
揭祕!文字識別在高德地圖資料生產中的演進
導讀:豐富準確的地圖資料大大提升了我們在使用高德地圖出行的體驗。相比於傳統的地圖資料採集和製作,高德地圖大量採用了影象識別技術來進行資料的自動化生產,而其中場景文字識別技術佔據了重要位置。商家招牌上的藝術字、LOGO五花八門,文字背景複雜或被遮擋,拍攝的影象質量差,如此複雜的場景下,如何解決文字識別技術全、準、快的問題?本文分享文字識別技術在高德地圖資料生產中的演進與實踐,介紹了文字識別自研演算法的主要發展歷程和框架,以及未來的發展和挑戰。
一 背景
作為一個DAU過億的國民級軟體,高德地圖每天為使用者提供海量的查詢、定位和導航服務。地圖資料的豐富性和準確性決定了使用者體驗。傳統的地圖資料的採集和製作過程,是在資料採集裝置實地採集的基礎上,再對採集資料進行人工編輯和上線。這樣的模式下,資料更新慢、加工成本高。為解決這一問題,高德地圖採用影象識別技術從採集資料中直接識別地圖資料的各項要素,實現用機器代替人工進行資料的自動化生產。通過對現實世界高頻的資料採集,運用影象演算法能力,在海量的採集圖片庫中自動檢測識別出各項地圖要素的內容和位置,構建出實時更新的基礎地圖資料。而基礎地圖資料中最為重要的是POI(Point of Interest)和道路資料,這兩種資料可以構建出高德地圖的底圖,從而承載使用者的行為與商家的動態資料。
影象識別能力決定了資料自動化生產的效率,其中場景文字識別技術佔據了重要位置。不同採集裝置的影象資訊都需要通過場景文字識別(Scene Text Recognition,STR)獲得文字資訊。這要求我們致力於解決場景文字識別技術全、準、快的問題。在POI業務場景中,識別演算法不僅需要儘可能多的識別街邊新開商鋪的文字資訊, 還需要從中找出擁有99%以上準確率的識別結果,從而為POI名稱的自動化生成鋪平道路;在道路自動化場景中,識別演算法需要發現道路標誌牌上細微的變化,日處理海量回傳資料,從而及時更新道路的限速、方向等資訊。與此同時,由於採集來源和採集環境的複雜性,高德場景文字識別演算法面對的影象狀況往往復雜的多。主要表現為:
-
文字語言、字型、排版豐富:商家招牌上的藝術字體,LOGO五花八門,排版形式各式各樣。
-
文字背景複雜:文字出現的背景複雜,可能有較大的遮擋,複雜的光照與干擾。
-
影象來源多樣:影象採集自低成本的眾包裝置,成像裝置引數不一,拍攝質量差。影象往往存在傾斜、失焦、抖動等問題。
