
資料結構與演算法之常用資料結構
阿新 • • 發佈:2020-08-30
# 常用資料結構
* 陣列、字串
* 連結串列
* 棧
* 佇列
* 雙端佇列
* 樹
## 陣列、字串(Array & String)
**字串轉化**
陣列和字串是最基本的資料結構,在很多程式語言中都有著十分相似的性質,而圍繞著它們的演算法面試題也是最多的。
很多時候,在分析字串相關面試題的過程中,我們往往要針對字串當中的每一個字元進行分析和處理,甚至有時候我們得先把給定的字串轉換成字元陣列之後再進行分析和處理。
**舉例**:反轉字串

**解法**:用兩個指標,一個指向字串的第一個字元 a,一個指向它的最後一個字元 m,然後互相交換。交換之後,兩個指標向中央一步步地靠攏並相互交換字元,直到兩個指標相遇。這是一種比較快速和直觀的方法。
**實現程式碼**:
```java
public static String reverseString(String str) {
if(str == null || str.length() < 0) {
return null;
}
char[] result = str.toCharArray();
int startIndex = 0;
int endIndex = result.length - 1;
char temp;
for (; endIndex > startIndex; startIndex++, endIndex--) {
temp = result[startIndex];
result[startIndex] = result[endIndex];
result[endIndex] = temp;
}
return new String(result);
}
```
**陣列的優缺點**
* 優點
* 構建非常簡單
* 能在 O(1) 的時間裡根據陣列的下標(index)查詢某個元素
* 缺點
* 構建時必須分配一段連續的空間
* 查詢某個元素是否存在時需要遍歷整個陣列,耗費 O(n) 的時間(其中,n 是元素的個數)
* 刪除和新增某個元素時,同樣需要耗費 O(n) 的時間
**例題分析**
LeetCode 第 242 題:給定兩個字串 s 和 t,編寫一個函式來判斷 t 是否是 s 的字母異位詞。
說明:你可以假設字串只包含小寫字母。
```
示例 1
輸入: s = "anagram", t = "nagaram"
輸出: true
示例 2
輸入: s = "rat", t = "car"
輸出: false
```
字母異位詞,也就是兩個字串中的相同字元的數量要對應相等。例如,s 等於 “anagram”,t 等於 “nagaram”,s 和 t 就互為字母異位詞。因為它們都包含有三個字元 a,一個字元 g,一個字元 m,一個字元 n,以及一個字元 r。而當 s 為 “rat”,t 為 “car”的時候,s 和 t 不互為字母異位詞。
**解題思路**
解題思路
