
解Bug之路-Nginx 502 Bad Gateway
阿新 • • 發佈:2020-07-31
# 解Bug之路-Nginx 502 Bad Gateway
## 前言
事實證明,讀過Linux核心原始碼確實有很大的好處,尤其在處理問題的時刻。當你看到報錯的那一瞬間,就能把現象/原因/以及解決方案一股腦的在腦中閃現。甚至一些邊邊角角的現象都能很快的反應過來是為何。筆者讀過一些Linux TCP協議棧的原始碼,就在解決下面這個問題的時候有一種非常流暢的感覺。
## Bug現場
首先,這個問題其實並不難解決,但是這個問題引發的現象倒是挺有意思。先描述一下現象吧,
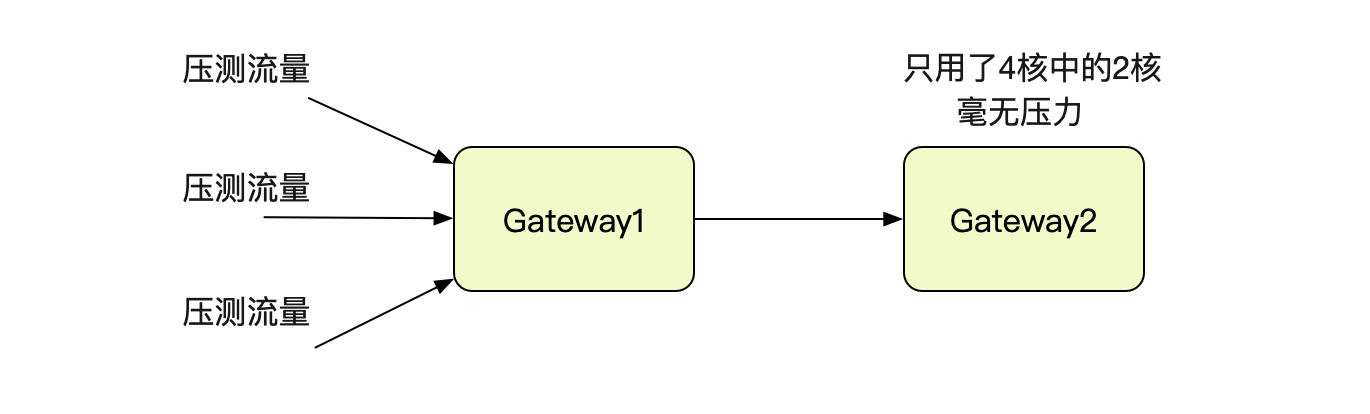
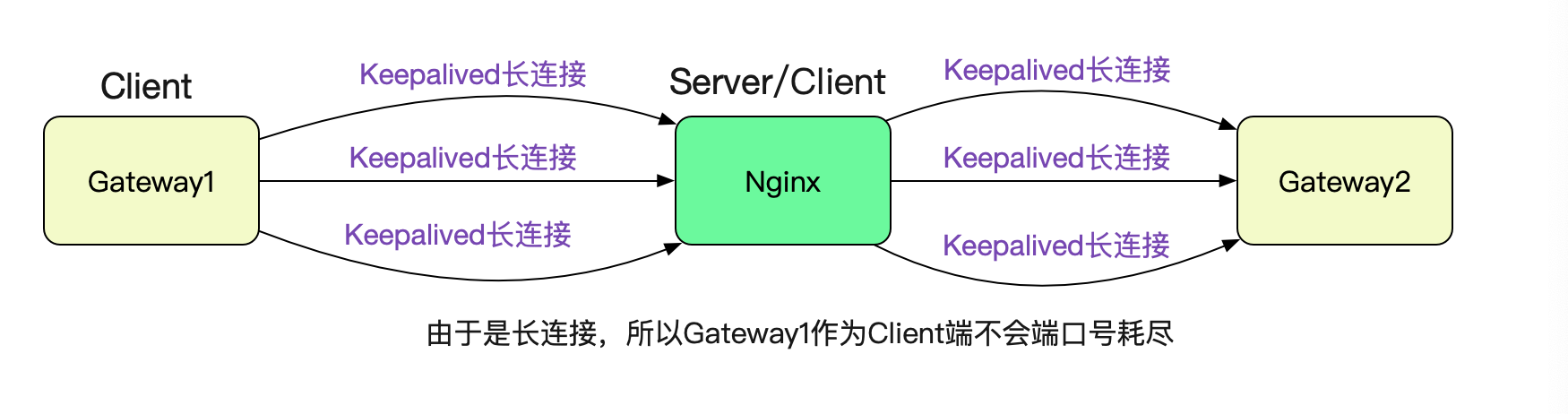
筆者要對自研的dubbo協議隧道閘道器進行壓測(這個閘道器的設計也挺有意思,準備放到後面的部落格裡面)。先看下壓測的拓撲吧:
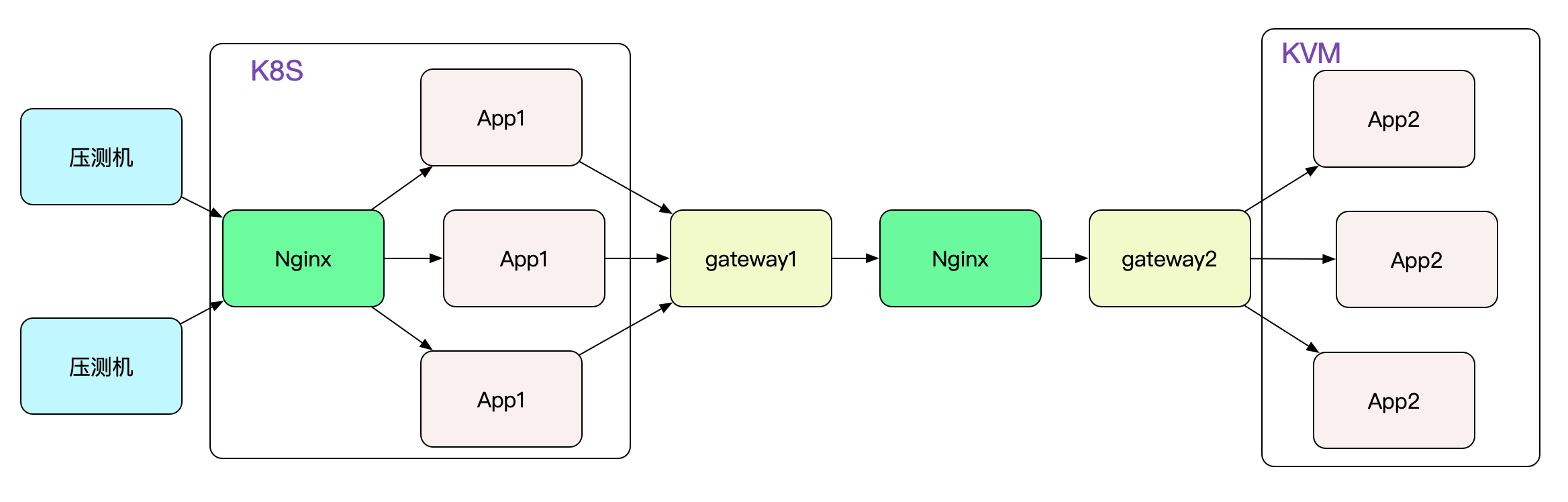
