
PowerJob 線上日誌飽受好評的祕訣:小但實用的分散式日誌系統
阿新 • • 發佈:2020-08-26
> 本文適合有 Java 基礎知識的人群

作者:HelloGitHub-**Salieri**
HelloGitHub 推出的[《講解開源專案》](https://github.com/HelloGitHub-Team/Article)系列。
> 專案地址:
>
> https://github.com/KFCFans/PowerJob
PowerJob 的線上日誌一直是飽受好評的一個功能,它能在前端介面實時展示開發者在任務處理過程中輸出的日誌,幫助開發者更好的監控任務的執行情況。其功能展示如下圖所示(前端介面略醜,請自動忽略~)。
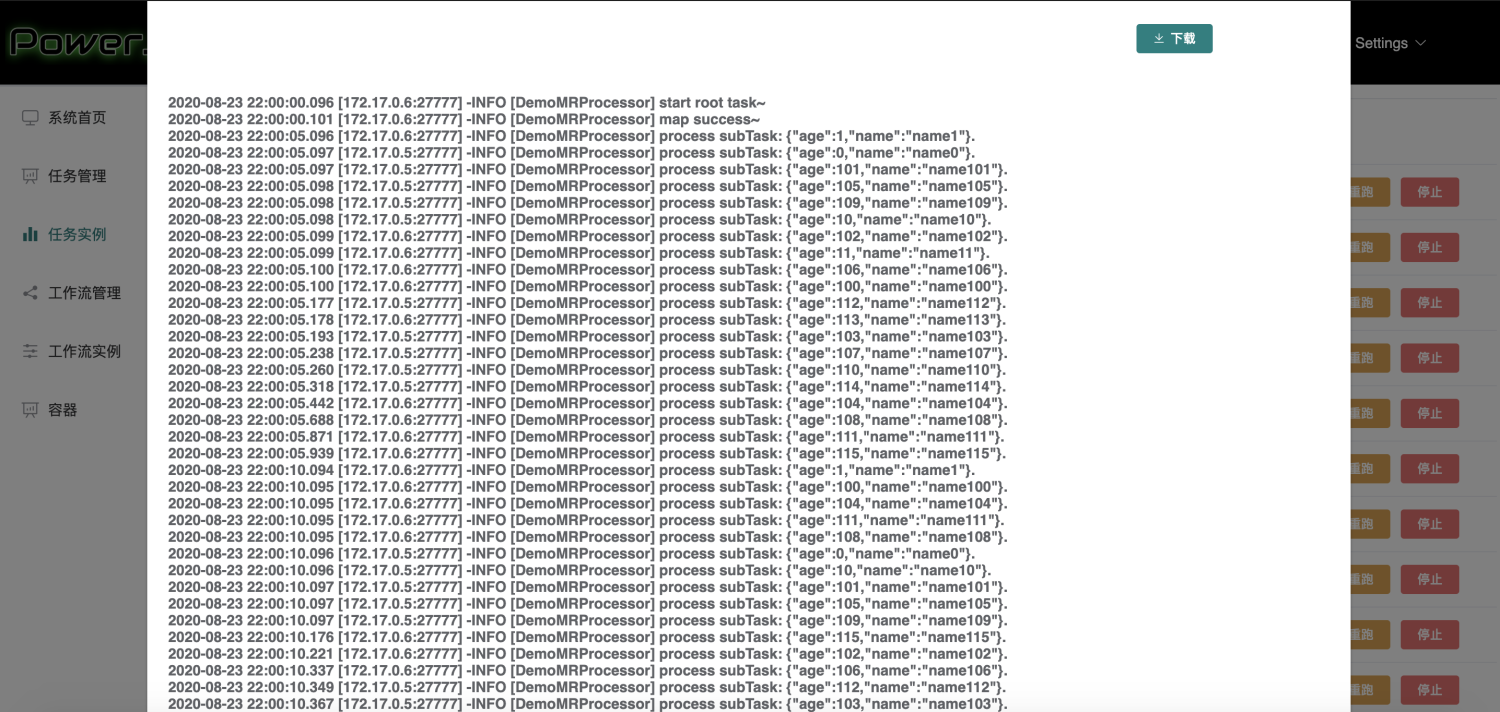
線上日誌這個功能,乍一聽很簡單,無非 worker 向 server 發日誌資料,server 接受後前端展示。但對於 PowerJob 這種任意節點都支援分散式部署且支援分散式計算的系統來說,還是存在著不少難點的,簡單來說,有以下幾點:
1. 多對多問題:在 PowerJob 的理想部署模式中,會存在多個 server 和多個 worker,當某個任務開始分散式計算時,其日誌散佈於各臺機器上,要想在前端統一展示,需要有收集器將分散的日誌彙集到一起。
2. 併發問題:當 worker 叢集規模較大時,一旦執行分散式計算任務,其產生的日誌 QPS 也是一個不小的數目,要想輕鬆支援百萬量級的分散式任務,需要解決併發情況下 QPS 過高的問題。
3. 排序問題:分散式計算時,日誌散佈在不同機器,即便收集彙總到同一臺機器,由於網路延遲等原因,不能保證日誌的有序性,而日誌按時間排序是強需求(否則根本沒法看啊...),因此,還需要解決大規模日誌資料的排序問題。
