
堵俊平:雲與開源——資料引擎的未來
大家好!我是堵俊平,來自Apache社群。我是Apache 基金會的member (會員), 也是 Hadoop 以及 YuniKorn等專案的committer和PMC。 我也是 Tube MQ, Nutx等孵化器專案的導師。在大資料方面有一個長時間的開源貢獻。
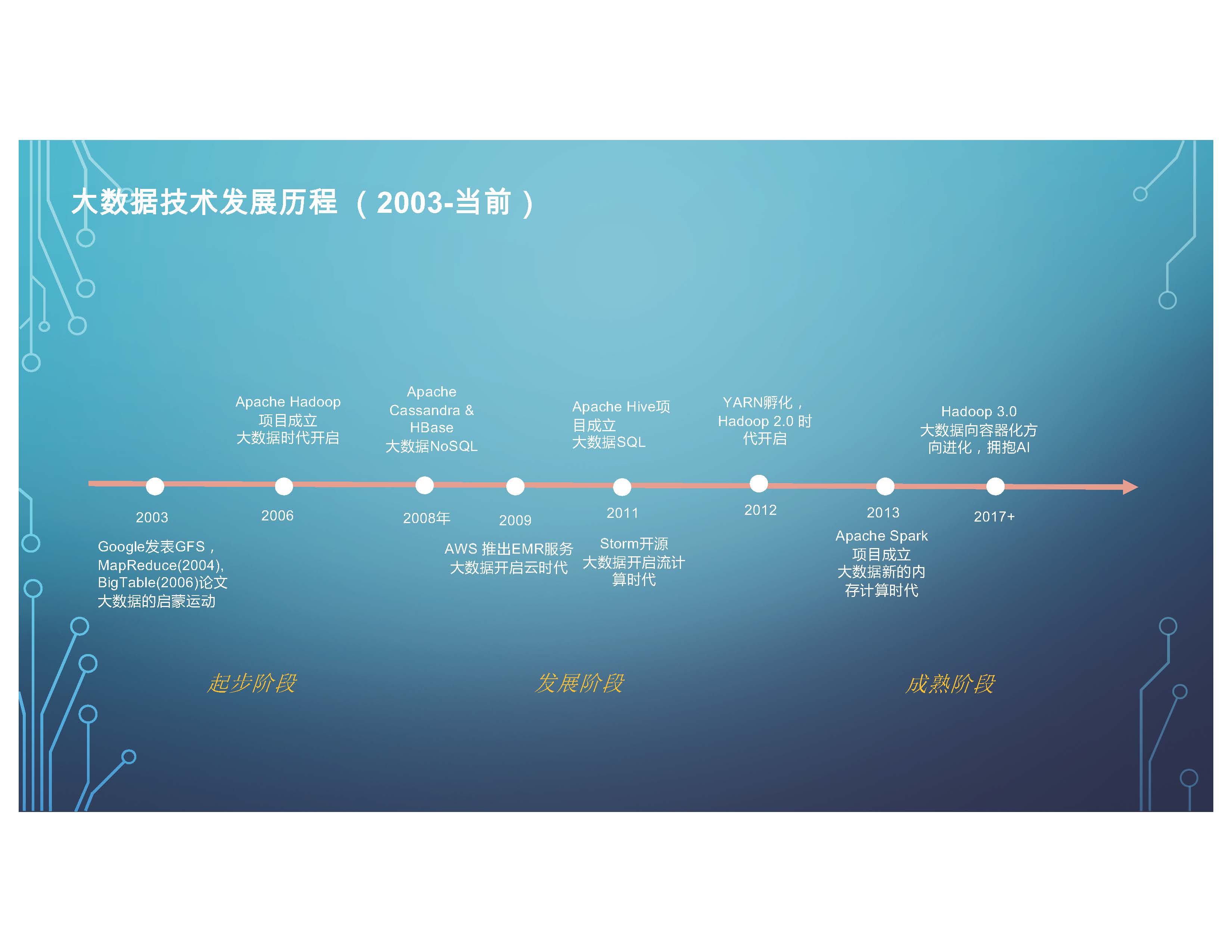
首先,我們回顧一下大資料技術的發展歷程。 從 2003年開始Google發表了GFS,MapReduce(2004), BigTable(2006)論文, 也就是我們熟知的三輛馬車的開始,一直到當前,經歷了很多階段。我們認為,剛開始的是一個起步階段。標誌性的專案Hadoop在2006年橫空出世。 2008年時, 像Apache Cassandra 和HBase這樣的NoSQL的引擎也相繼開源。
到了發展階段,AWS 推出了EMR服務, 在雲上第一次開始有部署大資料的服務。之後,(Apache) Hive成立,包括像Storm, 大資料進入SQL 的時代以及流計算的時代。 到2012年,Hadoop 2.0 時代開啟。 Hadoop 除了傳統的MapReduce, 它可以支援更多的計算引擎,包括2013年成立的 Spark 專案,再包括像現在比較流行的流處理平臺Flink這樣的技術等等。
