像是兩種的疊加,是因為prophet的設計師為了讓趨勢函式可微(連續,就理解成連續吧)做了平滑處理,
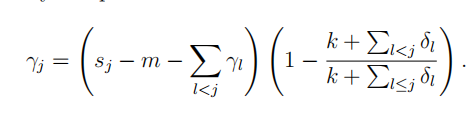
上面這貨就是論文中做平滑處理的公式。
#### 1.1.2 Changepoints
Changeponits形狀如[‘2013-01-01’,’2013-09-01’,’2017-02-5’],是changepoint的列表。
Changepoints是一個非常重要的引數,但使用者在決定設定此值時必須要注意,這個引數設定之後模型將不會自動尋找changepoints(同時n_changepoints和changepoint_range均不會生效),這就意味著手動設定的changeponits必須準確且完整,否則福布溼不建議大家設定此項。
#### 1.1.3 n_changeponits、changepoint_range
這2個引數是模型自動識別changepoint時需要的,n_changepoints限制了changepoint的最大數量,changepoint_range限制了changepoint在歷史資料中出現的時間範圍。例如圖1-1中changepoint_range福布溼設定的是0.5,而圖1-3中福布溼設定的是0.8,如果福布溼把圖1-3中的changepoint_range設定為0.2,那麼所有的changpoint均只能出現在2020-01-01至2020-02-01的範圍內。
### 1.2 週期性性引數
| 引數 | 描述 |
|-------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| yearly_seasonality | 年週期性,True為啟用,false為關閉,如果設定為自然數n,則n代表傅立葉級數的項數,項數越多,模型將擬合的越好,但是也越容易過擬合,因此論文中推薦年週期性的項數取10,而周的(weekly_seasonality)取3。 一般來講當歷史資料大於1年時模型預設為True(項數預設為10),否則預設為False |
| weekly_seasonality | 週週期性,True為啟用,false為關閉,如果設定為自然數n,則n代表傅立葉級數的項數,項數越多,模型將擬合的越好,但是也越容易過擬合,因此論文中推薦取3。 一般來講當歷史資料大於1周時模型預設為True(項數預設為3),否則預設為False |
| daily_seasonality | 天週期性,當時間序列為小時級別序列時才會開啟。 |
| seasonality_mode | 季節模型方式,'additive'(加法模型) (預設) 或者 'multiplicative'(乘法模型) |
| seasonality_prior_scale | 改變週期性影響因素的強度,值越大,週期性因素在預測值中佔比越大 |
週期性引數設定相對較為固化,除了seasonality_mode和seasonality_prior_scale可能需要手動調整外其餘各項一般情況下保持為預設值即可(當然具體問題具體分析,傅立葉項數在某些特殊情況下也可能需要調整)。
傅立葉級數跟泰勒展開式一樣,都是用特定的級數形式擬合某個函式,傅立葉級數是專門為週期性函式設計的,也就是說只要某個函式是周期函式就能使用傅立葉級數擬合。有興趣的同學可以看下知乎上的這個文章:
> https://zhuanlan.zhihu.com/p/41455378?from_voters_page=true
seasonality_mode的季節模型型別如果大家不深究按字面意思理解即可。
### 1.3 節假日引數
| 引數 | 描述 |
|---------------------|----------------------------------------------------------|
| holidays | 節假日或特殊日期,商業活動中活動日期是這類日期的典型代表 |
| holiday_prior_scale | 改變假日模型的強度 |
#### 1.3.1 holidays
Holidays引數是一個pd.DataFrame:
| holiday | ds | upper_window | lower_window |
|---------|----------|--------------|--------------|
| 元旦 | 2019/1/1 | 1 | \-1 |
| 元旦 | 2018/1/1 | 1 | \-1 |
holiday是特殊日期的時間,ds是時間(pd.Timestamp型別),upper_window和lower_window分別指特殊日期的影響上下限。
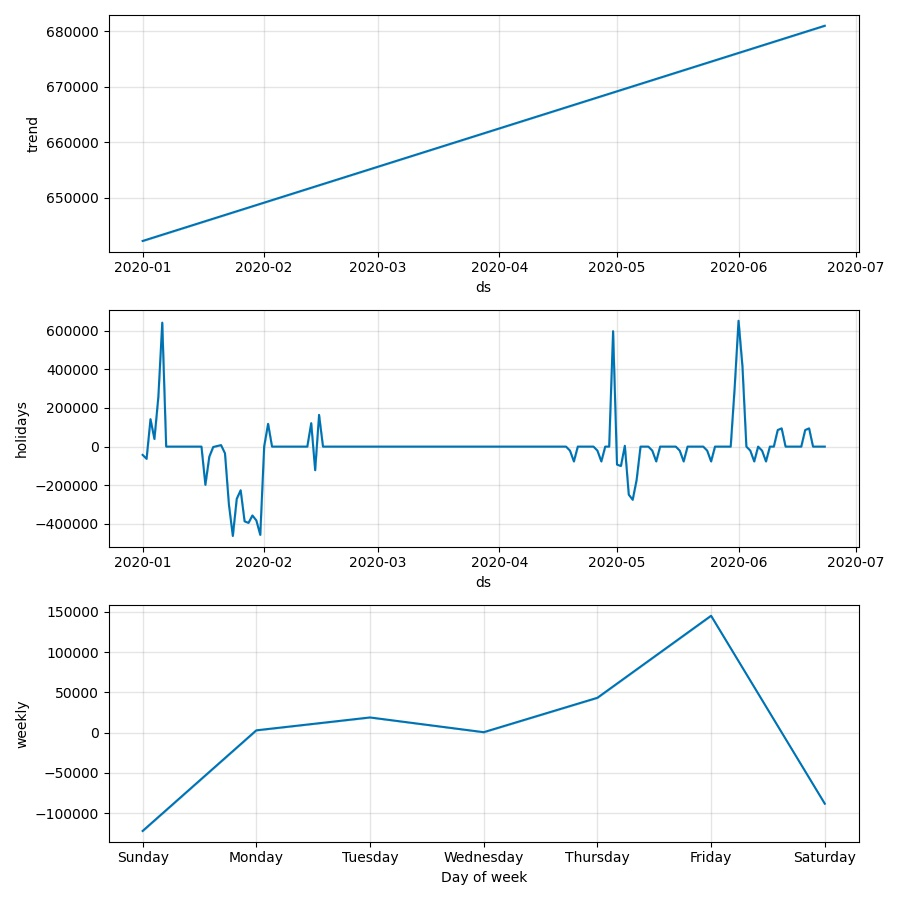
在Prophet中,認為holiday服從正態分佈,正態分佈的軸為ds。因此,prophet在預測節假日時會以正態分佈作為來估計預測值,但這個過程只是一個先驗估計的過程,如果模型後面發現這個holiday期間內不服從正態分佈,那麼模型將生硬的擬合該節假日。如**圖1-4**中所示,大家可以自行體會。
| 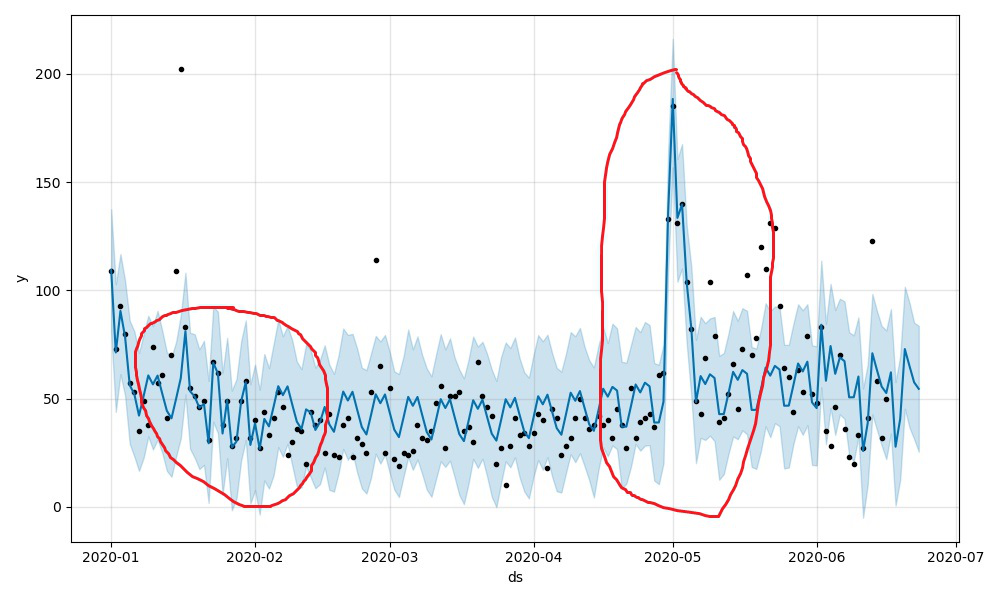 |
|--------------------------------------------|
| **圖1-4** |
holidays這個引數非常重要,對整個模型的影響極大,因此大家在構建這個引數時一定要給予相當的重視。
holidays在模型中是一個廣義的概念,不僅指節假日,也指活動日期,特殊事件日期等,因此大家在設定holidays時一定要確保完整,同時對於upper_window和lower_window的設定也應符合實際情況。
值得注意的是holidays的數量應儘量少,過多的holidays會對模型的過擬合現象加重,如果holidays的數量超過了整體資料的30%,工程師就應該考慮是否去掉一些影響較小的節假日。
### 1.4 其他引數
| 引數 | 描述 |
|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| mcmc_samples | 概率估計方式。如果為0將會採用最大後驗概率估計(MAP),如果為n(n\>0)將會以n個馬爾科夫取樣樣本做全貝葉斯推斷。 估計有同學有疑問,這些個概率估計的東西跟本模型有毛關係?大家仔細看下圖1-4中的藍色曲線和淡藍色區域,這其實就是預測結果,而取樣估計就是用來給出淡藍色區域的(uncertainty intervals),大家可以理解為置信區間或者是預測結果的上下限(雖然外國佬叫它‘不確定區間’)。 當mcmc_samples=0的時候,只有趨勢因素會存在這種估計,當mcmc_samples\>0時,週期性因素才會存在這種估計。 |
| interval_width | uncertainty intervals 的寬度,是一個浮點數,越大允許的uncertainty intervals範圍越大 |
| uncertainty_samples | 用來估計uncertainty intervals的取樣次數,如果設定為0或者False,就不會進行uncertainty intervals的估計,從而加快模型的訓練速度。 |
| stan_backend | CMDSTANPY或者PYSTAN。一般PYSTAN在linux上使用,cmdstanpy在微軟作業系統上使用。提示下在微軟作業系統上使用的同學,最好不要開啟馬爾科夫取樣(就是不要把mcmc_samples設成大於0),因為微軟作業系統上馬爾科夫取樣非常慢。 |
## 二 引數調優實戰
目前實際生產中,時序模型的訓練往往是數量驚人,因此如果依靠以往的指標和經驗調參以不大可行,所以只能採用機器尋參的方式。福布溼在這裡給大家介紹下常用的網格尋參。
在調參之前,最重要的是要確定好模型的評價指標。Prophet中內建的評價指標有傳統的mse、rmse、mae、mape、coverage。但這些不一定滿足在座各位的胃口,比如福布溼在部分模型中就使用了相對誤差的0.8分位數作為評價指標。
廢話不多說,直接上程式碼。
```
class ProphetTrain(ABC):
def __init__(self, name=None):
self.name = name
self.data: pd.DataFrame = None
self.params = {'holidays': holidays}
self.mape = np.inf
self.model = None
self.grid_search_params_path = None
self.predict_freq_num = 7
self.freq = 'd'
@abstractmethod
def _load_data(self):
"""
載入訓練及測試資料
:param rule: DataFrame.resample 中的rule
:return: 訓練及測試資料集,型別是pd.DataFrame
"""
pass
@property
def data_size(self):
if self.data is None:
self.data = self._load_data()
return self.data.shape[0] if self.data is not None else 0
def _cv_run(self):
if self.data_size < 14:
raise Exception("資料量不足,請保證資料航速大於14條")
self.model = Prophet(**self.params)
self.model.fit(self.data)