由於演算法的識別難度和識別需求的複雜性,已有的文字識別技術不能滿足高德高速發展的業務需要,因此高德自研了場景文字識別演算法,並迭代多年,為多個產品提供識別能力。
二 文字識別技術演進與實踐
STR演算法發展主要歷程
場景文字識別(STR)的發展大致可以分為兩個階段,以2012年為分水嶺,分別是傳統影象演算法階段和深度學習演算法階段。
傳統影象演算法
2012年之前,文字識別的主流演算法都依賴於傳統影象處理技術和統計機器學習方法實現,傳統的文字識別方法可以分為影象預處理、文字識別、後處理三個階段:
-
影象預處理:完成文字區域定位,文字矯正,字元切割等處理,核心技術包括連通域分析,MSER,仿射變換,影象二值化,投影分析等;
-
文字識別:對切割出的文字進行識別,一般採用提取人工設計特徵(如HOG特徵等)或者CNN提取特徵,再通過機器學習分類器(如SVM等)進行識別;
-
後處理:利用規則,語言模型等對識別結果進行矯正。
傳統的文字識別方法,在簡單的場景下能達到不錯的效果,但是不同場景下都需要獨立設計各個模組的引數,工作繁瑣,遇到複雜的場景,難以設計出泛化效能好的模型。
深度學習演算法
2012年之後,隨著深度學習在計算機視覺領域應用的不斷擴大,文字識別逐漸拋棄了原有方法,過渡到深度學習演算法方案。在深度學習時代,文字識別框架也逐漸簡化,目前主流的方案主要有兩種,一種是文字行檢測與文字識別的兩階段方案,另一種是端到端的文字識別方案。
1)兩階段文字識別方案
主要思路是先定位文字行位置,然後再對已經定位的文字行內容進行識別。文字行檢測從方法角度主要分為基於文字框迴歸的方法[1],基於分割或例項分割的方法[2],以及基於迴歸、分割混合的方法[3],從檢測能力上也由開始的多向矩形框發展到多邊形文字[2],現在的熱點在於解決任意形狀的文字行檢測問題。文字識別從單字檢測識別發展到文字序列識別,目前序列識別主要又分為基於CTC的方法[4]和基於Attention的方法[5]。
2)端到端文字識別方案[6]
通過一個模型同時完成文字行檢測和文字識別的任務,既可以提高文字識別的實時性,同時因為兩個任務在同一個模型中聯合訓練,兩部分任務可以互相促進效果。
文字識別框架