進入2017年之後, 大資料進入成熟階段。 Hadoop 3.0釋出,大資料整體向容器化方向進化,大資料和AI進行深度融合。整體來看這就是大資料發展的一個歷程。
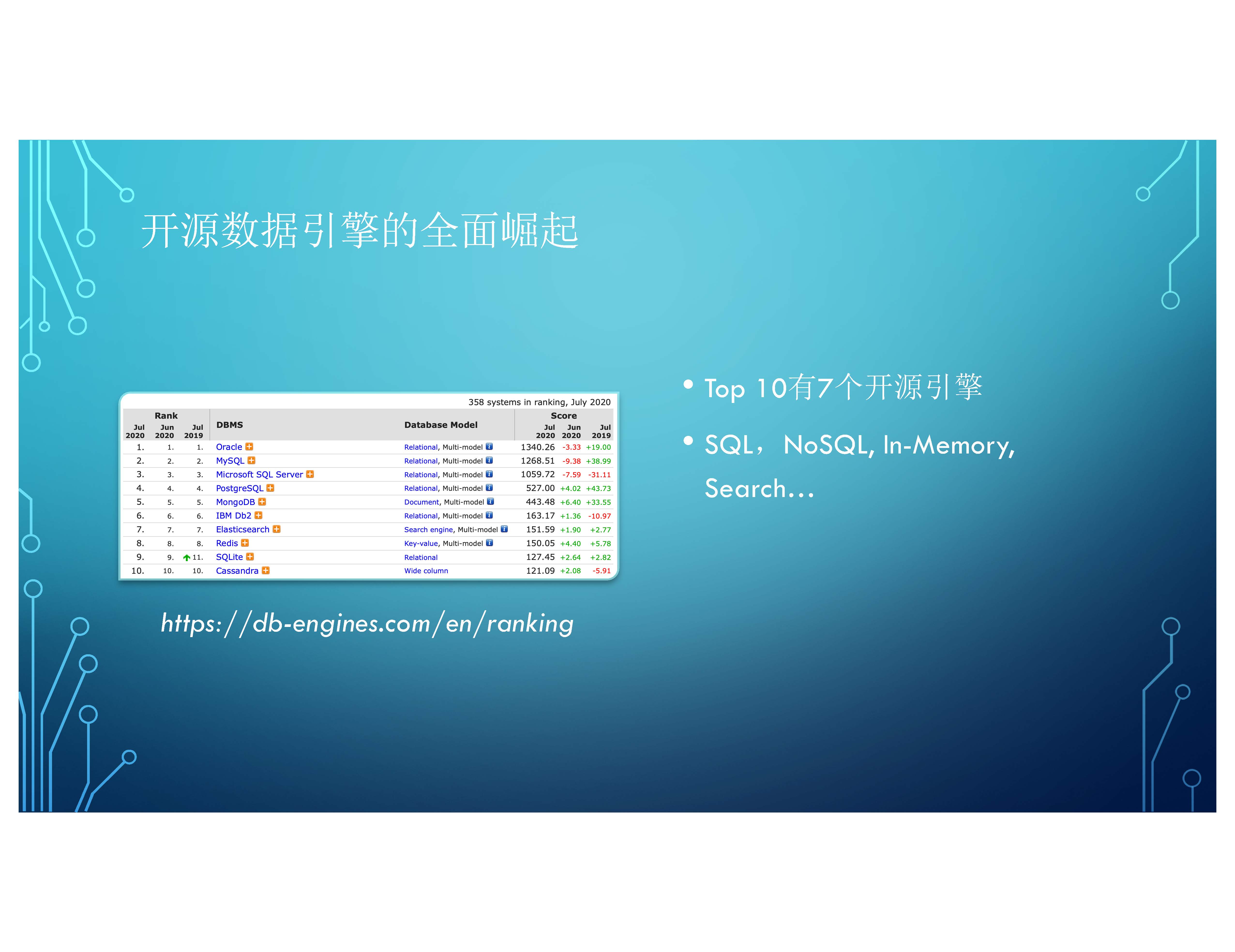
另外除了大資料領域,我們看到開源資料引擎全面崛起。 根據權威的榜單db-engines ranking(排名), 可以看到最流行的前10大與資料庫相關的引擎,10個裡有7個是開源引擎,其中涵蓋了 SQL,NoSQL, In-Memory, 搜素相關的引擎都在裡面。本次活動的主角Cassandra也歸列在前十之列。
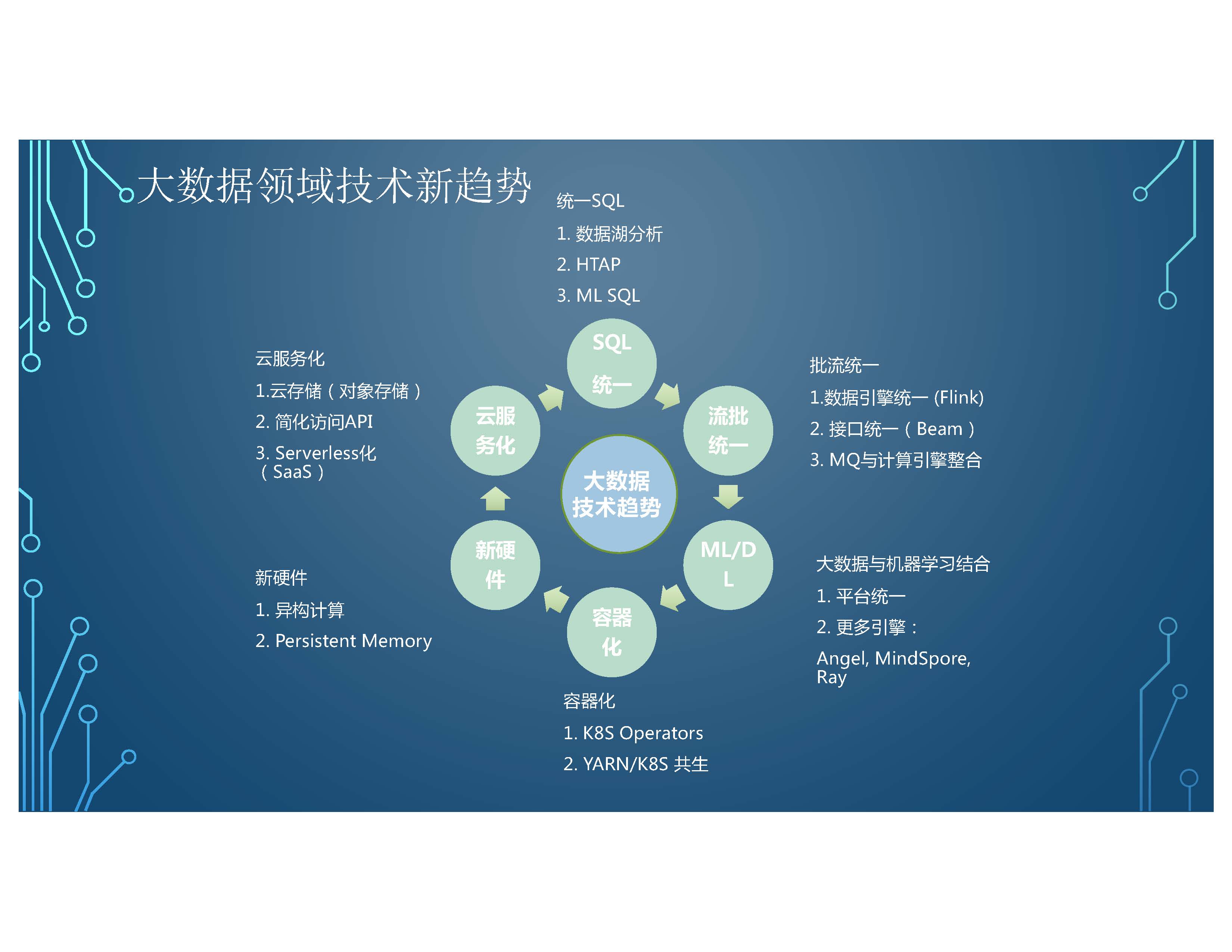
我們可以看到整個大資料領域技術有幾個很明顯的新趨勢。
第一個, 我覺得比較重要的,就是雲服務化。整個大資料領域全面地向雲化方向邁進。比如說,我們的儲存,大資料和傳統的物件儲存怎麼樣去結合,包括訪問的API進行簡化,包括全面的Serverless化 (SaaS)。傳統的大資料可能是一個叢集,伺服器化的部署, 現在變成是Serverless化的呼叫, SQL或其他的計算。