為了壓測筆者gateway的單機效能,兩端僅僅各保留一臺閘道器,即gateway1和gateway2。壓到一定程度就開始報錯,導致壓測停止。很自然的就想到,閘道器扛不住了。
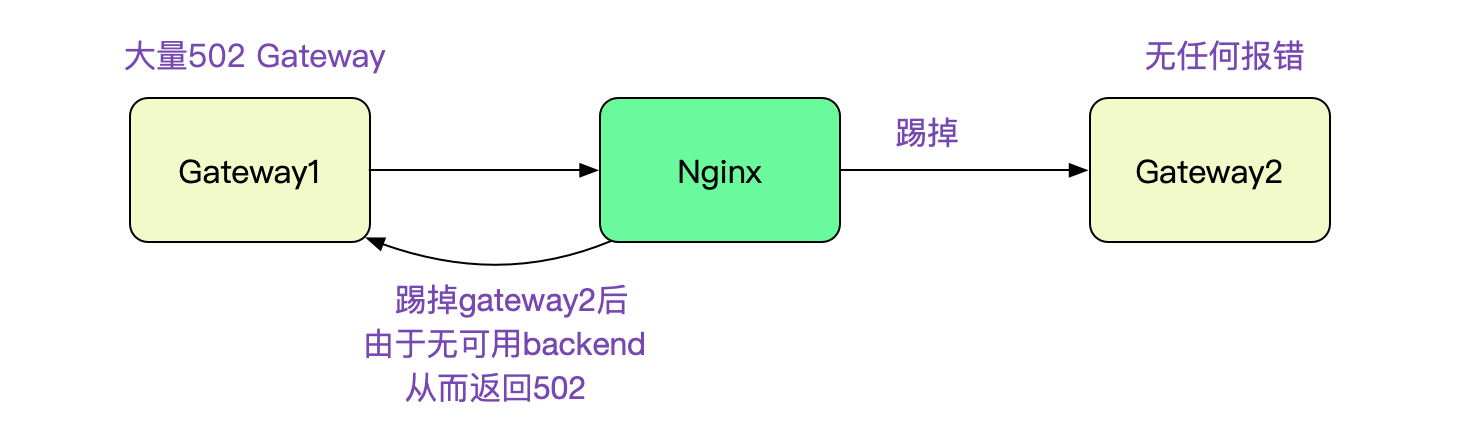
## 閘道器的情況
去Gateway2的機器上看了一下,沒有任何報錯。而Gateway1則有大量的502報錯。502是Bad Gateway,Nginx的經典報錯,首先想到的就是Gateway2不堪重負被Nginx在Upstream中踢掉。
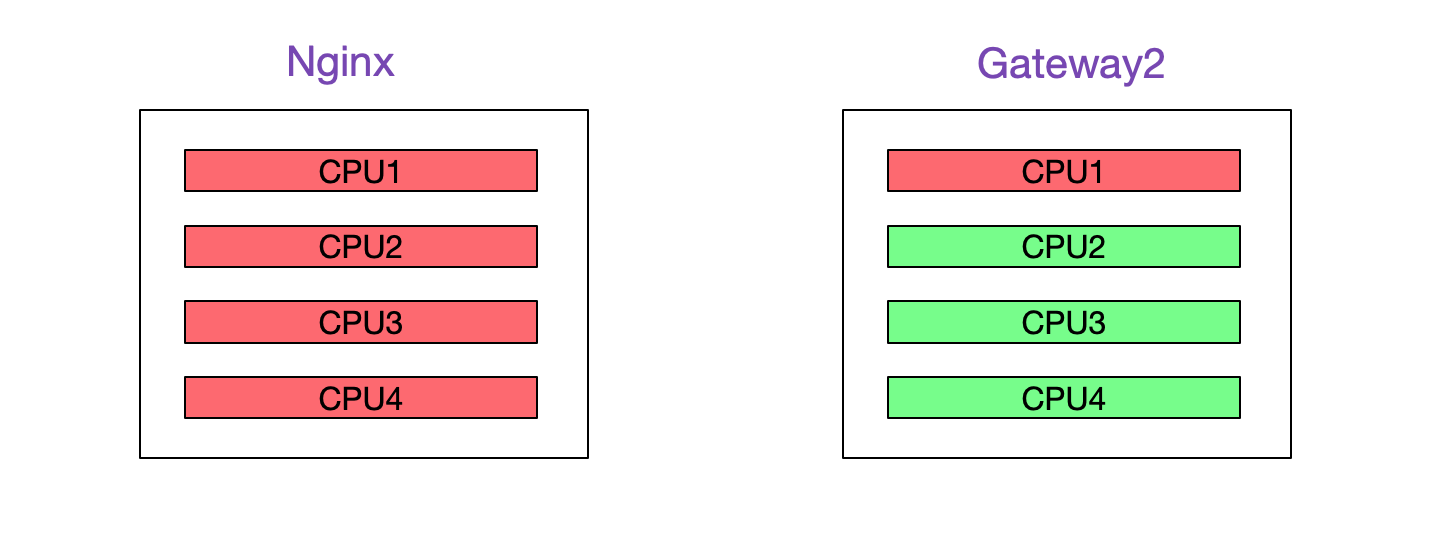
那麼,就先看看Gateway2的負載情況把,查了下監控,發現Gateway2在4核8G的機器上只用了一個核,完全看不出來有瓶頸的樣子,難道是IO有問題?看了下小的可憐的網絡卡流量打消了這個猜想。
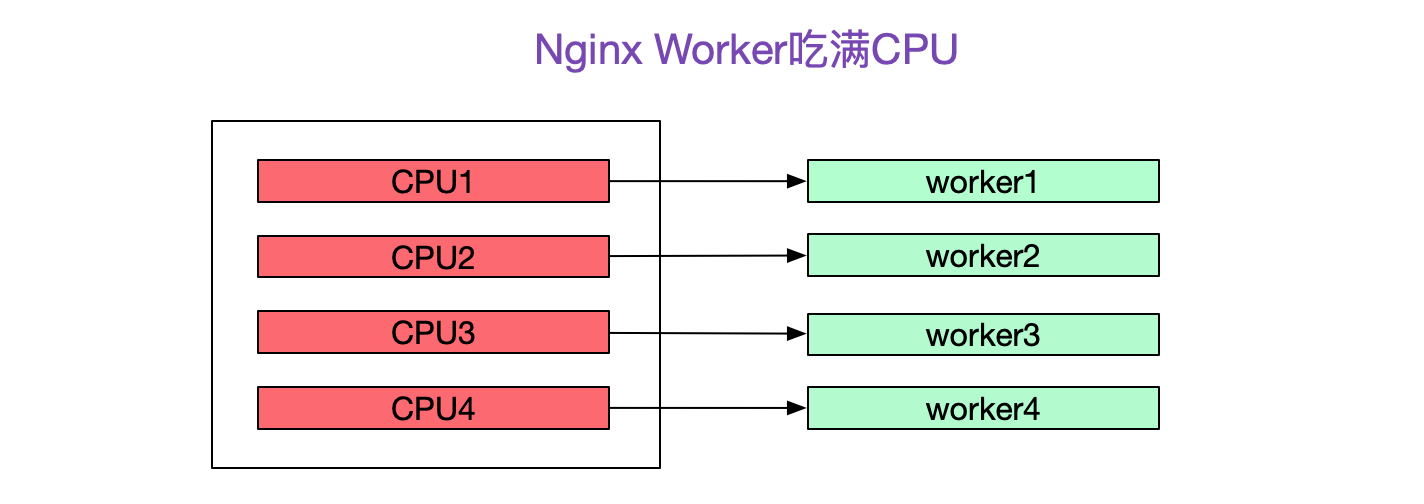
## Nginx所在機器CPU利用率接近100%
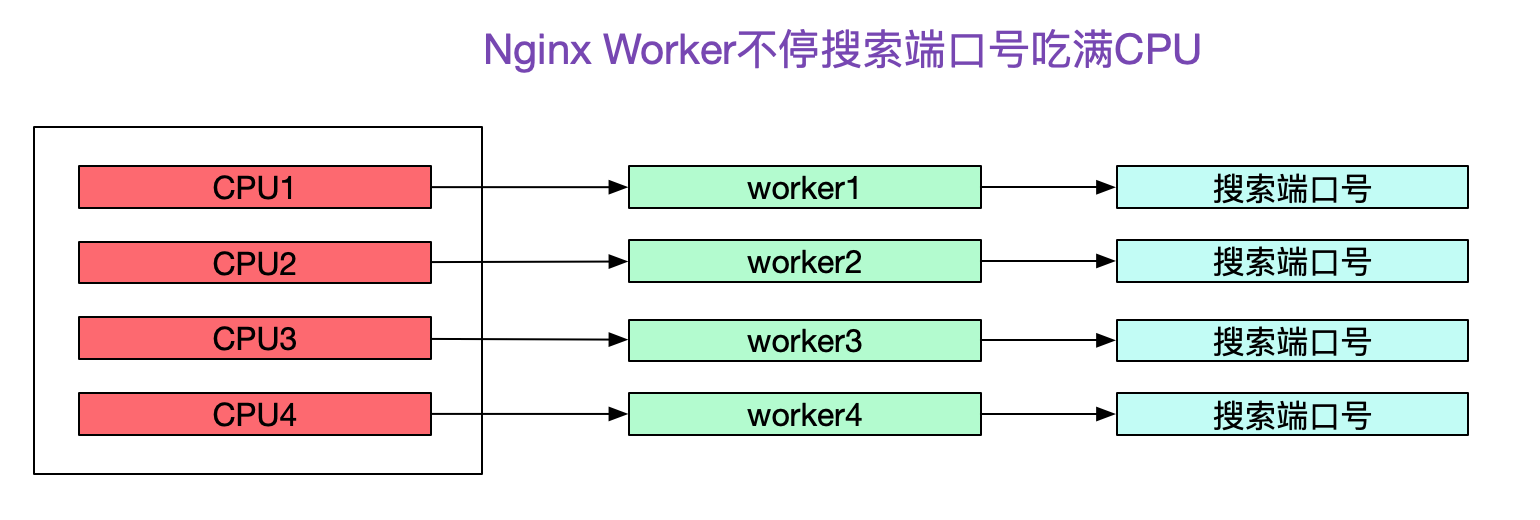