一個重要的前提“假設兩個字串只包含小寫字母”,小寫字母一共也就 26 個,因此:
1. 可以利用兩個長度都為 26 的字元陣列來統計每個字串中小寫字母出現的次數,然後再對比是否相等;
2. 可以只利用一個長度為 26 的字元陣列,將出現在字串 s 裡的字元個數加 1,而出現在字串 t 裡的字元個數減 1,最後判斷每個小寫字母的個數是否都為 0。
按上述操作,可得出結論:s 和 t 互為字母異位詞。
**實現程式碼**:
```java
//方法2 時間複雜度:O(n) 空間複雜度:O(1)
public boolean isAnagram(String s, String t) {
int[] judge = new int[26];
int lens = s.length(), lent = t.length();
if(lens != lent) {
return false;
}else{
for(int i = 0; i < lens; i++) {
judge[s.charAt(i)-'a']++;
judge[t.charAt(i)-'a']--;
}
for(int i = 0; i < judge.length; i++) {
if(judge[i] != 0) {
return false;
}
}
return true;
}
}
```
## 連結串列(LinkedList)
單鏈表:連結串列中的每個元素實際上是一個單獨的物件,而所有物件都通過每個元素中的引用欄位連結在一起。
雙鏈表:與單鏈表不同的是,雙鏈表的每個結點中都含有兩個引用欄位。
**連結串列的優缺點**
* 優點
* 連結串列能靈活地分配記憶體空間;
* 能在 O(1) 時間內刪除或者新增元素,前提是該元素的前一個元素已知,當然也取決於是單鏈表還是雙鏈表,在雙鏈表中,如果已知該元素的後一個元素,同樣可以在 O(1) 時間內刪除或者新增該元素。
* 缺點
* 不像陣列能通過下標迅速讀取元素,每次都要從連結串列頭開始一個一個讀取;
* 查詢第 k 個元素需要 O(k) 時間。
**應用場景**
如果要解決的問題裡面需要很多快速查詢,連結串列可能並不適合;如果遇到的問題中,資料的元素個數不確定,而且需要經常進行資料的新增和刪除,那麼連結串列會比較合適。而如果資料元素大小確定,刪除插入的操作並不多,那麼陣列可能更適合。
**經典解法**
連結串列是實現很多複雜資料結構的基礎,經典解法如下。
**1.利用快慢指標(有時候需要用到三個指標)**
典型題目例如:連結串列的翻轉,尋找倒數第 k 個元素,尋找連結串列中間位置的元素,判斷連結串列是否有環等等。
**2. 構建一個虛假的連結串列頭**
一般用在要返回新的連結串列的題目中,比如,給定兩個排好序的連結串列,要求將它們整合在一起並排好序。又比如,將一個連結串列中的奇數和偶數按照原定的順序分開後重新組合成一個新的連結串列,連結串列的頭一半是奇數,後一半是偶數。
在這類問題裡,如果不用一個虛假的連結串列頭,那麼在建立新連結串列的第一個元素時,我們都得要判斷一下連結串列的頭指標是否為空,也就是要多寫一條 if else 語句。比較簡潔的寫法是建立一個空的連結串列頭,直接往其後面新增元素即可,最後返回這個空的連結串列頭的下一個節點即可。
**建議**
在解決連結串列的題目時,可以在紙上或者白板上畫出節點之間的相互關係,然後畫出修改的方法,既可以幫助你分析問題,又可以在面試的時候,幫助面試官清楚地看到你的思路。
**例題分析**
LeetCode 第 25 題:給你一個連結串列,每 k 個節點一組進行翻轉,請你返回翻轉後的連結串列。k 是一個正整數,它的值小於或等於連結串列的長度。如果節點總數不是 k 的整數倍,那麼請將最後剩餘的節點保持原有順序。
說明:
* 你的演算法只能使用常數的額外空間。
* 你不能只是單純的改變節點內部的值,而是需要實際的進行節點交換。
```
示例:
給定這個連結串列:1->2->3->4->5
當 k=2 時,應當返回:2->1->4->3->5
當 k=3 時,應當返回:3->2->1->4->5
```
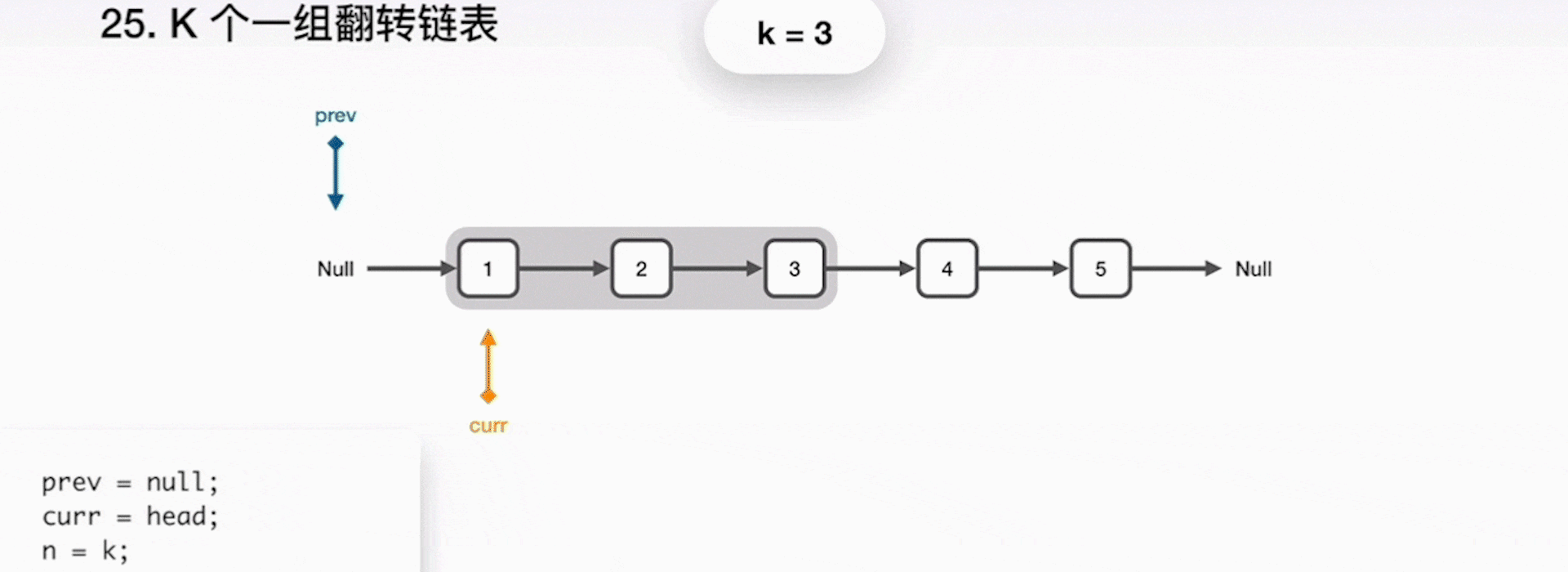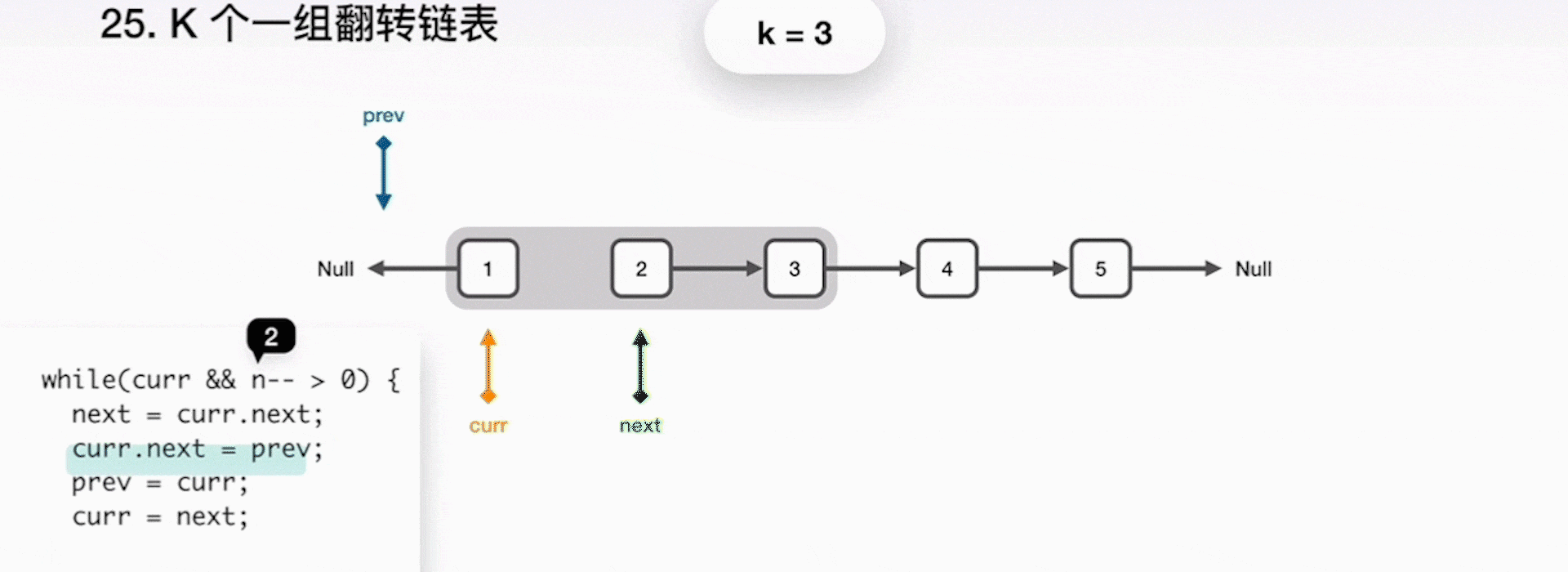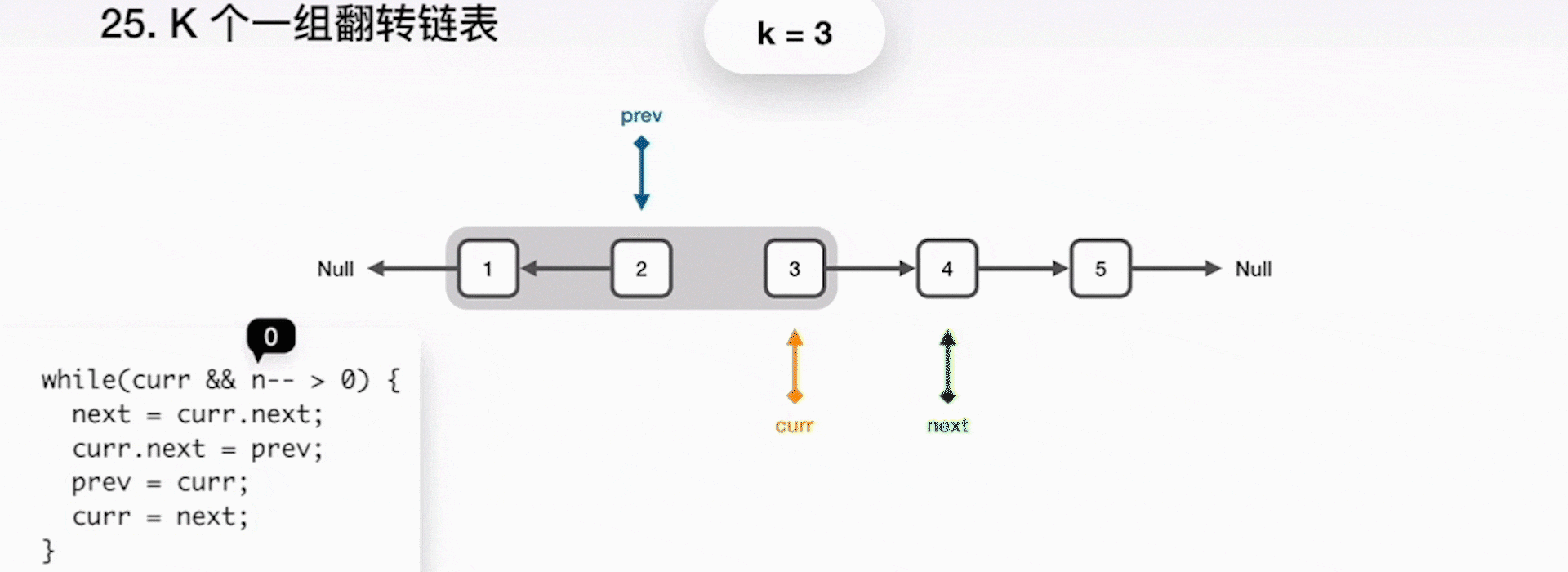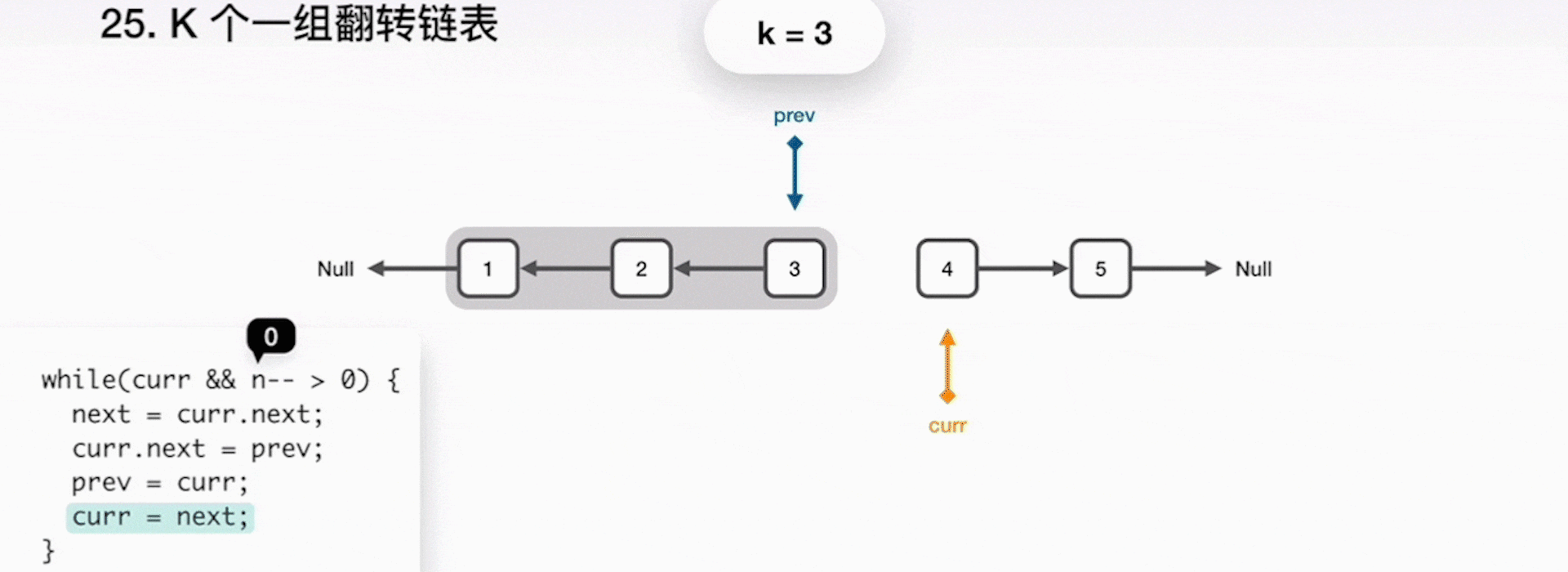
1. 將 curr 指向的下一節點儲存到 next 指標;
2. curr 指向 prev,一起前進一步;
3. 重複之前步驟,直到 k 個元素翻轉完畢;
4. 當完成了區域性的翻轉後,prev 就是最終的新的連結串列頭,curr 指向了下一個要被處理的區域性,而原來的頭指標 head 成為了連結串列的尾巴。
實現程式碼:
```java
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode prev = null, curr = head, next = null;
ListNode check = head;
int canProceed = 0, count = 0;
//檢查連結串列長度是否滿足翻轉
while(canProceed < k && check != null) {
check = check.next;
canProceed++;
}
//滿足條件進行翻轉
if(canProceed == k) {
while(count < k && curr != null) {
next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
count++;
}
if(next != null) {
//head為連結串列翻轉後的尾節點
head.next = reverseKGroup(next, k);
}
//prev為連結串列翻轉後的頭節點
return prev;
} else {
//不滿足翻轉條件直接返回head即可
