
解Bug之路-中介軟體"SQL重複執行"
阿新 • • 發佈:2020-06-28
## 前言
我們的分庫分表中介軟體在線上運行了兩年多,到目前為止還算穩定。在筆者將精力放在處理各種災難性事件(例如中介軟體物理機宕機/資料庫宕機/網路隔離等突發事件)時。竟然發現還有一些奇怪的corner case。現在就將排查思路寫成文章分享出來。
## Bug現場
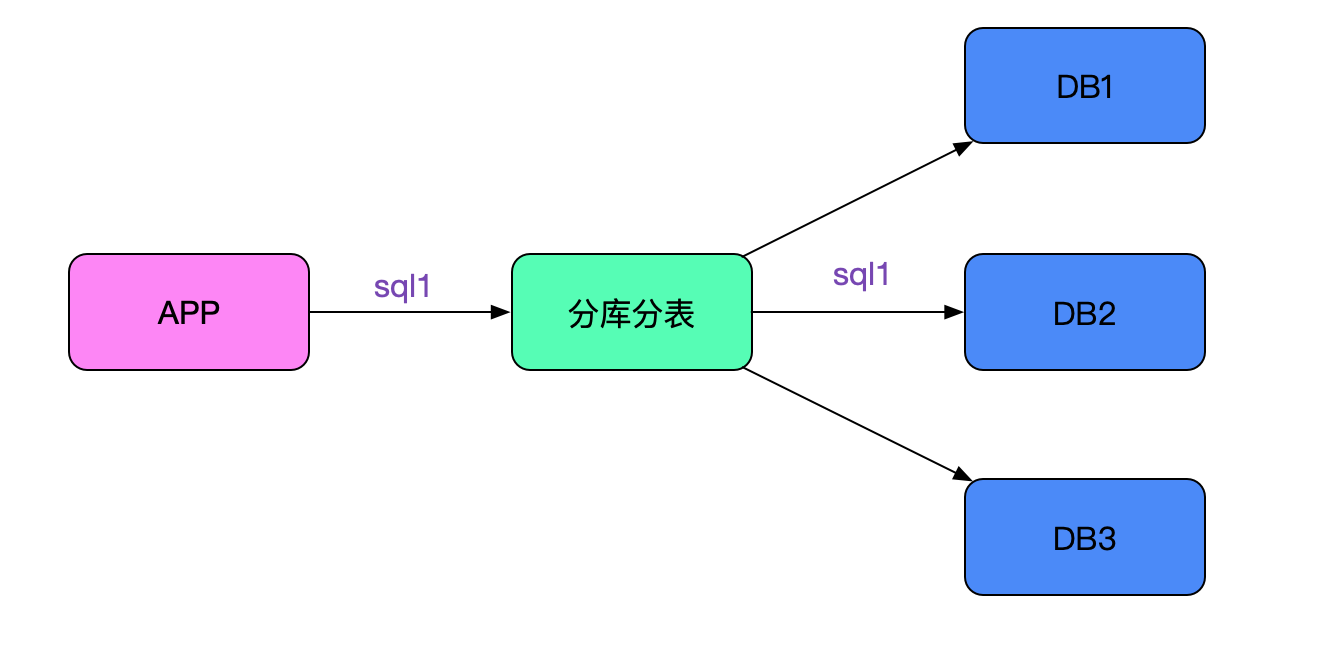
### 應用拓撲
應用通過中介軟體連後端多個數據庫,sql會根據路由規則路由到指定的節點,如下圖所示:
### 錯誤現象
應用在做某些資料庫操作時,會發現有比較大的概率失敗。他們的程式碼邏輯是這樣:
```
int count = updateSql(sql1);
...
// 虛擬碼
int count = updateSql("update test set value =1 where id in ("100","200") and status = 1;
if( 0 == count ){
throw new RuntimeException("更新失敗");
}
......
int count = updateSql(sql3);
...