這時候,發現一個有意思的現象,Nginx確用滿了CPU!
再次壓測,去Nginx所在機器上top了一下,發現Nginx的4個Worker分別佔了一個核把CPU吃滿-_-!
什麼,號稱效能強悍的Nginx竟然這麼弱,說好的事件驅動\epoll邊沿觸發\純C打造的呢?一定是用的姿勢不對!
## 去掉Nginx直接通訊毫無壓力
既然猜測是Nginx的瓶頸,就把Nginx去掉吧。Gateway1和Gateway2直連,壓測TPS裡面就飆升了,而且Gateway2的CPU最多也就吃了2個核,毫無壓力。
## 去Nginx上看下日誌
由於Nginx機器許可權並不在筆者手上,所以一開始沒有關注其日誌,現在就聯絡一下對應的運維去看一下吧。在accesslog裡面發現了大量的502報錯,確實是Nginx的。又看了下錯誤日誌,發現有大量的
```
Cannot assign requested address
```
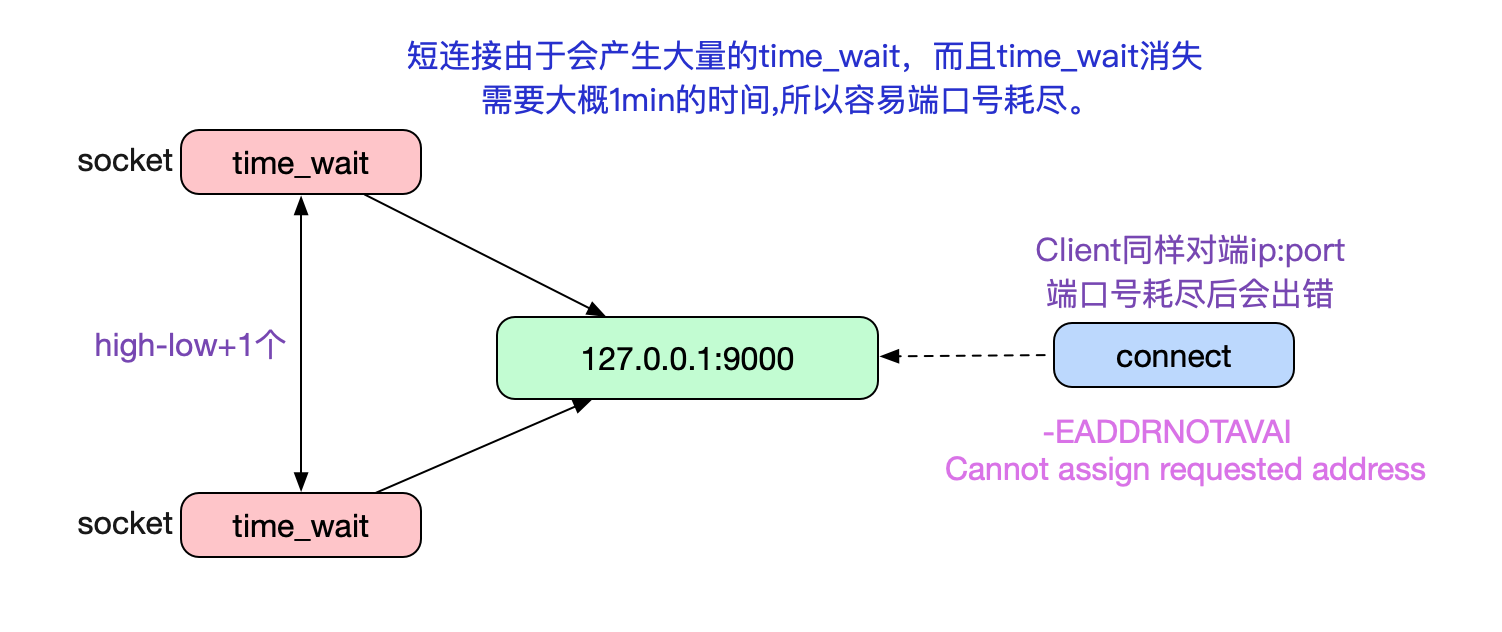