return head;
}
}
}
```
## 棧(Stack)
特點:棧的最大特點就是後進先出(LIFO)。對於棧中的資料來說,所有操作都是在棧的頂部完成的,只可以檢視棧頂部的元素,只能夠向棧的頂部壓⼊資料,也只能從棧的頂部彈出資料。
實現:利用一個單鏈表來實現棧的資料結構。而且,因為我們都只針對棧頂元素進行操作,所以借用單鏈表的頭就能讓所有棧的操作在 O(1) 的時間內完成。
應用場景:在解決某個問題的時候,只要求關心最近一次的操作,並且在操作完成了之後,需要向前查詢到更前一次的操作。
如果打算用一個數組外加一個指標來實現相似的效果,那麼,一旦陣列的長度發生了改變,哪怕只是在最後新增一個新的元素,時間複雜度都不再是 O(1),而且,空間複雜度也得不到優化。
**例題分析一**
LeetCode 第 20 題:給定一個只包括 '(',')','{','}','[',']' 的字串,判斷字串是否有效。
有效字串需滿足:
1. 左括號必須用相同型別的右括號閉合。
2. 左括號必須以正確的順序閉合。
注意:空字串可被認為是有效字串。
```
示例 1
輸入: "()"
輸出: true
示例 2
輸入: "(]"
輸出: false
```
**解題思路**
將給定字串轉換成字元陣列進行遍歷,利用一個棧,遇到左括號時將對應的右括號壓入棧中,如果遇到棧為空或者右括號不等於彈棧元素(括號不匹配的情況)直接返回false,最後返回棧是否為空即可。
```java
class Solution {
public boolean isValid(String s) {
Stack stack = new Stack();
for(char c: s.toCharArray()) {
if(c == '('){
stack.push(')');
}else if(c == '['){
stack.push(']');
}else if(c == '{'){
stack.push('}');
}else if(stack.isEmpty() || c != stack.pop()){
return false;
}
}
return stack.isEmpty();
}
}
```
**例題分析二**
LeetCode 第 739 題:根據每日氣溫列表,請重新生成一個列表,對應位置的輸入是你需要再等待多久溫度才會升高超過該日的天數。如果之後都不會升高,請在該位置用 0 來代替。
提示:氣溫列表 temperatures 長度的範圍是 [1, 30000]。
```
示例:給定一個數組 T 代表了未來幾天裡每天的溫度值,要求返回一個新的陣列 D,D 中的每個元素表示需要經過多少天才能等來溫度的升高。
給定 T:[23, 25, 21, 19, 22, 26, 23]
返回 D: [ 1, 4, 2, 1, 1, 0, 0]
```
**解題思路**
第一個溫度值是 23 攝氏度,它要經過 1 天才能等到溫度的升高,也就是在第二天的時候,溫度升高到 24 攝氏度,所以對應的結果是 1。接下來,從 25 度到下一次溫度的升高需要等待 4 天的時間,那時溫度會變為 26 度。
**思路1**
最直觀的做法就是針對每個溫度值向後進行依次搜尋,找到比當前溫度更高的值,這樣的計算複雜度就是 O(n2)。
但是,在這樣的搜尋過程中,產生了很多重複的對比。例如,從 25 度開始往後面尋找一個比 25 度更高的溫度的過程中,經歷了 21 度、19 度和 22 度,而這是一個溫度由低到高的過程,也就是說在這個過程中已經找到了 19 度以及 21 度的答案,它就是 22 度。
**思路2**
可以運用一個堆疊 stack 來快速地知道需要經過多少天就能等到溫度升高。從頭到尾掃描一遍給定的陣列 T,如果當天的溫度比堆疊 stack 頂端所記錄的那天溫度還要高,那麼就能得到結果。

1. 對第一個溫度 23 度,堆疊為空,把它的下標壓入堆疊;
2. 下一個溫度 24 度,高於 23 度高,因此 23 度溫度升高只需 1 天時間,把 23 度下標從堆疊裡彈出,把 24 度下標壓入;
3. 同樣,從 24 度只需要 1 天時間升高到 25 度;
4. 21 度低於 25 度,直接把 21 度下標壓入堆疊;
5. 19 度低於 21 度,壓入堆疊;
6. 22 度高於 19 度,從 19 度升溫只需 1 天,從 21 度升溫需要 2 天;
7. 由於堆疊裡儲存的是下標,能很快計算天數;
8. 22 度低於 25 度,意味著尚未找到 25 度之後的升溫,直接把 22 度下標壓入堆疊頂端;
9. 後面的溫度與此同理。
該方法只需要對陣列進行一次遍歷,每個元素最多被壓入和彈出堆疊一次,演算法複雜度是 O(n)。
實現程式碼:
```java
class Solution {
public int[] dailyTemperatures(int[] T) {
Stack stack = new Stack();
int[] res = new int[T.length];
for(int i = 0; i < T.length; i++) {
while(!stack.isEmpty() && T[i] > T[stack.peek()]) {
int temp = stack.pop();
res[temp] = i - temp;
}
stack.push(i);
}
return res;
}
}
```
> tip:官方的API文件中的建議:“Deque介面及其實現提供了更完整和一致的LIFO堆疊操作集,這些介面應優先於此類。”,且擁有一定的速度提升。所以可以將上述實現程式碼的棧Stack改成Deque,執行速度會有一定的提升。
利用堆疊,還可以解決如下常見問題:
* 求解算術表示式的結果(LeetCode 224、227、772、770)
* 求解直方圖裡最大的矩形區域(LeetCode 84)
## 佇列(Queue)
特點:和棧不同,佇列的最大特點是先進先出(FIFO),就好像按順序排隊一樣。對於佇列的資料來說,我們只允許在隊尾檢視和新增資料,在隊頭檢視和刪除資料。
實現:可以藉助雙鏈表來實現佇列。雙鏈表的頭指標允許在隊頭檢視和刪除資料,而雙鏈表的尾指標允許我們在隊尾檢視和新增資料。
應用場景:直觀來看,當我們需要按照一定的順序來處理資料,而該資料的資料量在不斷地變化的時候,則需要佇列來幫助解題。在演算法面試題當中,廣度優先搜尋(Breadth-First Search)是運用佇列最多的地方。
## 雙端佇列(Deque)
特點:雙端佇列和普通佇列最大的不同在於,它允許我們在佇列的頭尾兩端都能在 O(1) 的時間內進行資料的檢視、新增和刪除。
實現:與佇列相似,我們可以利用一個雙鏈表實現雙端佇列。
應用場景:雙端佇列最常用的地方就是實現一個長度動態變化的視窗或者連續區間,而動態視窗這種資料結構在很多題目裡都有運用。
**例題分析**
LeetCode 第 239 題:給定一個數組 nums,有一個大小為 k 的滑動視窗從陣列的最左側移動到陣列的最右側。你只可以看到在滑動視窗 k 內的數字,滑動視窗每次只向右移動一位。返回滑動視窗最大值。
注意:你可以假設 k 總是有效的,1 ≤ k ≤ 輸入陣列的大小,且輸入陣列不為空。
```
示例:給定一個數組以及一個視窗的長度 k,現在移動這個視窗,要求打印出一個數組,數組裡的每個元素是當前視窗當中最大的那個數。
輸入:nums = [1, 3, -1, -3, 5, 3, 6, 7],k = 3
輸出:[3, 3, 5, 5, 6, 7]
```
**解題思路**
**思路1**
移動視窗,掃描,獲得最大值。假設數組裡有 n 個元素,演算法複雜度就是 O(n)。這是最直觀的做法。
**思路2**
利用一個雙端佇列來儲存當前視窗中最大那個數在數組裡的下標,雙端佇列新的頭就是當前視窗中最大的那個數。通過該下標,可以很快地知道新的視窗是否仍包含原來那個最大的數。如果不再包含,我們就把舊的數從雙端佇列的頭刪除。
因為雙端佇列能讓上面的這兩種操作都能在 O(1) 的時間裡完成,所以整個演算法的複雜度能控制在 O(n)。

1. 初始化視窗 k=3,包含 1,3,-1,把 1 的下標壓入雙端佇列的尾部;
2. 把 3 和雙端佇列的隊尾的資料逐個比較,3 >1,把 1 的下標彈出,把 3 的下標壓入隊尾;
3. -1<3,-1 壓入雙端佇列隊尾保留到下一視窗進行比較;
4. 3 為當前視窗的最大值;
5. 視窗移動,-3 與隊尾資料逐個比較,-3<-1,-3 壓入雙端佇列隊尾保留;
6. 3 為當前視窗的最大值;
7. 視窗繼續移動,5>-3,-3 從雙端佇列隊尾彈出;
8. 5>-1,-1 從隊尾彈出;
9. 3 超出當前視窗,從佇列頭部彈出;
10. 5 壓入佇列頭部,成為當前視窗最大值;
11. 繼續移動視窗,操作與上述同理。
實現程式碼
```java
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums == null || nums.length < 2) {
return nums;
}
Deque deque = new ArrayDeque<>();
int[] res = new int[nums.length-k+1];
for(int i = 0; i < nums.length; i++) {
while(!deque.isEmpty() && nums[deque.peekLast()] <= nums[i]) {
deque.pollLast();
}
deque.addLast(i);
if(deque.peek() <= i-k) {
deque.poll();
}
if(i+1 >= k) {
res[i+1-k] = nums[deque.peek()];
}
}
return res;
}
}
```
## 樹(Tree)
樹的結構十分直觀,而樹的很多概念定義都有一個相同的特點:遞迴,也就是說,一棵樹要滿足某種性質,往往要求每個節點都必須滿足。例如,在定義一棵二叉搜尋樹時,每個節點也都必須是一棵二叉搜尋樹。
正因為樹有這樣的性質,大部分關於樹的面試題都與遞迴有關,換句話說,面試官希望通過一道關於樹的問題來考察你對於遞迴演算法掌握的熟練程度。
**樹的形狀**
在面試中常考的樹的形狀有:普通二叉樹、平衡二叉樹、完全二叉樹、二叉搜尋樹、四叉樹(Quadtree)、多叉樹(N-ary Tree)。
對於一些特殊的樹,例如紅黑樹(Red-Black Tree)、自平衡二叉搜尋樹(AVL Tree),一般在面試中不會被問到,除非你所涉及的研究領域跟它們相關或者你十分感興趣,否則不需要特別著重準備。
關於樹的考題,無非就是要考查樹的遍歷以及序列化(serialization)。
**樹的遍歷**
**1. 前序遍歷(Preorder Traversal**
方法:先訪問根節點,然後訪問左子樹,最後訪問右子樹。在訪問左、右子樹的時候,同樣,先訪問子樹的根節點,再訪問子樹根節點的左子樹和右子樹,這是一個不斷遞迴的過程。

應用場景:運用最多的場合包括在樹裡進行搜尋以及建立一棵新的樹。
**2. 中序遍歷(Inorder Traversal)**
方法:先訪問左子樹,然後訪問根節點,最後訪問右子樹,在訪問左、右子樹的時候,同樣,先訪問子樹的左邊,再訪問子樹的根節點,最後再訪問子樹的右邊。
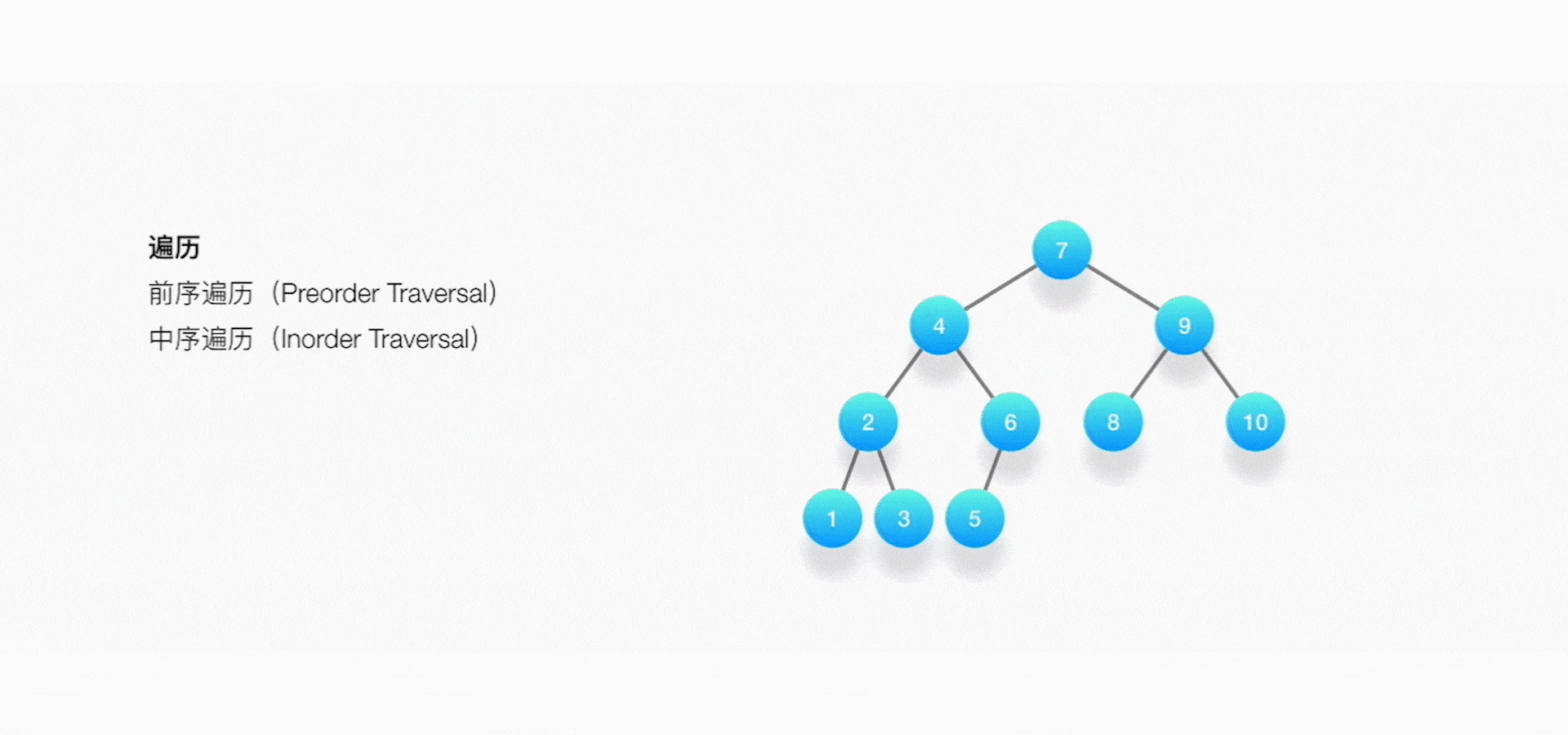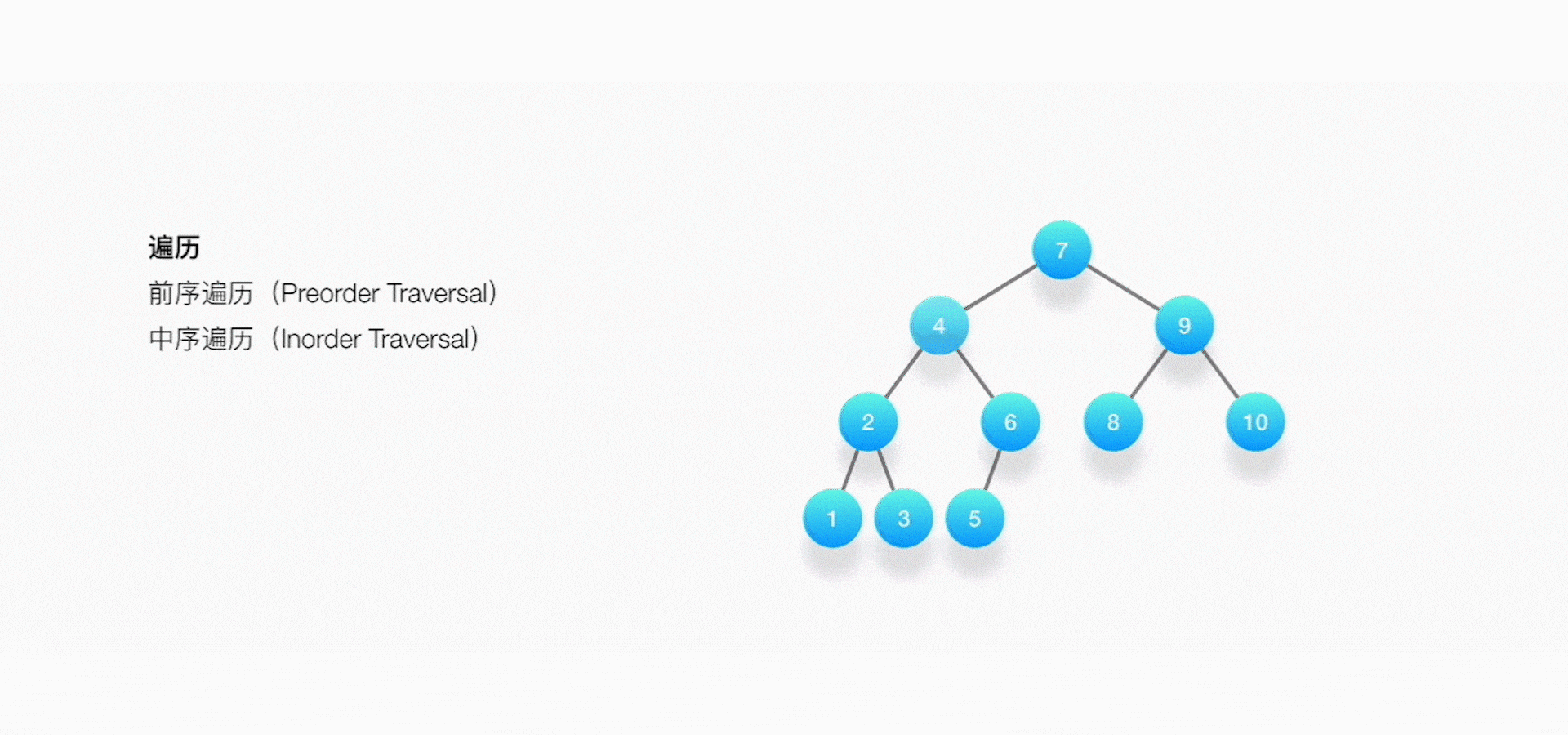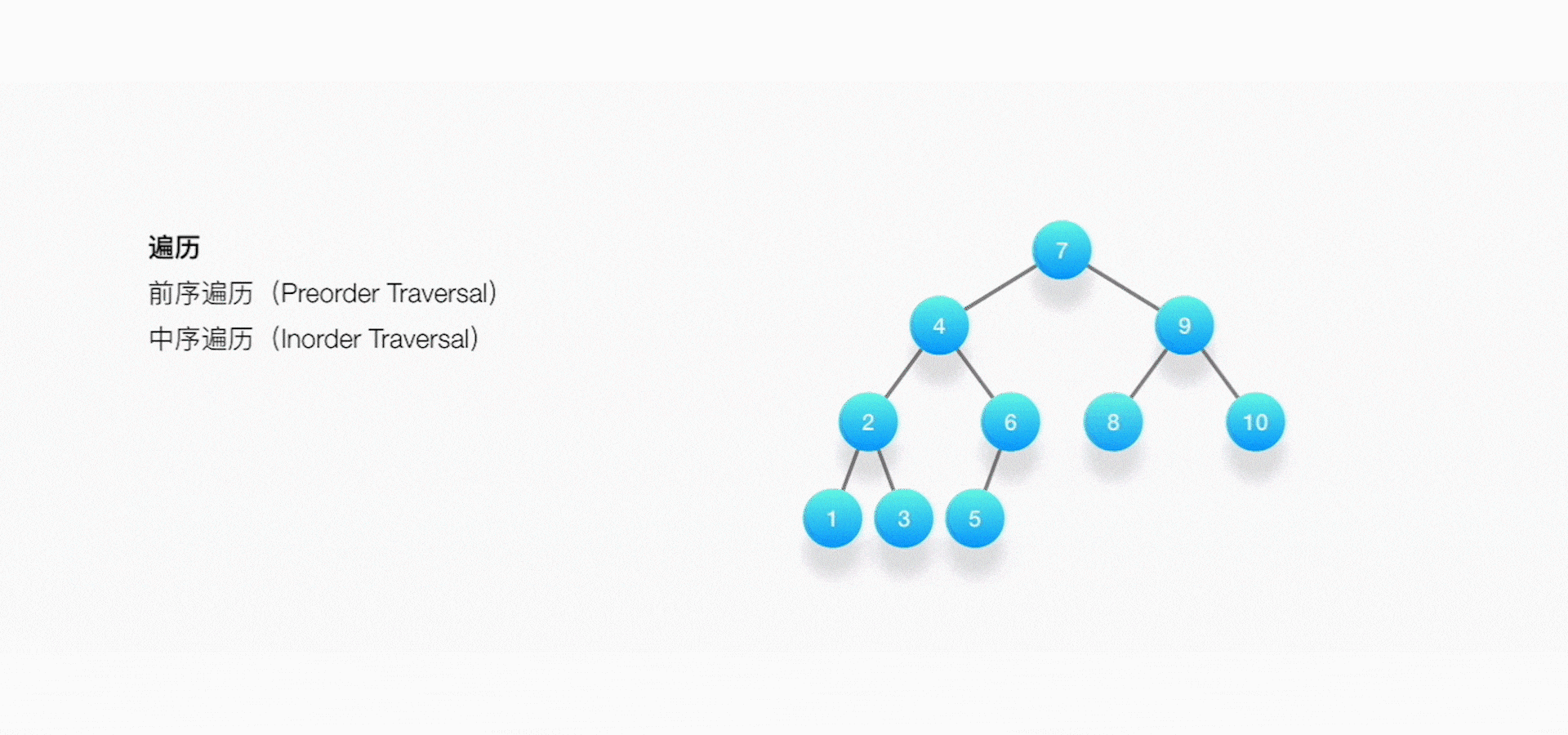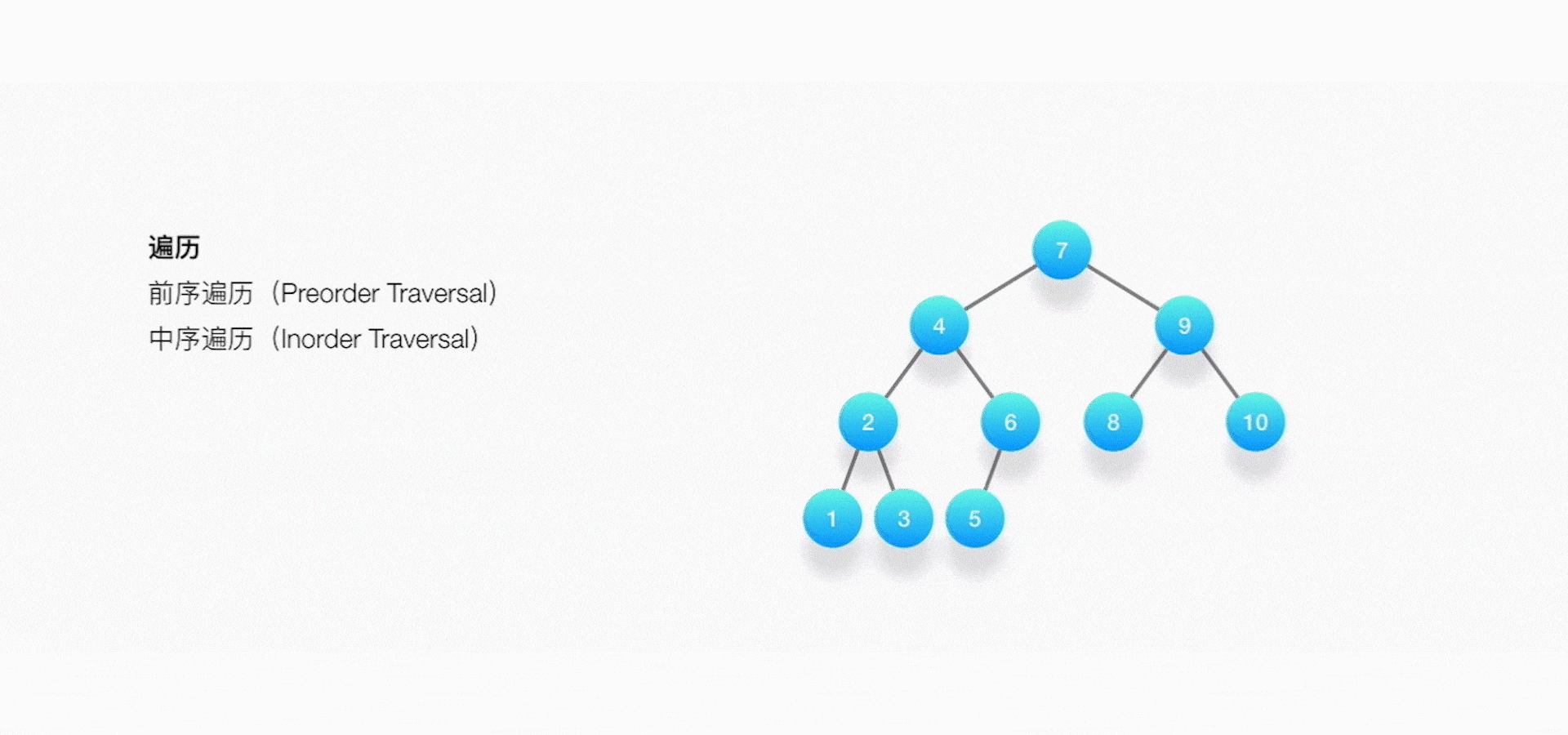
應用場景:最常見的是二叉搜尋樹,由於二叉搜尋樹的性質就是左孩子小於根節點,根節點小於右孩子,對二叉搜尋樹進行中序遍歷的時候,被訪問到的節點大小是按順序進行的。
**3. 後序遍歷(Postorder Traversal)**
方法:先訪問左子樹,然後訪問右子樹,最後訪問根節點。

應用場景:在對某個節點進行分析的時候,需要來自左子樹和右子樹的資訊。收集資訊的操作是從樹的底部不斷地往上進行,好比你在修剪一棵樹的葉子,修剪的方法是從外面不斷地往根部將葉子一片片地修剪掉。
**注意**
* 掌握好這三種遍歷的遞迴寫法和非遞迴寫法是非常重要的,懂得分析各種寫法的時間複雜度和空間複雜度同樣重要。
* 無論是前端工程師,還是後端工程師,在準備面試的時候,樹這個資料結構都是最應該花時間學習的,既能證明你對遞迴有很好的認識,又能幫助你學習圖論。樹的許多性質都是面試的熱門考點,尤其是二叉搜尋樹(BST)。
**例題分析**
LeetCode 第 230 題:給定一個二叉搜尋樹,編寫一個函式 kthSmallest 來查詢其中第 k 個最小的元素。
說明:你可以假設 k 總是有效的,1 ≤ k ≤ 二叉搜尋樹元素個數。
**解題思路**
這道題考察了兩個知識點:
1. 二叉搜尋樹的性質
2. 二叉搜尋樹的遍歷
二叉搜尋樹的性質:對於每個節點來說,該節點的值比左孩子大,比右孩子小,而且一般來說,二叉搜尋樹裡不出現重複的值。
二叉搜尋樹的中序遍歷是高頻考察點,節點被遍歷到的順序是按照節點數值大小的順序排列好的。即,中序遍歷當中遇到的元素都是按照從小到大的順序出現。
因此,我們只需要對這棵樹進行中序遍歷的操作,當訪問到第 k 個元素的時候返回結果就好。

實現程式碼:
```java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
int flag,res;
public void inOrder(TreeNode node) {
if(node == null || flag == 0) {
return;
}
inOrder(node.left);
if(--flag == 0) {
res = node.val;
}
inOrder(node.right);
}
public int kthSmallest(TreeNode root, int k) {
flag = k;
inOrder(root);
return res;
}
}
```
注意:這道題可以變成求解第 K 大的元素,方法就是對這個二叉搜尋樹進行反向的中序遍歷,那麼資料的被訪問順序就是由大到小了。
第K大元素實現程式碼:
```java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
int flag,res;
public void reinOrder(TreeNode node) {
if(node == null || flag == 0) {
return;
}
reinOrder(node.right);
if(--flag == 0) {
res = node.val;
}
reinOrder(node.left);
}
public int kthLargest(TreeNode root, int k) {
flag = k;
reinOrder(root);
return res;