4. 資料的儲存問題:當日志資料量非常大時,如何高效的儲存和讀取這一批資料,也是需要解決的問題。
因此,為了完美實現線上日誌功能,PowerJob 在內部實現了一個麻雀雖小五臟俱全的**分散式日誌系統**。話不多說,下面正式開始逐一分析~
## 一、多對多問題
這個問題,其實在 PowerJob 解決多 worker 多 server 的選主問題時順帶著解決了。簡單來說,PowerJob 系統中,某一個分組下的所有 worker,在執行時都只會連線到某一臺 server。因此,日誌資料上報時,選擇當前 worker 進行上報即可。由於任務不可能跨分組執行,因此某個任務在執行過程中產生的所有日誌資料都會上報給該分組當前連線的 server,這樣就做到了日誌的收集,即日誌會彙總到負責當前分組排程的 powerjob-server,由該 server 統一處理。
## 二、併發問題
併發問題的解決也不難。
大家一定都聽說過訊息中介軟體,也知道訊息中介軟體的一大功能為削峰。引入訊息中介軟體後,把原來同步式的呼叫轉化為非同步的間接推送,中間通過一個佇列在一端承接瞬時的流量洪峰,在另一端平滑地將訊息推送出去。訊息中介軟體就像水庫一樣,攔蓄上游的洪水,削減進入下游河道的洪峰流量,從而達到減免洪水災害的目的。
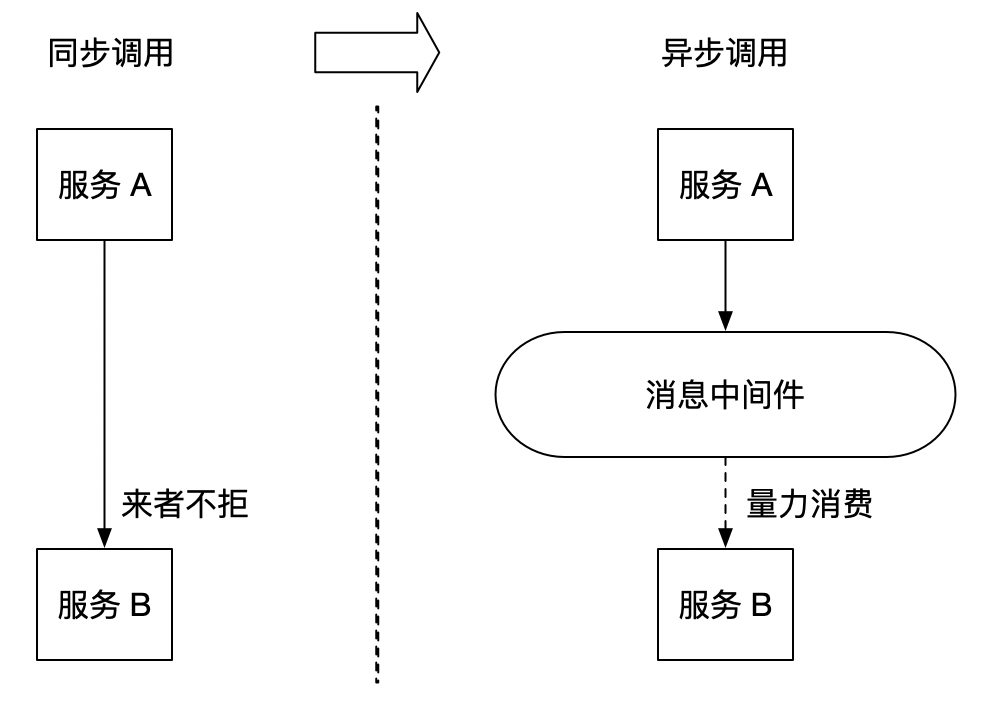
PowerJob 在處理日誌的高併發問題時也採用了類似的方式,通過引入本地佇列,對需要傳送給 server 的訊息進行快取,再定時將訊息批量傳送給 server,化同步為非同步,並引入批量傳送的機制,充分利用每一次資料傳輸的機會發送儘可能多的資料,從而降低對 server 的衝擊。
## 三、排序問題
### 3.1 日誌的儲存
將排序問題之前,先來聊一聊 server 怎麼處理接收到的日誌資料,也就是如何**儲存**日誌。
這個抉擇其實並不難,用一下簡單的排除法就能獲取正確答案:
1. 存內部還是存外部?PowerJob 作為任務排程中介軟體,最小依賴一直是需要牢牢把控的指導思想。因此,在已知最小依賴僅為資料庫的情況下,似乎不太可能使用外部的儲存介質,至少不能把收到的日誌直接傳送到外部儲存介質,否則又是一波龐大的 QPS,會對依賴的外部元件有非常高的效能要求,不符合框架設計原則。因此,線上日誌的第一級儲存介質應該由 server 本身來承擔。
2. 存記憶體還是磁碟?既然確定了由 server 來儲存原始資料,那麼就面臨記憶體和磁碟二選一的問題了。但,這還用選嗎?成百上千萬的文字資料存記憶體,這不妥妥的 OutOfMemory 嗎?顯然,存磁碟。
經過一波簡單的排除法,日誌的一級儲存方案確定了:server 的本機磁碟。那麼,存磁碟會帶來什麼問題呢?
且不說檔案操作的複雜性和難度,一個最簡單的需求就能讓這個方案跌入萬丈深淵,那就是:排序。
眾所周知,日誌必須按時間排序,否則根本沒法看。而 PowerJob 又是一個純粹的分散式系統,顯然不可能指望所有的日誌資料按順序發到 server,因此對日誌的再排序是一件必須要做的事情。但讓我們來考慮一下難度。
- 首先,日誌是純文字資料,要想做排序,首先要將整個日誌檔案變為一堆日誌記錄,即分行。
- 其次,分完行後,由於日誌是給人看的,時間肯定已經被轉化為 yyyy-MM-dd HH:mm:ss.SSS 這種方便人閱讀的格式,那麼將它反解析回可排序的時間戳又是一件麻煩事。
- 最後,也是最終 BOSS,就是排序了。要知道,之所以會選擇磁碟儲存這個方案,是因為沒有足夠的記憶體。這也就意味著,這個排序沒辦法在記憶體完成。外部排序的難度和效率,想必不用我多說了吧。同時,我也相信,大部分程式設計師(包括我在內)應該從來沒有接觸過外部排序,這趟渾水,我又何必去趟呢?

### 3.2 H2 資料庫簡介
那麼,有沒有什麼既能使用磁碟做儲存,又有排序能力的框架/軟體呢?世上會有這等好事嗎?你別說,還真有。而且是遠在天邊,近在眼前,可以說是和程式設計師形影不離的一樣東西——資料庫。
“等等,你剛才不是說,不拿資料庫作為一級儲存介質嗎?怎麼滴,出爾反爾?”
“哼,年輕人。此資料庫非彼資料庫,這個資料庫啊,是 powerjob-server 內建的嵌入式資料庫 H2”
H2 是一個用 Java 開發的嵌入式資料庫,它本身只是一個類庫,即只有一個 jar 檔案,可以直接嵌入到應用專案中。嵌入式模式下,應用在 JVM 中啟動 H2 資料庫並通過 JDBC 連線。該模式同時支援資料持久化和記憶體兩種方式。
H2 的使用很簡單,在專案中引入依賴後,便會自動隨 JVM 啟動,應用可以通過 JDBC URL 進行連線,並在 JDBC URL 中指定所使用的模式,比如對於 powerjob-server 來說,需要使用嵌入式磁碟持久化模式,因此使用以下 JDBC URL 進行連線:
```
jdbc:h2:file:~/powerjob-server/powerjob_server_db
```
同時,H2 支援相當標準的 SQL 規範,也和 Spring Data Jpa、MyBatis 等 ORM 框架完美相容,因此使用非常方便。在 powerjob-server 中,我便通過 Spring Data Jpa 來使用 H2,使用者體驗非常友好(當然,多資料來源的配置很不友好!)。
綜上,有了內建的 H2 資料庫,日誌的儲存和排序也就不再是難以解決的問題了~
### 3.3 儲存與排序
引入 H2 之後,powerjob-server 處理線上日誌的流程如下:
1. 接收來自 worker 的日誌資料,直接寫入內嵌資料庫 H2 中
2. 線上呼叫時,通過 SQL 查詢語句的 order by log_time 功能,完成日誌的排序和輸出
可見,合適的技術選型能讓問題的解決簡單很多~
## 四、一些其他的優化
以上介紹了 PowerJob 分散式日誌元件的核心原理和實現,當然,在實際使用中,還引入了許多優化,限於篇幅,這裡簡單提一下,有興趣的同學可以自己去看原始碼~
- 高頻率線上訪問降壓:如果每次使用者檢視日誌,都需要從資料庫中查詢並輸出,這個效率和速度都會非常慢。畢竟當資料量達到一定程度時,光是磁碟 I/O 就得花去不少時間。因此,powerjob-server 會為每次查詢生成快取檔案,一定時間範圍內的日誌查詢,會通過檔案快取直接返回,而不是每次都走 DB 查詢方案。
- 日誌分頁:成百上千萬條資料的背後,生成的檔案大小也以及遠遠高於正常網路頻寬所能輕鬆承載的範圍了。因此,為了在前端控制檯快速顯示線上日誌,需要引入分頁功能,一次顯示部分日誌資料。這也是一項較為複雜的檔案操作。
- 遠端儲存:所有日誌都存在 server 本地顯然不符合高可用的設計目標,畢竟換一臺 server 就意味著所有的日誌資料都丟了,因此 PowerJob 引入了 mongoDB 作為日誌的持久化儲存介質。mongodb 支援使用者直接使用其底層的分散式檔案系統 GridFS,經過我仔細的考量,認為這是一個可接受且較為強大的擴充套件依賴,因此選擇引入。
## 五、最後
好了,本期的內容就到這裡結束了,下一期,我將會大家講述 PowerJob 作為一個各個節點時刻需要進行通訊的框架,底層序列化框架該如何選擇,具體的序列化方案又該如何設計~
那麼我們下期再見嘍~
---

**關注 HelloGitHub 公