由於筆者讀過TCP原始碼,一瞬間就反應過來,是埠號耗盡了!由於Nginx upstream和後端Backend預設是短連線,所以在大量請求流量進來的時候回產生大量TIME\_WAIT的連線。
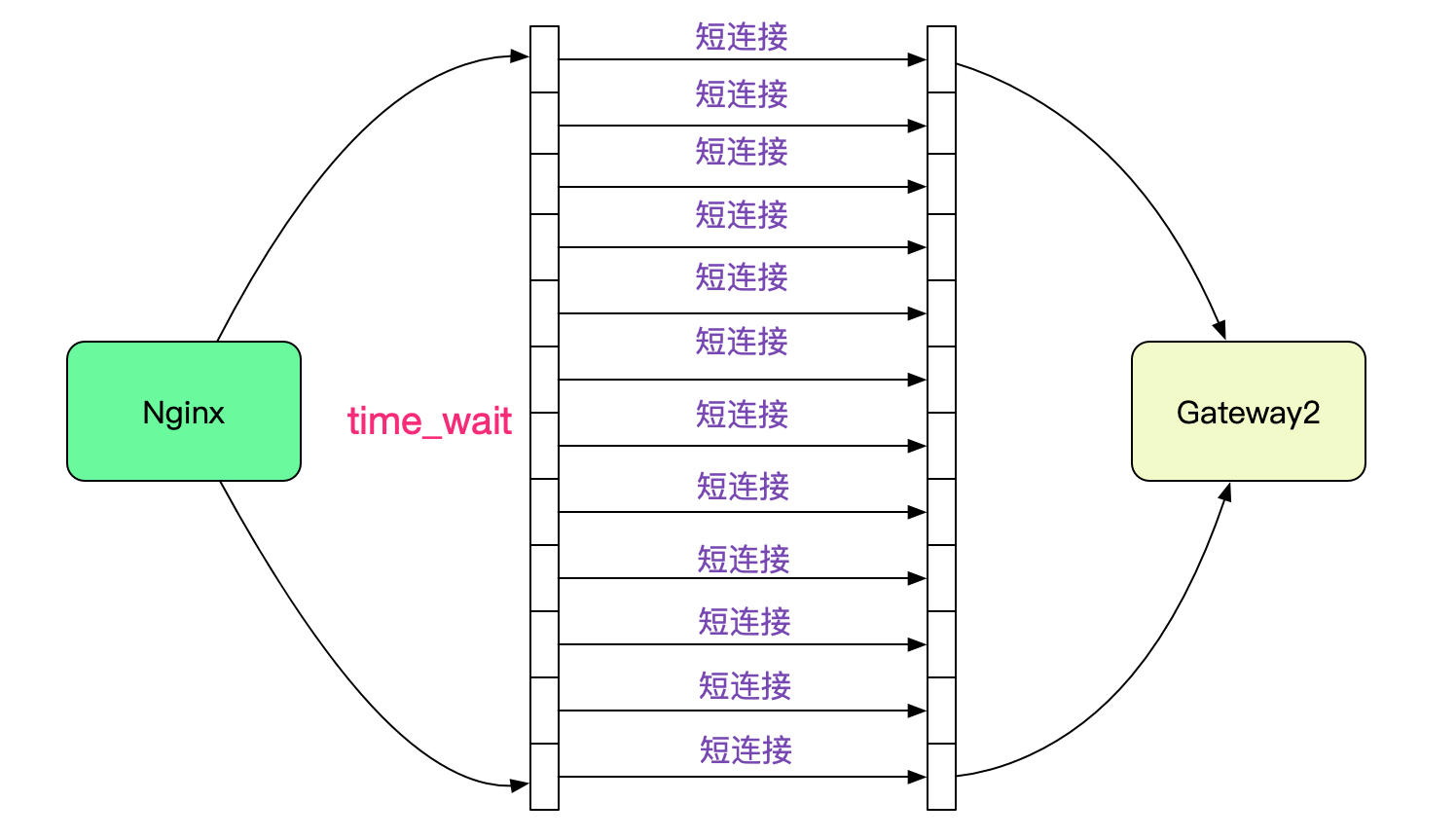
而這些TIME\_WAIT是佔據埠號的,而且基本要1分鐘左右才能被Kernel回收。
```
cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000
```
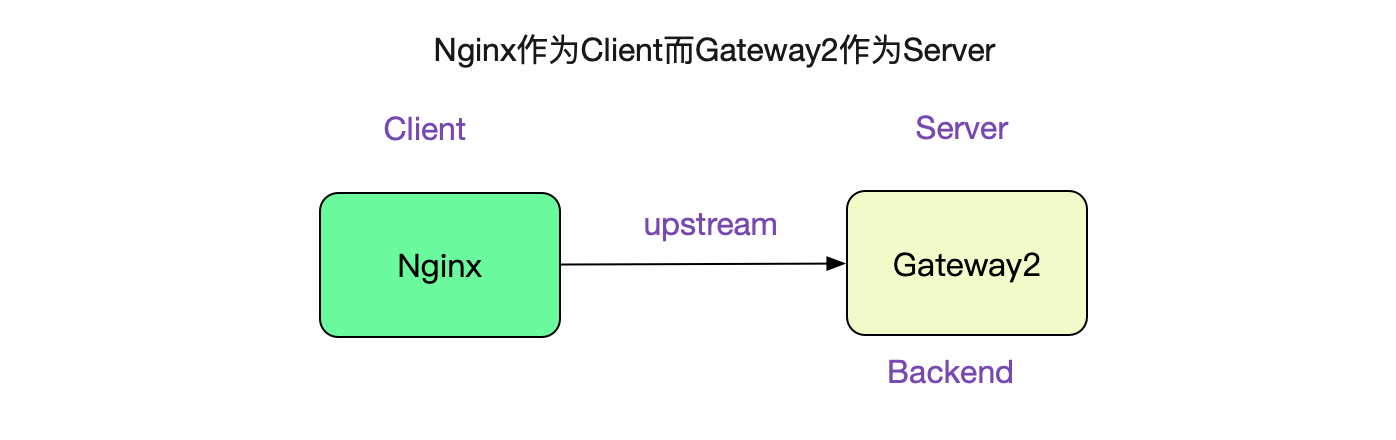
也就是說,只要一分鐘之內產生28232(61000-32768)個TIME\_WAIT的socket就會造成埠號耗盡,也即470.5TPS(28232/60),只是一個很容易達到的壓測值。事實上這個限制是Client端的,Server端沒有這樣的限制,因為Server埠號只有一個8080這樣的有名埠號。而在
upstream中Nginx扮演的就是Client,而Gateway2就扮演的是Nginx
