
Caffe簡明教程5:訓練你的第一個Caffe模型-MNIST分類器
如果你已經根據前面幾篇文章成功地編譯了Caffe,那麼現在是時候訓練你的第一個模型了。我準備借用Caffe官網的LeNet例子來寫這篇文章,您也可以訪問原始的文件:Training LeNet on MNIST with Caffe
Caffe在編譯完成之後,在caffe根目錄下有個
examples資料夾,裡面包含了很多Caffe的例子,其中就有MNIST。
1 準備資料
這次實驗使用的是MNIST資料集,相信做計算機視覺的朋友都知道,MNIST資料集是一個由Yann LeCun及其同事整理和開放出來的手寫數字圖片的資料集。我們將使用Caffe來訓練一個能夠識別手寫數字的模型。
首先我們需要下載MNIST資料集,執行caffe提供下載資料集的shell指令碼:
cd $CAFFE_ROOT # $CAFFE_ROOT是你caffe的根目錄
./data/mnist/get_mnist.sh # 此指令碼將下載MNIST資料集執行上面的指令碼之後,目錄$CAFFE_ROOT/data/mnist/下將出現以下四個檔案:
- train-images-idx3-ubyte(訓練樣本)
- train-labels-idx1-ubyte(訓練樣本標籤)
- t10k-images-idx3-ubyte(測試樣本)
- t10k-labels-idx1-ubyte(測試樣本標籤)
接著,我們需要把上面的資料轉換為Caffe需要的資料形式(lmdb資料庫形式,不瞭解lmdb的話可以暫時放在這裡,後面的文章會詳細解釋),執行Caffe提供的資料轉換指令碼,將MNIST資料集轉換為Caffe所需的lmdb檔案:
./examples/mnist/create_mnist.sh # 將MNIST資料集轉換為Caffe所需的lmdb檔案開啟目錄$CAFFE_ROOT/examples/mnist你會發現多了兩個資料夾:mnist_test_lmdb和mnist_train_lmdb,這兩個資料夾分別儲存了MNIST的以lmdb形式儲存的測試集和訓練集。
Trouble shooting
如果報錯wget或者gnuzip沒有安裝,那麼使用命令
sudo apt-get install wget gzip安裝它們。
wget用於從遠端伺服器獲取檔案,gzip用於解壓縮檔案。
2 LeNet: 用於MNIST資料集的分類模型
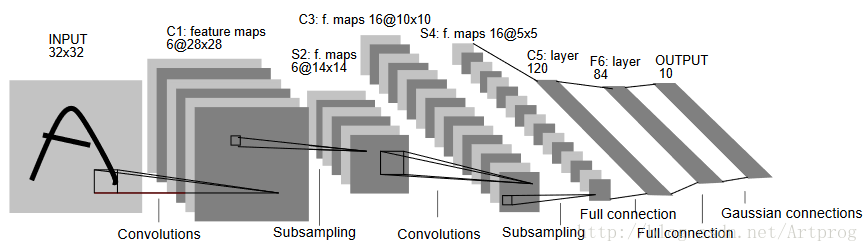
簡單介紹一下LeNet的結構:
- 輸入為32x32的灰度圖片
- 接著是一個卷積層
- 接著是一個取樣層(池化層)
- 又是一個卷積層
- 又是一個取樣層(池化層)
- 最後有一個10維的softmax輸出層(分別對應數字0-9)
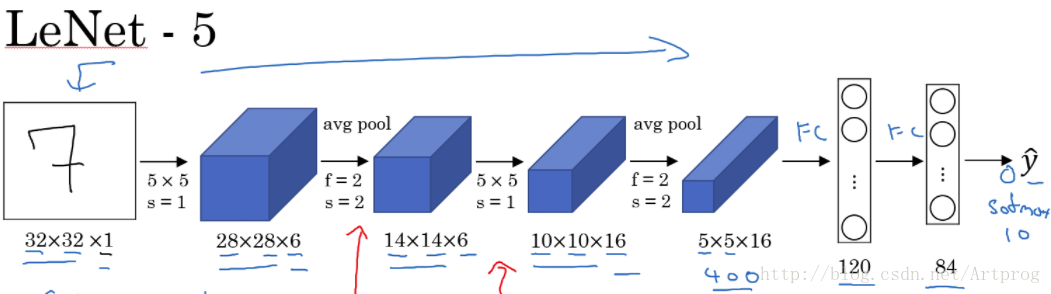
Andrew的圖可能更清晰一點:
OK,瞭解了LeNet的結構之後,我們來看看如何在Caffe中定義這網路。
3 在Caffe中定義LeNet
在Caffe中定義一個網路的結構可能是入門者的大難題,但是,只要我們靜下心仔細學習,你會發現在Caffe中定義一個網路其實是非常方便的,而且不需要我們寫任何C++或者Python程式碼。
在Caffe中,定義網路的結構需要用的到Google的Protocol Buffer。我們現在可以先不急著去深入瞭解Protocol Buffer,我們只需要知道,Protocal Buffer就是一種用來描述資料結構的簡單的語言(類似XML,但是比XML強大得多)。
幸運的是,Caffe的MNIST例子中已經有寫好了的LeNet網路結構,這個網路結構的定義在這裡:
$CAFFE_ROOT/examples/mnist/lenet_train_test.prototxt。
現在你可以開啟它檢視一下,看看裡面的內容是什麼,是不是很像C語言裡面的結構(struct)呀?看看自己能否看出來這些內容的含義。
注意:Protocol Buffer檔案一般都是以.prototxt結尾的文字檔案。
現在,我們複製lenet_train_test.prototxt中的內容,開啟網址:http://ethereon.github.io/netscope/#/editor,粘帖進去,然後按shift+enter,看看這個網路到底是什麼樣的。
看不出來沒關係,下面會仔細講解這個檔案的內容。另外,雖然這裡有個現成的LeNet結構定義檔案,但是光看它的內容是不能掌握Caffe的,你還是應該親自動手,在目錄$CAFFE_ROOT/examples/mnist下建立一個空白的檔案,並命名為my_lenet.prototext。下面我們就在my_lenet.prototext中親自定義一個LeNet。