```
即每做一次update之後都檢查下是否更新成功,如果不成功則回滾並拋異常。
在實際測試的過程中,發現經常報錯,更新為0。而實際那條sql確實是可以更新到的(即報錯回滾後,我們手動執行sql可以執行並update count>0)。
### 中介軟體日誌
筆者根據sql去中介軟體日誌裡面搜尋。發現了非常奇怪的結果,日誌如下:
```
2020-03-13 11:21:01:440 [NIOREACTOR-20-RW] frontIP=>ip1;sqlID=>12345678;rows=>0;sql=>update test set value =1 where id in ("1","2") and status = 1;start=>11:21:01:403;time=>24266;
2020-03-13 11:21:01:440 [NIOREACTOR-20-RW] frontIP=>ip1;sqlID=>12345678;rows=>2;sql=>update test set value =1 where id in ("1","2") and status = 1;start=>11:21:01:403;time=>24591;
```
由於中介軟體對每條sql都標識了唯一的一個sqlID,在日誌表現看來就好像sql執行了兩遍!由於sql中有一個in,很容易想到是否被拆成了兩條執行了。如下圖所示:
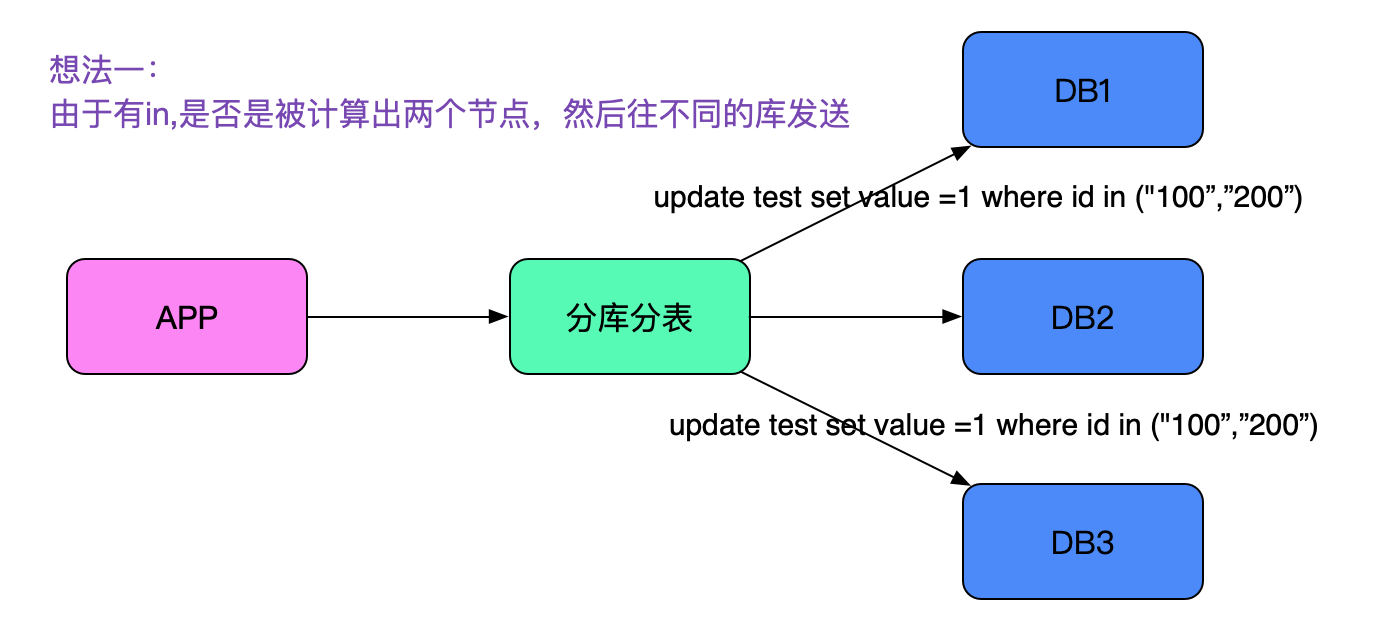
這條思路很快被筆者否決了,因為筆者explain並手動執行了一下,這條sql確實只路由到了一個節點。真正完全否決掉這條思路的是筆者在日誌裡面還發現,同樣的SQL會列印三遍!即看上去像執行了三次,這就和僅僅只in了兩個id的sql在思路上相矛盾了。
### 資料庫日誌
那到底資料真正執行了多少條呢?找DBA去撈一下其中的sql日誌,由於線下環境沒有日誌切割,日誌量巨大,搜尋時間太慢。沒辦法,就按照現有的資料進行分析吧。
### 日誌如何被觸發
由於當前沒有任何思路,於是筆者翻看中介軟體的程式碼,發現在update語句執行後,中介軟體會在收到mysql okay包後列印上述日誌。如下圖所示:
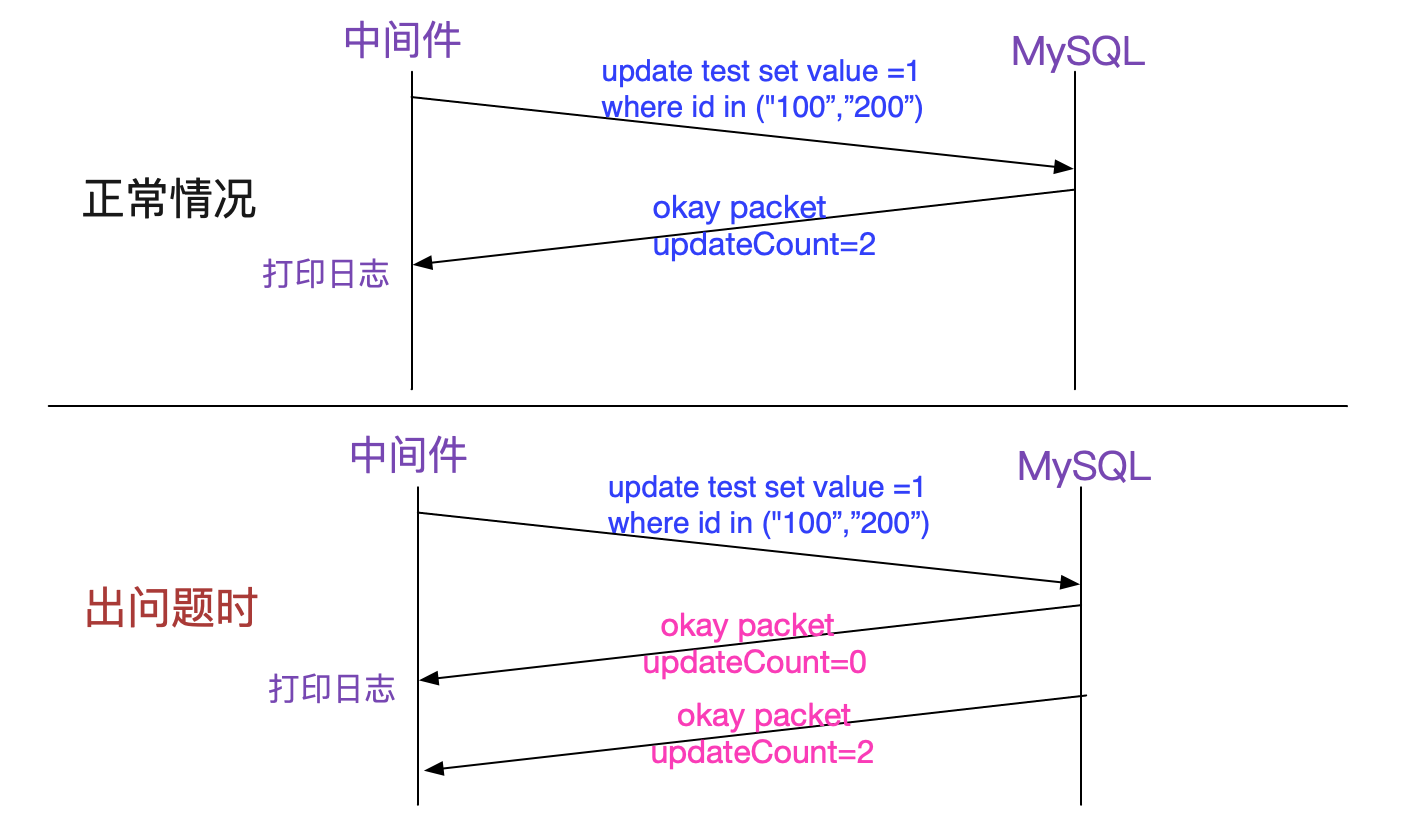
注意到所有出問題的update出問題的時候都是同一個NIOREACTOR執行緒先後列印了兩條日誌,所以筆者推斷這兩個okay大概率是同一個後端連線返回的。
### 什麼情況會返回多個okay?
這個問題筆者思索了很久,因為在筆者的實際重新執行出問題的sql並debug時,永遠只有一個okay返回。於是筆者聯想到,我們中介軟體有個狀態同步的部分,而這些狀態同步是將set auto\_commit=0等sql拼接到應用傳送的sql前面。即變成如下所示:
```
sql可能為
set auto_commit=0;set charset=gbk;>update test set value =1 where id in ("1","2") and status = 1;
```