## 為什麼Nginx的CPU是100%
而筆者也很快想明白了Nginx為什麼吃滿了機器的CPU,問題就出來埠號的搜尋過程。
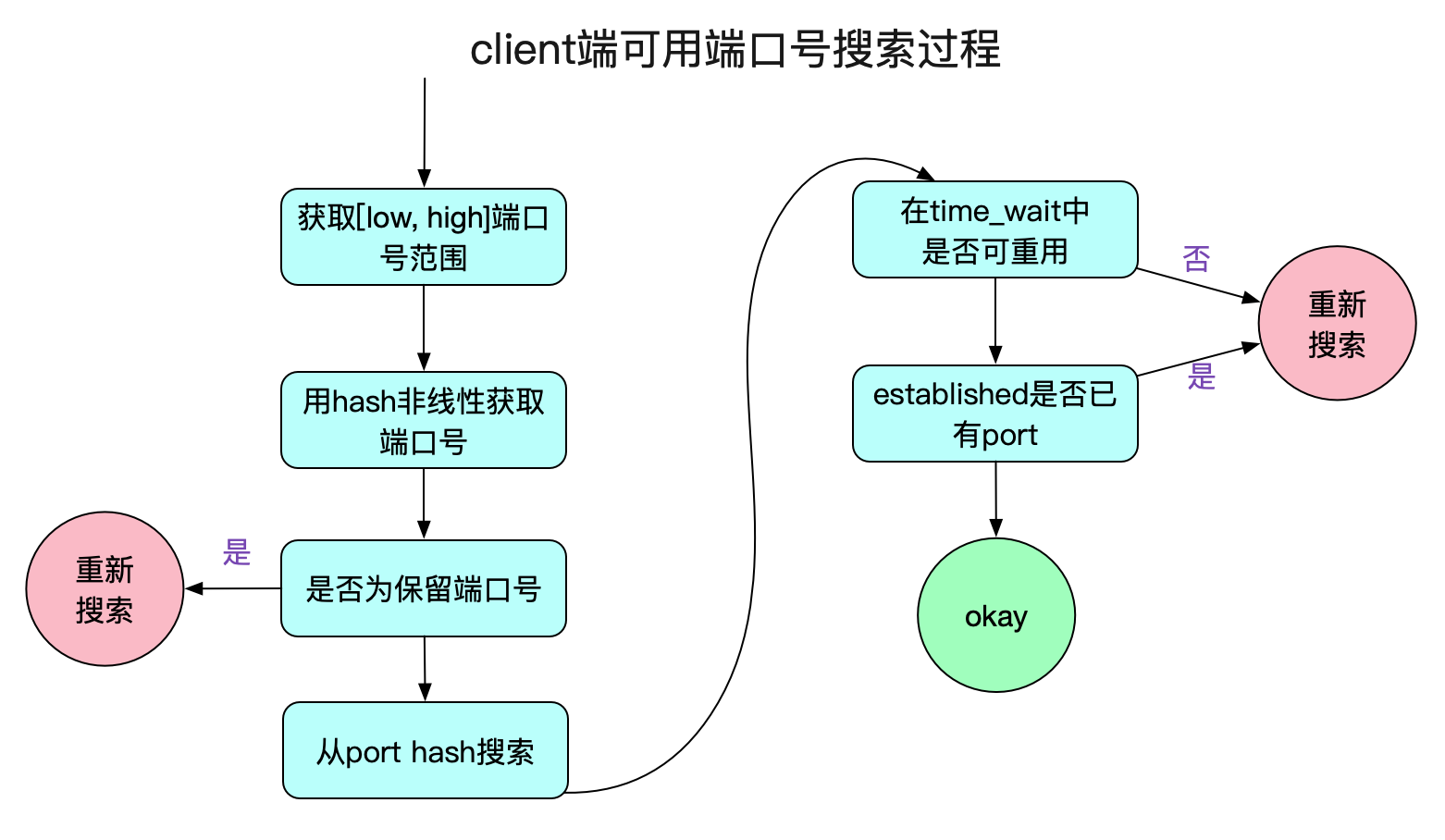
讓我們看下最耗效能的一段函式:
```
int __inet_hash_connect(...)
{
// 注意,這邊是static變數
static u32 hint;
// hint有助於不從0開始搜尋,而是從下一個待分配的埠號搜尋
u32 offset = hint + port_offset;
.....
inet_get_local_port_range(&low, &high);
// 這邊remaining就是61000 - 32768
remaining = (high - low) + 1
......
for (i = 1; i <= remaining; i++) {
port = low + (i + offset) % remaining;
/* port是否佔用check */
....
goto ok;
}
.......
ok:
hint += i;
......