高德文字識別技術經過多年的發展,已經有過幾次大的升級。從最開始的基於FCN分割、單字檢測識別的方案,逐漸演進到現有基於例項分割的檢測,再進行序列、單字檢測識別結合的方案。與學術界不同,我們沒有采用End-to-End的識別框架,是由於業務的現實需求所決定的。End-to-End框架往往需要足夠多高質量的文字行及其識別結果的標註資料,但是這一標註的成本是極為高昂的,而合成的虛擬資料並不足以替代真實資料。因此將文字的檢測與識別拆分開來,有利於分別優化兩個不同的模型。
如下圖所示,目前高德採用的演算法框架由文字行檢測、單字檢測識別、序列識別三大模組構成。文字行檢測模組負責檢測出文字區域,並預測出文字的掩模用於解決文字的豎直、畸變、彎曲等失真問題,序列識別模組則負責在檢測出的文字區域中,識別出相應的文字,對於藝術文字、特殊排列等序列識別模型效果較差的場景,使用單字檢測識別模型進行補充。
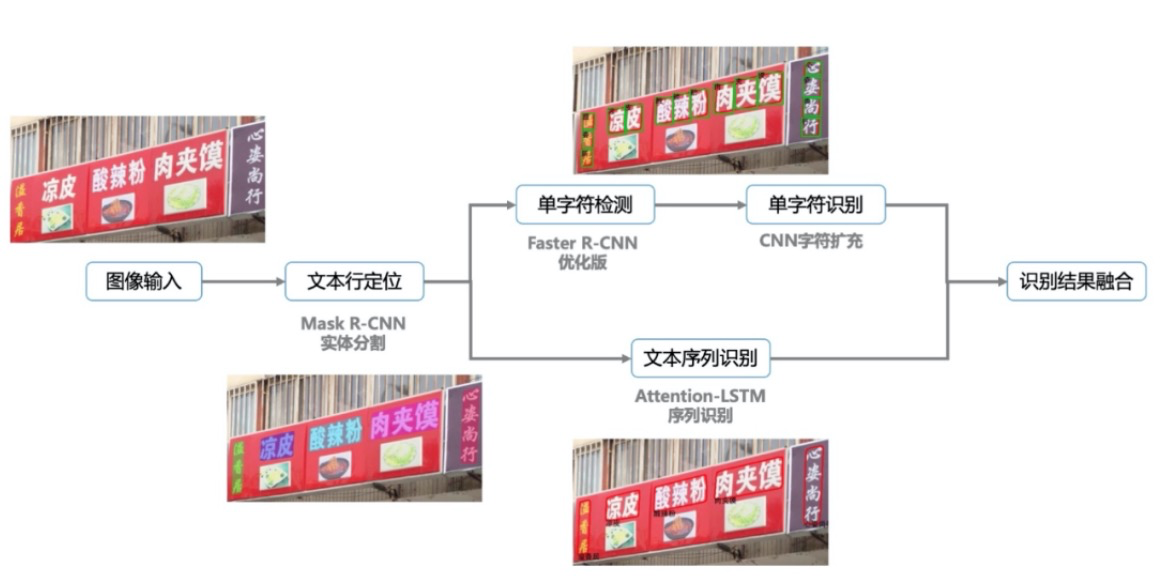
文字識別框架
文字行檢測
自然場景中的文字區域通常是多變且不規則的,文字的尺度大小各異,成像的角度和成像的質量往往不受控制。同時不同採集來源的影象中文字的尺度變化較大,模糊遮擋的情況也各不相同。我們根據實驗,決定在兩階段的例項分割模型的基礎上,針對實際問題進行了優化。
文字行檢測可同時預測文字區域分割結果及文字行位置資訊,通過整合DCN來獲取不同方向的文字的特徵資訊,增大mask分支的feature大小並整合ASPP模組,提升文字區域分割的精度。並通過文字的分割結果生成最小外接凸包用於後續的識別計算。在訓練過程中,使用online的資料增廣方法,在訓練過程中對資料進行旋轉、翻轉、mixup等,有效的提高了模型的泛化能力。具體檢測效果如下所示:

檢測結果示例
目前場景文字檢測能力已經廣泛應用於高德POI、道路等多個產品中,為了驗證模型能力,分別在ICDAR2013(2018年3月)、ICDAR2017-MLT(2018年10月)、ICDAR2019-ReCTS公開資料集中進行驗證,並取得了優異的成績。

文字行檢測競賽成績
文字識別
根據背景的描述,POI和道路資料自動化生產對於文字識別的結果有兩方面的需求,一方面是希望文字行內容儘可能完整識別,另外一方面對於演算法給出的結果能區分出極高準確率的部分(準確率大於99%)。不同於一般文字識別評測以單字為維度,我們在業務使用中,更關注於整個文字行的識別結果,因此我們定義了符合業務使用需求的文字識別評價標準:
-
文字行識別全對率:表示文字識別正確且讀序正確的文字行在所有文字行的佔比。
-
文字行識別高置信佔比:表示識別結果中的高置信度部分(準確率大於99%)在所有文字行的佔比。
文字行識別全對率主要評價文字識別在POI名稱,道路名稱的整體識別能力,文字行識別高置信佔比主要評價演算法對於拆分出識別高準確率部分的能力,這兩種能力與我們的業務需求緊密相關。為了滿足業務場景對文字識別的需求,我們針對目前主流的文字識別演算法進行了調研和選型。
文字識別發展到現在主要有兩種方法,分別是單字檢測識別和序列識別。單字檢測識別的訓練樣本組織和模型訓練相對容易,不被文字排版的順序影響。缺點在某些"上下結構","左右結構"的漢字容易檢測識別錯誤。相比之下序列識別包含更多的上下文資訊,而且不需要定位單字精確的位置,減小因為漢字結構導致的識別損失。但是現實場景文字的排版複雜,"從上到下","從左到右"排版會導致序列識別效果不穩定。結合單字檢測識別和序列識別各自的優缺點,採用互補的方式提高文字識別的準確率。
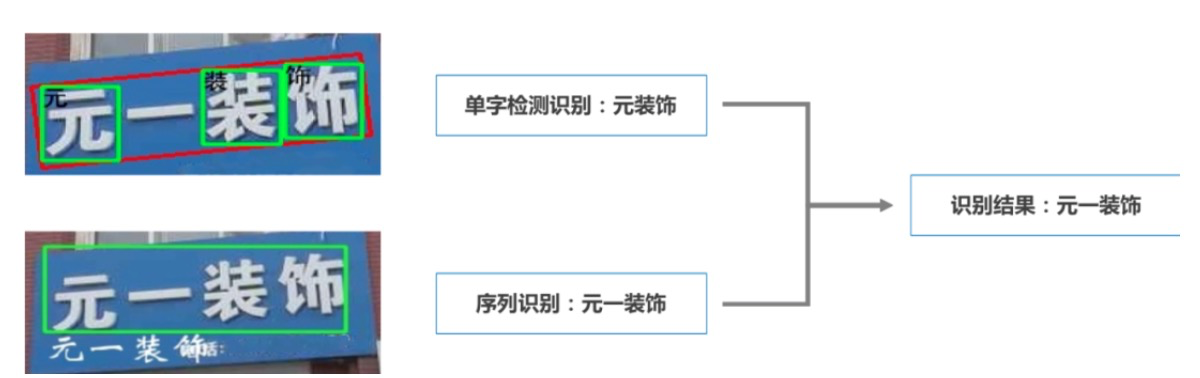
單字檢測識別和序列識別結果融合
1)單字檢測識別
單字檢測採用Faster R-CNN的方法,檢測效果滿足業務場景需求。單字識別採用SENet結構,字元類別支援超過7000箇中英文字元和數字。在單字識別模型中參考identity mapping的設計和MobileNetV2的結構,對Skip Connections和啟用函式進行了優化,並在訓練過程中也加入隨機樣本變換,大幅提升文字識別的能力。在2019年4月,為了驗證在文字識別的演算法能力,我們在ICDAR2019-ReCTS文字識別競賽中獲得第二名的成績(準確率與第一名相差0.09%)。

單字檢測識別效果圖
2)文字序列識別
近年來,主流的文字序列識別演算法如Aster、DTRT等,可以分解為文字區域糾正,文字區域特徵提取、序列化編碼影象特徵和文字特徵解碼四個子任務。文字區域糾正和文字區域特徵提取將變形的文字行糾正為水平文字行並提取特徵,降低了後續識別演算法的識別難度。序列化編碼影象特徵和文字特徵解碼(Encoder-Decoder的結構)能在利用影象的紋理特徵進行文字識別的同時,引入較強的語義資訊,並利用這種上下文的語義資訊來補全識別結果。
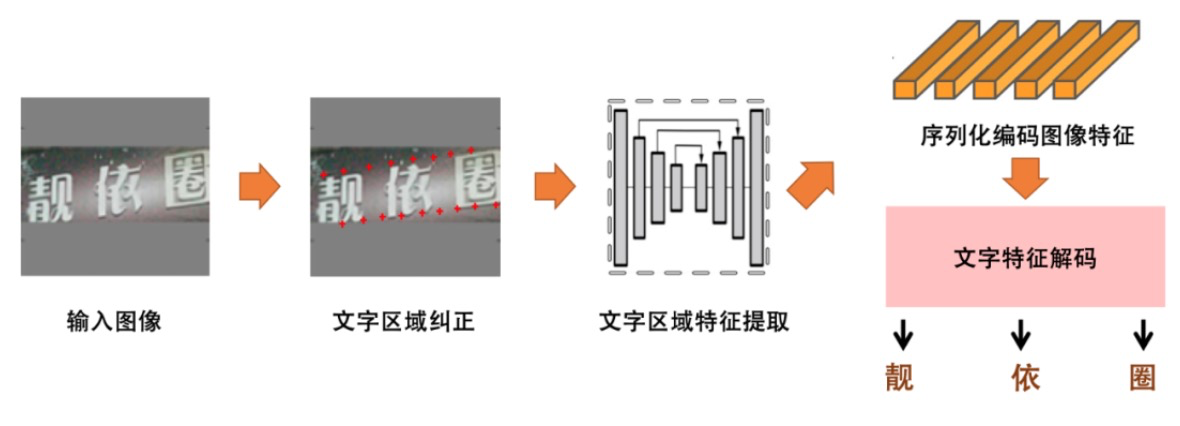
通用序列識別結構
在實際應用中,由於被識別的目標主要以自然場景的短中文字為主,場景文字的幾何畸變、扭曲、模糊程度極為嚴重。同時希望在一個模型中識別多個方向的文字,因此我們採用的是的TPS-Inception-BiLSTM-Attention結構來進行序列識別。主要結構如下所示:
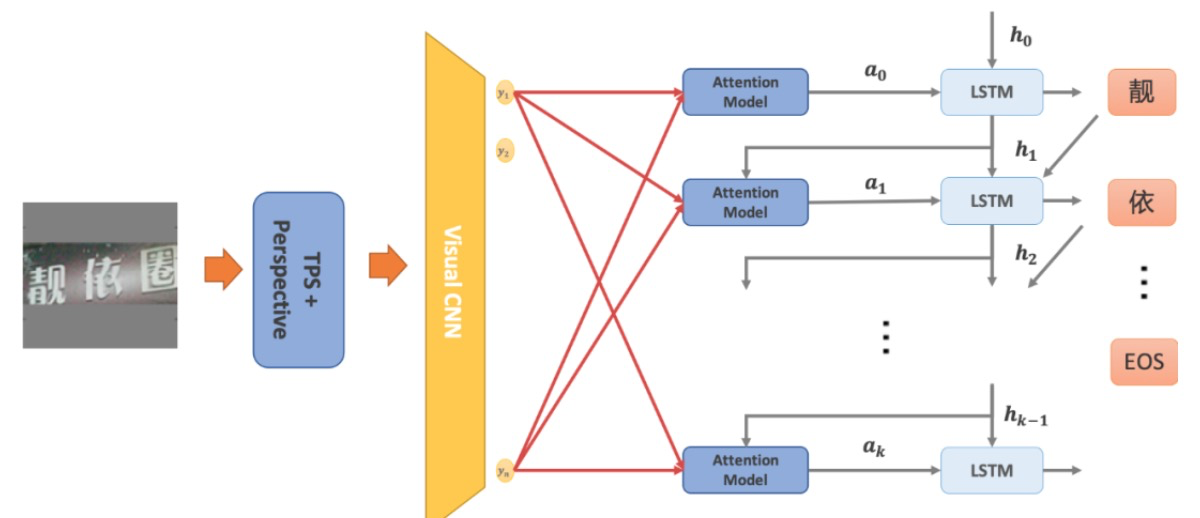
文字序列識別模型
對於被檢測到的文字行,基於角點進行透視變換,再使用TPS變換獲得水平、豎直方向的文字,按比例縮放長邊到指定大小,並以灰色為背景padding為方形影象。這一預處理方式既保持了輸入影象語義的完整,同時在訓練和測試階段,影象可以在方形範圍內自由的旋轉平移,能夠有效的提高彎曲、畸變文字的識別效能。將預處理完成的影象輸入CNN中提取影象特徵。再使用BiLSTM編碼成序列特徵,並使用Attention依次解碼獲得預測結果。如下圖所示,這一模型通過注意力機制在不同解碼階段賦予影象特徵不同的權重,從而隱式表達預測字元與特徵的對齊關係,實現在一個模型中同時預測多個方向文字。文字序列識別模型目前已覆蓋英文、中文一級字型檔和常用的繁體字字型檔,對於藝術文字、模糊文字具有較好的識別效能。

序列識別效果
3)樣本挖掘&合成
在地圖資料生產業務中經常會在道路標誌牌中發現一些生僻的地點名稱或者在POI牌匾中發現一些不常見的字甚至是繁體字,因此在文字識別效果優化中,除了對於模型的優化外,合理補充缺字、少字的樣本也是非常重要的環節。為了補充缺字、少字的樣本,我們從真實樣本挖掘和人工樣本合成兩個方向入手,一方面結合我們業務的特點,通過資料庫中已經完成製作的包含生僻字的名稱,反向挖掘出可能出現生僻字的影象進行人工標註,另一方面,我們利用影象渲染技術人工合成文字樣本。實際使用中,將真實樣本和人工合成樣本混合使用,大幅提升文字識別能力。

樣本挖掘和合成方案
文字識別技術小結
高德文字識別演算法通過對演算法結構的打磨,和多識別結果的融合,滿足不同使用場景的現實需要。同時以文字識別為代表的計算機視覺技術,已廣泛應用於高德資料自動化生產的各個角落,在部分採集場景中,機器已完全代替人工進行資料的自動化生產。POI資料中超過70%的資料都是由機器自動化生成上線,超過90%的道路資訊資料通過自動化更新。資料工藝人員的技能極大簡化,大幅節約了培訓成本和支出開銷。
三 未來發展和挑戰
目前高德主要依賴深度學習的方式解決場景文字的識別問題,相對國外地圖資料,國內漢字的基數大,文字結構複雜導致對資料多樣性的要求更高,資料不足成為主要痛點。另外,影象的模糊問題往往會影響自動化識別的效能和資料的製作效率,如何識別模糊和對模糊的處理也是高德的研究課題之一。我們分別從資料,模型設計層面闡述如何解決資料不足和模糊識別的問題,以及如何進一步提高文字識別能力。
資料層面
資料問題很重要,在沒有足夠的人力物力標註的情況下,如何自動擴充資料是影象的一個通用研究課題。其中一個思路是通過資料增廣的方式擴充資料樣本。Google DeepMind在CVPR 2019提出AutoAugment的方法, 主要通過用強化學習的方法尋找最佳的資料增廣策略。另一種資料擴充的解決辦法是資料合成,例如阿里巴巴達摩院的SwapText利用風格遷移的方式完成資料生成。
模型層面
模糊文字的識別
模糊通常造成場景識別文字未檢測和無法識別的問題。在學術界超解析度是解決模糊問題的主要方式之一,TextSR通過SRGAN對文字超分的方式,還原高清文字影象,解決模糊識別的問題。對比TextSR,首爾大學和馬薩諸塞大學在Better to Follow文中提出通過GAN對特徵的超解析度方式,沒有直接生成新的影象而是將超解析度網路整合在檢測網路中,在效果接近的同時,由於其採用End-to-End的模式,計算效率大幅提高。
文字語義理解
通常人在理解複雜文字時會參考一定的語義先驗資訊,近年來隨著NLP(Natural Language Processing)技術的發展,使得計算機也擁有獲得語義資訊的能力。參考人理解複雜文字的方式,如何利用語義的先驗資訊和影象的關係提高文字識別能力是一個值得研究的課題。例如SEED在CVPR 2020提出將語言模型新增到識別模型中,通過影象特徵和語義特徵綜合判斷提高文字識別能力。
其他發展
除此之外,從雲到端也是模型發展的一個趨勢,端上化的優勢在於節約資源,主要體現在節約上傳至雲端的流量開銷和雲端伺服器的計算壓力。在端上化設計上,針對OCR演算法的研究和優化,探索高精度、輕量級的檢測和識別框架,壓縮後模型的大小和速度滿足端上部署的需要,也是我們今後需要研究的一個課題。
溫馨提示:由阿里巴巴高德地圖發起,阿里雲天池平臺作為支撐平臺的AMAP-TECH演算法大賽初賽已經開啟,賽題為基於車載視訊影象的動態路況分析,權威評委、豐厚獎金、終面通道、榮譽證書,歡迎同學們踴躍參與,一起用技術幫助更多人美好出行!
初賽時間:7月8日-8月31日(UTC+8)。
更多比賽詳情:https://tianchi.aliyun.com/competition/entrance/531809/introduction

相關推薦
揭祕!文字識別在高德地圖資料生產中的演進
導讀:豐富準確的地圖資料大大提升了我們在使用高德地圖出行的體驗。相比於傳統的地圖資料採集和製作,高德地圖大量採用了影象識別技術來進行資料的自動化生產,而其中場景文字識別技術佔據了重要位置。商家招牌上的藝術字、LOGO五花八門,文字背景複雜或被遮擋,拍攝的影象質量差,如此複雜的場景下,如何解決文字識別技術全、準
關於高德地圖在iOS中呼叫騎行導航
SDK中實時導航時可以進行不同的路線規劃,這塊又跳到各自的路徑規劃頁面,或者串聯不起來。高德給的demo中也沒有騎行導航的相關示例,網上也查不到相關有用的資訊,所以只能自己深入檢視SDK,發現如果想要實現在移動端的騎行導航,步驟如下: 1、獲取起始點和終點的經緯度座標
高德地圖大批量資料(上萬)畫歷史軌跡實現方案
轉載請註明出處:https://www.cnblogs.com/Joanna-Yan/p/9896180.html 需求:裝置傳回伺服器的軌跡點,需要在web地圖上顯示。包括畫座標點覆蓋物、軌跡路線圖。當資料量達到一定量時,介面出現卡頓。問題出現幾天前端人員都未解決。 第一反應,大量的覆蓋物肯
高德地圖全國各城市POI資料
目前爬了這麼多。都是用Arcgis驗證過的,基本上都是完整的了! 因最近湊考試費用,所以賤賣TAT!!! 每座城市視情況而定,畢竟一二三線城市POI資料量不一樣。 所以價格在39-79之間!!已經比很多人都便宜了!!! 如果你多跟我說幾句好話,還可以酌情講價 需要其他城市的可以跟我講
高德地圖和百度地圖資料下載
百度地圖對開發者很友好,介面全面針對手機開發的應用場景提供了兩套解決方案。 一種是原生的內嵌SDK的形式,還有html5輕量級的解決方案(JavaScript API 極速版)。座標資料管理提供了LBS雲,如果只是做簡單的地圖應用這個資料管理就足夠用了。技術
百度高德地圖poi資料下載
對於地圖產品而言,某個地理位置周邊的資訊,稱之為 POI 。百度地圖的官方文件中是這麼解釋的:位置資料,point of information。不過網路上也有其他的說法,point of interest ,地圖上任何
百度地圖、高德地圖的資料下載
POI資料:嚴格來說屬於向量資料,不過是最簡單的向量資料,換句話來說就是座標點標註資料。也是電子地圖上最常用的資料圖層。 我們日常在電子地圖上所使用的資料都是POI資料(就是地圖上常見的那種標個氣球的點)。 POI資料只是資訊關聯座標點的資料,不涉及到線和麵,是最簡單的向量資料,用於簡單的地
2018年高德地圖POI全國資料下載
全國商戶、樓宇、社群、公交,景點、學校、加油站,汽車維修與服務等各類地圖資料,有經緯度,電話。2018全國最新poi資料資料,詳細到樓棟出入口。 對於地圖產品而言,某個地理位置周邊的資訊,稱之為 POI 。百度地圖的官方文件中是這麼解釋的:位置資料,poin
Cesium 呼叫高德地圖天地圖本地瓦片資料
網上看到了geoserver+cesium+全能地圖下載器的離線使用組合,但是遇到的問題是,如果將下載器的瓦片資料轉換成geotiff的大圖的話,伺服器需要消耗大量的資源用於對tiff大圖的切割,於是思考如何實現cesium直接讀取瓦片資料。 首先看高德地圖的瓦片伺服器,是
全國百度高德地圖poi資料下載
2018年11月11日 13:33:00 wanjiawen0260 閱讀數:15 標籤: poi
使用高德地圖仿最新版微信傳送位置實現,相似度高達99.99%!!!
背景 其實程式猿要開發一個demo的背景,都!一!樣! 說什麼為了社會進步,為了挑戰自我,都!是!瞎!扯!蛋! 無非就是一個背景,產品經理要求實現該功能!!! 廢話少說,先上gif為敬! 功能 沒什麼好說的,用上最新版微信,開啟“位置”—“傳
高德地圖擁堵榜資料獲取
1.中國主要城市擁堵排行(5分鐘)實際獲得前100名 url: https://report.amap.com/ajax/getCityRank.do 程式碼 import pandas as pd import requests import time wh
通過JAVA從高德地圖URL連接獲取json資料 解析並存入資料庫的程式舉例
首先 進入高德開放平臺 按官網教程獲取key 這裡以杭州某區域車站資訊舉例 通過線上解析工具獲取json格式的資料 通過此資料建立實體類 package geturl; import java.util.List; public class JsonBean
基於高德地圖的交通資料分析
前言 設計需求在於每天上班早高峰期,每次都提前出門,雖然有地圖可以實時檢視路況,但是再過一陣時間 就會異常的堵車如果通過資料監控分析每天指定路段在什麼時間段相應的擁堵情況,即可合理控制時間. 有時候很早出門,卻堵車堵得依然快遲到,而有時出門時間晚了,卻發現那個
【高德地圖API】從零開始學高德JS API(七)——定位方式大揭祕
摘要:關於定位,分為GPS定位和網路定位2種。GPS定位,精度較高,可達到10米,但室內不可用,且超級費電。網路定位,分為wifi定位和基站定位,都是通過獲取wifi或者基站資訊,然後查詢對應的wifi或者基站位置資料庫,得到的定位地點。定位資料庫可以不斷完善不斷補充,所以,
高德地圖之根據矩形範圍爬取範圍內的分類POI資料
之前寫了一篇在城市範圍內根據關鍵字爬取POI資料的部落格,由於一個城市的POI資料量太大,高德地圖介面容易返回錯誤資料,因此有個比較好的辦法就是藉助高德地圖POI搜尋中根據多邊形範圍或矩形範圍搜尋POI資料,具體分為兩個步驟:其一是將城市分為多個小矩形(得到左上和右
java中從高德地圖爬取資料
最近一個人負責公司的一個app專案開發,需要從高德地圖爬取杭州市全部的超市資訊,放入mongodb的資料庫中。做地理位置查詢。(mongodb這部分有時間補上) 首先去高德地圖建立一個開發者賬號,獲取一個開發web服務的高德key.這個是必須要有的,可以用我
從高德地圖抓取資料
resultStr1 + =“ < DIV ID = 'DIVID”+第(i + 1)+“' 的onmouseover = 'openMarkerTipById1(”+ I +“時,此)' 的onmouseout= 'onmouseout_MarkerStyle(
百度高德地圖全國poi資料
對於地圖產品而言,某個地理位置周邊的資訊,稱之為 POI 。本文作者將簡單地聊聊自己對於地圖產品中POI的瞭解和看法。 作為一個標準的路痴,以前信奉的一句話是「地圖長在嘴巴上」,到一個不熟悉的地方,多問幾個人,總能到達目的地。後來,隨著智慧機的普及與地圖
百度地圖、高德地圖的資料從哪裡得到的?
這個問題比較複雜,要真儘量說清楚的話需要費不少口舌,因此答案會比較長,請看官不妨耐心點。要說資料來源,首先得對地圖資料做一個分類,因為不同分類的資料,其來源,採集方法都是有大不同的。 並非想說上面高票答案的分類方式不對或者不可以,只是說,其分類方式對於完全說明這個問題,可能不是太合適和合理。裡面的一些觀點和描