於是筆者細細讀了這部分的程式碼,發現處理的很好。其通過計算出前面拼接出的sql數量,再在接收okay包的時候進行遞減,最後將真正執行的那條sql處理返回。其處理如下圖所示:
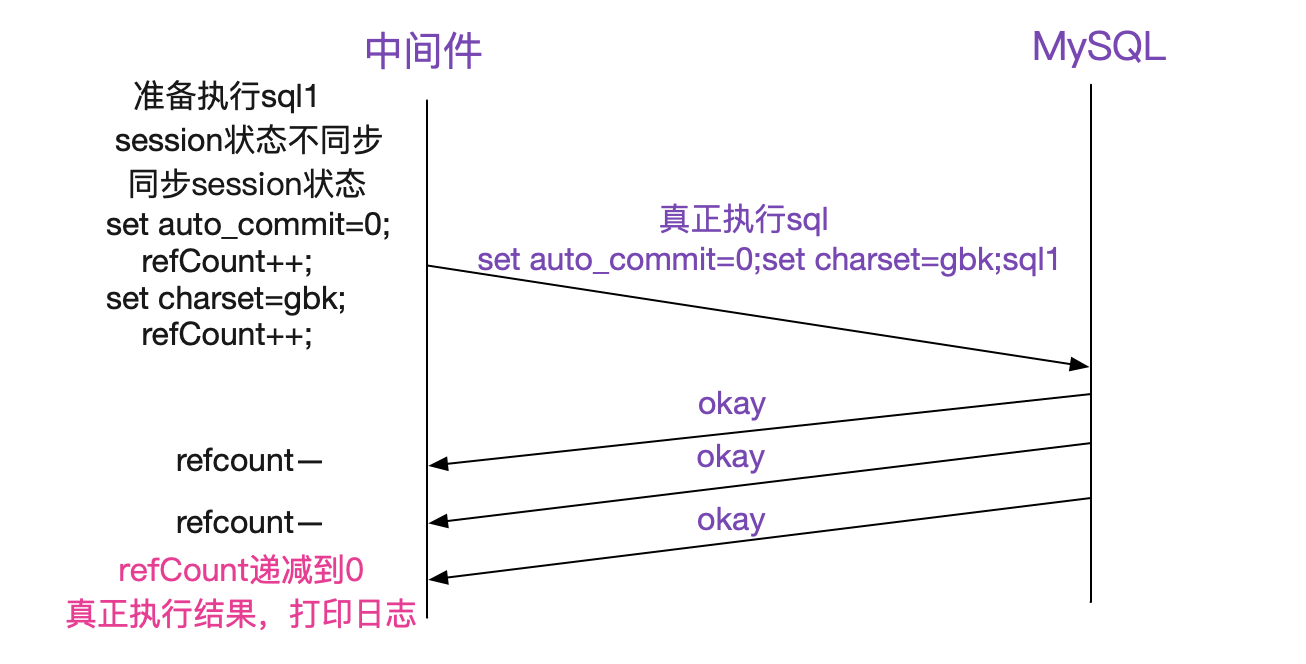
但這裡確給了筆者一個靈感,即一條sql文字確實是有可能返回多個okay包的。
### 真相大白
在筆者發現(sql1;sql2;)這樣的拼接sql會返回多個okay包後,就立刻聯想到,該不會業務自己寫了這樣的sql發給中介軟體,造成中介軟體的sql處理邏輯錯亂吧。因為我們的中介軟體只有在對自己拼接(同步狀態)的sql做處理,明顯是無法處理應用傳過來即為拼接sql的情況。
由於看上去有問題的那條sql並沒有拼接,於是筆者憑藉這條sql列印所在的reactor執行緒往上搜索,發現其上面真的有拼接sql!