}
```
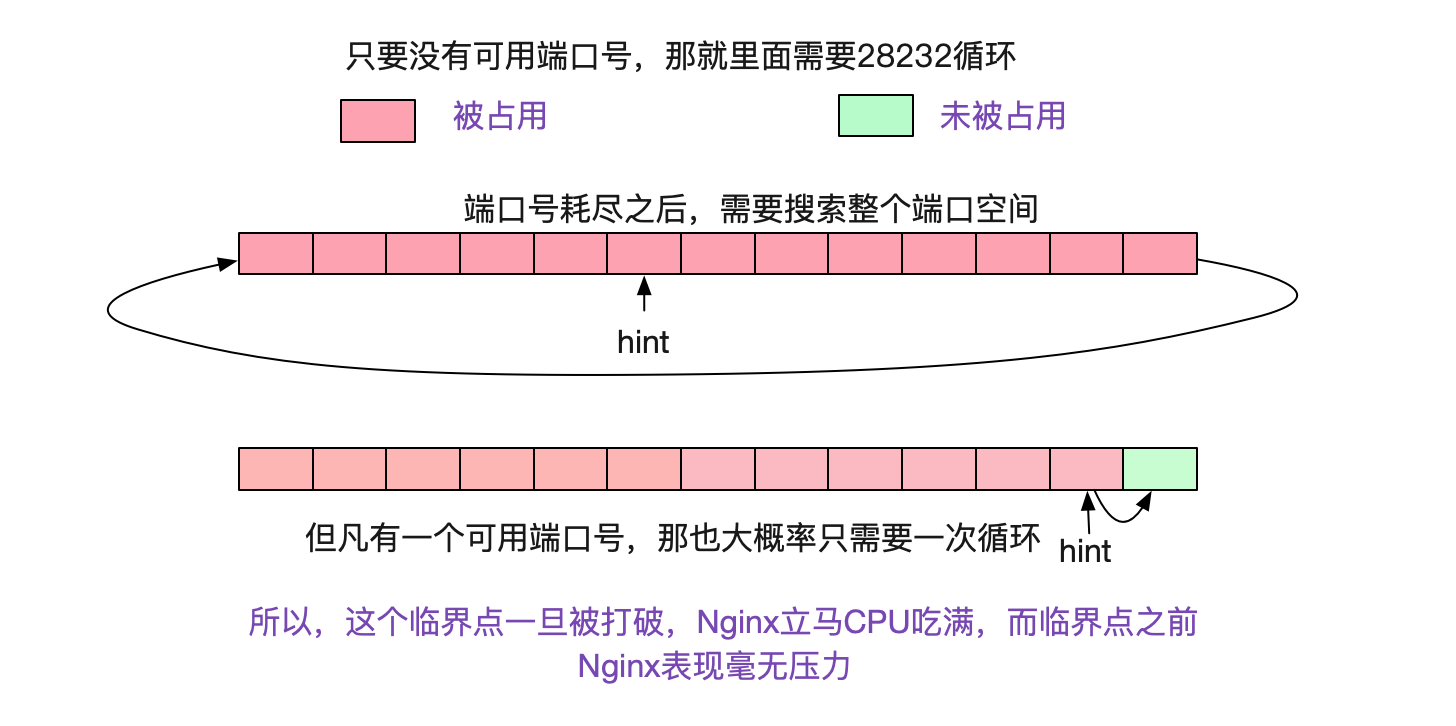
看上面那段程式碼,如果一直沒有埠號可用的話,則需要迴圈remaining次才能宣告埠號耗盡,也就是28232次。而如果按照正常的情況,因為有hint的存在,所以每次搜尋從下一個待分配的埠號開始計算,以個位數的搜尋就能找到埠號。如下圖所示:
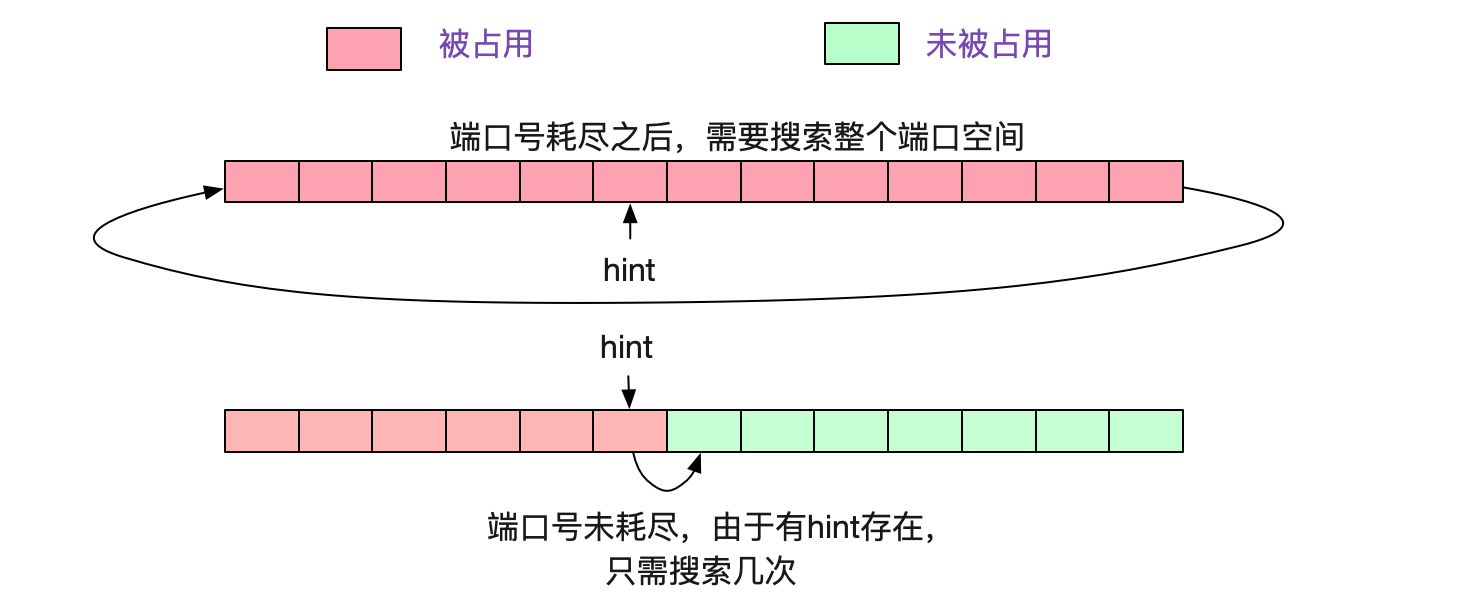
所以當埠號耗盡後,Nginx的Worker程序就沉浸在上述for迴圈中不可自拔,把CPU吃滿。
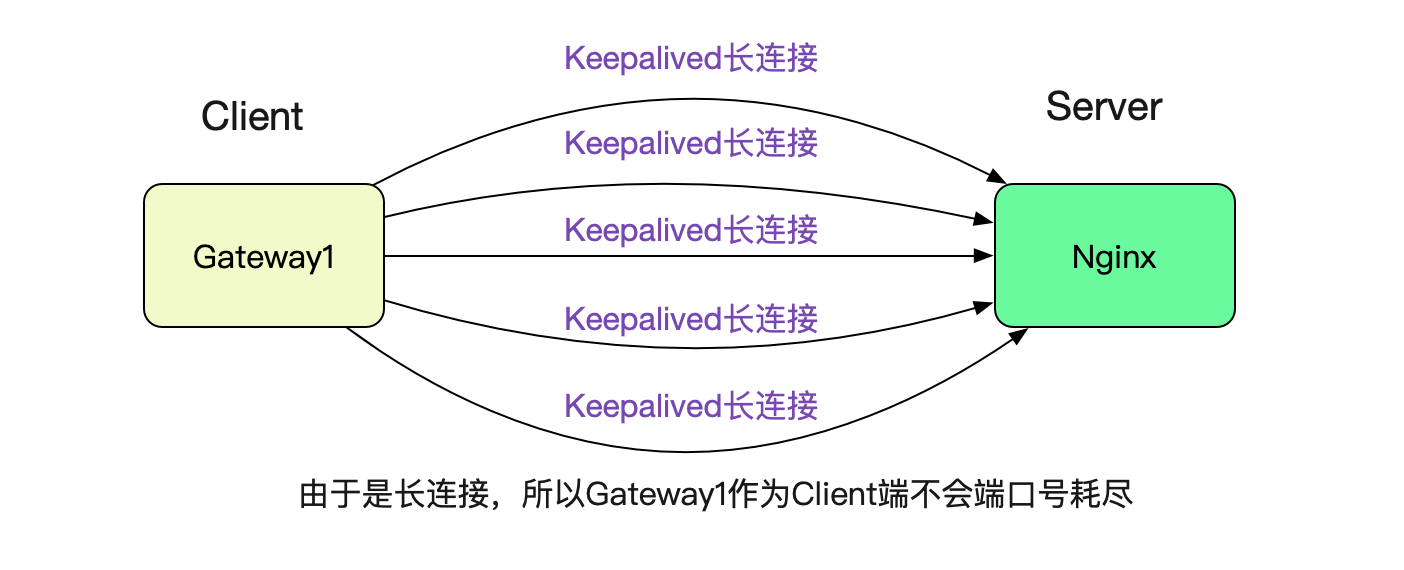
## 為什麼Gateway1呼叫Nginx沒有問題
很簡單,因為筆者在Gateway1呼叫Nginx的時候設定了Keepalived,所以採用的是長連線,就沒有這個埠號耗盡的限制。
## Nginx 後面有多臺機器的話
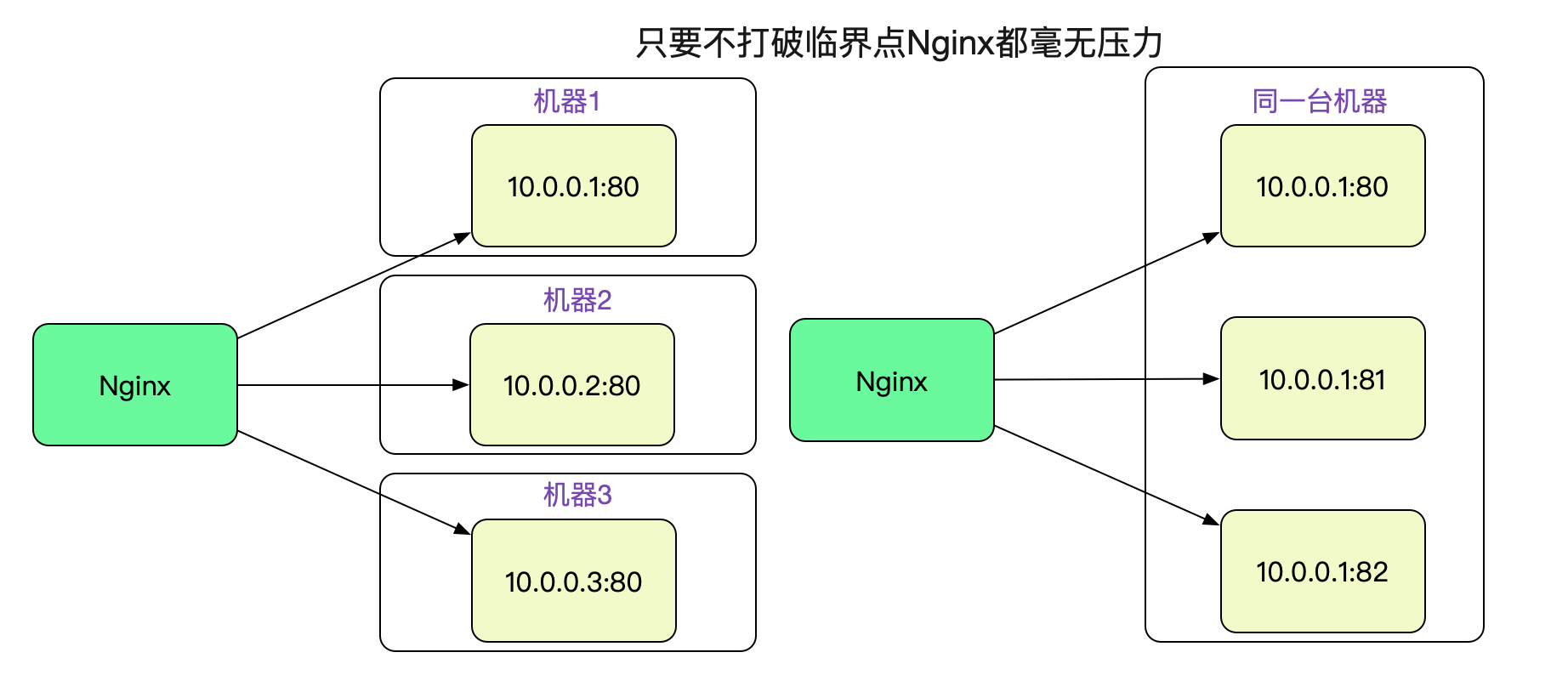
由於是因為埠號搜尋導致CPU 100%,而且但凡有可用埠號,因為hint的原因,搜尋次數可能就是1和28232的區別。
因為埠號限制是針對某個特定的遠端server:port的。
所以,只要Nginx的Backend有多臺機器,甚至同一個機器上的多個不同埠號,只要不超過臨界點,Nginx就不會有任何壓力。
## 把埠號範圍調大
比較無腦的方案當然是把埠號範圍調大,這樣就能抗更多的TIME\_WAIT。同時將tcp\_max\_tw\_bucket調小,tcp\_max\_tw\_bucket是kernel中最多存在的TIME\_WAIT數量,只要port範圍 - tcp\_max\_tw\_bucket大於一定的值,那麼就始終有port埠可用,這樣就可以避免再次到調大臨界值得時候繼續擊穿臨界點。
```
cat /proc/sys/net/ipv4/ip_local_port_range
22768 61000
cat /proc/sys/net/ipv4/tcp_max_tw_buckets