還有一個重要趨勢就是,我們希望有統一的SQL, 做資料湖分析的資料可能是跨源的,有的在檔案系統裡面,有的在SQL引擎裡面, 有的在SQL裡面等等。 這種跨源的統一SQL的資料庫分析是一個重要的趨勢。除此之外,像TPE和融合HTAP 的引擎, 甚至包括傳統的SQL和machine learning 相統一的引擎也非常重要。另
外一個趨勢就是PO統一, 在資料引擎層統一。 就是通過比如說 Flink的技術或其他的引擎,既能處理流,也能處理批。還有在介面層統一。 就是我們介面層統一了,下面有不同的引擎,有流的引擎,有批的引擎, 做一個融合,還有以及MSEQ與計算引擎整合,可能在入口資料的MQ 往後延申流計算相應的服務。 還有重要的技術趨勢包括 machine learning, 與傳統大資料平臺的結合。比如說,平臺上的統一,從資料的預處理到訓練到推理,形成統一的閉環。包括我們更多的引擎,比如像, 陸陸續續有更多的引擎開發出來,包括我們熟知tensil flow, Y torch之外,比如像國內的Angel, MindSpore, 也包括Ray一樣新型的跨資料和machine learning的引擎,也是重要的一個方式。
除此之外,一個重要的方向就是大資料的容器化,包括K8S Operators和.YARN與K8S 共生的專案。比如說,原產於大資料專案的Yunicorn、K8S社群、CNCF資料孵化的Volcano專案,試圖把大資料和容器化相結合。還有一個重要的趨勢是新硬體。包括異構計算,比如說,CPU 和GPU 怎麼樣協同或統一。在不同CPU裡面,我們有x86 的一套、有ARM的一套,不同的體系之間怎麼樣去融合。對我們上層的大資料,未來的技術有不同的推動作用。 甚至包括有一些像現在新的技術創新,像Persistent Memory,傳統的記憶體和磁碟之間有一層融合,整體來說就是很多的方向去引領大資料領域。雖然我們說它是成熟期,可以看到很多新的技術革命仍然在醞釀。 當然這些大部分的技術都是開源的技術。
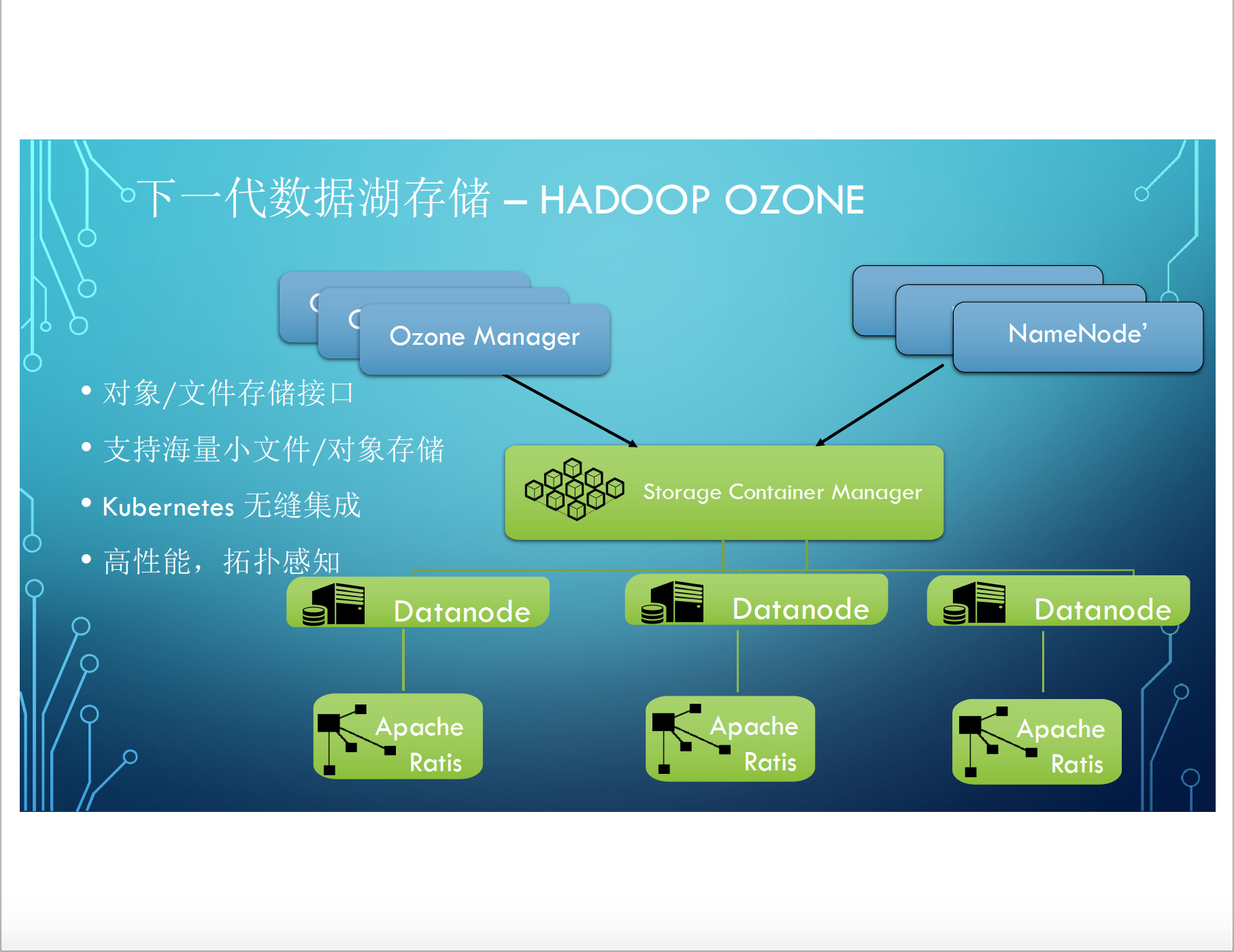
這裡簡單列舉幾個吧, 包括下一代資料湖儲存。 Hadoop專案裡孵化的 Ozone專案值得大家關注。Ozone專案它是為解決什麼問題呢?傳統的HDFS 它的擴充套件能力可能有問題,也不能提供,目前來說很多的應用比較喜歡物件儲存的介面, HDFS也不能提供。Ozone是完全可以提供物件介面, 也可以提供檔案儲存介面。 另外它可以無縫支援海量小檔案。傳統的HDFS 做不到, 因為設計上它把所有的 metadata 都放在NameNode上。 Ozone的設計, Ozone Manager 和 Storage Container Manager兩層的設計可以把原資料拆開打散, 包括對K8S 整個 體系的無縫整合,包括高效能, 拓撲感知等等,相對於原有的 HDFS算是一個重要突破, 可以成為下一代資料庫儲存的重磅級的候選人。

下一代資源排程也有很多技術創新。 比如YARN 社群孵化出來的專案YuniKorn 。 它是 Apache的一個專案,能支援Yarn的伺服器和與 K8S專案進行融合, 下面有不同的實現,可以放在 Yarn 的caster上, 把K8S叢集的能力調動起來。
另外還有一個專案就是 Volcano, 也就是CNCF專案, 它在K8S的排程體系上做了重要的擴充套件,不僅支援雲原生的面向服務的排程, 它也可以支援面向任務的,面向job的, 比較貼近於像 Spark這樣的大資料應用 batch job 的排程, 可以提供一個很好的支援。
現在一個新的熱點是資料湖儲存格式, 像原產於 Uber 的 Hudi, 以及Netflix的 Apache 專案 Iceberg, 以及 Databricks (Spark 的原廠)貢獻出來的 Delta Lake, 應該是 Linux 基金會的一個專案。 這幾個專案主要是為解決什麼問題呢? 傳統流批資料處理有很多痛點。
比如說, 上游資料匯入與下游分析作業的schema規範與對齊的問題。 包括整個流式的資料寫入是沒有ACID保證。 這樣的話, 我們是需要在 Table Format 這一層有更加豐富的餘的保證。 第三, 在資料寫入的時候,資料需要執行Update, Delete等的操作, 原始資料需要一些修正, 或者有一些丟包等操作, 在新的資料庫儲存格式下可能可以更容易支援這種操作,以及像這種頻繁的資料匯入會造成的海量小檔案讓HDFS不堪重負。 當然我們之前說到的Ozone 某種程度上是可以解決這樣的問題的, 但是在這些資料庫儲存格式普及之前,HDSF 還是目前在大資料領域的一個實施的標準。
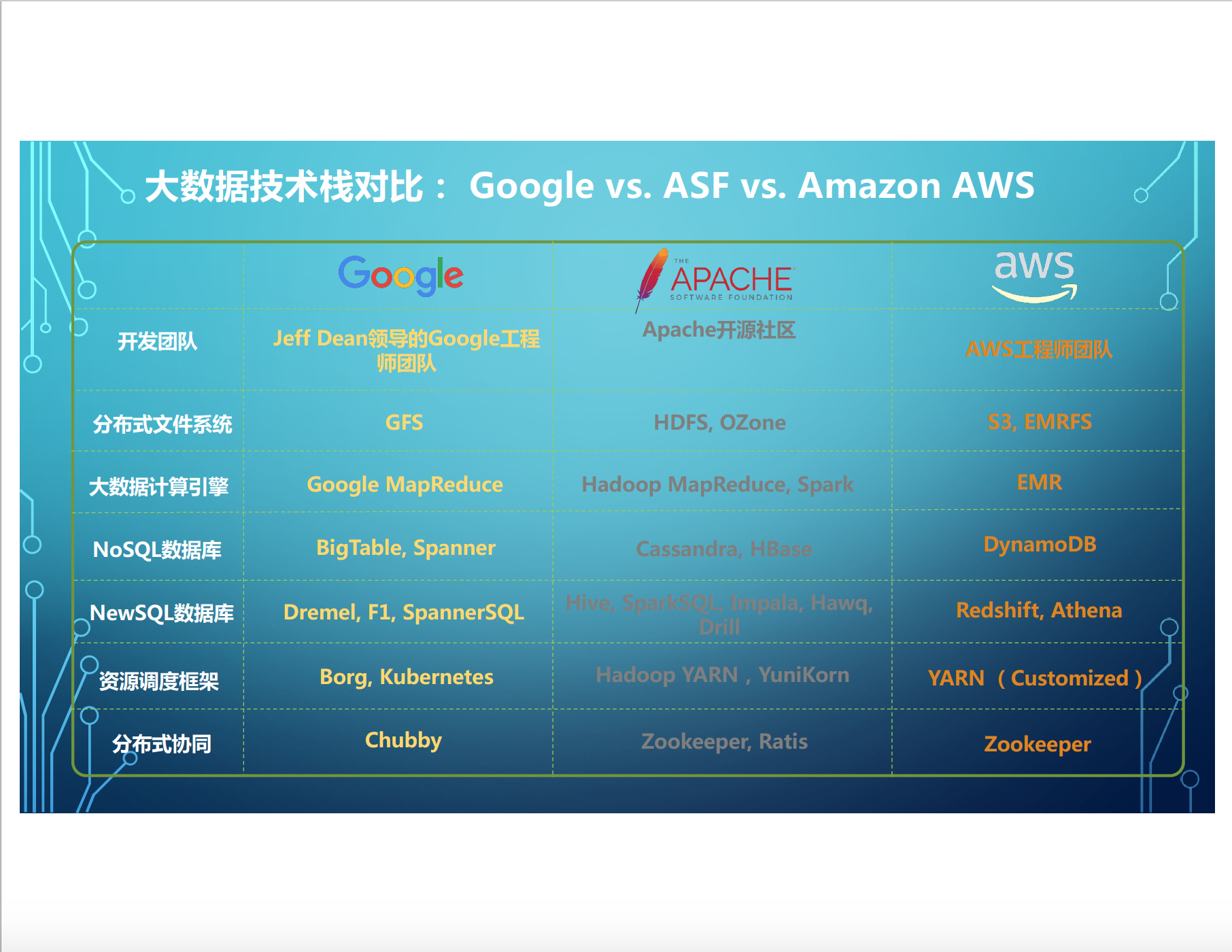
這裡可以說一下整個大資料的技術棧其實有3個路線: Google基本上是自成一體的。另外占主導地位是Apacha基金會。 Apacha的開源社群,包括各種專案,跟 Google去對標,甚至有些是走在Google之前。還有就是AWS, 它作為一個雲服務,很容易在雲上進行落地的。這裡有一個簡單對比,就包括,分散式檔案系統,大資料的計算引擎, NoSQL的資料庫,還有New SQL的資料庫 (Big SQL就是大資料的新的資料倉庫),以及資源排程框架,包括分散式協同, 都是有很多對應的關係。可以看到Apache的很多專案,包括跟這次主題的Cassandra專案, 都是在業界非常 popular, 很多大資料業者目前從事的工作降低了相應的壁壘,整體的生態是非常蓬勃的。

雲和開源的時代是最好的技術創新的時代,雲跟開源其實可能天然就無法分開。對於雲端計算而言,開源的價值在於什麼呢? 它是一個開放的生態, 能打造事實標準,幫助新技術快速推廣。 傳統上來說,我們的很多新技術要落地, 它面臨很多產業的挑戰,包括場景的限制以及市場碎片化 ,包括標準難統一等等,甚至包括端到端很難整合起來。 但是開源方案天然就很容易推廣, 開源方案自帶流量,它的應用場景是非常豐富的。 因為它的很多使用者接受意願高,他們可以去幫助優化我們的場景,幫我們去貢獻相應的feature。 開源天然就是標準,它可以統一介面,也易於整合。

對開源軟體而言,雲端計算也是很有意義的, 有好幾個層面它可以加速開源技術的落地, 商業化的落地也好,或者是應用落地也好,它都是一個很好的技術。 傳統對於開源軟體來說有很大的挑戰, 站在產業的角度, 第一就是,它的贏利模式可能不是那麼直接,不是那麼清晰;第二就是, 開源的方案要去實際使用的時候可能會面臨一些相應的問題。但在雲上的時候,它是一鍵部署, 用一鍵部署的方式來去推廣使用。它是可以用分鐘級的方式去佈局使用的,包括它的贏利模式非常清晰,很容易按需付費。 對開源專案來說, 雲是天然的一個比較適合去推廣的平臺和商業化落地的平臺。
所以說,我們認為,在雲和開源的時代,未來可能是把資料價值融入到各行各業,用技術打造智慧互聯的新時代。 我們認為資料引擎的未來一定是在雲上,一定是開源的技術。
&n