cv_result = cross_validation(self.model, f'{self.predict_freq_num}{self.freq}',
f'{self.predict_freq_num}{self.freq}')
return performance_metrics(cv_result, metrics=['mape'])['mape'][0]
def run(self, show: int = 0, retrain=False):
"""
根據當前引數生成模型
:param retrain: 是否根據當前引數重新生成模型
:param show:
0: 不儲存圖片及預測結果 也 不展示圖片
1: 展示圖片
2: 儲存圖片及預測結果
3: 儲存圖片及預測結果 也 展示圖片
:return:
"""
if self.data_size < 14:
raise Exception("資料量不足,請保證資料航速大於14條")
if retrain or self.model is None:
self.model = Prophet(**self.params)
self.model.fit(self.data)
future = self.model.make_future_dataframe(freq=self.freq,
periods=self.predict_freq_num) # 建立資料預測框架,資料粒度為天,預測步長為一年
forecast = self.model.predict(future)
if show & 0b01:
self.model.plot(forecast).show() # 繪製預測效果圖
self.model.plot_components(forecast).show() # 繪製成分趨勢圖
if show & 0b10:
y = forecast[['ds', 'yhat_lower', 'yhat_upper', 'yhat']].iloc[-self.predict_freq_num:]
y.to_csv(f'csv/{self.name}.csv', index=False)
self.model.plot(forecast).savefig(f"img/{self.name}-scatter.png") # 繪製預測效果圖
self.model.plot_components(forecast).savefig(f"img/{self.name}-trend.png") # 繪製成分趨勢圖
mape_score = np.abs(1 - forecast['yhat'].iloc[:self.data.shape[0]] / self.data['y'].values)
return np.quantile(mape_score, 0.8)
@property
def get_predict_df(self):
future = self.model.make_future_dataframe(freq=self.freq,
periods=self.predict_freq_num) # 建立資料預測框架,資料粒度為天,預測步長為一年
forecast = self.model.predict(future)
return forecast
def grid_search(self, use_cv=True, save_result=True):
"""
結合cv進行網格尋參,cv方式網格尋參很慢,一般建議先使用非網格方式,待引數調整完畢再使用cv驗證。
:param save_result:
:return:
"""
changepoint_range = [i / 10 for i in range(3, 10)]
seasonality_mode = ['additive', 'multiplicative']
seasonality_prior_scale = [0.05, 0.1, 0.5, 1, 5, 10, 15]
holidays_prior_scale = [0.05, 0.1, 0.5, 1, 5, 10, 15]
for sm in seasonality_mode:
for cp in changepoint_range:
for sp in seasonality_prior_scale:
for hp in holidays_prior_scale:
params = {
"seasonality_mode": sm,
"changepoint_range": cp,
"seasonality_prior_scale": sp,
"holidays_prior_scale": hp,
"holidays": holidays
}
score = self._cv_run() if use_cv else self.run()
if self.mape >