3.1 給你的網路取個好聽的名字
第一步,當然得給網路取個好聽的名字,對吧?
用你喜歡的編輯器開啟你剛剛建立的檔案:$CAFFE_ROOT/examples/mnist/my_lenet.prototext。現在,該檔案是空的,我們在第一行寫上:
name: "LeNet"那麼取名這個事情就完成了。
3.2 網路當然要有輸入資料才能訓練
名字取好之後,在新的一行,我們來定義資料的輸入層,層(layer)這個概念在Caffe中是非常重要的,現在我們使用關鍵字layer來定義網路的一個層,這裡我們定義資料輸入層。在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "mnist" // 網路層的名字
type: "Data" // 網路層的型別,這裡Data指的是資料層,後面你還會看到其他型別的層
top: "data" // top屬性指明本層的資料將輸出到何處,這裡資料將儲存到data中
top: "label" // 資料的標籤將儲存在label中
include { // 此屬性用於確定在哪個過程中使用本層
phase: TRAIN // 只在訓練的過程中使用本層
}
transform_param { // 這個是網路層的資料轉換屬性,在Caffe的網路層中傳輸資料時,可以對資料進行處理
scale: 0.00390625 // 用於修改資料範圍,就是所有輸入的資料都乘以這個值,0.00390625=1/256
// 因為灰度圖是0~255,乘以scale,那麼所有的資料都在0~1之間,方便處理。
}
data_param { // 這個用於定義資料的一些屬性
source: "examples/mnist/mnist_train_lmdb" // 儲存訓練集的資料夾
backend: LMDB // 後端使用的是LMDB來儲存資料,在文章開頭講過Caffe的資料集形式
batch_size: 64 // 這個就不用解釋了吧。每一批輸入64個樣本
}
}上面的層定義是不是看起來很頭大,沒關係,不是還有註釋嘛,快看註釋(.prototxt檔案的註釋和C語言中的註釋方法相同)。
資料(data)和標籤(label):Caffe規定,最開始的資料層必須有一個名為data的資料輸出(top);另外還必須有一個名為label的標籤輸出(top)。Caffe從資料集中讀取資料後,就將樣本和標籤分別儲存在data和label中以便後面的層使用,這就是此例中Data層的作用。
data和label其實是Caffe內部的名為Blob的類的例項,現在可以把Blob當作陣列即可,後面會細講,現在不用深究。
剛剛我們定義了訓練資料的輸入層(include中的phase屬性指明什麼時候使用該層),現在我們要定義測試階段時資料的輸入層。在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST // 測試階段才使用本層
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb" // 包含測試集的資料夾
batch_size: 100 // 每批測試100個樣本
backend: LMDB
}
}總結一下,目前,我們定義了兩個layer,它們的型別都是Data,即資料層,都用於網路的輸入層。第一個用於訓練階段的資料輸入,第二個用於測試階段的資料輸入。
3.3 定義卷積層
定義了資料輸入層之後,我們需要對樣本進行卷積操作,那麼接下來就讓我們定義第一個卷積層,在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "conv1" // 該層的名字,可以自己隨便取
type: "Convolution" // 該層的型別為卷積層
bottom: "data" // bottom和top對應,bottom表示資料的輸入來源是什麼,本層的輸入為data
top: "conv1" // 執行卷積後,資料儲存到conv1層中
param {
lr_mult: 1 // 第一個param中的lr_mult用於設定weights的學習速率
// 與待會兒後面要設定的訓練學習速率的比值
}
param {
lr_mult: 2 // 第二個param中的lr_mult用於設定bias的學習速率
// 與待會兒後面要設定的訓練學習速率的比值,設定為2收斂得更好
}
convolution_param { // 設定卷積層的相關屬性
num_output: 20 // 輸出的通道數
kernel_size: 5 // 卷積核的大小
stride: 1 // 步長
weight_filler { // weights的初始化的方法
type: "xavier" // 使用xavier初始化演算法,此方法可以根據網路的規模自動初始化合適的引數值
}
bias_filler { // bias的初始化方法
type: "constant" // 使用常數初始化偏置項,預設初始化為0
}
}
}上面的註釋已經比較清楚了,說一下lr_mult,待會兒定義好網路結構之後,我們還需要定義一個訓練檔案,裡面會設定網路的學習速率,這裡的lr_mult即是這個學習速率的倍數。
3.4 定義池化層
在LeNet中,第一個卷積層後面是池化層,在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "pool1"
type: "Pooling" // 型別為Pooling,即池化層
bottom: "conv1" // 該層的輸入來自前面的卷積層conv1
top: "pool1" // 輸出儲存在本層中
pooling_param { // 池化層的引數
pool: MAX // 池化方法(取樣方法)
kernel_size: 2 // 核大小
stride: 2 // 步長
}
}池化層很簡單對不對。
3.5 第二個卷積層和池化層
上面的看懂了,接下來就不難啦。我們接著新增第二個卷積層,以及該卷積層後面的池化層。在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer { // 定義第二個卷積層
name: "conv2"
type: "Convolution"
bottom: "pool1" // 輸入來自前面的第一個池化層
top: "conv2" // 輸出儲存到本層
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50 // 輸出通道數為50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer { // 定義第二個池化層
name: "pool2"
type: "Pooling"
bottom: "conv2" // 輸入來自上面的第二卷積層
top: "pool2" // 輸出儲存到本層
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}好了,目前我們已經定義了LeNet的資料輸入層、卷積層以及池化層。還剩下兩個全連線層和一個Softmax輸出層。
3.6 定義全連線層
全連線層即Fully Connected Layer,一般簡單地縮寫為FC。全連線層很簡單,就是標準神經網路中的網路層。在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "ip1"
type: "InnerProduct" // InnerProduct即Caffe中的全連線層,引數和輸入做內積
bottom: "pool2" // 輸入來自前面的池化層
top: "ip1" // 輸出儲存在本層
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param { // 全連線層的引數
num_output: 500 // 輸出神經元個數
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}很簡單吧。我們知道標準神經網路中都有啟用函式,LeNet原始論文使用的是Sigmoid,但是實踐證明ReLU效果更佳。所以我們要對上面的全連線層計算啟用值。
3.6 定義ReLU層
在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "relu1"
type: "ReLU" // 該層型別為ReLU
bottom: "ip1" // 輸入為之前的全連線層
top: "ip1" // 輸出儲存在該全連線層中(覆蓋之前的值)
}3.7 第二個全連線層
下面是第二個全連線層,在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10 // 輸出神經元的數量為10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}到此,LeNet的主體已經定義完成了。但是我們還需要定義loss,以及用於計算準確率的層。Caffe正好提供了各種各樣的層供我們使用。
3.8 定義用於計算準確率的層
下面的層能夠在測試階段,計算模型的準確率。在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "accuracy"
type: "Accuracy" // 該層的型別為Accuracy,計算準確率
bottom: "ip2" // 第一個輸入為之前的全連線層
bottom: "label" // 第二個輸入為樣本的標籤
top: "accuracy" // 輸出儲存在本層中
include {
phase: TEST // 只在測試階段使用本層
}
}3.9 定義loss
馬上就要大功告成了,定義LeNet的最後一步,即定義loss。Caffe可以根據loss自動計算梯度,並進行反向傳播。在檔案$CAFFE_ROOT/examples/mnist/my_lenet.prototext中接著新增如下內容:
layer {
name: "loss"
type: "SoftmaxWithLoss" // 該層的型別為Softmax Loss
bottom: "ip2" // 第一個輸入為上面的第二個全連線層
bottom: "label" // 第二個輸入為樣本標籤
top: "loss" // 輸出儲存在本層中
}Nice!整個LeNet已經定義完了。下面是檔案my_lenet.prototext的完整內容,看看自己少了什麼沒有,沒有註釋,看自己能不能看懂,有疑惑一定要盡情地google之:
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}沒問題了?那麼我們還需要寫一個solver,即網路的解法,或者說我們要告訴Caffe如何去訓練LeNet。
4 定義LeNet的解法檔案
Caffe給的例子中已經寫了,其內容如下,強烈推薦你自己試著寫一遍。檔案$CAFFE_ROOT/examples/mnist/lenet_solver.prototxt的內容如下:
# The train/test net protocol buffer definition
net: "examples/mnist/my_lenet.prototxt" # 這裡換成我們定義的網路結構檔案
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100 # 每次測試執行100次前向傳播
# Carry out testing every 500 training iterations.
test_interval: 500 # 訓練每迭代500次就測試一次
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01 # 基本學習速率
momentum: 0.9 # 衝量梯度下降引數
weight_decay: 0.0005 # 正則化引數
# The learning rate policy
lr_policy: "inv" # 學習速率的更新模式
# inv: return base_lr * (1 + gamma * iter) ^ (- power) 此方法可逐漸降低學習速率,防止發散
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100 # 100次顯示一次當前的loss
# The maximum number of iterations
max_iter: 10000 # 最多迭代10000次
# snapshot intermediate results
snapshot: 5000 # 5000次迭代儲存一次模型
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: GPU # 使用GPU訓練上面的註釋解釋了這些設定的含義。總結一下,在Caffe中想要訓練一個網路,必須提供下面這些東西:
- 資料(LMDB方式儲存)
- 網路結構的定義
- 網路的solver(其中有個引數net的值即為網路結構定義檔案)
5 訓練LeNet模型
訓練模型非常簡單。編譯Caffe時已經在目錄$CAFFE_ROOT/build/tools目錄下生成了一個名為caffe的可執行檔案,它就是我們用於訓練網路的工具,輸入如下命令進行訓練:
$ cd $CAFFE_ROOT
$ ./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt當然你也可以使用caffe寫好的訓練指令碼(內容和上面的差不多):
$ ./examples/mnist/train_lenet.sh然後你就會看到刷拉拉地一行行訓練資訊不停地顯示出來。MNIST資料集不大,很快就能訓練完成。
下一篇文章:待續