
冷飯新炒:理解Snowflake演算法的實現原理
阿新 • • 發佈:2020-08-10
## 前提
`Snowflake`(雪花)是`Twitter`開源的高效能`ID`生成演算法(服務)。
上圖是`Snowflake`的`Github`倉庫,`master`分支中的`REAEMDE`檔案中提示:初始版本於`2010`年釋出,基於`Apache Thrift`,早於`Finagle`(這裡的`Finagle`是`Twitter`上用於`RPC`服務的構建模組)釋出,而`Twitter`內部使用的`Snowflake`是一個完全重寫的程式,在很大程度上依靠`Twitter`上的現有基礎架構來執行。
而`2010`年釋出的初版`Snowflake`原始碼是使用`Scala`語言編寫的,歸檔於`scala_28`分支。換言之,**大家目前使用的`Snowflake`演算法原版或者改良版已經是十年前(當前是`2020`年)的產物,不得不說這個演算法確實比較厲害**。`scala_28`分支中有介紹該演算法的動機和要求,這裡簡單摘錄一下:
**動機:**
- `Cassandra`中沒有生成順序`ID`的工具,`Twitter`由使用`MySQL`轉向使用`Cassandra`的時候需要一種新的方式來生成`ID`(印證了架構不是設計出來,而是基於業務場景迭代出來)。
**要求:**
- 高效能:每秒每個程序至少產生`10K`個`ID`,加上網路延遲響應速度要在`2ms`內。
- 順序性:具備按照時間的自增趨勢,可以直接排序。
- 緊湊性:保持生成的`ID`的長度在`64 bit`或更短。
- 高可用:`ID`生成方案需要和儲存服務一樣高可用。
下面就`Snowflake`的原始碼分析一下他的實現原理。
## Snowflake方案簡述
`Snowflake`在初版設計方案是:
- 時間:`41 bit`長度,使用毫秒級別精度,帶有一個自定義`epoch`,那麼可以使用大概`69`年。
- 可配置的機器`ID`:`10 bit`長度,可以滿足`1024`個機器使用。
- 序列號:`12 bit`長度,可以在`4096`個數字中隨機取值,從而避免單個機器在`1 ms`內生成重複的序列號。
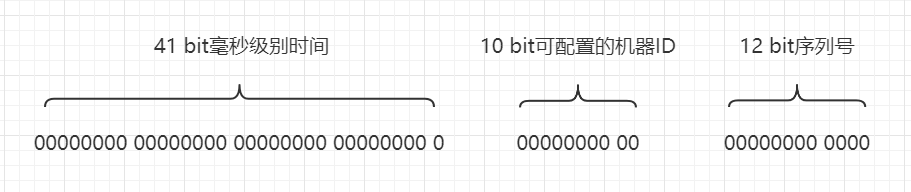
但是在實際原始碼實現中,`Snowflake`把`10 bit`的可配置的機器`ID`拆分為`5 bit`的`Worker ID`(這個可以理解為原來的機器`ID`)和`5 bit`的`Data Center ID`(資料中心`ID`),詳情見`IdWorker.scala`:
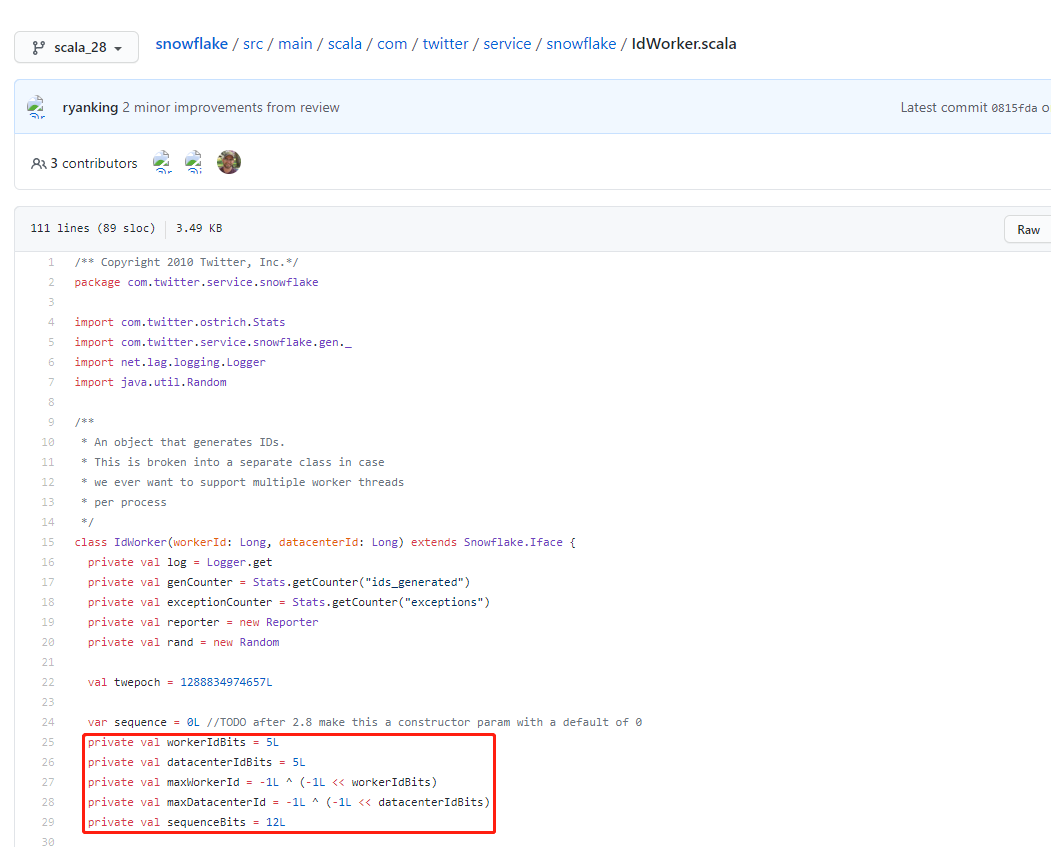
也就是說,支援配置最多`32`個機器`ID`和最多`32`個數據中心`ID`:

由於演算法是`Scala`語言編寫,是依賴於`JVM`的語言,返回的`ID`值為`Long`型別,也就是`64 bit`的整數,原來的演算法生成序列中只使用了`63 bit`的長度,要返回的是無符號數,所以在高位補一個`0`(佔用`1 bit`),那麼加起來整個`ID`的長度就是`64 bit`:

其中:
- `41 bit`毫秒級別時間戳的取值範圍是:`[0, 2^41 - 1]` => `0 ~ 2199023255551`,一共`2199023255552`個數字。
- `5 bit`機器`ID`的取值範圍是:`[0, 2^5 - 1]` => `0 ~ 31`,一共`32`個數字。
- `5 bit`資料中心`ID`的取值範圍是:`[0, 2^5 - 1]` => `0 ~ 31`,一共`32`個數字。
- `12 bit`序列號的取值範圍是:`[0, 2^12 - 1]` => `0 ~ 4095`,一共`4096`個數字。
那麼理論上可以生成`2199023255552 * 32 * 32 * 4096`個完全不同的`ID`值。
`Snowflake`演算法還有一個明顯的特徵:**依賴於系統時鐘**。`41 bit`長度毫秒級別的時間來源於系統時間戳,所以必須保證系統時間是向前遞進,不能發生**時鐘回撥**(通說來說就是不能在同一個時刻產生多個相同的時間戳或者產生了過去的時間戳)。一旦發生時鐘回撥,`Snowflake`會拒絕生成下一個`ID`。
## 位運算知識補充
`Snowflake`演算法中使用了大量的位運算。由於整數的補碼才是在計算機中的儲存形式,`Java`或者`Scala`中的整型都使用補碼錶示,這裡稍微提一下原碼和補碼的知識。
- 原碼用於閱讀,補碼用於計算。
- 正數的補碼與其原碼相同。
- 負數的補碼是除最高位其他所有位取反,然後加`1`(反碼加`1`),而負數的補碼還原為原碼也是使用這個方式。
- `+0`的原碼是`0000 0000`,而`-0`的原碼是`1000 0000`,補碼只有一個`0`值,用`0000 0000`表示,這一點很重要,補碼的`0`沒有二義性。
簡單來看就是這樣:
```shell
* [+ 11] 原碼 = [0000 1011] 補碼 = [0000 1011]
* [- 11] 原碼 = [1000 1011] 補碼 = [1111 0101]
* [- 11]的補碼計算過程:
原碼 1000 1011
除了最高位其他位取反 1111 0100
加1 1111 0101 (補碼)
```
使用原碼、反碼在計算的時候得到的不一定是準確的值,而使用補碼的時候計算結果才是正確的,記住這個結論即可,這裡不在舉例。由於`Snowflake`的`ID`生成方案中,除了最高位,其他四個部分都是無符號整數,所以四個部分的整數**使用補碼進行位運算的效率會比較高,也只有這樣才能滿足Snowflake高效能設計的初衷**。`Snowflake`演算法中使用了幾種位運算:異或(`^`)、按位與(`&`)、按位或(`|`)和帶符號左移(`<<`)。
### 異或
異或的運算規則是:`0^0=0` `0^1=1` `1^0=1` `1^1=0`,也就是位不同則結果為1,位相同則結果為0。主要作用是:
- 特定位翻轉,也就是一個數和`N`個位都為`1`的數進行異或操作,這對應的`N`個位都會翻轉,例如`0100 & 1111`,結果就是`1011`。
- 與`0`項異或,則結果和原來的值一致。
- 兩數的值互動:`a=a^b` `b=b^a` `a=a^b`,這三個操作完成之後,`a`和`b`的值完成交換。
這裡推演一下最後一條:
```shell
* [+ 11] 原碼 = [0000 1011] 補碼 = [0000 1011] a
* [- 11] 原碼 = [1000 1011] 補碼 = [1111 0101] b
a=a^b 0000 1011
1111 0101
---------^
1111 1110
b=b^a 1111 0101
---------^
0000 1011 (十進位制數:11) b
a=a^b 1111 1110
---------^
1111 0101 (十進位制數:-11) a
```
### 按位與
按位與的運算規則是:`0^0=0` `0^1=0` `1^0=0` `1^1=1`,只有對應的位都為1的時候計算結果才是1,其他情況的計算結果都是0。主要作用是:
- 清零,如果想把一個數清零,那麼和所有位為`0`的數進行按位與即可。
- 取一個數中的指定位,例如要取`X`中的低`4`位,只需要和`zzzz...1111`進行按位與即可,例如取`1111 0110`的低`4`位,則`11110110 & 00001111`即可得到`00000110`。
### 按位或
按位與的運算規則是:`0^0=0` `0^1=1` `1^0=1` `1^1=1`,只要有其中一個位存在1則計算結果是1,只有兩個位同時為0的情況下計算結果才是0。主要作用是:
- 對一個數的部分位賦值為`1`,只需要和對應位全為`0`的數做按位或操作就行,例如`1011 0000`如果低`4`位想全部賦值為`1`,那麼`10110000 | 00001111`即可得到`1011 1111`。
### 帶符號左移
帶符號左移的運算子是`<<`,一般格式是:`M << n`。作用如下:
- `M`的二進位制數(補碼)向左移動`n`位。
- 左邊(高位)移出部分直接捨棄,右邊(低位)移入部分全部補`0`。
- 移位結果:相當於`M`的值乘以`2`的`n`次方,並且0、正、負數通用。
- 移動的位數超過了該型別的最大位數,那麼編譯器會對移動的位數取模,例如`int`移位`33`位,實際上只移動了`33 % 2 = 1`位。
推演過程如下(假設`n = 2`):
```shell
* [+ 11] 原碼 = [0000 1011] 補碼 = [0000 1011]
* [- 11] 原碼 = [1000 1011] 補碼 = [1111 0101]
* [+ 11 << 2]的計算過程
補碼 0000 1011
左移2位 0000 1011
舍高補低 0010 1100
十進位制數 2^2 + 2^3 + 2^5 = 44
* [- 11 << 2]的計算過程
補碼 1111 0101
左移2位 1111 0101
舍高補低 1101 0100
原碼 1010 1100 (補碼除最高位其他所有位取反再加1)
十進位制數 - (2^2 + 2^3 + 2^5) = -44
```
可以寫個`main`方法驗證一下:
```java
public static void main(String[] args) {
System.out.println(-11 << 2); // -44
System.out.println(11 << 2); // 44
}
```
### 組合技巧
利用上面提到的三個位運算子,相互組合可以實現一些高效的計算方案。
**計算n個bit能表示的最大數值:**
`Snowflake`演算法中有這樣的程式碼:
```java
// 機器ID的位長度
private val workerIdBits = 5L;
// 最大機器ID ->