20000
```
## 開啟tcp\_tw\_reuse
這個問題Linux其實早就有了解決方案,那就是tcp\_tw\_reuse這個引數。
```
echo '1' > /proc/sys/net/ipv4/tcp_tw_reuse
```
事實上TIME\_WAIT過多的原因是其回收時間竟然需要1min,這個1min其實是TCP協議中規定的2MSL時間,而Linux中就固定為1min。
```
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
```
2MSL的原因就是排除網路上還殘留的包對新的同樣的五元組的Socket產生影響,也就是說在2MSL(1min)之內重用這個五元組會有風險。為了解決這個問題,Linux就採取了一些列措施防止這樣的情況,使得在大部分情況下1s之內的TIME\_WAIT就可以重用。下面這段程式碼,就是檢測此TIME\_WAIT是否重用。
```
__inet_hash_connect
|->__inet_check_established
static int __inet_check_established(......)
{
......
/* Check TIME-WAIT sockets first. */
sk_nulls_for_each(sk2, node, &head->twchain) {
tw = inet_twsk(sk2);
// 如果在time_wait中找到一個match的port,就判斷是否可重用
if (INET_TW_MATCH(sk2, net, hash, acookie,
saddr, daddr, ports, dif)) {
if (twsk_unique(sk, sk2, twp))
goto unique;
else
goto not_unique;
}
}
......
}
```
而其中的核心函式就是twsk\_unique,它的判斷邏輯如下:
```
int tcp_twsk_unique(......)