```
2020-03-1311:21:01:040[NIOREACTOR-20RW]frontIP=>ip1;sqlID=>12345678;rows=>1;
sql=>update test_2 set value =1 where id=1 and status = 1;update test_2 set value =1 where id=2 and status = 1;
```
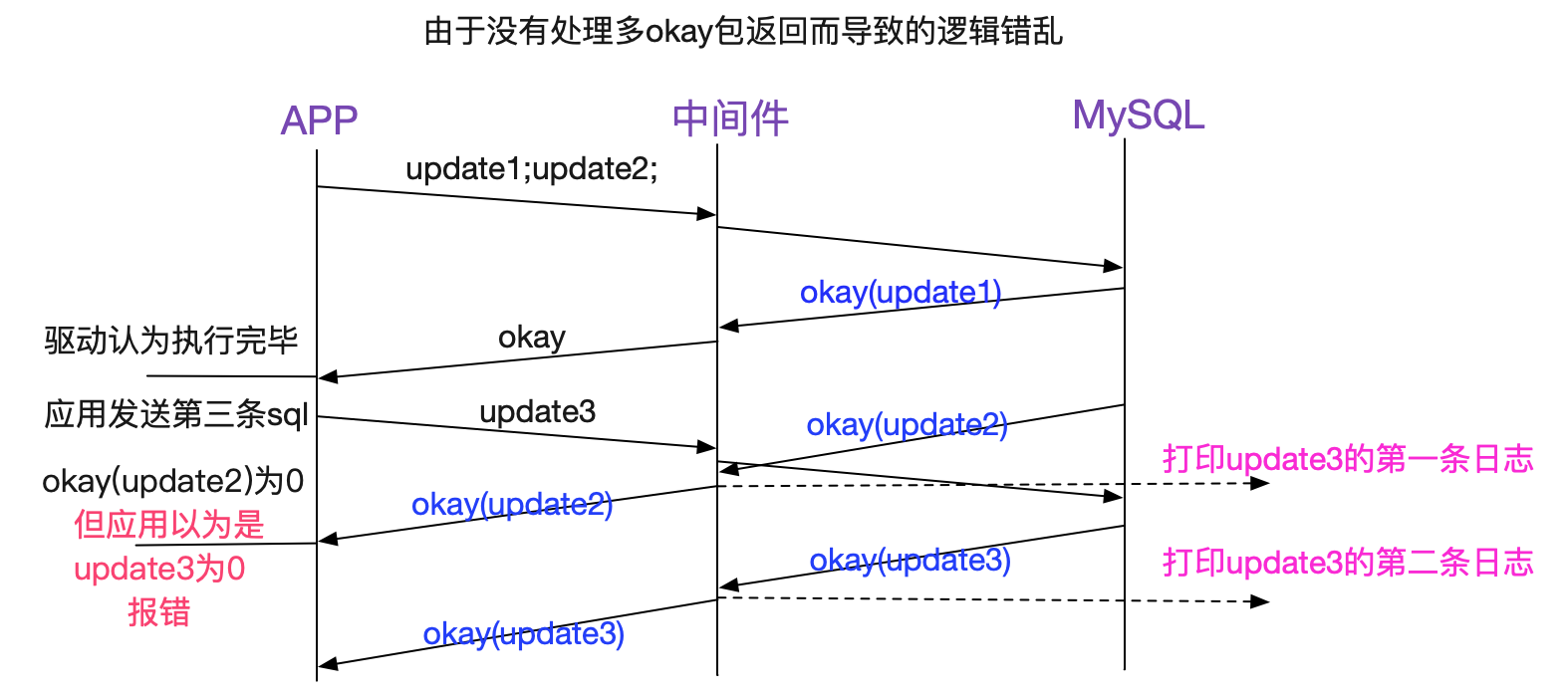
如上圖所示,(update1;update2)中update1的okay返回被驅動認為是所有的返回。然後應用立即傳送了update3。前腳剛傳送,update2的okay返回就回來了而其剛好是0,應用就報錯了(要不是0,這個錯亂邏輯還不會提前暴露)。那三條"重複執行"也很好解釋了,就是之前的拼接sql會有三條。
### 為何是概率出現
但奇怪的是,並不是每次拼接sql都會造成update3"重複執行"的現象,按照筆者的推斷應該前面只要是多條拼接sql就會必現才對。於是筆者翻了下jdbc驅動原始碼,發現其在傳送命令之前會清理下接收buffer,如下所示:
```
MysqlIO.java
final Buffer sendCommand(......){
......
// 清理接收buffer,會將殘存的okay包清除掉
clearInputStream();
......
send(this.sendPacket, this.sendPacket.getPosition());
......
}
```
正是由於clearInputStream()使得錯誤非必現(暴露),如果okay(update2)在應用傳送第三條sql前先到jdbc驅動會被驅動忽略!
讓我們再看一下不會讓update3"重複執行"的時序圖:

即根據okay(update2)返回的快慢來決定是否暴露這個問題,如下圖所示:
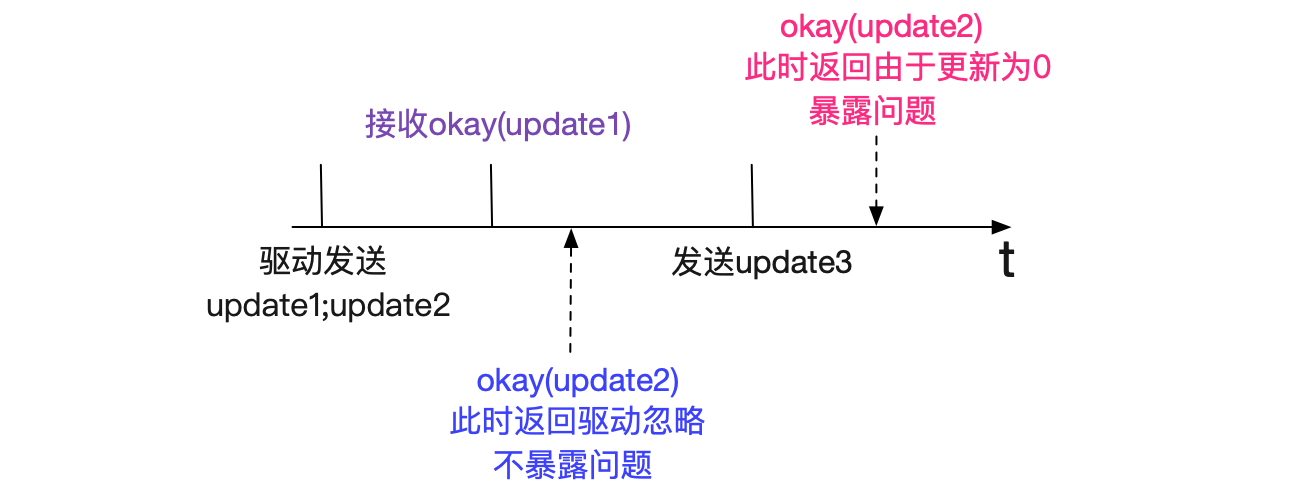
同時筆者觀察日誌,確實這種情況下"update1;update2"這條語句在中介軟體裡面日誌有兩條。
### 臨時解決方案
讓業務開發不用這些拼接sql的寫法後,再也沒出過問題。
## 為什麼不連中介軟體是okay的
業務開發這些sql是就在線上運行了好久,用了中介軟體後才出現問題。
既然不連中介軟體是okay的,那麼jdbc必然有這方面的完善處理,筆者去翻了下mysql-connect-java(5.1.46)。由於jdbc裡面存在大量的相容細節處理,筆者這邊只列出一些關鍵程式碼路徑:
```
MySQL JDBC 原始碼
MySQLIO
stack;
executeUpdate
|->executeUpdateInternel
|->executeInternal
|->execSQL
|->sqlQueryDirect
|->readAllResults (MysqlIO.java)
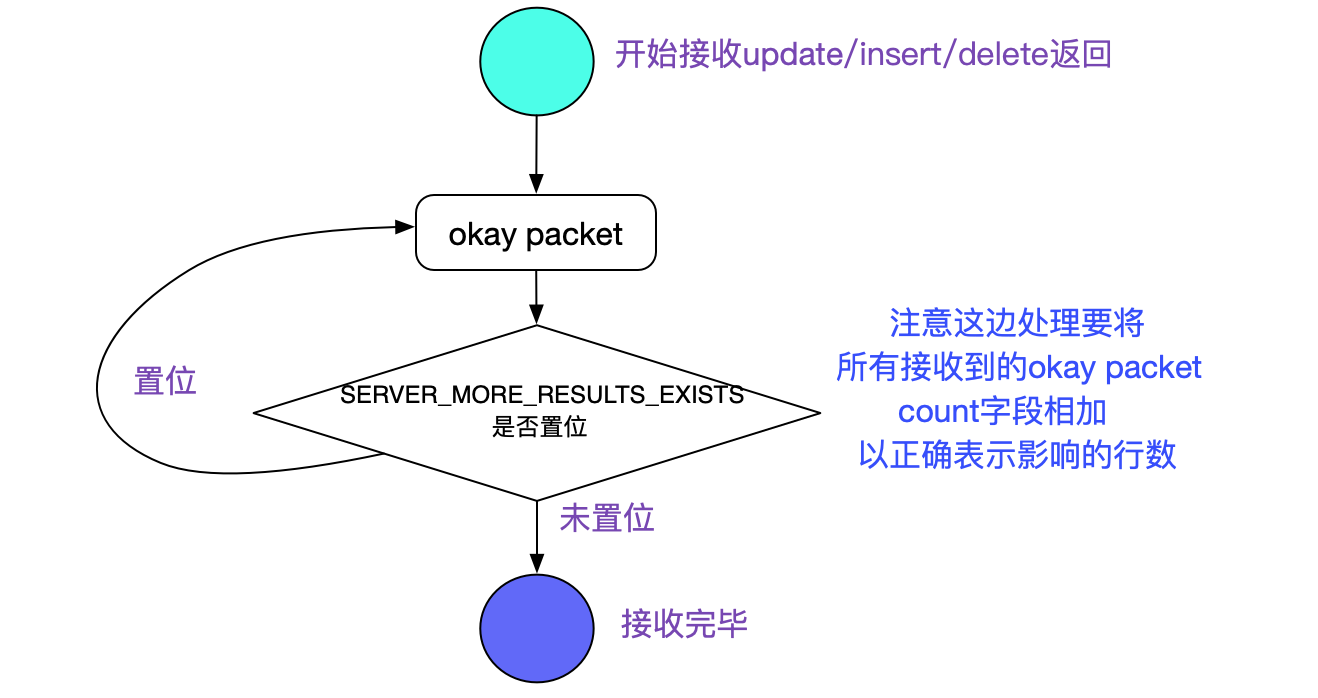
readAllResults: //核心在這個函式的處理裡面
ResultSetImpl readAllResults(......){
......
while (moreRowSetsExist) {
......
// 在返回okay包的保中其serverStatus欄位中如果SERVER_MORE_RESULTS_EXISTS置位
// 表明還有更多的okay packet
moreRowSetsExist = (this.serverStatus & SERVER_MORE_RESULTS_EXISTS) != 0;
}
......
}
```
正確的處理流程如下圖所示:
而我們中介軟體的原始碼確實這麼處理的:
```
@Override
public void okResponse(byte[] data, BackendConnection conn) {
......
// 這邊僅僅處理了autocommit的狀態,沒有處理SERVER_MORE_RESULTS_EXISTS
// 所以導致了不相容拼接sql的現象
ok.serverStatus = source.isAutocommit() ? 2 : 1;
ok.write(source);
......
}
```
### select也"重複執行"了
解決完上面的問題後,筆者在日誌裡竟然發現select盡然也有重複的,這邊並不會牽涉到okay包的處理,難道還有問題?日誌如下所示:
```
2020-03-13 12:21:01:040[NIOREACTOR-20RW]frontIP=>ip1;sqlID=>12345678;rows=>1;select abc;
2020-03-13 12:21:01:045[NIOREACTOR-21RW]frontIP=>ip2;sqlID=>12345678;rows=>1;select abc;
```
從不同的REACTOR執行緒號(20RW/21RW)和不同的frontIP(ip1,ip2)來看是兩個連線執行了同樣的sql,但為何sqlID是一樣的?任何一個詭異的現象都必須一查到底。於是筆者登入到應用上看了下應用日誌,確實應用有兩個不同的執行緒運行了同一條sql。
那肯定是中介軟體日誌列印的問題了,筆者很快就想通了其中的關竅,我們中介軟體有個對同樣sql快取其路由節點結構體的功能(這樣下一次同樣sql就不必解析,降低了CPU),而sqlID資訊正好也在那個路由節點結構體裡面。如下圖所示:
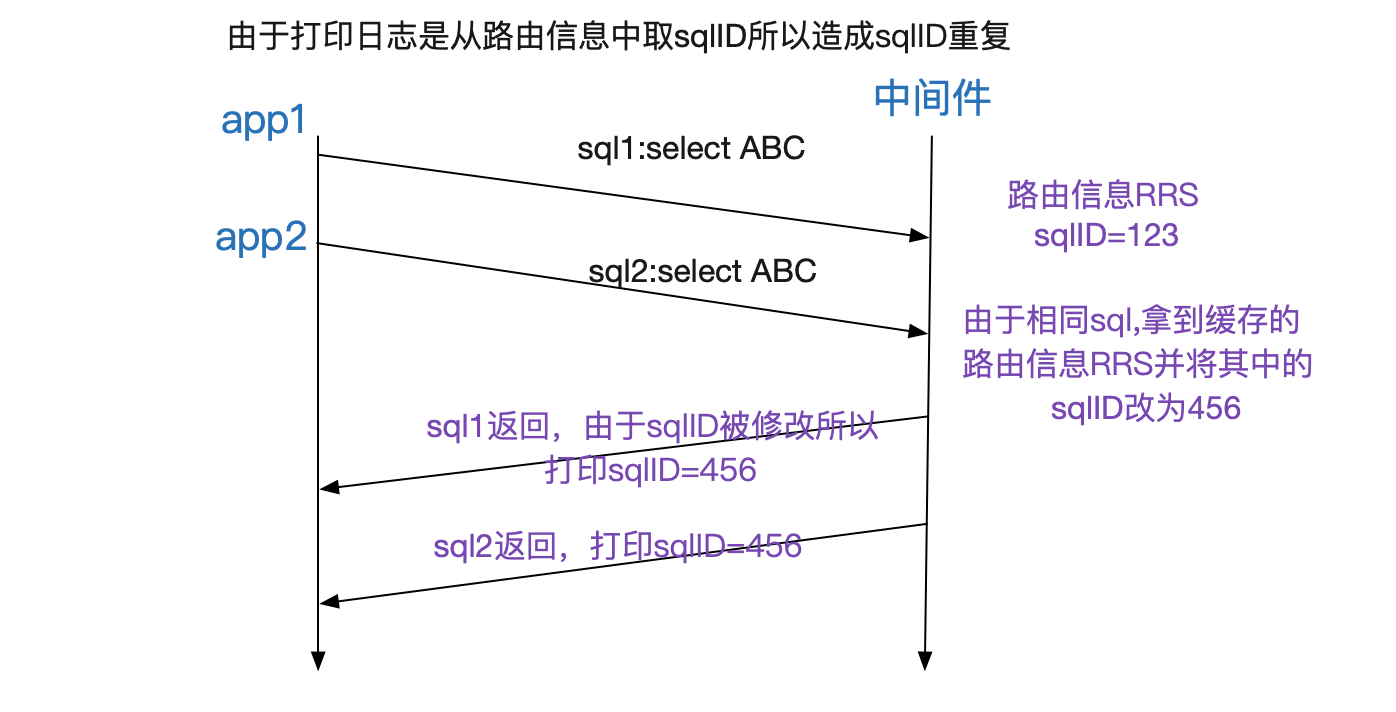
這個快取功能感覺沒啥用(因為線上基本是沒有相同sql的),於是筆者在筆者優化的閃電模式下(大幅度提高中介軟體效能)將這個功能禁用掉了,沒想到為了排查問題而開啟的詳細日誌碰巧將這個功能開啟了。
## 總結
任何系統都不能說百分之百穩定可靠,尤其是不能立flag。在線上運行了好幾年的系統也是如此。只有對所有預料外的現象進行細緻的追查與深入的分析並解決,才能讓我們的系統越來越可靠。

## 公眾號
關注筆者公眾號,獲取更多幹貨文章:
