
老哥,您看我這篇Java集合,還有機會評優嗎?
阿新 • • 發佈:2020-08-03
集合在我們日常開發使用的次數數不勝數,`ArrayList`/`LinkedList`/`HashMap`/`HashSet`······信手拈來,抬手就拿來用,在 IDE 上龍飛鳳舞,但是作為一名合格的優雅的程式猿,僅僅瞭解怎麼使用`API`是遠遠不夠的,如果在呼叫`API`時,知道它內部發生了什麼事情,就像開了`透視`外掛一樣,洞穿一切,這種感覺才真的爽,而且這樣就**不是集合提供什麼功能給我們使用,而是我們選擇使用它的什麼功能了**。
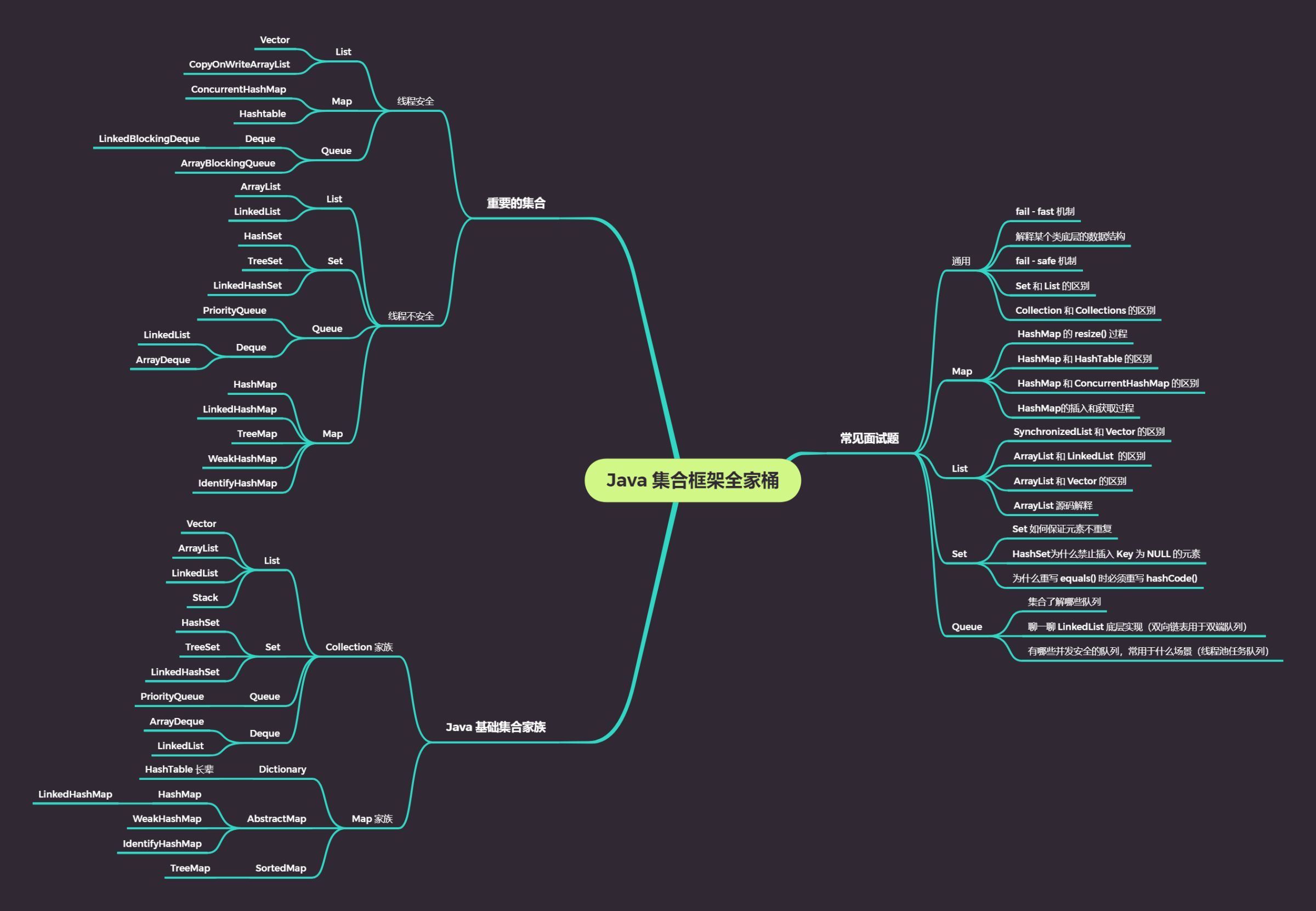
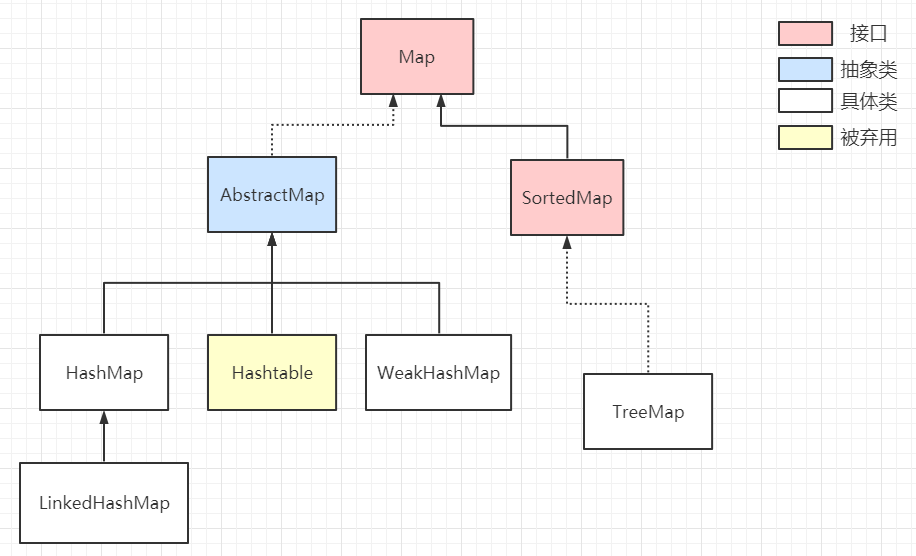
## 集合框架總覽
下圖堪稱集合框架的**上帝視角**,講到集合框架不得不看的就是這幅圖,當然,你會覺得眼花繚亂,不知如何看起,這篇文章帶你一步一步地秒殺上面的每一個介面、抽象類和具體類。我們將會從最頂層的介面開始講起,一步一步往下深入,幫助你把對集合的認知構建起一個知識網路。
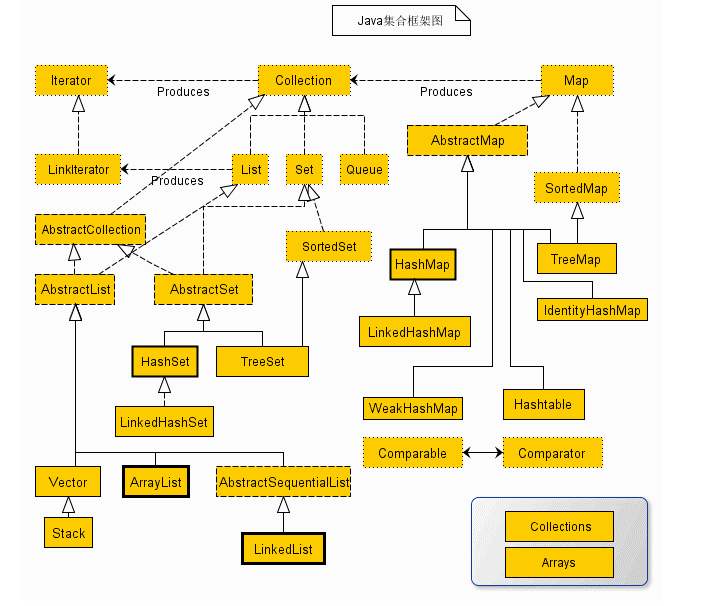
工欲善其事必先利其器,讓我們先來過一遍整個集合框架的組成部分:
1. 集合框架提供了兩個遍歷介面:`Iterator`和`ListIterator`,其中後者是前者的`優化版`,支援在任意一個位置進行**前後雙向遍歷**。注意圖中的`Collection`應當繼承的是`Iterable`而不是`Iterator`,後面會解釋`Iterable`和`Iterator`的區別
2. 整個集合框架分為兩個門派(型別):`Collection`和`Map`,前者是一個容器,儲存一系列的**物件**;後者是鍵值對``,儲存一系列的**鍵值對**
3. 在集合框架體系下,衍生出四種具體的集合型別:`Map`、`Set`、`List`、`Queue`
4. `Map`儲存``鍵值對,查詢元素時通過`key`查詢`value`
5. `Set`內部儲存一系列**不可重複**的物件,且是一個**無序**集合,物件排列順序不一
6. `List`內部儲存一系列**可重複**的物件,是一個**有序**集合,物件按插入順序排列
7. `Queue`是一個**佇列**容器,其特性與`List`相同,但只能從`隊頭`和`隊尾`操作元素
8. JDK 為集合的各種操作提供了兩個工具類`Collections`和`Arrays`,之後會講解工具類的常用方法
9. 四種抽象集合型別內部也會衍生出許多具有不同特性的集合類,**不同場景下擇優使用,沒有最佳的集合**
上面瞭解了整個集合框架體系的組成部分,接下來的章節會嚴格按照上面羅列的順序進行講解,每一步都會有`承上啟下`的作用
> 學習`Set`前,最好最好要先學習`Map`,因為`Set`的操作本質上是對`Map`的操作,往下看準沒錯
### Iterator Iterable ListIterator
在第一次看這兩個介面,真以為是一模一樣的,沒發現裡面有啥不同,**存在即合理**,它們兩個還是有本質上的區別的。
首先來看`Iterator`介面:
```java
public interface Iterator {
boolean hasNext();
E next();
void remove();
}
```
提供的API介面含義如下:
- `hasNext()`:判斷集合中是否存在下一個物件
- `next()`:返回集合中的下一個物件,並將訪問指標移動一位
- `remove()`:刪除集合中呼叫`next()`方法返回的物件
在早期,遍歷集合的方式只有一種,通過`Iterator`迭代器操作
```java
List list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator iter = list.iterator();
while (iter.hasNext()) {
Integer next = iter.next();
System.out.println(next);
if (next == 2) { iter.remove(); }
}
```
再來看`Iterable`介面:
```java
public interface Iterable {
Iterator iterator();
// JDK 1.8
default void forEach(Consumer action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}
```
可以看到`Iterable`接口裡面提供了`Iterator`介面,所以實現了`Iterable`介面的集合依舊可以使用`迭代器`遍歷和操作集合中的物件;
而在 `JDK 1.8`中,`Iterable`提供了一個新的方法`forEach()`,它允許使用增強 for 迴圈遍歷物件。
```java
List list = new ArrayList<>();
for (Integer num : list) {
System.out.println(num);
}
```
我們通過命令:`javap -c`反編譯上面的這段程式碼後,發現它只是 Java 中的一個`語法糖`,本質上還是呼叫`Iterator`去遍歷。
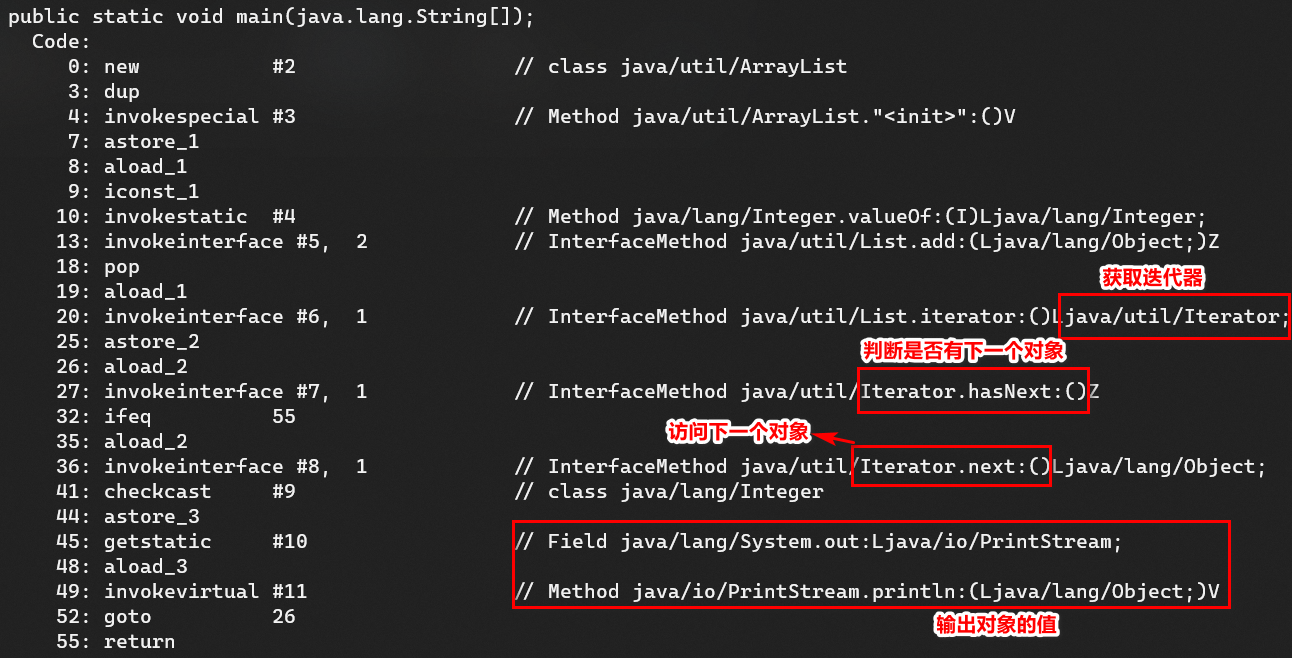
翻譯成程式碼,就和一開始的`Iterator`迭代器遍歷方式基本相同了。
```java
Iterator iter = list.iterator();
while (iter.hasNext()) {
Integer num = iter.next();
System.out.println(num);
}
```
> 還有更深層次的探討:為什麼要設計兩個介面`Iterable`和`Iterator`,而不是保留其中一個就可以了。
>
> 簡單講解:`Iterator`的保留可以讓子類去**實現自己的迭代器**,而`Iterable`介面更加關注於`for-each`的增強語法。具體可參考:[Java中的Iterable與Iterator詳解](https://www.cnblogs.com/litexy/p/9744241.html)
關於`Iterator`和`Iterable`的講解告一段落,下面來總結一下它們的重點:
1. `Iterator`是提供集合操作內部物件的一個迭代器,它可以**遍歷、移除**物件,且只能夠**單向移動**
2. `Iterable`是對`Iterator`的封裝,在`JDK 1.8`時,實現了`Iterable`介面的集合可以使用**增強 for 迴圈**遍歷集合物件,我們通過**反編譯**後發現底層還是使用`Iterator`迭代器進行遍歷
等等,這一章還沒完,還有一個`ListIterator`。它繼承 Iterator 介面,在遍歷`List`集合時可以從**任意索引下標**開始遍歷,而且支援**雙向遍歷**。
ListIterator 存在於 List 集合之中,通過呼叫方法可以返回**起始下標**為 `index`的迭代器
```java
List list = new ArrayList<>();
// 返回下標為0的迭代器
ListIterator listIter1 = list.listIterator();
// 返回下標為5的迭代器
ListIterator listIter2 = list.listIterator(5);
```
ListIterator 中有幾個重要方法,大多數方法與 Iterator 中定義的含義相同,但是比 Iterator 強大的地方是可以在**任意一個下標位置**返回該迭代器,且可以實現**雙向遍歷**。
```java
public interface ListIterator extends Iterator {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
// 替換當前下標的元素,即訪問過的最後一個元素
void set(E e);
void add(E e);
}
```
### Map 和 Collection 介面
Map 介面和 Collection 介面是集合框架體系的兩大門派,Collection 是儲存元素本身,而 Map 是儲存``鍵值對,在 Collection 門派下有一小部分弟子去`偷師`,利用 Map 門派下的弟子來修煉自己。
是不是聽的一頭霧水哈哈哈,舉個例子你就懂了:`HashSet`底層利用了`HashMap`,`TreeSet`底層用了`TreeMap`,`LinkedHashSet`底層用了`LinkedHashMap`。
下面我會詳細講到各個具體集合類哦,所以在這裡,我們先從整體上了解這兩個`門派`的特點和區別。
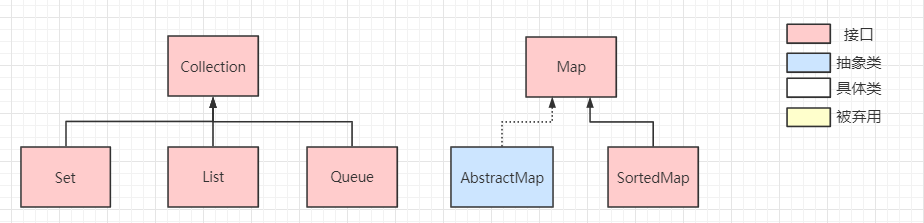
`Map`介面定義了儲存的資料結構是``形式,根據 key 對映到 value,一個 key 對應一個 value ,所以`key`不可重複,而`value`可重複。
在`Map`介面下會將儲存的方式細分為不同的種類:
- `SortedMap`介面:該類對映可以對``按照自己的規則進行**排序**,具體實現有 TreeMap
- `AbsractMap`:它為子類提供好一些**通用的API實現**,所有的具體Map如`HashMap`都會繼承它
而`Collection`介面提供了所有集合的**通用方法**(注意這裡不包括`Map`):
- 新增方法:`add(E e)` / `addAll(Collection var1)`
- 刪除方法:`remove(Object var1)` / `removeAll(Collection var1)`
- 查詢方法:`contains(Object var1)` / `containsAll(Collection var1);`
- 查詢集合自身資訊:`size()` / `isEmpty()`
- ···
在`Collection`介面下,同樣會將集合細分為不同的種類:
- `Set`介面:一個**不允許儲存重複元素**的**無序**集合,具體實現有`HashSet` / `TreeSet`···
- `List`介面:一個**可儲存重複元素**的**有序**集合,具體實現有`ArrayList` / `LinkedList`···
- `Queue`介面:一個**可儲存重複元素**的**佇列**,具體實現有`PriorityQueue` / `ArrayDeque`···
## Map 集合體系詳解
`Map`介面是由``組成的集合,由`key`對映到**唯一**的`value`,所以`Map`不能包含重複的`key`,每個鍵**至多**對映一個值。下圖是整個 Map 集合體系的主要組成部分,我將會按照日常使用頻率從高到低一一講解。
不得不提的是 Map 的設計理念:**定位元素**的時間複雜度優化到 `O(1)`
Map 體系下主要分為 AbstractMap 和 SortedMap兩類集合
`AbstractMap`是對 Map 介面的擴充套件,它定義了普通的 Map 集合具有的**通用行為**,可以避免子類重複編寫大量相同的程式碼,子類繼承 AbstractMap 後可以重寫它的方法,**實現額外的邏輯**,對外提供更多的功能。
`SortedMap` 定義了該類 Map 具有 `排序`行為,同時它在內部定義好有關排序的抽象方法,當子類實現它時,必須重寫所有方法,對外提供排序功能。
head;
// 尾結點
transient LinkedHashMap.Entry tail;
```
利用 LinkedHashMap 可以實現 `LRU` 快取淘汰策略,因為它提供了一個方法:
```java
protected boolean removeEldestEntry(java.util.Map.Entry eldest) {
return false;
}
```
該方法可以移除`最靠近連結串列頭部`的一個節點,而在`get()`方法中可以看到下面這段程式碼,其作用是挪動結點的位置:
```java
if (this.accessOrder) {
this.afterNodeAccess(e);
}
```
只要呼叫了`get()`且`accessOrder = true`,則會將該節點更新到連結串列`尾部`,具體的邏輯在`afterNodeAccess()`中,感興趣的可翻看原始碼,篇幅原因這裡不再展開。
現在如果要實現一個`LRU`快取策略,則需要做兩件事情:
- 指定`accessOrder = true`可以設定連結串列按照訪問順序排列,通過提供的構造器可以設定`accessOrder`
```java
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
```
- 重寫`removeEldestEntry()`方法,內部定義邏輯,通常是判斷`容量`是否達到上限,若是則執行淘汰。
這裡就要貼出一道大廠面試必考題目:[146. LRU快取機制](https://leetcode-cn.com/problems/lru-cache/),只要跟著我的步驟,就能順利完成這道大廠題了。
關於 LinkedHashMap 主要介紹兩點:
1. 它底層維護了一條`雙向連結串列`,因為繼承了 HashMap,所以它也不是執行緒安全的
2. LinkedHashMap 可實現`LRU`快取淘汰策略,其原理是通過設定`accessOrder`為`true`並重寫`removeEldestEntry`方法定義淘汰元素時需滿足的條件
### TreeMap
TreeMap 是 `SortedMap` 的子類,所以它具有**排序**功能。它是基於`紅黑樹`資料結構實現的,每一個鍵值對``都是一個結點,預設情況下按照`key`自然排序,另一種是可以通過傳入定製的`Comparator`進行自定義規則排序。
```java
// 按照 key 自然排序,Integer 的自然排序是升序
TreeMap naturalSort = new TreeMap<>();
// 定製排序,按照 key 降序排序
TreeMap customSort = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
```
TreeMap 底層使用了陣列+紅黑樹實現,所以裡面的儲存結構可以理解成下面這幅圖哦。
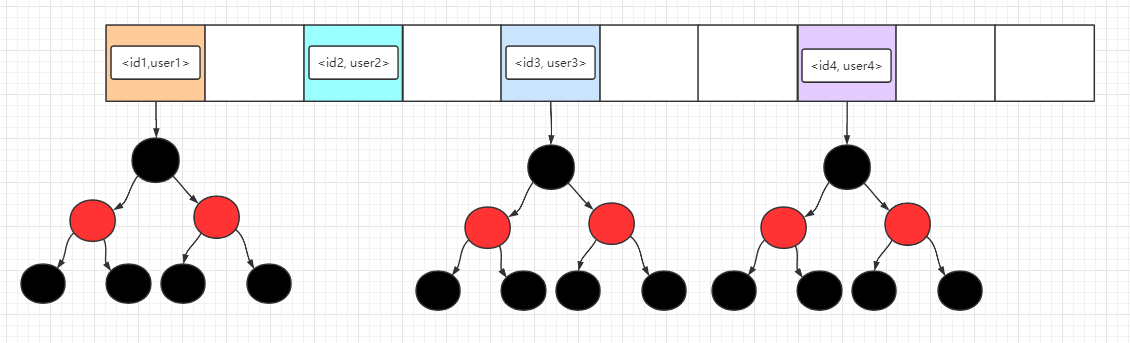
圖中紅黑樹的每一個節點都是一個`Entry`,在這裡為了圖片的簡潔性,就不標明 key 和 value 了,注意這些元素都是已經按照`key`排好序了,整個資料結構都是保持著`有序` 的狀態!
關於`自然`排序與`定製`排序:
- 自然排序:要求`key`必須實現`Comparable`介面。
由於`Integer`類實現了 Comparable 介面,按照自然排序規則是按照`key`從小到大排序。
```java
TreeMap treeMap = new TreeMap<>();
treeMap.put(2, "TWO");
treeMap.put(1, "ONE");
System.out.print(treeMap);
// {1=ONE, 2=TWO}
```
- 定製排序:在初始化 TreeMap 時傳入新的`Comparator`,**不**要求`key`實現 Comparable 介面
```java
TreeMap treeMap = new TreeMap<>((o1, o2) -> Integer.compare(o2, o1));
treeMap.put(1, "ONE");
treeMap.put(2, "TWO");
treeMap.put(4, "FOUR");
treeMap.put(3, "THREE");
System.out.println(treeMap);
// {4=FOUR, 3=THREE, 2=TWO, 1=ONE}
```
通過傳入新的`Comparator`比較器,可以覆蓋預設的排序規則,上面的程式碼按照`key`降序排序,在實際應用中還可以按照其它規則自定義排序。
`compare()`方法的返回值有三種,分別是:`0`,`-1`,`+1`
(1)如果返回`0`,代表兩個元素相等,不需要調換順序
(2)如果返回`+1`,代表前面的元素需要與後面的元素調換位置
(3)如果返回`-1`,代表前面的元素不需要與後面的元素調換位置
而何時返回`+1`和`-1`,則由我們自己去定義,JDK預設是按照**自然排序**,而我們可以根據`key`的不同去定義降序還是升序排序。
關於 TreeMap 主要介紹了兩點:
1. 它底層是由`紅黑樹`這種資料結構實現的,所以操作的時間複雜度恆為`O(logN)`
2. TreeMap 可以對`key`進行自然排序或者自定義排序,自定義排序時需要傳入`Comparator`,而自然排序要求`key`實現了`Comparable`介面
3. TreeMap 不是執行緒安全的。
### WeakHashMap
WeakHashMap 日常開發中比較少見,它是基於普通的`Map`實現的,而裡面`Entry`中的鍵在每一次的`垃圾回收`都會被清除掉,所以非常適合用於**短暫訪問、僅訪問一次**的元素,快取在`WeakHashMap`中,並儘早地把它回收掉。
當`Entry`被`GC`時,WeakHashMap 是如何感知到某個元素被回收的呢?
在 WeakHashMap 內部維護了一個引用佇列`queue`
```java
private final ReferenceQueue