{
......
if (tcptw->tw_ts_recent_stamp &&
(twp == NULL || (sysctl_tcp_tw_reuse &&
get_seconds() - tcptw->tw_ts_recent_stamp > 1))) {
// 對write_seq設定為snd_nxt+65536+2
// 這樣能夠確保在資料傳輸速率<=80Mbit/s的情況下不會被迴繞
tp->write_seq = tcptw->tw_snd_nxt + 65535 + 2
......
return 1;
}
return 0;
}
```
上面這段程式碼邏輯如下所示:
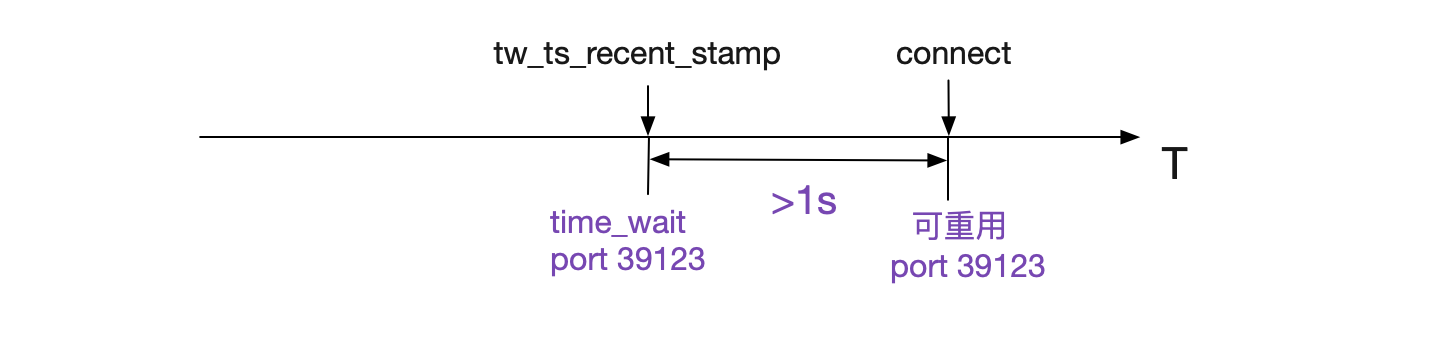
在開啟了tcp\_timestamp以及tcp\_tw\_reuse的情況下,在Connect搜尋port時只要比之前用這個port的TIME\_WAIT狀態的Socket記錄的最近時間戳>1s,就可以重用此port,即將之前的1分鐘縮短到1s。同時為了防止潛在的序列號衝突,直接將write\_seq加上在65537,這樣,在單Socket傳輸速率小於80Mbit/s的情況下,不會造成序列號重疊(衝突)。
同時這個tw\_ts\_recent\_stamp設定的時機如下圖所示:
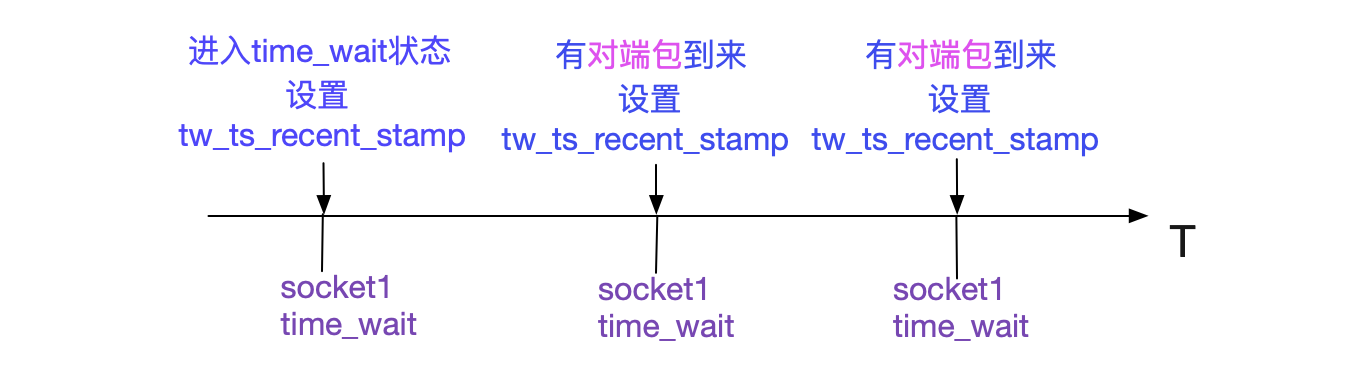
所以如果Socket進入TIME\_WAIT狀態後,如果一直有對應的包發過來,那麼會影響此TIME\_WAIT對應的port是否可用的時間。
開啟了這個引數之後,由於從1min縮短到1s,那麼Nginx單臺對單Upstream可承受的TPS就從原來的470.5TPS(28232/60)一躍提升為28232TPS,增長了60倍。
如果還嫌效能不夠,可以配上上面的埠號範圍調大以及tcp\_max\_tw\_bucket調小繼續提升tps,不過tcp\_max\_tw\_bucket調小可能會有序列號重疊的風險,畢竟Socket不經過2MSL階段就被重用了。
## 不要開啟tcp\_tw\_recycle
開啟tcp\_tw\_recyle這個引數會在NAT環境下造成很大的影響,建議不開啟。
# Nginx upstream改成長連線
事實上,上面的一系列問題都是由於Nginx對Backend是短連線導致。
Nginx從 1.1.4 開始,實現了對後端機器的長連線支援功能。在Upstream中這樣配置可以開啟長連線的功能:
```
upstream backend {
server 127.0.0.1:8080;
# It should be particularly noted that the keepalive directive does not limit the total number of connections to upstream servers that an nginx worker process can open. The connections parameter should be set to a number small enough to let upstream servers process new incoming connections as well.
keepalive 32;
keepalive_timeout 30s; # 設定後端連線的最大idle時間為30s
}
```
這樣前端和後端都是長連線,大家又可以愉快的玩耍了。
# 由此產生的風險點
由於對單個遠端ip:port耗盡會導致CPU吃滿這種現象。所以在Nginx在配置Upstream時候需要格外小心。假設一種情況,PE擴容了一臺Nginx,為防止有問題,就先配一臺Backend看看情況,這時候如果量比較大的話擊穿臨界點就會造成大量報錯(而應用本身確毫無壓力,畢竟臨界值是470.5TPS(28232/60)),甚至在同Nginx上的非此域名的請求也會因為CPU被耗盡而得不到響應。多配幾臺Backend/開啟tcp\_tw\_reuse或許是不錯的選擇。
# 總結
應用再強大也還是承載在核心之上,始終逃不出Linux核心的樊籠。所以對於Linux核心本身引數的調優還是非常有意義的。如果讀過一些核心原始碼,無疑對我們排查線上問題有著很大的助力,同時也能指導我們避過一些坑!
## 公眾號
關注筆者公眾號,獲取更多幹貨文章:
